





















Kevin Song
I'm a student at UT (that's the one in Austin) who studies things.
Questions
What is the difference between supervised and unsupervised learning?
Supervised: human generates the labels for correct output given the input.
DOG
CAT
Unsupervised: data set somehow generates its own correct output.
For the neural network itself, just 70 billion weights (~30 GB) and the code necessary to run the network (maybe ~15 GB).
For training....all the data used in the training set. For newer GPT models, this is basically the entire internet and then some. Such data can only be stored on "the cloud" (in massive datacenters run by the largest companies).
Both can be true. Human art is "original" but every artist learns from artwork they've seen before.
I don't have a great definition for what it means to be original, so I don't know how to answer this :(
Yes. Even if NeRFs could completely render any scene (they can't), you still can't interact with objects, or do physics with them, or change their appearance (e.g. for artistic reasons).
At the moment, the ability to do this is very limited. We don't fully understand why.
Cynical answer: 🤑🤑🤑🤑
Actual answer: AI can solve really interesting problems, but it's going to be hard to tell what's actually working during the hype cycle.
(Personal take: the true tragedy of AI is that everyone who was hawking Bitcoin turned around and started hawking AI).
(Pause here to old-man-rant).
A flash flood which loses 90% of its intensity can still hit pretty hard.
There is, they're called journals. But even if researchers could get things published there, what incentive would they have to do it?
User selects which functions to use on which nodes.
How do researchers make sure the image examples given to the model are valid?
They don't.
Bad training data from the internet is a huge problem for ML, but I don't know of many systematic efforts to tackle it.
When people come up with processes that don't have an application (like NeRFs), what is the end goal in mind?
"Wouldn't it be cool if we could...."
Scanners, depth sensors, and LASERS
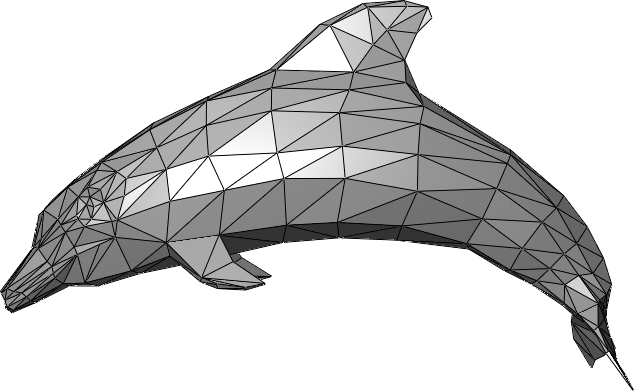
I've claimed throughout this class that 3D data is represented by triangle meshes.
Do we need to know about its interior?
How accurately do we need to know the shape?
Do we need connectivity information or is just the shape okay?
...and many more.
But we might lose some information along the way!
But we can no longer recover the original density function!
Once a full ring of scans has been completed, move the scanner head down (or move the patient up) and scan the next slice.
Reconstruct unknown scene geometry from a sequence of scans.
However, in the NeRF problem, we had sparse input data (very few images) and light stops at a surface.
