Hyperparameter optimization using
Bayesian optimization on transfer learning for medical image classification

Rune Johan Borgli
Outline
Motivation
Methodology
Experiments
Conclusion
Introduction
Introduction
Start
Finish
Introduction
Hyperparameter optimization
Short overview of the presentation
Bayesian optimization
Transfer learning
Medical image classification

Short overview of the presentation
Deep convolutional neural networks (CNNs)
Transfer Learning
+
Solve the problem of generalization in small datasets
Transfer learning has many hyperparameters.
We want to explore automatic hyperparameter optimization of these hyperparameters.
Our use case is datasets of gastroenterological observations.
Research questions
Can hyperparameters for transfer learning be optimized automatically? If so, how does it influence the performance and what should be optimized?
How should a system be build that automatically can fulfill the task of automated hyperparameter optimization for transfer learning?
Question one:
Question two:
motivation
Start
Finish
Introduction
Motivation
Use Case: Gastroenterology

gastroenterology
The gastrointestinal (GI) tract is prone to many different diseases
Doctors use sensor and image data to diagnose
The procedure's success is heavily dependent on the doctor
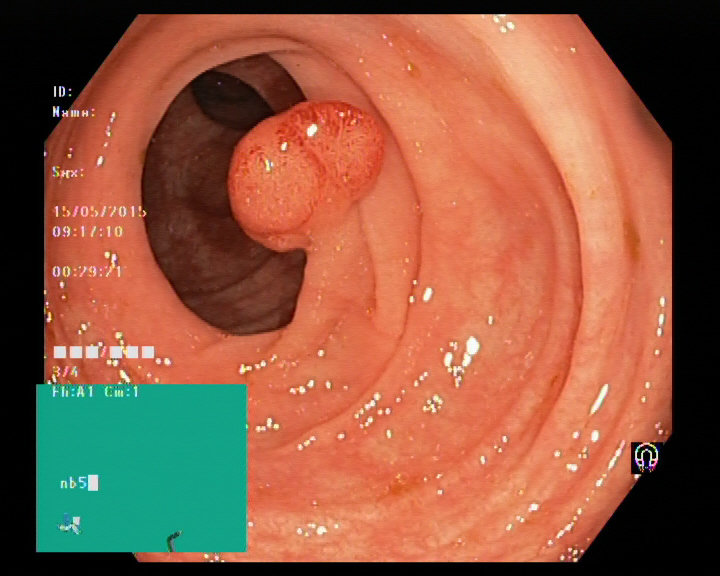
Image of a polyp from a colonoscopy
Gastroscopy and colonoscopy
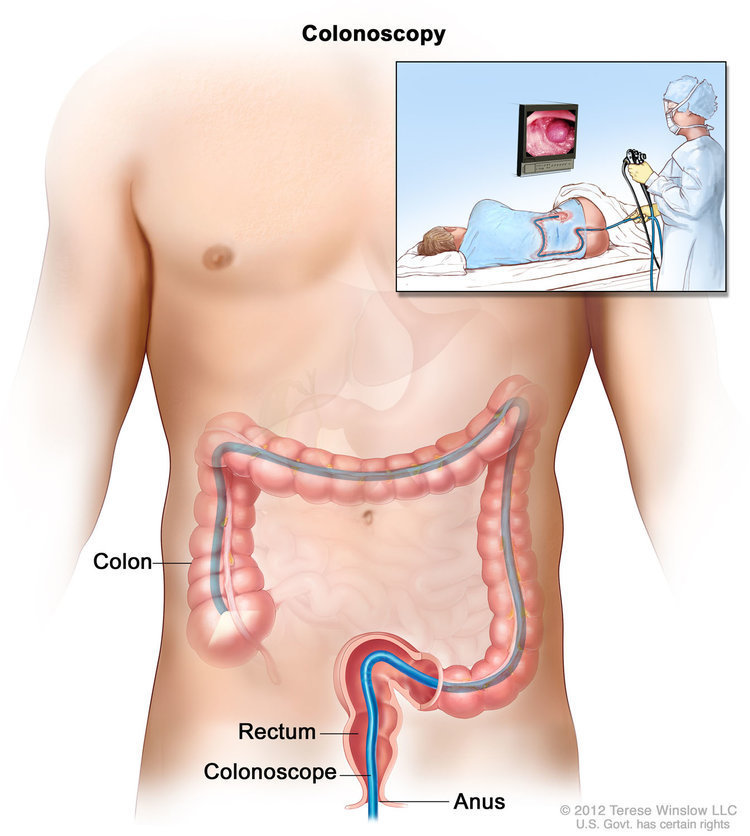

We can use this data to train machine learning algorithms
Not so simple...
Datasets for medical images are small
This makes them hard to generalize and they will often overfit on the dataset
Transfer learning is a solution!
What is transfer learning?

CNN
CNN
SUCCESS
Imagenet
Kvasir
Transfer learning is useful
It helps with overfitting
It is much faster to train
It can obtain the same or better results as a CNN trained from scratch
Transfer learning has a special hyperparameter
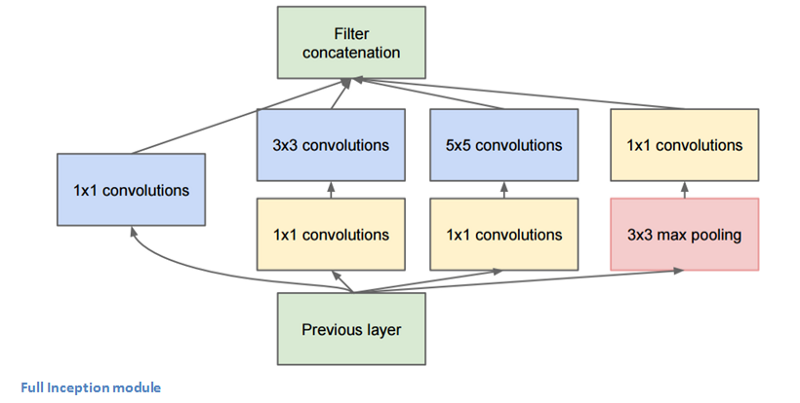
Transfer learning has a special hyperparameter
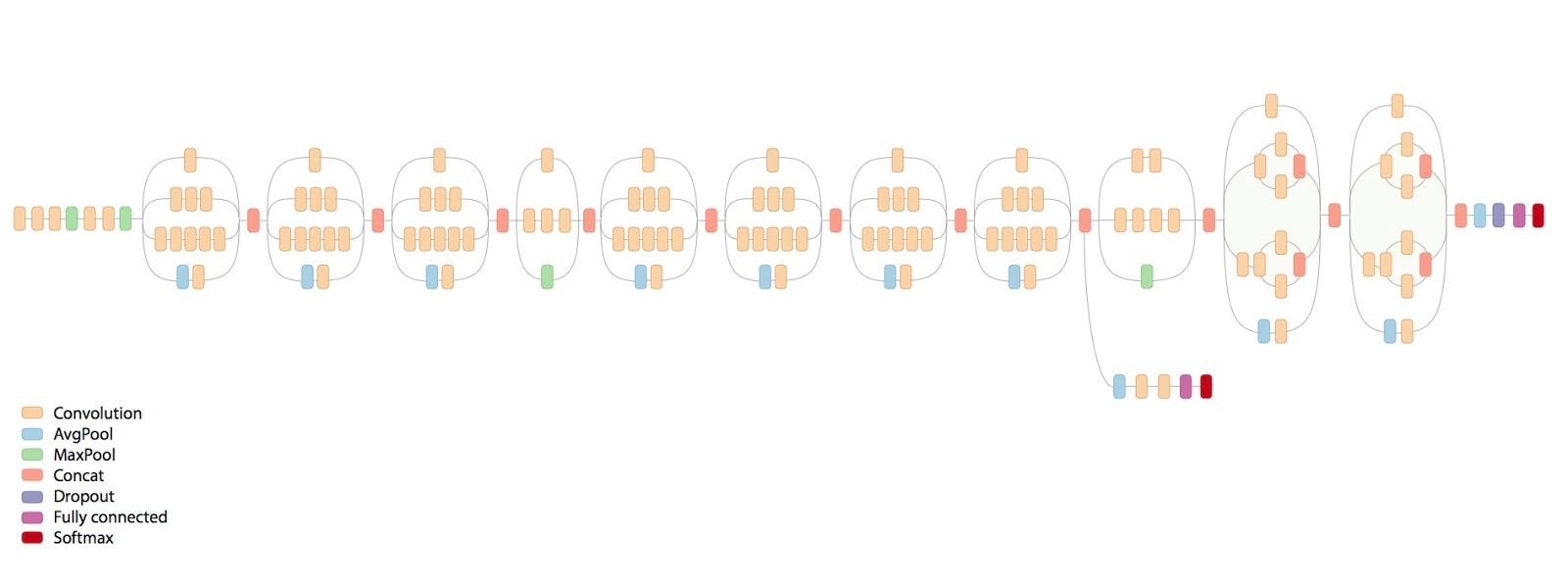
Inception v3:
Transfer learning has a special hyperparameter
THE DELIMIting layer is a hyperparameter
We want to optimize this automatically
Bayesian Optimization
-
Sequential
-
Used on black-box functions
-
Uses standard Gaussian process for creating a surrogate model
-
Uses expected improvement for the Aquisition function
Bayesian Optimization

Summary
In the medical field of Gastroenterology equipment for visualization of the gastrointestinal tract is used for diagnosis
The doctor's detection rate during examinations are heavily dependent on their experience and state-of-mind.
