Mystery behind 502
Error
Users frequently receiving "Something bad happened" messages
What was happening?
- Randomly getting 502 gateway timeout error from Cloudfront
- PROD /QA / E2E
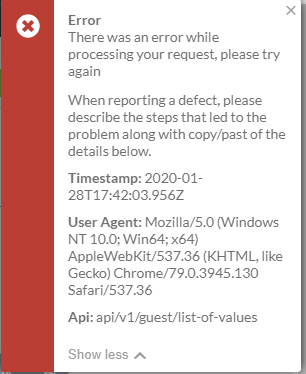
Architecture
Revisit
Initial Assumption
- No idea , from where the error was originating.
- We thought it might be due to load or some bad code, which was causing nodejs event loop to get blocked.
- Planned load test to proof this theory.
New Clues
- The error occurred even when the load was low
- The error was return immediately from api
So that means...

The issue was not due to Load

Time to Dig Deeper
- Enabled Cloudfront logs
- Enable Loadbalancer Logs
- Wrote custom scripts to filter logs

Average occurrence in production
{ date: '2020-02-01', count: 1 },
{ date: '2020-01-31', count: 27 },
{ date: '2020-01-30', count: 35 },
{ date: '2020-01-29', count: 40 },
{ date: '2020-01-28', count: 39 },
{ date: '2020-01-27', count: 31 },
{ date: '2020-01-26', count: 2 },
{ date: '2020-01-25', count: 1 },
{ date: '2020-01-24', count: 25 },
{ date: '2020-01-23', count: 42 },
{ date: '2020-01-22', count: 44 }Finding Root Cause

Root Cause Identified
- Keep alive of API server/container was less than the keep alive (idle timeout) of AWS load balancer.
- So just before receiving the HTTP request from load balancer, api server/container terminates the TCP connection, hence the load balancer immediately returns 502.
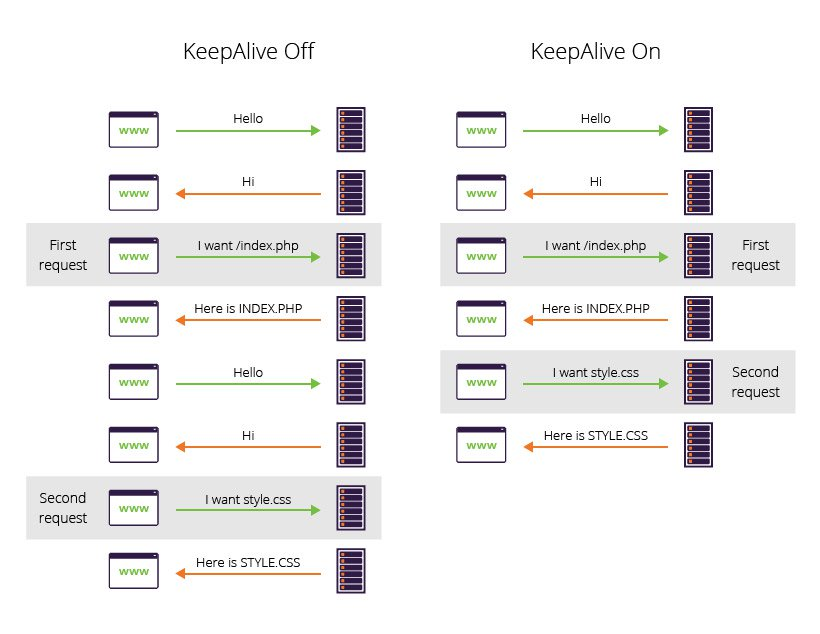
What is Keep Alive?
- By default, HTTP connections close after each request
- Is an instruction that allows a single TCP connection to remain open for multiple HTTP requests/responses.
Initial Config
- Cloudfront (60 seconds)
- load Balancer (60 seconds)
- API container (Default 5 seconds)
Initial Config
- cloudfront (55 seconds) < load balancer (60 seconds) < API container (nodejs keepAliveTimeout (61 seconds) < headersTimeout (65 seconds) )
Mystery Closed

502 error
By Asjad Saboor




