THE MERGE
本日主題
為什麼需要區塊鏈?
一些技術演進
ETH: THE MERGE
為什麼需要區塊鏈?
ex:
- 治安,法規
- 法幣、證券
- 資訊
首先先想想那些你鮮少質疑過的事情
為什麼你對這些事物的運作理所當然,是什麼確保了這層信任
----> 可靠第三方的擔保
-----> 你相信這個第三方
這個世界的運作是建立在『信任』的基礎之上的,若是每件事情都需要懷疑,就很累
但你總會有懷疑的時候吧?
且越多轉手的資訊越不容易查證
區塊鏈正是透過技術上一目瞭然各種資訊的傳遞,你也能確保鍊上資訊不被篡改,且也少了中間人的介入
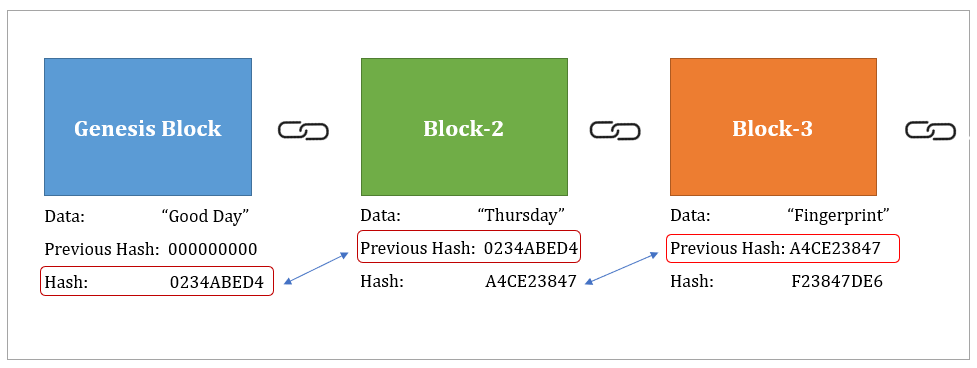
信任比較
可靠權威
就相信他
區塊鏈
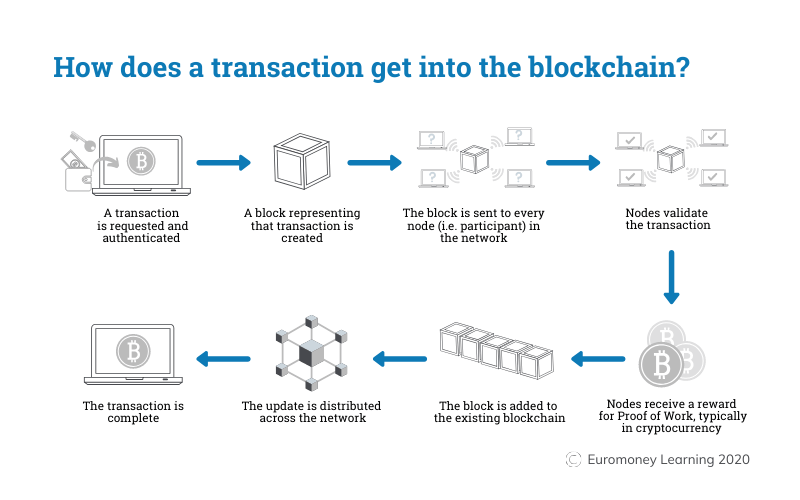
透過多數節點的驗證,確保這個資訊沒有被篡改過
HOW
COST
??
交些錢給驗證節點,他們才會幫你驗證
鍊上的不可竄性至少證明了這筆資料是被這些驗證節點驗證是沒被竄改過的
現在感覺很多東西都在發展,例如
NFT, Defi, X to earn.......
但浪潮過了,到底剛需是什麼?
現在的基礎建設撐得起這些需求嗎?

但這些是不能解決的問題嗎?
