Parallel implementation of Particle-Mesh mapping using CUDA enabled GPU
@brijesh68kumar
Git hub : bit.ly/brijesh_gpu_git
Slides : bit.ly/slide_gpu_indicon2015
A little about me
- ICT graduate, class of 2015
- Past IAS IEEE chair sb DAIICT Guj | Mercedes Benz
- Now SRF at NGO | IEEE YP
- @brijesh68kumar| github.com/brijesh68kumar
- Community growing (sponsors, speakers)
- Previous
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
Introduction
Do you like series/manga
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar



Download
How


http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
⬇ CPU ⬇ GPU
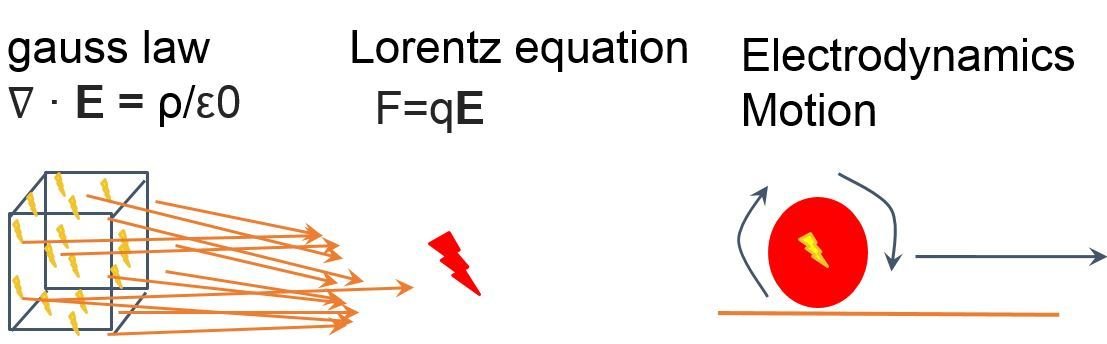
Particle mesh mapping
Application
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
Machine
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
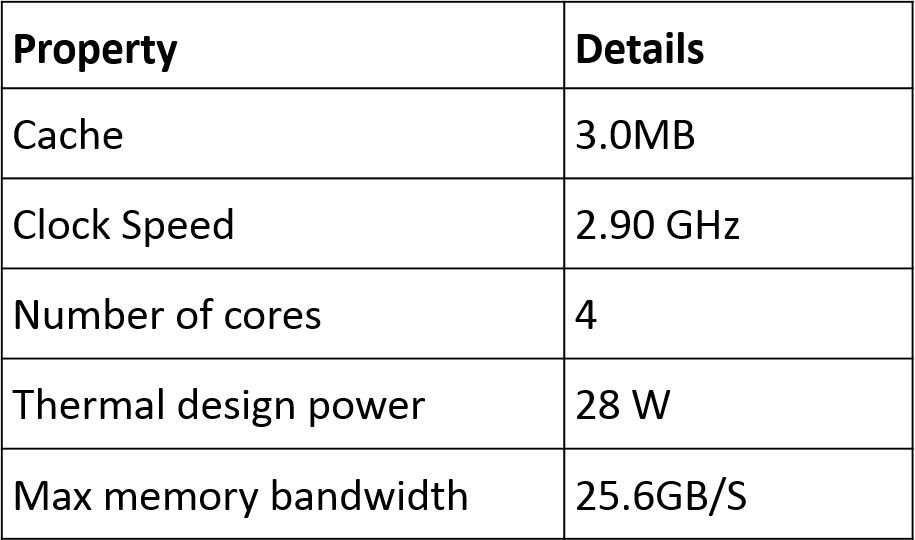


GPU accelerated computing
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
Application code
Rest of
sequential
cpu code
CPU
GPU
computer intensive
5%
of code
// Algorithm to launch the kernel from CPU
Int main()
{
Variable hostGrid, hostParticle;
Variable deviceGrid, deviceParticle;
// initialize host variable using Algorithm 1.
