10 分钟 AI 入门
Yolo + Fine-tune SDXL

Yolo
YOLO(You Only Look Once)
是一种流行的目标检测算法,它以高速和准确性而闻名。相对于传统的目标检测算法,YOLO采用单阶段检测的方式,即在一次前向传播中同时预测图像中所有对象的边界框和类别。
The Summit is what drives us, but the climb itself is what matters.
– Conrad Anker
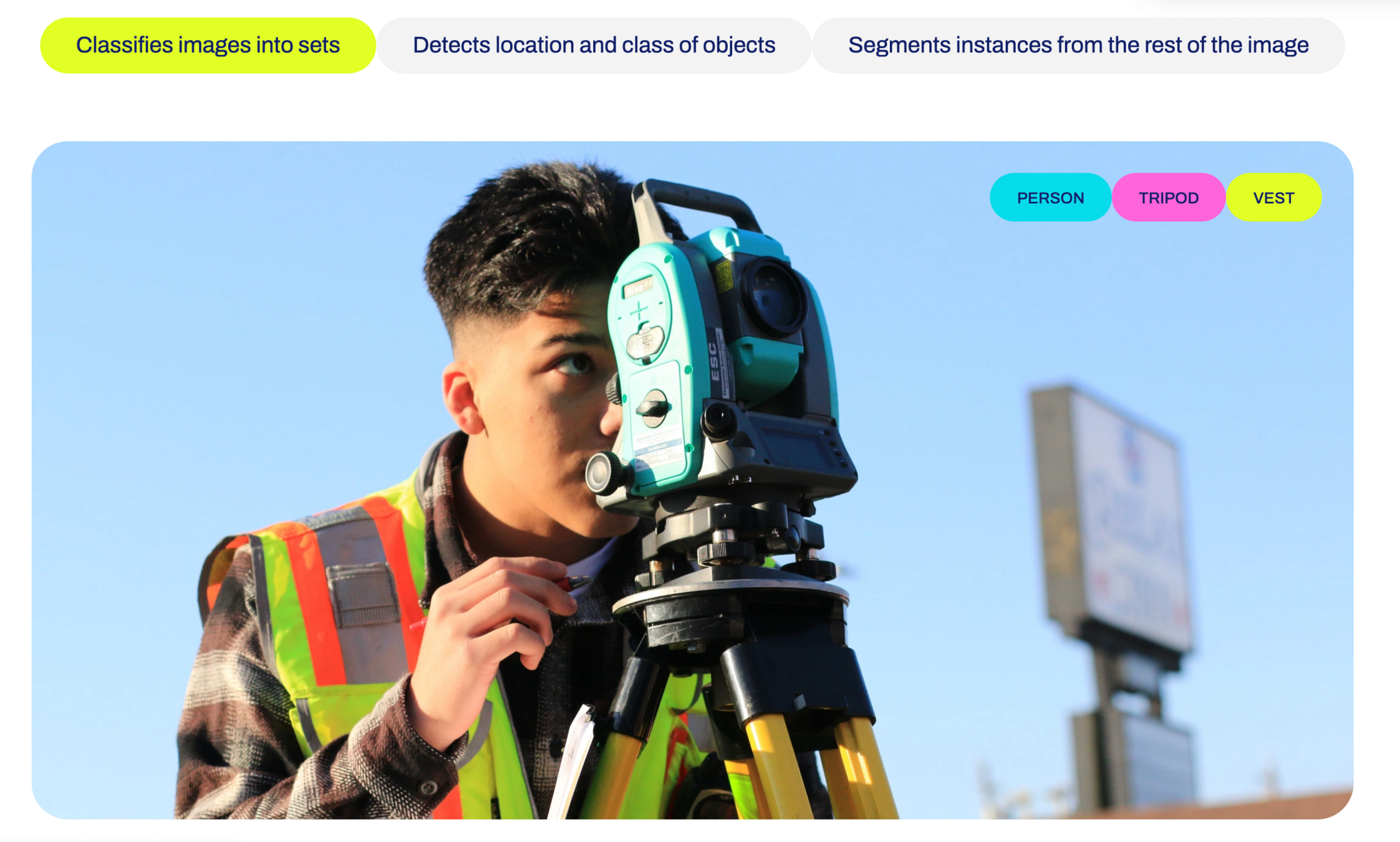

