Data Generation For
Behavior Cloning
RLG Long Talk
March 8, 2024
Adam Wei
Agenda
- Motivation: why data generation?
- Experiments & (empirical) results
- Future work
Single Maze
Multi-Maze
Motion Planning Experiments
Planar Pushing
Sim2Real Transfer
Scaling Laws & Generalization
Motivation: Learning Perspective
Motivation: Learning Perspective
Tesla
1X
...if we can collect enough data, we can solve the task
- Shuran at CoRL
If we have enough data... is robotics (mostly) solved?
If we have enough data... is robotics (mostly) solved?
1. How can we get robot data at scale?

Big data
Big transfer
Small data
No transfer

Ego-Exo
robot teleop


Open-X
simulation rollouts
Slide credit: Russ
If we have enough data... is robotics (mostly) solved?
2. Is scaling all we need?
We need to scale and generalize across:
- objects, tasks, embodiments, environments, camera views, sensor modalities, etc
This is a big ask!
Proposal: Begin by exploring questions about scale directly in simulation
Motivation: Model-Based Perspective
Model-Based Challenges
- Requires state estimation
- Real-time & reactive planning
Behavior Cloning...
- Visuomotor policy
- "Amortizes" the compute
Agenda
Single Maze
Multi-Maze
Motion Planning Experiments
Planar Pushing
Sim2Real Transfer