The generated data can be used with deep convolutional neural network models for assisting doctors by automatically detecting abnormalities and diseases.
The generated data can be used with deep convolutional neural network models for assisting doctors by automatically detecting abnormalities and diseases.
Summary
Annotated data for training is difficult to obtain, leading to small datasets.
CNNs are hard to train on small datasets from scratch as they tend to overfit.
Transfer learning is a solution. The technique revolves around transferring knowledge from a pre-trained model to a new task on a different domain.
When transfer learning is used, hyperparameter optimization is often ignored. We want to do automatic hyperparameter optimization.
Bayesian optimization is the method of optimization we will use.
MethodoloGy
Start
Finish
Introduction
Motivation
Methodology
The Kvasir Dataset
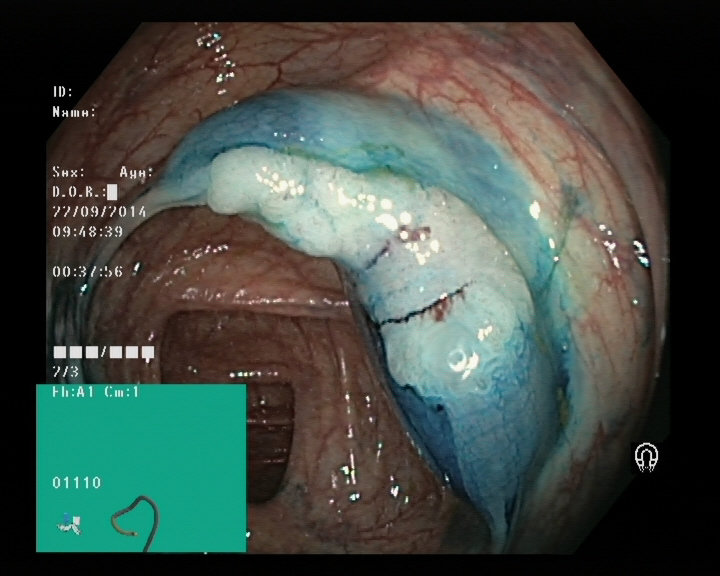
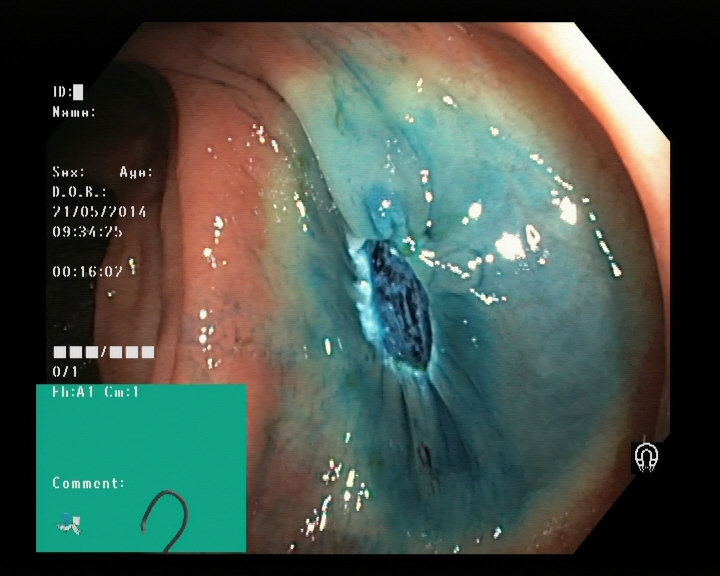
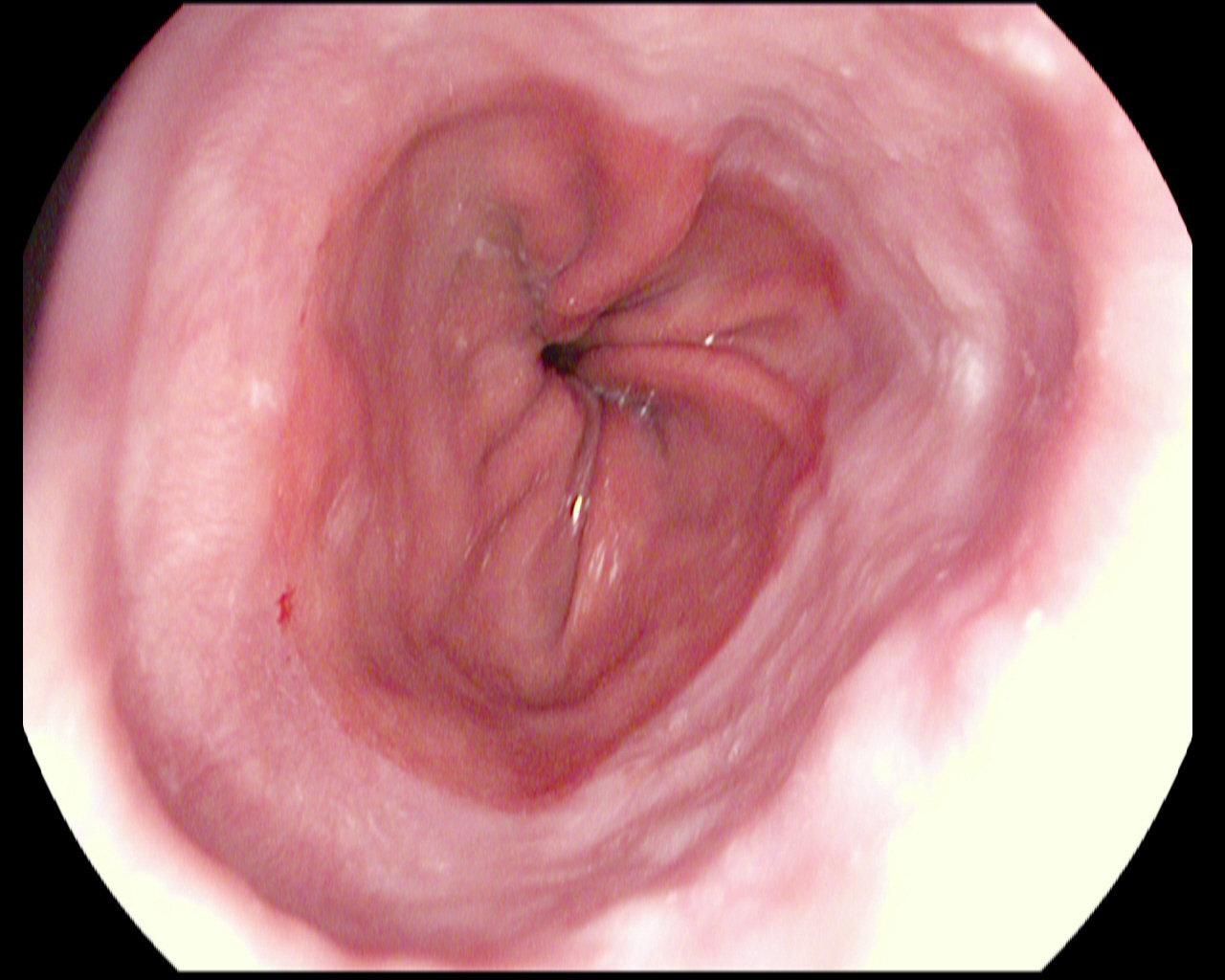
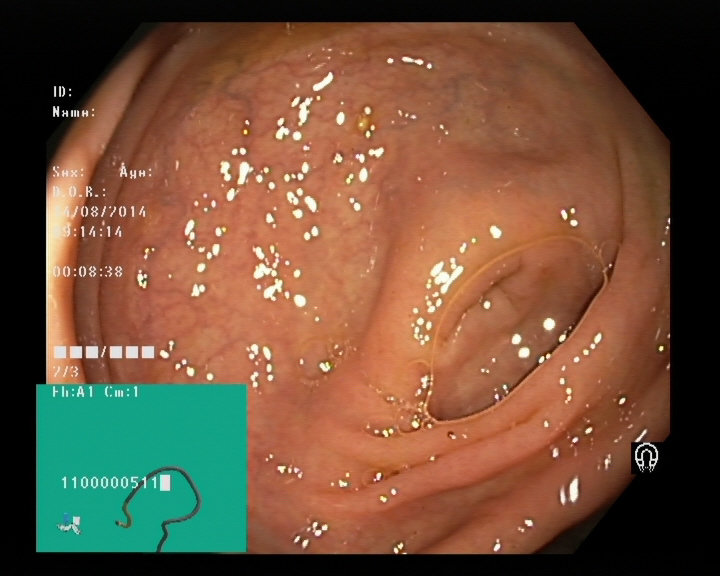
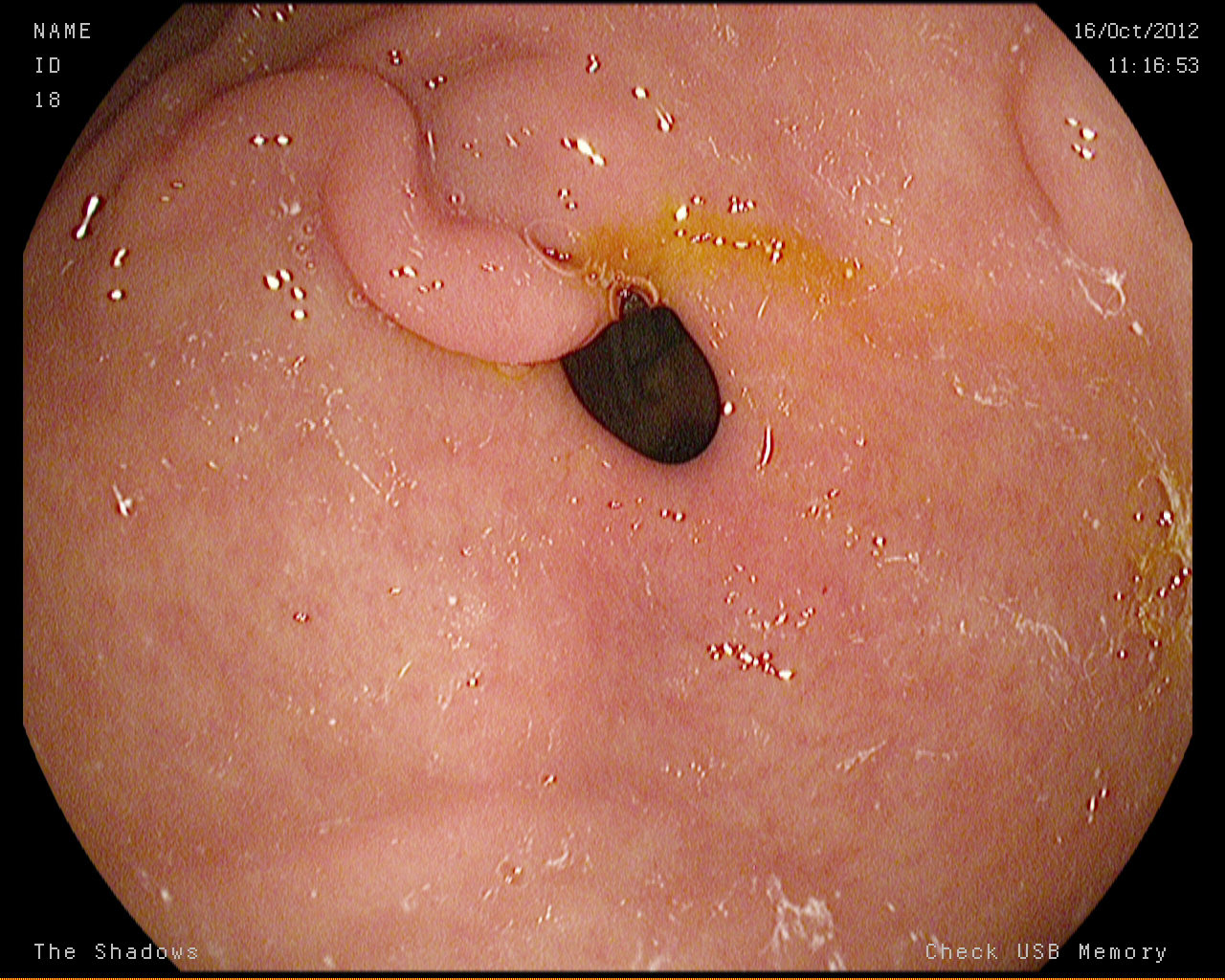
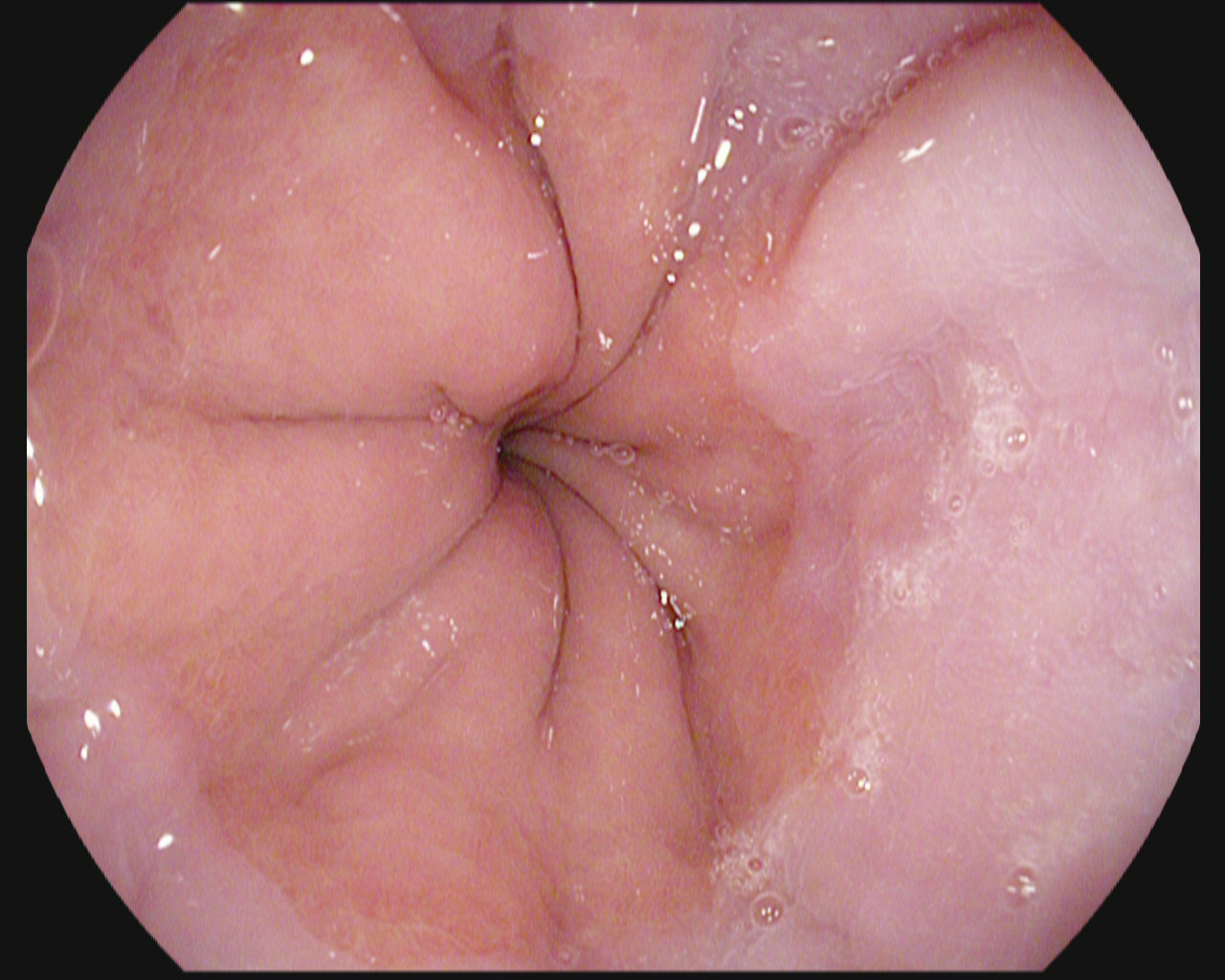