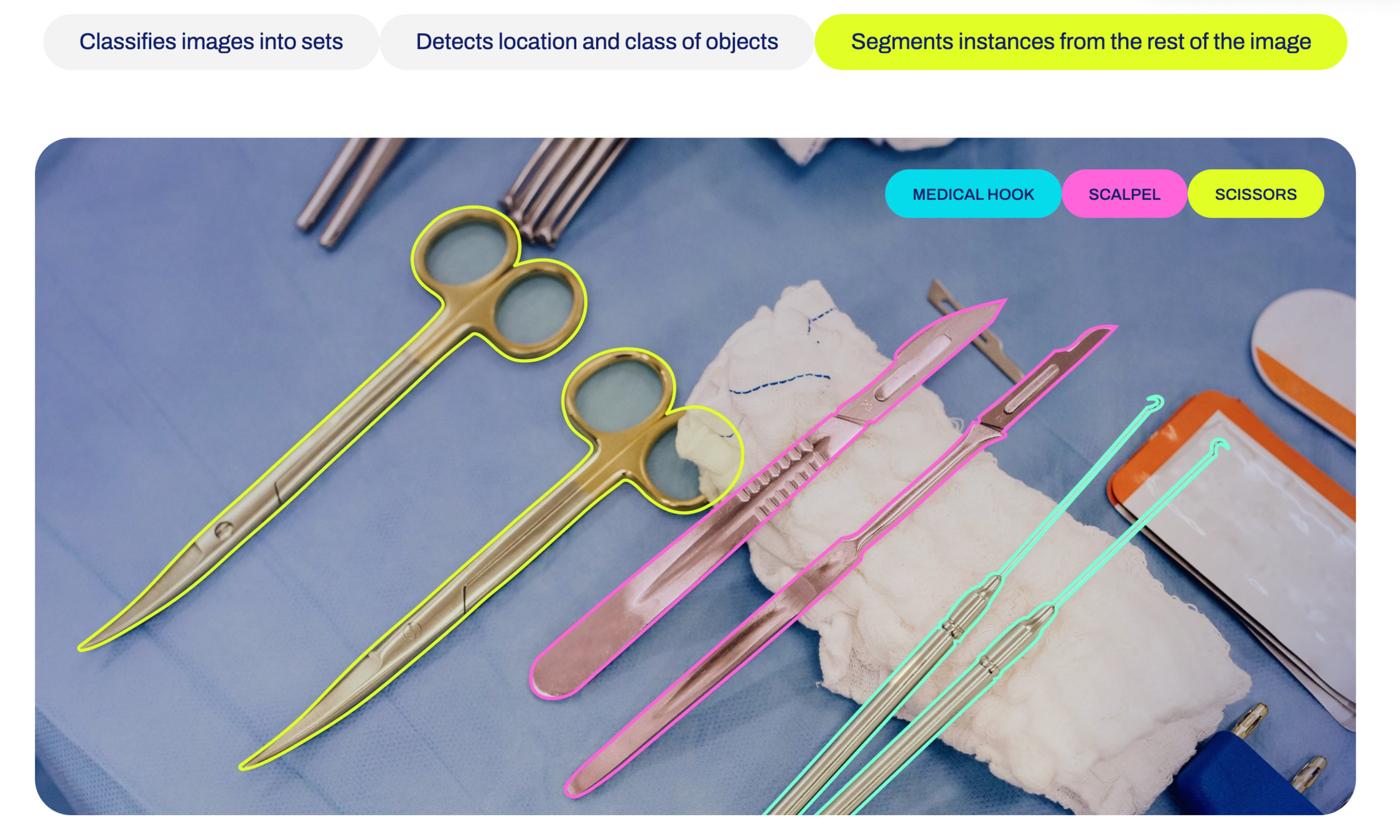
如何训练自己的 YOLO 检测模型
收集并标注一个包含目标对象的数据集,为每个对象添加边界框和类别标签。
1
数据集
使用现有的 YOLO 实现,加载预训练权重,配置训练参数,并使用数据集进行模型训练。
2
训练
加载训练好的权重,在新图像或视频上应用模型进行目标检测,获取检测边界框和类别信息。
3
运行





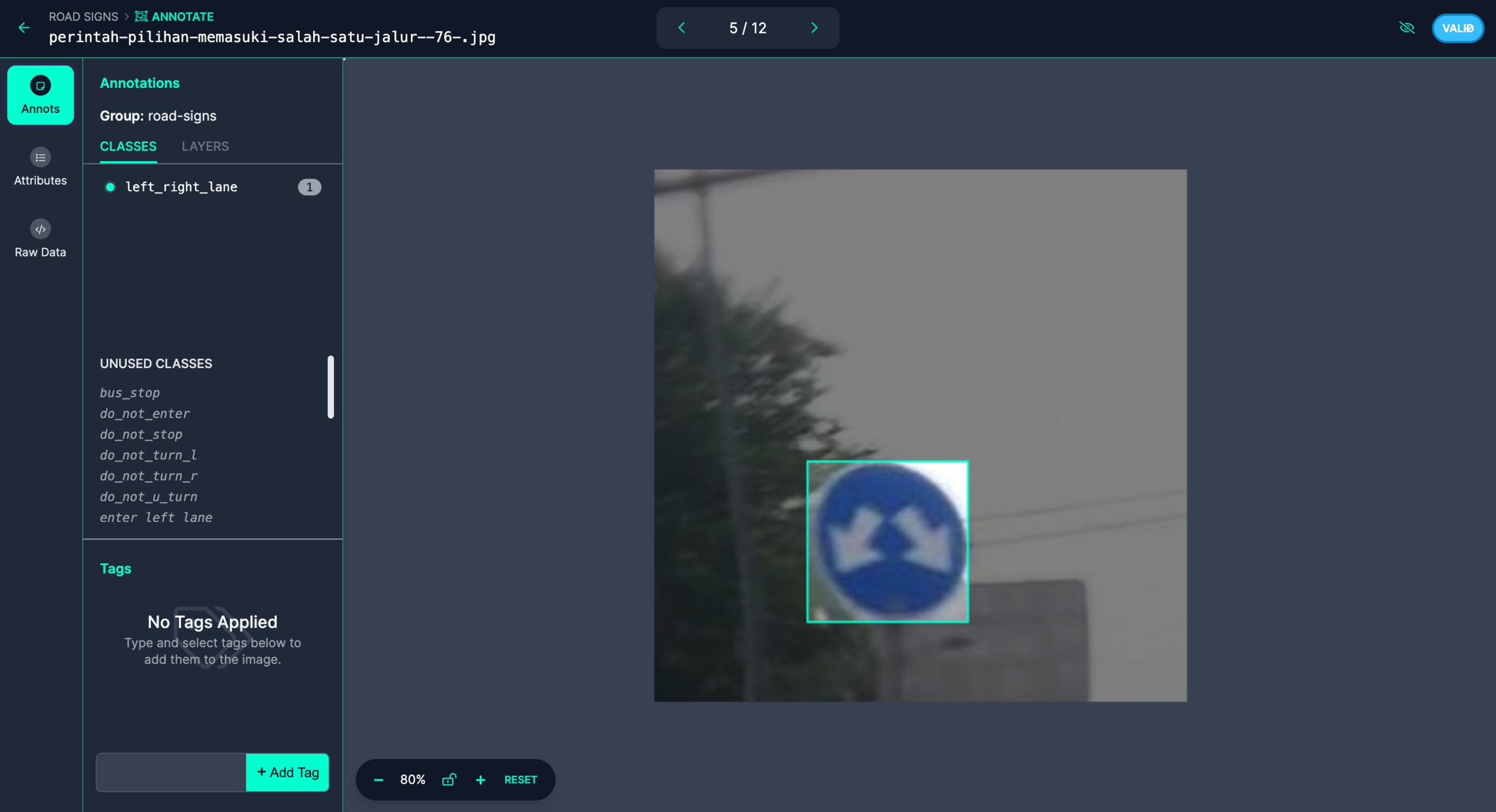
标注