cudaMalloc(device variable space in GPU);
cudaMemcpy( host to device );
// define block dimension
Dim3 bD; //block dimension;
Dim3 gD; //grid dimension;
// bD x gD = total number of particles;
Launch kernel<< bD, gD>>(parameters);
cudaMemcpy(from device to host);
Store data into file;
Free memory;
}Architecture
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
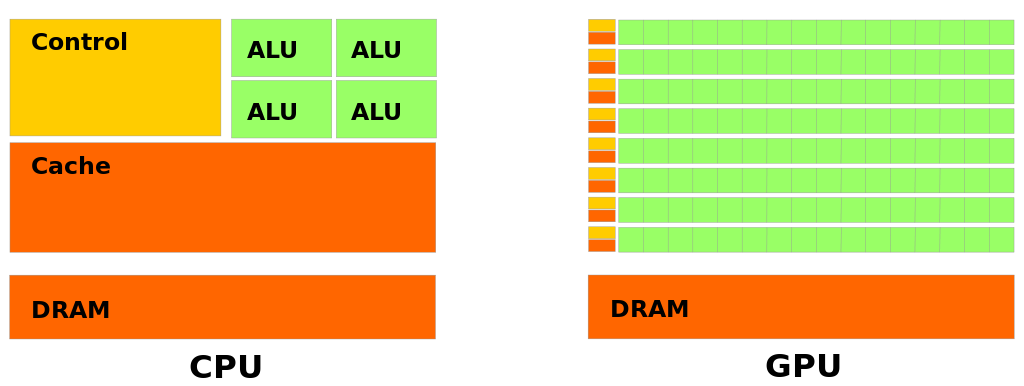
Latency oriented approach
Throughput oriented approach
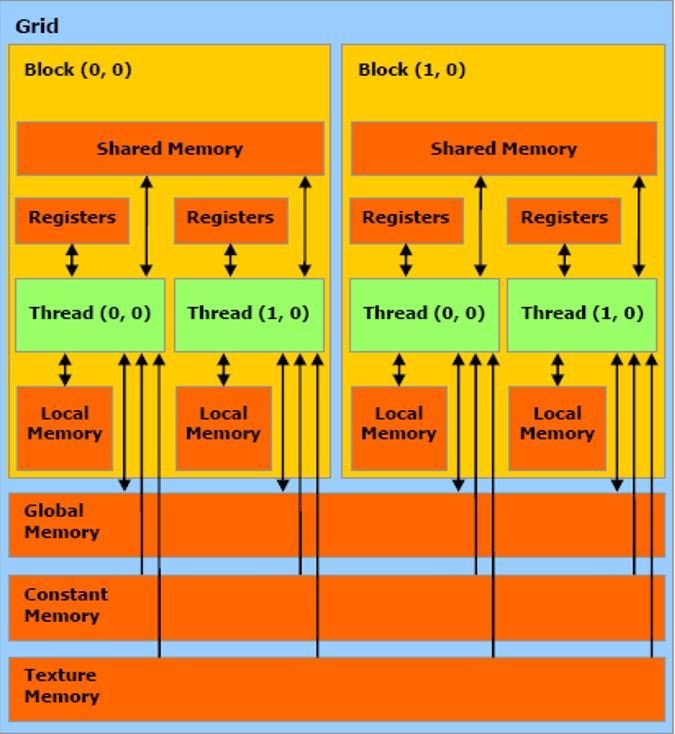
Algorithum
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
- Issues
-
Debugging
-
Functions
-
- Collision
- Thread Synchronization
Code
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <sys/time.h>
#include "time.h"
int main(int argc, char *argv[])
{
//--------------------Declaring Variables-------------------------
int max = 1024, i, j , lp;
int top, bottom, left, right;
float net[1024][1024];
float x, y, fL, fR, fB, fT;
unsigned int par=160000, loop=2000;
struct timespec start, stop;
double t1=0, t2=0, result=0;
//----------------------------------------------------------------
//------------------calculate Starting time-----------------------
clock_gettime(CLOCK_REALTIME,&start);
t1 = start. tv_sec + (start. tv_nsec/pow(10, 9));
//----------------------------------------------------------------
//------------------Initialising grid-----------------------------
for (i=0; i<max; i++)
for (j =0; j <max; j ++)
net[i][j ]=0;
//----------------------------------------------------------------
//------------------ Mapping--------------------------------------
for (lp=1; lp<loop; lp++){
for ( i = 0; i < par; ++i){
//---Random position to particle---
x = ((float) rand()/(float)(RAND_MAX) * (float) max);
y = ((float) rand()/(float)(RAND_MAX) * (float) max);
//___finding coordinate around particle___
left = (int) floor(x);
right = left + 1;
bottom = (int) floor(y);
top = bottom +1;
//___Checking boundary conditions___
if (top>=max|| bottom>=max|| left>=max|| right>=max)
continue;
//___Finding particle position within box___
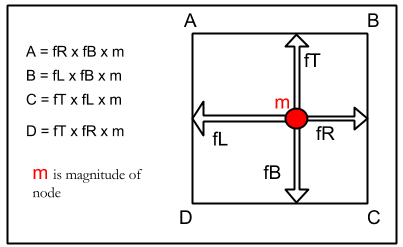
fL = x - left;
fR = 1 - fL;
fB = y - bottom;
fT = 1 - fB;
//___calculating contribution___
net[left][bottom] = net[left][bottom] +( fT * fR ) ;
net[right][bottom] = net[right][bottom] +( fT * fL ) ;
net[left][top] = net[left][top] +( fB * fR ) ;
net[right][top] = net[right][top] +( fB * fL ) ;
}
}
//----------------------------------------------------------------
