


























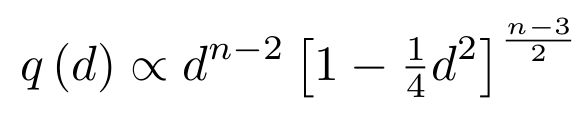
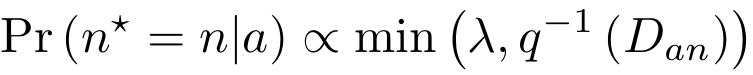


























Artsiom S
PhD student in Computer Vision
PhD candidate, Computer Vision Group
Kaggle Master (45-th out of 113.000+)
Divide and Conquer the Embedding Space for Metric Learning (CVPR 2019)
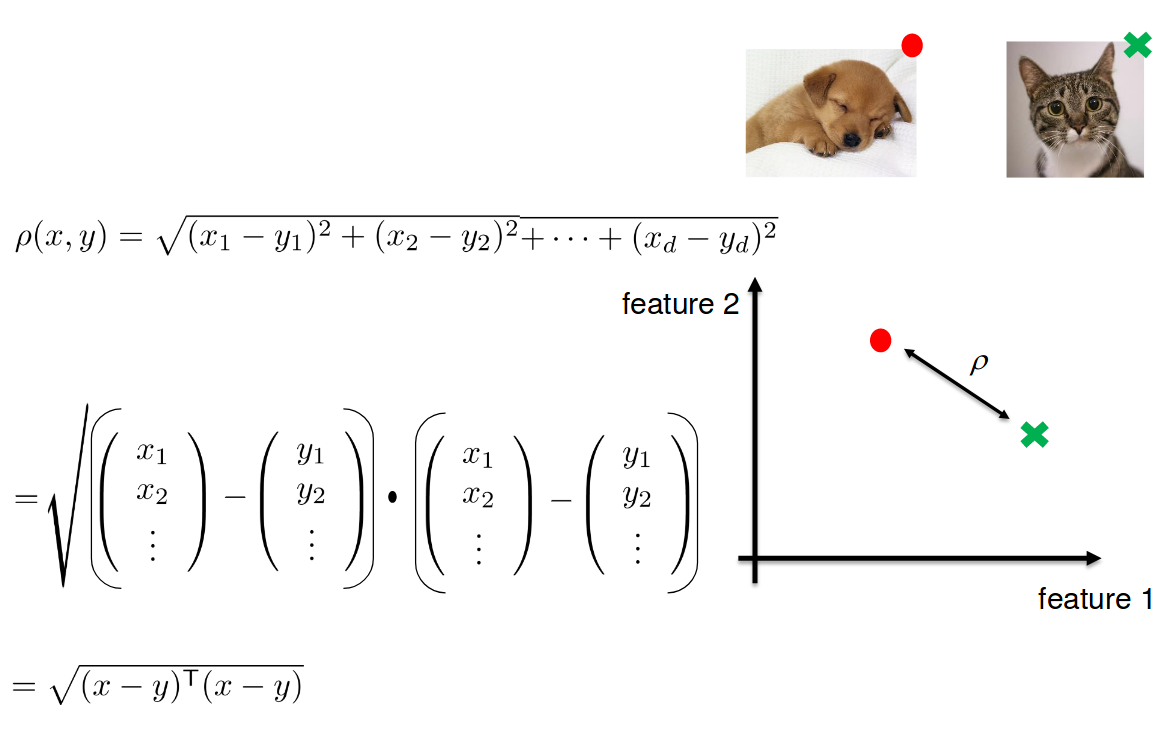
Project images in d-dimensional Euclidean space where distances directly correspond to a measure of similarity
Basic idea: learn a metric that assigns small (resp. large) distance to pairs of examples that are semantically similar (resp. dissimilar).
Metric Learning
d-dimensional Embedding Space
Basic idea: learn a metric that assigns small (resp. large) distance to pairs of examples that are semantically similar (resp. dissimilar).
Metric Learning
d-dimensional Embedding Space
Small distance
Basic idea: learn a metric that assigns small (resp. large) distance to pairs of examples that are semantically similar (resp. dissimilar).
Metric Learning
d-dimensional Embedding Space
Large distance
Handwriting recognition
Person identification
Image Search
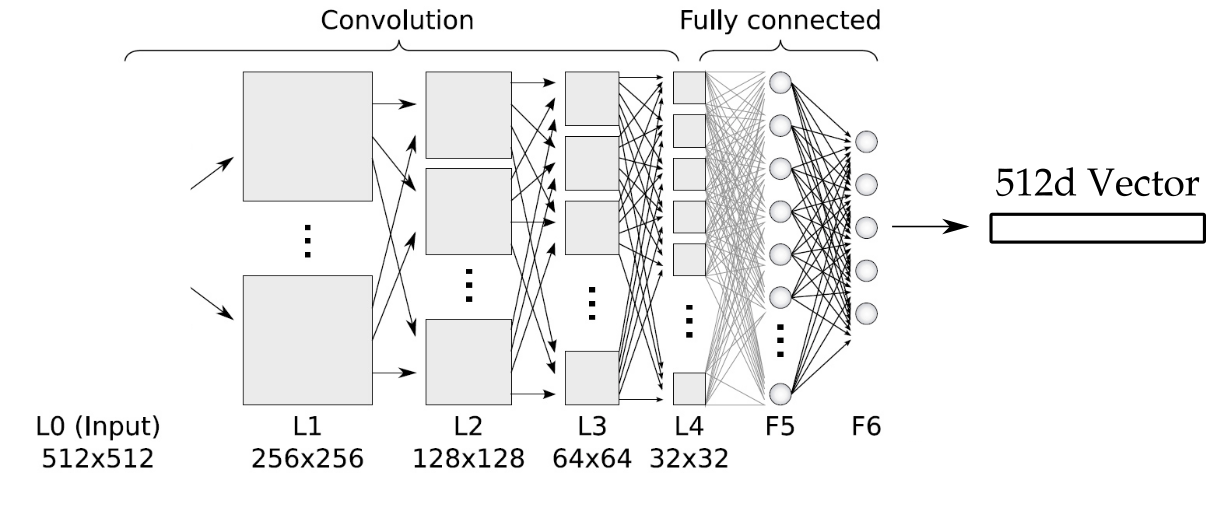
Project Image in d-dimensional space where Euclidean distance would make sense
Courtesy: cs-230 course, Stanford University
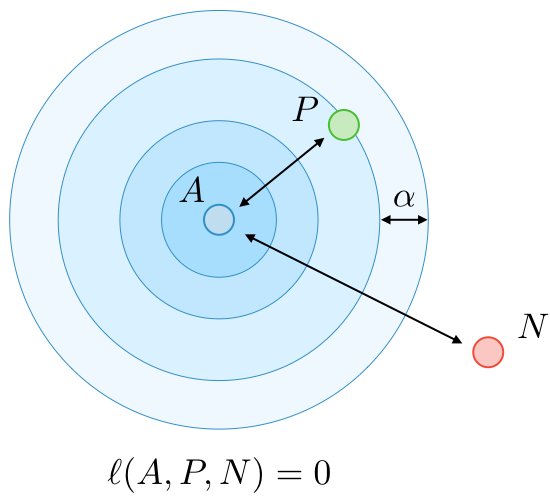
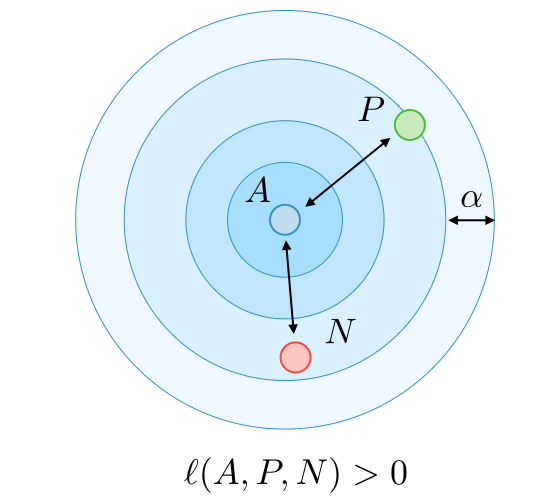
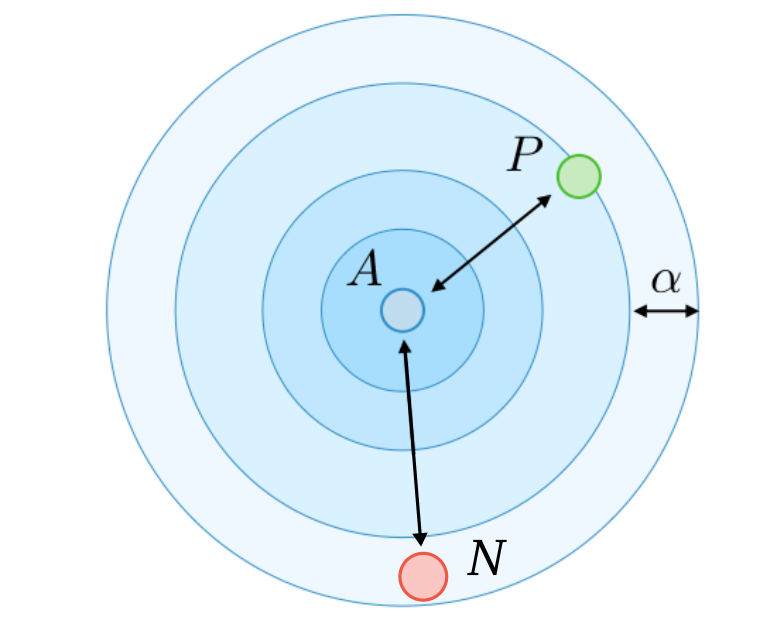
A = Anchor
P = Positive
N = Negative
Leopard
Lion
Easy!