收集和标注一个适合您应用场景的目标检测数据集。确保数据集中包含了您感兴趣的对象,并为每个对象标注边界框和类别信息。可以使用标注工具(如 LabelImg、Roboflow 等)来辅助标注过程,并将数据集划分为训练集和验证集。


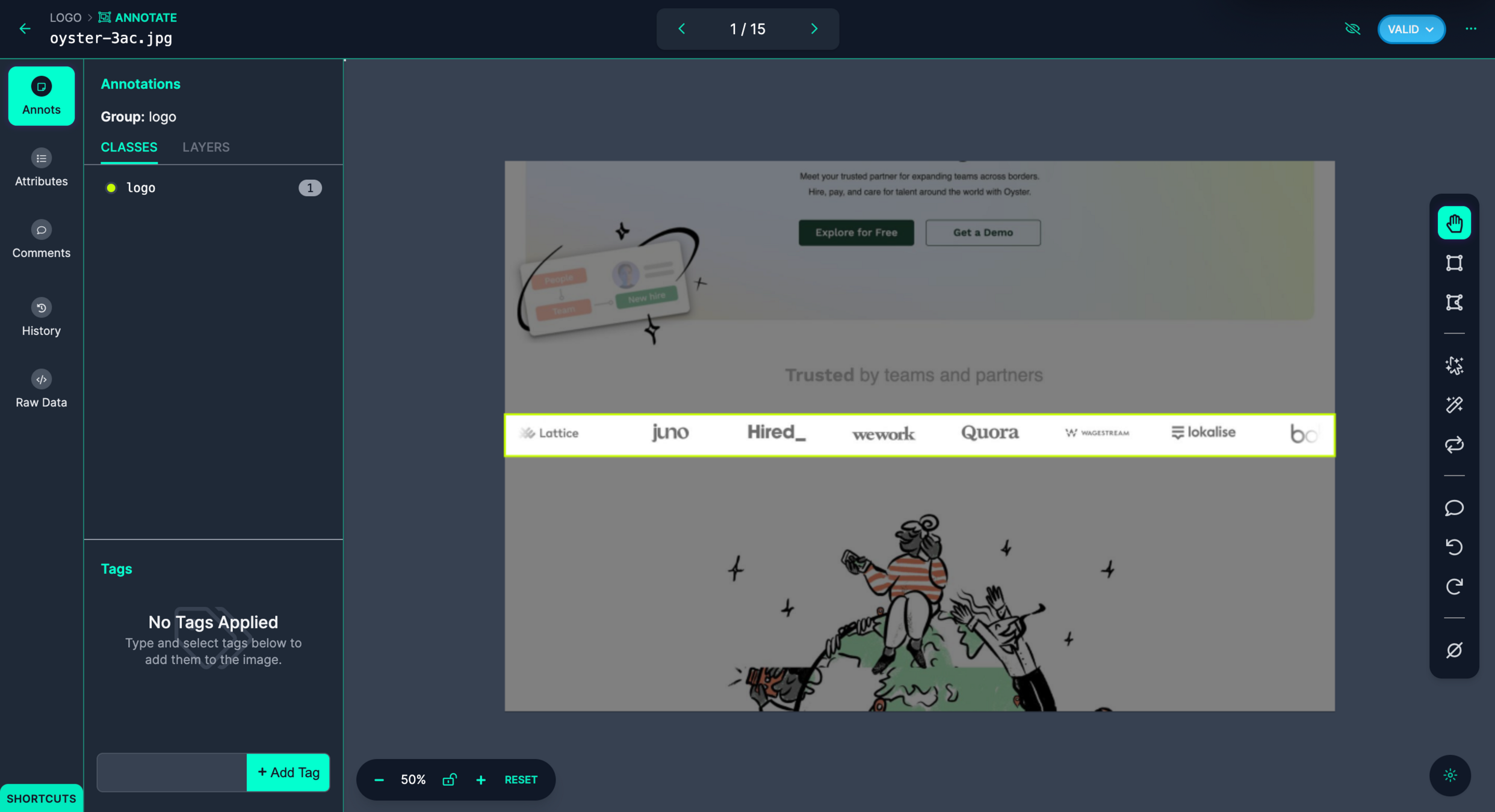
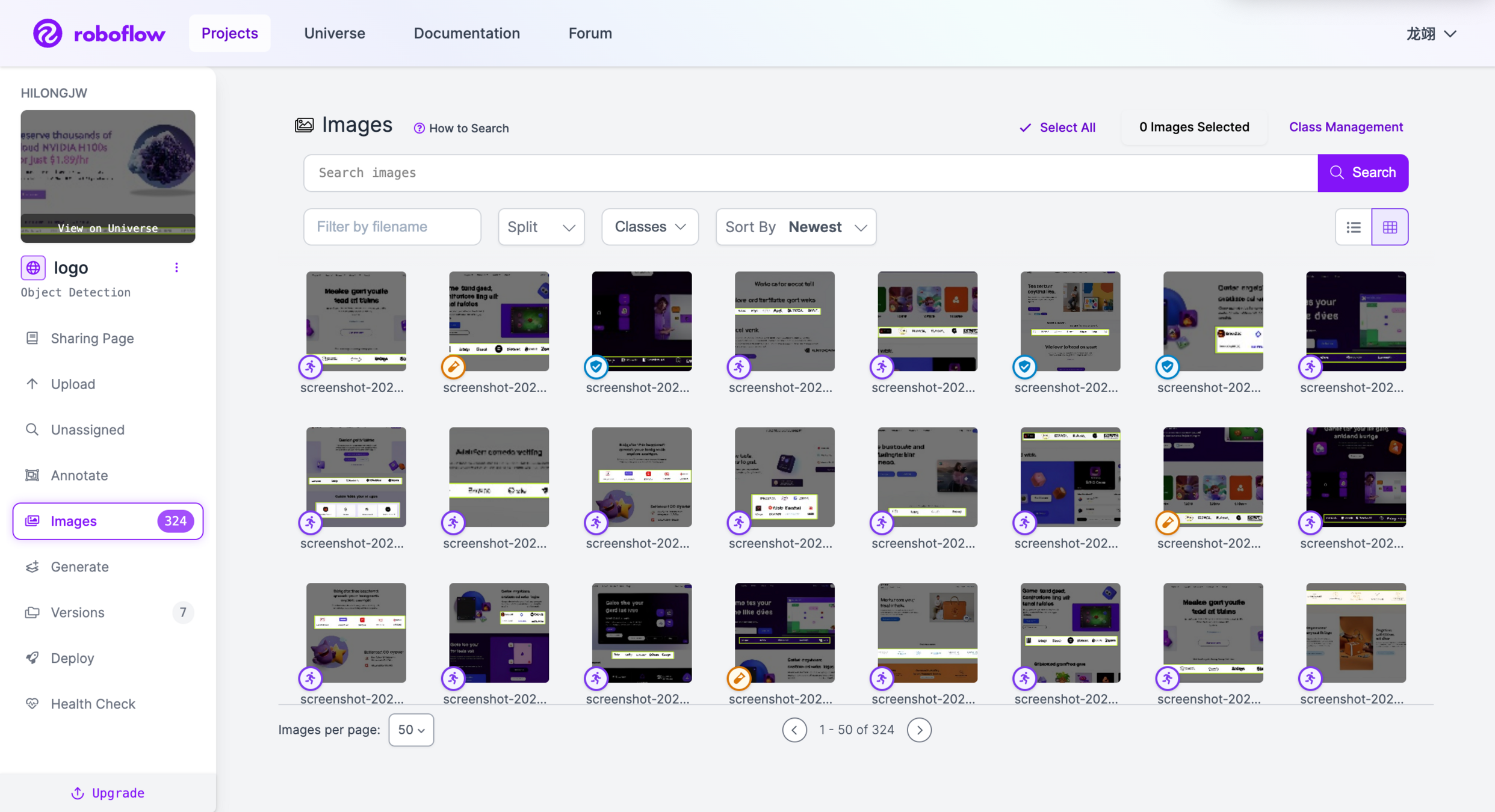
训练
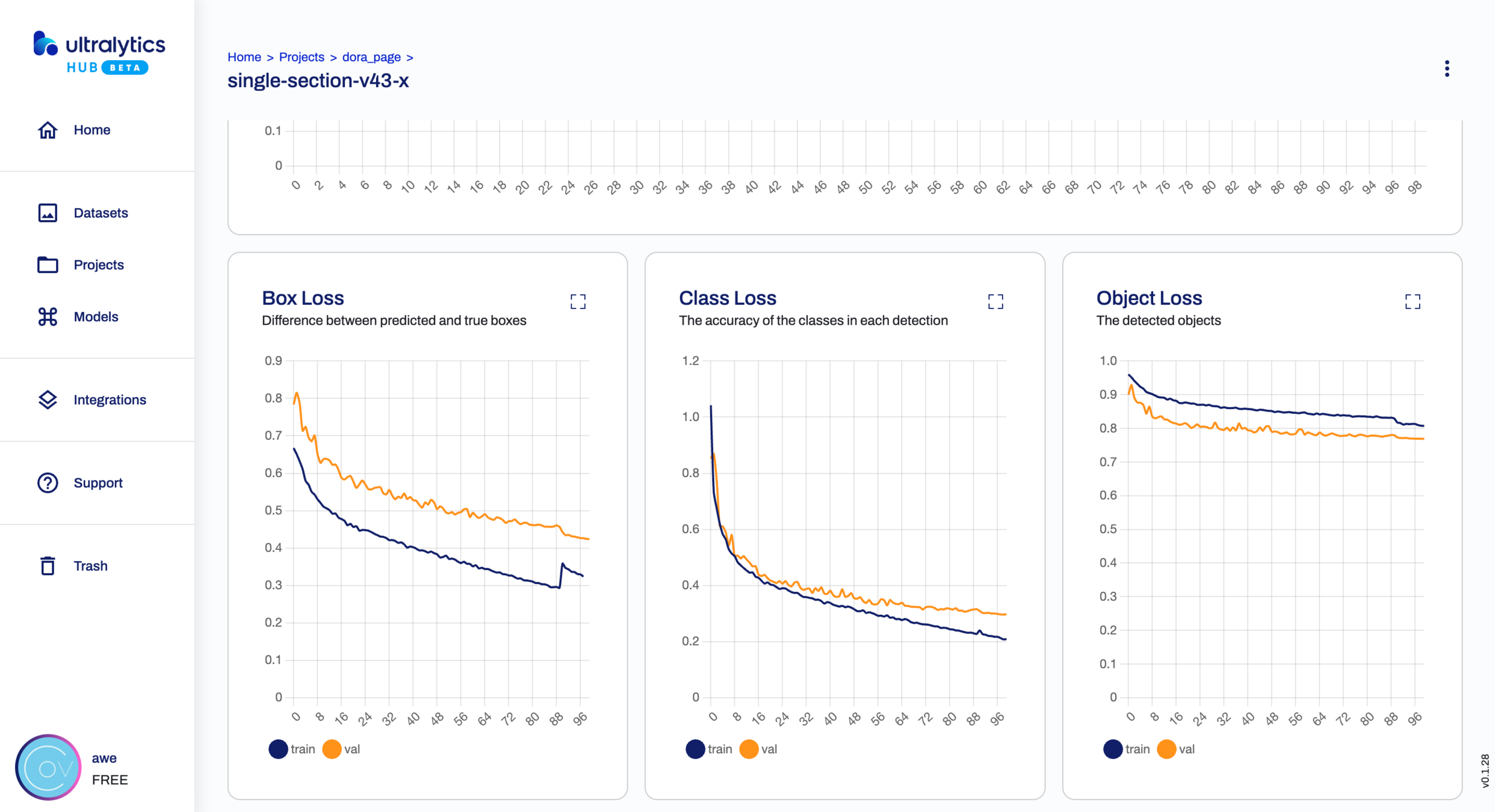
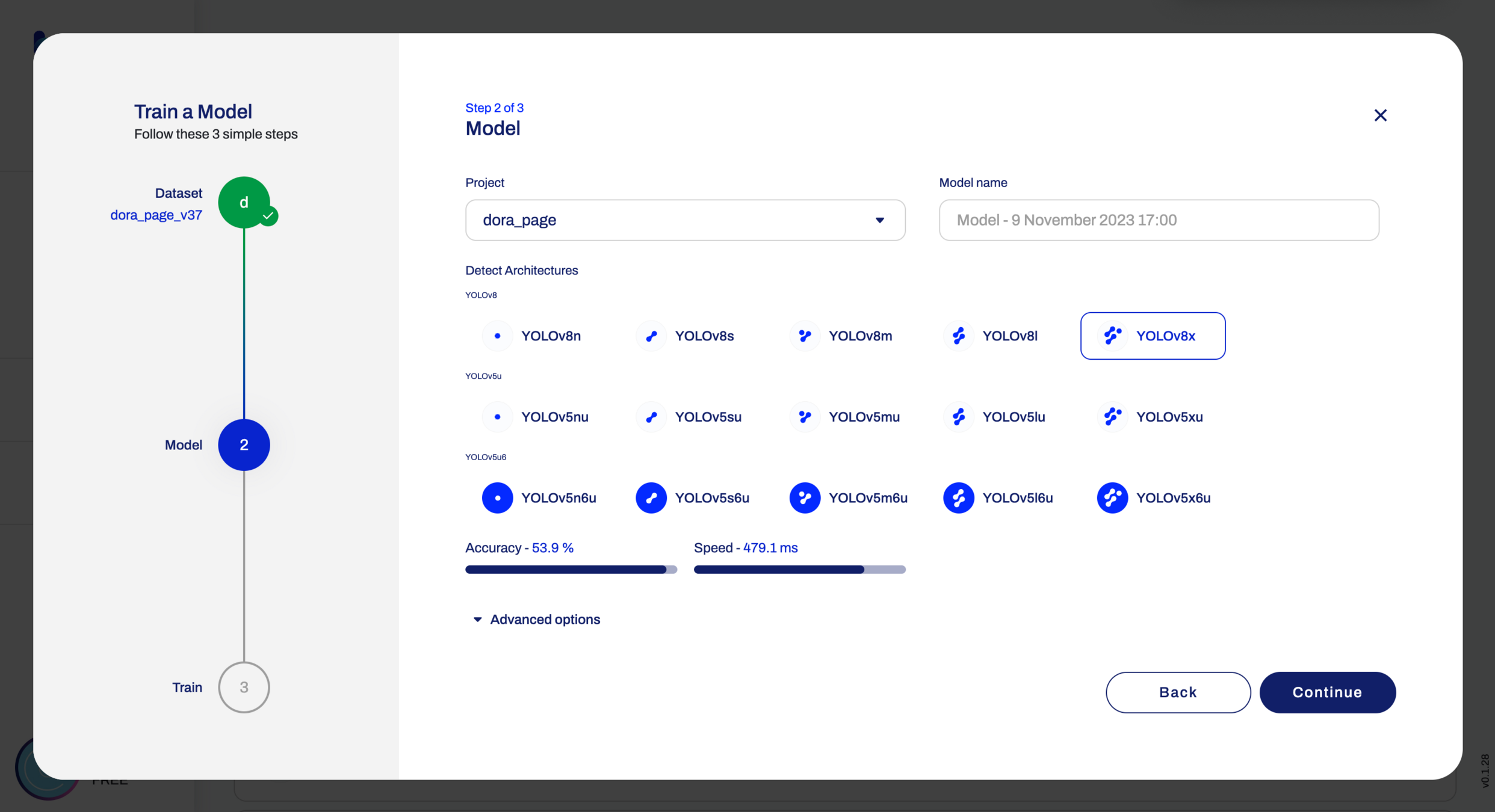
