CS2106 Tutorial 2
Chen Minqi
Q1a. Given that the probability of a task accessing an I/O device is , explain why the probability of n processes accessing an I/O device is .
p^n
p
- Assuming the processes are running independent of each other.
- The probability of two independent event happening together:
- Hence with n processes, the probability of all of them accessing the I/O device is
P(A B) = P(A) \times P(B)
p^n
b. What's the CPU utilization?
- CPU utilization is the percentage of time spent NOT on idle task.
- A process becomes blocked when it needs other resources.
- CPU is doing work if there is at least one process running.
- Assuming that a process is either running or waiting for I/O (blocked), CPU utilization is the same as the probability that at least one process is not accessing I/O device.
1-p^n
c. Plot the CPU Utilization chart.
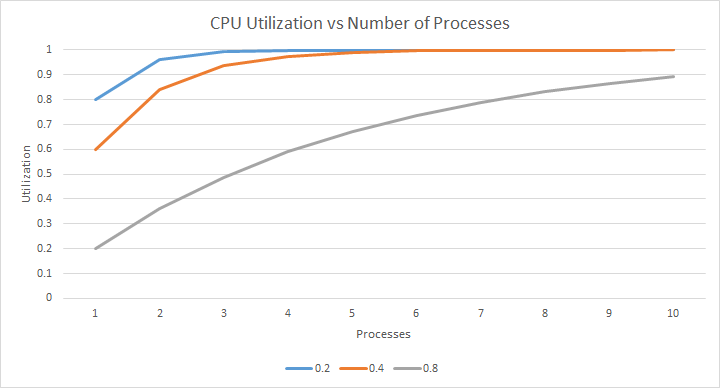
d. How does n and p affect CPU utilization?
- higher n results in higher utilization.
- as there are more processes, there is more "opportunity" for something to be running.
- higher p results in lower utilization.
- processes are more likely to be blocked on I/O.
2. Explain, with an example, why the highest priority task can still be interrupted by the lowest priority interrupt, and how this affects ISR design. (Hint: Interrupts are implemented in hardware in the CPU itself).
\neq
Interrupt
Preemption
An interrupt scenario
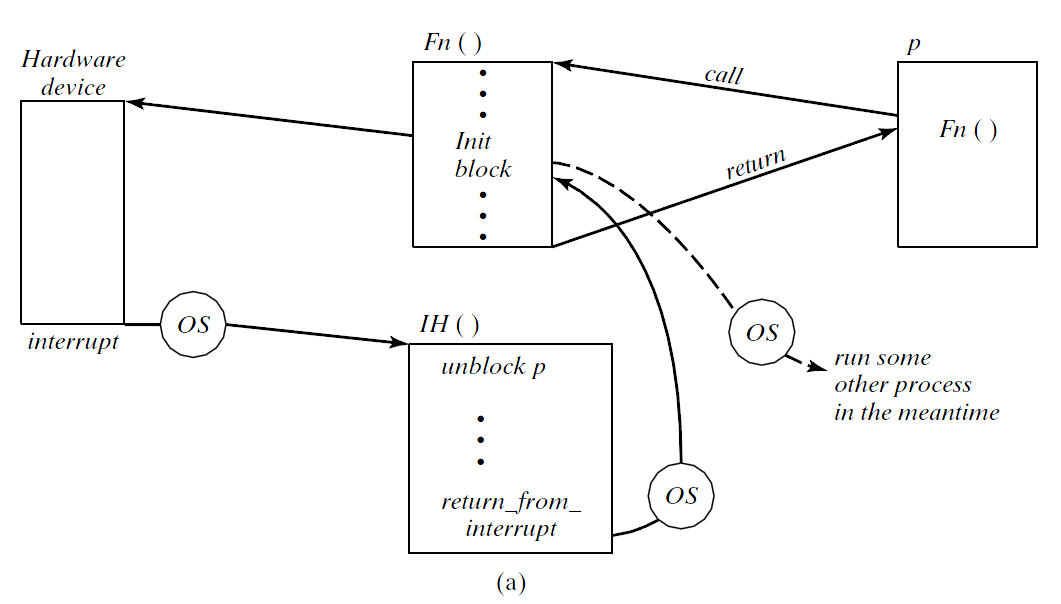
- Priorities are seen only by the OS.
- As far as the CPU is concerned, it just fetches and executes instructions. All processes are handled the same way.
- CPU senses (checks) interrupt request line after every instruction, so interrupts are always serviced.
- It is up to the OS/scheduler to decide if the running process needs to be preempted.
- But the interrupt has been serviced nonetheless.
