Annotating a
Code-switching Corpus
Ways and Challenges
Lingzi Zhuang
Bingyan Hu
Outline
- Introduction: code-switching
- Corpus Description
-
Our Tasks:
- POS Tagging
- Language ID
-
Future Work
- Parsing
- Semantic Role Labelling
Code-Switching
All cases where lexical items and grammatical features of two languages appear in one sentence.
"
"
Muysken, Pieter. Bilingual Speech: A Typology of Code-Mixing. Port Chester, NY, USA: Cambridge University Press, 2001.
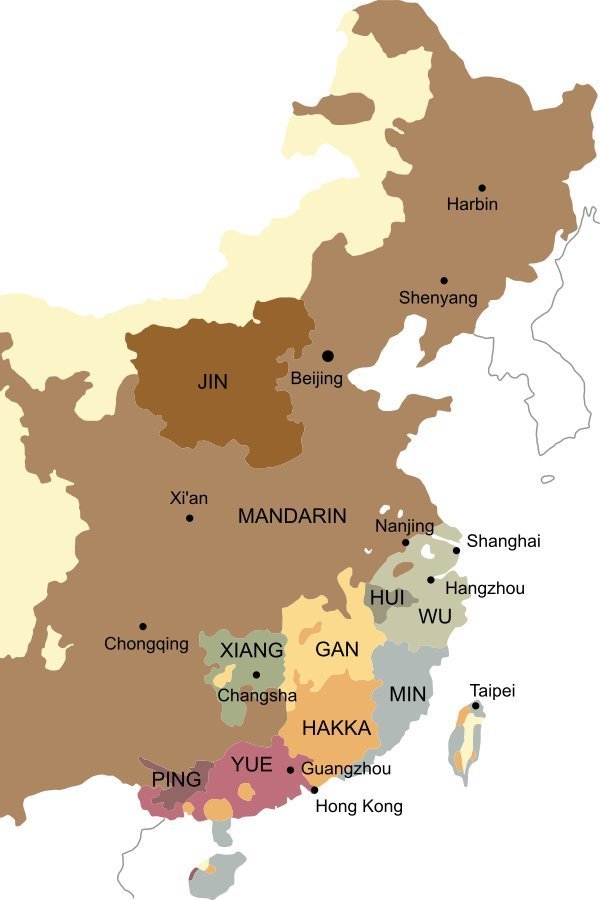
CS in Singapore/Malaysia
-
Official recognition: English, Mandarin, Malay, Tamil (SG & ML)
-
Lingua franca: English (SG & ML), Malay (ML, national language)
-
Chinese varieties: Hokkien (Min-nan), Teochew (Chao-shan), Hakka (Ke-jia), Cantonese (Yue).
-
Mandarin (written language, lingua franca among various Chinese-speakers). Language of instruction.
-
In Singapore, 1979 Speak Mandarin campaign prescribes official status to Mandarin Chinese solely
-
Official bilingualism > extensive code-switching
-
Loans from dialect
CS in Singapore/Malaysia
-
Official recognition: English, Mandarin, Malay, Tamil (SG & ML)
-
Lingua franca: English (SG & ML), Malay (ML, national language)
-
Chinese varieties: Hokkien (Min-nan), Teochew (Chao-shan), Hakka (Ke-jia), Cantonese (Yue).
CS in Singapore/Malaysia
-
Official recognition: English, Mandarin, Malay, Tamil (SG & ML)
-
Lingua franca: English (SG & ML), Malay (ML, national language)
-
Chinese varieties: Hokkien (Min-nan), Teochew (Chao-shan), Hakka (Ke-jia), Cantonese (Yue).
-
Mandarin (written language, lingua franca among various Chinese-speakers). Language of instruction.
