bingxuan9112
Omelet >wO
204
不包含以上兩種邊的稱為簡單圖,反之可能稱為偽圖或多重圖,一般來說競程中很少出現後者,今天先預設我們講的都是簡單圖
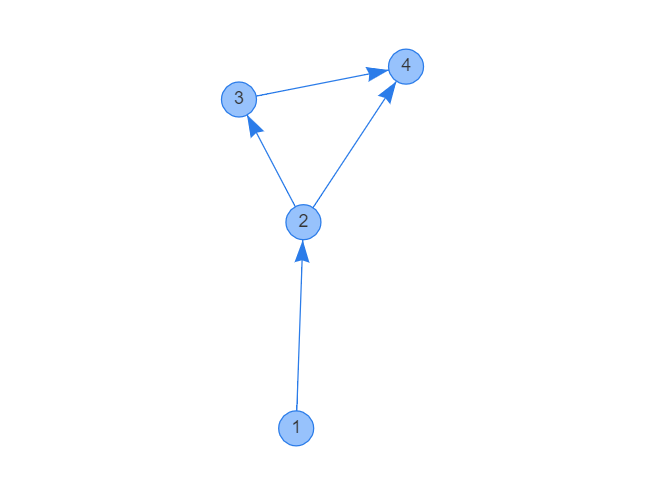
右圖中\(\{4,4\}\)為一自環,\(\{1,2\}\)為兩條重邊
一些特殊的圖
用一個01矩陣\(A_{n\times n}\)儲存,\(a_{ij}=1\)代表有邊由\(i\)指向\(j\),反之則沒有
需要\(O(|V|^2)\)的空間
無向圖的情況通常會寫成\(a_{ij}=a_{ji}=1\)代表\(i,j\)兩頂點之間有邊
const int N = 1000;
int g[N][N];
void addEdge(int a, int b) { // 加上一條a到b的邊
g[a][b] = 1;
}
void print_neighbors(int u) { // 印出u走得到的鄰居
for(int v = 1; v <= n; v++)
if(g[u][v])
cout << v << ' ';
cout << '\n';
}very simple!
對於每個頂點,我們都開一個list紀錄他可以走到的鄰居有哪些
空間\(O(|V|+|E|)\),競程中最常用
通常會使用\(\texttt{std::vector}\)或是自己寫偽指標型list,而不會用\(\texttt{std::list}\)
const int N = 200000;
vector<int> g[N];
void addEdge(int a, int b) { // 加上一條a到b的邊
g[a].push_back(b);
}
void print_neighbors(int u) { // 印出u走得到的鄰居
for(int v:g[u]) cout << v << ' ';
cout << '\n';
}very simple, too
const int N = 200000, M = 1000000; // 點數、邊數
// 大陸人超愛這樣寫 常數比較小的樣子
int tot,head[N],nxt[M],to[M];
void addEdge(int a, int b) { // 加上一條a到b的邊
++tot;
nxt[tot] = head[a];
to[tot] = b;
head[a] = tot;
}
void print_neighbors(int u) { // 印出u走得到的鄰居
for(int id = head[u]; id; id = nxt[id]) //以0當作結尾編號
cout << to[id] << ' ';
cout << '\n';
}偽指標型list
呃...就是開一個陣列只存邊的兩個端點
通常用在演算法只需枚舉邊,如Kruskal's Algorithm
好像已經算舊時代的產品
和邊集一樣用陣列儲存,但是把起點相同的邊放在連續的區間,並對所有\(v\)記錄由\(v\)往外的邊所在的區間\([s_v,t_v)\)
通常直接以字典序排列邊集即可,可以使用counting sort維持時間複雜度在線性時間內
const int N = 200000, M = 1000000; // 點數、邊數
struct Edge {
int a,b;
} E[M];
int cnt[N],L[N],R[N],tot;
void addEdge(int a,int b) {
E[tot].a = a, E[tot].b = b, tot++;
}
void arrange() { // 排序邊
vector<Edge> tmp(tot);
vector<int> cnt(n+1);
for(int i = 0; i < tot; i++) cnt[E[i].a]++;
for(int i = 1; i <= n; i++) cnt[i] += cnt[i-1];
for(int i = 1; i <= n; i++) L[i] = cnt[i-1], R[i] = cnt[i];
for(int i = 0; i < tot; i++) {
int pos = --cnt[E[i].a];
tmp[pos] = E[i];
}
for(int i = 0; i < tot; i++) E[i] = tmp[i];
}
void print_neighbors(int u) { // 印出u走得到的鄰居
for(int i = L[u]; i < R[u]; i++)
cout << E[i].b << ' ';
cout << '\n';
}很廢的練習,如果上星期你有去數讀...
很廢的練習,如果上星期你有去數讀...
圖的遍歷 (Traversal) 是指一張圖從某個點 v 開始,依照某種順序拜訪與已拜訪的點相鄰的點,最終拜訪過圖內所有頂點。而如果我們令 T 為包含拜訪過的節點和拜訪節點所經過的邊的子圖,可以知道 T 會形成一棵 (有向) 樹,我們把樹 T 稱作搜索生成樹。主要的遍歷方法有DFS、BFS等。
-- 並查集 --
By bingxuan9112