3. Given four batch jobs T1, T2, T3 and T4 with running times of 190 cycles, 300 cycles, 30 cycles and 130 cycles, find the average waiting time to run if the jobs are
a: FIFO
b: SJF.
| T | Ci |
|---|---|
| T1 | 190 |
| T2 | 300 |
| T3 | 30 |
| T4 | 130 |
| T | Waiting time | Time@completion |
|---|---|---|
| T1 | 0 | 0+190 |
| T2 | 190 | 190+300 |
| T3 | 490 | 490+30 |
| T4 | 520 | 520+130 |
Total = 0 + 190 + 490 + 520 = 1200 cycles
Average = 300 cycles waiting time.
FIFO
| T | Ci |
|---|---|
| T1 | 190 |
| T2 | 300 |
| T3 | 30 |
| T4 | 130 |
| T | Waiting time | Time@completion |
|---|---|---|
| T3 | 0 | 0+30 |
| T1 | 30 | 30+130 |
| T4 | 160 | 160+190 |
| T2 | 350 | 350+300 |
Total = 0 + 30 + 160 + 350 = 540 cycles
Average = 135 cycles
SJF
From your answer and otherwise, explain the advantage and disadvantage of SJF.
In particular, what if the number of jobs running is not fixed and new jobs can be added at any time.
FIFO vs SJF
| Algorithm | Decision Mode | Priority Function | Arbitration rule |
|---|---|---|---|
| FIFO | Non-preemptive | r | Random |
| SJF | Non-preemptive | -t | Chronological or random |
r - real time in system
t - service time
Pros of SJF:
- Less waiting time on average, faster response for more jobs
Cons:
- Slightly more expensive to implement (in practice difference is negligible).
- Continuous inflow of short processes can starve long processes
4. Explain why, in critical instance analysis, if for each , every task is guaranteed to meet its deadline.
S_{i, F} \leq P_i
T_i
RMS recap
Shorter period, higher priority.
RMS recap
Shorter period, higher priority.
S_{i, 0} = \sum\limits_{j=1}^{i}{C_j}
Sum of the service time of all processes up to i.
Also the turnaround time for process i if there is no pre-emption.
P_j < S_{i, 0} \;\; _{j < i}
Process j occurs again before process i can complete.
Hence j will pre-empt i.
\lceil \frac{S_{i, 0}}{P_j} \rceil
| T | Ci | Pi |
|---|---|---|
| 1 | 1 | 3 |
| 2 | 3 | 10 |
This captures the total number of times that i will be blocked by j.
Total time that i spent waiting for j.
\sum\limits_{j=1}^{i-1}{C_j \times \lceil \frac{S_{i, 0}}{P_j} \rceil}
C_j \times \lceil \frac{S_{i, 0}}{P_j} \rceil
Total time that i spent waiting for all higher priority processes.
S_{i, 1} = C_i + \sum\limits_{j=1}^{i-1}{C_j \times \lceil \frac{S_{i, 0}}{P_j} \rceil}
This is a new estimate of the turnaround time for process i.
But now that this turnaround time estimation is potentially longer than the old one, it will be pre-empted a few more times.
\lceil \frac{S_{i, 1}}{P_j} \rceil
S_{i, n} = C_i + \sum\limits_{j=1}^{i-1}{C_j \times \lceil \frac{S_{i, n-1}}{P_j} \rceil}
S_{i, n} = C_i + \sum\limits_{j=1}^{i-1}{C_j \times \lceil \frac{S_{i, n-1}}{P_j} \rceil}
This estimate keeps growing, but eventually it reaches a point where it reflects the actual scheduling.
S_{i, n} = S_{i, n-1} = S_{i, F}
As long as all processes can meet its deadline, everything can be scheduled.
S_{i, F} \leq D_i
Bonus: A quick estimate (what I learnt)
\sum\limits_{i=1}^n{\frac{C_i}{P_i}\leq 1}
Scheduling is feasible using EDF if
This is actually CPU utilization.
Bonus: A quick estimate (what I learnt)
\sum\limits_{i=1}^n{\frac{C_i}{P_i}\leq 0.7}
Using the same formula for RMS:
Scheduling is feasible with RMS as long as the CPU utilization is less than approximately 0.7.
Furthermore, the condition is sufficient but not necessary
i.e., feasible schedules may still be possible for U > 0.7, but RM is not guaranteed to always find them.
CS2106 Tutorial 2
By Chen Minqi
CS2106 Tutorial 2
Email me at chen.minqi@u.nus.edu or ask your questions next time before / after tutorial!



