Principes
et
Bonnes pratiques
MongoDB vs mySQL
Base NOSQL
orientée document sans relationnel
Vocabulaire
- Base <=> Base
- Collection <=> Table
- Document / Objet <=> Ligne / Enregistrement
- Champ <=> Colonne
- Sous document ou Lien <=> Jointure
Orientée document
Document <=> JSON avec un "_id"
{
"_id" : ObjectId("5811bac48b0cf22ea39e16ec"),
...
}{
"_id" : "toto",
...
}{
"_id" : 42,
...
}Orientée document
- Pas de relationnel
- Pas de schéma
(enfin pas obligatoire) - Pas de transactionnel
(mais ça va venir dans certaines conditions)
Pas de relationnel
Pourtant l’agrégation et l'association sont des concepts de base des relations entre objets
Pas de relationnel
Mais on peut avoir des objets composés
{
_id: "564f36c87dcbd96cf6f3e2ea",
name: "Tactilia",
address: {
city: "Saint Grégoire"
...
},
...
}
Pas de relationnel
Mais on peut mettre des références vers un objet
{
_id: "564f36c87dcbd96cf6f3e2ea",
name: "Tactilia",
employees: [
"/employees/564f36c87dcbd07cf6f3e2ea",
...
],
logo: "564f36c87dcbd97cf6f3e2ea",
...
}
L'aggrégation est à
gérer à la main
Voir annexes
Pas de schéma
On peut y mettre n'importe quel JSON (de moins de 16Mo)
=> mongo ne gère aucun schéma
=> c'est à l'utilisateur de gérer
Pas de schéma
Du coup on peut avoir plusieurs types d'objets qui cohabitent dans la même collection !
{
"name": "Voiture",
"plate": "AR-456-YI",
"nextControlDate": ISODate("2017-10-01T00:00:00.000Z"),
"nbSeats": 5
}
{
"name": "Camion",
"plate": "AD-123-PS",
"nextControlDate": "none",
"capacity": 20
}
Pas de schéma
Règles de bon sens :
- On met une collection par type
=> On sait a priori ce qui est stocké - On identifie les types
=> explications ci-après
Les requêtes
Find & Aggregate
Les requêtes
les bases
Le langage de requête est l'ecmascript
(alias javascript)
Insert
INSERT INTO Contacts (First_Name, Last_Name)
VALUES ('John','Doe'); db.Contacts.insert(
{
First_Name: "John",
Last_Name : "Doe"
}
)Find
SELECT *
FROM Contacts
WHERE First_Name = 'John'; db.Contacts.find(
{ First_Name: "John" }
){
"_id": ObjectId("58776b8643ab721e65d744ba"),
"First_Name": "John",
"Last_Name": "Doe"
}Premier argument :
la requête
Findone
SELECT *
FROM Contacts
WHERE First_Name = 'John'; db.Contacts.findone(
{ First_Name: "John" }
){
"_id": ObjectId("58776b8643ab721e65d744ba"),
"First_Name": "John",
"Last_Name": "Doe"
}Find (dans un sous objet)
SELECT Company.Name
FROM Company
LEFT JOIN Address
ON Address.OwnerId = Company.ID
WHERE City REGEXP 'Saint.*'; db.Contacts.find(
{ "address.city": { $regex: /Saint.*/g } },
{ name: 1 }
){
"_id": ObjectId("58776b8643ab721e65d744ba"),
"name": "Yieloo"
}Second argument :
la projection (select)
Find (avec projection)
SELECT Last_Name
FROM Contacts
WHERE First_Name = 'John'; db.Contacts.find(
{ First_Name: "John" },
{ Last_Name: 1 }
){
"_id": ObjectId("58776b8643ab721e65d744ba"),
"Last_Name": "Doe"
}Find (opérateurs)
- Comparaisons : $eq, $gt, $in,...
- Logiques : $and, $not,...
- Elements : $exists, $type
- Evaluation : $regex, $mod, $where,...
- Géospatial : $near,...
- Tableaux : $size, $elemMatch,...