Leopard
Jaguar
Difficult!
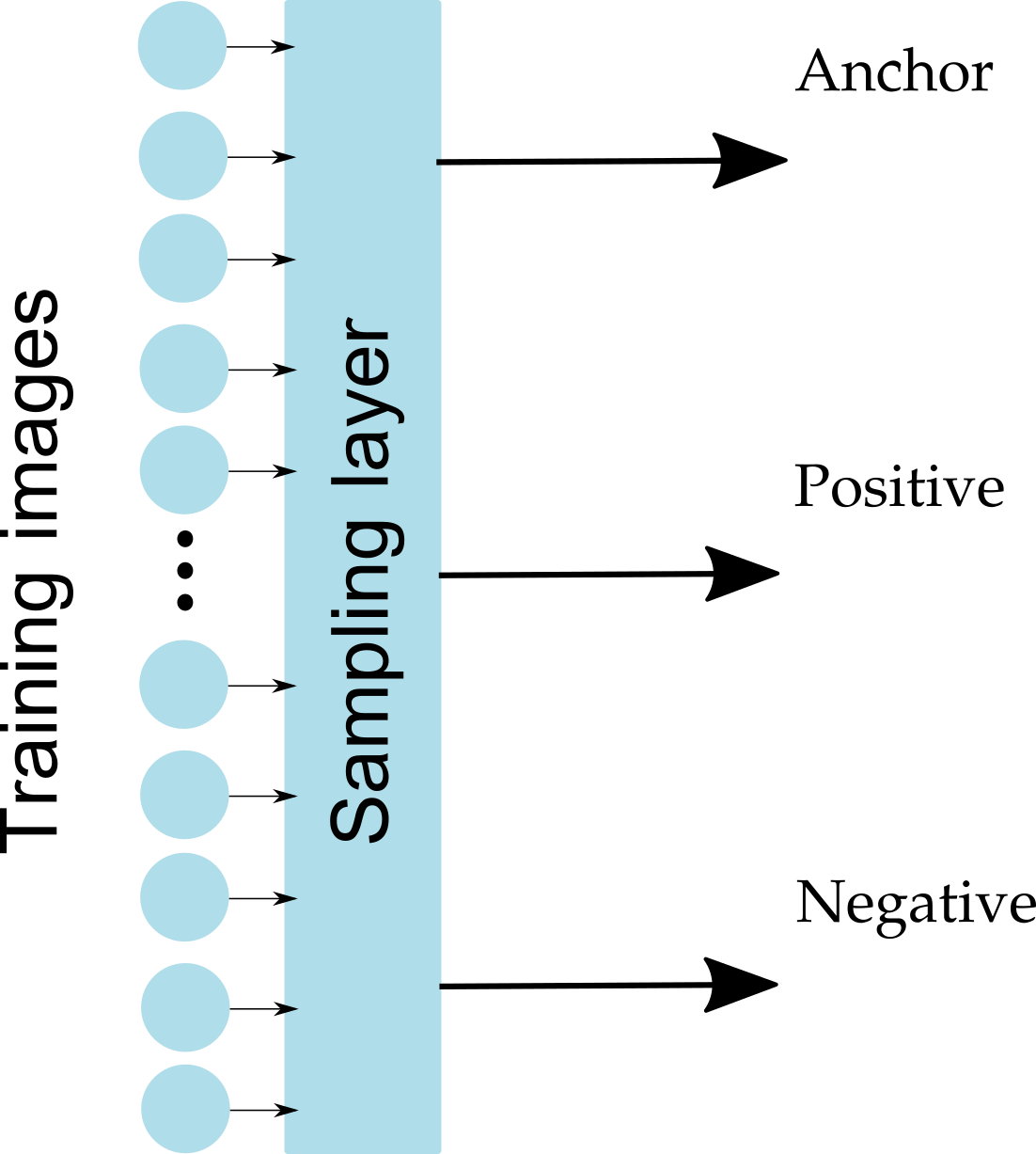
possible triplets in the dataset
Sample randomly?!
NO. Only small portion of all triplets is meaningful and has non-zero loss
possible triplets in the dataset
Sample randomly?!
NO. Only small portion of all triplets is meaningful and has non-zero loss
Sample only meaningful triplets!
It’s important to select “hard” triplets (which would contribute to improving the model) to use in training. How do we do that?
Sample "hard" (informative) triplets, where loss > 0
Sampling must select different triplets as training progresses
[*] FaceNet: A Unified Embedding for Face Recognition and Clustering, Schroff et al., 2015
Hard triplet
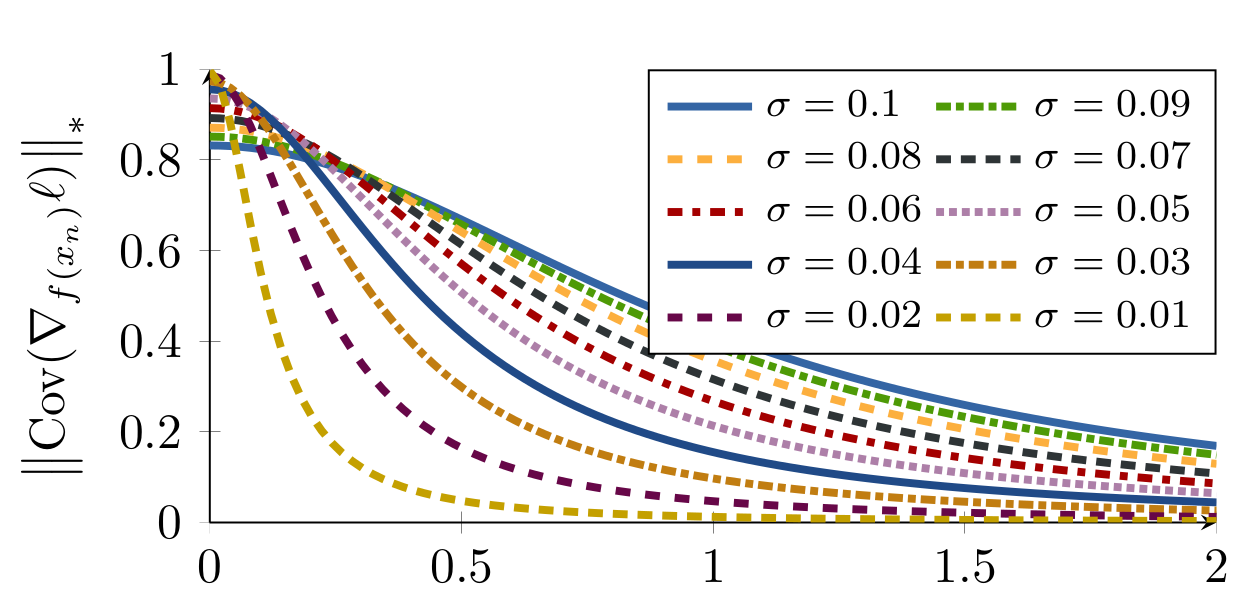
1. Gradient with respect to negative example f(N) takes form of
- some function
determines the gradient direction.
Hard triplet
1. Gradient with respect to negative example f(N) takes form of
determines the gradient direction. Dominated by noise if is too small
- some function
noise
Variance of gradient at different noise levels
Sampling Matters in Deep Embedding Learning, Wu et al., ICCV 2017
Hard triplet
2. Selecting the hardest negatives can in practice lead to bad local minima early on in training, specifically it can result in a collapsed model (i.e. f(x) = 0) [1].
