





Howie Chen
建中資訊社 副社長兼學術 陳泓宇
Machine Learning Intro
Decision Tree
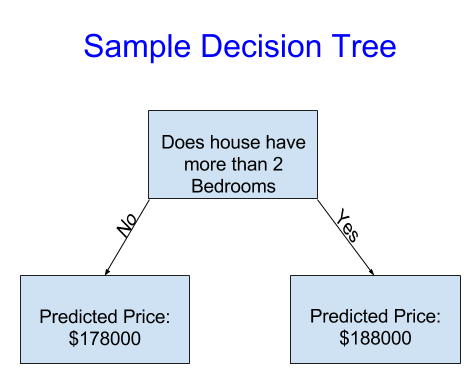
利用歷史資料來決定樹要怎麼分組和每組的值,這步驟稱為擬合(fitting)或訓練(training)模型
而其中用來訓練模型的歷史資料稱為
訓練資料(training data)
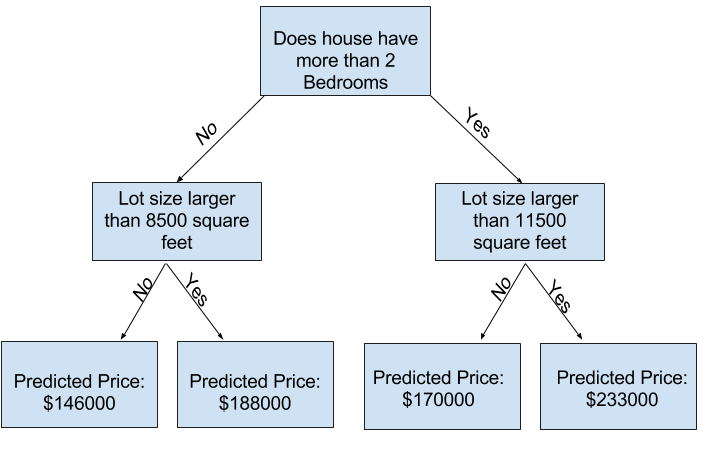
使用更多的變因,來讓決策樹有更多分支,也可以稱為更深的決策樹
樹葉
預測數值的地方
Data Processing
在cmd打上 pip install pandas
import pandas
melbourne_data = pandas.read_csv("melb_data.csv")
print(melbourne_data.describe())| count | 有幾行值 |
| mean | 平均 |
| std | 標準差 |
| min | 最小值 |
| 25% | PR25 |
| 50% | PR50 |
| 75% | PR75 |
| max | 最大值 |
First Machine Learning Model
在cmd打上 pip install scikit-learn
選擇訓練模型的資料
選擇要用的特徵
選擇要用的模型
用訓練好的模型來預測結果
用訓練資料來訓練模型
為結果評分
前面pandas用到的檔案
import pandas
melbourne_data = pandas.read_csv("melb_data.csv")import pandas
melbourne_data = pandas.read_csv("melb_data.csv")
melbourne_data = melbourne_data.dropna(axis=0)import pandas
melbourne_data = pandas.read_csv("melb_data.csv")
melbourne_data = melbourne_data.dropna(axis=0)
y = melbourne_data.Priceimport pandas
melbourne_data = pandas.read_csv("melb_data.csv")
melbourne_data = melbourne_data.dropna(axis=0)
y = melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]import pandas
melbourne_data = pandas.read_csv("melb_data.csv")
melbourne_data = melbourne_data.dropna(axis=0)
y = melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
from sklearn.tree import DecisionTreeRegressor
melbourne_model = DecisionTreeRegressor(random_state=1)import pandas
melbourne_data = pandas.read_csv("melb_data.csv")
melbourne_data = melbourne_data.dropna(axis=0)
y = melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