再來講一下感覺無關緊要的技術討論,
後面講 the merge 會再提到
一個簡單的服務的系統架構可能是這樣
front-end
App/Web
back-end
一個簡單的服務的系統架構可能是這樣
front-end
App/Web
back-end
Server
database
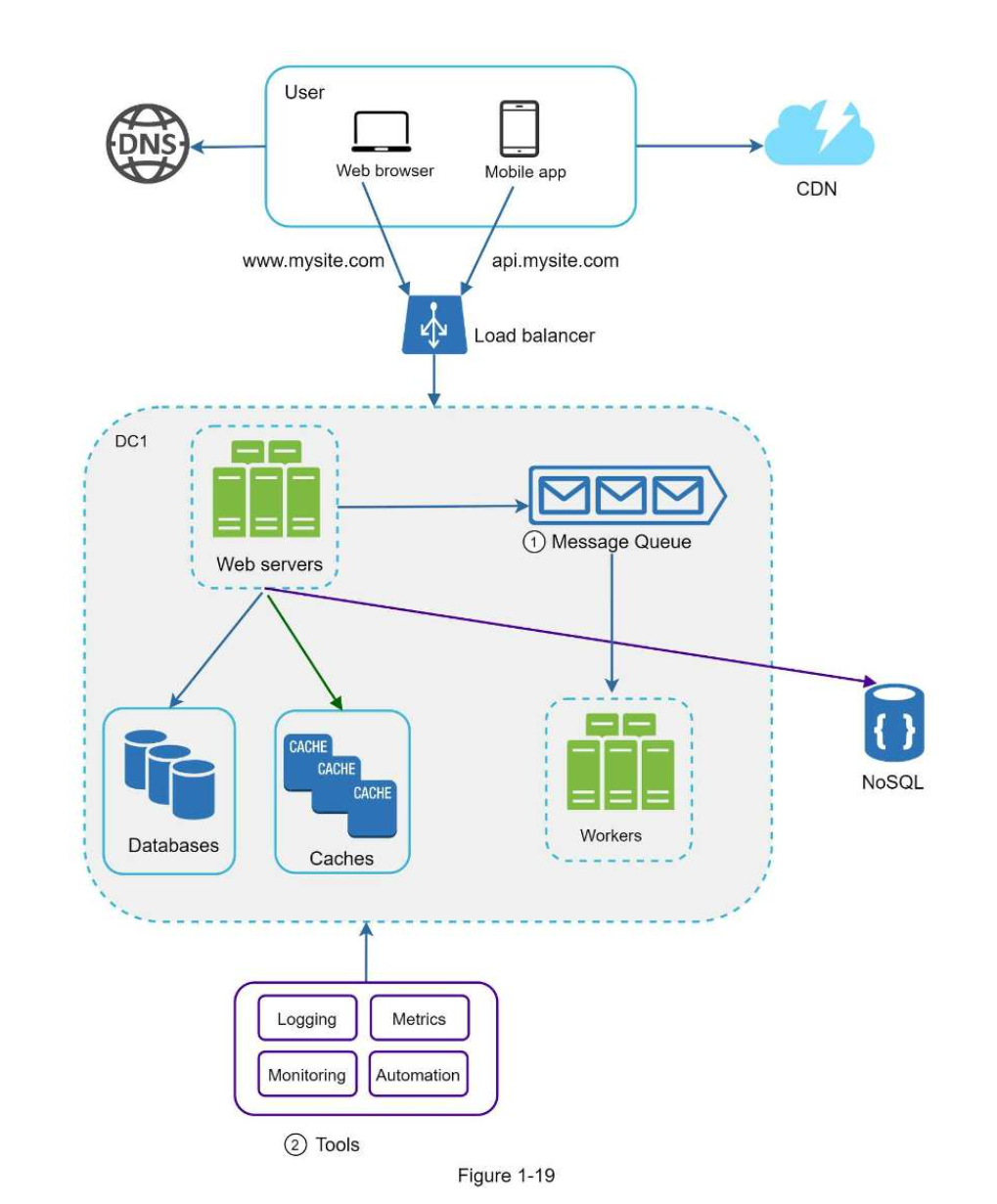
In Real World
如果使用量/資料量一直成長
除了根據情況設定 cache 或 rate - limit等等之類的
我們的 DB 也要跟著 upgrade(scaling)
除了就把規格升好升滿的 vertical scaling
除了就把規格升好升滿的 vertical scaling
Server
Master DB
Replica DB
一個 DB 不夠就團結力量大
如果使用量/資料量一直成長
除了根據情況設定 cache 或 rate - limit等等之類的
我們的 DB 也要跟著 upgrade(scaling)
Server
Master DB
Replica DB
一個 DB 不夠就團結力量大
除了就把規格升好升滿的 vertical scaling
Replica DB
Replica DB
Replica DB
...