在数据集准备好后,您可以使用已有的 YOLO 实现(如YOLOv5、YOLOv8 等)进行模型训练。通常,您需要下载相应的预训练权重作为起点,并使用训练脚本或配置文件进行训练。在训练过程中,您需要指定数据集路径、类别数量、训练参数等,并根据需要调整学习率和迭代次数等超参数。训练可能需要一定的时间和计算资源,在 GPU 支持下速度会更快。
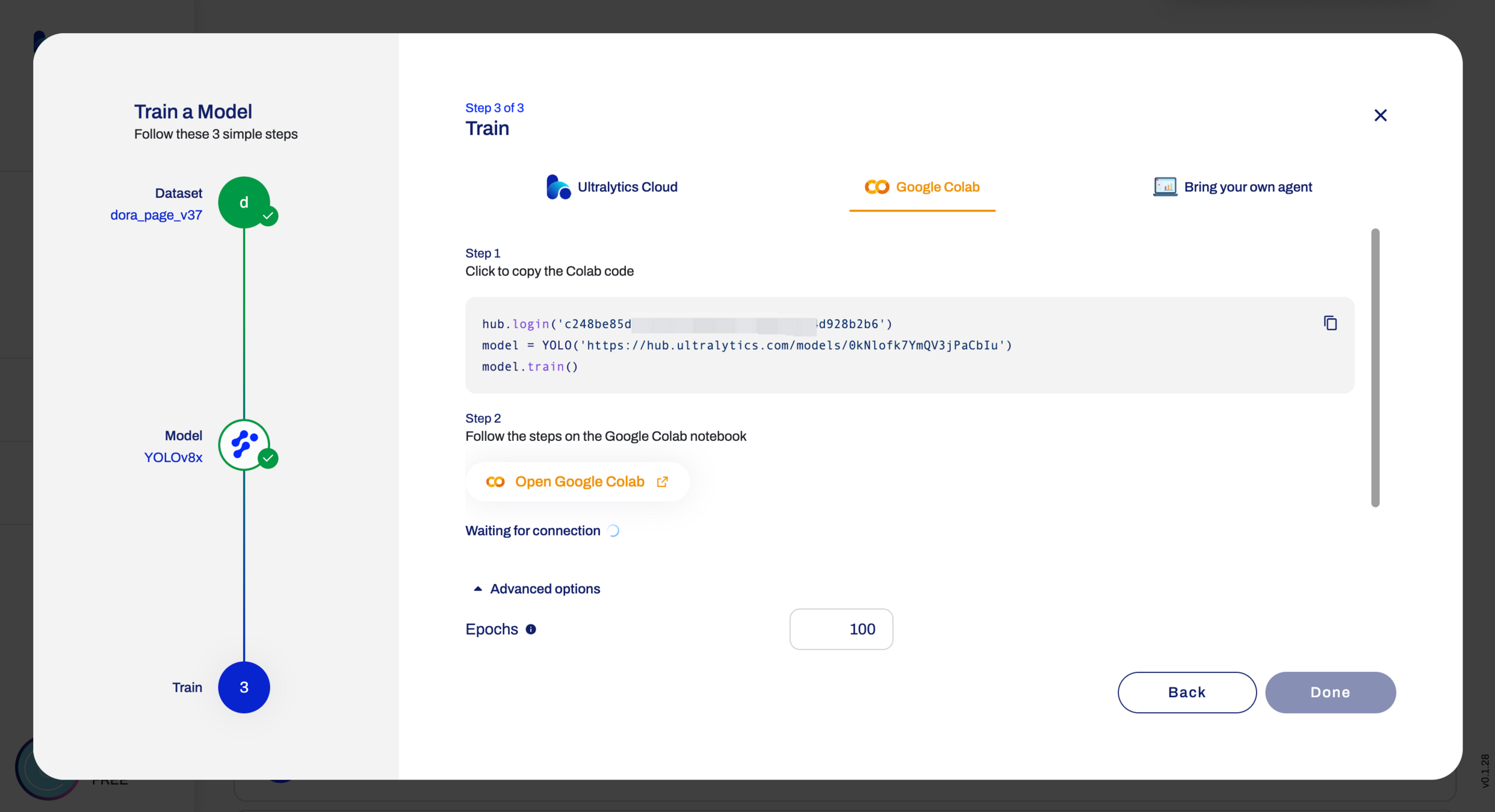
运行
您可以使用训练得到的权重文件进行目标检测。通过加载权重并使用适当的推理代码,您可以将模型应用于新的图像或视频。在运行时,模型会输出检测到的边界框和类别信息。您可以根据需要进行后续处理,如可视化、结果过滤等。
