Optimizing Performance in Ruby on Rails Applications with GraphQL Layer
Wroclaw, Poland
April 13, 2024

- Brazil
- Ruby On Rails since 2008
- https://ca.ios.ba
- @caiosba

- San Francisco - California
- Meedan Software Engineer since 2011
- https://meedan.com
- @meedan

Check
meedan.com/check
github.com/meedan/check-api


github.com/meedan/check
The focus of this talk is on...
GraphQL
Ruby On Rails
... but it doesn't need to be!
Many concepts and architectures are applied to other frameworks and technical stacks.
More disclaimers!
- There is no silver bullet
- Premature Optimization
- The problems and solutions presented here worked for me, but it depends on different factors (e.g., database) and needs - and remember, every decision has a trade off (maintainability, readability, dependencies, etc.)
GraphQL
"GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data"
REST
Media
Comment
Tag
1
*
User
*
*
*
1
GET /api/v1/medias/1
GET /api/v1/medias/1/comments
GET /api/v1/medias/1/tags
GET /api/v1/medias/1/comments/1
GET /api/v1/users/1?fields=avatar,name
GET /api/v1/users/2?fields=avatar,name
GET /api/v1/users/3?fields=avatar,name
...Reusable endpoints
GET /api/v1/medias/1?include=comments&count=5
GET /api/v1/medias/1?include=comments,tags
&comments_count=5&tags_count=5
GET /api/v1/medias/1?fields=comments(text,date)
&tags(tag)
...
GET /api/v1/media_and_comments/1
GET /api/v1/media_comments_and_tags/1
GET /api/v1/media_comments_tags_and_users/1GET /api/v1/medias/1?include=comments&count=5
GET /api/v1/medias/1?include=comments,tags
&comments_count=5&tags_count=5
GET /api/v1/medias/1?fields=comments(text,date)
&tags(tag)
...
GET /api/v1/media_and_comments/1
GET /api/v1/media_comments_and_tags/1
GET /api/v1/media_comments_tags_and_users/1Too many requests!
GraphQL
One endpoint to rule them all

POST /graphql
POST /api/graphql?query=
{
media(id: 1) {
title
embed
tags(first: 3) {
tag
}
comments(first: 5) {
created_at
text
user {
name,
avatar
}
}
}
}POST /api/graphql?query=
{
media(id: 1) {
title
embed
tags(first: 3) {
tag
}
comments(first: 5) {
created_at
text
user {
name,
avatar
}
}
}
}Media
Comment
Tag
1
*
User
*
*
*
1
~
POST /api/graphql?query=
{
media(id: 1) {
title
embed
tags(first: 3) {
tag
}
comments(first: 5) {
created_at
text
user {
name,
avatar
}
}
}
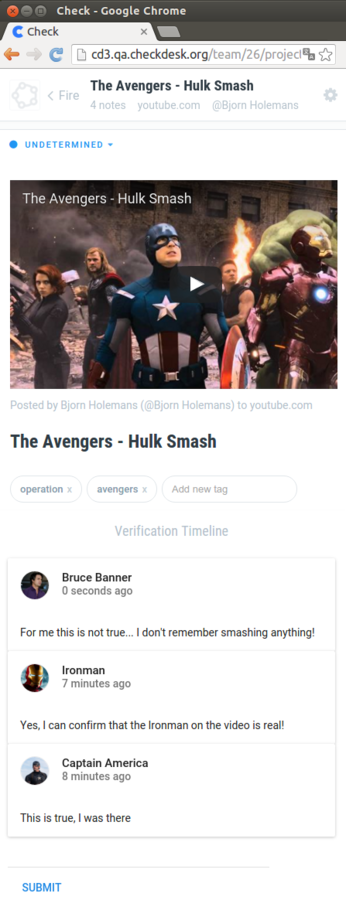
}{
"media": {
"title": "Avangers Hulk Smash",
"embed": "<iframe src=\"...\"></iframe>",
"tags": [
{ "tag": "avengers" },
{ "tag": "operation" }
],
"comments": [
{
"text": "This is true",
"created_at": "2016-09-18 15:04:39",
"user": {
"name": "Ironman",
"avatar": "http://[...].png"
}
},
...
]
}
}GraphQL
Ruby On Rails
Types