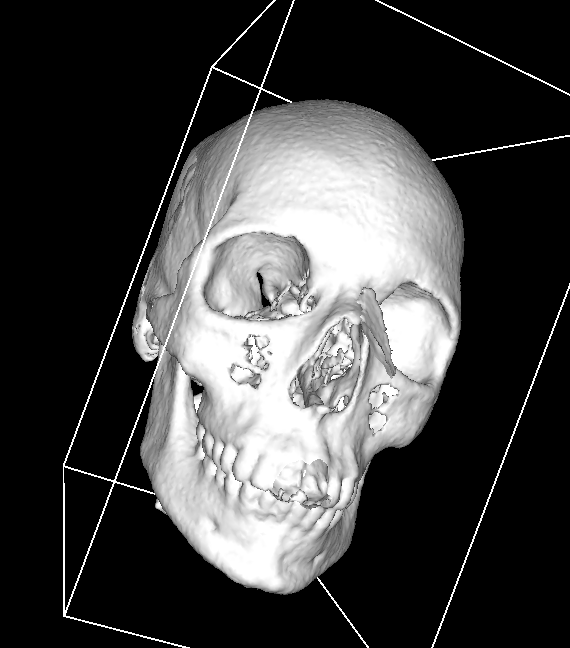
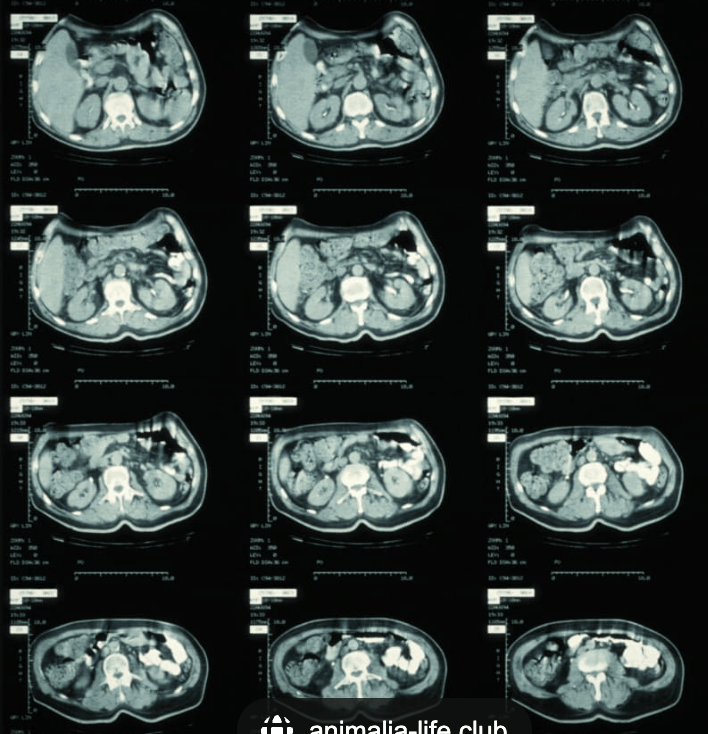
When doing CT scans, we have dense input data (one snapshot every few degrees) and X-rays pass through hard tissue (even bone to a limited degree).
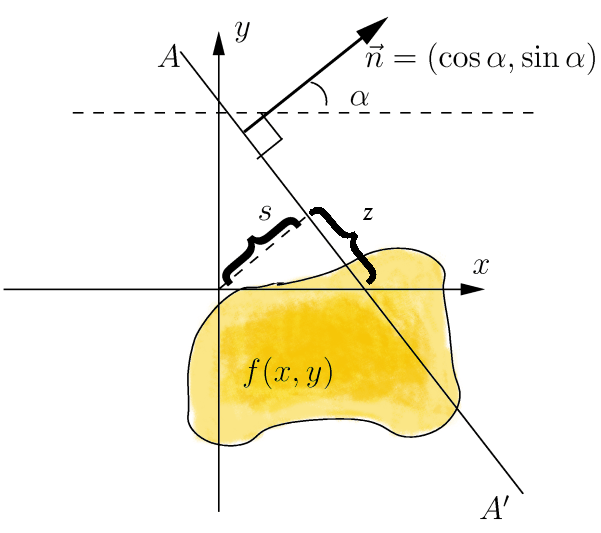
We can recompute the density using the Radon Transform.
Fun fact: the DICOM image format which is used to transmit X-ray and CT data in the US was designed for arbitrary medical use, so it actually has fields that tell you if the patient is human or not. I think this patient is a dog.