[1] FaceNet: A Unified Embedding for Face Recognition and Clustering, Schroff et al., 2015
Semi-Hard triplet
Hard triplet
Semi-Hard triplet
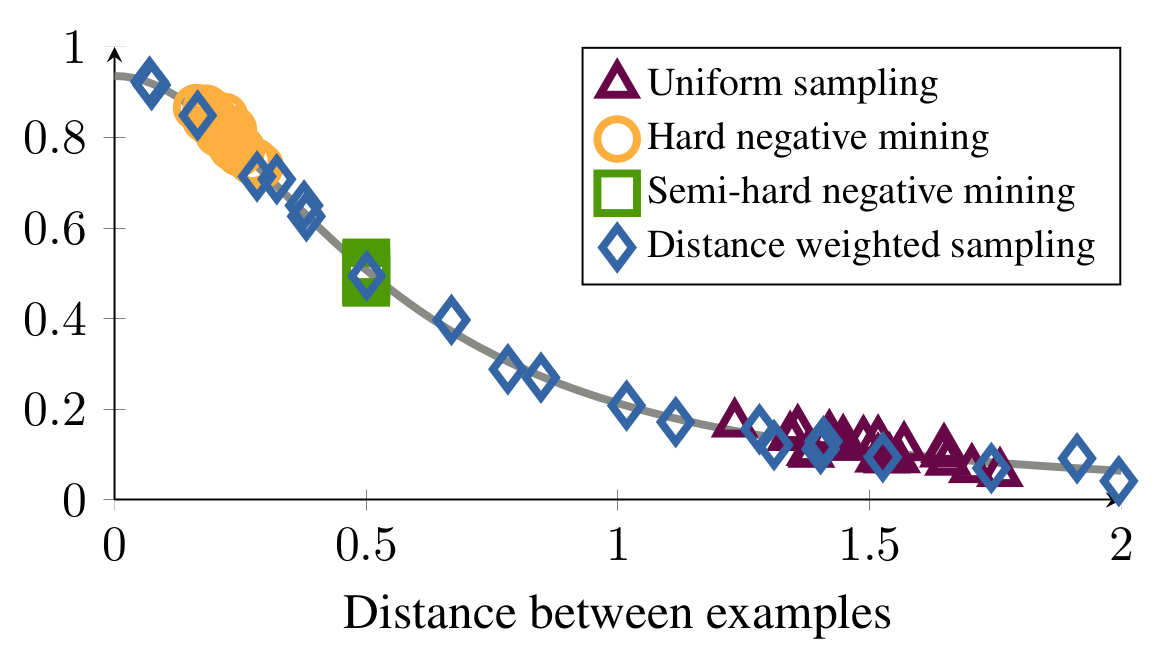
Fig. 2: Distribution of distances between anchor and negative for different strategies
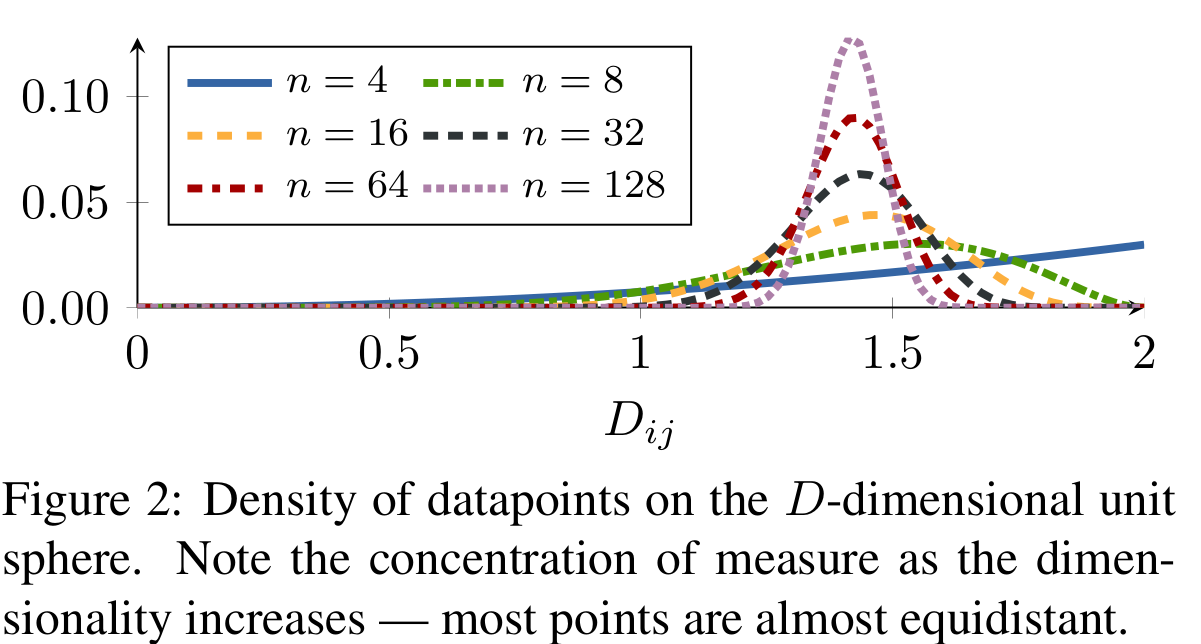
Fig. 1: Density of datapoints on the n-dimensional unit
sphere. Note the concentration of measure as the dimensionality increases — most points are almost equidistant.
Variance of gradient
Sampling Matters in Deep Embedding Learning, Wu et al., ICCV 2017
Sampling Matters in Deep Embedding Learning, Wu et al., ICCV 2017
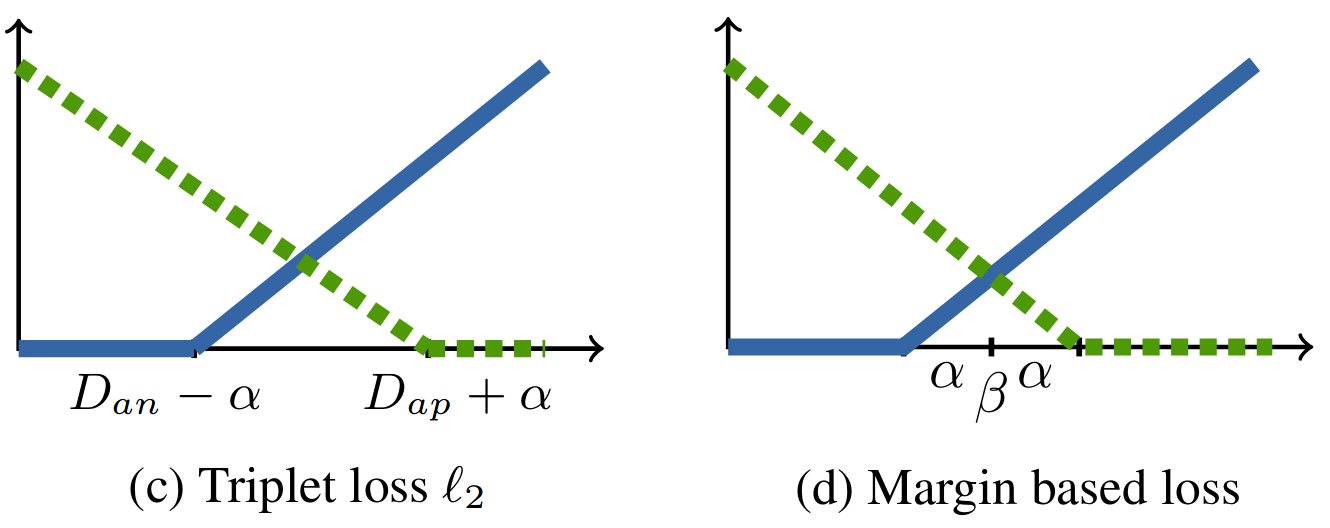
Triplet Loss
Loss for positive pairs
Loss for negative pairs
Triplet Loss
Margin Loss
CVPR 2019
Universal approximation theorem:
A feed-forward network with a single hidden layer containing a finite number of neurons can approximate continuous functions on compact subsets of R, under mild assumptions on the activation function — Wikipedia
In simple terms: you can always come up with a deep neural network that will approximate any complex relation between input and output.
IN PRACTICE: It is extremely difficult to get an optimal solution since the objective function is highly non-convex. We always get stuck in local optima.
Existing Approaches: Learn a single distance metric for all training data
→ Overfit and fail to generalize well.
Existing Approaches: Learn a single distance metric for all training data
→ Overfit and fail to generalize well.
