Desempenho em aplicações web que utilizam GraphQL (mas não somente)
GDG Lauro de Freitas
08 de novembro de 2024
- Ciência da Computação / UFBA
- Ruby On Rails desde 2008 / JavaScript desde 2006
- https://ca.ios.ba
- @caiosba

- São Francisco - Califórnia
- Engenheiro de Software desde 2011
- https://meedan.com
- @meedan

Check
github.com/meedan/check-api


github.com/meedan/check
O foco desta palestra é...
GraphQL
Ruby On Rails
... mas não precisa ser!
Muitos conceitos e arquiteturas são aplicados a outros frameworks e stacks.
Mais disclaimers!
- Não existe bala de prata
- Otimização Prematura
- Os problemas e soluções apresentados aqui funcionaram para mim, mas dependem de fatores diferentes (por exemplo, banco de dados) e necessidades - e lembre-se, toda decisão tem um trade-off (manutenibilidade, legibilidade, dependências, etc.)
GraphQL
"GraphQL é uma linguagem de consulta para sua API, e uma ferramenta do lado do servidor para executar consultas usando um sistema de tipos que você define para seus dados."
REST
Media
Comment
Tag
1
*
User
*
*
*
1
GET /api/v1/medias/1
GET /api/v1/medias/1/comments
GET /api/v1/medias/1/tags
GET /api/v1/medias/1/comments/1
GET /api/v1/users/1?fields=avatar,name
GET /api/v1/users/2?fields=avatar,name
GET /api/v1/users/3?fields=avatar,name
...Endpoints reutilizáveis
GET /api/v1/medias/1?include=comments&count=5
GET /api/v1/medias/1?include=comments,tags
&comments_count=5&tags_count=5
GET /api/v1/medias/1?fields=comments(text,date)
&tags(tag)
...
GET /api/v1/media_and_comments/1
GET /api/v1/media_comments_and_tags/1
GET /api/v1/media_comments_tags_and_users/1GET /api/v1/medias/1?include=comments&count=5
GET /api/v1/medias/1?include=comments,tags
&comments_count=5&tags_count=5
GET /api/v1/medias/1?fields=comments(text,date)
&tags(tag)
...
GET /api/v1/media_and_comments/1
GET /api/v1/media_comments_and_tags/1
GET /api/v1/media_comments_tags_and_users/1Muitas requisições!
GraphQL
Um endpoint para todos governar

POST /graphql
POST /api/graphql?query=
{
media(id: 1) {
title
embed
tags(first: 3) {
tag
}
comments(first: 5) {
created_at
text
user {
name,
avatar
}
}
}
}POST /api/graphql?query=
{
media(id: 1) {
title
embed
tags(first: 3) {
tag
}
comments(first: 5) {
created_at
text
user {
name,
avatar
}
}
}
}Media
Comment
Tag
1
*
User
*
*
*
1
~
POST /api/graphql?query=
{
media(id: 1) {
title
embed
tags(first: 3) {
tag
}
comments(first: 5) {
created_at
text
user {
name,
avatar
}
}
}
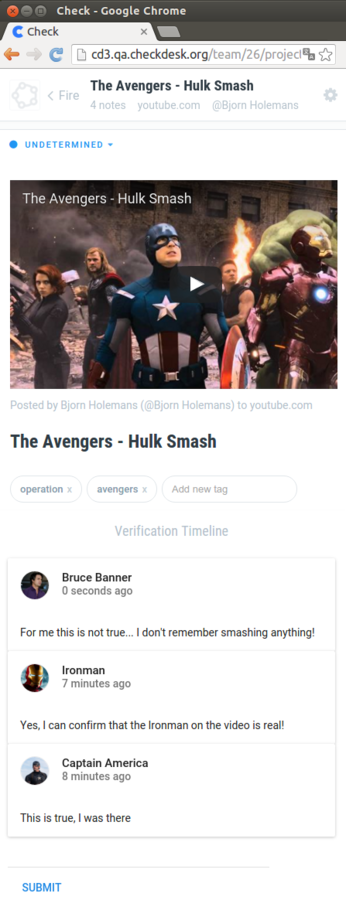
}{
"media": {
"title": "Avangers Hulk Smash",
"embed": "<iframe src=\"...\"></iframe>",
"tags": [
{ "tag": "avengers" },
{ "tag": "operation" }
],
"comments": [
{
"text": "This is true",
"created_at": "2016-09-18 15:04:39",
"user": {
"name": "Ironman",
"avatar": "http://[...].png"
}
},
...
]
}
}GraphQL
Ruby On Rails
Tipos