Scaling Laws & Generalization
Agenda
Single Maze
Multi-Maze
Motion Planning Experiments
Planar Pushing
Sim2Real Transfer
Scaling Laws & Generalization
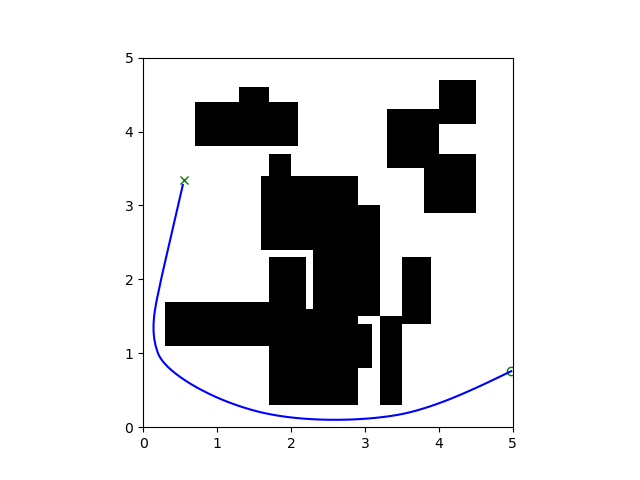
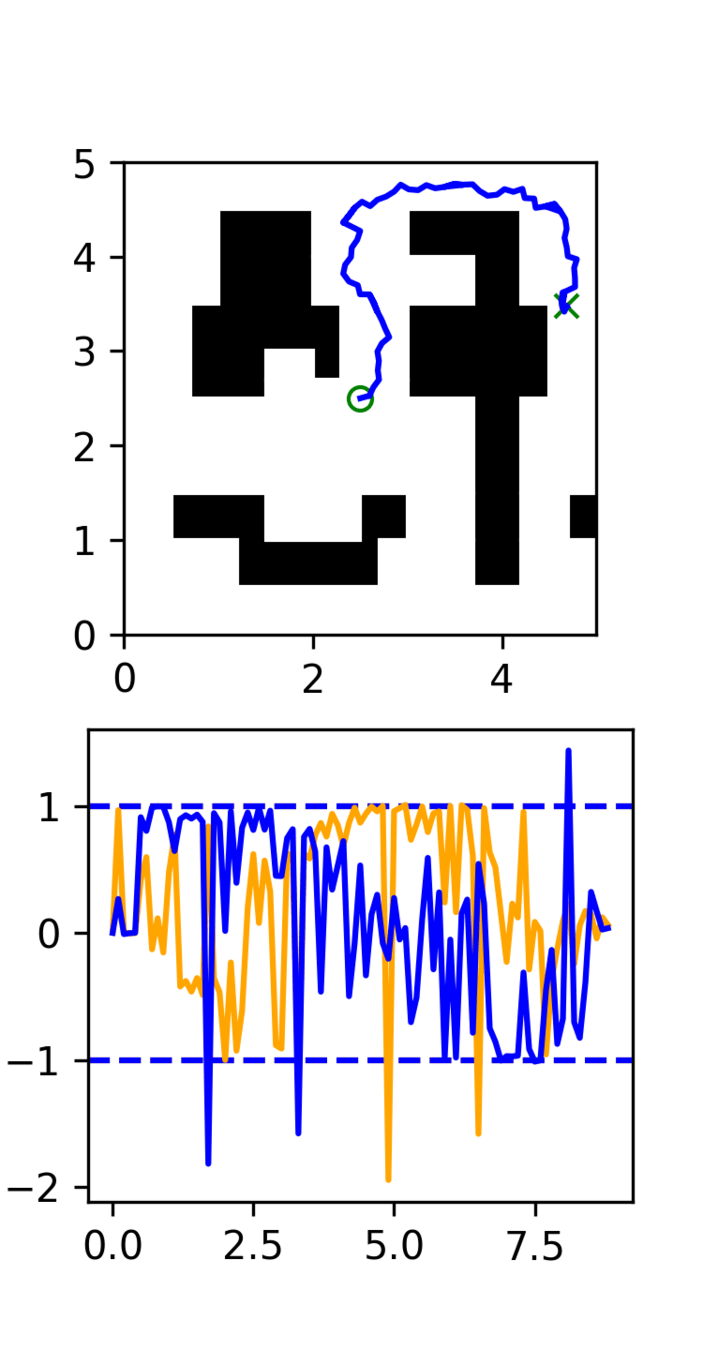
Single Maze: Problem Set Up
Goal: Train a policy to navigate a single maze
- Sequence of robot actions
- History of robot positions
- Target position
Single Maze: Training
Dataset:
- 50k GCS demonstrations
GCS settings
- Min length and time objectives
- Box velocity constraints
- Bezier order 3
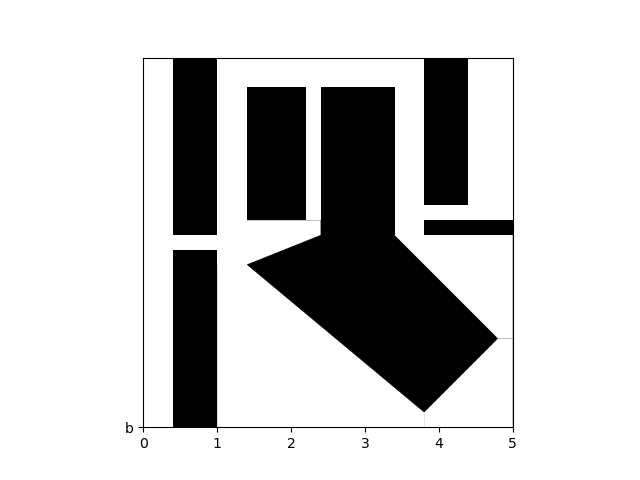
Single Maze: Results
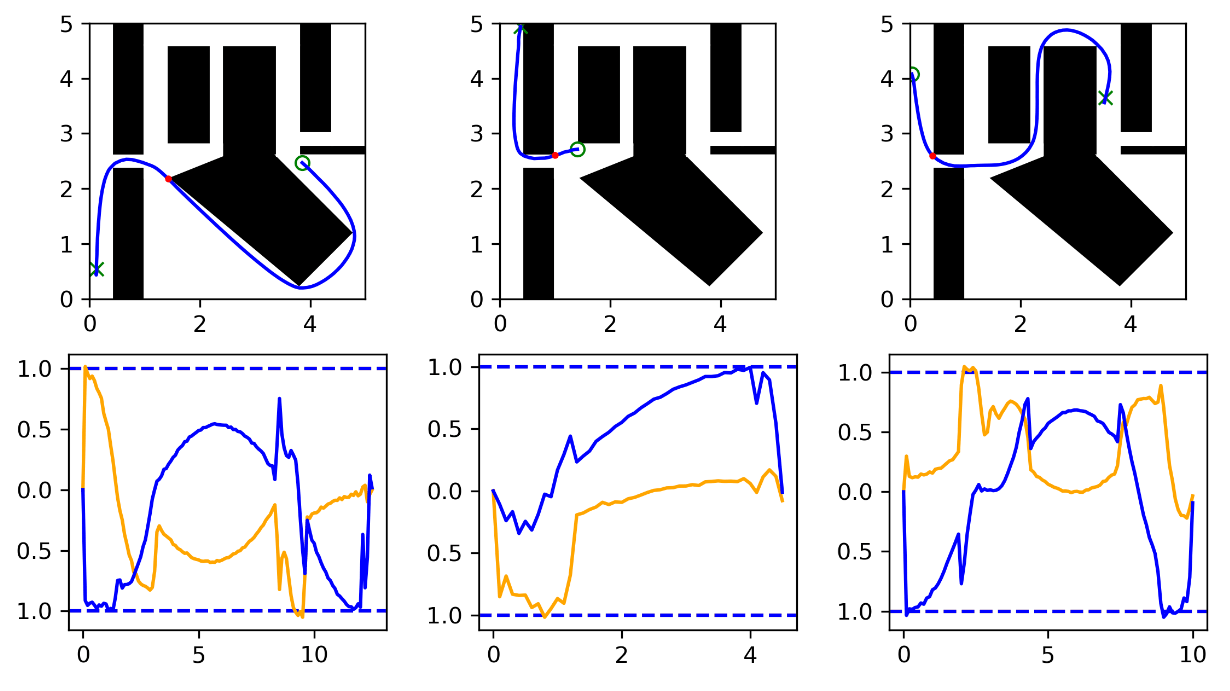
