







Kevin Song
I'm a student at UT (that's the one in Austin) who studies things.
What you don’t use, you don’t pay for. And further: What you do use, you couldn’t hand code any better.
Pay for them even if you don't use them!
a = [1, "1", 1.0]\( O(N) \) indexing
Indirect storage
Green Threads
User-level threads managed by the language runtime.
Can be left unused, but they have to be included in the language runtime regardless.
Garbage Collection
Garbage-collected systems must have all their memory in garbage collection.
Incur the cost of running gc even if we know exactly when all memory can be freed.
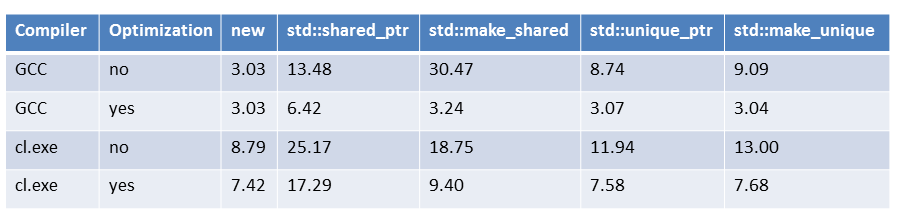
std::unique_ptr
std::vector
Speed difference: tens of seconds in 24 hours.
Element access is identical assembly code to raw array access, because some parts can be done at compile-time.
Vector copy code is 15% faster than handwritten naive copy code!
A: What do we mean by zero cost?
Under the definition that Bjarne Stroustrup gives us, they are zero cost.
But shared pointers are not free! (Not even close!)
From Lecture 0: while it is not true that C++ is a language for experts only, it is a language that requires discipline and knowledge from its users in order to be effective.
Performance matters. But it doesn't always matter where we think it does.
More Zero-Cost Abstractions and Undefined Behavior
A not-quite-zero cost abstraction
void operation_1();
void operation_2();
void operation_3() noexcept;
int main(){
operation_1();
operation_2();
operation_3();
}Pretty much anywhere!
(In C++17, functions labeled 'noexcept' cannot throw)
Exactly what code it inserts will depend on how we implement
Just check every instruction!
int main(){
try{
op1();
}catch(Exception& e){
handler1(e);
}
try{
op2();
}
catch(Exception& e){
handler2(e);
}
op3();
}Execption_Structure x;
int main(){
op1();
if(x.exception_happened){
handler1(x);
}
op2();
if(x.exception_happened){
handler2(x);
}
op3();
if(x.exception_happened){
terminate();
}
}Runtime cost
Compile time cost
Code Complexity Cost
Yes: we have to insert all these additional exception checks--we may also want to optimize by trying to remove some checks (which could be costly!)
In source code? No. In binary code? Oh hell yes. You won't be able to tell what the code is doing underneath all those branches!
Do we have to pay a cost even if we don't actually throw/catch any exceptions?
Yes. In the worst case, we have to insert a branch every other instruction, which at least doubles the runtime of the code
Even though we're not catching exceptions, we still have to include these branches, because we cannot ignore any exceptions.
int main(){
try{
op1();
}catch(Exception& e){
handler1(e);
}
try{
op2();
}
catch(Exception& e){
handler2(e);
}
op3();
}Execption_Structure x;
int main(){
op1();
if(x.exception_happened){
handler1(x);
}
op2();
if(x.exception_happened){
handler2(x);
}
op3();
if(x.exception_happened){
terminate();
}
}Now do it again, but properly this time!
We would like an exception handling framework that is:
The interfaces used for exception handling are defined not by the C++ Standard or the API, but the ABI. This means that every compiler could potentially implement its own exception techniques
There is no guarantee that your compiler implements things the same way!
Instead of checking if an exception occurred at every instruction, we should have some routine which runs when an exception is thrown.
This routine will be responsible for executing the exception.
operation_1();
if(exception){
handle();
}
operation_2();
if(exception){
handle();
}void operation_1(){
if(bad_thing){
__cxa_throw();
}
}
void operation_2(){
if(bad_thing){
__cxa_throw();
}
}How does the exception executor know e.g. whether it's been invoked inside of a try-catch block? How does it know which catch to use?
void operation1(){
if(bad_thing){
__cxa_throw();
}
}
void operation2(){
if(bad_thing){
__cxa_throw();
}
}int main(){
try{
op1();
}catch(Exception& e){
handler1(e);
}
try{
op2();
}
catch(Exception& e){
handler2(e);
}
op3();
}Handle exception? Call terminate?
At the start of a catch block, call __cxa_begin_catch and call __cxa_end_catch at the end--this will install information in some global area about what exception handlers are available at the time.
int main(){
__cxa_begin_catch(handler1);
op1();
__cxa__end_catch(handler1);
__cxa_begin_catch(handler2);
op2();
__cxa__end_catch(handler2);
op3();
}
int main(){
try{
op1();
}catch(Exception& e){
handler1(e);
}
try{
op2();
}
catch(Exception& e){
handler2(e);
}
op3();
}The state records stored by __cxa_begin_catch can be stored in two different locations:
GCC on x86 platforms uses the former, variants on ARM use the latter. The choice of location has a minor-to-moderate impact on runtime performance.
The state includes things like "which exception handlers are active", "where control for those handlers jumps to", and "active variables that need to be cleaned up."
1. When we enter a try/catch block, we use __cxa_begin_catch() to record information about what to do if an exception triggers.
