Make History Come Alive
The time when AI meets Archeology


處理模型
架設網站
王政祺
蕭梓宏
協助標記
製作簡報
劉至軒
蒐集資料
訓練模型




DEMO
Results
訓練成果



對照表~
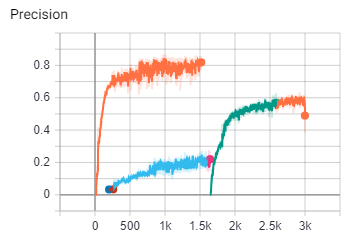
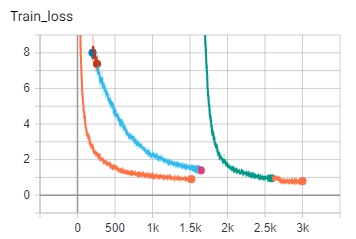
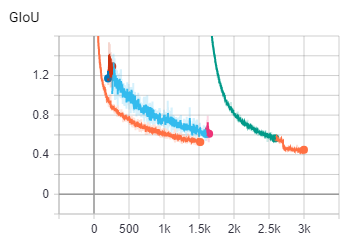
紅色是第一次Training
有五個Class
(最後採用的是橘色的線,藍色的線是用比較小的model實驗的結果)
綠色框框是第二次Training
增加至21個Class
用上次的權重繼續訓練
背景知識

羅塞塔石碑(現存於大英博物館)
古埃及文字
聖書體,是古代埃及的正式書寫體系,是由表音字母與表意文字所構成

自公元五世紀以後,古埃及文字便已無人使用
1820年,法國語言學家商博良利用羅塞塔石碑成功破解了古埃及文,古埃及才又再次吸引了世人的目光


石碑與刻板上面所受的侵蝕,是造成辨識不易的重要原因
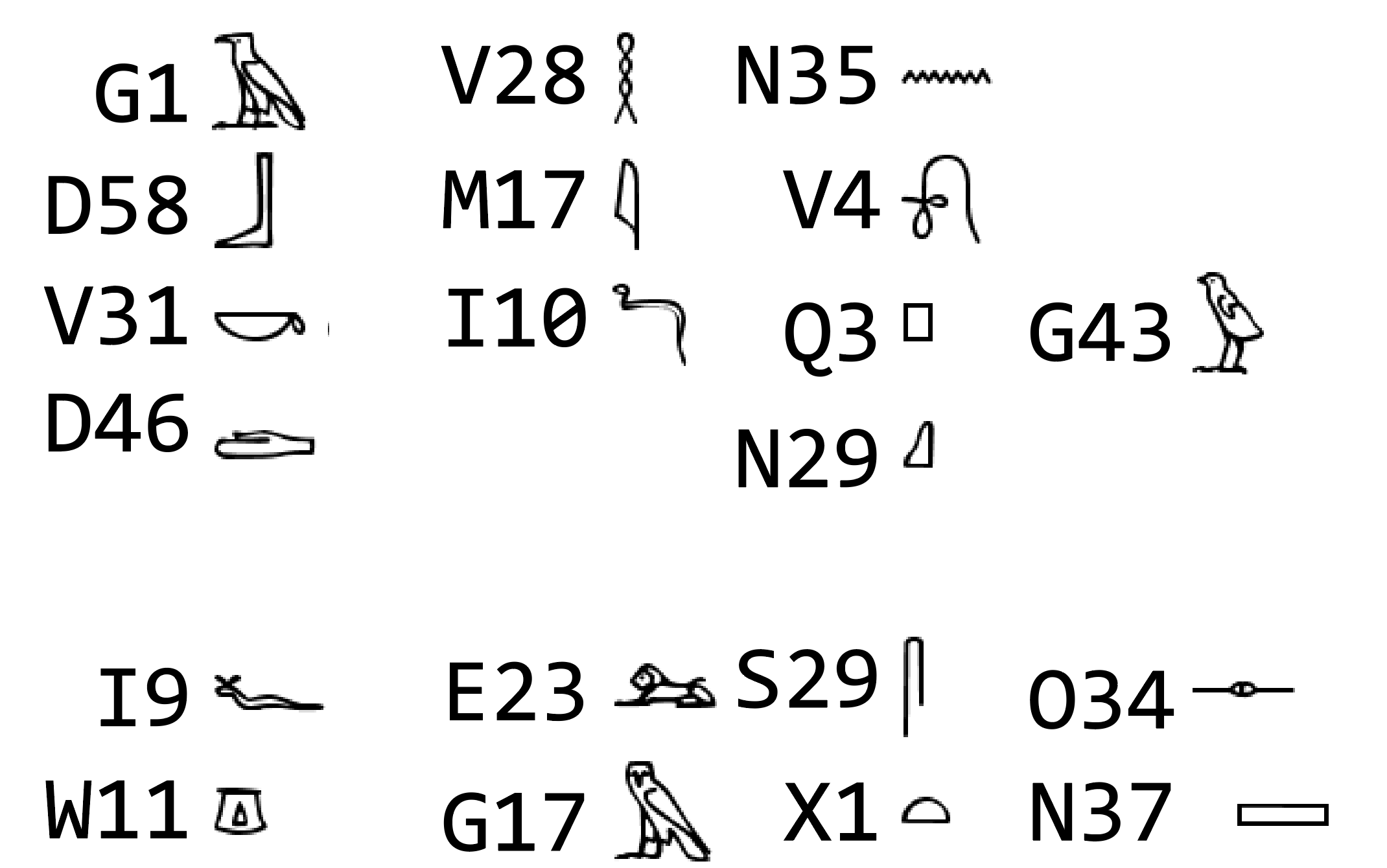
Gardner中有收錄763個符號
我們取了其中21個當作範例來做標註
於1928/9年發表了他的符號表,對現代的古埃及學很有幫助!
也寫了「Middle Egyptian Grammar」一書,是一本研究古埃及文文法的專書!
對照表~
我們做了什麼
Collecting Training Data
I
Training Data
在網路上看到一篇相關的論文
其內有附上他整理出的古埃及文字相關Data
M. Franken的Dataset
M. Franken的Dataset
說有標註4210個圖片....