- Bits : $bitsAllSet,...
db.Contacts.find(
{ First_Name: { $in: ["John", "Jane"] } }
)
db.Equipments.find(
{ $or: [ { nextControlDate: "none" }, { nextControlDate: { $gt: new Date() } } ] }
)
db.Equipments.find(
{ nbSeats: { $exists: true } }
)Update
UPDATE Contacts
SET First_Name = 'Jane'
WHERE Last_Name = 'Doe'; db.Contacts.update(
{ Last_Name: "Doe" },
{ $set: { First_Name: "Jane" } }
) db.Contacts.update(
{ Last_Name: "Doe" },
{ First_Name: "Jane" }
)Second argument :
la modification à effectuer
Premier argument :
la requête
Update (opérateurs)
db.Contacts.update(
{},
{ $rename: { First_Name: "firstName", Last_Name: "lastName" } },
{ multi: true }
)
db.Contacts.update(
{ "_id": ObjectId("58776b8643ab721e65d744ba") },
{ $push: { score: 42 } },
{ upsert: true }
)
db.Contacts.update(
{ "_id": ObjectId("58776b8643ab721e65d744ba") },
{
$push: { score: 42, game: "slot" },
$currentDate: { "last.play": true },
$set: { "last.result": "win" },
$inc: { credits: -1 }
}
)Delete
DELETE FROM Contacts
WHERE Last_Name = 'Doe'; db.Contacts.delete(
{ Last_Name: "Doe" }
)L'opération d'agrégation
principe
Enchaîner les opérations
Exemple
{
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468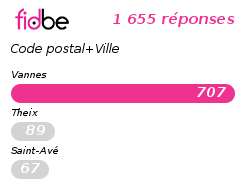
Etape #1 : Récupérer les données
db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: {
mod_id: ObjectId("5840597be4b07592382acc4c"),
modVersion: 1,
submitDate: { $exists: 1 }
} } ] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : ObjectId("58418252741d85f3df914805"),
"mod_id" : ObjectId("5840597be4b07592382acc4c"),
"modVersion" : 1,
"startDate" : ISODate("2016-12-02T14:06:49.758Z"),
"submitDate" : ISODate("2016-12-02T14:07:47.871Z"),
"data" : {
...
"CITY" : {
"date" : NumberLong(1480687625106),
"value" : {
"zip" : "35000",
"city" : "Rennes"
}
},
...
},
},
... x 1655
],
"ok" : 1
}Etape #2 : Élaguer les données
db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: { ... } },
{ $project: { "data.CITY": 1 } }
] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : ObjectId("58418252741d85f3df914805"),
"data" : {
"CITY" : {
"date" : NumberLong(1480687625106),
"value" : {
"zip" : "35000",
"city" : "Rennes"
}
}
}
},
... x 1655
],
"ok" : 1
}Etape #3 : Grouper les résultats
db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: { ... } },
{ $project: { "data.CITY": 1 } },
{ $group: { _id: "$data.CITY.value.city", count: { $sum:1 } } }
] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : "Bourges",
"count" : 12
},
{
"_id" : "Angers",
"count" : 2
},
... x 57
],
"ok" : 1
}Etape #4 : Trier les résultats
db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: { ... } },
{ $project: { "data.CITY": 1 } },
{ $group: { _id: "$data.CITY.value.city", count: { $sum:1 } } },
{ $sort: { "count" : -1 } }
] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : "Vannes",
"count" : 707
},
{
"_id" : "Theix",
"count" : 89
},
... x 57
],
"ok" : 1
}
Etape #5 : Limiter le nombre
db.formData_582b2b5ae4b0a55f3d0f436f.aggregate( [
{ $match: { ... } },
{ $project: { "data.CITY": 1 } },
{ $group: { _id: "$data.CITY.value.city", count: { $sum:1 } } },
{ $sort: { "count" : -1 } },
{ $limit: 3 }
] ){
"_id" : ObjectId("584159ba741d85f3df9147d4"),
"mod_id" : ObjectId("584158d4e4b07592382ba74b"),
"modVersion" : 0,
"startDate" : ISODate("2016-12-02T11:12:54.837Z"),
"submitDate" : ISODate("2016-12-02T11:14:36.643Z"),
"data" : {
"CITY" : {
"date" : NumberLong(1480677182830),
"value" : {
"zip" : "35830",
"city" : "Betton"
}
},
...
},
...
}
x 2468{
"result" : [
{
"_id" : "Vannes",
"count" : 707
},
{
"_id" : "Theix",
"count" : 89
},
{
"_id" : "Saint-Avé",
"count" : 67
}
],
"ok" : 1
}Bonnes pratiques
Les principes de base
Typer les documents
Obligatoire en cas de polymorphisme
Pourquoi ?
- Parce qu'il n'y a pas de schéma !
=> plusieurs types différents peuvent cohabiter- on peut mélanger les choux et les carottes
- mais on ne sait pas quel type on manipule
=> ajouter un champ "_type" ou "_class"
(si absent = type générique de la collection)
Comment ?