- Tipos personalizados
- Argumentos
- Campos
- Conexões
Mutations

mutation {
createMedia(
input: {
url: "http://youtu.be/7a_insd29fk"
clientMutationId: "1"
}
)
{
media {
id
}
}
}
As mutações fazem alterações no seu lado do servidor.
CRUD:
Queries: Read
Mutations:
- Create
- Update
- Delete
# mutation {
createMedia(
# input: {
url: "http://youtu.be/7a_insd29fk"
# clientMutationId: "1"
# }
# )
{
media {
id
}
}
# }
Nome da mutação
Parâmetros de entrada
Saída desejada
Muito flexível!
😊
Flexível demais!
😔
query {
teams(first: 1000) {
name
profile_image
users(first: 1000) {
name
email
posts(first: 1000) {
title
body
tags(first: 1000) {
tag_name
}
}
}
}
}Consultas aninhadas podem se tornar um verdadeiro problema.
A complexidade real de uma consulta e o custo de alguns campos podem ficar ocultos pela expressividade da linguagem.
Vamos ver algumas estratégias para lidar com isso.
Vamos por partes... Você não pode realmente consertar o que não pode testar
# Some controller test
gql_query = 'query { posts(first: 10) { title, user { name } } }'
assert_queries 5 do
post :create, params: { query: gql_query }
endMonitore se alguma refatoração ou alteração de código introduz regressões em como algumas consultas GraphQL são executadas.
# Some test helper
def assert_queries(max, &block)
query_cache_enabled = ApplicationRecord.connection.query_cache_enabled
ApplicationRecord.connection.enable_query_cache!
queries = []
callback = lambda { |_name, _start, _finish, _id, payload|
if payload[:sql] =~ /^SELECT|UPDATE|INSERT/ && !payload[:cached]
queries << payload[:sql]
end
}
ActiveSupport::Notifications.subscribed(callback, "sql.active_record", &block)
queries
ensure
ApplicationRecord.connection.disable_query_cache! unless query_cache_enabled
message = "#{queries.size} expected to be less or equal to #{max}."
assert queries.size <= max, message
endDebaixo dos panos, uma maneira é:
Ok, os testes estão passando! Hora de enviar, implantar e... monitorar
O monitoramento padrão de requisições HTTP não é suficiente...

- As coisas podem melhorar com um log mais estruturado
- Útil para integrar com outras ferramentas de alerta (Uptime, etc.)
Sabemos quanto tempo as requisições HTTP GraphQL estão levando, mas quanto tempo a consulta GraphQL realmente leva?
OpenTelemetry / Honeycomb

Ótimo! Agora podemos ver quanto tempo cada etapa da GraphQL realmente leva... mas quais campos?
Apollo GraphQL Studio