from sklearn.tree import DecisionTreeRegressor
melbourne_model = DecisionTreeRegressor(random_state=1)
melbourne_model.fit(X, y)import pandas
melbourne_data = pandas.read_csv("melb_data.csv")
melbourne_data = melbourne_data.dropna(axis=0)
y = melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
from sklearn.tree import DecisionTreeRegressor
melbourne_model = DecisionTreeRegressor(random_state=1)
melbourne_model.fit(X, y)
predict = melbourne_model.predict(X.head())import pandas
melbourne_data = pandas.read_csv("melb_data.csv")
#print(melbourne_data.columns)
melbourne_data = melbourne_data.dropna(axis=0)
y = melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
#print(X.describe())
#print(X.head())
from sklearn.tree import DecisionTreeRegressor
melbourne_model = DecisionTreeRegressor(random_state=1)
melbourne_model.fit(X, y)
predict = melbourne_model.predict(X.head())
print(predict)Model Validation
錯誤 = |實際值 - 預測值|
from sklearn.metrics import mean_absolute_error
predicted_home_prices = melbourne_model.predict(X)
mean_absolute_error(y, predicted_home_prices)就等於你用作業裡的題目來出段考題目
from sklearn.model_selection import train_test_split
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)Overfitting&Underfitting
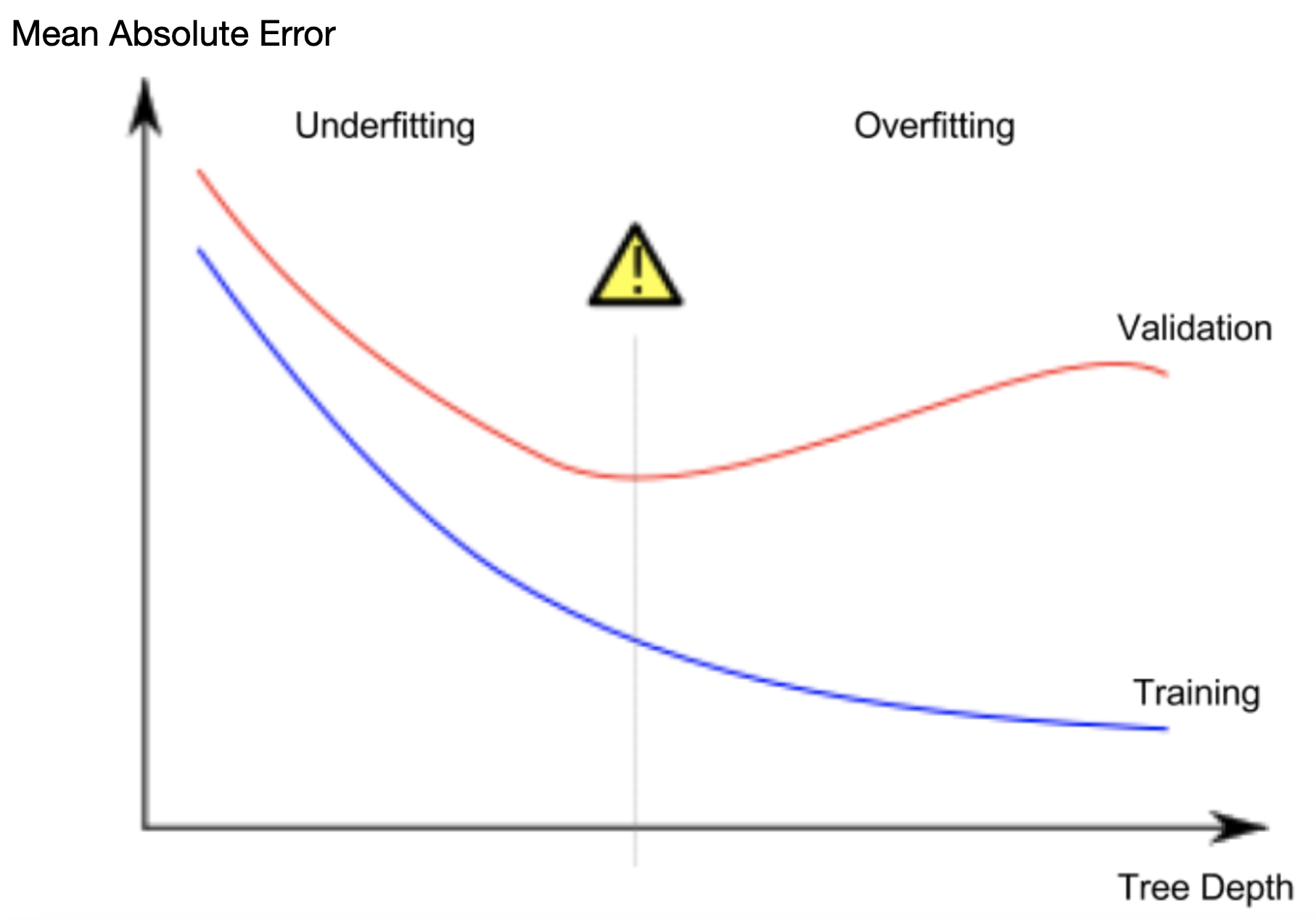
樹有很多層,導致每層只有少量的房子,因此無法準確預測價格
樹只有一層,完全沒辦法把房子分類來預測價格
DecisionTreeRegressor(max_leaf_nodes=counts, random_state=0)測試要用哪種最大樹葉深度才會有最好的結果
Random Forests
生成很多棵樹,最後對每個樹的預測結果取平均
from sklearn.ensemble import RandomForestRegressor
forest_model = RandomForestRegressor(random_state=1)By Howie Chen
初探機器學習