-
In Singapore, 1979 Speak Mandarin campaign prescribes official status to Mandarin Chinese solely
-
Official bilingualism > extensive code-switching
-
Loans from dialect
CS in Singapore/Malaysia
-
English ~ Singlish ~ Singaporean Mandarin ~ Mandarin
-
Different levels of mixing
-
Lexical ( insertion of lexical items)
-
Syntactical ( alternation between structures)
-
-
Idiolectal variation
CS in Singapore/Malaysia
-
English ~ Singlish ~ Singaporean Mandarin ~ Mandarin
-
Different levels of mixing
-
Lexical ( insertion of lexical items)
-
Syntactical ( alternation between structures)
-
-
Idiolectal variation
I didn’t know that … yeah… I didn’t tell you ’cause I thought that nĭ (you)… yŏu (have) meeting … yeah wŏ jiù (so I) méiyŏu (did not) reconcile nàgè (that) part with nĭ jiăng de nàgè part (that part which you mentioned).
SEAME Corpus
-
Southeast Asia Mandarin English Code-switching corpus (LDC2015S04)
-
Nanyang Technological U (SG), U Sains Malaysia (ML)
-
156 speakers; 19-33 yrs; balanced in gender.
-
82% Singaporean, 18% Malaysian
-
-
192 hrs audio in conversational and interview (monologue) styles
-
63 hrs of individual, sentence-/semantic chunk-level utterances transcribed.
-
18% from conversational, 82% from interview.
- 54% Singaporean, 46% Malaysian.
-
http://www.signalprocessingsociety.org/technical-committees/list/sl-tc/spl-nl/2015-05/2015-05-Seame/
SEAME Corpus
-
- .
01NC01FBX_0101 86300 88370 then area five 的 total 是
01NC01FBX_0101 165090 167860 不 懂 but official result 还 没有 出 i think 出 了 他们 就 会
01NC01FBX_0101 275720 281420 as in 我 可以 meet la but 我 不 懂 我 还 以为 你们 我 不 懂 你们 有 confirm 去 gym then 我 自己 也 没有 带 我 东西
01NC01FBX_0101 532940 538300 maybe 他 at least at least 他 没有 跟 你 讲 他 在 做工 during the week saturday and sunday
01NC01FBX_0101 579040 580900 做工 做到 很 迟 then in the end 他
01NC01FBX_0101 597330 606920 then 就 不 懂 讲 什么 话 then andy 就 started saying that like 你 去 civil service 你 真的 要 有 like 你 的 honors 那种 不然 就 like 很 disadvantage in terms of 你 的 pay 这些 then 我 就 讲 你 不 是 second up
01NC01FBX_0101 615770 625430 andy's school 的 那个 miss singapore universe 那个 头发 短短 then 每次 参加 那种 pageant 就 总之 她 蛮 出名 的 then 就 他 突然间 讲 到 like peggy 是 第六 年 liao 了
01NC01FBX_0101 625650 627930 她 还 在 读 她 的 对对 对 她 今年 是 sixth year
01NC01FBX_0101 669870 673820 oh 他 拿 third class 他 差一点点 他 的 F.Y.P. screwed up 他 拿 到 B. minus C. plus
01NC01FBX_0101 706820 709160 屁 没有 打包 啊 他 没有 打包 过
01NC01FBX_0101 743340 747050 我 我 是 觉得 很 浪费 那个 sem 我 die die 继续 take then 看 怎么样 讲
01NC01FBX_0101 860180 864580 but then 如果 你 不 take I.A. 你 take I.O. 你 要 clear more electives
01NC01FBX_0101 1031580 1036200 she could have transferred course eh 你 懂 我 有 两 个 or should say 我 那个 F.Y.P. friend 那个 男 的
01NC01FBX_0101 1036230 1045850 他 是 from engine 的 then 他 就 就 也 是 a levels 考得 很 烂 很 烂 then 就 被 丢 进 engine but then 他 year one sem one 就 考得 like three point something 就 not bad then 他 就 apply then 就 换
01NC01FBX_0101 1045860 1051850 他 year one sem two 就 来 econs then 我 还有 多 两 个 friend 也 是 有 一个 女 的 更 惨 她 是 我 J.C. first three months 的 friend
01NC01FBX_0101 1099510 1105490 超 喜欢 啦 我 觉得 我 是 读 对 东西 我 很 开心 我 那 时候 appeal accountancy 我 没有 进