Single Point of Failure
如果使用量/資料量一直成長
除了根據情況設定 cache 或 rate - limit等等之類的
我們的 DB 也要跟著 upgrade(scaling)
Server
Shard_0 DB
或是因為需求使然需要多台 DB
除了就把規格升好升滿的 vertical scaling
Sharding
Shard_1 DB
Shard_2 DB
user_id % 3
如果使用量/資料量一直成長
除了根據情況設定 cache 或 rate - limit等等之類的
我們的 DB 也要跟著 upgrade(scaling)
這些 nodes 傳遞的資訊是正確的
我們這邊都是從多個資料庫去討論,
但這邊都有一個假設
今天假設我們使用的 node 我們不能確保他傳遞的資訊,我們就需要一個容錯機制去確保資料的傳遞可用性
拜占庭容錯
簡單來說就是以少數服從多數的機制,令節點之間的溝通有一個共識
而比特幣的中本聰協議,就是一個比經典的BFT(少數服從多數)更進一步的解決方案,透過將信息重度加密,再要解密者以極高難度的蠻力去計算數學題,從而獲得答案。這項驗證方式要大量高難度數學計算,所以又名為「工作證明」(Proof-of-work, PoW)
可以說,區塊鏈之間的溝通就是以共識為基礎建立出來的
ETH the Merge
主要資料來源 -> Matrix DAO 的報告
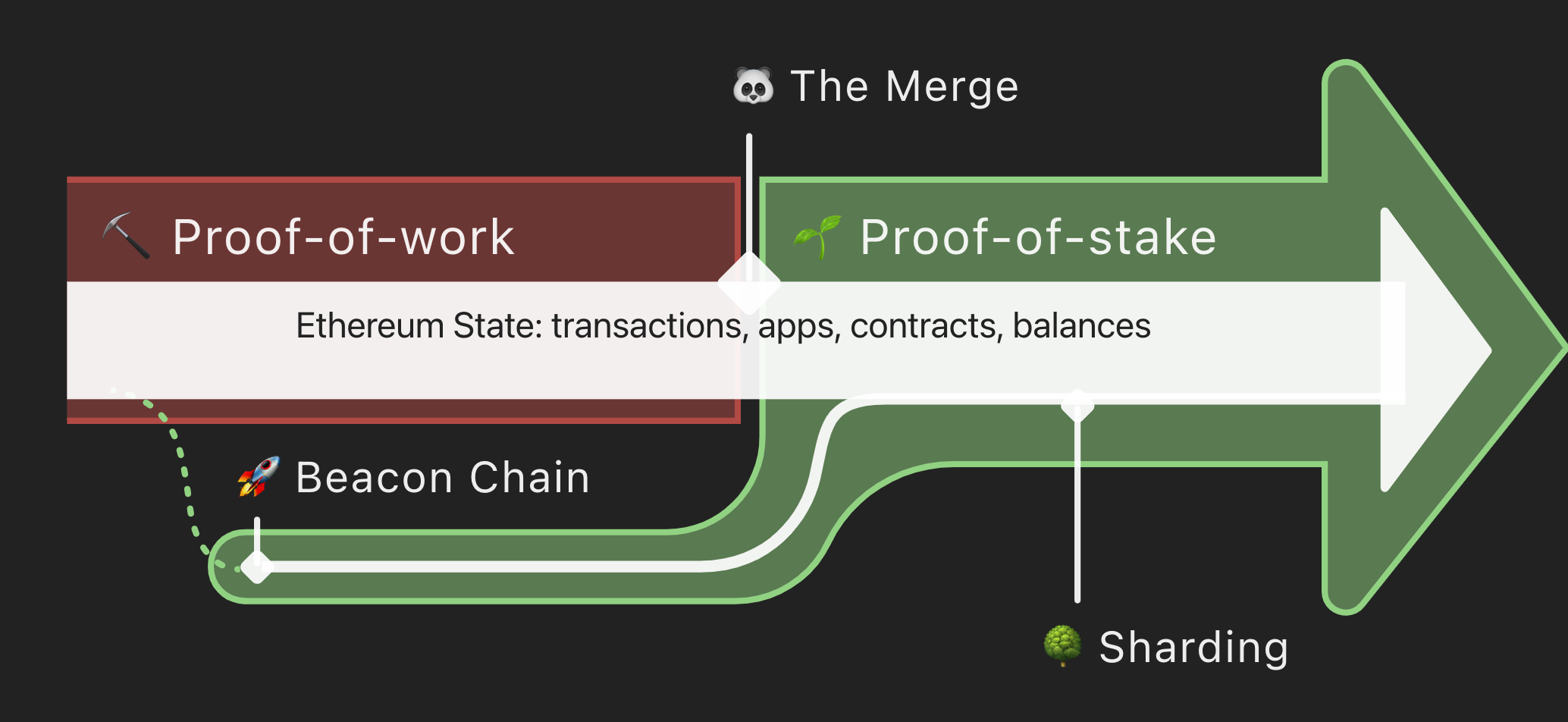
除了 POW->POS
還有為了將來的 sharding 做準備
目的?