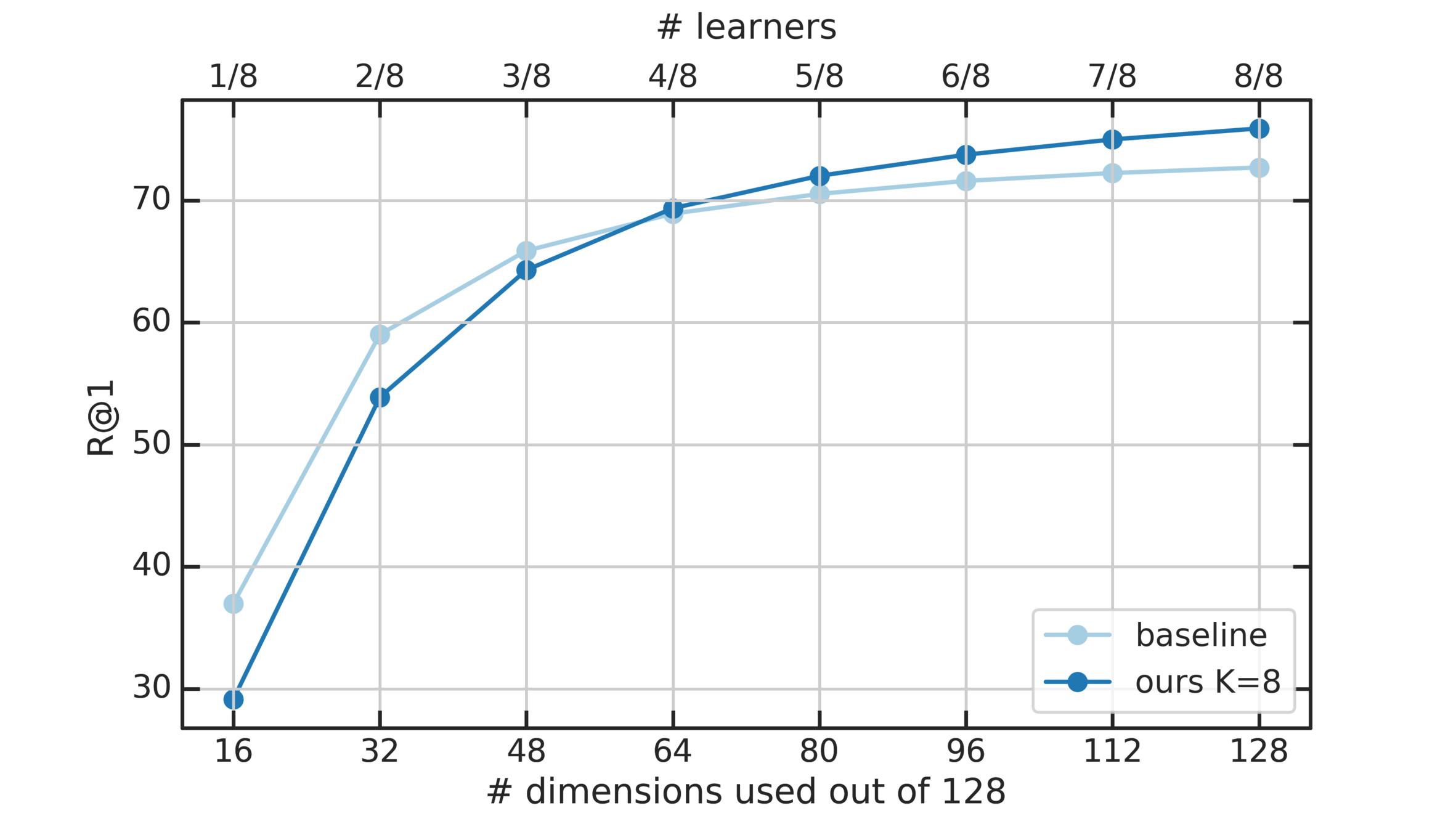
To alleviate this problem: Learn several different distance metrics on non-overlaping subsets of the data.