如何微调自己的人脸 LoRA 模型
收集包含人脸的图像数据集,并为每个图像提供相应的标注框信息,确保数据集具有多样性和代表性。
1
数据集
使用预训练模型作为基础,在数据集上进行微调训练。根据需要,可以冻结部分层或完全替换最后一层。通过传入图像和标签,计算损失并更新模型权重,经过多次迭代训练以达到满意的性能。
2
训练
运行微调后的人脸 LoRA 模型,输入图像并检测人脸。评估模型的准确率、召回率等指标,根据需求进行模型调整和优化。确保代码实现严谨,参考相关文档和最佳实践,以确保任务的成功完成。
3
运行
准备人脸素材
1.png
2.png
3.png



-
图像可以是你自己、你的宠物或任何独特的物体。
-
图像应仅包含主体本身,无背景噪音或其他物体。
-
未经他人同意,请勿使用其他人的图像。
-
图像可以是JPEG或PNG格式。
-
尺寸和大小并不重要。
-
文件名并不重要。
训练图像原则
训练
推荐使用 replicate 提供无代码训练方式,可以在 10 mins 左右完成训练等到你的结果
replicate
https://replicate.com/

1
准备图片
3
创建模型
5
训练完成
2
打包上传
4
启动训练
https://replicate.com/account/api-tokens