//------------------calculate End time----------------------------
clock_gettime(CLOCK_REALTIME,&stop);
t2 = stop. tv_sec + (stop. tv_nsec/pow(10, 9));
//----------------------------------------------------------------
//----------------calculating processing time---------------------
result = t2 - t1 ;
printf("its done in :\t%lf s\n", result);
//----------------------------------------------------------------
//--------------- Saving result in file---------------------------
//___Opening file___
FILE *f = fopen("file1.txt", "w");
par*=loop;
if (f == NULL){
printf("Error opening file!\n");
exit(1);
}
//___Normalizing result___
float avg= par/(max*max);
for ( i = 0; i < max; ++i){
for ( j = 0; j < max; j ++){
fprintf (f, "%f ,",((net[i][j ])/avg));
}
fprintf (f, "\n" );
}
//___Closing file___
fclose(f);
//------------------------------------------------------------
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <iostream>
#include <sys/time.h>
#include "time.h"
using namespace std;
__global__ void parMap(float *pD, float *netD, int grid)
{
unsigned int rID= blockDim.x*blockIdx. x+threadIdx. x;
int left, right, top, bottom;
float x, y, fL, fR, fB, fT;
x = pD[rID*2];
y = pD[rID*2+1];
left = (int) floorf(x);
right = left + 1;
bottom = (int) floorf(y);
top = bottom +1;
if (left>= grid|| right>= grid|| top>= grid|| bottom>= grid){
left=0;
right=1;
top=1;
bottom = 0;
x=0.500000;
y=0.500000;
}
fL = x - left;
fR = 1 - fL;
fB = y - bottom;
fT = 1 - fB;
netD[grid*left + bottom] = netD[grid*left + bottom] +(fT*fR);
netD[grid*right + bottom] = netD[grid*right + bottom]+(fT*fL);
netD[grid*left+ top] = netD[grid*left + top] +(fB*fR);
netD[grid*right+ top] = netD[grid*right + top] +(fB*fL);
}
int main(int argc, char *argv[])
{
//--------------------Declaring Variables-------------------------
int grid = 1024, i, j , lp=1, max = grid, sizeGrid= grid*grid;
unsigned int par = 160000, loop=2000, sizePar = 2*par;
float t_i=0.0, t_mc_h2d=0.0, t_mc_d2h=0.0, t_pl=0.0, ti=0.0, tmc_h2d=0.0, tpl=0.0;
cudaEvent_t s_i, e_i, s_mc_h2d, e_mc_h2d, s_mc_d2h, e_mc_d2h, s_pl, e_pl;
float *netH, *pH, *netD, *pD;
//___Time flags___
cudaEventCreate(&s_i);
cudaEventCreate(&e_i);
cudaEventCreate(&s_mc_h2d);
cudaEventCreate(&e_mc_h2d);
cudaEventCreate(&s_mc_d2h);
cudaEventCreate(&e_mc_d2h);
cudaEventCreate(&s_pl);
cudaEventCreate(&e_pl);
//________________
//-----------------------------------------------------------------
//--------------------Declaring Variables--------------------------
//___start clock___.