1. 環保大使,人人有責(POW -> POS)
2. 現在交易速度過慢,將來擴大經營肯定不夠用
15tps
3. 安全性/去中心化危機
節能(POW -> POS)
- 從礦機的算力改成質押以太幣(根據質押數量、天數......決定記帳權機率)
- 算力減少,電力消耗減少
-> 就數據來看,當前以太坊的平均電力年耗則來到了 5.31 吉瓦 ( GW ),相當於一個中型國家
的年用電規模 - 預計可以大幅增加51%攻擊的難度, 因為掌握全網51%的以太幣比掌握全網51%的算力還要困難
交易速度過慢
交易速度過慢和 Gas Fee 競價
一直是被以太坊用戶所詬病的地方


但這點其實可以和
『去中心化、安全性』一起討論
這也是為什麼在 alt 1 如雨春筍冒出來的時候,
以太坊還是堅決找尋更好的方案解決
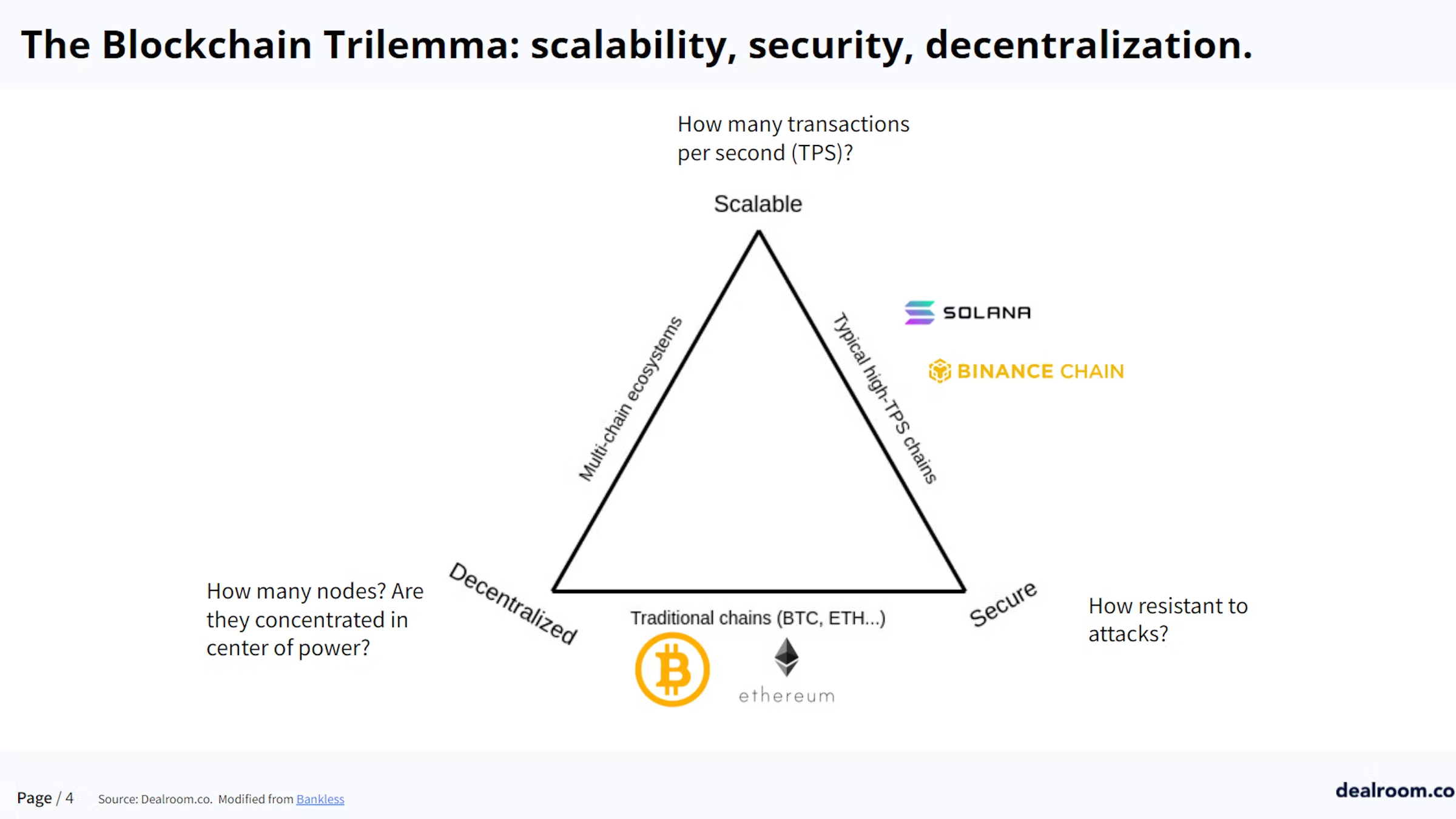
但這點其實可以和
『去中心化、安全性』一起討論
這也是為什麼在 alt 1 如雨春筍冒出來的時候,
以太坊還是堅決找尋更好的方案解決
先講要解決 tps 的論述有分兩種
單片區塊鏈 ( Monolithic ): 其信仰者認為區塊鏈擴容的未來來自一條效能超強的L1單片區塊鏈的表對象有 Solana、幣安智能鏈等強勢L1。
模塊區塊鏈 ( Modular ): 其信仰者認為區塊鏈擴容的未來來自多條區塊鏈的專業分工。模塊區塊鏈延伸出來方案非常多,包含狀態通道、ZK-rollup、OP-rollup、側鏈、分片等等概念。
BSC, Solana 等 alt L1 有哪些被質疑的問題?
----> 去中心化

----> 成為 validator 的門檻太高
https://docs.solana.com/running-validator/validator-reqs

BSC, Solana 等 alt L1 有哪些被質疑的問題?