- Custom types
- Arguments
- Fields
- Connections
Mutations

mutation {
createMedia(
input: {
url: "http://youtu.be/7a_insd29fk"
clientMutationId: "1"
}
)
{
media {
id
}
}
}
Mutations make changes on your server side.
CRUD:
Queries: Read
Mutations:
- Create
- Update
- Delete
# mutation {
createMedia(
# input: {
url: "http://youtu.be/7a_insd29fk"
# clientMutationId: "1"
# }
# )
{
media {
id
}
}
# }
Mutation name
Input parameters
Desired output
So flexible!
😊
Too flexible!
😔
query {
teams(first: 1000) {
name
profile_image
users(first: 1000) {
name
email
posts(first: 1000) {
title
body
tags(first: 1000) {
tag_name
}
}
}
}
}Nested queries can become a real problem.
The actual complexity of a query and cost of some fields can get hidden by the expressiveness of the language.
Let's see some strategies to handle this.
But first things first... You can't really fix what you can't test
# Some controller test
gql_query = 'query { posts(first: 10) { title, user { name } } }'
assert_queries 5 do
post :create, params: { query: gql_query }
endKeep track if some refactoring or code change introduces regressions on how some GraphQL queries are executed.
# Some test helper
def assert_queries(max, &block)
query_cache_enabled = ApplicationRecord.connection.query_cache_enabled
ApplicationRecord.connection.enable_query_cache!
queries = []
callback = lambda { |_name, _start, _finish, _id, payload|
if payload[:sql] =~ /^SELECT|UPDATE|INSERT/ && !payload[:cached]
queries << payload[:sql]
end
}
ActiveSupport::Notifications.subscribed(callback, "sql.active_record", &block)
queries
ensure
ApplicationRecord.connection.disable_query_cache! unless query_cache_enabled
message = "#{queries.size} expected to be less or equal to #{max}."
assert queries.size <= max, message
endUnder the hood, one way is:
Alright, tests are passing! Time to push, deploy and... monitor
Regular HTTP request monitoring is not enough...

- Things can get better with more structured logging
- Useful for integrating with other alerting tools (Uptime, etc.)
We know how long GraphQL HTTP requests are taking, but how long the GraphQL query actually takes?
OpenTelemetry / Honeycomb

Great! Now we can see how long each step of the GraphQL actually takes... but which fields?
Apollo GraphQL Studio