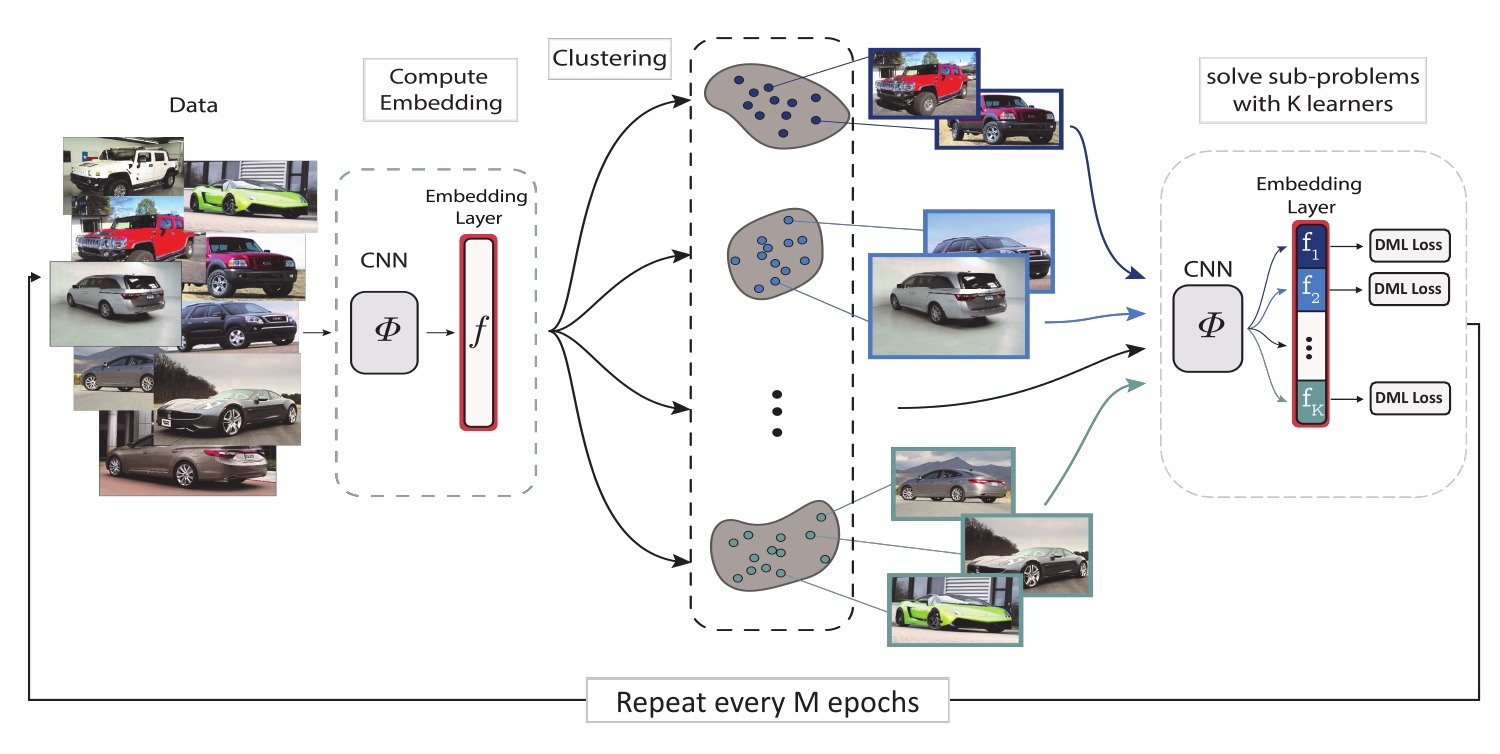
1. Compute embeddings for all train images
K clusters
2. Split the data into K disjoint subsets
3. Split the embedding space in K subspaces of d/K dimensions each.
Split the embedding space in K subspaces
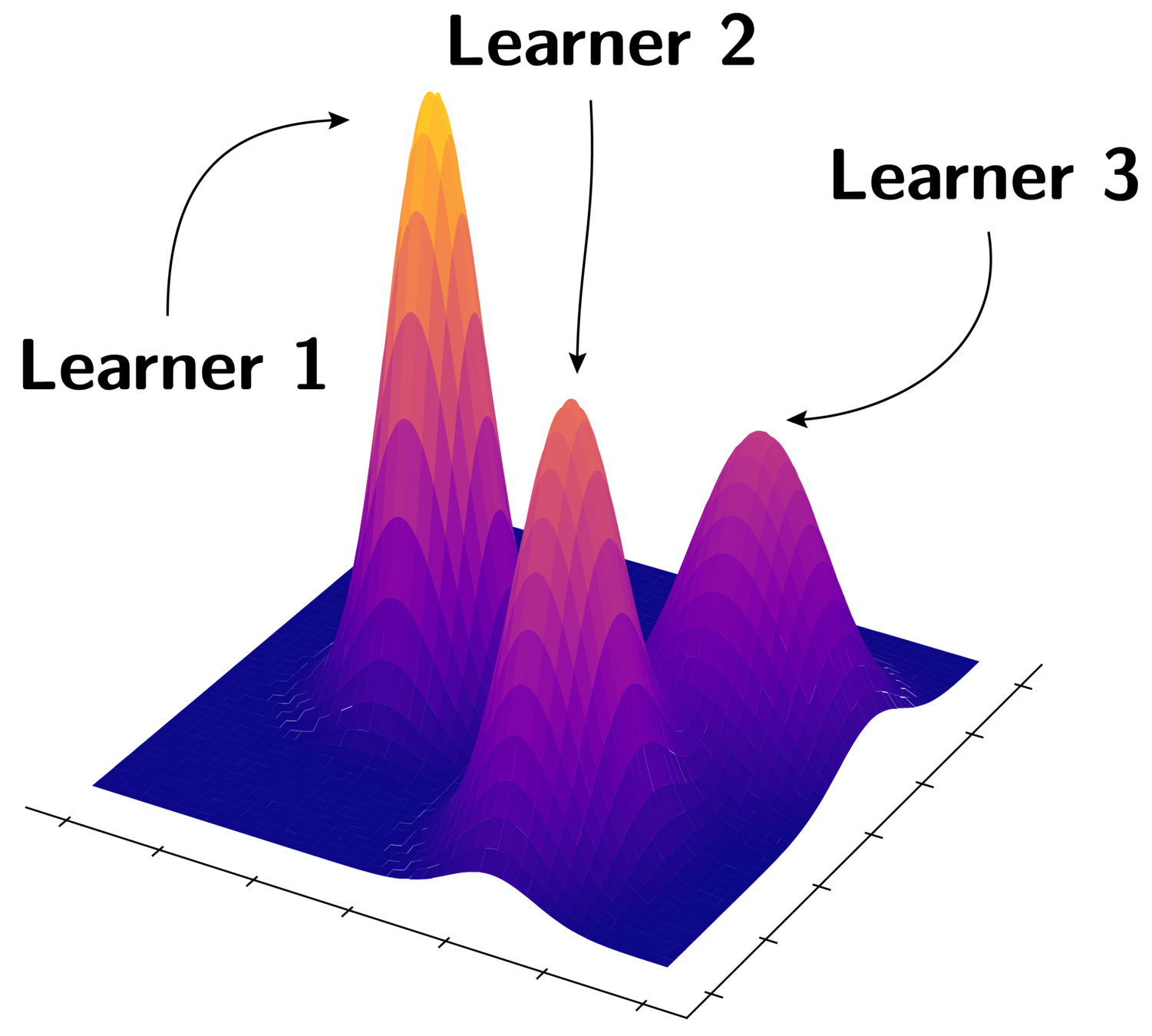
4. Assign a separate learner (loss) to each subspace.
5. Train K different distance metrics using K learners.
K Learners
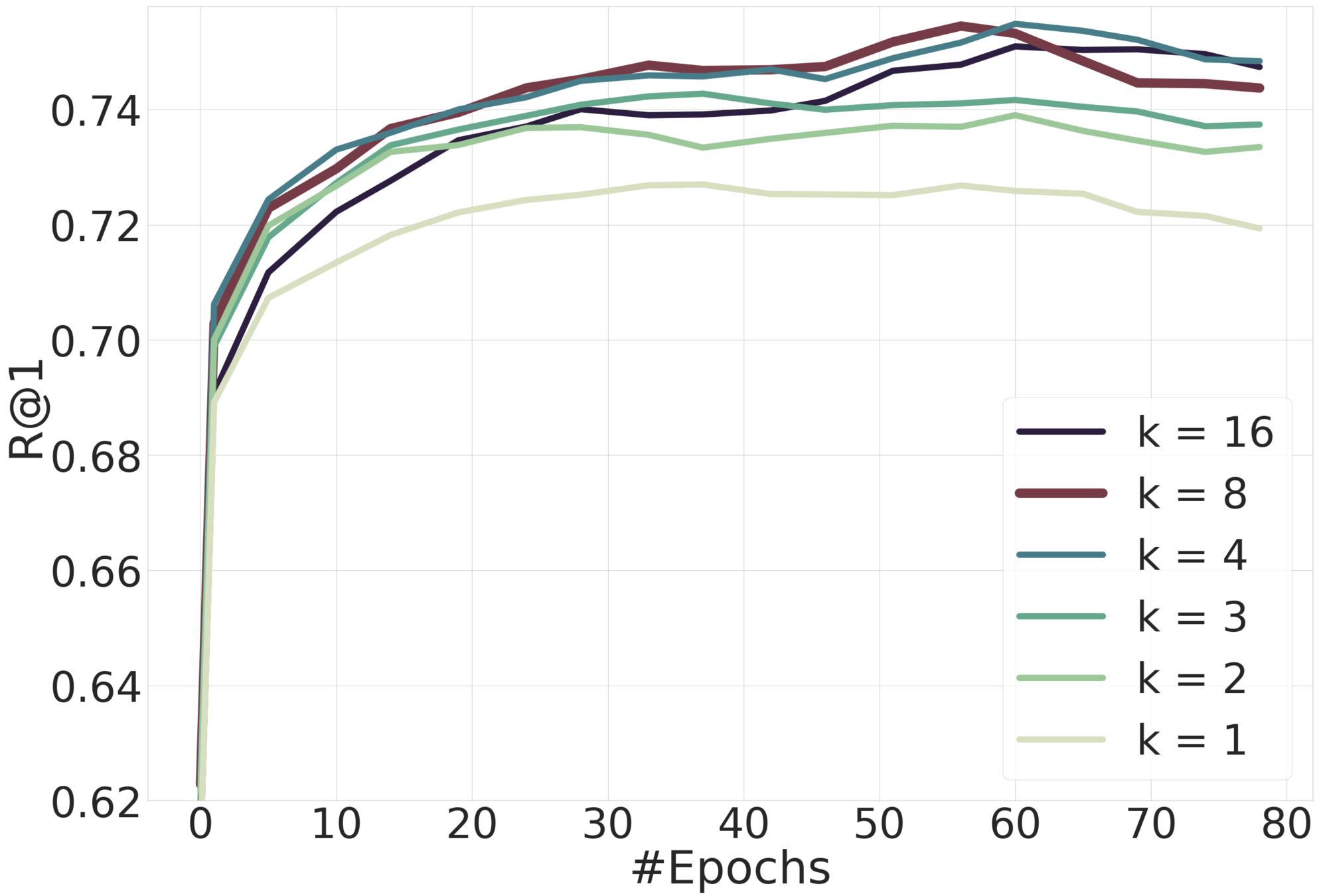
6. Repeat every M epochs
Split the embedding space in K subspaces of d/K dimensions each.
Assign a separate learner (loss) to each subspace.