获取 Token
上传数据集
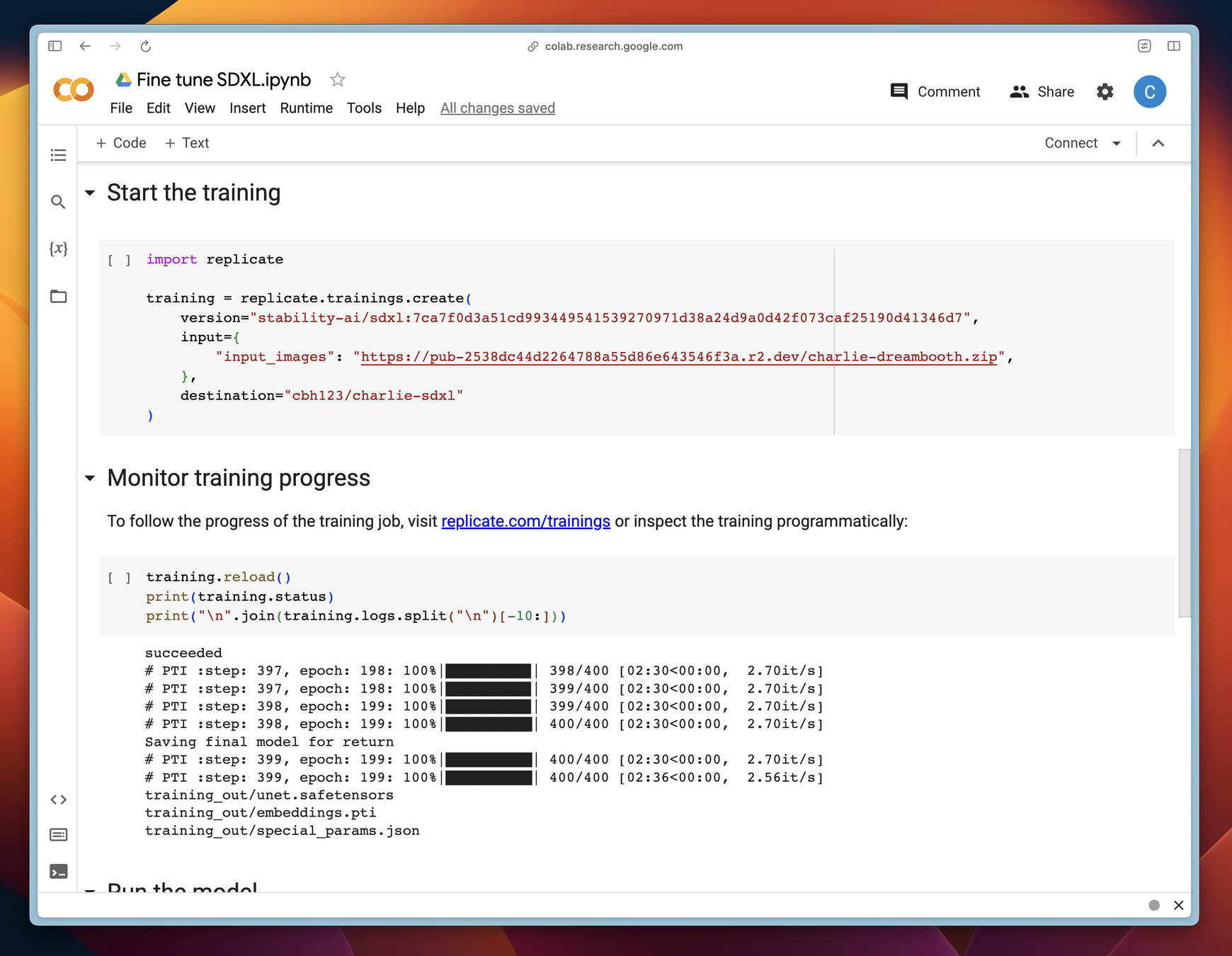
RESPONSE=$(curl -s -X POST -H "Authorization: Token $REPLICATE_API_TOKEN" https://dreambooth-api-experimental.replicate.com/v1/upload/data.zip)
curl -X PUT -H "Content-Type: application/zip" --upload-file data.zip "$(jq -r ".upload_url" <<< "$RESPONSE")"
SERVING_URL=$(jq -r ".serving_url" <<< $RESPONSE)
echo $SERVING_URL在运行后获取数据集 URL
运行训练
Philosophy
Once all is removed that can be removed, that is how designs are truly in their simplest form.
Thank You!
Questions?
Palette
By Awe