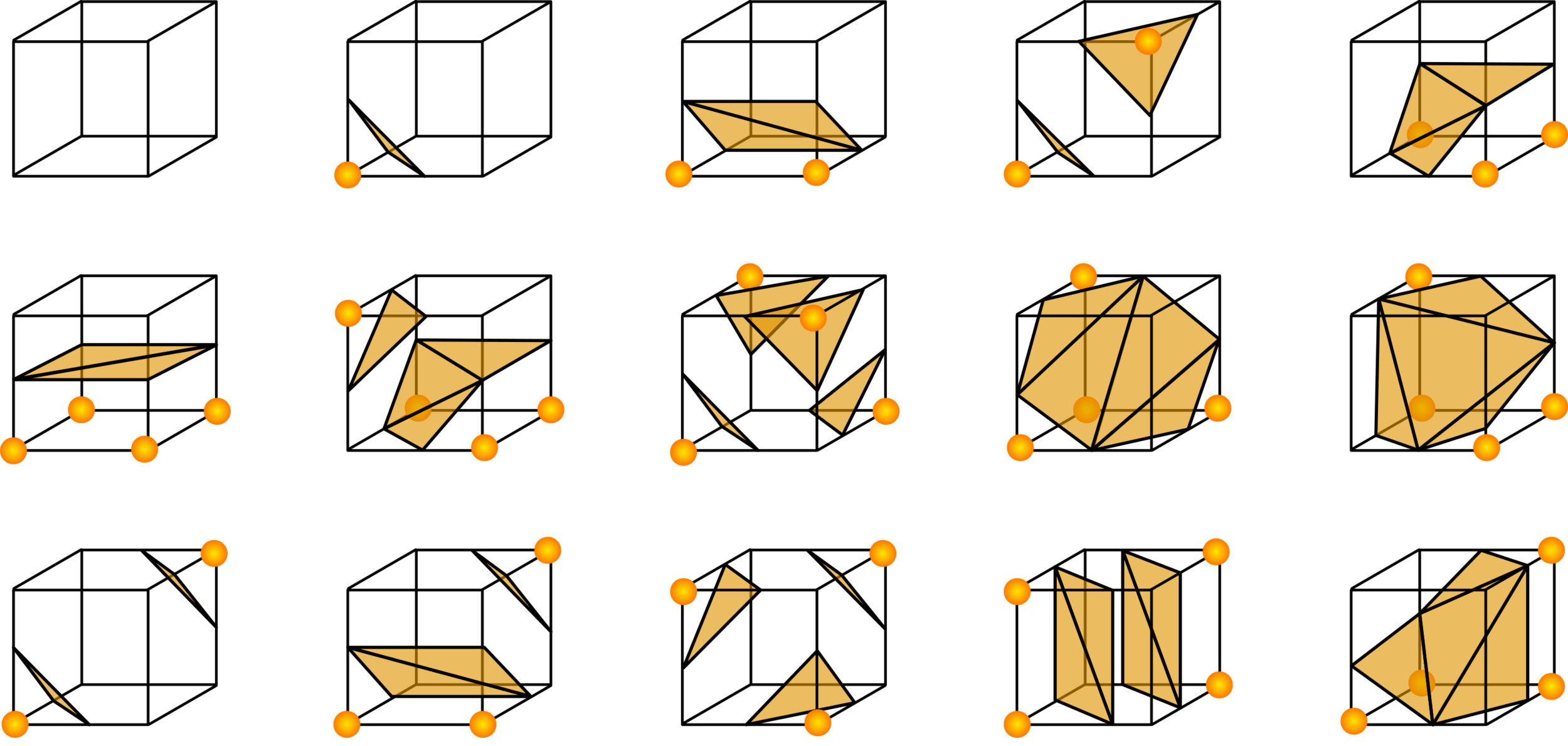
We can extract a triangle mesh from the voxel data the same way we did for 2D data!
Suppose we want to extract the surface with density = 3.0
1.0
4.0
100.0
50.0
We can extract a triangle mesh from the voxel data the same way we did for 2D data!
Suppose we want to extract the surface with density = 3.0
1.0
4.0
100.0
50.0
We can extract a triangle mesh from the voxel data the same way we did for 2D data!
Suppose we want to extract the surface with density = 3.0
1.0
4.0
100.0
50.0
We can extract a triangle mesh from the voxel data the same way we did for 2D data!
Suppose we want to extract the surface with density = 3.0
1.0
4.0
100.0
50.0
In 3D, this yields the famous Marching Cubes algorithm.
We can't make one big enough, and the resulting x-ray exposure would do some pretty nasty things anyways.
For older projects, people built 3D collection arms.
In modern times, we prefer optical methods, since these are faster and cheaper to capture.
Optical = using light.
Three general ways to acquire optical depth data.