01NC01FBX_0101 1106560 1115600 因为 我 的 first choice 我 放 accountancy second choice 我 才放 econs then 我 就 没有 进 accountancy 因为 那 时候 那个 cutoff 是 a a B.S. 我 不 是 蛮 高 的 我 就 拿 B.B.B. 那种
01NC01FBX_0101 1115690 1118680 then in the end 就读 econs then 我 还去 appeal 一 次
01NC01FBX_0101 1124910 1131600 就 我 觉得 three years then some more 它 是 一个 professional job then 我 就 觉得 i mean like why spend four years doing a general arts
01NC01FBX_0101 1330860 1335250 but i think 这种 business 的 应该 没有 很 凶 like 那种 major project 酱
01NC01FBX_0101 1470440 1480000 从 我 一 到 那个 toa-payoh M.R.T. station 我 就 看 很多 人 惨 了 那个 announcement 就 讲 there was some delay in the previous train then 就 什么 it might cause it might cause a 什么 delay in your ride 什么 东西
01NC01FBX_0101 1556330 1560860 but then 谁 会要 从 ang-mo-kio 搭 到 jurong-east then 搭 去 pasir-ris
01NC01FBX_0101 1869620 1878690 它 有 那个 show flat then 我 跟 我 friend 我 跟 jerrin 就 很 gian to 去 看 then 就 弄到 很 美 很美 可是 很 小 很 小 but 它 的 five rooms hor 就 你家 也 是 five rooms 对 吗
01NC01FBX_0101 1898810 1906880 and then 他 就 pay 了 like almost sixty six hundred thousand for 那个 屋子 就 more than half of a million for 一个 新 的 H.D.B.flat lehOur Task: so far...
-
Given word-segmented transcription, implement different types of lexical/syntactic annotation that are potentially useful for feature extraction of code-switching behaviour.
-
POS tags
-
Language identification: Mandarin, English, other
-
Named entities
- Singlish/Manglish discourse particles (ultimately loaned from local varieties of Chinese)
-
-
Our Task: so far...
-
Given word-segmented transcription, implement different types of lexical/syntactic annotation that are potentially useful for feature extraction of code-switching behaviour.
-
POS tags
-
Language identification: Mandarin, English, other
-
Named entities
- Singlish/Manglish discourse particles (ultimately loaned from local varieties of Chinese)
-
-
Our Task: so far...
-
Given word-segmented transcription, implement different types of lexical/syntactic annotation that are potentially useful for feature extraction of code-switching behaviour.
-
POS tags
-
Language identification: Mandarin, English, other
-
Named entities
- Singlish/Manglish discourse particles (ultimately loaned from local varieties of Chinese)
-
-
-
I am trying to avoid it [ar] (… emphatic declarative)
- But then if cannot get a bank then die already [lorh] (… hasten affirmation of new circumstance)
Our Task: Overall Challenges
-
Spoken language corpus
-
Non-standard words/spellings
-
Fragments, repetitions, etc.
-
-
Inconsistent quality of transcription
-
Spelling/character mistakes (have not > kerosene)
-
Undelivered promises
-
discourse particles, named entities, loans
-
-
-
Problematic utterance selection
- Many utterances contain more than one sentence; no boundary marked
Our Task: Overall Challenges
-
Spoken language corpus
-
Non-standard words/spellings
-
Fragments, repetitions, etc.
-
-
Inconsistent quality of transcription
-
Spelling/character mistakes (have not > kerosene)
-
Undelivered promises
-
discourse particles, named entities, loans
-
-
-
Problematic utterance selection
- Many utterances contain more than one sentence; no boundary marked
Our Task: Overall Challenges
-
Spoken language corpus
-
Non-standard words/spellings
-
Fragments, repetitions, etc.