----> 去中心化
----> 成為 validator 的門檻太高
https://docs.solana.com/running-validator/validator-reqs
以太坊團隊有個擴容的原則,
就是『必須在不犧牲去中心化與安全性的前提下,發展擴容方案』
這也體現了以太坊團隊的中心思想
安全性
PoW 改成 PoS,這預計可以大幅增加51%攻擊的難度,
因為掌握全網51%的以太幣比掌握全網51%的算力還要困難。
就當前以太幣礦機的分佈格局來看,第一名的 EtherMine 公司擁有46%的哈希算力,第二名的 NanoPool 有20%的哈
希算力,若這兩間礦場合作的話就能直接達成「51%攻擊」,這代表當前以太坊是非常中心化與集權的,這令以太坊
社區十分擔憂。
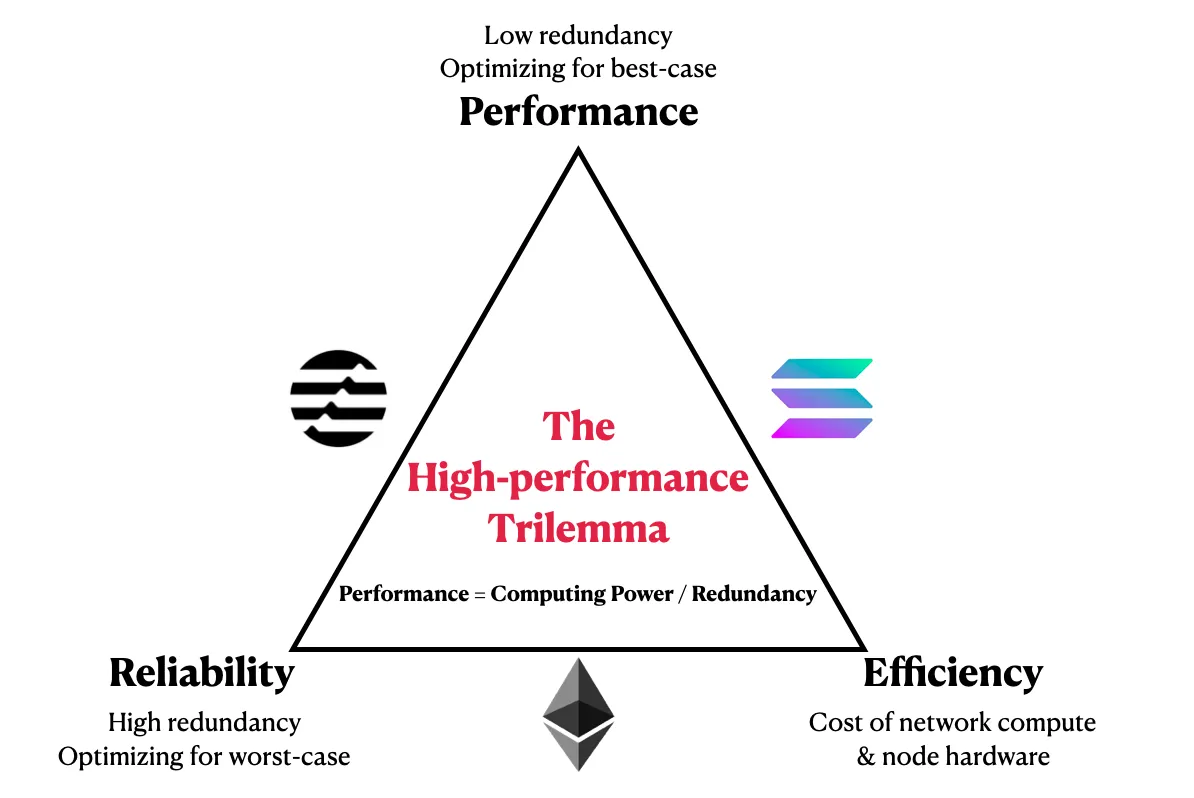
技術面
以太坊2.0的具體擴容方案其實「仍在發展的過程中」,因此方案上有經過多次迭代。
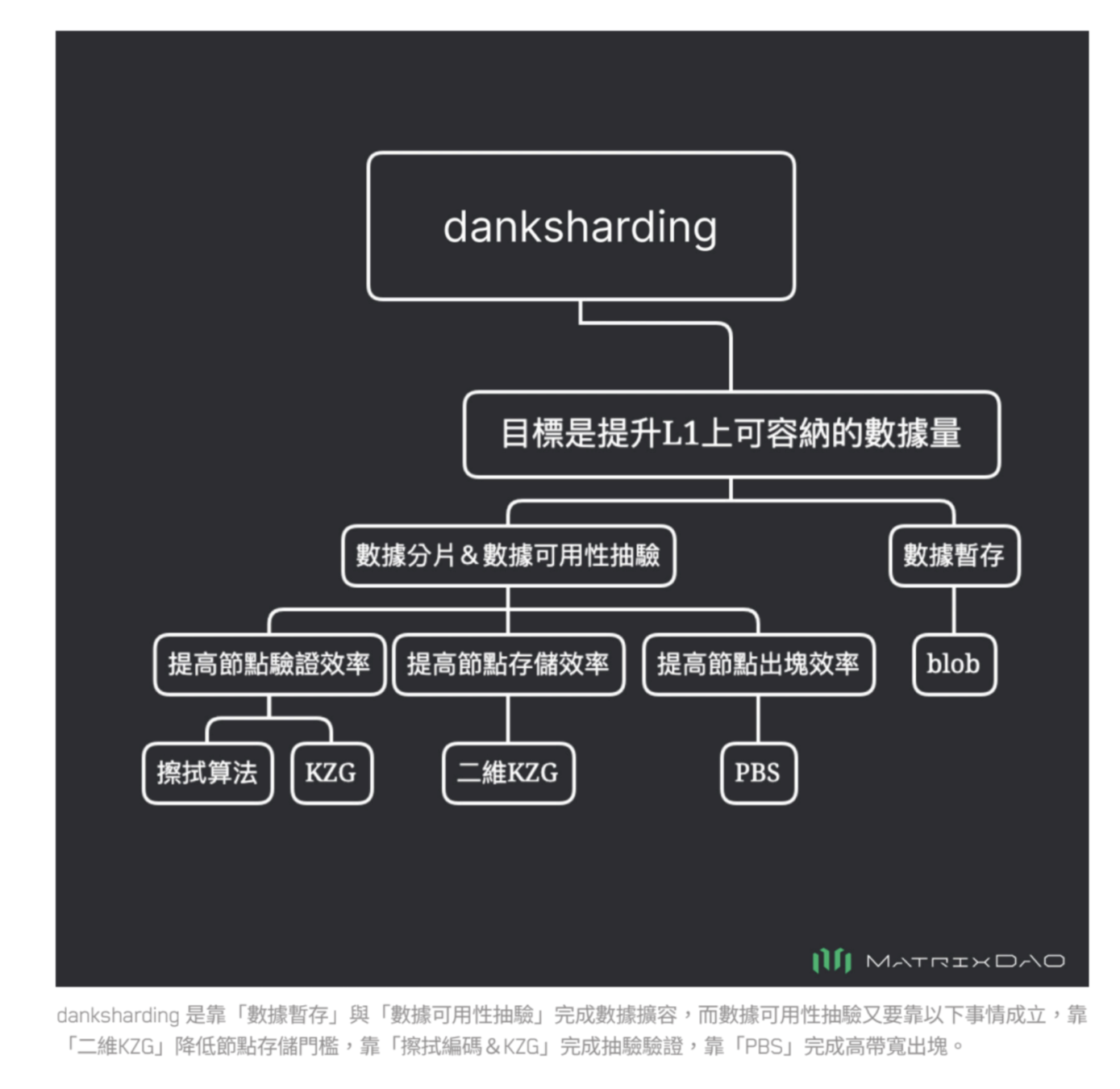