Apollo GraphQL Studio

Apollo GraphQL Studio

Outras ferramentas
- Grafana
- Stellate
- Hasura
- ...
Agora que podemos rastrear e monitorar requisições GraphQL, como realmente melhorá-las ?
Evitar Consultas N+1
query {
posts(first: 5) {
id
author {
name
}
}
}Post Load (0.9ms) SELECT "posts".* FROM "posts"
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]]
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]]
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]]
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]]
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 5], ["LIMIT", 1]]class User < ApplicationRecord
has_many :posts
end
class Post < ApplicationRecord
belongs_to :user
has_many :tags
endEm um endpoint REST, você normalmente preveria retornar tanto posts quanto seus autores, sugerindo eager-loading na sua consulta. No entanto, como não podemos antecipar o que o cliente solicitará aqui, não podemos sempre pré-carregar os dados.
graphql-batch
# app/graphql/types/post_type.rb
field :author, Types::UserType do
resolve -> (post, _args, _context) {
RecordLoader.for(User).load(post.user_id)
}
endPost Load (0.5ms) SELECT "posts".* FROM "posts" ORDER BY "posts"."id" DESC LIMIT $1 [["LIMIT", 5]]
User Load (0.4ms) SELECT "users".* FROM "users" WHERE "users"."id" IN (1, 2, 3, 4, 5)BatchLoader pode ser usado também.
Isso funciona bem para relacionamentos 1-para-1, mas e quanto a 1-para-muitos?
graphql-preload
# app/graphql/types/post_type.rb
field :tags, !types[Types::TagType] do
preload :tags
resolve -> (post, _args, _ctx) { post.tags }
endMas ainda assim, pode haver problemas de performance ao lidar com consultas mais complexas... E se pudéssemos prever dados consultados com precisão e criar um hash dinâmico para pré-carregar associações?
graphql: lookahead
field :users, [Types::UserType], null: false, extras: [:lookahead]
def users(lookahead:)
# Do something with lookahead
endquery
└── users
├── id
├── name
└── posts
├── id
└── titleO objeto lookahead é como uma estrutura de árvore que representa as informações que você precisa para otimizar sua consulta. Na prática, é muito mais complicado do que isso.
Evite consultas complexas
query {
teams(first: 1000) {
users(first: 1000) {
name
posts(first: 1000) {
tags(first: 1000) {
tag_name
}
author {
posts(first: 1000) {
title
}
}
}
}
}
}- Consultas podem facilmente se tornar muito aninhadas, muito profundas e até circulares
graphql: max_depth
# app/graphql/your_schema.rb
YourSchema = GraphQL::Schema.define do
max_depth 4 # adjust as required
use GraphQL::Batch
enable_preloading
mutation(Types::MutationType)
query(Types::QueryType)
endAplicando timeouts
# Added to the bottom of app/graphql/your_schema.rb
YourSchema.middleware <<
GraphQL::Schema::TimeoutMiddleware.new(max_seconds: 5) do |e, q|
Rails.logger.info("GraphQL Timeout: #{q.query_string}")
endCache de fragmentos
class PostType < BaseObject
field :id, ID, null: false
field :title, String, null: false, cache_fragment: true
endclass QueryType < BaseObject
field :post, PostType, null: true do
argument :id, ID, required: true
end
def post(id:)
last_updated_at = Post.select(:updated_at).find_by(id: id)&.updated_at
cache_fragment(last_updated_at, expires_in: 5.minutes) { Post.find(id) }
end
endNossa própria abordagem para cache de campos para campos de alta demanda (baseados em eventos, meta-programação)
# app/models/media_rb
cached_field :last_seen,
start_as: proc { |media| media.created_at },
update_es: true,
expires_in: 1.hour,
update_on: [
{
model: TiplineRequest,
if: proc { |request| request.associated_type == 'Media' },
affected_ids: proc { |request| request.associated.medias },
events: {
create: proc { |request| request.created_at },
}
},
{
model: Relationship,
if: proc { |relationship| relationship.is_confirmed? },
affected_ids: proc { |relationship| relationship.parent.medias },
events: {
save: proc { |relationship| relationship.created_at },
destroy: :recalculate
}
}
]Até aqui, vimos consultas únicas...
Mas o que acontece se muitas consultas forem enviadas ao mesmo tempo?
Por exemplo, o agrupamento de consultas do cliente Apollo ou até mesmo Relay do React:

Então, o backend é capaz de processá-las de forma concorrente
# Prepare the context for each query:
context = {
current_user: current_user,
}
# Prepare the query options:
queries = [
{
query: "query postsList { posts { title } }",
variables: {},
operation_name: 'postsList',
context: context,
},
{
query: "query latestPosts ($num: Int) { posts(last: $num) }",
variables: { num: 3 },
operation_name: 'latestsPosts',
context: context,
}
]
# Execute concurrently
results = YourSchema.multiplex(queries)Multiplex:
- Economiza tempo com autorização e sobrecarga HTTP
- Quando habilitado, até mesmo uma única consulta é executada dessa forma (então, "multiplex de um")
- Execuções de multiplex têm seu próprio contexto, analisadores e instrumentação
- Cada consulta é validada e analisada independentemente. O array de resultados pode incluir uma mistura de resultados bem-sucedidos e resultados falhos.
- Novamente, o monitoramento é importante para ter certeza de que uma consulta específica não está atrasando as outras
Isso é bastante para consultas GraphQL, e quanto às mutações?
Algumas dicas rápidas para isso:
- Trabalhos em segundo plano (Sidekiq, SQS, etc.)
- Operações em massa (INSERT de múltiplos registros, etc.)
Conclusão:
"Com grandes sistemas vem grande responsabilidade"

Não, sério, conclusão:
-
Priorize a otimização de desempenho para melhorar a experiência do usuário e a escalabilidade da aplicação.
-
Identifique e Resolva Gargalos: Monitore sua aplicação regularmente para identificar gargalos de desempenho, focando em consultas de banco de dados, execução de código e otimização de consultas GraphQL/web.
-
A otimização é um processo contínuo: A otimização de desempenho não é uma tarefa única; é um processo contínuo que requer monitoramento, análise e melhoria constantes.
Obrigado! :)
https://ca.ios.ba
@caiosba
Desempenho em aplicações web que utilizam GraphQL (mas não somente)
By Caio Sacramento