Train K different distance metrics using K learners.
Every learner is trained on the data within one cluster
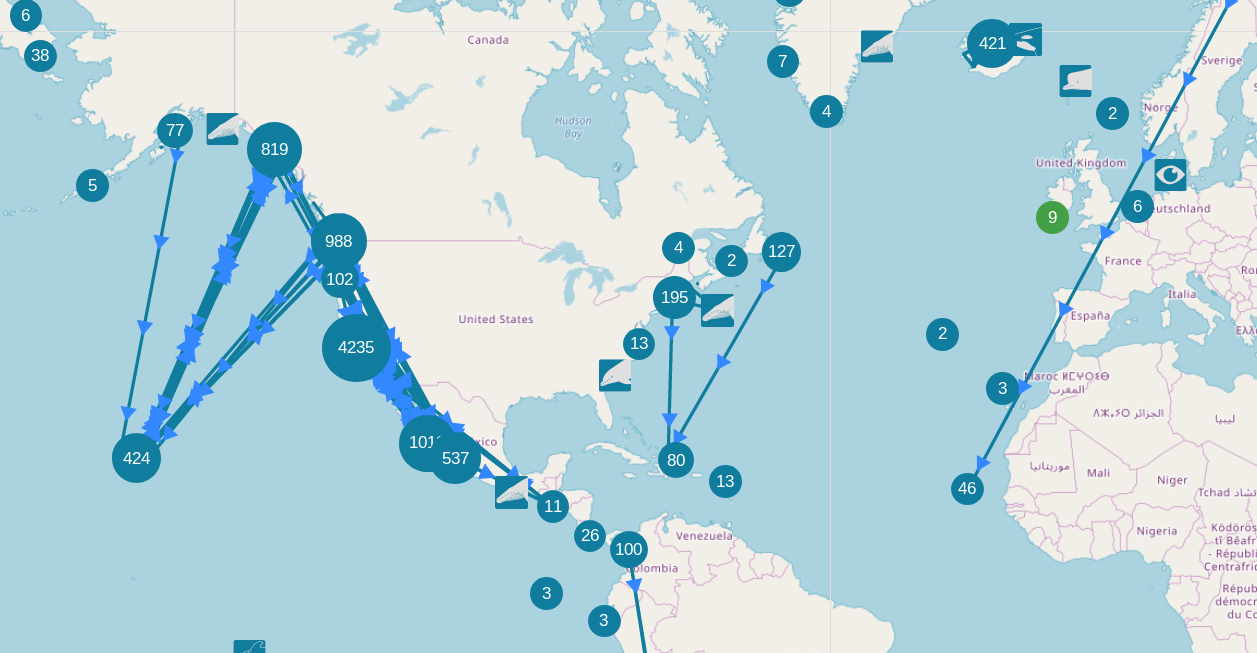
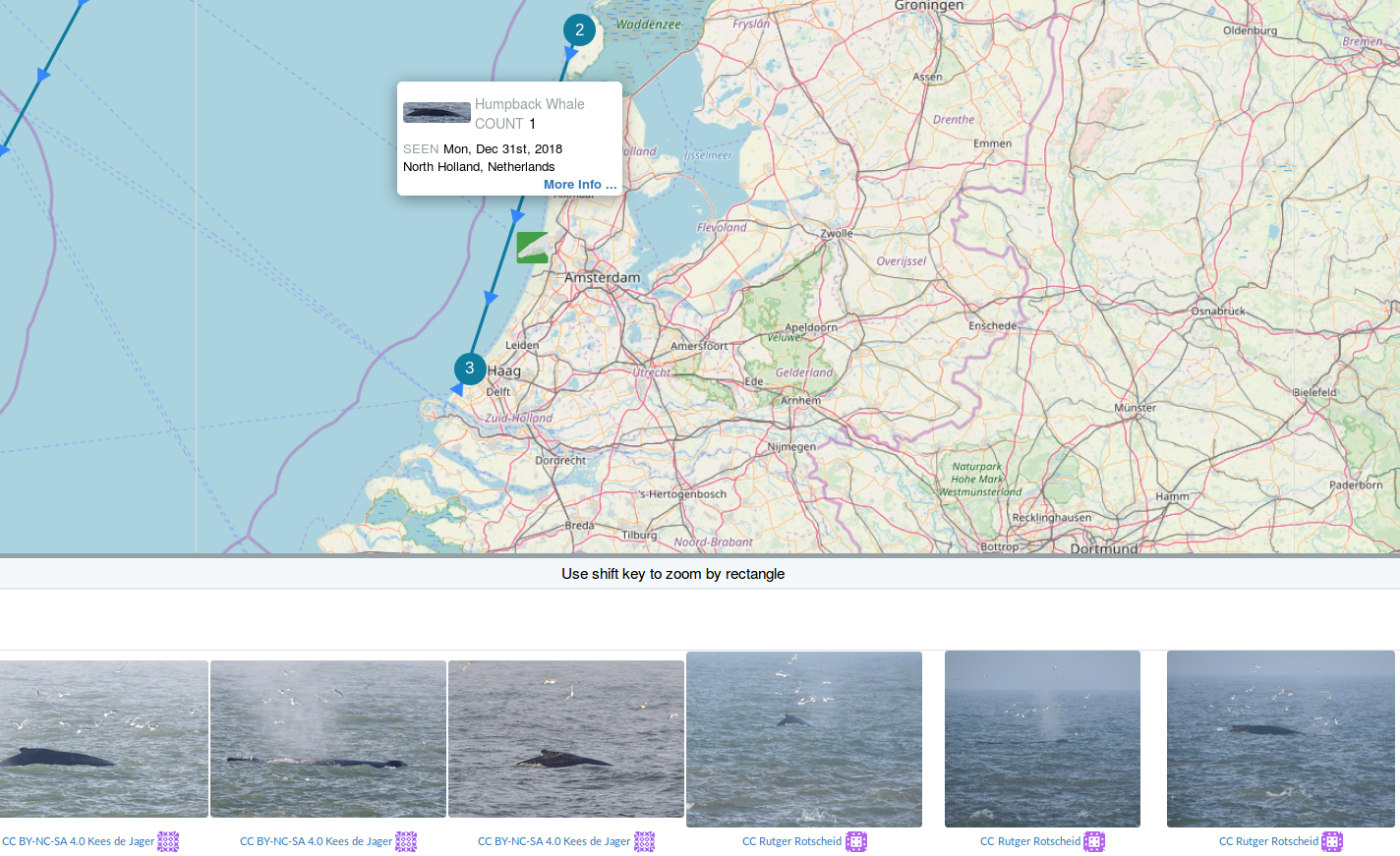
Which whale is it?
Oscar
Match!
Happywhale engages citizen scientists to identify individual marine mammals, for fun and for science
They tracks your whales around the globe
Vladislav Shakhray
MIPT Student,
Russia
Artsiom Sanakoyeu
Me
Pavel Pleskov
Data Scientist at Point API
Russia
Open Data Science - Russian Speaking Data Science Community: ODS.ai