-
-
Inconsistent quality of transcription
-
Spelling/character mistakes (have not > kerosene)
-
Undelivered promises
-
discourse particles, named entities, loans
-
-
-
Problematic utterance selection
- Many utterances contain more than one sentence; no boundary marked
POS-Tagging
-
Word-level segmentation of Chinese parts
-
Original SEAME segmentation less-than-ideal
-
Stanford Chinese Word Segmenter works well with bilingual Chinese-English data
-
-
POS-tag Chinese and English parts separately
-
Automatic POS-tagging using Stanford POS-tagger
-
Penn Treebank & Penn Chinese Treebank standards
-
-
Map PTB and CTB tags to Universal POS Tagset
- "A set of coarse POS categories exists cross-linguistically in one form or another" (Carnie)
POS-Tagging
-
Word-level segmentation of Chinese parts
-
Original SEAME segmentation less-than-ideal
-
Stanford Chinese Word Segmenter works well with bilingual Chinese-English data
-
-
POS-tag Chinese and English parts separately
-
Automatic POS-tagging using Stanford POS-tagger
-
Penn Treebank & Penn Chinese Treebank standards
-
-
Map PTB and CTB tags to Universal POS Tagset
- "A set of coarse POS categories exists cross-linguistically in one form or another" (Carnie)
POS-Tagging
-
Word-level segmentation of Chinese parts
-
Original SEAME segmentation less-than-ideal
-
Stanford Chinese Word Segmenter works well with bilingual Chinese-English data
-
-
POS-tag Chinese and English parts separately
-
Automatic POS-tagging using Stanford POS-tagger
-
Penn Treebank & Penn Chinese Treebank standards
-
-
Map PTB and CTB tags to Universal POS Tagset
- "A set of coarse POS categories exists cross-linguistically in one form or another" (Carnie)
POS-Tagging
-
Word-level segmentation of Chinese parts
-
Original SEAME segmentation less-than-ideal
-
Stanford Chinese Word Segmenter works well with bilingual Chinese-English data
-
-
POS-tag Chinese and English parts separately
-
Automatic POS-tagging using Stanford POS-tagger
-
Penn Treebank & Penn Chinese Treebank standards
-
-
Map PTB and CTB tags to Universal POS Tagset
- "A set of coarse POS categories exists cross-linguistically in one form or another" (Carnie)
POS-Tagging
Chinese/中文
English/英文
Chinese/中文
他们 就 要 take I.O. 所以 可以 自己 去 找
POS-Tagging
Chinese/中文
English/英文
Chinese/中文
他们 就 要 take I.O. 所以 可以 自己 去 找
Chinese/中文
English/英文
["他们", "就", "要";
"所以", "可以", "自己", "去", "找"]
["take", "I.O."]
POS-Tagging
Chinese/中文
English/英文
Chinese/中文
他们 就 要 take I.O. 所以 可以 自己 去 找
Chinese/中文
English/英文
["他们", "就", "要";
"所以", "可以", "自己", "去", "找"]
["take", "I.O."]
Chinese/中文
English/英文
[("他们", "PN"), ("就","AD"), ("要", "VV");
("所以", "CC"), ("可以","VV), ("自己", "AD"), ("去", "VV"), ("找", "VV")]
[("take", "VB"), ("I.O.", "NNP")]
POS-Tagging
Chinese/中文
English/英文
("take", "VERB"), ("I.O.", "PROPN"),
[("他们", "PRON"), ("就","ADV"), ("要", "VERB"),
Chinese/中文
("所以", "CONJ"), ("可以","VERB), ("自己", "ADV"), ("去", "VERB"), ("找", "VERB")]
Chinese/中文
English/英文
[("他们", "PRON"), ("就","ADV"), ("要", "VERB");
("所以", "CONJ"), ("可以","VERB), ("自己", "ADV"), ("去", "VERB"), ("找", "VERB")]
[("take", "VERB"), ("I.O.", "PROPN")]
POS-Tagging
-
Problems fixed:
-
discourse particles (global search using a list)
-
"lah", "leh", etc.
-
-
-
In progress:
-
Named entities
-
Manual identification using crowdsourcing
-
"lord" "of" "the" "rings" type
-
-
Discourse markers
-
"well", "you know", "like", "right", "okay", etc.
-
Crowdsourcing results unsatisfactory
-
Manual disambiguation in lab?
-
-
POS-Tagging
-
Problems fixed:
-
discourse particles (global search using a list)
-
"lah", "leh", etc.
-
-
-
In progress:
-
Named entities
-
Manual identification using crowdsourcing
-
"lord" "of" "the" "rings" type
-
-
Discourse markers
-
"well", "you know", "like", "right", "okay", etc.