Dyed lifted polyps
Dyed resection margins
Polyps
Ulcerative colitis
Normal cecum
Esophagitis
Normal z-line
Normal pylorus
The Nerthus Dataset
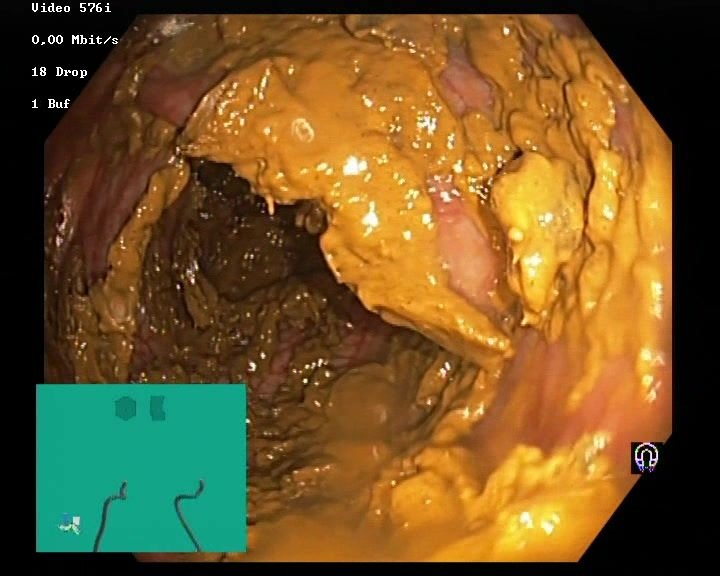
BBPS 3
BBPS 2
BBPS 1
BBPS 0
Hyperparameters
- The pre-trained model to use
- Learning rate
- The CNN optimizer
- The delimiting layer
Hyperparameters
MODELS
- Xception
- VGG16
- VGG19
- ResNet50
- InceptionV3
- InceptionResNetV2
- DenseNet121
- DenseNet169
- DenseNet201
Optimizers:
- Nadam
- SGD
- RMSprop
- Adagrad
- Adam
- Adamax
- Adadelta
Learning Rate:
Continuous from 1 to 10-4
Delimiting Layer:
Any layer from the first layer to the last layer of the model
The transfer learning method
Three steps:
1. We remove the classification block of the pre-trained model and replace it with a classification block set for the number of classes in our dataset.
The block is then trained.
2. We select a default delimiting layer of 2/3rds of the model length.
All layers after the selected layer then is trained.
3. We do step 2 again, but only optimizing the delimiting layer.
All layers after the selected layer then is trained.
