4 / 17 專題進度報告
資訊組
22601 王政祺 & 22625 劉至軒
Deepfake
「Deep Learning」+「Fake」
Using Deep Neural Nets to generate fakes
Why Deepfake ?
Security
By building a DeepFake of our own, we can better understand the limitations of DeepFakes, and how to counter them.
It's Fun!
Obviously, being able to stuff words into other peoples' mouths is fun (as long as the words are harmless)! So why not do an academically stimulating and fun project?
What do we expect?
Yoda
C-3PO

"Hmm. In the end, cowards are those who follow the dark side."
"Oh my goodness"


Yoda
C-3PO
Model
Model
"Hmm. In the end, cowards are those who follow the dark side."
Expected Result
How are we going to do this?
Voice Conversion Model
AutoVC: Zero-Shot Voice Style Transfer with Only AutoEncoder Loss
AutoEncoder Model
Encoder
Decoder
Encoding
Input
Output
Learns an encoding (representation) for the input data
Learns to decode the encoding and produce some output
Ex. Removal of Noise


Learns to decode the encoding and produce some output
Learns to represent that it's a '7' and ignore the noise
Encoding
Decoder
Encoder
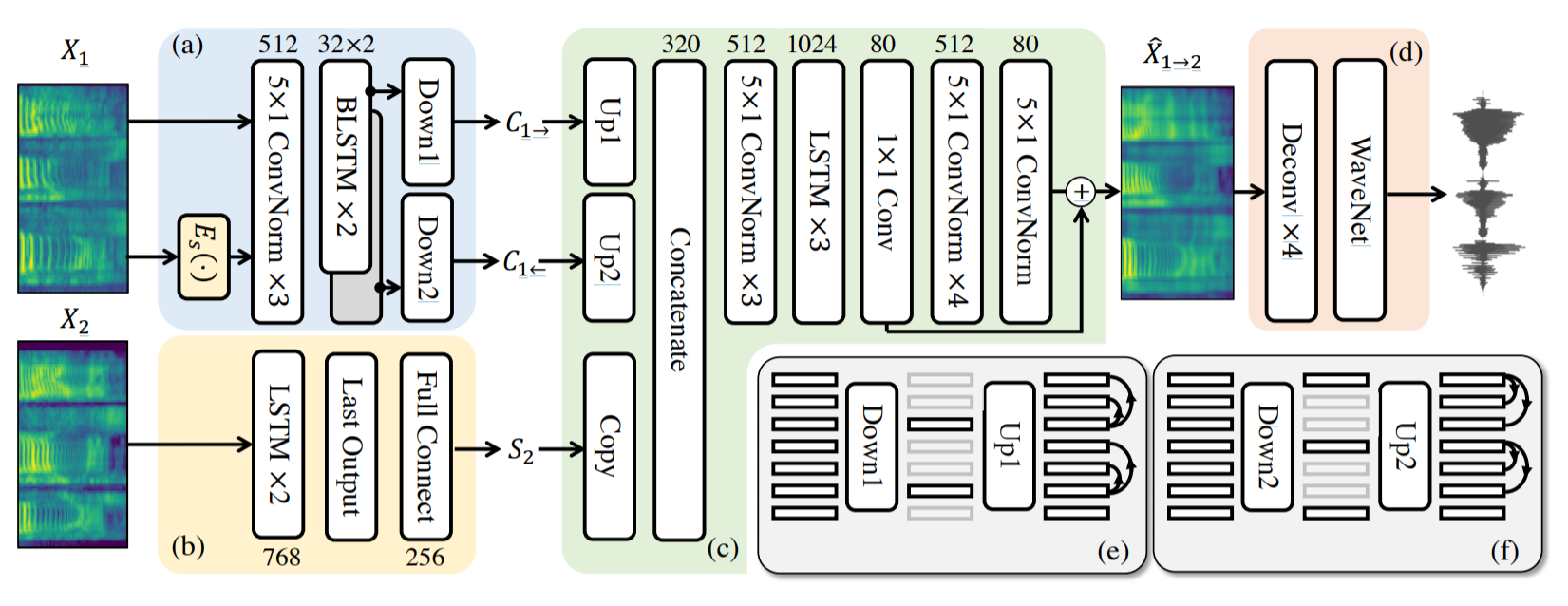
AutoVC Model
Content
Encoder
\(E_C(\cdot)\)
\(E_S(X_1)\)
\(E_C(X_1)\)
Style
Encoder
\(E_S(\cdot)\)
\(X_1\)
Tries to separate the content (what is actually being said, i.e., phonology, tones) and the speaker data (accent, voice)
The content encoder receives both the style encoding and the original spectrogram as input as it needs to learn to separate the two
AutoVC Model
Content
Encoder
\(E_C(\cdot)\)
\(E_S(X_1)\)
\(E_C(X_1)\)
Style
Encoder
\(E_S(\cdot)\)
\(X_1\)
\(E_S(X_2)\)
