CS2106 Tutorial 3
Chen Minqi
Q1. Given a set of n processes each with running times Ci and periods Pi, running within a FIXED PRIORITY operating system, prove or disprove that of , for all processes i, it is guaranteed that every process will meet its deadline.
You may assume that process 0 has the highest priority and process n-1 has the lowest. However, you may not assume any ordering in the periods Pi or the execution times Ci.
S_{i, F} \leq P_i
Important: RMS is a form of fixed priority system.
- Yes, CIA can be applied.
- In CIA there are only two things that are important:
- The priority remains fixed throughout.
- The period and service time of each process is fixed so the preemption is predictable.
Hint: Can Critical Instance Analysis be applied here?
- In CIA there are only two things that are important:
-
-
The priority remains fixed throughout.
-
In RMS the priority remains fixed because we assume that Pi is fixed.
-
In Fixed Priority system, the priority is fixed by definition.
-
- The period of each process is fixed so the preemption is predictable.
-
The priority remains fixed throughout.
- With these two conditions satisfied, we can apply the same formula in CIA to a fixed priority system.
- This problem then reduces to Q4 in tutorial 2.
- Refer to last week's slides for more detailed explanation on how CIA guarantees satisfiable scheduling.
- Basic idea:
- Preemption happens in a deterministic way since the periods of all higher priority tasks are known.
S_{i, n} = C_i + \sum\limits_{j=1}^{i-1}{C_j \times \lceil \frac{S_{i, n-1}}{P_j} \rceil}
Q2. Will the following processes meet their deadlines?
Scheduling algorithm: RR
Time quantum (aka time slice): 2 cycles
| Process | Ci | Pi |
|---|---|---|
| T1 | 1 | 4 |
| T2 | 2 | 8 |
| T3 | 3 | 12 |
- If a process has run for q continuous time units, it is preempted from its processor and placed at the end of the process list waiting for the processor.
- Note that all processes have the same priority,
i.e., P = 0.
| Process | Ci | Pi |
|---|---|---|
| T1 | 1 | 4 |
| T2 | 2 | 8 |
| T3 | 3 | 12 |
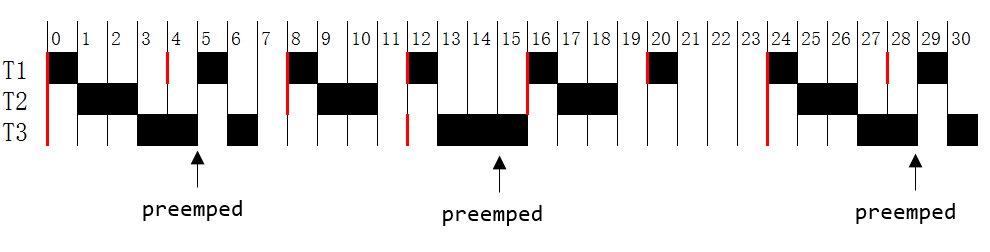
(If we start with {T2, T3, T1}, it will miss the deadline... you can try to draw the diagram to see where exactly does the scheduling fail)
You can, however assume that the starting queue is {T1, T2, T3} so the answer will be "yes".
Q3. What are the possible values of n? Why does it happen?
n++;
n = n * 2;
# P1: n++;
LW R0, n # load from memory
ADD R0, R0, 1 # Increment R0 by 1
SW R0, n # Store n back# P2 n = n * 2;
LW R1, n
MUL R1, R1, 2
SW R1, nImportant: Neither operation is atomic.
# P1: n++;
LW R0, n # lw1
ADD R0, R0, 1 # add
SW R0, n # sw1# P2: n = n * 2;
LW R1, n # lw2
MUL R1, R1, 2 # mul
SW R1, n # sw2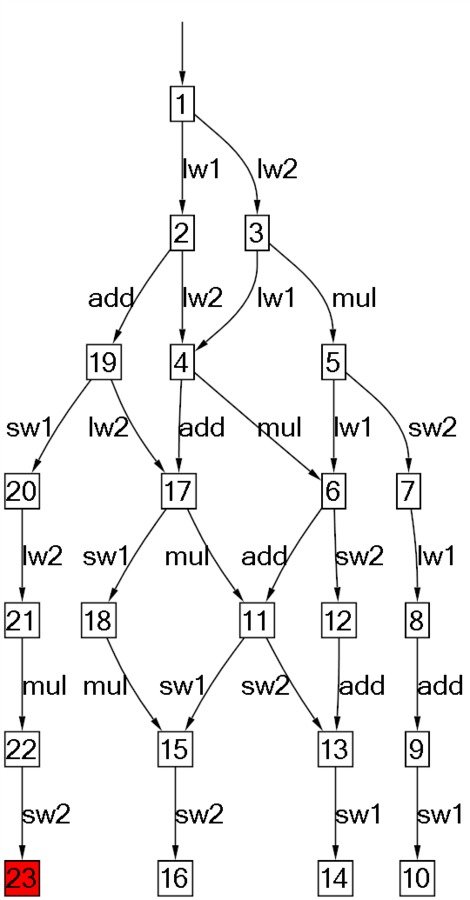
Total of 4 different end results, but a LOT MORE execution traces.