Optimization Strategies
The shared hyperparameters optimization strategy
The Separate hyperparameters optimization strategy
The Separate optimizations optimization strategy
our Proposed system
Built on Keras with TensorFlow backend
Runs experiments on given datasets automatically
Results are written after each optimization run




Nonconvergence filtering
Experiments
Start
Finish
Introduction
Motivation
Methodology
Experiments
Design of Experiments
We split the dataset into 70% training data and 30% validation data
We remove the classification block of a CNN model pre-trained on ImageNet available from Keras, and replace it with a pooling layer and a softmax classification layer for the amount of classes in our dataset
We train the new classification block on the dataset
Part 1:
Hyperparameters are chosen by the optimizer
Design of Experiments
We tune all layers after the delimiting layer on the dataset
The delimiting layer is default 2/3rd of all layers and not chosen by the optimizer
PART 3:
Part 2:
Hyperparameters are chosen by the optimizer
Train again with the best hyperparameters from part 2
This time the optimizer chooses the best delimiting layer

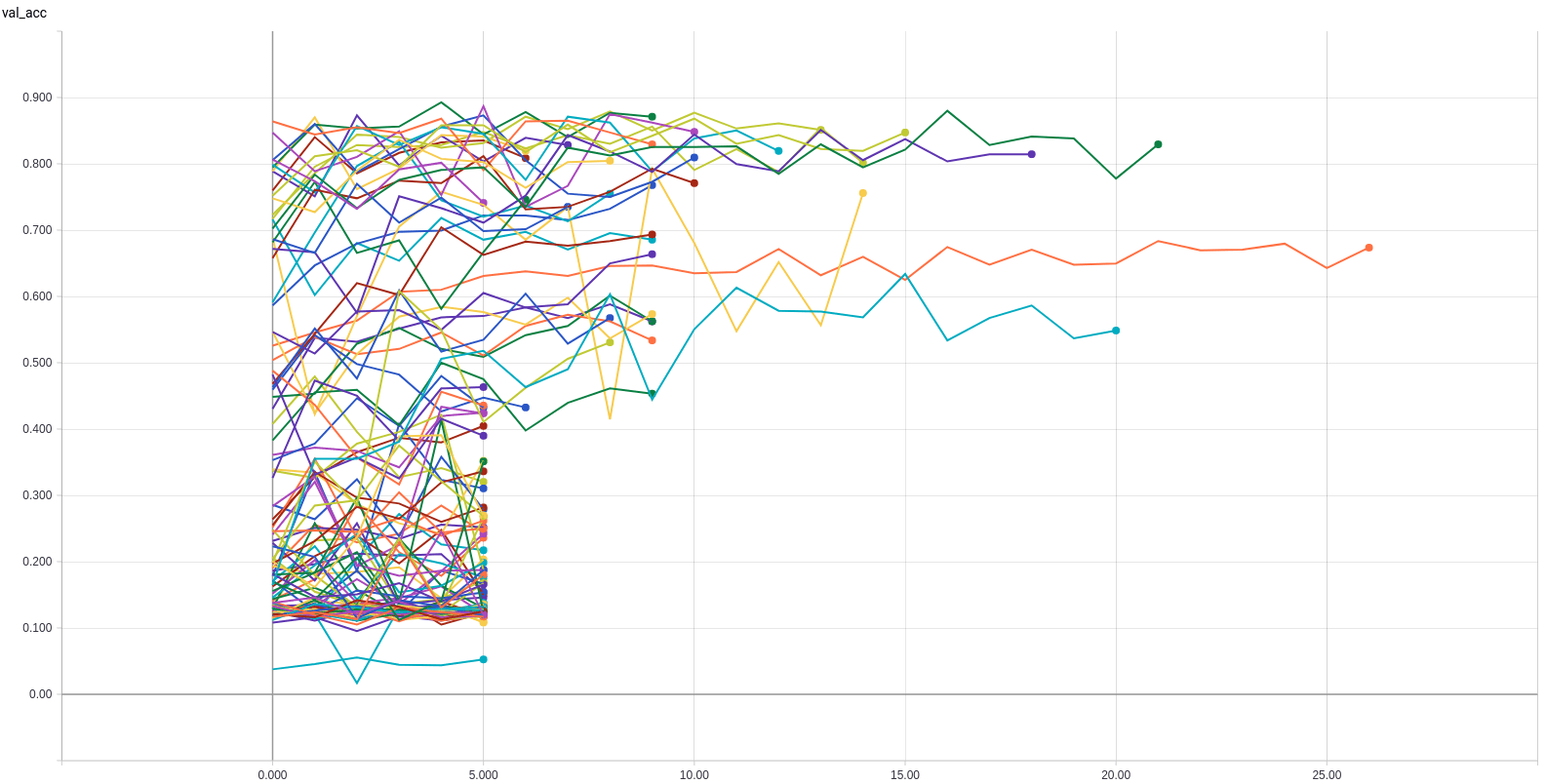
Example of optimization run
REsults from THe Kvasir dataset
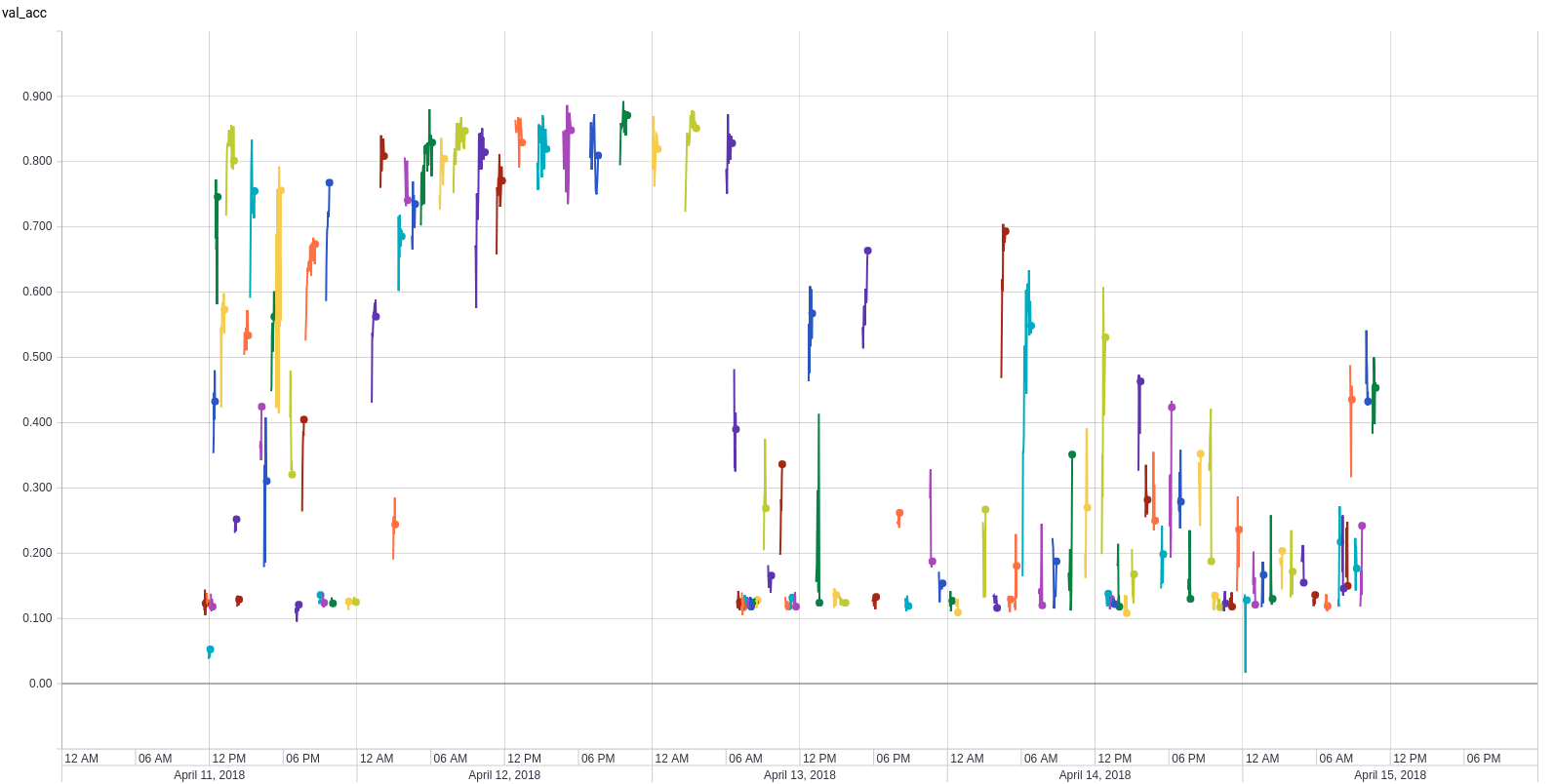
Shared hyperparameters
Separate hyperparameters
Separate optimizations
Model
Layer
Layer
Tuning
Block
Layer
Model
REsults from THe Kvasir dataset
Nonconvergence filtering
Competitive results

Shared Hyperparameter Optimization
Model optimization
Layer optimization
Shared Hyperparameter Optimization
Nonconvergence filtering
Competitive results
Layer optimization
Best Trained model

- Model: InceptionResNetV2
- Optimizer: Adadelta
- Learning rate: 0.8417
- Delimiting layer: 136/782
Similarities between classes
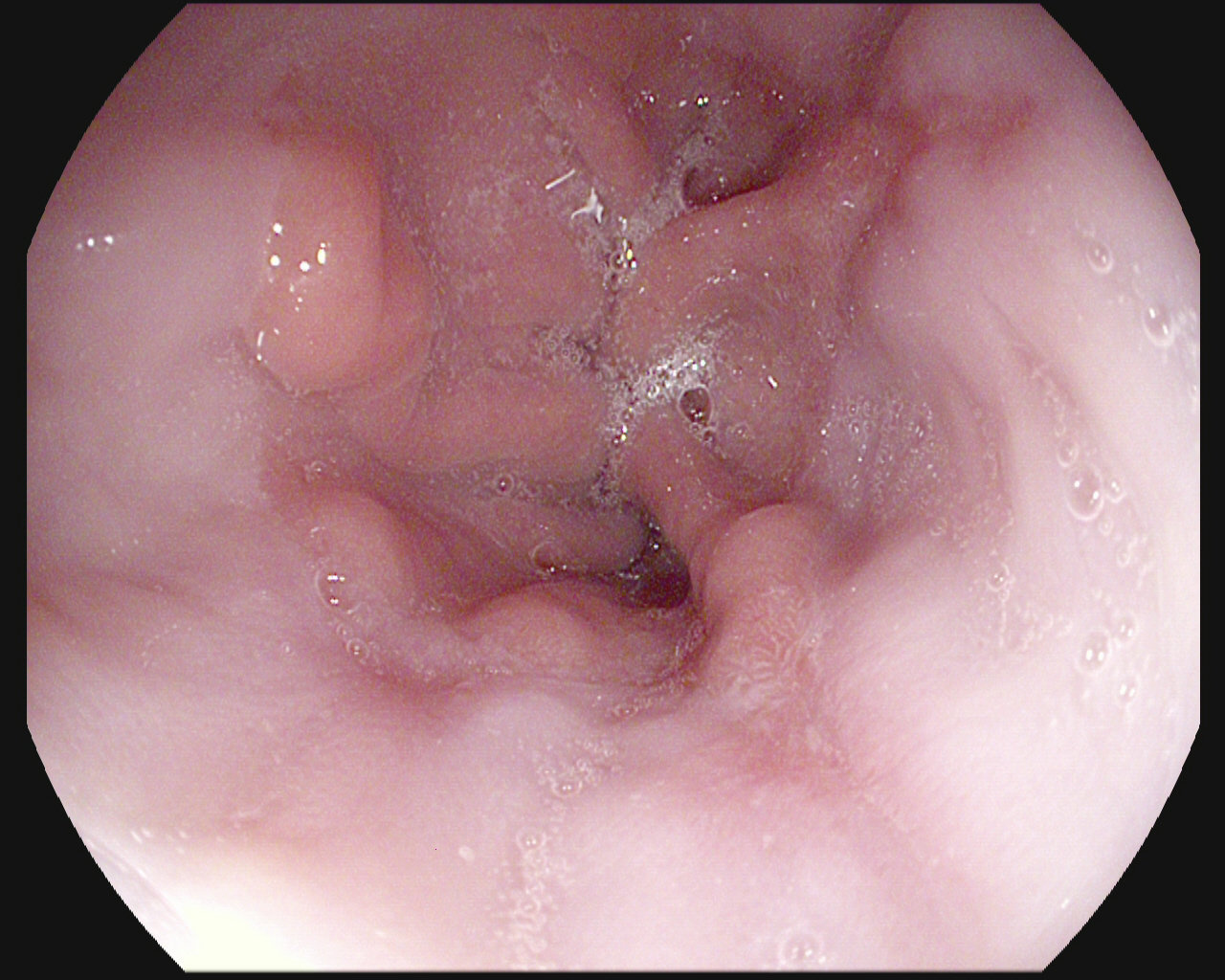
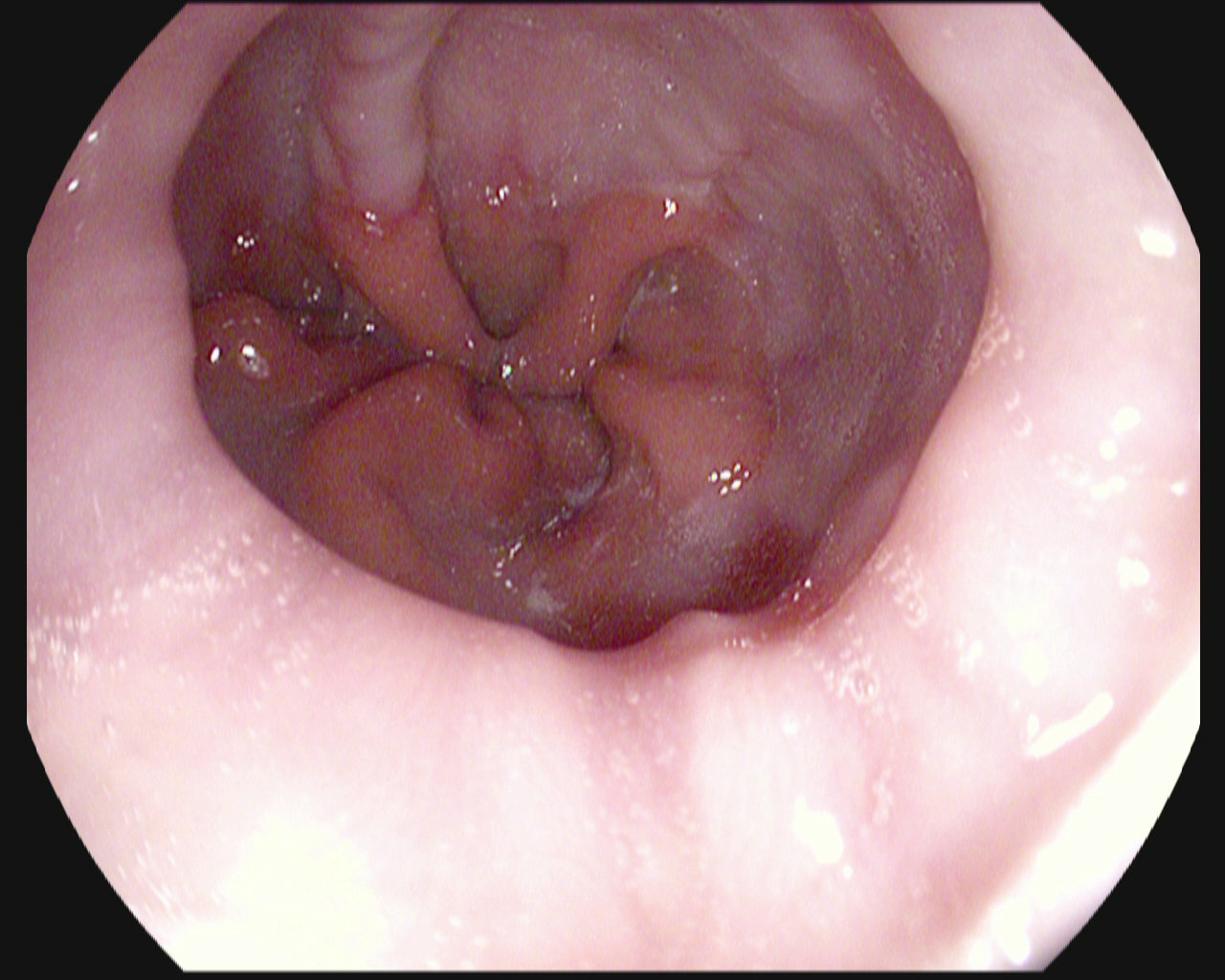
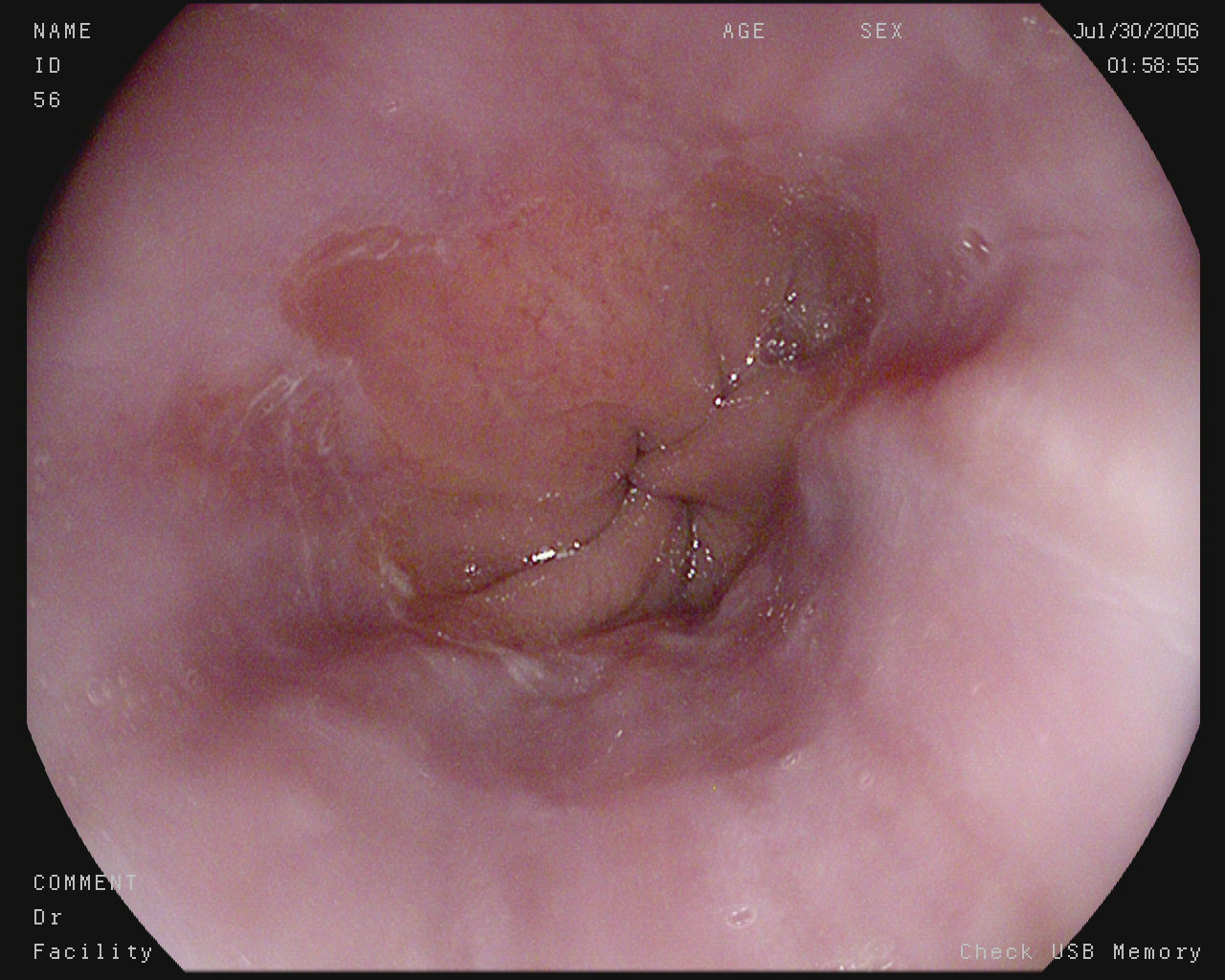
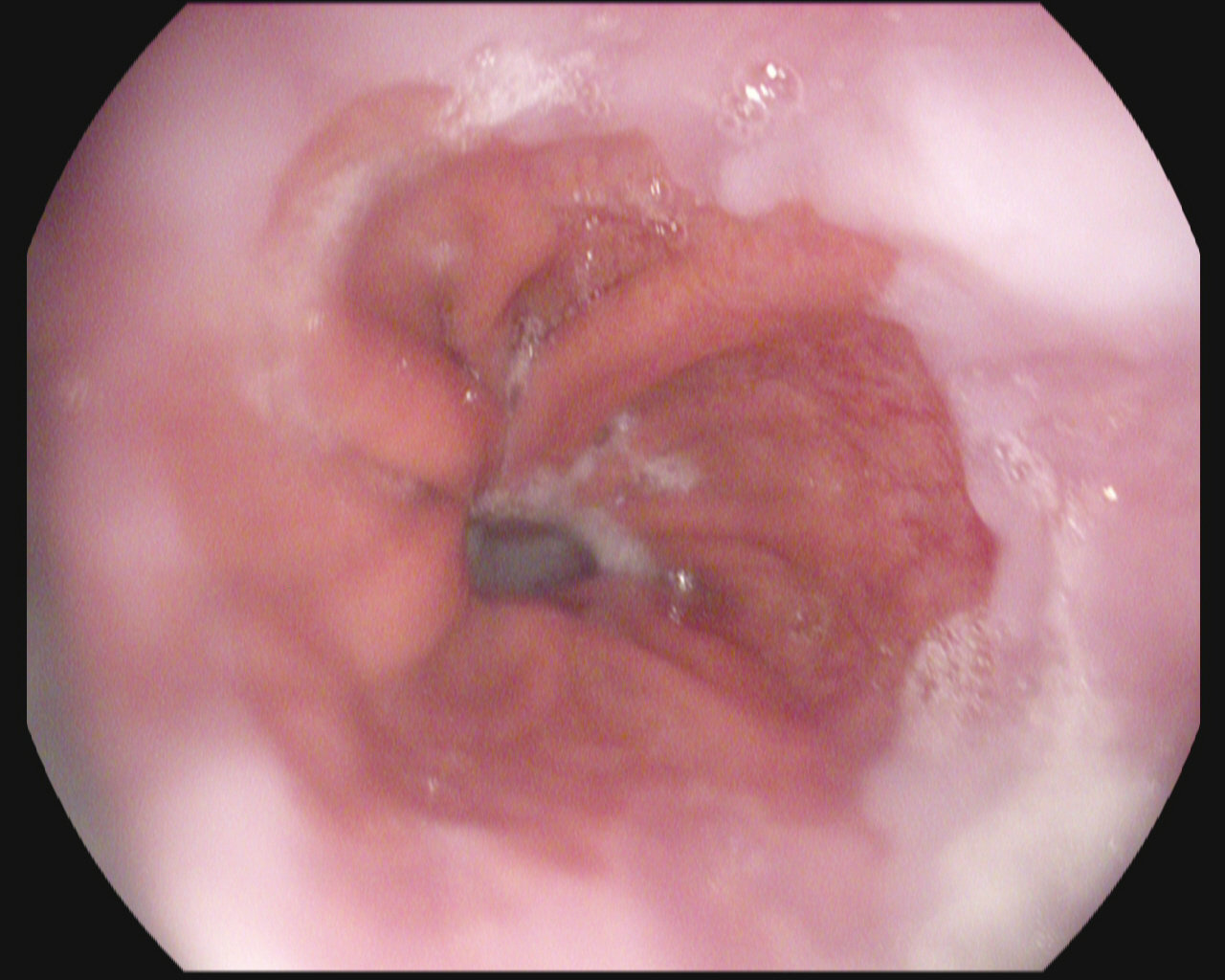
Esophagitis
Normal z-line
Comparison to baseline
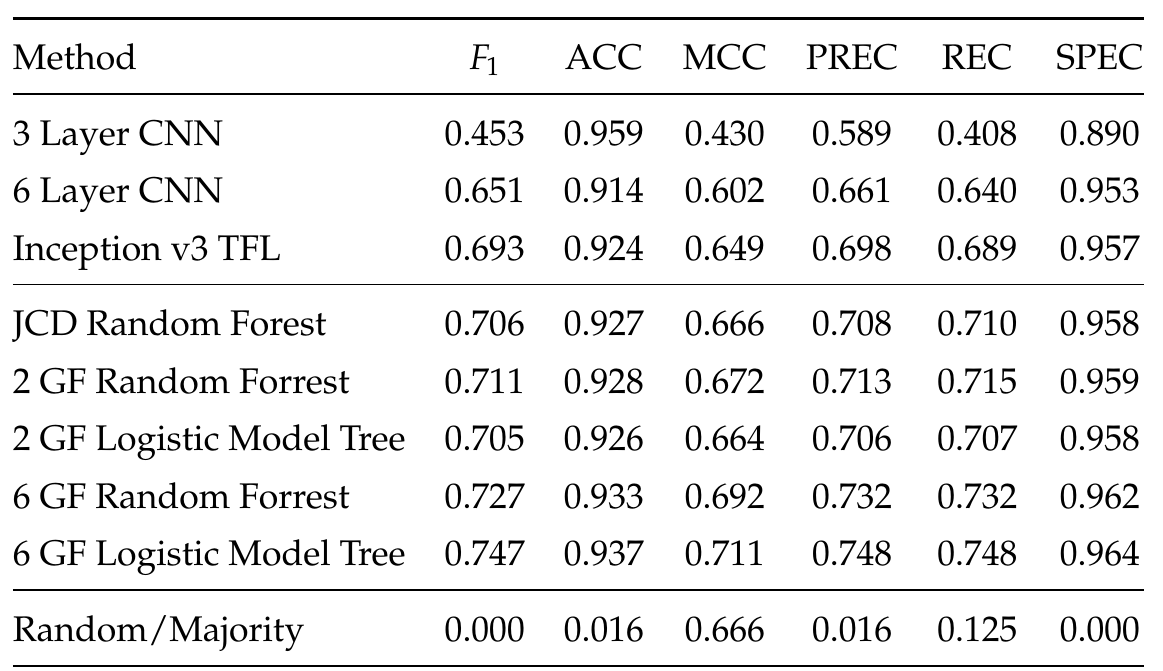
0.88
0.97
0.87
0.91
0.89
0.98
Our results