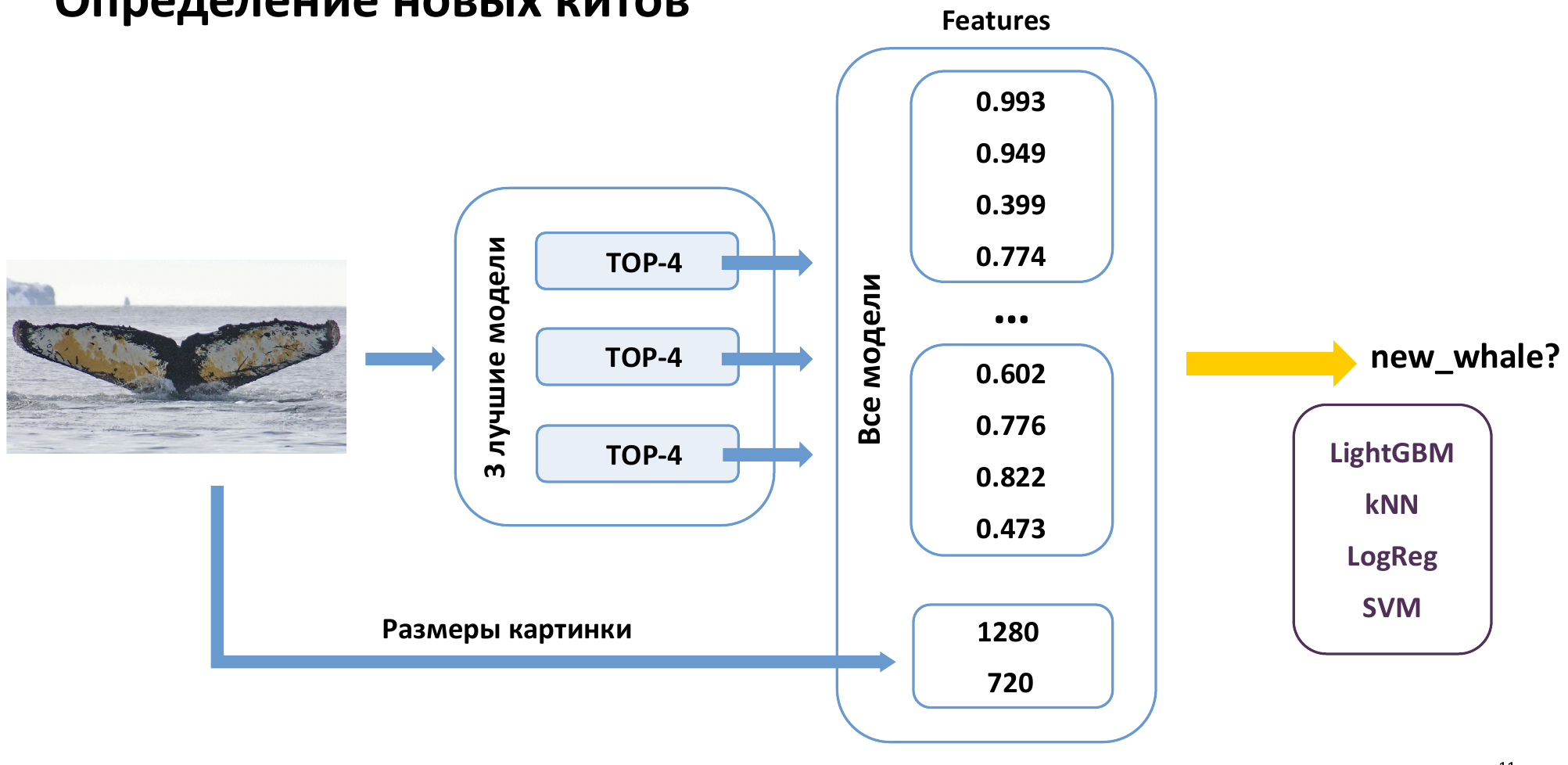
Identify among 5004 whale IDs or predict "new whale"
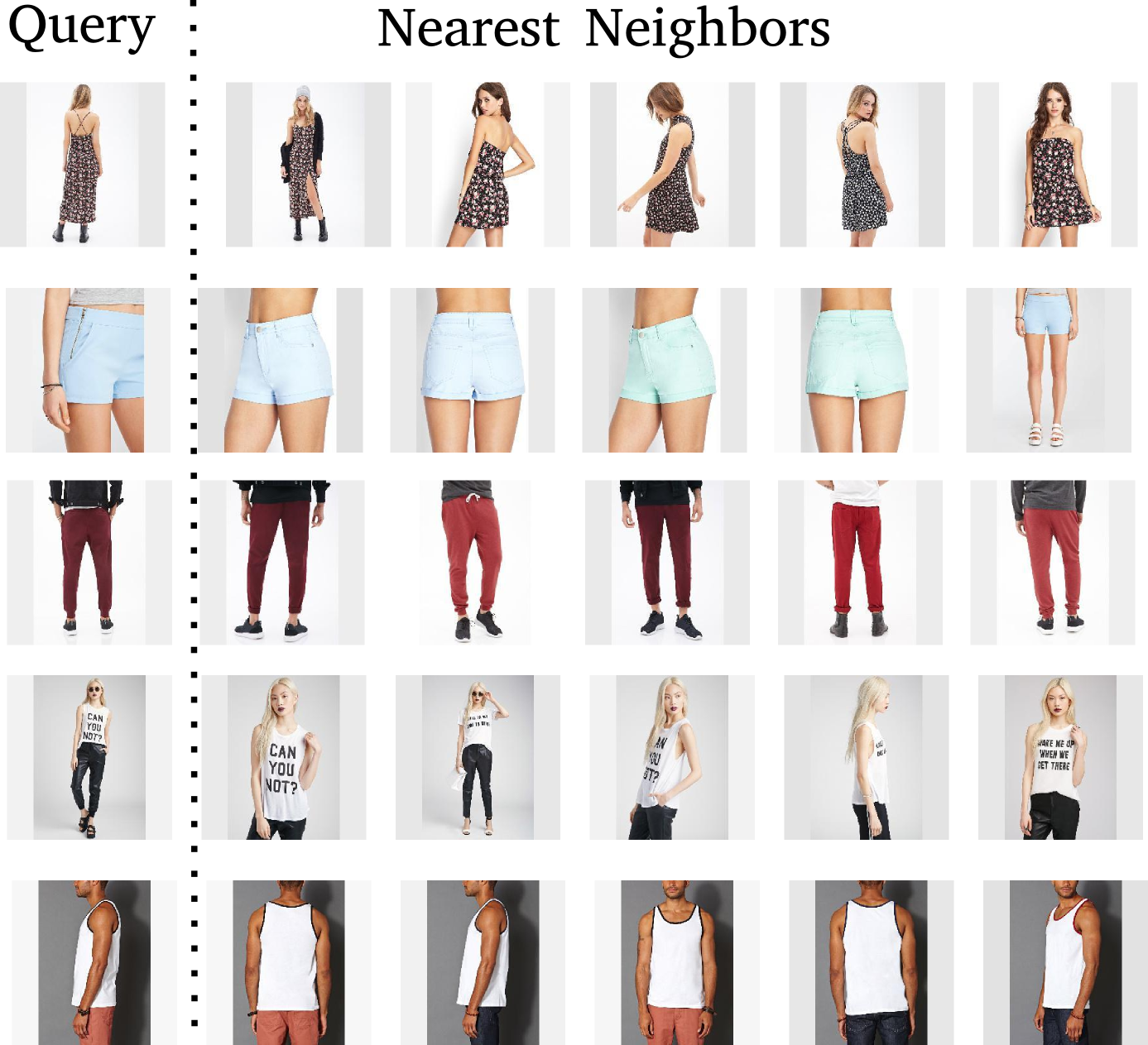
Query image
Find a match in the train set
Other train images
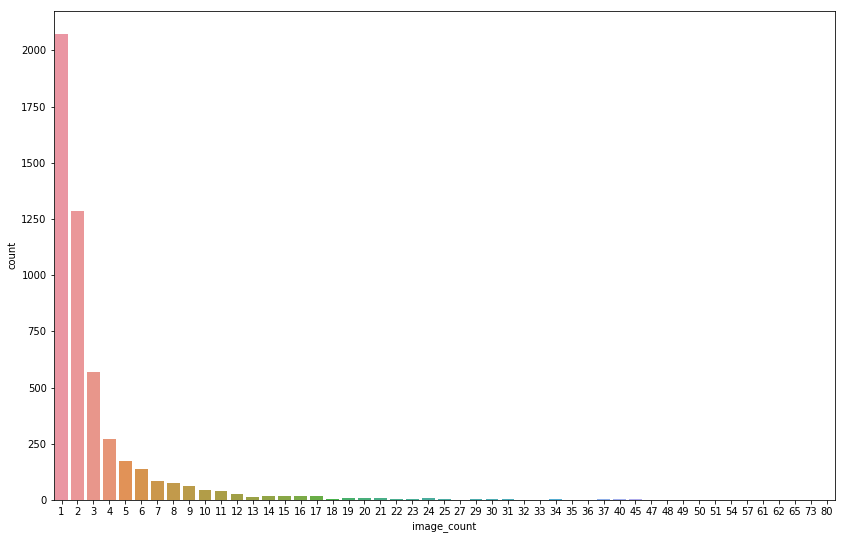
Class size distribution
Mean Average Precision @ 5
N is the number of images,
P(k) is the precision at cutoff k,
n is the number predictions per image,
rel(k) is an indicator function equaling 1 if the item at rank k is a relevant (correct) label, zero otherwise.
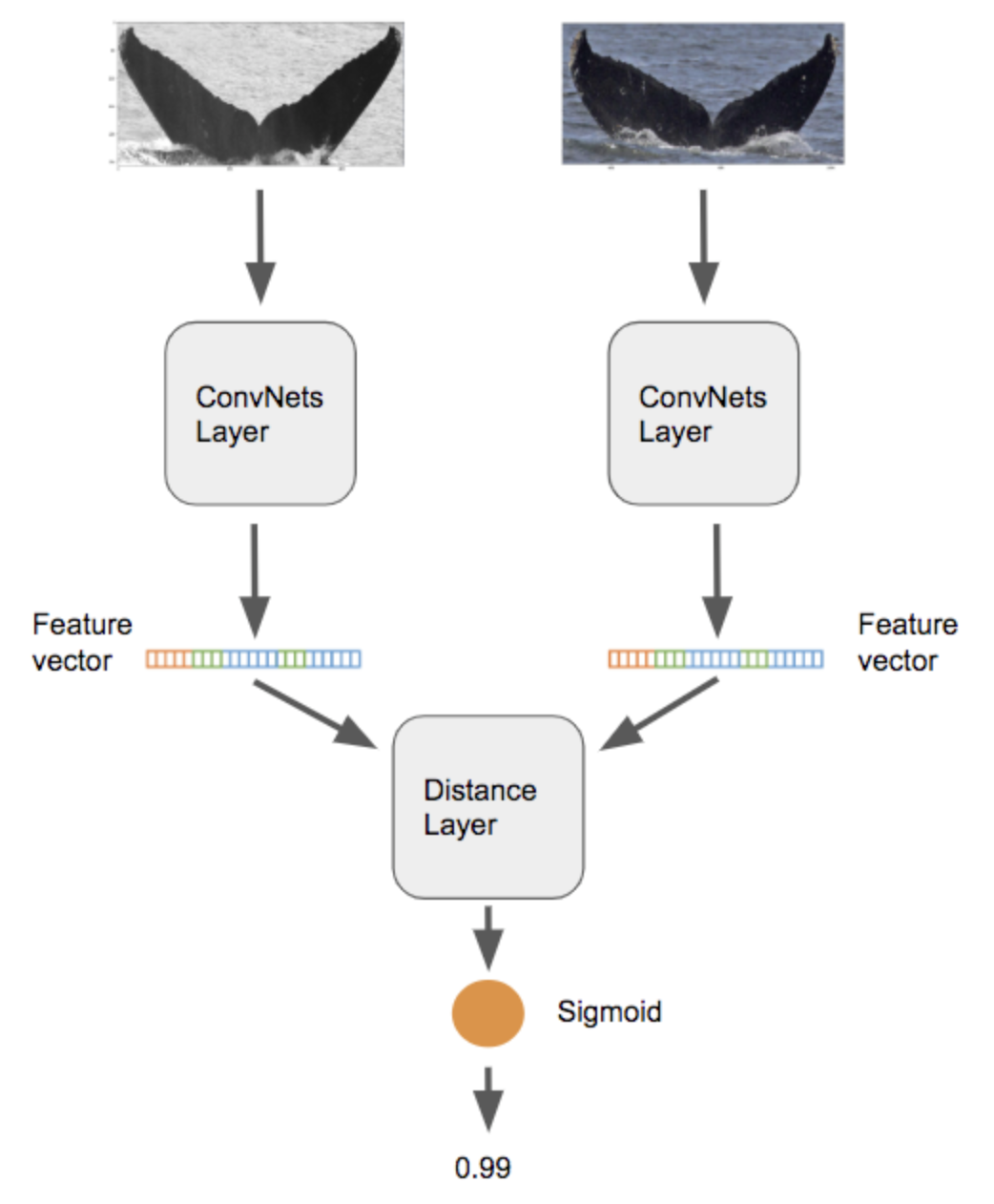
A. Ensemble of:
B.