M. Franken的Dataset
說有標註4210個圖片....
...但是單個符號的(V28)









\(\approx 10\)
\(\approx 4000\)
Start Training by using a CNN-Derived Model
II
我們決定先進行單一個文字的辨識
利用 CNN 捲積神經網路
達到近 90% 的準確率
Multiclass Classification
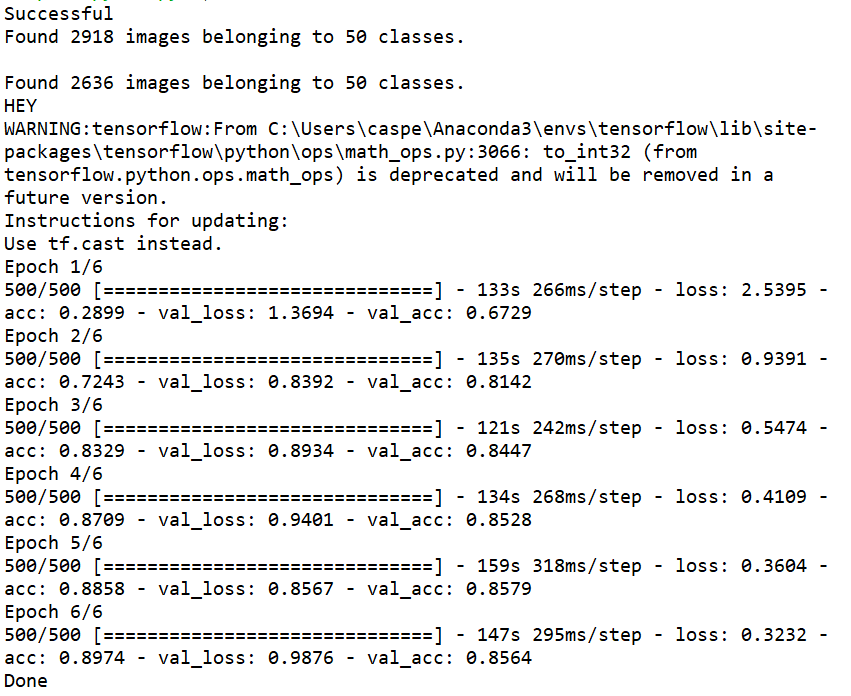
目前的結果
Object Detection
III
YOLOv3 Model
用來做 object detection 的 model
Why YOLOv3?