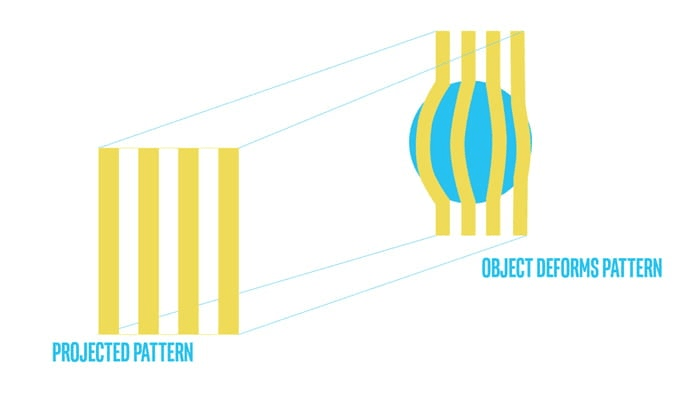
Structured Light
Multi-View
Time-of-flight
👀
Advantages
Disadvantages
FaceID uses structured light to build a 3D depth scan of the user's face.
Note that multiple projection is not an issue, since people don't tend to try to unlock multiple iPhones simultaneously.
Use the fact that it takes time for a photon to hit an object and return. Use an active photon emitter and the time of flight to determine the distance to an object.
You may know the most famous version of this technology, known as LIDAR (Light Detection and Ranging).
ToF measurements like LIDAR can give incredibly accurate readings down to 0.5mm at frame rates of over 120 Hz.
Great when high-accuracy readings are needed from a single sensor with fast refresh.
Downsides: cost ($1000+ per unit) and cannot see visible wavelengths.
If we know the inter-camera distance and the angles to the same point, we can reconstruct how far away the point must be.