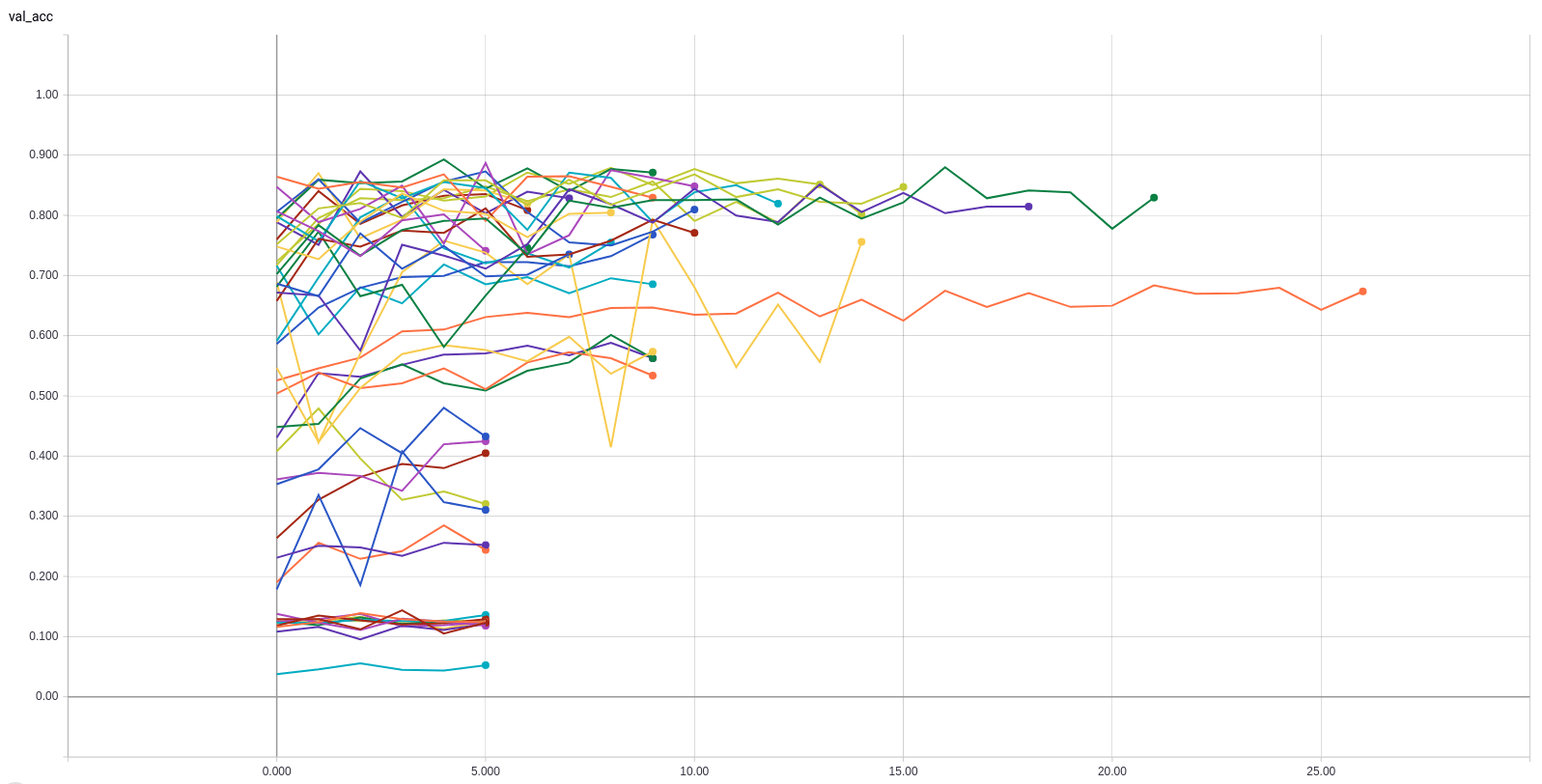
REsults From the Nerthus dataset
Shared hyperparameters
Separate hyperparameters
Separate optimizations
Model
Layer
Layer
Tuning
Block
Layer
Model
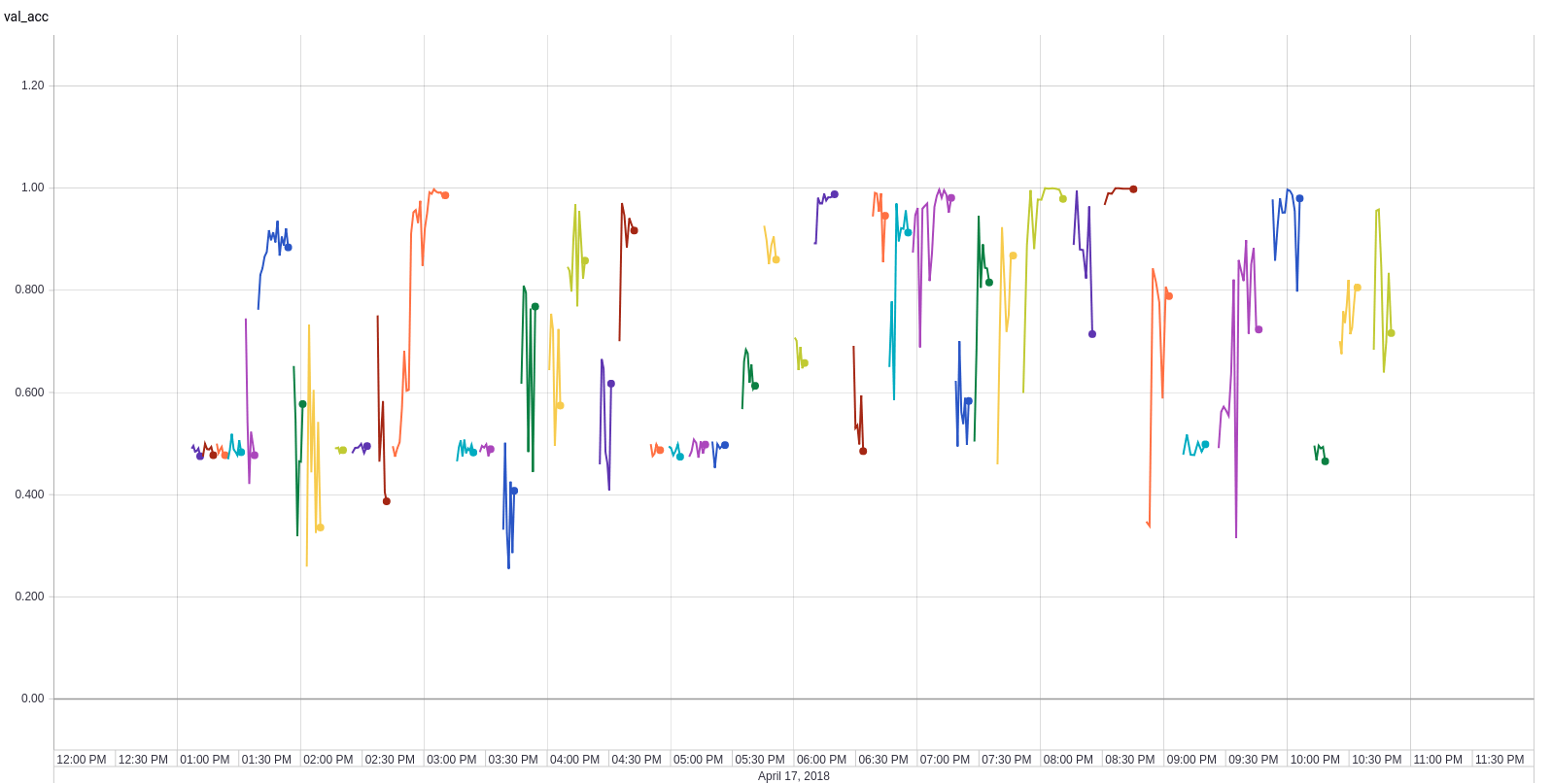
Shared Hyperparameter Optimization
Model optimization
Layer optimization
REsults From the Nerthus dataset

Nonconvergence filtering
Competitive results
Runs failing to converge
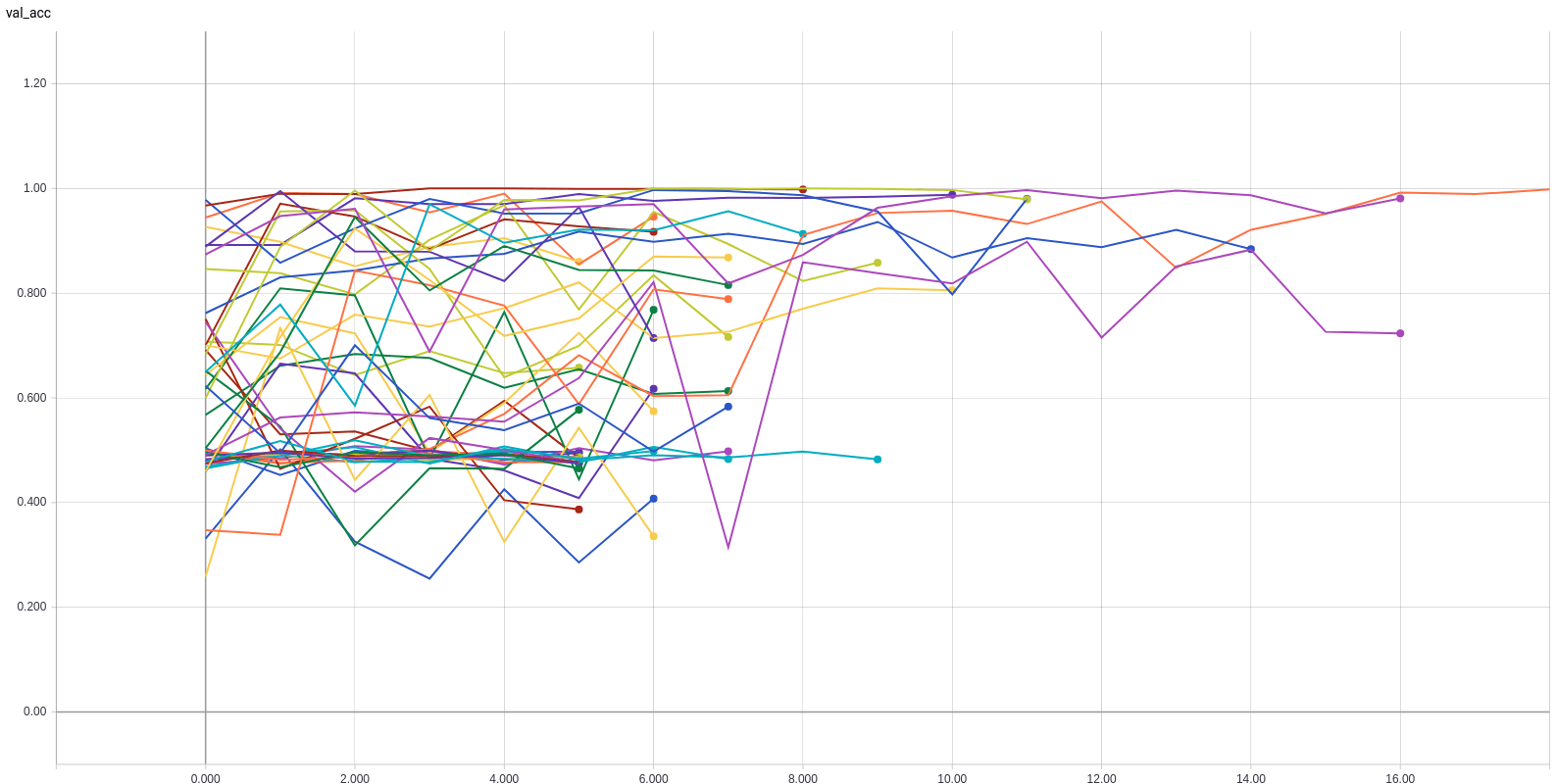
Shared Hyperparameter Optimization
Competitive results
Runs failing to converge

Layer optimization
Best Trained model

- Model: Xception
- Optimizer: SGD
- Learning rate: 0.5495
- Delimiting layer: 0/134
Comparison to baseline
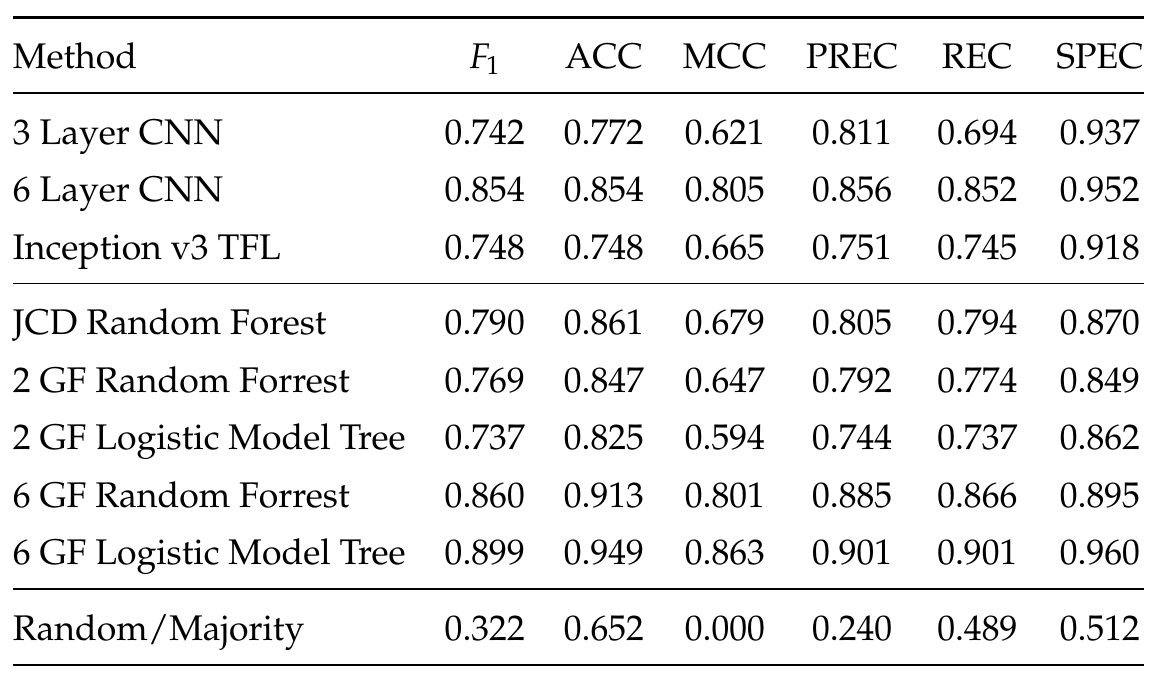
1.00
1.00
1.00
1.00
1.00
1.00
Our results
Conclusion
Start
Finish
Introduction
Motivation
Methodology
Experiments
Conclusion
The research questions
Can hyperparameters for transfer learning be optimized automatically? If so, how does it influence the performance and what should be optimized?