-
Crowdsourcing results unsatisfactory
-
Manual disambiguation in lab?
-
-
POS-Tagging
-
Unfixed:
-
POS-tags for loans (Malay, non-Mandarin Chinese)
-
-
Systematic error
-
Breaking up the sentences limits context scope for POS-tagger
-
Words on the margin may not be tagged accurately
-
POS-ambiguous words are more likely to receive the wrong tag
-
-
Stuttering (partial repetition), especially at code-switching boundaries, produces half-words whose POS tags might be noisy
-
POS-Tagging
-
Unfixed:
-
POS-tags for loans (Malay, non-Mandarin Chinese)
-
-
Systematic error
-
Breaking up the sentences limits context scope for POS-tagger
-
Words on the margin may not be tagged accurately
-
POS-ambiguous words are more likely to receive the wrong tag
-
-
Stuttering (partial repetition), especially at code-switching boundaries, produces half-words whose POS tags might be noisy
-
We will like (*VERB) 去 (go to) 一个 人 (someone’s) 家里 (home).
POS-Tagging
-
Unfixed:
-
POS-tags for loans (Malay, non-Mandarin Chinese)
-
-
Systematic error
-
Breaking up the sentences limits context scope for POS-tagger
-
Words on the margin may not be tagged accurately
-
POS-ambiguous words are more likely to receive the wrong tag
-
-
Stuttering (partial repetition), especially at code-switching boundaries, produces half-words whose POS tags might be noisy
-
We will like (*VERB) 去 (go to) 一个 人 (someone’s) 家里 (home).
我 (I) 做 了 (did) 一点点 (a little) lit (*VERB) literature (NOUN) review ah
Language ID
-
Chinese and English character sets are mutually exclusive
-
Outstanding cases:
-
discourse particles (solved)
-
uncaught loans from Malay and non-Mandarin Chinese
-
The dictionary method
-
-
Future: from lexical to syntactical
- Possible next steps:
-
Parsing?
- Structure of colloquial speech tends to be flat
-
Semantic role labelling?
- Current semantic role labelling tools are monolingual and rely on parsing information
- Translate-label-replace trick?
-
Parsing?
Future: from lexical to syntactical
- Possible next steps:
-
Parsing?
- Structure of colloquial speech tends to be flat
-
Semantic role labelling?
- Current semantic role labelling tools are monolingual and rely on parsing information
- Translate-label-replace trick?
-
Parsing?
Future: from lexical to syntactical
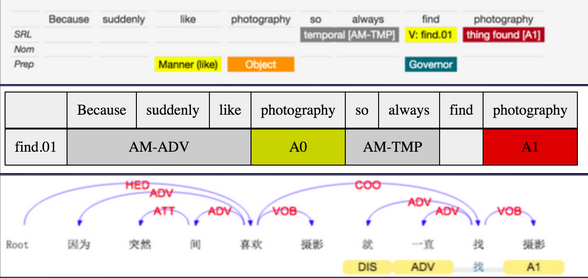
因为 突然间 喜欢 photography 就 一直 找 photography [loh]
--- Because suddenly like photography, so always find photography []
--- 因为 突然间 喜欢 摄影 就 一直 找 摄影 []
Future: from lexical to syntactical
-
But nevertheless 我 有 learn 了 另外 一 种 technique
-
But nevertheless I have learn [] another one kind technique
- 但是 但是 我 有 学 了 另外 一 种 技巧
-

Future
- From lexical to syntactical...
- Possible next steps:
-
Parsing?
- Structure of colloquial tends to be flat
-
Semantic role labelling?
- Current semantic role labelling tools are monolingual and rely on parsing information
-
Translate-label-replace trick?
- "Alternation" idea: there is a "basic structure", which is either Chinese or English.
- If basic structure is English, then word-translate Chinese parts to English, and use English semantic parser. Vice versa.
-
Criterion: verb? (Basic syntax is English if most VERBs are English; vice versa)
-
Parsing?
Thank you!

code-switching
By Bingyan Hu
code-switching
code-switching