原本的主線擴容方案是在2021年提出 sharding1.0,但後來被今年提出的 danksharding 取代,而目前最新的方案是5月時提出的混合方案(結合 sharding1.0 和 danksharding ),但該方案的細節也還在發展當中。
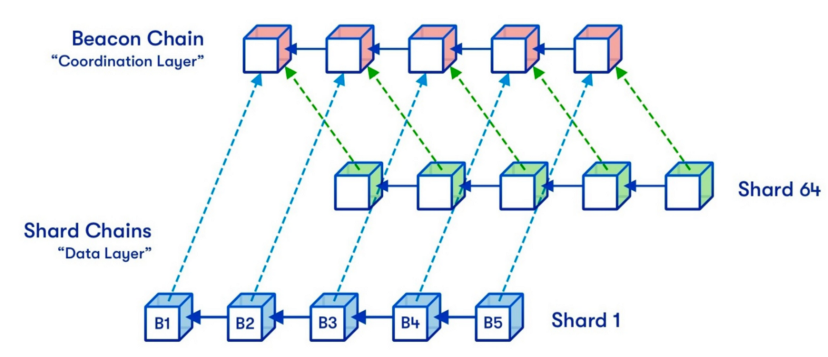
https://ethereum-magicians.org/t/a-rollup-centric-ethereum-roadmap/4698

Danksharding
如果說sharding 1.0的方式算是採用並行處理、分工合作的方式去做擴容(複雜度極高),DankSharding 則是用完全不一樣的手段去完成擴容。
核心思想是:『對數據做分片』與『數據暫存』

數據暫存
- 以太坊的核心地位為共識層,共識層的責任是確保檔下狀態的正確性
- 交易數據只存『一個月』,過期就刪除
- 新的儲存格式: blob
數據分片
- 對數據本身做分片,每個節點都只負責處理部分的數據碎片(像 BitTorrent)
- 各節點只有少量的數據碎片,要如何確實地完成對區塊鏈數據的驗證?