{
"_type": "car",
"name": "Voiture",
"plate": "AR-456-YI",
"nextControlDate": ISODate("2017-10-01T00:00:00.000Z"),
"nbSeats": 5
}
{
"_type": "truck",
"name": "Camion",
"plate": "AD-123-PS",
"nextControlDate": "none",
"capacity": 20
}
Versionner les documents
Sinon c'est vite le bordel
Pourquoi ?
- Parce qu'il n'y a pas de schéma !
=> plusieurs versions différentes peuvent cohabiter- pas la peine de mettre les documents à jour
=> pas de script de mise à jour
(sauf énorme changement) - mais on ne sait pas quelle version on manipule
=> ajouter un champ "_version"
(si absent = version 0)
- pas la peine de mettre les documents à jour
Comment ?
{
"addressStreet": "rue d'Alembert",
"addressZipCode": "35000",
"addressCityName": "Rennes",
...
}{
"_version": 1
"address": {
"street": "rue de Gauss",
"zipCode": "56230",
"cityName": "Questembert"
},
...
}{
"_version": 2
"address": {
"street": "rue du Rennes",
"city" : {
"zipCode": "35700",
"name": "Saint Malo"
}
},
...
}var CONVERTERS = [
function(obj) {
obj.address = {
street: obj.addressStreet,
zipCode: obj.addressZipCode,
cityName: obj.addressCityName
};
delete obj.addressStreet;
delete obj.addressZipCode;
delete obj.addressCityName;
obj._version = 1;
},
function(obj) {
obj.address.city = {
zipCode: obj.address.zipCode,
name: obj.address.cityName
};
delete obj.address.zipCode;
delete obj.address.cityName;
obj._version = 2;
}
];
while ( obj._version < currentVersion ) {
CONVERTERS[obj._version]();
}Gérer l'historique
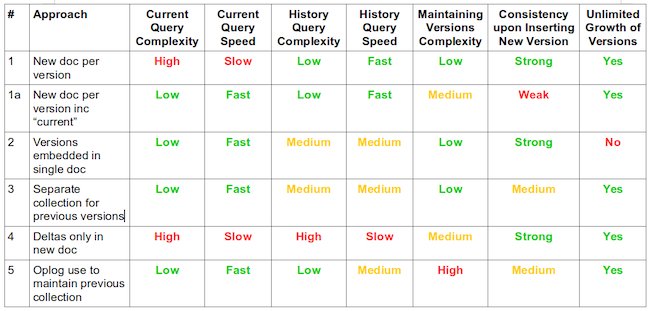
Cas #1
Un document par version
{ "docId" : 174, "rev" : 1, "attr1": 165 } /*version 1 */
{ "docId" : 174, "rev" : 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "rev" : 3, "attr1": 184, "attr2": "A-1" }db.docs.find({ "docId": 174 }).sort({ "rev": -1 }).limit(-1);findone
db.docs.aggregate( [
{ "$sort": { "docId" : 1, "rev" : -1 } },
{ "$group" : { "_id" : "$docId",
"doc": { "$first" : "$$ROOT" }
} },
{ "$match": { "doc.attr1": 184 } }
] );find
Cas #1a
Un document par version avec current
{ "docId" : 174, "v" : 1, "attr1": 165 }
{ "docId" : 174, "v" : 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "v" : 3, "attr1": 184, "attr2": "A-1", "current": true }db.docs.findOne({ "docId": 174, "current": true }));findone
db.docs.find({ "doc.attr1": 184, "current": true }));find
Cas #2
un seul document contenant toutes les versions
{
"docId" : 174,
"current" : { "attr1": 184, "attr2": "A-1" },
"prev": [ { "attr1": 165 }, { "attr1": 165, "attr2": "A-1" } ]
}db.CurrentCollection.findone({ "docId": 174 }, { current: 1 });findone
db.CurrentCollection.find(
{ "current.attr1": 184 },
{ current: 1 }
);find
Cas #3
Deux collections
CurrentCollection:
{ "docId" : 174, "rev": 3, "attr1": 184, "attr2": "A-1" }
PreviousCollection:
{ "docId" : 174, "rev": 1, "attr1": 165 }
{ "docId" : 174, "rev": 2, "attr1": 165, "attr2": "A-1" }
{ "docId" : 174, "rev": 3, "attr1": 184, "attr2": "A-1" }db.CurrentCollection.findone({ "docId": 174 });findone
db.CurrentCollection.find({ "attr1": 184 });find
Cas #4
Un document par version mais on stocke les deltas
sous forme de JSONPatch
{ "_id": ..., "id": 174, "userId": "xxx", "date": ISODate(...), patch: [
{ "op": "add", "path": "/attr1", "value": 165 }
] }
{ "_id": ..., "id": 174, "userId": "yyy", "date": ISODate(...), patch: [
{"op": "add", "path": "/attr2", "value": "A-1" }
] }
{ "_id": ..., "id": 174, "userId": "zzz", "date": ISODate(...), patch: [
{ "op": "replace", "path": "/attr1", "value": 184 }
] }chaque patch contient
- id du document
- date de modification
- patch à appliquer
en option
- id utilisateur
- son rôle
- id du tenant
find
Compliqué on doit procéder en deux étapes
- créer une collection où on reconstruit les objets
- puis effectuer la recherche
db.docs.aggregate( [
{ $match: { id: "174" } }, // recherche tous les patches sur l'entité