Extra: How many different execution traces are there?
# P1: n++;
LW R0, n # lw1
ADD R0, R0, 1 # add
SW R0, n # sw1# P2: n = n * 2;
LW R1, n # lw2
MUL R1, R1, 2 # mul
SW R1, n # sw2-
lw1-add-sw1-lw2-mul-sw2
-
lw2-mul-sw2-lw1-add-sw1
-
lw1-lw2-add-sw1-mul-sw2
-
lw1-lw2-mul-sw2-add-sw1
# P1: n++;
LW R0, n # lw1
ADD R0, R0, 1 # add
SW R0, n # sw1# P2: n = n * 2;
LW R1, n # lw2
MUL R1, R1, 2 # mul
SW R1, n # sw2-
lw1-add-sw1-lw2-mul-sw2
-
lw2-mul-sw2-lw1-add-sw1
-
lw1-lw2-add-sw1-mul-sw2
-
lw1-lw2-mul-sw2-add-sw1
| Ins | R0 | R1 | n |
|---|---|---|---|
| 6 | |||
| lw1 | 6 | ||
| add | 7 | ||
| sw1 | 7 | ||
| lw2 | 7 | ||
| mul | 14 | ||
| sw2 | 14 |
# P1: n++;
LW R0, n # lw1
ADD R0, R0, 1 # add
SW R0, n # sw1# P2: n = n * 2;
LW R1, n # lw2
MUL R1, R1, 2 # mul
SW R1, n # sw2-
lw1-add-sw1-lw2-mul-sw2=14
-
lw2-mul-sw2-lw1-add-sw1
-
lw1-lw2-add-sw1-mul-sw2
-
lw1-lw2-mul-sw2-add-sw1
| Ins | R0 | R1 | n |
|---|---|---|---|
| 6 | |||
| lw2 | 6 | ||
| mul | 12 | ||
| sw2 | 12 | ||
| lw1 | 12 | ||
| add | 13 | ||
| sw1 | 13 |
# P1: n++;
LW R0, n # lw1
ADD R0, R0, 1 # add
SW R0, n # sw1# P2: n = n * 2;
LW R1, n # lw2
MUL R1, R1, 2 # mul
SW R1, n # sw2-
lw1-add-sw1-lw2-mul-sw2=14
-
lw2-mul-sw2-lw1-add-sw1=13
-
lw1-lw2-add-sw1-mul-sw2
-
lw1-lw2-mul-sw2-add-sw1
| Ins | R0 | R1 | n |
|---|---|---|---|
| 6 | |||
| lw1 | 6 | ||
| lw2 | 6 | ||
| add | 7 | ||
| sw1 | 7 | ||
| mul | 12 | ||
| sw2 | 12 |
# P1: n++;
LW R0, n # lw1
ADD R0, R0, 1 # add
SW R0, n # sw1# P2: n = n * 2;
LW R1, n # lw2
MUL R1, R1, 2 # mul
SW R1, n # sw2-
lw1-add-sw1-lw2-mul-sw2=14
-
lw2-mul-sw2-lw1-add-sw1=13
-
lw1-lw2-add-sw1-mul-sw2=12
-
lw1-lw2-mul-sw2-add-sw1
| Ins | R0 | R1 | n |
|---|---|---|---|
| 6 | |||
| lw1 | 6 | ||
| lw2 | 6 | ||
| mul | 12 | ||
| sw2 | 12 | ||
| add | 7 | ||
| sw1 | 7 |
# P1: n++;
LW R0, n # lw1
ADD R0, R0, 1 # add
SW R0, n # sw1# P2: n = n * 2;
LW R1, n # lw2
MUL R1, R1, 2 # mul
SW R1, n # sw2-
lw1-add-sw1-lw2-mul-sw2=14
-
lw2-mul-sw2-lw1-add-sw1=13
-
lw1-lw2-add-sw1-mul-sw2=12
-
lw1-lw2-mul-sw2-add-sw1=7
Q4. Show how mutual exclusion guarantees that the two processes in Question 3 produce only correct values of n.
-
The operations of each line of code is treated as one critical section.
-
Mutex guarantees that each process reads, updates and writes n before the other process runs. Hence possible values are 14 and 13.
Copy of Copy of CS2106 Tutorial 3
By Chen Minqi