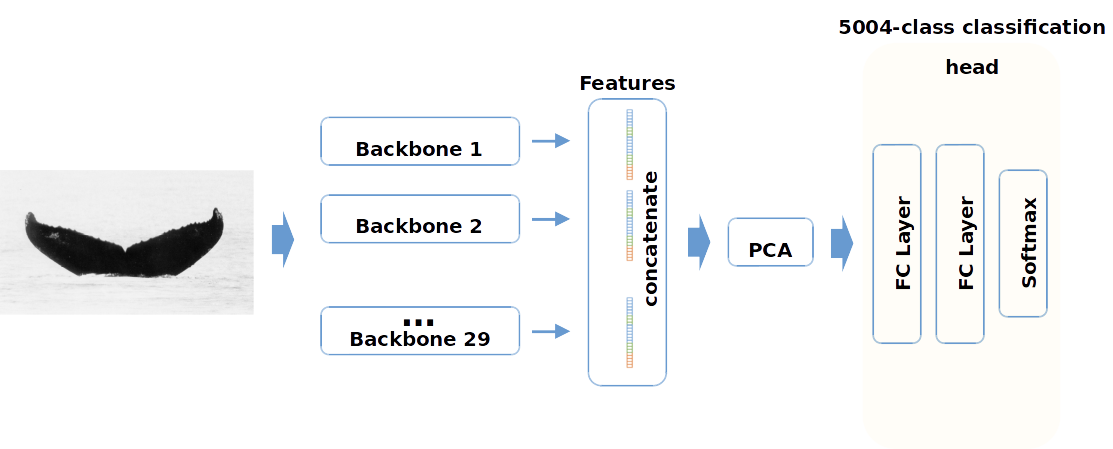
Softmax classifier on top of features from 29 networks.
Backbones:
Tricks:
Backbones:
Tricks:
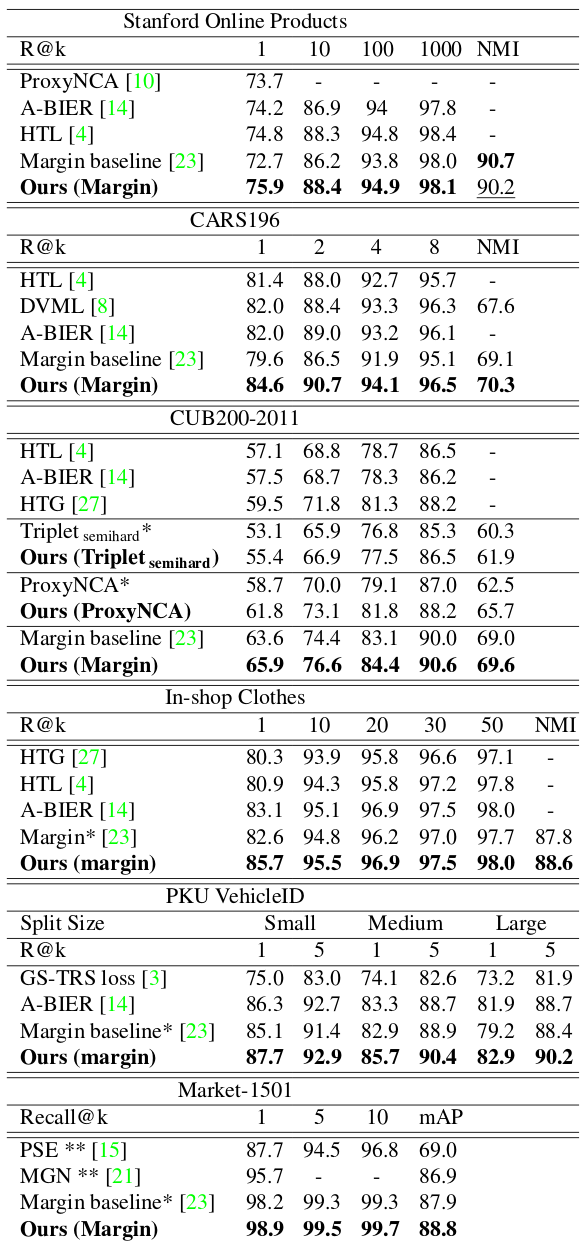
“Divide and Conquer the Embedding Space for Metric Learning”, Sanakoyeu et al., In CVPR 2019
MAP@5=0.924 LB
~12.000 dim
2048 dim
Image size
3 Best models
class probabilities
By Artsiom S
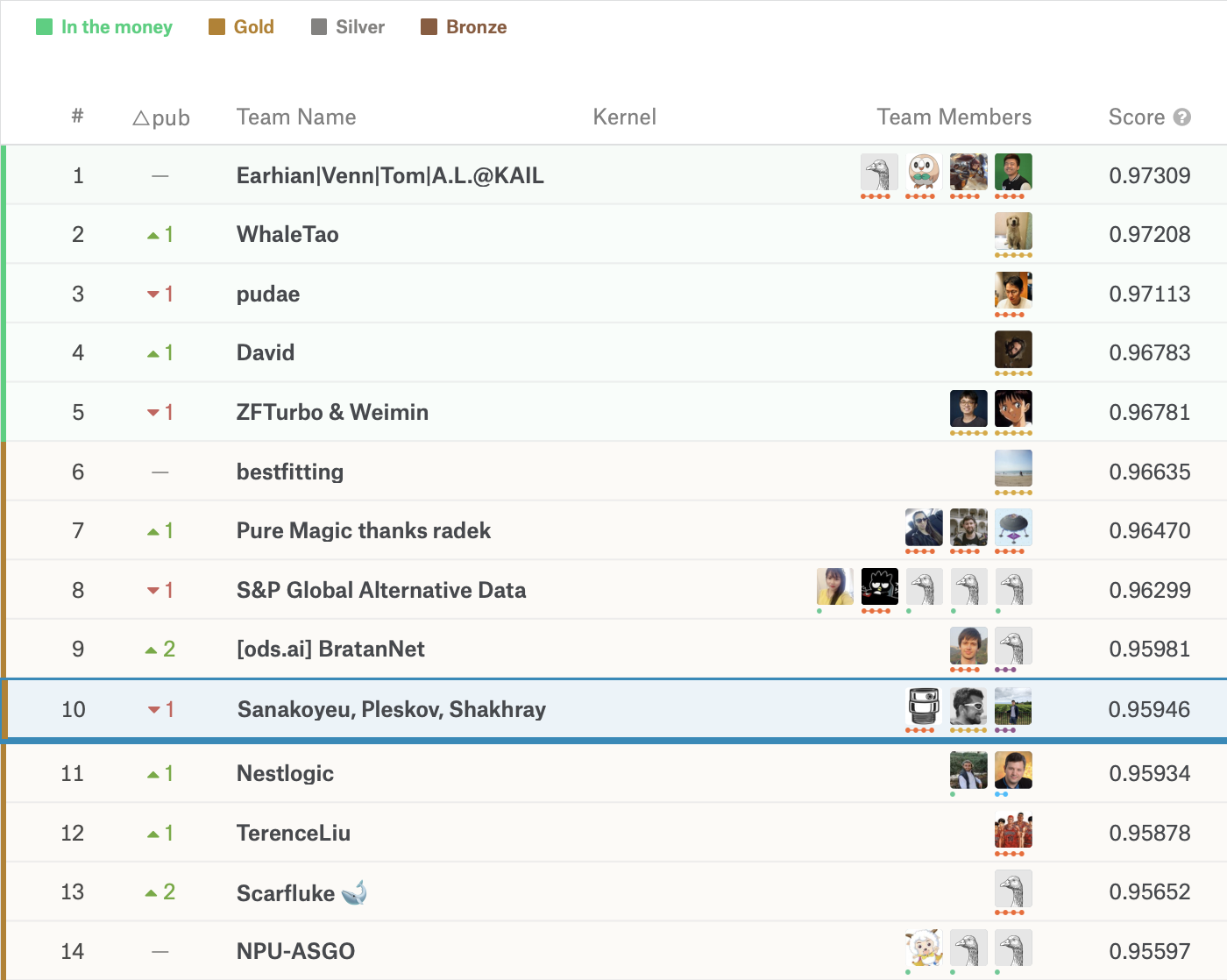
Talk at Heidelberg SIAM chapter (09.07.2019). I will discuss existing approaches to learn the embedding space using Deep Metric Learning (DML) as long as our novel `divide and conquer` approach (CVPR 2019) for deep metric learning, which significantly improves the state-of-the-art performance of metric learning. In the second part of the talk, I will show how deep metric learning approaches can be applied to a real-world problem: Humpback whale identification. Humpback whale identification challenge was hosted at Kaggle platform. More than 2100 teams were challenged to build a computer vision algorithm to identify individual whales in images and release biologists form tedious manual work. I will discuss our solution based on DML which placed us in the Top-10 in the final standings.