{ $sort: { "date" : 1 } }, // trie les résultats par date
{ $unwind : "$patch" }, // aplati tous les patchs
{ $group: { _id: "$id", patch: { $push:"$patch" } } }
// regroupe tous les patchs en un tableau
] );findone
- On agrège tous les patchs lié à l'id de l'objet puis on applique la liste de patchs sur un objet vide
- On peut ajouter un filtre sur la date pour gérer les révisions
Cas #3+4
Deux collections
SnapshotCollection:
{ "id" : 174, "v": 3, "attr1": 184, "attr2": "A-1" }
PatchCollection:
{ "_id": ..., "id": 174, "userId": "xxx", "date": ISODate(...), patch: [...] }
{ "_id": ..., "id": 174, "userId": "yyy", "date": ISODate(...), patch: [...] }
{ "_id": ..., "id": 174, "userId": "zzz", "date": ISODate(...), patch: [...] }db.SnapshotCollection.findone({ "docId": 174 });findone
db.SnapshotCollection.find({ "attr1": 184 });find
Cas #5
oplog
Le but est d'utiliser les logs de mongo pour gérer l'historique des versions du document (voir ce blog)
Au final
S'adapter
au besoin
et
à la volumétrie
- dans le nom de la collection
Les tenants
- dans les documents
db.data_564f36c87dcbd97cf6f3e2ea.find()Mettre un id
db.data.find({ownerId: "564f36c87dcbd97cf6f3e2ea"}){
...,
ownerId: "564f36c87dcbd97cf6f3e2ea",
...
}Les doublons
C'est le mal !
Ben non, c'est même plutôt utile
Les doublons
un cache
=> il faut une référence
- Idéal pour les données en lecture seule
- Il faut un mode de synchronisation
Les doublons
requêtes croisées
- Impossibles en une seule étape
=> Mettre les champs nécessaires
{
...
"otherDocId": xxx,
...
}{
"_id": xxx,
"name": "toto",
...
}{
"_id": xxx,
"name": "toto",
...
}{
...,
"otherDoc": {
"_id": xxx,
"name": "toto"
},
...
}Les objets sont vivants
Les objets ont des champs
- en plus
- en moins
- renommés
- qui changent de type
En plus
- même pas mal !
- si c'est un champ qui ne peut être nul
=> initialiser la valeur par défaut dans le constructeur - au prochain enregistrement il apparaîtra
En moins
- on s'en fout !
- au prochain enregistrement complet il disparaîtra
- au pire utiliser $unset
renommage
- garder les deux noms
- ajouter accesseur et mutateur
ou
- utiliser le système de version d'objets
ou
- mettre à jour les objets de la base avec $rename
changement de type
- si le langage le permet
- ajouter accesseur et mutateur
pour retourner le bon type
ou
- utiliser le système de version d'objets
ou
- mettre à jour les objets de la base
Un objet
- change de nature
- fusionne avec un autre
- se scinde en deux
changement de nature
- le nouveau format est dans une autre collection
- grâce au UUIDs
- si l'objet est dans la nouvelle collection => ok
- sinon l'objet est dans l'ancienne
=> convertir l'objet
- inconvénient les recherches doivent se faire dans les deux collections et les résultats fusionnés
ou
- utiliser le système de version d'objets
ou
- on met à jour les objets de la base
fusion
- à la lecture l'objet principal agrège le second objet
- Il faut utiliser le système de version
ou
- on met à jour les objets de la base
scission
- le second objet est dans une autre collection
- principe
- rien ne change pour l'objet principal
- le second objet est dans la nouvelle collection => ok
- sinon l'objet est dans l'ancienne
=> convertir la partie du second objet
=> mettre à jour l'objet principal
- inconvénient les recherches doivent se faire dans les deux collections et les résultats fusionnés
- problème de UUIDs
ou
- on met à jour les objets de la base
Un objet a un cycle de vie
- création
- modification
- destruction
destruction
- delete
ou
- Archivage
=>Ajout d'un champ _archive: true
find({
...,
$or: [ { _archive: { $exists: false } }, { _archive: false } ]
})find({
...,
_archive: true
})Indexation
_id par défaut
Rappel sur _id et UUID
- C'est n'importe quoi
- mais ce doit être un UUID
- on peut trouver une équivalence entre SQL et mongo
{
_id: ObjectId("000280000000000000000042"),
...