How hard can that be?
First, we need to know the directions of the cameras and the intercamera distance very precisely.
Small errors in distance and facing can compound drastically over long distances. Tend to need very precisely placed cameras (e.g. in studio settings) or cameras placed together in a small physical rig.
Pretty hard!
Image from a 2024 paper published from MIT
Don't try to find arbitrary correspondences between photos: track known, fixed points in the 3D world!
A pixel grid of depth values. When coupled to a regular camera, the resulting image data is often referred to as "RGBD" (RGB + Depth).
And so on...
And so on...
And so forth...
And so forth...
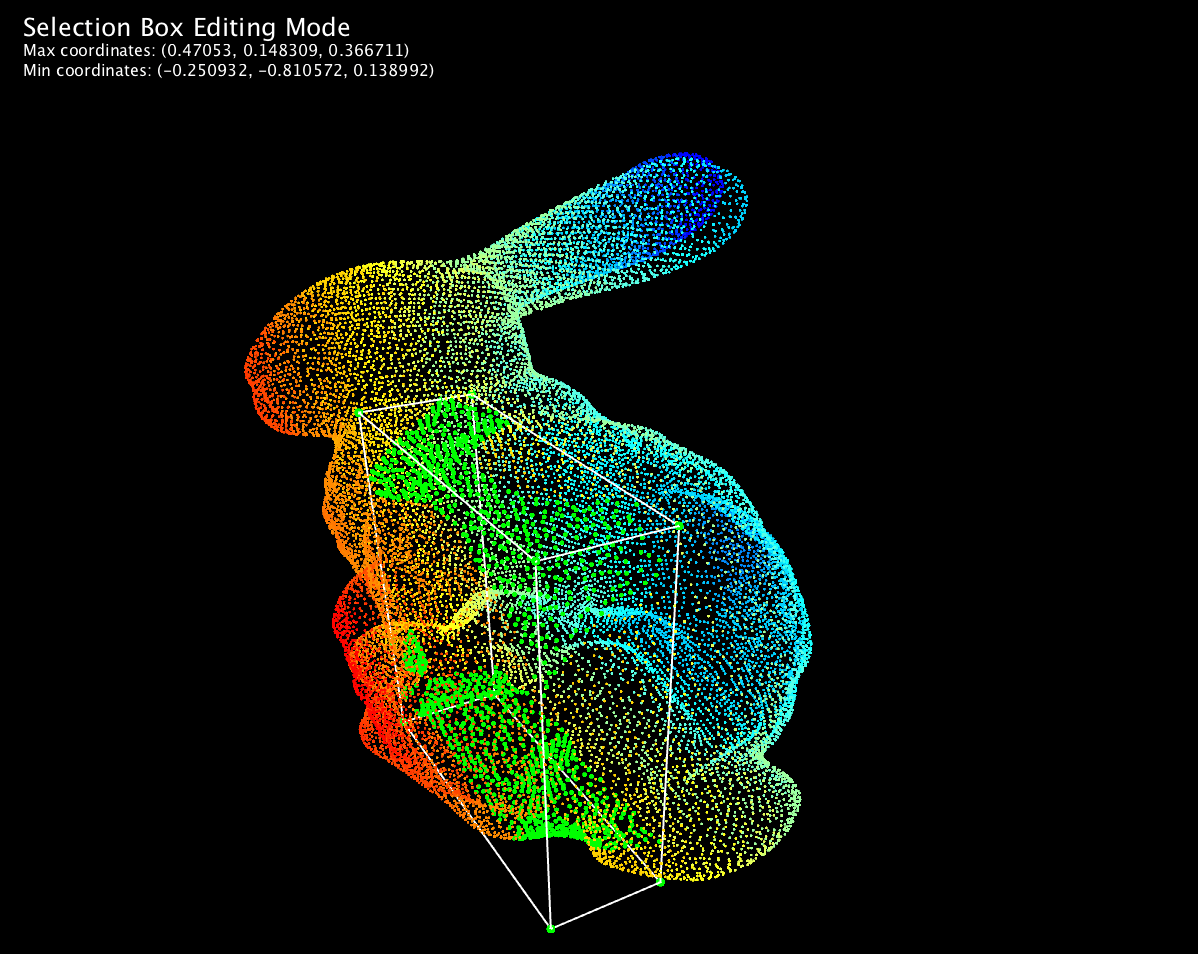
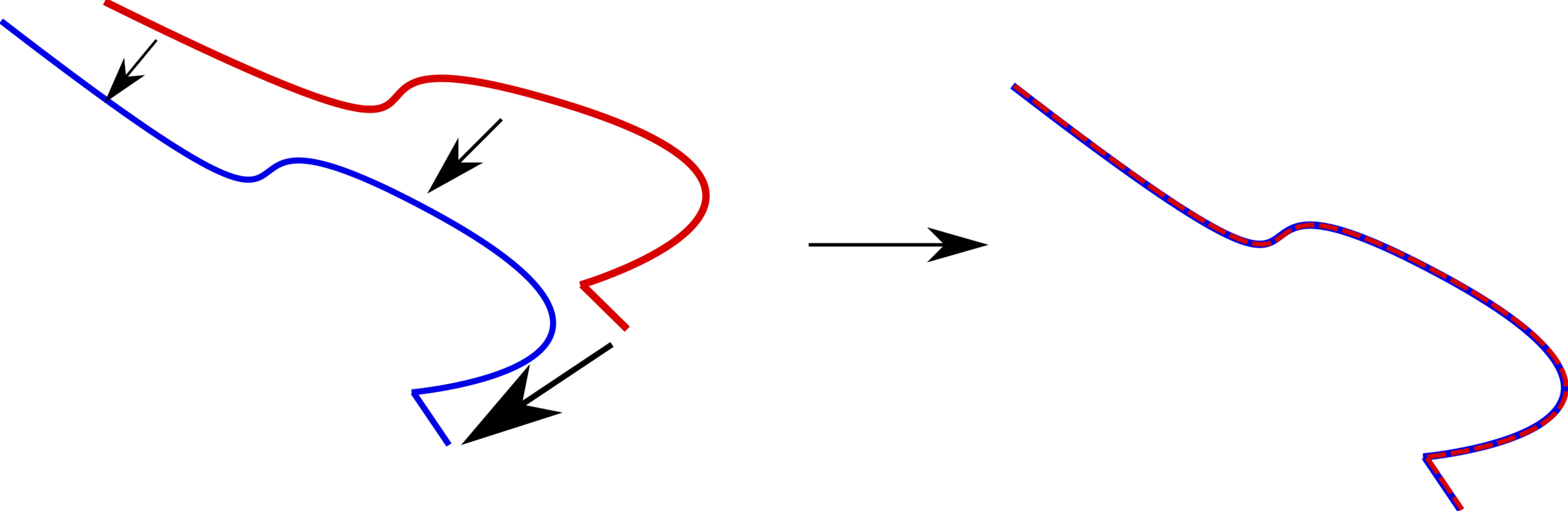
This is the Iterative Closest Points algorithm and it's the basic tool for aligning two shapes in 3D.
