Search & Policy
achieves AGI?
Search
Given dynamics model, reward model, walk down a tree of future, search for actions if doing test time planning
e.g. Tree Search, RRT, GCS
When to use:
- transition dynamics is easier to get (e.g. chess, sim)
- smaller action space
- interaction is expensive
- online execution isn't too demanding on speed
- want more guarantees & accuracy
Policy
Have an intuition of what immediate action(s) to take, from past interactions or expert demonstrations
e.g. LLM, PPO, Imitation Learning
When to use:
- interaction data or expert demo is plentiful
- dynamics is complex to model
- bigger action space
Terminology
Planning is the test time behavior of Search
Search itself is more general
"Tree traversal, also known as tree search, is a process of visiting each node of a tree data structure"
Combine both
How we distinguish planning vs policy -> test time behavior
But we can combine both at training time
With a current policy and learned dynamics model, run MCTS to plan actions, take actions to get interaction data,
use data to improve policy & dynamics model
e.g. Chess agents, Tree of thought
When to use:
- Almost always!
- Especially when you want to combine knowledge of dynamics model & expert demo
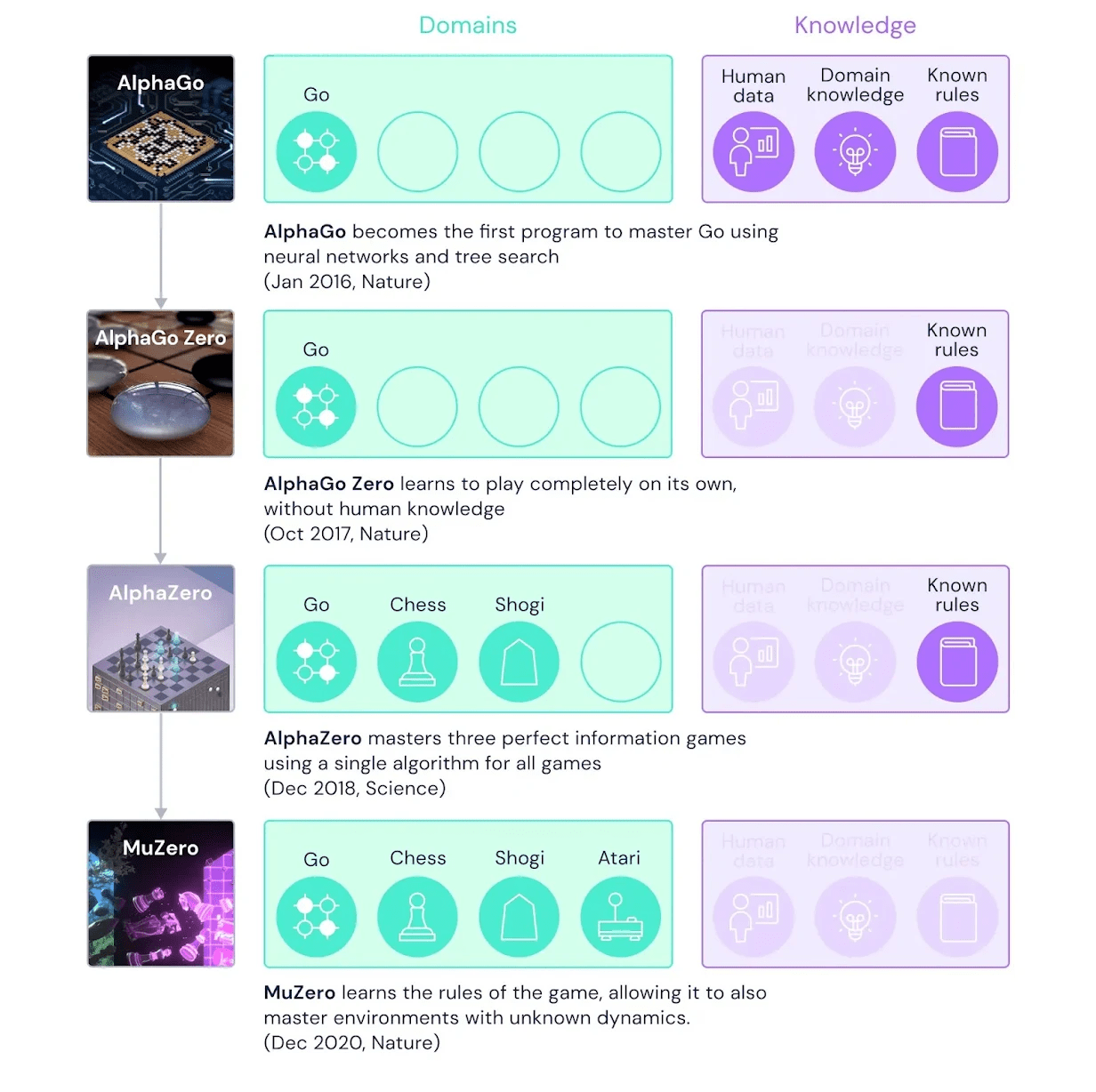
Example: Alpha GO
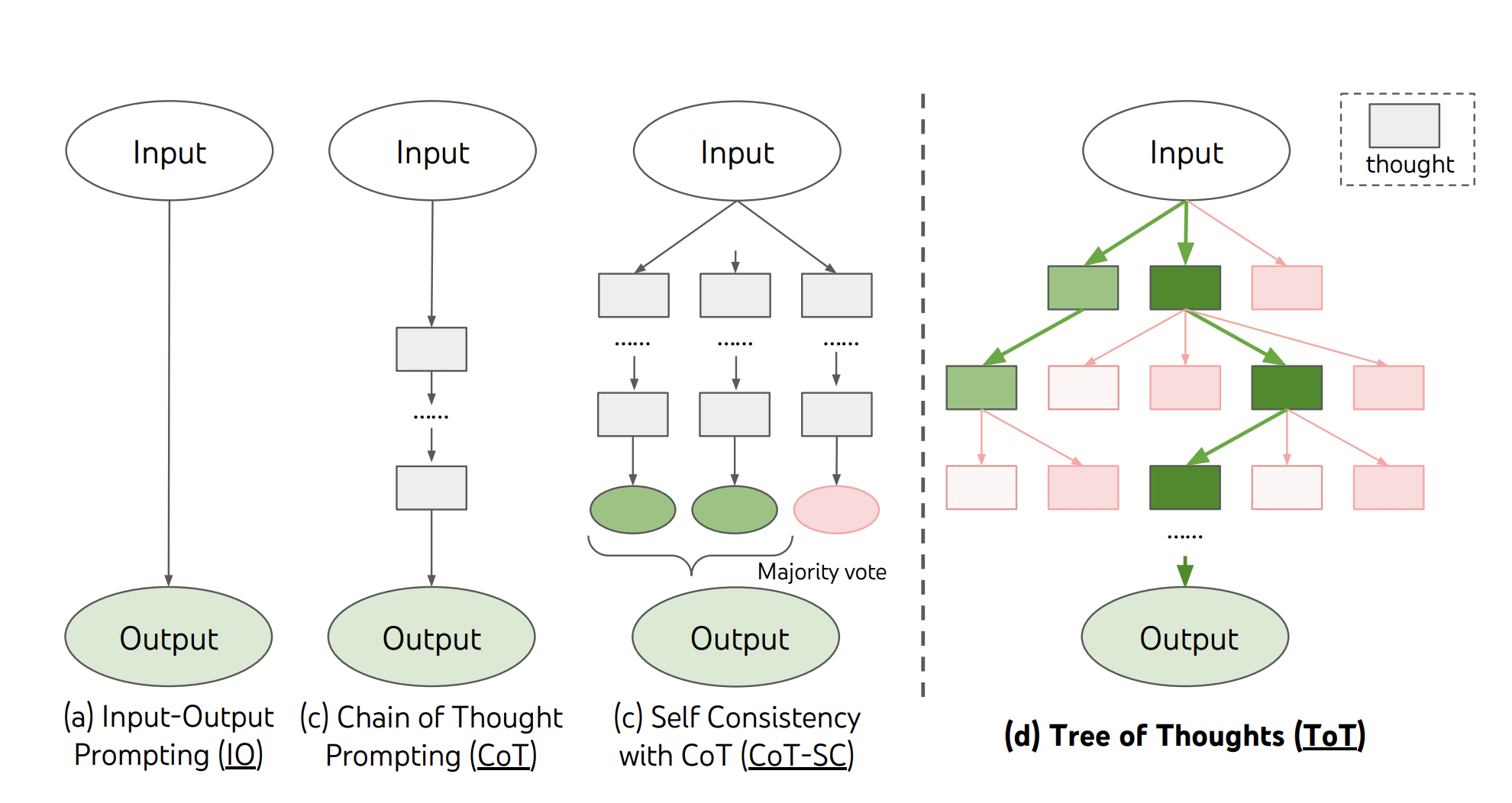
Example: Tree of Thought
Example: Model Based RL?
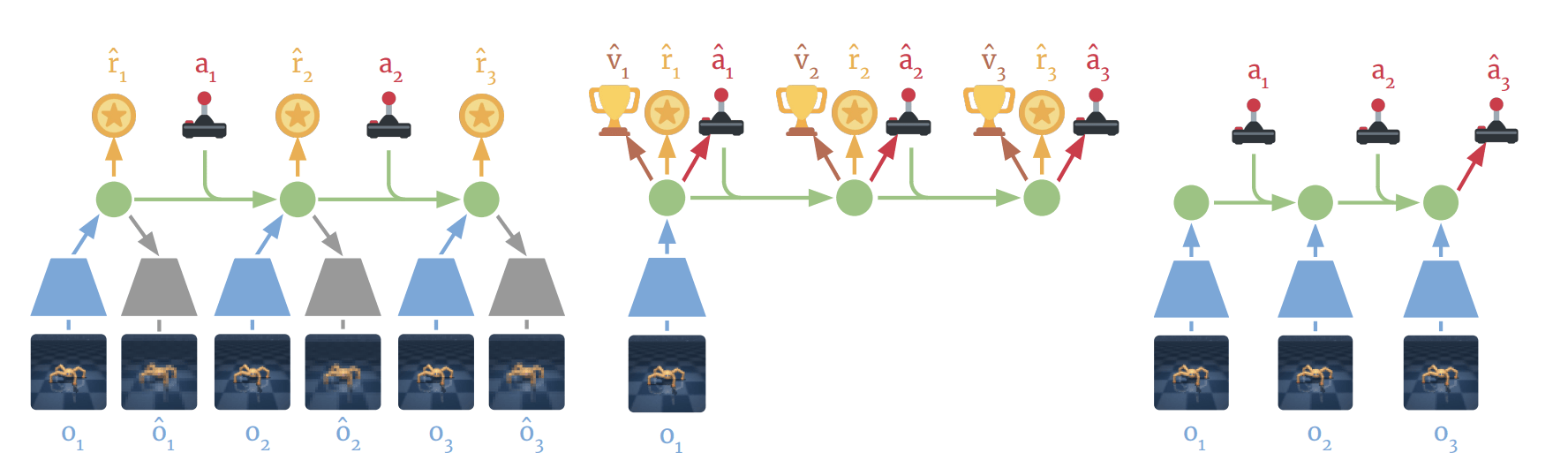
1. MBRL is definitely a policy by test time behavior
2. It does search to generate data
Minimal
By buoyancy99

