In die Tiefe gehen:
Lektüre und Nutzung
digitaler Repräsentationen historischer Textzeugen.
Christian Thomas (HU & BBAW)


"Lektüre im Zeitalter digitaler Medien", HU, IdL, 29./20.9.17
Gliederung
Teil I:
Thesen zur Lektüre (von (digitalen) Editionen)
im Zeitalter digitaler Medien;
Folgen für Produktion und Rezeption
Teil II:
Illustration der Thesen anhand konkreter Nutzungsbeispiele einer digitalen Edition
"Lektüre im Zeitalter digitaler Medien", HU, IdL, 29./20.9.17
Thesen zur 'Lektüre' digitaler Editionen:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Die Exploration der Grunddaten eröffnet weitere, eigene Lektüren (alternativ, konkurrierend, kontextualisierend z. Edition).
"Lektüre im Zeitalter digitaler Medien", HU, IdL, 29./20.9.17
Thesen zur 'Lektüre' digitaler Editionen:
-
Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Edition = Auswahl, Interpretation, i.d.R. Vereinfachung.
- Die Edition wird über ein Interface – (e-)Buch, Website, HTML-/PDF-/etc.-Ausgabe – zugänglich gemacht und die Präsentation der Grunddaten wird für dieses Interface optimiert ==> weitere Auswahl, Interpretation, i.d.R. Vereinfachung.
- Beides sollte ausführlich dokumentiert werden, denn:
- Beide Prozesse sollten bei der Lektüre berücksichtigt werden!
"Lektüre im Zeitalter digitaler Medien", HU, IdL, 29./20.9.17
Thesen zur 'Lektüre' digitaler Editionen:
-
Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Das Interface stellt den edierten Text dar, dabei je nach Medium mehr oder weniger tief strukturiert/annotiert.
- Die zugrunde liegenden Daten (und Metadaten) sind i.d.R. reichhaltiger als im Interface darstellbar; sie enthalten mehr Informationen als dort recherchierbar. (Bsp. Hybrid-Ed. MoE)
- > zur Lektüre: Menschen und Maschinen sollten diese Daten lesen können (und lesen dürfen)! (Negativ-Bsp. Asiatische Banise, s. Rez. AR)
Inspiriert vom Symposium DSEs as Interfaces (Graz 16), #DH2017, esp. @eerstewart1, @GretaFranzini #1, @GretaFranzini#2 u.v.a.
"Lektüre im Zeitalter digitaler Medien", HU, IdL, 29./20.9.17
Thesen zur 'Lektüre' digitaler Editionen:
-
Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Das Interface ((e-)Buch, Website, HTML-/PDF-/etc.-Ausgabe) zeigt 1, 2, 3, ... von n Lektürewegen, kuratiert durch EditorIn.
- Die zugrunde liegenden Daten (und Metadaten) sind i.d.R. reichhaltiger als im Interface darstellbar; d.h. sie enthalten mehr Informationen als dort recherchierbar. (Bsp. Hybrid-Ed. MoE)
- > zur Lektüre: Menschen und Maschinen sollten diese Daten lesen können (und lesen dürfen)! (Negativ-Bsp. Asiatische Banise, s. Rez. AR)
Inspiriert vom Symposium DSEs as Interfaces (Graz 16), #DH2017, esp. @eerstewart1, @GretaFranzini #1, @GretaFranzini#2 u.v.a.
NB zum erwähnten u. vielen anderen Negativbeispielen:
Der fehlende Zugang zu den Grunddaten bzw. deren ständiger Verlust hat keine technischen Ursachen.
Es handelt sich v.a. um ein sozialisatorisches
(und auch förderpolitisches) Problem.
"Lektüre im Zeitalter digitaler Medien", HU, IdL, 29./20.9.17
Thesen zur 'Lektüre' digitaler Editionen:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
- Die Exploration der Grunddaten eröffnet weitere, eigene Lektüren (alternativ, konkurrierend, kontextualisierend z. Edition).
==> Diese können u. sollten durch die LeserInnen/NutzerInnen der Edition erschlossen werden ==> Lektüre im Digitalen.
"Lektüre im Zeitalter digitaler Medien", HU, IdL, 29./20.9.17
Thesen zur 'Lektüre' digitaler Editionen:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
-
Exploration der Grunddaten durch NutzerInnen = n Lektüren; Voraussetzungen dafür sind unter anderem:
- Gute Dokumentation (inhaltlich, editorisch und technisch)
- Zugang zu den Grunddaten & 'Data Literacy'
- Zugang zu geeigneten Tools¹ & 'Tool Literacy' (¹ z.B. für TEI-XML)
- i.d.R. erforderlich: Datenvor- bzw. aufbereitung; -visualisierung
- Dokumentation der eigenen Lektüre (inhaltlich, (editorisch,) technisch); ggf. Bereitstellung der erzeugten Daten (z.B. edissPlus)
"Lektüre im Zeitalter digitaler Medien", HU, IdL, 29./20.9.17
Einige Folgerungen für Produktion und Rezeption:
- Eine Edition stellt 1, 2, 3, ... von n Lektürevorschlägen dar.
-
Exploration der Grunddaten durch NutzerInnen = n Lektüren; daher umso wichtiger:
- Lektürewege als vom Editor/in ausgewählt kennzeichnen.
- Nicht (nur) das Interface wichtig, sondern Reichhaltigkeit u. flexible Nutzbarkeit der Daten (für Menschen u. Maschinen).
- Traditionell: Lektüre auf autorisierten Pfaden (via Interface)
- +Digital: Exploration der Daten (via Download/API/...)
= Lektüre auf eigenen Pfaden, lesend und mit Tools.
II: Illustration der Thesen
Hintergrund:
Projekt "Hidden Kosmos":
Edition/Textkorpus
Nachschriften der 'Kosmos-Vorträge' A. v. Humboldts