Multi-Maze: Problem Set Up
Goal: Obtain a policy that can navigate arbitary mazes
- Sequence of robot actions
- History of images
- History of robot positions
- Target position
Spoiler: Diffusion Policy cannot solve this task
Multi-Maze: Training
Dataset:
- 250k unique mazes
- 2 trajectories per maze
- Trinary images
GCS Settings
- Same as single maze case
- Padded obstacles
Multi-Maze: Training
RGB
Trinary
64x64x3 [0, 255]
52x52x1 [0, 2]
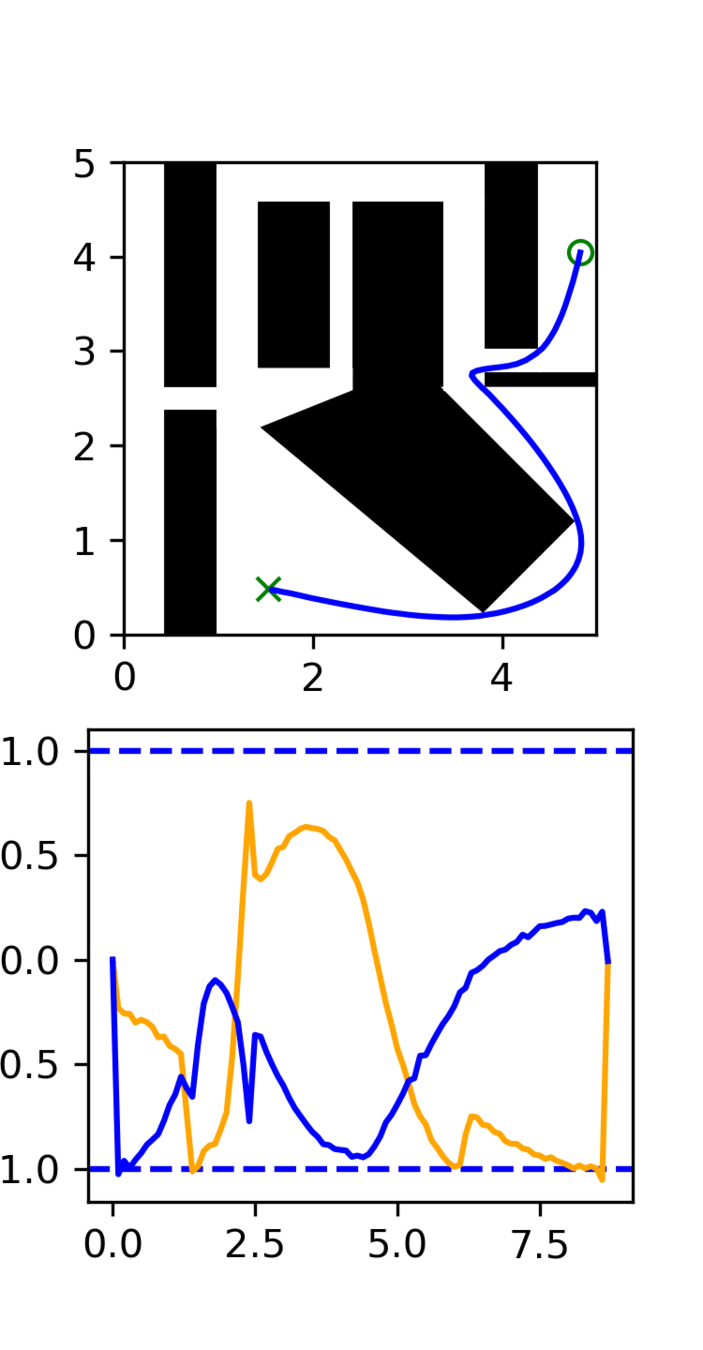
Multi-Maze: [Selected] Results
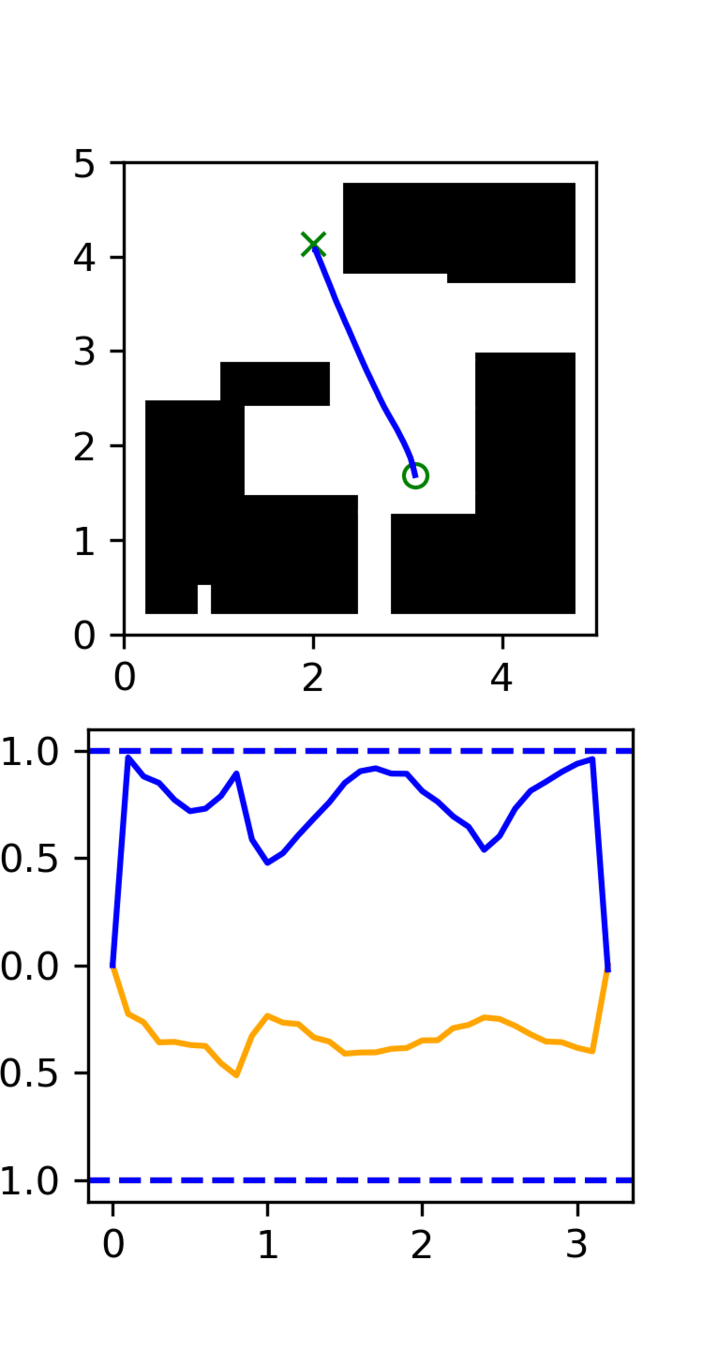
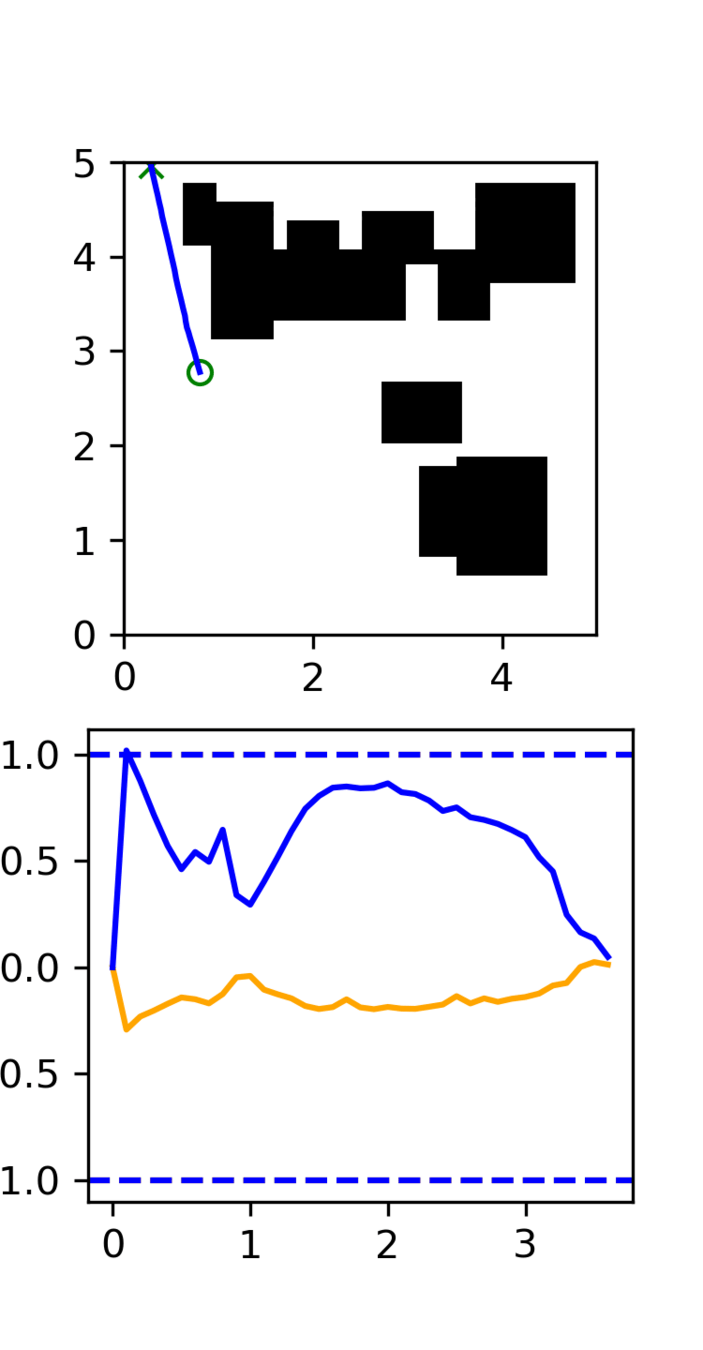
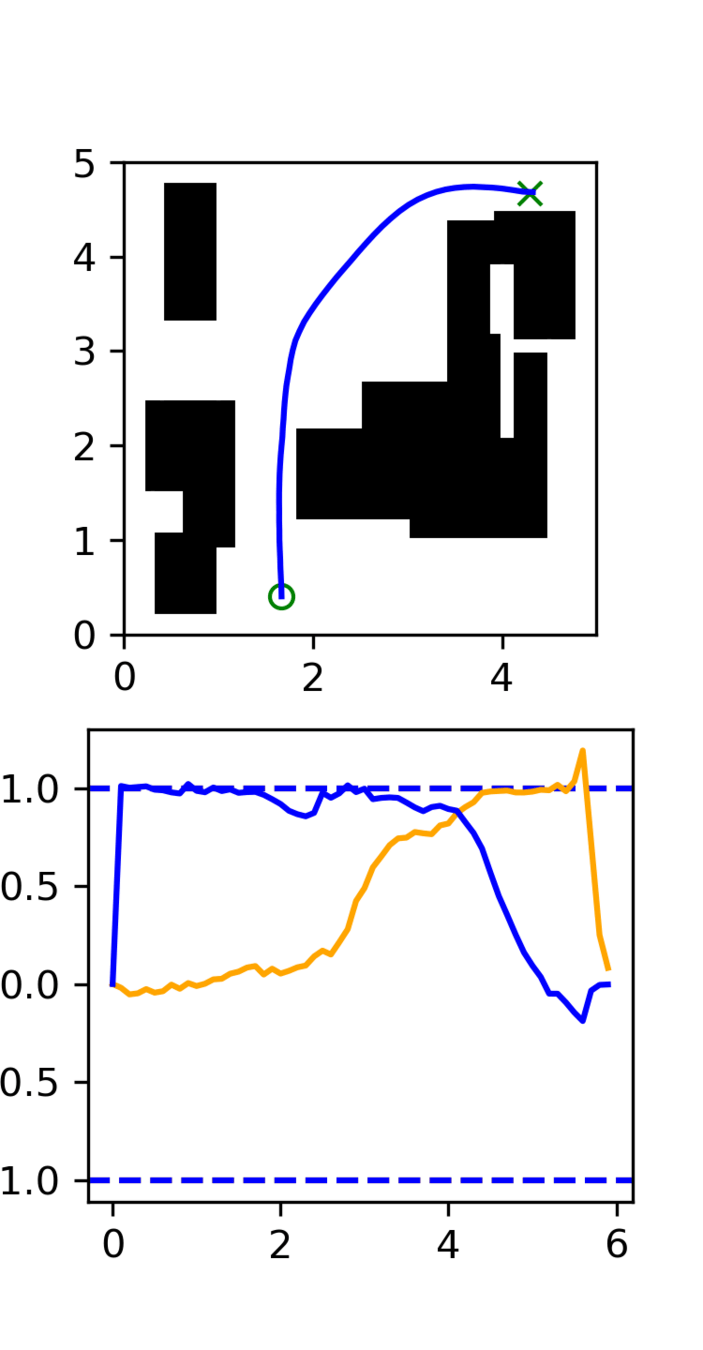