Apollo GraphQL Studio

Apollo GraphQL Studio

Other tools
- graphql-metrics
- Grafana
- Stellate
- Hasura
- ...
Now that we can track and monitor GraphQL requests, how to actually improve them?
Avoid N+1 Queries
query {
posts(first: 5) {
id
author {
name
}
}
}Post Load (0.9ms) SELECT "posts".* FROM "posts"
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]]
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]]
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]]
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]]
User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 5], ["LIMIT", 1]]class User < ApplicationRecord
has_many :posts
end
class Post < ApplicationRecord
belongs_to :user
has_many :tags
endIn a REST endpoint, you'd typically predict returning both posts and their authors, prompting eager-loading in your query. However, since we can't anticipate what the client will request here, we can't always preload the owner.
graphql-batch gem
# app/graphql/types/post_type.rb
field :author, Types::UserType do
resolve -> (post, _args, _context) {
RecordLoader.for(User).load(post.user_id)
}
endPost Load (0.5ms) SELECT "posts".* FROM "posts" ORDER BY "posts"."id" DESC LIMIT $1 [["LIMIT", 5]]
User Load (0.4ms) SELECT "users".* FROM "users" WHERE "users"."id" IN (1, 2, 3, 4, 5)BatchLoader could be used as well.
This works well for belongs_to
relationships, but what about has_many?
graphql-preload gem
# app/graphql/types/post_type.rb
field :tags, !types[Types::TagType] do
preload :tags
resolve -> (post, _args, _ctx) { post.tags }
endBut still, it can suffer when dealing with more complex queries... What if we could predict queried data precisely and create a dynamic hash to preload associations?
graphql gem: lookahead
field :users, [Types::UserType], null: false, extras: [:lookahead]
def users(lookahead:)
# Do something with lookahead
endquery
└── users
├── id
├── name
└── posts
├── id
└── titleThe lookahead object is like a tree structure that represents the information you need in order to optimize your query. In practice, it's way more complicated than this.
Avoid complex queries
query {
teams(first: 1000) {
users(first: 1000) {
name
posts(first: 1000) {
tags(first: 1000) {
tag_name
}
author {
posts(first: 1000) {
title
}
}
}
}
}
}- Queries can easily get too nested, too deep and even circular
graphql gem: max_depth
# app/graphql/your_schema.rb
YourSchema = GraphQL::Schema.define do
max_depth 4 # adjust as required
use GraphQL::Batch
enable_preloading
mutation(Types::MutationType)
query(Types::QueryType)
endApplying timeouts
# Added to the bottom of app/graphql/your_schema.rb
YourSchema.middleware <<
GraphQL::Schema::TimeoutMiddleware.new(max_seconds: 5) do |e, q|
Rails.logger.info("GraphQL Timeout: #{q.query_string}")
endgraphql-ruby-fragment_cache gem
class PostType < BaseObject
field :id, ID, null: false
field :title, String, null: false, cache_fragment: true
endclass QueryType < BaseObject
field :post, PostType, null: true do
argument :id, ID, required: true
end
def post(id:)
last_updated_at = Post.select(:updated_at).find_by(id: id)&.updated_at
cache_fragment(last_updated_at, expires_in: 5.minutes) { Post.find(id) }
end
endOur own approach to caching fields for high-demanding fields (events-based, meta-programming)
# app/models/media_rb
cached_field :last_seen,
start_as: proc { |media| media.created_at },
update_es: true,
expires_in: 1.hour,
update_on: [
{
model: TiplineRequest,
if: proc { |request| request.associated_type == 'Media' },
affected_ids: proc { |request| request.associated.medias },
events: {
create: proc { |request| request.created_at },
}
},
{
model: Relationship,
if: proc { |relationship| relationship.is_confirmed? },
affected_ids: proc { |relationship| relationship.parent.medias },
events: {
save: proc { |relationship| relationship.created_at },
destroy: :recalculate
}
}
]Single queries are handled... now what if many queries are sent at the same time?
For example, Apollo's client query batching or even React's Relay:

Then, the backend is able to process those concurrently, using graphql gem's multiplex
# Prepare the context for each query:
context = {
current_user: current_user,
}
# Prepare the query options:
queries = [
{
query: "query postsList { posts { title } }",
variables: {},
operation_name: 'postsList',
context: context,
},
{
query: "query latestPosts ($num: Int) { posts(last: $num) }",
variables: { num: 3 },
operation_name: 'latestsPosts',
context: context,
}
]
# Execute concurrently
results = YourSchema.multiplex(queries)Multiplex:
- Saves time with authorization and HTTP overhead
- When enabled, even one single query is executed this way (so, "multiplex of one")
- Multiplex runs have their own context, analyzers and instrumentation
- Each query is validated and analyzed independently. The results array may include a mix of successful results and failed results.
- Again, monitoring is important to be sure that one specific query is not delaying the others
This is a lot for GraphQL queries, what about mutations?
A couple of quick tips for that:
- Background jobs (Sidekiq, Active Job, etc.)
- Bulk-operations (upsert_all, insert_all etc.)
Conclusion:
"With great systems comes great responsibility"

No, seriously, conclusion:
-
Prioritize performance optimization to enhance user experience and application scalability.
-
Identify and Address Bottlenecks: Regularly monitor and profile your application to identify performance bottlenecks, focusing on database queries, Ruby code execution, and GraphQL query optimization.
-
Optimization is an Ongoing Process: Performance optimization is not a one-time task; it's an ongoing process that requires continuous monitoring, analysis, and improvement.
Dziękuję! :)
https://ca.ios.ba
@caiosba
Optimizing Performance in Ruby on Rails Applications with GraphQL Layer
By Caio Sacramento




