

Cheuk Ting Ho
Developer advocate / Data Scientist - support open-source and building the community.
by Cheuk Ting Ho (@cheukting_ho)
Define the problem
Black-box method
Open the box
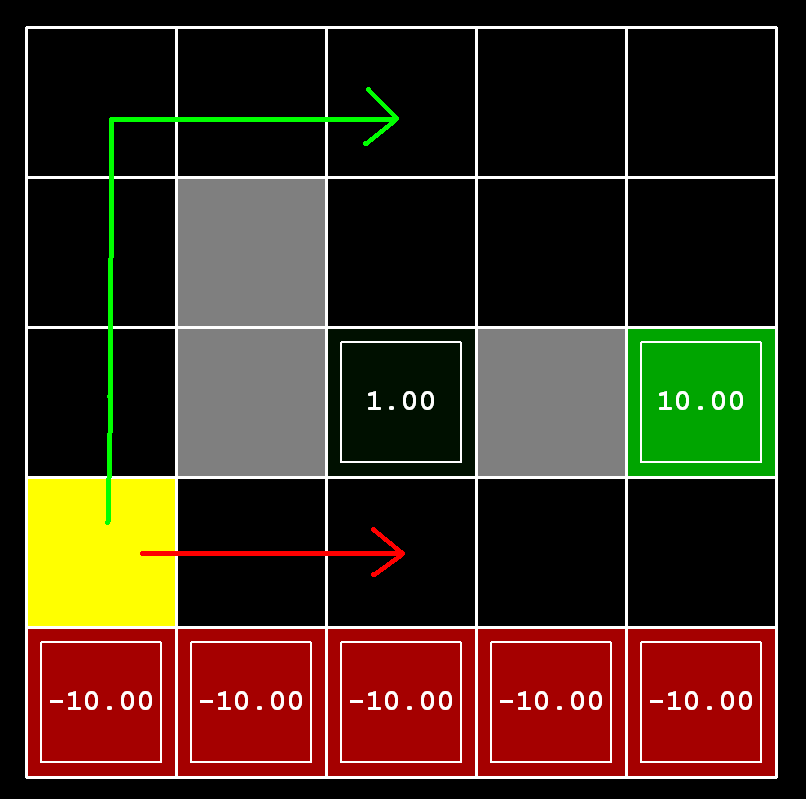
Agent: cart (Action: left, right)
Environment: the mountain
State: Location of the cart (x, y)
Reward: reaching the flag (+10)
Policy: series of actions
outcomes are partly under the control of a decision maker (choosing an action) partly random (probability to a state)
Tabular
- a table to keep track of the policy
- reward corresponding to the state and action pair
- update policy according to elite state and actions
Deep learning
- approximate with neural net
- when the table becomes too big
*caution: randomness in environment
Deep learning
- Agent pick actions with prediction from a MLP classifier on the current state
Tools
Steps
Bellman equations depends on P(s',r|s,a)
What if we don't know P(s',r|s,a)?
Introduction Qπ(s,a) which is the expected gain at a state and action following policy π
Learning from trajectories
which is a sequence of
– states (s)
– actions (a)
– rewards (r)
Model-based: you know P(s'|s,a)
- can apply dynamic programming
- can plan ahead
Model-free: you can sample trajectories
- can try stuff out
- insurance not included
Finding expectation by:
1: Monte-Carlo
2: temporal difference
Don't want agent to stuck with current best action
Balance between using what you learned and trying to find
something even better
ε-greedy
With probability ε take random action;
otherwise, take optimal action
Softmax
Pick action proportional to softmax of shifted
normalized Q-values
(not Doom)
Q-learning will learn to follow the shortest path from the "optimal" policy
Reality: robot will fall due to
epsilon-greedy “exploration"
Introducing SARSA
(not Doom)
Difference:
SARSA gets optimal rewards under current policy
where
Q-learning assume policy would be optimal
(not Doom)
on-policy (e.g. SARSA)
off-policy (e.g. Q-learning)
State space is usually large,
sometimes continuous.
And so is action space;
Approximate agent with a function
Learn Q value using neural network
However, states do have a structure,
similar states have similar action outcomes.
Paper published by Google Deep Mind
to play Atari Breakout in 2015
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
Stacked 4 flames together and use a CNN as an agent (see the screen then take action)
Slides: https://slides.com/cheukting_ho/intro-rl
Course: https://github.com/yandexdataschool/Practical_RL
By Cheuk Ting Ho
Introduction to Reinforcement Learning, overview of different RL strategy and the comparisons.