---->『數據可用性抽驗』
少量抽驗但達成極低誤差空間
Reed-Solomon
KZG 承諾算法
Data Availability Sampling


- 增加一些冗余資料,但在資料有損失時(以圖為例, 50%)時可以重建
- 攻擊者必須隱藏超過 50% 的區塊才能成功欺騙 DAS 節點,使其認為數據在不可用時可用
-
假設抽樣 30次,那機率就會是 (1/2)^30
----> (1/2)^30是個極小的數字,在實務上可被接受的夠低機率

KZG 承諾算法
為了確保冗餘這個過程沒有被動過手腳,資料集會帶一個KZG root,當你收到資料時就可以對這個 root 做驗證。
我的理解其實就像是 hash 的變相手法,你的冗余數據就是對你的原始數據作 hash。
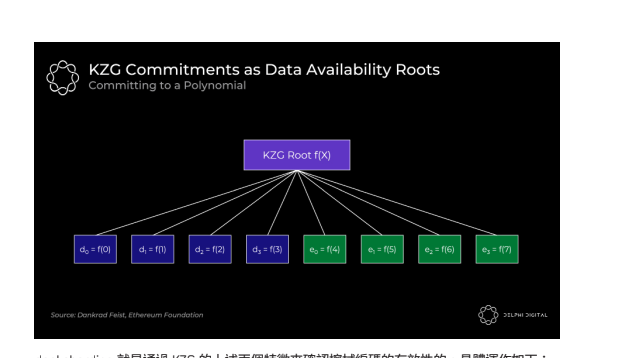
為了確保冗餘這個過程沒有被動過手腳,資料集會帶一個KZG root,當你收到資料時就可以對這個 root 做驗證。
我的理解其實就像是 hash 的變相手法,你的冗余數據就是對你的原始數據作 hash。
KZG 承諾算法

Proposer/Builder Separation
將打包者與出塊者分開
- 超級節點來製作區塊
- 去中心化的節點安排交易順序

Proposer/Builder Separation
將打包者與出塊者分開
we get a world where, block production is centralized, block validation is trustless and highly decentralized, and censorship is still prevented
Vitalik(2021) `Endgame`
- 首先系統會按 PoS 算法隨指派一個節點當出塊者
- 該出塊者會定義下個區塊要包含的交易數據,然後將其整理成一個交易列表 ( crList ) 廣播出去
- 各打包者接收到這個交易列表 ( crList ) 後,會發動他們的超級電腦來製作區塊的「區塊體(區塊格式裡的實際交易內容)」,製作完後會廣播出去
- 出塊者會從多個打包者製作的區塊體中挑出一個,然後根據該區塊體製作「區塊頭(區塊格式裡的摘要資訊)」
- 最終雙方共同產出一個完整的區塊(區塊頭+區塊體=區塊)
區塊頭
區塊體
crList
一個區塊涵蓋的交易數據範圍,
是由去中心化的出塊者製作的 crList 所決定的,
而打包者只能照著 crList 內的交易數據來打包出來的區,換言之打包者已經難以發動MEV。
MEV: 出塊者可以先審查一個區塊的交易數據,然後再安插自己的交易到該區塊中插隊,為自己謀取利益。
詳細說明了何謂 MEV,以及在不同階段(中心化市場、鍊上、 eth merge 後)是哪些角色從中套利
技術總結
犧牲「數據保存性」換取「效能」。
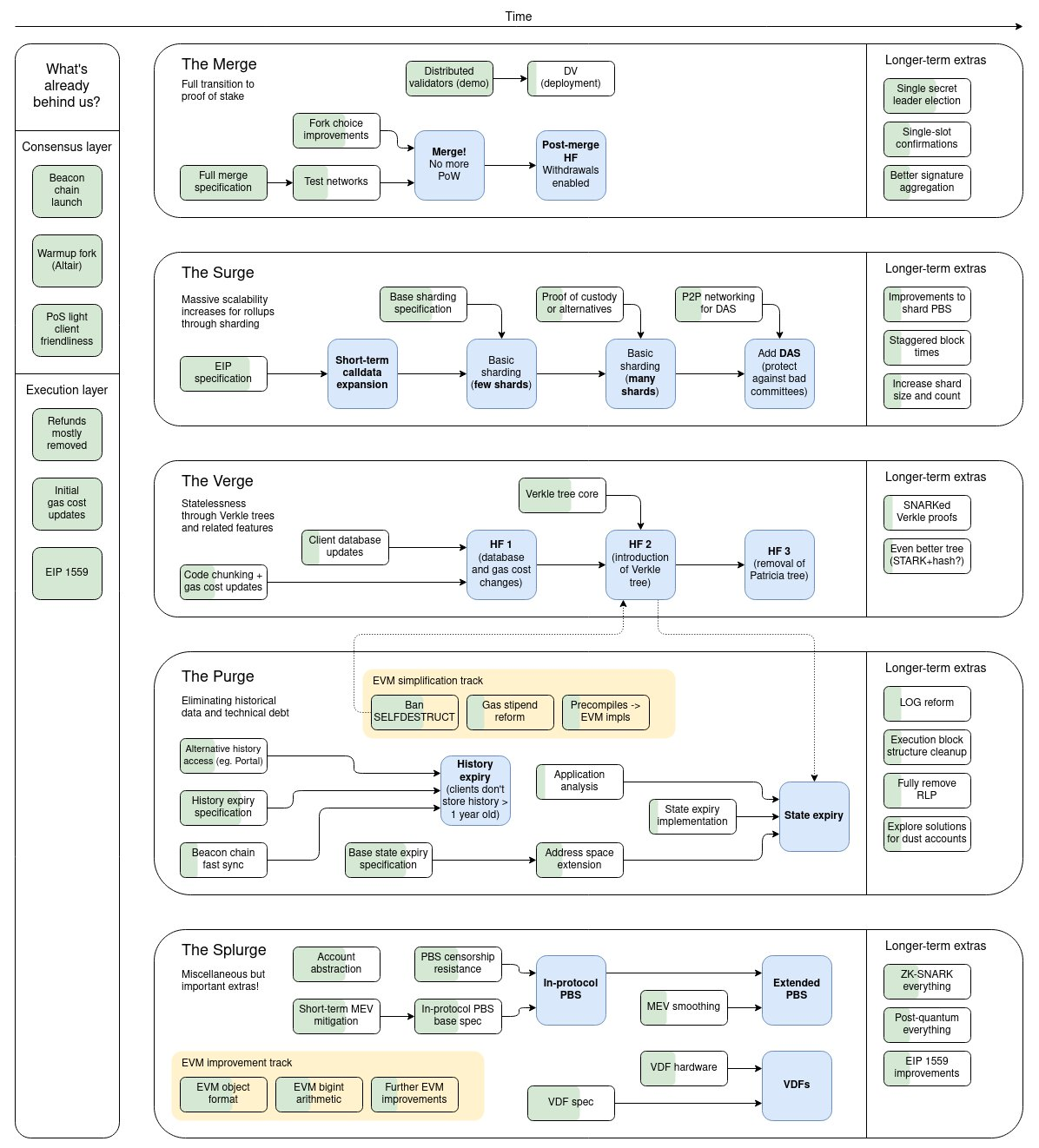
- The Merge