Humboldts 'Kosmos-Vorträge'
- Berlin, 1827/28, zwei Kurse:
- 62 Stunden Berliner Universität, 3.11.1827–26.04.1828,
ca. 400 Studis, Staff, Gasthörer - 16 Stunden Sing-Akademie,
6.12.1827–27.03.1828,
ca. 1000 Pers., 'gemischtes' Publikum
- 62 Stunden Berliner Universität, 3.11.1827–26.04.1828,
... ein Meilenstein der
Wissenschaftspopularisierung
(Hamel/Tiemann 1993)

(c) Schiller-Nationalmuseum, Marbach
Humboldts 'Kosmos-Vorträge'
- Berlin, 1827/28; ! ≠ Kosmos, 1845–62
- keine autorisierte Publikation der Vorträge durch Humboldt
- A.v.H.s ursprüngliche Manuskripte
im Nachl. verstreut, aber (z.T.) erhalten
– entgegen Humboldts Angaben:
Bei freier Rede habe ich [...]
nichts über meine Vorträge schriftlich aufgezeichnet
(A.v.H in der 'Vorrede' zum Kosmos, Bd. 1, S. X.)
Nachl. A.v.H., Gr. K. 8, Nr. 15, Bl. 33

Humboldts 'Kosmos-Vorträge'
- Berlin, 1827/28; ! ≠ Kosmos, 1845–62
- keine autorisierte Publikation der Vorträge durch Humboldt
- Humboldt verbat sich Druck von Nachschriften, "Eingriff in mein Eigenthum" (Spenersche Zeitung, 12.12.1827)
nichts […] widerwärtiger, als publicirt
zu sehen, was ein Gemisch von Gehörtem
und Selbstzugesetztem ist.“
(A.v.H an R. Zeune, Berlin, 16.2.1857)
Anonym (Hrsg.) 1934
Hamel/Tiemann (Hrsg.) 1993 [2. A. 2004]


Projekt "Hidden Kosmos"

≈ 3600 Seiten,
≈ 4,5M Zeichen,
≈ 660K Tokens,
≈ 103K Types.
Projekt "Hidden Kosmos"

≈ 3600 Seiten,
≈ 4,5M Zeichen,
≈ 660K Tokens,
≈ 103K Types.
Nachschriften der 'Kosmos-Vorträge' A. v. Humboldts

| Projekt- Förderung |
Texterfassung und -anntoation | Publikation und ling. Erschließg. | Nachhaltigkeit & Dissemination |
|---|

Nachschriften der 'Kosmos-Vorträge' A. v. Humboldts
| Texterfassung und -anntoation | Publikation und ling. Erschließg. |
|---|
Texterfassung und -Annotation gemäß P5 Text Enoding Initiative
“The TEI-C is… a consortium which collectively develops and maintains
a standard for the representation of texts in digital form.” (http://www.tei-c.org/)
TEI-C = Herausgeber der TEI Guidelines:
- XML-basierter, freier, internationaler (de facto-) Standard
- umfassend dokumentiert
- plattformunabhängig, flexibel nutzbar
- menschen- & maschinenlesbar
- generische und TEI-spezifische Tools
- (prinzipiell) interoperabel

Texterfassung und -Annotation gemäß P5 Text Enoding Initiative
TEI-C = Herausgeber der TEI Guidelines:
- XML-basierter, freier,
internationaler (de facto-) Standard - umfassend dokumentiert
- plattformunabhängig, flexibel nutzbar
- menschen- & maschinenlesbar
- generische und TEI-spezifische Tools
- (prinzipiell) interoperabel

Aktuelle Version: 3.2.0., last updated
10th July 2017; as PDF: 1891 pp.
http://www.tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf
TEI-XML gemäß DTA-Basisformat