}| Id | ... |
|---|---|
| 42 | ... |
table #28
Créer un index
- Différents types d'index :
- simple, composé, multi-clé, géospatial, texte, hash
- Propriétés
- unique, partiel, clairsemé, TTL,
db.xxx.createIndex( <key & index type specification>, <options> )Indexation
- Pour le geospatial c'est top
- Pour le texte c'est bof mais ça s'améliore
il faut mieux utiliser une base d'indexation basée sur lucene (comme solr ou elasticsearch)
MongoDB
Compléments
Retour sur
agrégation & relation
{
_id: "5b50f8968656472a58970167",
password: "xxx",
userId: "bchanclo",
}{
_id: "5b50f8968656472a58970167",
firstname: "Benoît",
lastname: "Chanclou",
birthdate: ...
}Un id
- on sait où aller chercher la ressource
- on sait faire
-
en local
- ou sur un autre référentiel
-
en local
{
user: "564f36c87dcbd97cf6f3e2ea",
}
GET http://api.myapp.com/tiers/1/contacts/564f36c87dcbd97cf6f3e2eadb.users.findOne({_id: "564f36c87dcbd97cf6f3e2ea"})Une uri
- dans le cas d'une ressource d'un autre référentiel
- on sait
- extraire l'id pour une requête locale
- ou appeler l'url correspondant à l'uri
{
user: "http://api.myapp.com/tiers/1/contacts/564f36c87dcbd97cf6f3e2ea",
}
Une référence riche
- les objets de type "User" sont dans une collection ou un référentiel connu
- on sait
- récupérer la ressource
- que ce sera un objet de type User
{
user: {
type: "User",
id: "564f36c87dcbd97cf6f3e2ea"
},
}
Une référence avec cache
- on sait récupérer la ressource
- si régulièrement on veut juste le nom et le prénom pour l'afficher
- inutile d'aller charger la ressource
- on utilise le cache
- lorsque la ressource est chargée en lazy loading, le cache peut être mis à jour si nécessaire
{
user: {
firstname: "Benoît",
lastname: "Chanclou",
uri: "http://api.myapp.com/tiers/1/contacts/564f36c87dcbd97cf6f3e2ea"
},
}
Utiliser un framework
- Spring sait gérer ce type de référence
(au sein d'une même application)
Les champs supp' dynamiques
C'est open bar
Pas de schéma
- Il suffit d'ajouter les champs
- Les champs peuvent être :
- un objet
- un tableau
- un type simple
Nécessité d'un modèle
- Connaître le contenu est indispensable
=> Spécifier le type de document
Sous types
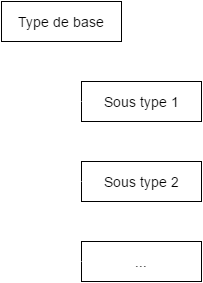
=> utiliser le "_type"
{
"_id": ...,
"_type": "Sous type 1",
"champSpecifiqueSousType1" : []
...
}Agrégats
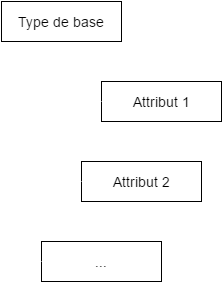
=> utiliser un tableau de "_tags"
{
"_id": ...,
"_tags": [
"Attribut 1",
"Attribut 2",
...],
"champSpecifiqueAttr1" : null,
"champSpecifiqueAttr2" : ""
...
}Champs dynamiques
=> utiliser un modèle
{
"_id": ...,
"_modId": 1,
"aaa": 42
...
}{
"_id": 1,
"fields": [ {
"name": "Champ quelconque",
"label": "aaa",
"type": "int",
.... },
... ]
}Recommandations
- Attention aux collisions de noms de champs
- envisager des sous documents
- Les requêtes se font de la même manière
- champs supp' <=> champs normaux
MongoDB
outils
RoboMongo
- le plus connu
- permet d'éditer les requêtes directement
- version plus complète payante
MongoDB Compass
- l'outil officiel
- beaucoup plus complet (management et monitoring)
- payant pour avoir la version complète
présentation MongoDB
By Benoît Chanclou
présentation MongoDB
Présentation sur la structuration des données. Les sujets de déploiement de Mongo ne sont pas abordés.