- 速度 —— 比其他的multiclass classifier還輕巧,快許多,對於沒有cluster的我們實在是太棒了!能夠相對快速(一個晚上)的train完並修改程式。
- 準確率高——在CoCo Dataset上面,YOLOv3和其他的Model是並駕齊驅的,並沒有因為速度而犧牲了準確度
- 有Readily-Available的Github Repo——別人寫的code一定比我們的高效,所以能有一個好的Repo供我們修改、使用是一個非常重要的Deciding Factor
LabelImg
可以協助手動標記文字 bounding box 的小工具
我們使用他來標記古埃及文字
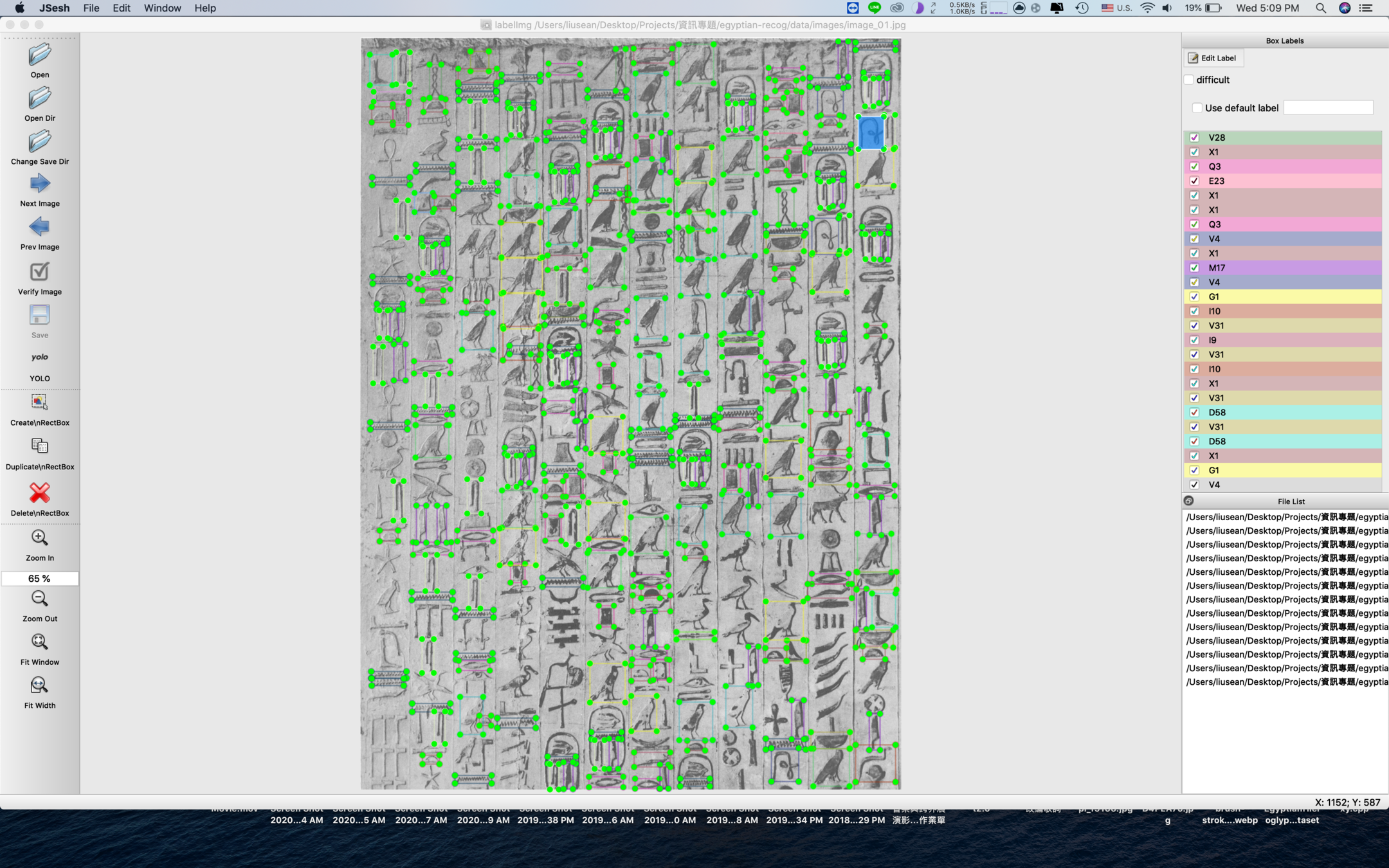
一張差不多要標15~30分鐘
Example of Labeled Image