We want the style of \(X_2\) and the content of \(X_1\)
AutoVC Model
\(E_S(X_2)\)
\(E_C(X_1)\)
Decoder
\(D(\cdot, \cdot)\)
\(\tilde{X}_{1\rightarrow 2}\)
\(R_{1 \rightarrow 2}\)
Initial estimate
Residue
\(\hat{X}_{1\rightarrow 2}\)
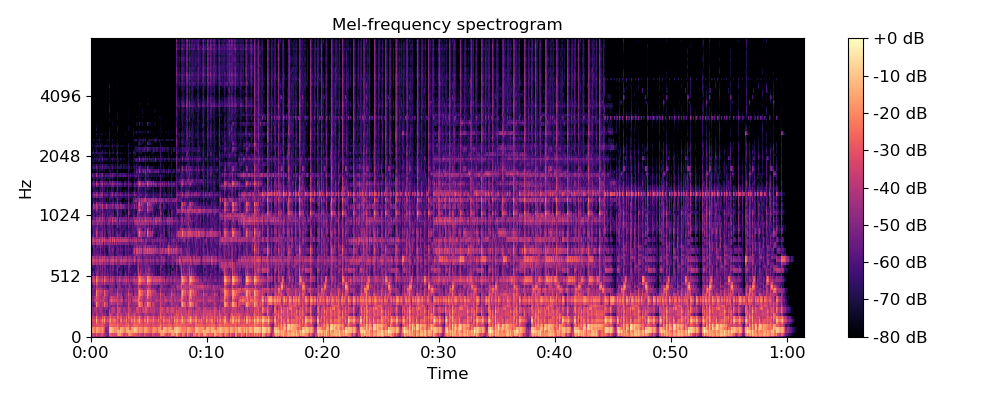
WaveNet
(Spectrogram to Wave)
Finished Product!
Voilà! We can now convert between voices!
Our Schedule
Phase I.
Survey & Decide our problem
Egyptian Hieroglyph Recognition
Fake News Evaluation
Deepfake
Phase II.
Learn tools required
& Read papers

Phase III.
Prototyping Phase
Phase IV.
Debugging,
Tweaking,
Commenting
Phase V.
Cleaning Up,
Write Thesis,
Ready the presentation!
What we are doing
The paper gave a half-complete implementation of AutoVC
(auspicious3000 @ IBM)
Content
Encoder
\(E_C(\cdot)\)
Decoder
\(D(\cdot, \cdot)\)
Generator
WaveNet
(Spectrogram to Wave)
(r9y9 @ Google)
What we were given
Style
Encoder
\(E_S(\cdot)\)
(CorentinJ @ Resemble AI)
Generator
What we need to do
-
Fit all the pieces together and ensure the smooth operation of the three models
-
Write code to load our own data and feed it into the pieced-together machine
-
Be able to train and evaluate the machine on our own data
Generator
What we need to do
-
Fit all the pieces together and ensure the smooth operation of the three models
-
Write code to load our own data and feed it into the pieced-together machine
-
Be able to train and evaluate the machine on our own data
mostly complete!
Is in testing phase
Is in testing phase

Future Prospects
Finish the code
Stitch the voice onto a video
To be looked into further...
Thank you!
1 / 2 專題進度報告
By CasperWang