Does require good guesses for correspondences and initial poses (can partially be solved by machine learning).
We need to precisely know the locations of these cameras and the distances between them.
These serve two key purposes:
On older films, this was literally done by a human, frame by frame.
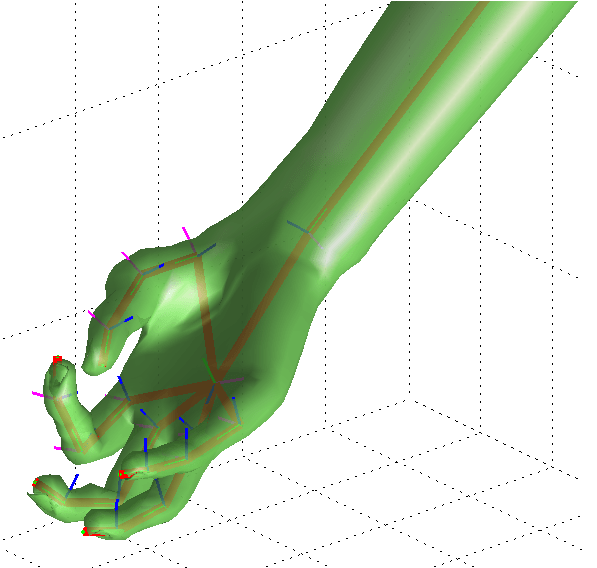
Modern systems use machine learning and coherence of frames: if a keypoint is in one location and we're recording at 60fps, it can only have moved so far in the next frame.
But still a fair bit of error that has to be hand-corrected.
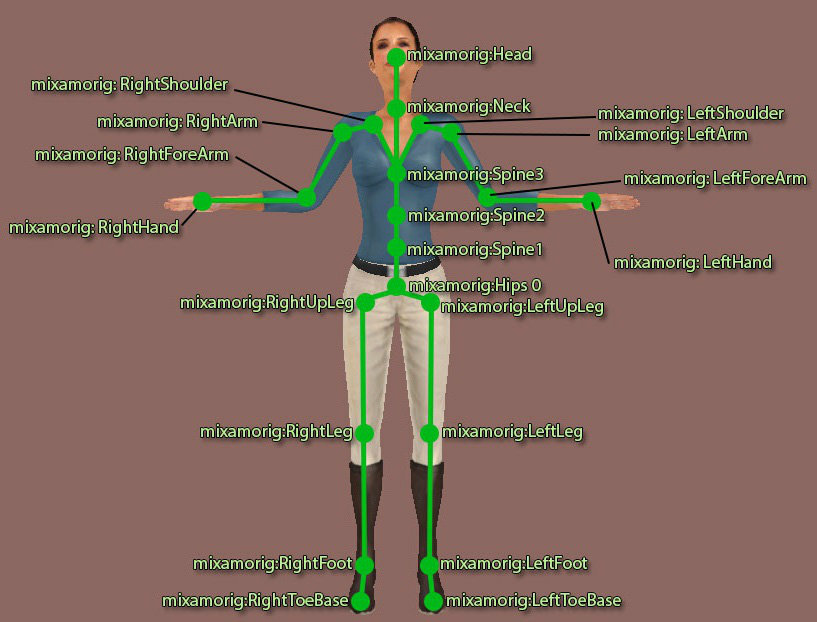
From 3D positions of important skeleton points, we can generated the 3D positions of the character skeleton.
If needed, at this point, we might perform registration (e.g. with ICP) to fix partial captures.
Double-check presentation schedule: a few groups had to be moved!
By Kevin Song