Yes! The performance for both results increase performance of about 10 percent. The hyperparameters we chose are important, but the flaw uncovered should be avoided in future work.
Question one:
Answer:
The research questions
How should a system be build that automatically can fulfill the task of automated hyperparameter optimization for transfer learning?
Using Bayesian optimization we proposed a system for automatic hyperparameter optimization for given datasets using three different hyperparameter optimization strategies.
Question Two:
Answer:
Conclusion
Automatic hyperparameter optimization is an effective stategy for increasing performance in transfer learning use cases
Adjusting the delimiting layer reveals layers that are nontrivial to select manually
We show the usefulness of automatic hyperparameter optimization and present a system capable of running optimizations on present transfer learning solutions
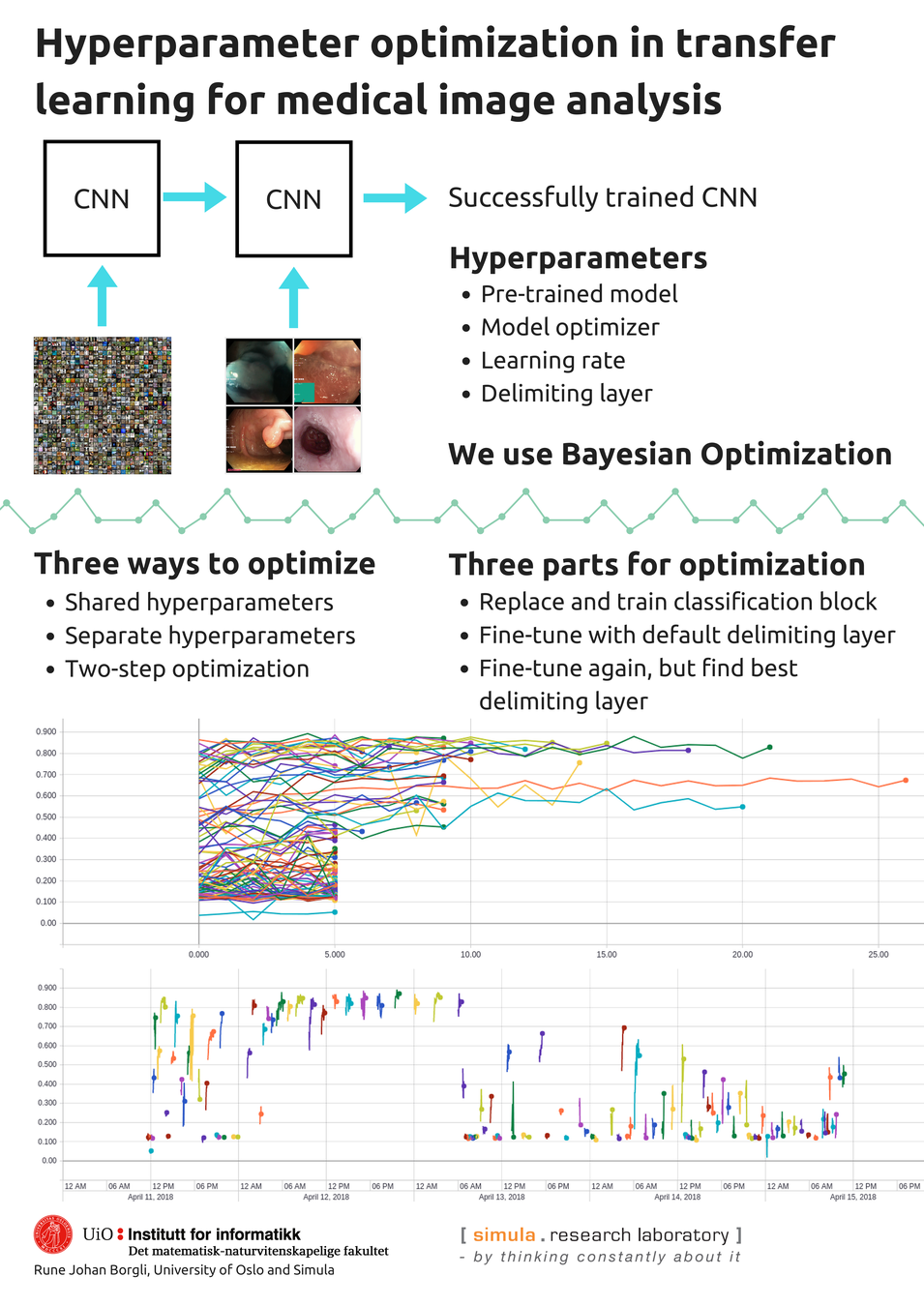
Best poster award
A 3-minute lightning talk was held and a poster presented at Autonomy Day 2018 about the work from the thesis
The poster won the best poster award at the event
Future Work
Try other optimizations methods
Optimize the Bayesian optimization
Remove the dependency between the pre-trained model and the delimiting layer
Try other hyperparameters
END
Start
Finish
Introduction
Motivation
Methodology
Experiments
Conclusion
Thank you
No questions please!
Hyperparameter optimization in transfer learning for medical image analysis
By Hanna Borgli
Hyperparameter optimization in transfer learning for medical image analysis
There are different approaches to automatically optimize the hyperparameter configuration. One such solution, also implemented by Google in their cloud engine using Google Vizier, is Bayesian optimization. This is a sequential design strategy for global optimization of black-box functions. Other solutions are grid search, random search, and Hyperband. In this presentation, we will use a framework for Bayesian optimization for tuning the hyperparameters of image object classification models available in Keras being trained with transfer learning on a dataset of medical images of the GI tract.