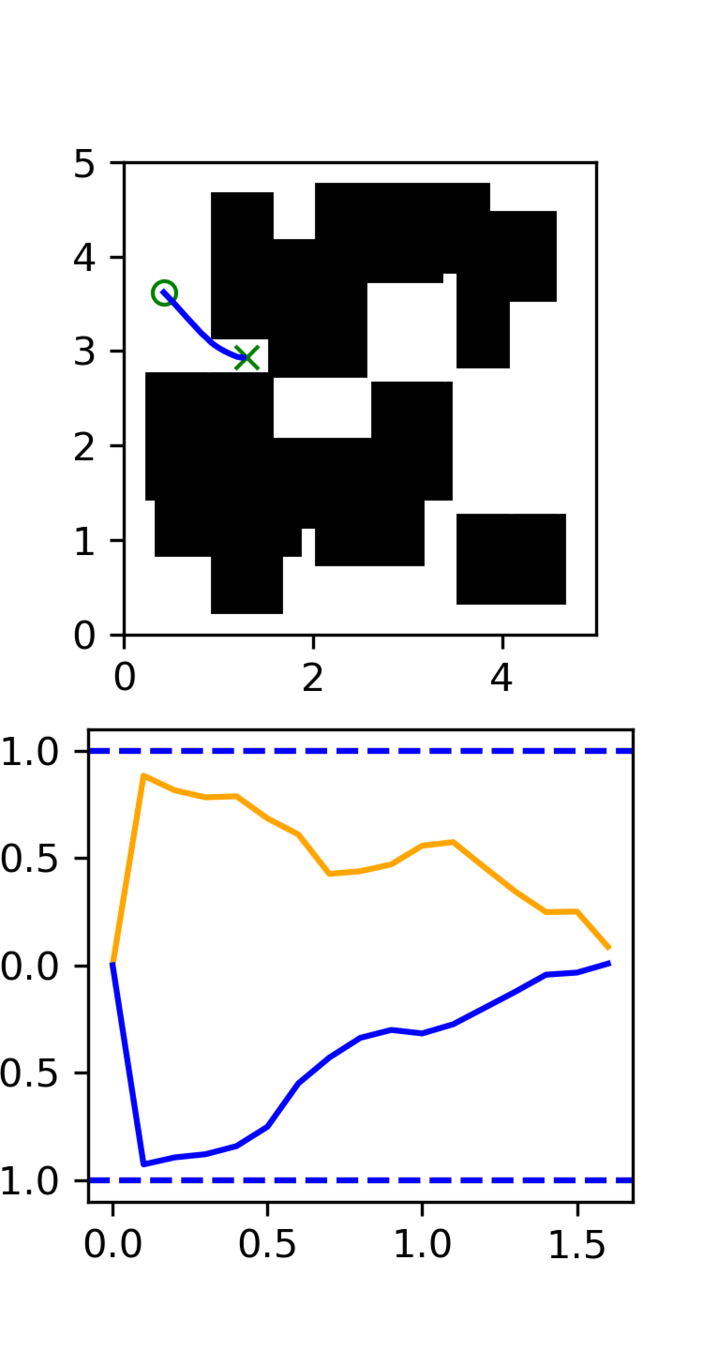
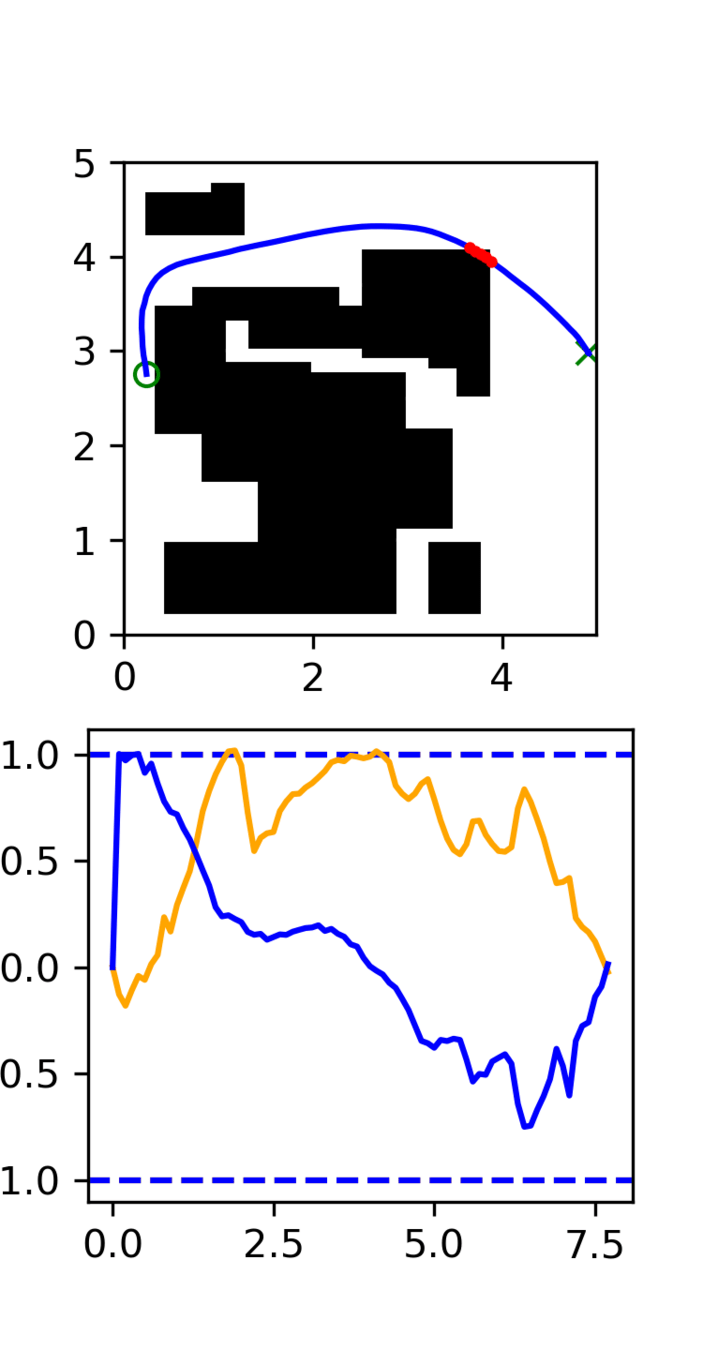
Multi-Maze: Results
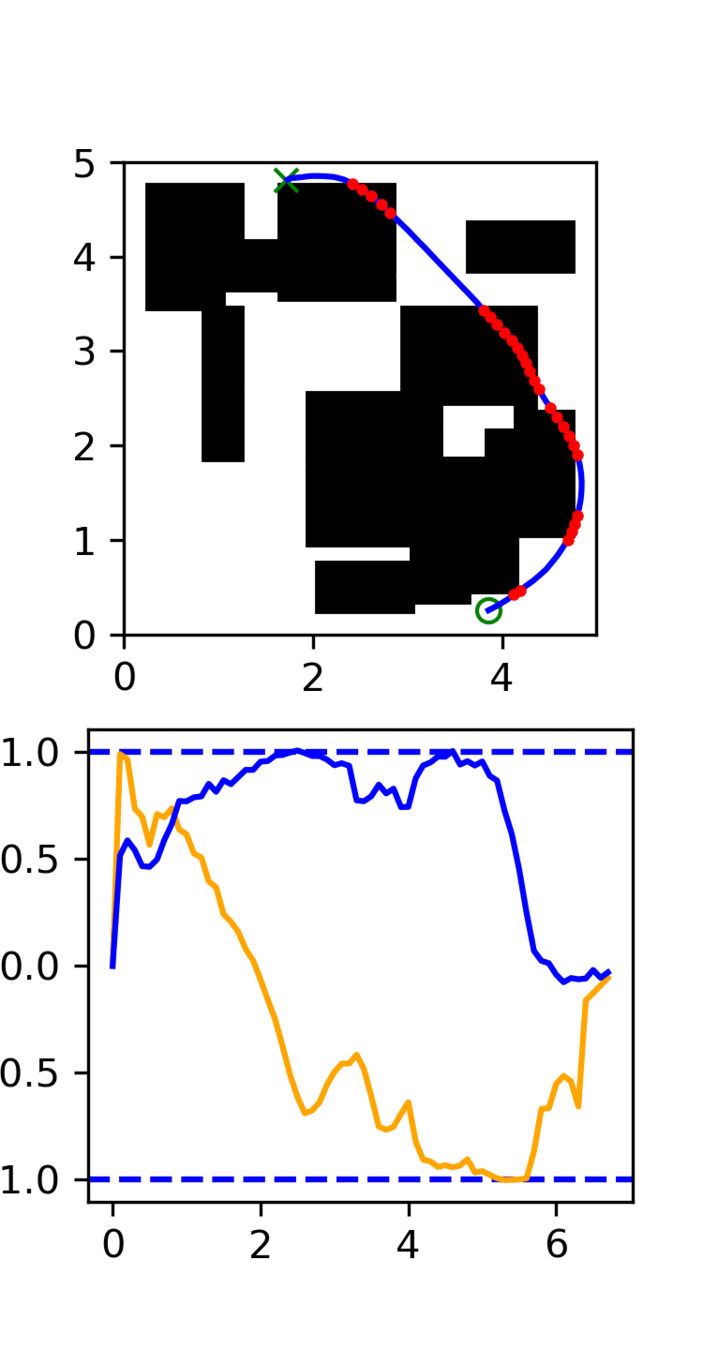
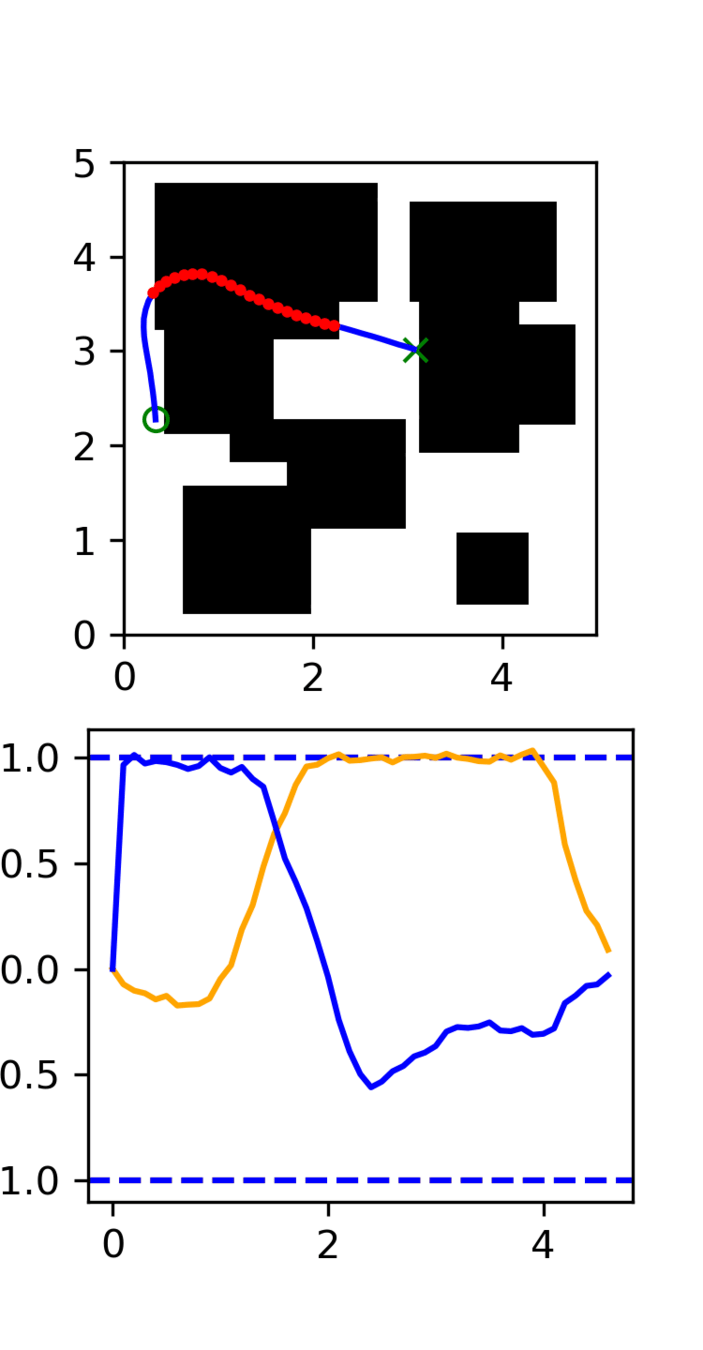
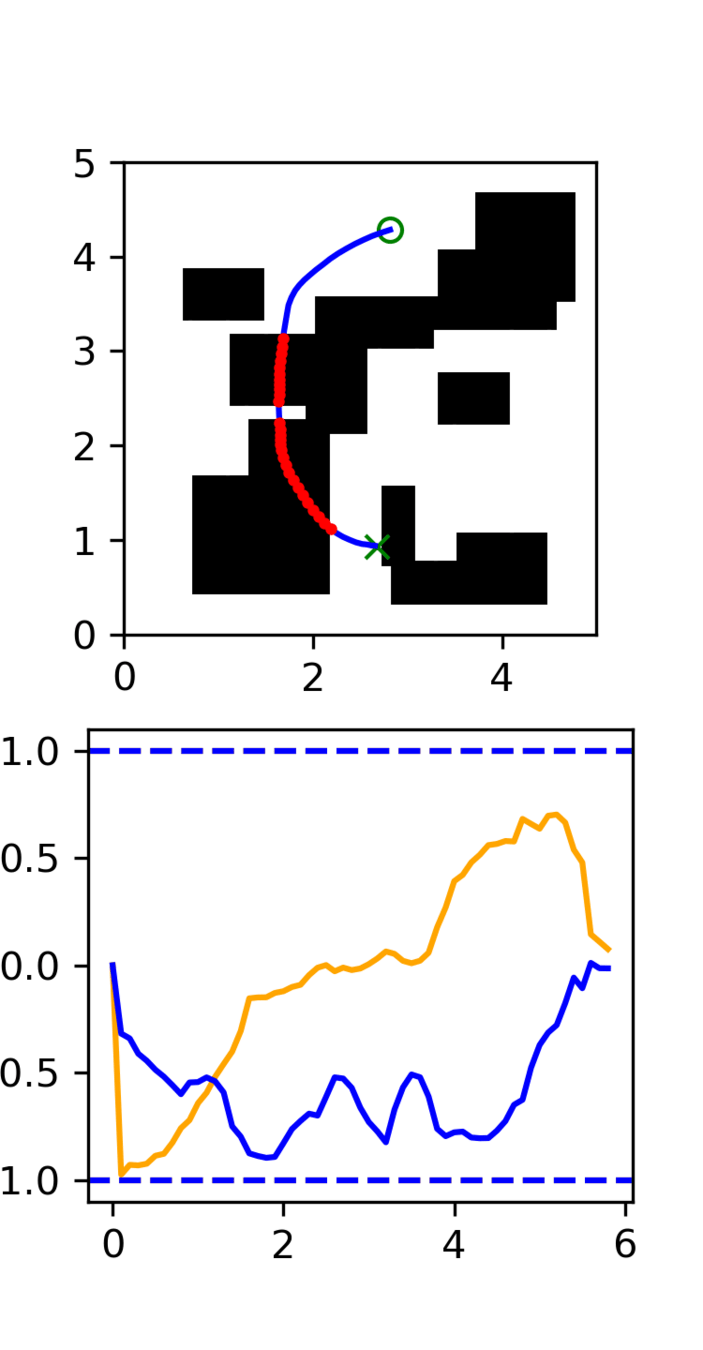
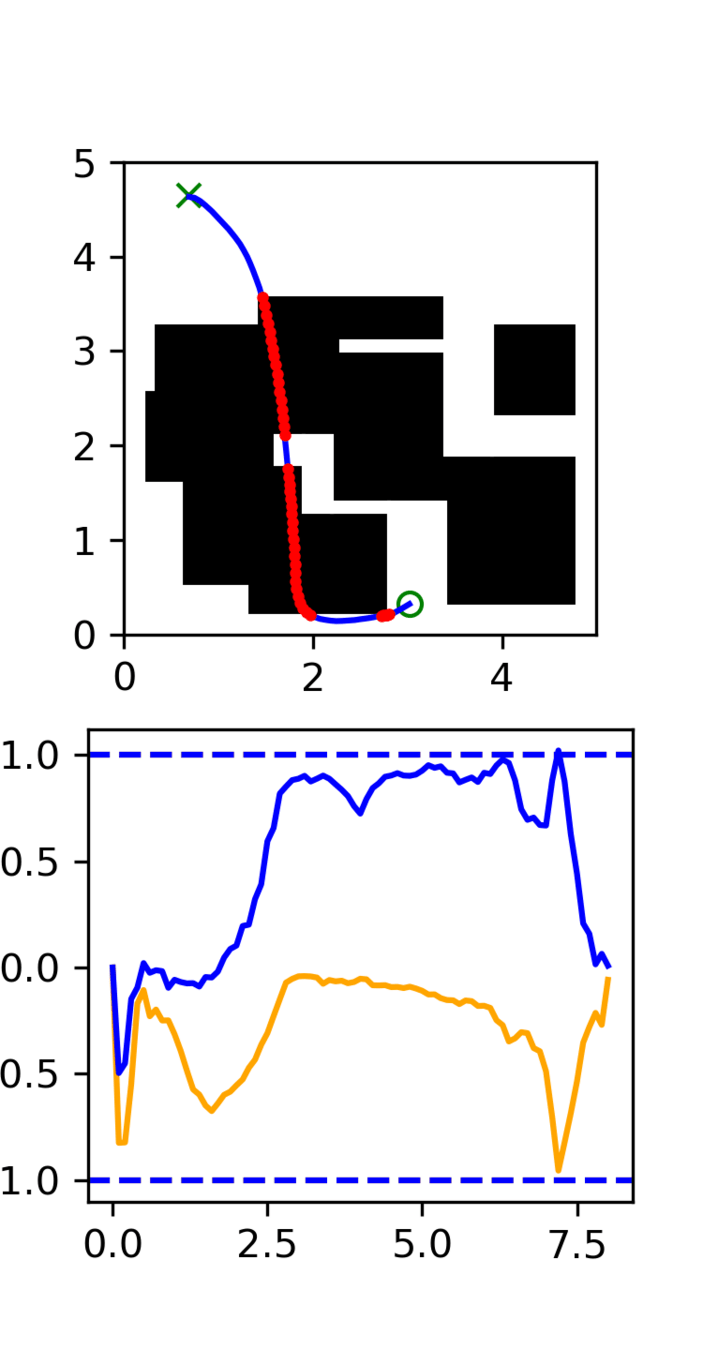
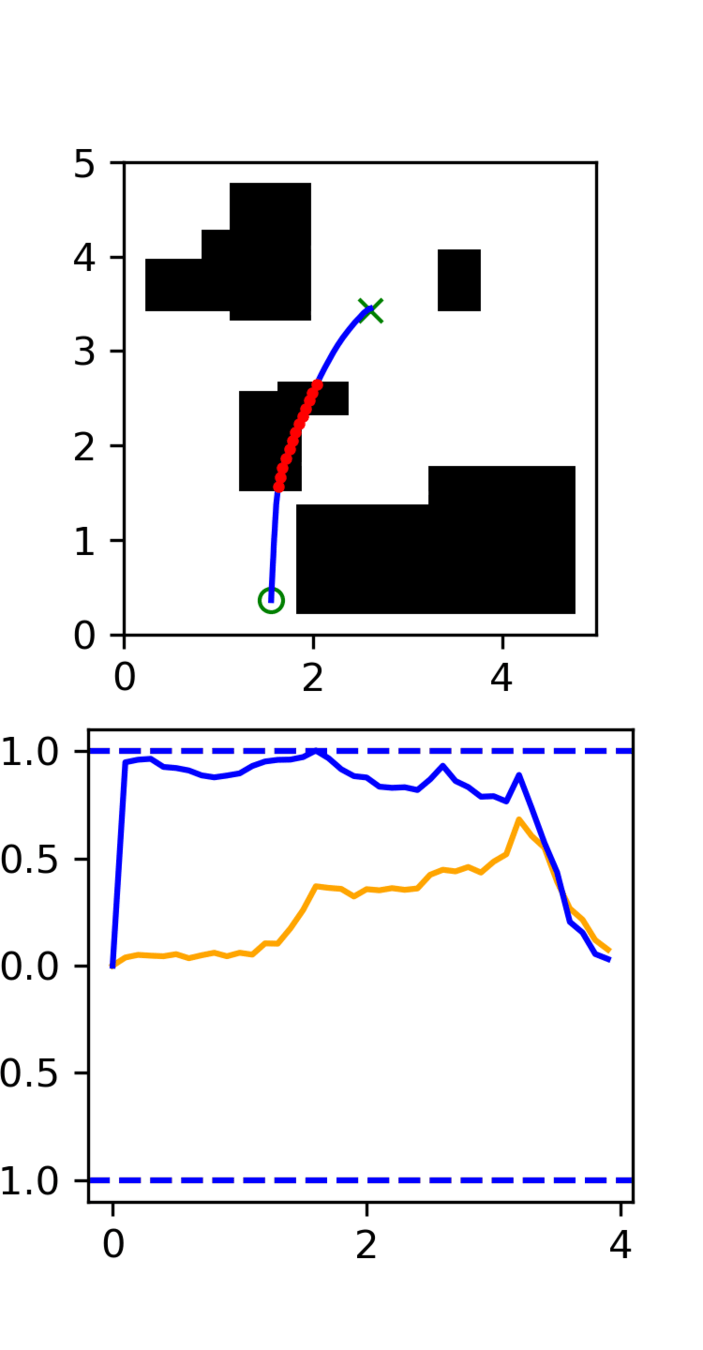
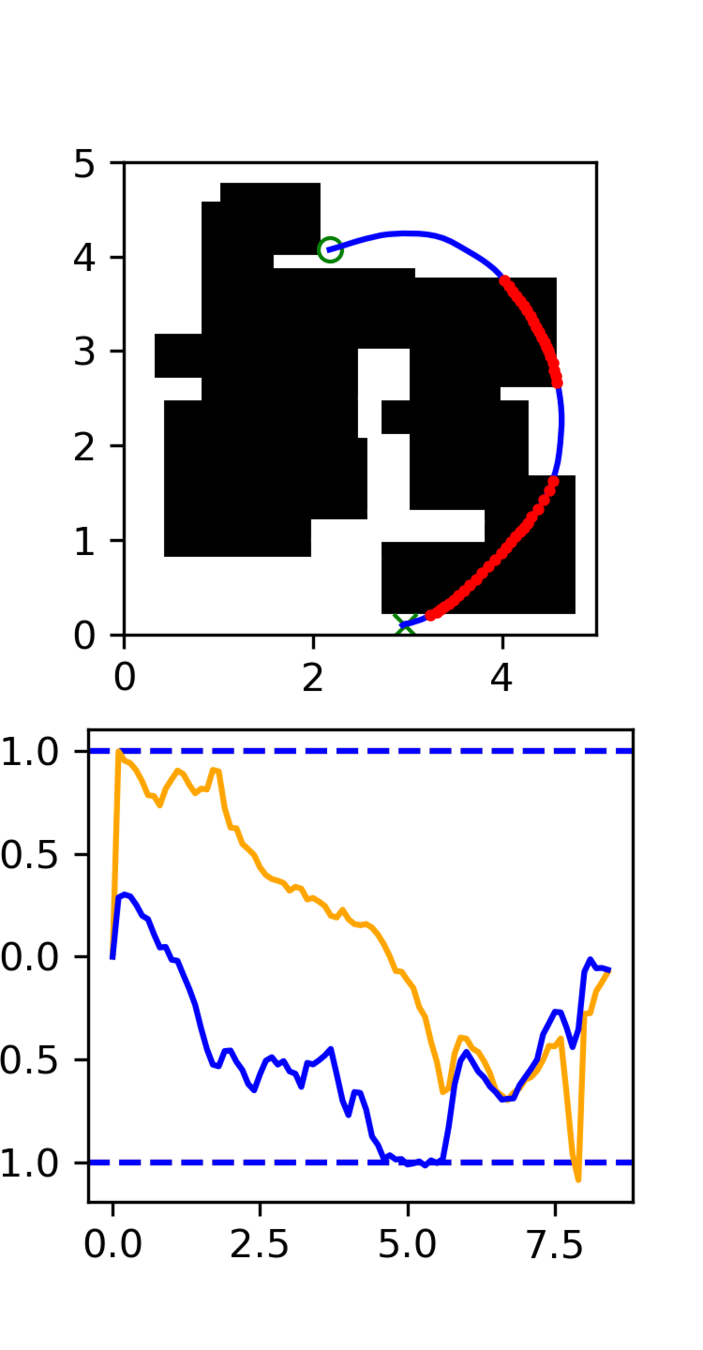
Multi-Maze: Takeaways
- The distribution conditioned on mazes is complex and hard to learn (combinatorial)
- Ex. Given a list of numbers, you wouldn't use a neural network to do sorting
- Need a planner to solve mazes, not a policy
- Generalization in images could just be hard?