- The Surge
- The Verge
- The Purge
- The Splurge
其實此次升級有五階段
- The Merge
- The Surge
- The Verge
- The Purge
- The Splurge
現在不過才在 phase 1
目前 The Merge 後除了 POW 換成 POS 比較節能外,沒有什麼其他改變
TPS 暫時都還不會提升,要陸續等 danksharding, L2 rollup 等方案一一實踐
那升級提出至今已過了八年之久,
為啥這麼久?
延伸閱讀: 以太坊8年挖矿时代结束:V神、中国矿业,与英伟达
- 牛熊交替,要備齊資源、技術方案、執行力都是一個艱辛的過程
- 要將目前這些龐大的交易數據滑順轉移且過程不能停機是一件不容易的事(
反觀 solana
死機會怎樣,再幫大家複習一次
代幣面
merge 前後比較:
- merge 前,增發量14500ETH/天,交易費燃燒3000ETH/天,淨增加11500ETH/天
- merge 後,增發量1800ETH/天,交易費燃燒3000ETH/天,淨減少1200ETH/天
日增量少90%
供給端影響
質押累積可能發生解鎖潮
信標鏈上 PoS 的 ETH 要等到 Shanghai upgrade 後才能提取出來,而在信標鏈上參與 PoS 質押的節點會越來越多,因
此可能會造成更新後出現超大型解鎖潮
供給端影響
需求端影響
新增質押收益
- staking APY 7~8%
- 以太坊在幣圈的信用,近「無風險收益」的獲利手段
- 可能成為傳統大資本願意進場買入的誘因
需求端影響
基礎買盤相對增加
在 merge 前,每日 ETH 淨變化是增加11500顆,
若當天 ETH 價格要維持平衡,
那代表二級市場上要有11500*1300USD(假設ETH價值1300U)的買盤來承接
那我們假設 merge 後相應的買盤仍存在,
這時每日 ETH 淨變化是減少1200顆,
那同樣的11500*1300 USD 買盤進來的話,
相當於以太坊有很充分的買盤基礎存在。

這條路上可以看到為了追尋理想所以人們不斷嘗試、探索各種可能。面對效能、去中心化、安全性的突破,各種新穎的設計.......
這種追求的過程也令我心中油然敬佩
希望透過這次簡報,讓大家對以太坊 2.0 有更深刻地認識
區塊鏈這條路還長,但值得期待

QA
為什麼一開始就不用 POS?
-> 因為那時的時空背景下,POS 相對不成熟,而比特幣的 POW 已有個範本在
Ref
- https://dailyclipper.net/dc/2022/06/06/318944/
- https://drive.google.com/file/d/10jE80tpKZjkCkZaevLn38AOGfOaemGb3/view
- https://vitalik.ca/general/2021/12/06/endgame.html
Ethereum: THE MERGE
By Jay Chou