Linguistic Analysis
IV
NLP 自然語言處理
目前還處在學習與研究的階段...
目前的問題 & 未來展望
資⋯⋯料⋯⋯量⋯⋯
因為我們是幾乎第一個嘗試做這件事的人(第一個應該是這個人(M. Franken, 2013),所以對於這種的資料真的是少之又少;他所提供的資料也因為不符合格式所以還是得重新標記
他說用他自己的model訓練三千張可以達到接近九成的正確率,我們目前雖然比三千張少很多,但是相信隨著資料量慢慢的增加,能夠大大的提升準確率!
語言學分析
上述的paper還有一個地方我們沒有實作:語言學的分析!他利用分析接下來的字最有可能為何和機器學習所吐出來的預測加權後得到更好的預測結果。
我們有初步的在蒐集資料
(How to Read Egyptian Hieroglyphs, M. Collier, British Museum Press)
不過還沒有完成
GUI & App
搭配JSesh (專門用來打出古埃及文的軟體)來幫我們畫出古埃及文,我們希望能將我們的成果包裝成APP,不用再一直和Command Line奮鬥,有圖形介面能快速、便利的辨認古埃及文!
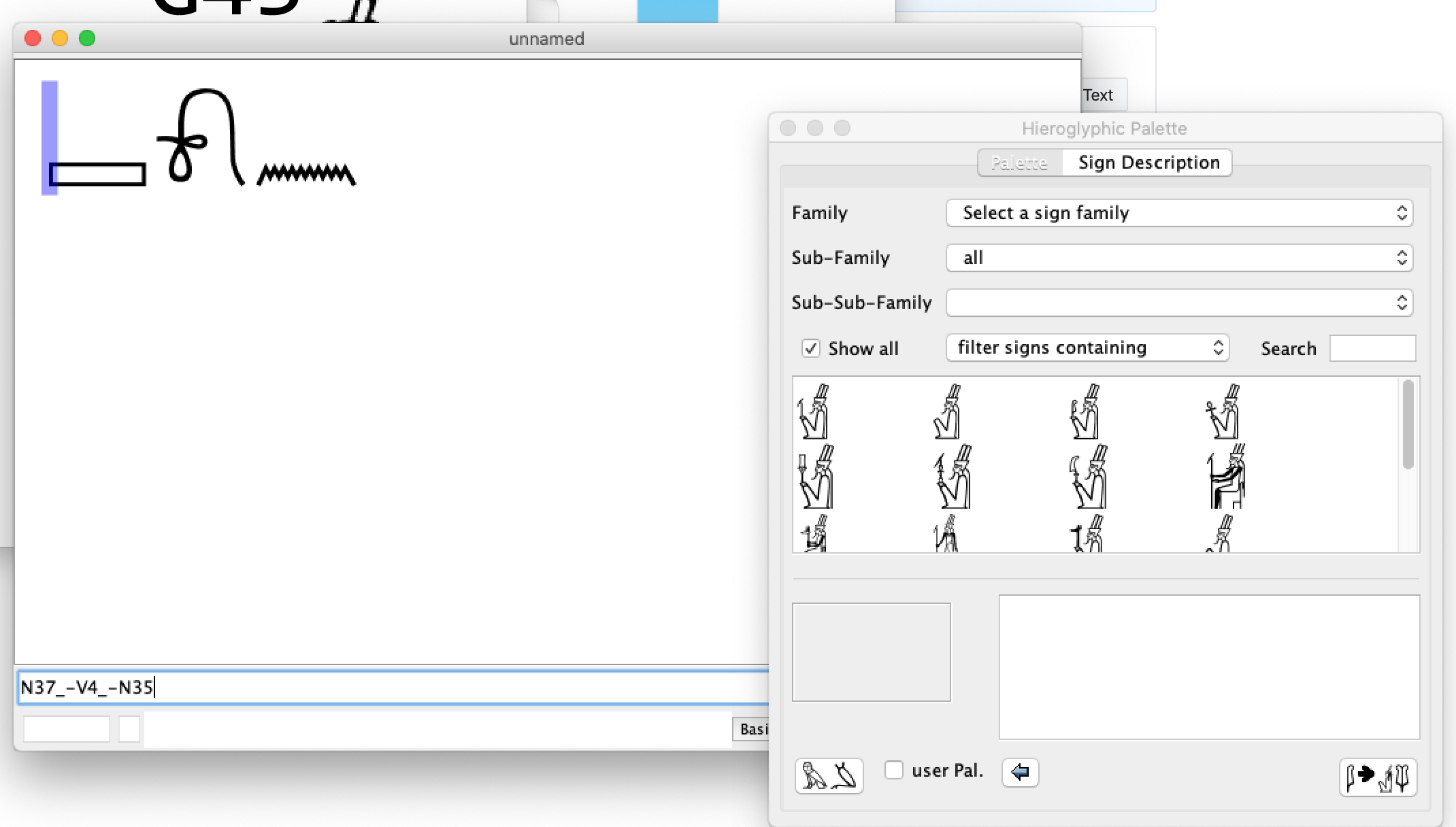
未來應用
1.成為古埃及文的即時翻譯,讓大家對古埃及文不再陌生
2.協助辨識古埃及文物,使其加速並減少人力投入
特別感謝
pecu lab的各位!特別謝謝蔡教授每月都固定將我們約出來,盡量讓我們on schedule,監督我們的進度!
Thanks for Listening!

YTP 專題報告
By CasperWang