- Training on 6250 trajectories yields similar performance as full dataset
Multi-Maze: Related Work

- Diffusing entire plans instead of policies
- One model per maze
Might work for multi-maze?
Multi-Maze: Related Work
Thank you to Ahbinav
for sharing this work

Similar recipe to video prediction:
1. Visually hallucinate a plan
2. Back out actions from the hallucination
??
Agenda
Single Maze
Multi-Maze
Motion Planning Experiments
Planar Pushing
Sim2Real Transfer
Scaling Laws & Generalization
Brief discussion
Motion Planner Comparisons
- Compared different motion planners for diffusion training in the single maze setting

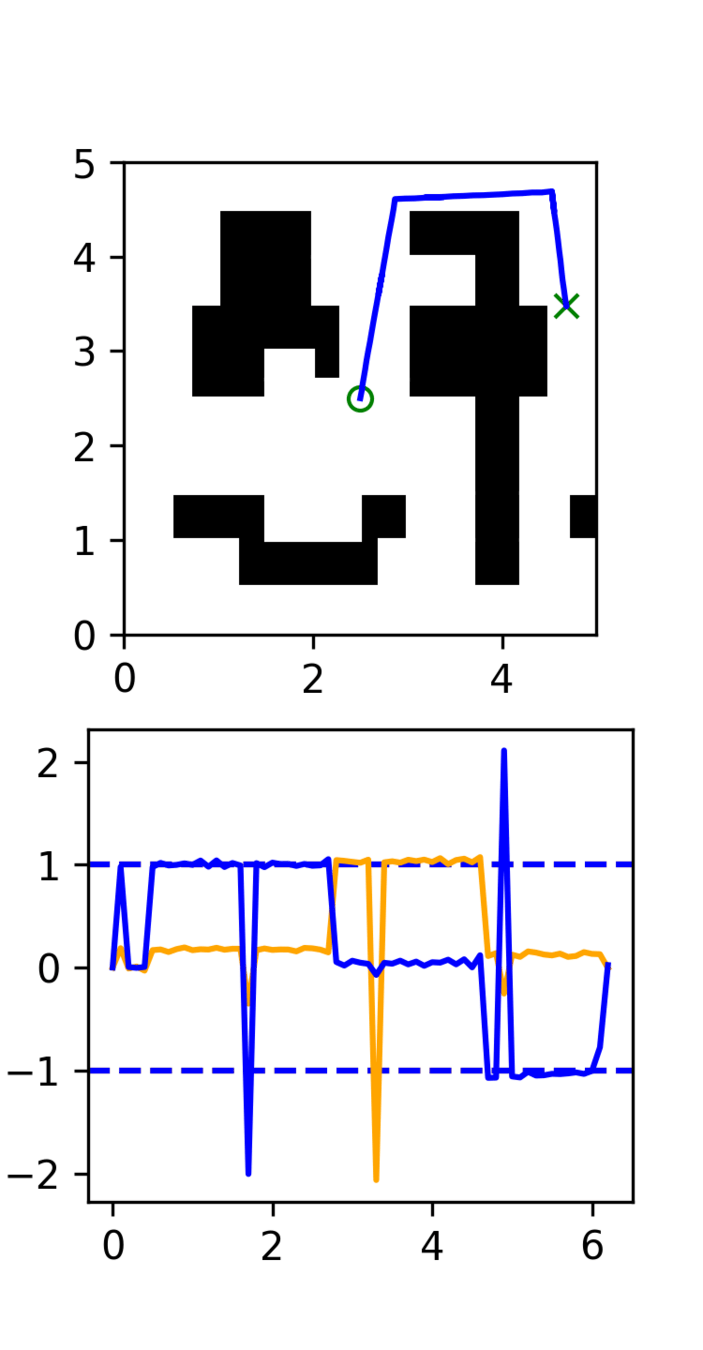
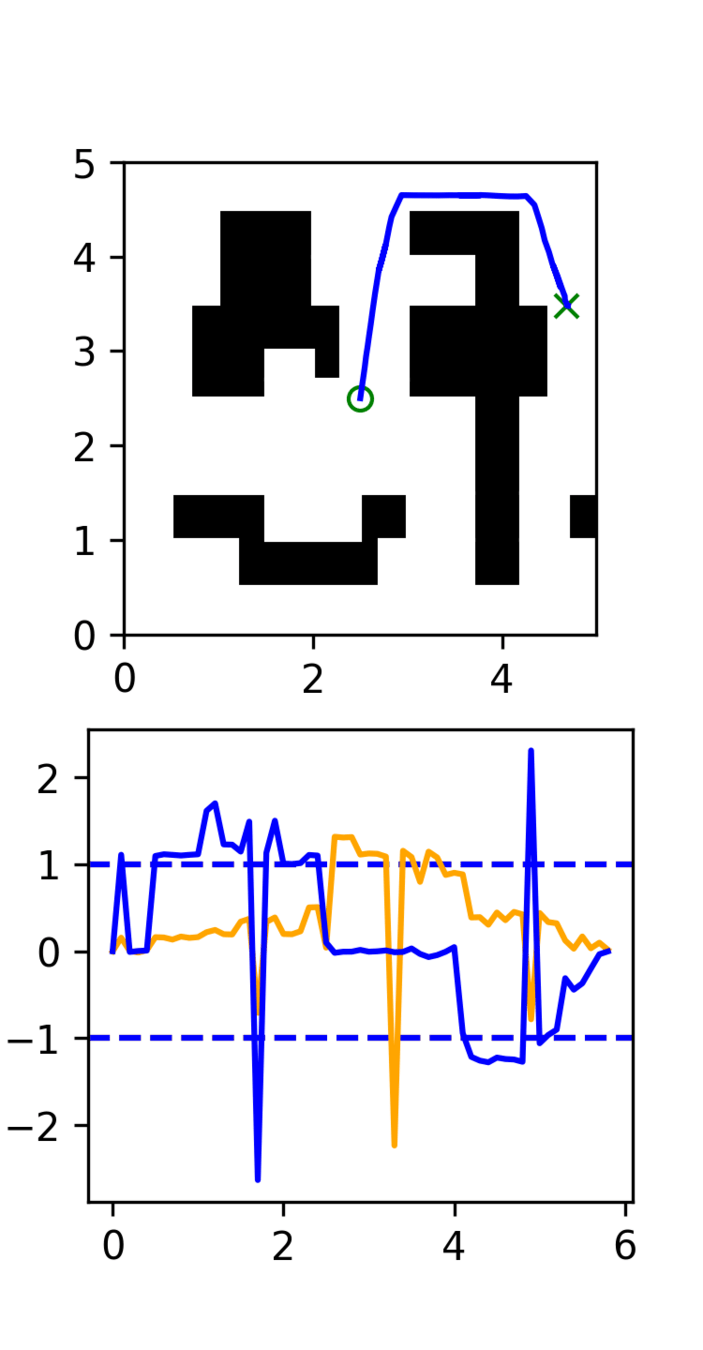
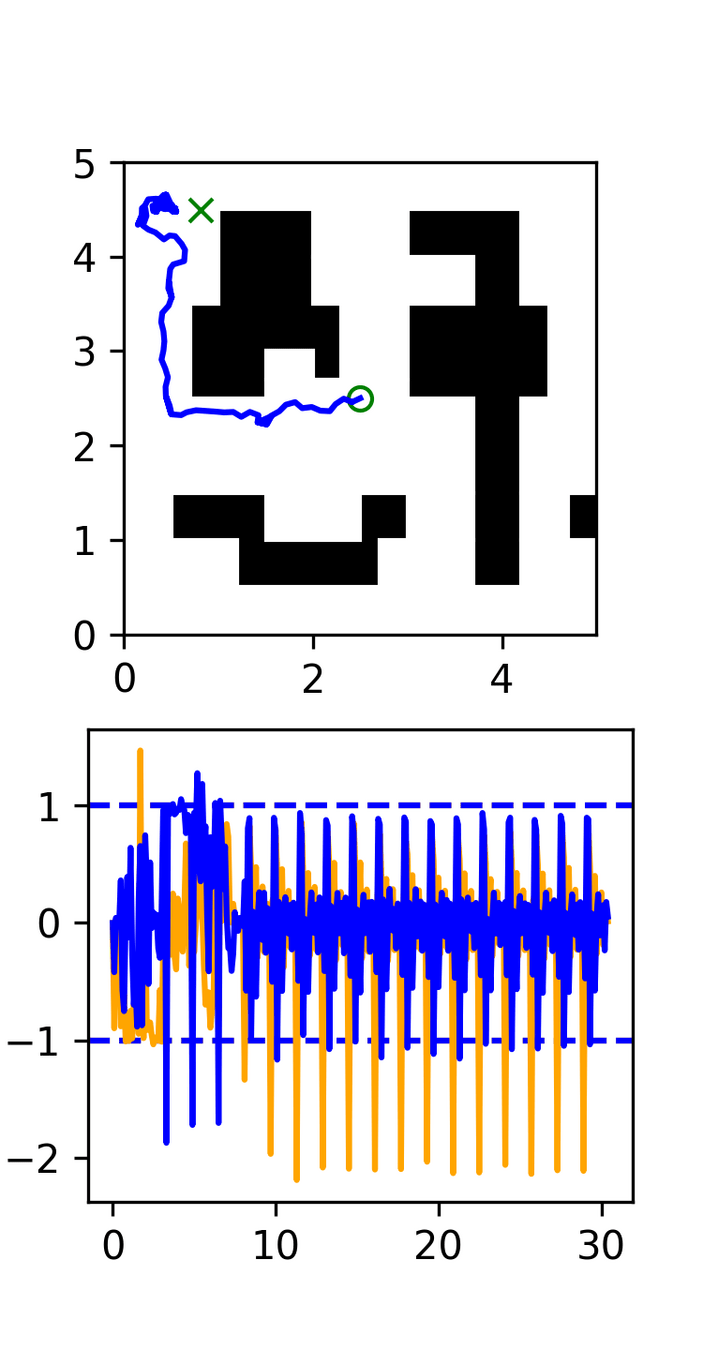
GCS
RRT
RRT (shortcut)
RRT*
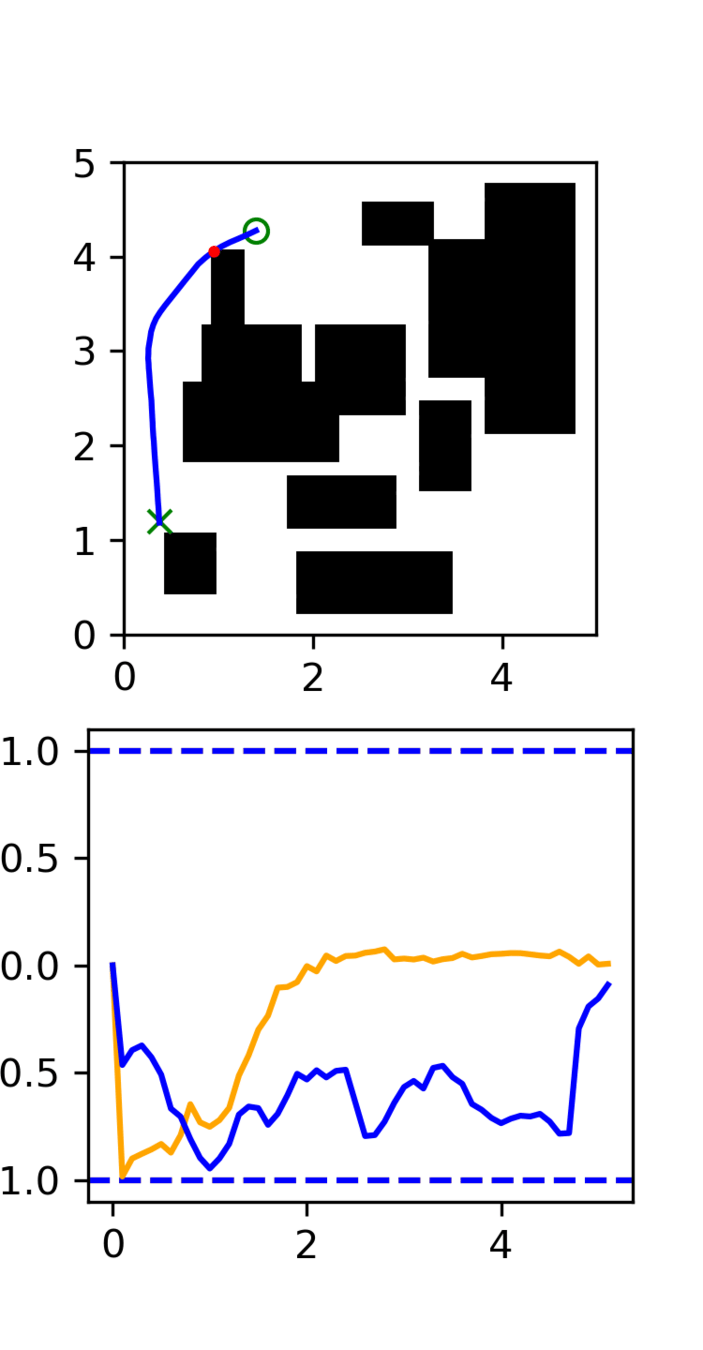
Motion Planner: Takeaways
Data quality matters: diffusion is shockingly good at imitating the characteristics of the expert
- Optimality, smoothness, robustness, etc are important
Ex. RRT
- The policy struggles to converge to the target (too random)
- Diffusion doesn't smooth out the randomness
RRT
Agenda
Single Maze
Multi-Maze
Motion Planning Experiments
Planar Pushing
Sim2Real Transfer
Scaling Laws & Generalization
Learning Perspective
- Scale-up data collection
- Learn a useful representation of physics in simulation; then transfer to real
Data Generation In Simulation
Model-based Perspective
- [Mostly] addresses the 'state estimation' problem
- Real-time and reactive planning (amortizes the compute)




Policy
Training
Data
Trajectory Generation

Data Generation In Simulation
Example: Push-T Task
Policy
Training
Data
Trajectory Generation
Data Generation In Simulation
Example: Push-T Task (with Kuka)



Implementation Details
Data quality matters!
(at least in the low data regime)
Text
Maybe policies become less sensitive to data quality in the big data regime?
Pushing on the vertices
Pushing on the sides (more robust)
Agenda
Single Maze
Multi-Maze
Motion Planning Experiments
Planar Pushing
Sim2Real Transfer
Scaling Laws & Generalization

Sim2Real
Sim2Real
Physics gap
- Simulated physics doesn't need to be perfect; just good enough
Visual gap
- Proposals: domain randomization, photo-realistic rendering (Blender, CycleGan, etc)
Sim2Real
Sim2Real: Real-World Data
- Simulated data can do the heavy lifting, but we can benefit greatly from a small amount of real-world data
- Goal: How can we most effectively leverage a small amount of real-world data?