cudaEventRecord(s_i, 0);
//___CPU Memory allocation___
netH = (float*) malloc(sizeof(float)*sizeGrid);
pH = (float*) malloc(sizeof(float)*sizePar);
//___________________________
//___initializing grid___
for(i=0; i< grid; i++)
for(j =0; j < grid; j ++)
netH[grid*i+j ]=0.0;
//___________________________
//___Random particle position___
for( i = 0; i < sizePar; i++)
pH[i]= ((float) rand()/(float)(RAND_MAX) * (float)(max-1));
//___________________________
cudaEventRecord( e_i, 0 );
cudaEventSynchronize( e_i );
cudaEventElapsedTime( &ti, s_i, e_i);
//___________________________
//-----------------------------------------------------------------
//--------------------GPU memory allocation for grid--------------------------
//___start clock___.
cudaEventRecord(s_mc_h2d, 0);
//___GPU memory allocation___
cudaMalloc( (void **)&netD, sizeof(float)*sizeGrid);
//___________________________
//___Data Transfer___
cudaMemcpy(netD, netH, sizeGrid*(sizeof(float)), cudaMemcpyHostToDevice);
//___________________
cudaEventRecord( e_mc_h2d, 0 );
cudaEventSynchronize( e_mc_h2d );
cudaEventElapsedTime( &tmc_h2d, s_mc_h2d, e_mc_h2d);
t_mc_h2d+=tmc_h2d; //calculating time
//___________________________
//----------------------------------------------------------------------------
for(lp=1; lp<loop; lp++)
{
cudaEventRecord(s_mc_h2d, 0);
// Allocating GPU memory And transferring data to GPU
cudaMalloc( (void **)&pD, sizeof(float)*sizePar);
cudaMemcpy( pD, pH, sizePar*(sizeof(float)), cudaMemcpyHostToDevice);
cudaEventRecord( e_mc_h2d, 0 );
cudaEventSynchronize( e_mc_h2d );
cudaEventElapsedTime( &tmc_h2d, s_mc_h2d, e_mc_h2d);
//___________________________
//___Launching threads___
cudaEventRecord( s_pl, 0 );
//___thread dimentions___
dim3 dimBlock(192);
dim3 dimGrid((par/192));