2. If an exception is triggered, __cxa_throw() will use this information to decide which exception handlers to run.
We've actually omitted about 12 steps here, but that should be enough for the basics
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}can catch: DumbException
resume execution at: handler2
destroy stack variables: none
can catch: SillyException
resume execution at: handler1
destroy stack variables: class1
| Exception Type | Resume At | Destroy Var |
|---|---|---|
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
| DumbException | handler2 | class2 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
| DumbException | handler2 | class2 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
| DumbException | handler2 | class2 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}op2 throws a SillyException!
| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
| DumbException | handler2 | class2 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}op2 throws a SillyException!
We look through our handlers from innermost scope to outermost, trying to find a match. If a match is found, execute!
| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
| DumbException | handler2 | class2 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}op2 throws a SillyException!
We look through our handlers from innermost scope to outermost, trying to find a match. If a match is found, execute!
| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
| DumbException | handler2 | class2 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}op2 throws a SillyException!
We look through our handlers from innermost scope to outermost, trying to find a match. If a match is found, execute!
| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
| DumbException | handler2 | class2 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}op2 throws a SillyException!
I found a match! We need to execute the cleanup routines of all blocks below us (destroy class2 + class1), then jump to the handler.
| Exception Type | Resume At | Destroy Var |
|---|---|---|
| SillyException | handler1 | class1 |
| DumbException | handler2 | class2 |
void op1(){
try{
MyClass class2;
op2();
}catch (DumbException& e){
handler2(e);
}
}
int main(){
try{
MyClass class1;
op1();
}catch (SillyException& e){
handler1(e);
}
}op2 throws a SillyException!
I found a match! We need to execute the cleanup routines of all blocks below us (destroy class2 + class1), then jump to the handler.
Runtime cost
Compile time cost
Code Complexity Cost
Very nearly. There is no visible cost if no exception is actually thrown...but the cleanup code occupies space in the instruction cache, potentially slowing down branches a little.
A small cost. We need to add some of the extra functions and cleanup information.
A complexity cost to implementing the standard library. Otherwise, not an unthinkably large cost.
Do we pay if we don't actually catch any exceptions? (Throwing might happen anyways)
Could you write this better?
...depends on your error handling needs. If you don't need the full power of exceptions (arbitrary distance from throw to catch, pre-emption of executing code), you can probably do better.
No.
But they turn out to be useful enough in a variety of situations (and close enough to zero-cost) that they're worth including anyways.
Somebody thought long and hard about what should happen in certain cases, and came to the conclusion that the compiler should be allowed to do anything it wants to do!
Why did they come to this conclusion?
int32_t x = 5;
x <<= 31; // Just fine!
x <<= 32; // Undefined!By Thomas Nguyen - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=46809082
The 8086 did not have hardware to carry out an arbitrary shift operation.
Instead, it would shift your register one position at a time, using one clock cycle per shift.
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
|---|
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
|---|
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
|---|
You could provide an 8-bit register as the shift amount.
You could provide an 8-bit register as the shift amount.
So...you could shift up to 255 times, using 1 shift per clock cycle. Meaning one instruction could take 255 cycles.
Intel later realized this was a terrible idea, and every single x86 processor since then has masked shifts to the lower 5 bits (effectively putting a cap of 31 on the shift amount).
But now we have a problem!
int x = 173, y = 33;
x <<= y;| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
|---|
On 8086
On 80286
Shift Register
Mask
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
|---|
Shift Amount
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
|---|
Final value of x
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
|---|
Final value of x
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
|---|
The same shift instruction results in different outcomes on different processors!
But wait, it gets worse!
Some CPUs treat anything greater than a 31-bit shift as a zero shift (not implementing masking like the 80286).
There are only two things the compiler can do to mitigate this:
Check the result of every shift operation for overshifts, and insert fixup code if this occurs.
Pros:
Cons:
Declare that if you shift by too much, you're on your own.
Pros:
Cons:
What happens when you dereference the pointer referring to address 0 on different CPUs?
| Architecture | Behavior |
|---|---|
| x86-64, 64-bit mode | Illegal Page Fault (segfault) |
| x86-64, real mode | Completely legal! |
| PDP-11 | Always contains value zero. |
| Other CPUs | Access memory-mapped I/O |
...but NULL doesn't even have to be zero! The standard just defines it as a pointer which is "different from a pointer to any object or function"
We really only have two choices here:
Most CPUs use twos-complement.
Some use ones-complement.
That one wacky Russian ternary computer doesn't even use binary representations.
Either have to do runtime checks or declare behavior to be undefined
A C++ compiler may transform the program in any way it likes, including ways that break the rules of the standard, as long as all observable behavior of the program is as if the rules were obeyed.
int x = foo();
if (x > 0) {
int y = x + 5;
int z = y / 4;
}Division is slow!
What we'd like to be able to do: optimize division statements into bitshifts
int x = foo();
int y = x + 5;
int z = y / 4;int x = foo();
int y = x + 5;
int z = y >> 2;Is this legal?
-1 >> 2 == 4611686018427387903
int x = foo();
if (x > 0){
int y = x + 5;
int z = y / 4;
}int x = foo();
if (x > 0){
int y = x + 5;
int z = y >> 2;
}Is this legal?
Compiler Reasoning:
int x = foo();
if (x > 0){
int y = x + 5;
int z = y / 4;
}int x = foo();
if (x > 0){
int y = x + 5;
int z = y >> 2;
}Is this legal?
Compiler Reasoning:
Is this a valid assumption?
Most of the difficulty of the project is in prime(), hamming(), and pi(), so try to have the other functions (particularly map, filter, and chain) working before leaving for break!
This is the Wednesday after we get back!
(changed from the original date of Monday after Thanksgiving)
Will close sometime after 6:30pm today.
Currently on Piazza.
Name and EID
One thing you learned today (can be "nothing")
One question you have about the material. If you leave this blank, you will be docked points.
If you do not want your question to be put on Piazza, please write the letters NPZ and circle them.
By Kevin Song
Why does UB exist?