Big data
Big transfer
Small data
No transfer
Ego-Exo
robot teleop
Simulation
Open-X
Sim2Real
Sim2Real: Finetuning
- Few shot fine-tuning / transfer learning
- Need to train twice


Simulated Policy
Simulated Data
Trajectory Generation
Real Policy
Real-world Data
Sim2Real
Sim2Real: Heterogeneous Datasets
Real-world data
Policy
Training
Data
Trajectory Generation
Sim2Real
Classifier-Free Guidance
- Method to conditionally sample from classes
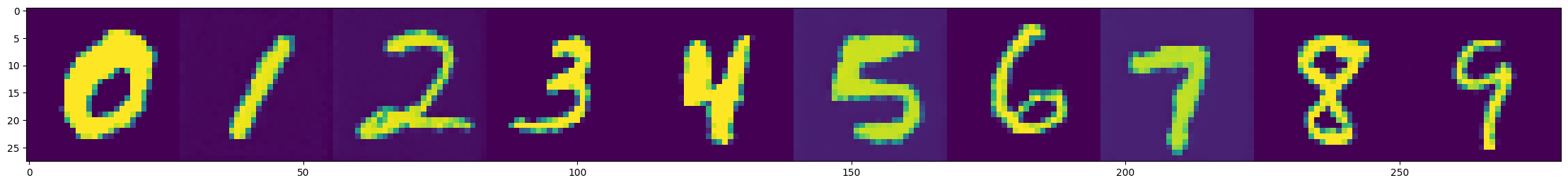
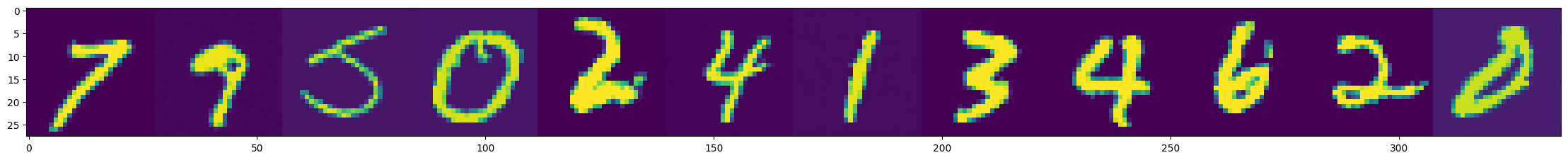
No guidance
With guidance
Sim2Real
Classifier-Free Guidance
- Method to conditionally sample from classes
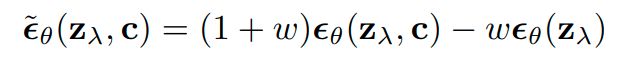
unconditional score
Cats
Dogs
- Unconditional distribution can be complex
Sim2Real
Classifier-Free Guidance
- Method to conditionally sample from classes
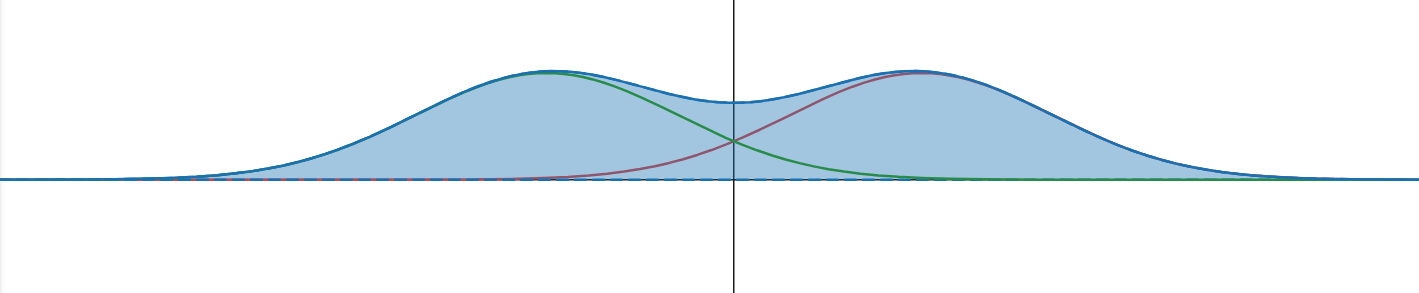
unconditional score
conditional score
Cats
Dogs
- Conditional distributions are simpler
Sim2Real
Sim2Real: Classifier-Free Guidance
Real-world data collection
Policy
(trained via CFG)
Simulated Data + Labels
Trajectory Generation
(I would also be interested in a more rigorous exploration)
Real-world data + Labels
Sim2Real
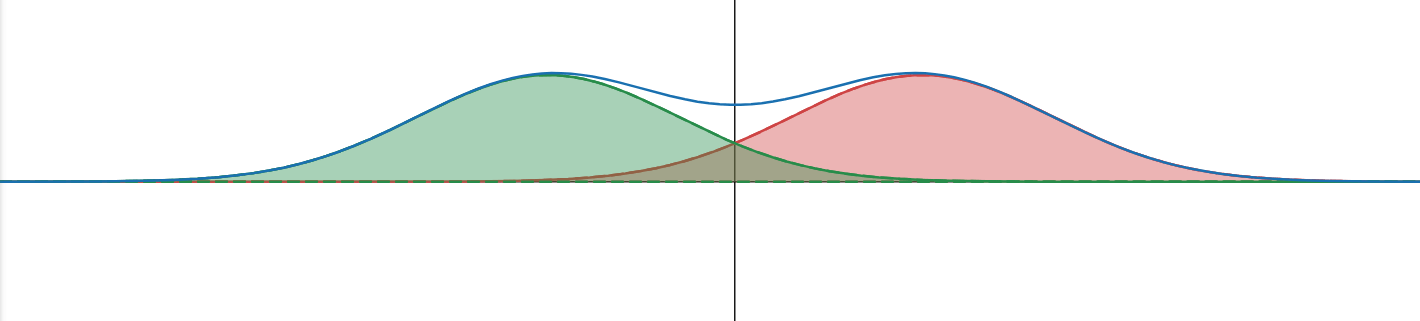
Sim2Real: Classifier-Free Guidance
Sim Data
Real Data
Goal: learn the distributions for both the sim and real data
- Hope that the sim and real distributions are similar enough that the sim data can help the model learn something useful about the real data
- Simultaneously, learn the real distribution to deploy on hardware
Sim2Real
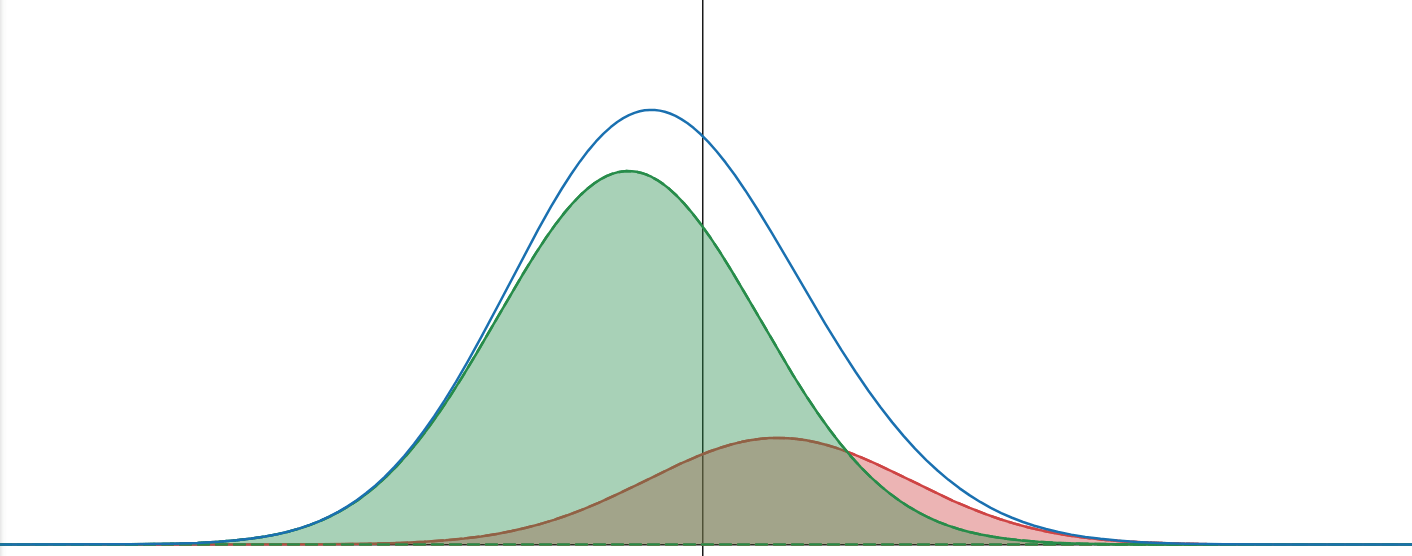
Sim2Real: Classifier-Free Guidance
Sim Data
Real Data
Goal: learn the distributions for both the sim and real data
Caveat: Might not give huge improvements... The policy could already implicitly distinguish between sim and real by the input images?
Agenda
Single Maze
Multi-Maze
Motion Planning Experiments
Planar Pushing
Sim2Real Transfer
Scaling Laws & Generalization
Scaling Laws

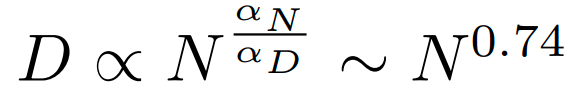
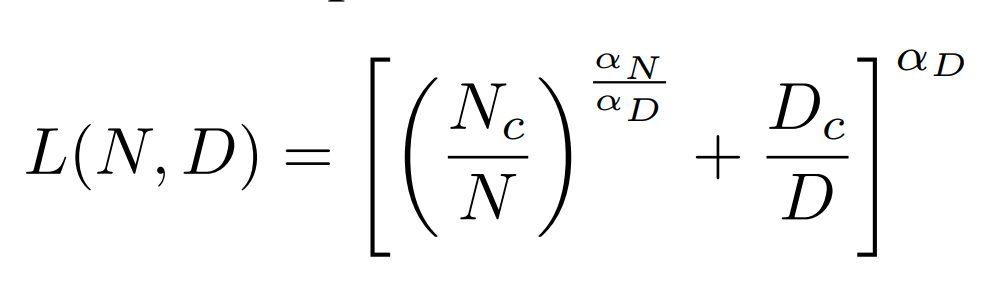
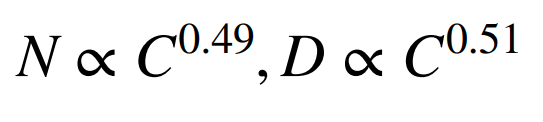
Roughly speaking: For LLMs...
2x data => 2x model size

D = data, N = parameters, C =compute
Scaling Laws
Super useful for practitioners; however...
- Power laws are only valid in the large-data regime
- Power laws require tons of compute to identify (better suited for industry)
Instead, explore scaling and generalization at a smaller scale in simulation:
- objects, tasks, embodiments, environments, camera views, sensor modalities, etc
Generalization Across Objects
Collect a planar-pushing dataset with N objects
Questions: If the policy has learned to push n objects...
- how many of the N objects can it generalize to?
- how much data is required to push the (n+1)th object
Generalization Across Tasks
- Does learning one task make it easier to learn the others?
- Does learning multiple tasks improve performance of individual tasks?
- Can language guidance improve data efficiency?
Push-T
Insertion [IBC]
Sorting [IBC]
Thank you!
Copy of Spring 2024 Long Talk
By Bernhard Paus Græsdal