parMap<<<dimGrid, dimBlock>>>(pD, netD, grid);
//________________________________
cudaEventRecord( e_pl, 0 );
cudaEventSynchronize( e_pl );
cudaEventElapsedTime( &tpl, s_pl, e_pl);
//_______________________
//___Time keeing___
t_i+=ti;
t_mc_h2d+=tmc_h2d;
t_pl+=tpl;
}
cudaEventRecord( s_mc_d2h, 0 );
// Copy the results in GPU memory back to the CPU
cudaMemcpy(netH, netD, sizeof(float)*sizeGrid, cudaMemcpyDeviceToHost);
cudaEventRecord( e_mc_d2h, 0 );
cudaEventSynchronize( e_mc_d2h );
cudaEventElapsedTime( &t_mc_d2h, s_mc_d2h, e_mc_d2h);
FILE *f = fopen("file.txt", "w");
par*=loop;
if (f == NULL){
printf("Error opening file!\n");
exit(1);
}
float avg= par/(max*max);
for ( i = 0; i < sizeGrid; ++i){
fprintf (f, "%f ",((netH[i])/avg)) ;
if (i%grid==(grid-1))
fprintf (f, " \n" );
}
fclose(f);
printf("\n\nGrid size: \t\t%d \n particle:\t %d\n", grid, par);
printf("\nInitialisation time:\t%f \n", t_i);
printf("\nMemory Copy H 2 D:\t%f \n", t_mc_h2d);
printf("\nMemory Copy D 2 H:\t%f \n", t_mc_d2h);
printf("\nProcessing time:\t%f \n\n", t_pl);
//event destroy
cudaEventDestroy(s_i);
cudaEventDestroy(e_i);
cudaEventDestroy(s_mc_h2d);
cudaEventDestroy(e_mc_h2d);
cudaEventDestroy(s_pl);
cudaEventDestroy(e_pl);
cudaEventDestroy(s_mc_d2h);
cudaEventDestroy(e_mc_d2h);
// Free the memory
cudaFree(netD);
cudaFree(pD);
free(netH);
free(pH);
return 0;
}
Result
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
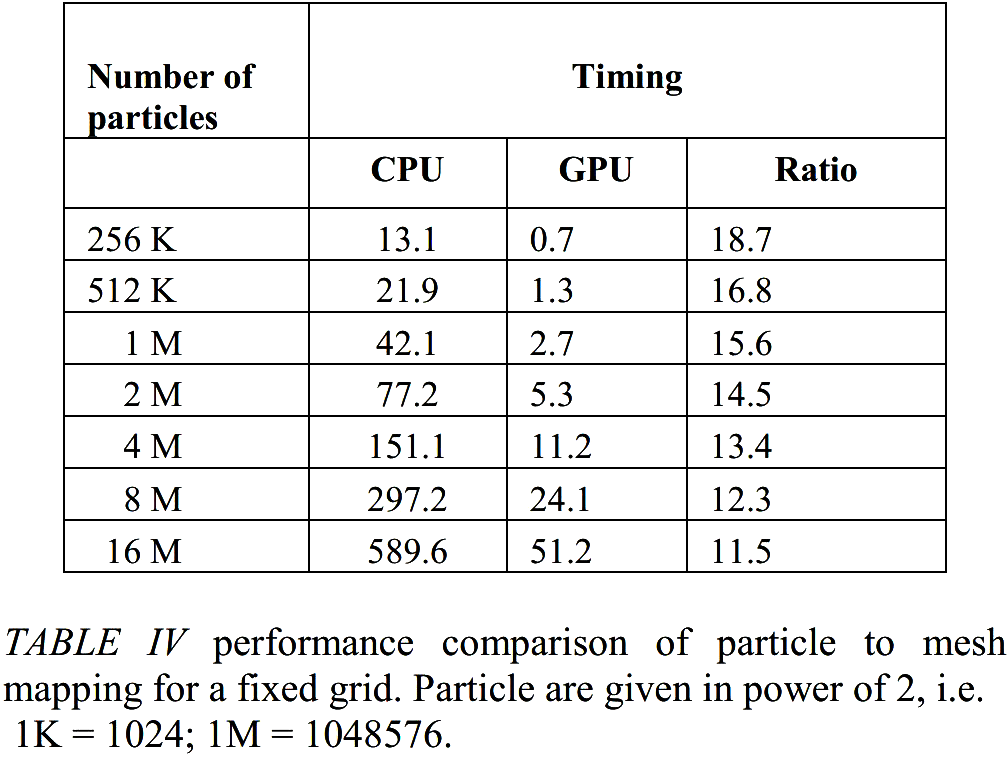

Current interest
Health care
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar






Forest biodiversity
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar





Building machines
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar



Thanks!
@brijesh68kumar
Parallel implementation of Particle-Mesh mapping using CUDA enabled GPU
By Brijesh Kumar