TEI-XML gemäß DTA-Basisformat
> Haaf/Geyken/Wiegand: The DTA “Base Format”: A TEI Subset for the Compilation of a Large Reference Corpus of Printed Text from Multiple Sources, In: jTEI 8, 2014-2015, http://jtei.revues.org/1114.
Das DTA-Basisformat DTABf, http://www.deutschestextarchiv.de/doku/basisformat/
- = echte Untermenge des TEI-P5 Tagsets
-
Ziele: Reichhaltigkeit der TEI-Richtlinien reduzieren,
nur je eine, eindeutige Tagging-Lösung vorgeben - > Reduktion der Elementauswahl,
Festlegung erlaubter Attribute und Werte - Komponenten: Dokumentation, ODD, RelaxNG
- DTABf = Ausgangsformat für DTA-Tools & (TEI-)XML-Tools
Umwandlung in HTML mit XSLT
<!-- processing-instruction, RNG-Schema, Schematron-Regelsatz usw. -->
<?xml version="1.0" encoding="UTF-8"?>
<?xml-model href="http://www.deutschestextarchiv.de/basisformat_ms.rng" type="application/xml" schematypens="http://relaxng.org/ns/structure/1.0"?>
<?xml-model href="http://www.deutschestextarchiv.de/basisformat.sch" type="application/xml" schematypens="http://purl.oclc.org/dsdl/schematron"?>
<!-- Wurzelelement mit namespace -->
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>[Metadaten]</teiHeader>
<text>
<front>[Elemente vor Beginn des Buchtextes]</front>
<body> <!-- Textkörper -->
<p> <!-- Beginn eines Absatzes (öffnender Tag des Elements <p>) -->
TEXT, <hi rendition="#b">FETTER TEXT</hi><lb/> <!-- Zeilenwechsel -->
<del rendition="#erased">GESTRICHENER TEXT (ausrasiert)</del><lb/> <!-- Zeilenwechsel -->
</p> <!-- Ende eines Absatzes (schließender Tag des Elements <p>) -->
</body>
<back>[Elemente nach Abschluss des Buchtextes]</back>
</text>
</TEI>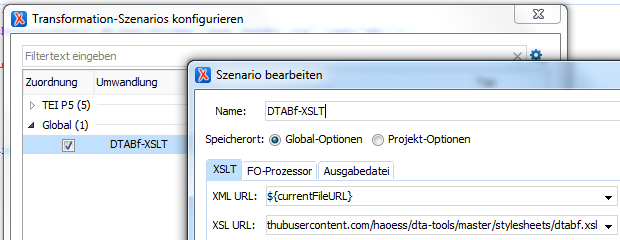
<!-- processing-instruction, RNG-Schema, Schematron-Regelsatz usw. -->
<?xml version="1.0" encoding="UTF-8"?>
<?xml-model href="http://www.deutschestextarchiv.de/basisformat_ms.rng" type="application/xml" schematypens="http://relaxng.org/ns/structure/1.0"?>
<?xml-model href="http://www.deutschestextarchiv.de/basisformat.sch" type="application/xml" schematypens="http://purl.oclc.org/dsdl/schematron"?>
<!-- Wurzelelement mit namespace -->
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>[Metadaten]</teiHeader>
<text>
<front>[Elemente vor Beginn des Buchtextes]</front>
<body> <!-- Textkörper -->
<p> <!-- Beginn eines Absatzes (öffnender Tag des Elements <p>) -->
TEXT, <hi rendition="#b">FETTER TEXT</hi><lb/> <!-- Zeilenwechsel -->
<del rendition="#erased">GESTRICHENER TEXT (ausrasiert)</del><lb/> <!-- Zeilenwechsel -->
</p> <!-- Ende eines Absatzes (schließender Tag des Elements <p>) -->
</body>
<back>[Elemente nach Abschluss des Buchtextes]</back>
</text>
</TEI>
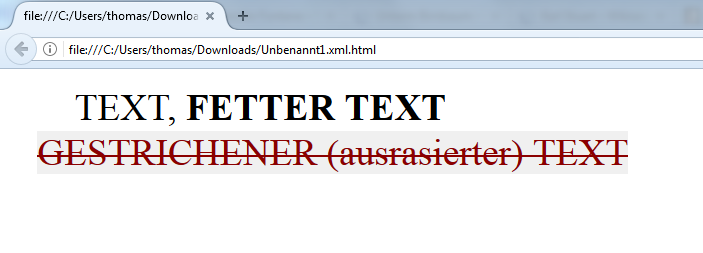
Umwandlung in HTML mit XSLT
Texterfassung und -Annotation

- erweitertes DTA-Basisformat (DTABf):
DTABf für Manuskripte (DTABf-M) (jTEI-Artikel im Ersch.) - Metadaten, Dokument-Struktur, 'Typographie'
Texterfassung und -Annotation
- DTABf für Manuskripte (DTABf-M) (jTEI-Artikel im Ersch.)
- Manuskript-typische Textmerkmale wie Überschreibungen, @hand-Wechsel, <metamark>s u.a.

Texterfassung und -Annotation
- Manuskript-typische Textmerkmale wie Überschreibungen, @hand-Wechsel, <metamark>s u.a.
-
= wichtig (nicht nur)
für Nachschriften: Eingriffe Dritter, Unsicherheiten und Fehler(!) der Schreiber usw.
Texterfassung und -Annotation:
Nutzungsmöglichkeiten
Beispiel: Bleistift-Gebrauch in parthey_msgermqu1711_1828 (XML)

Texterfassung und -Annotation:
Nutzungsmöglichkeiten
Beispiel: Bleistift-Gebrauch in parthey_msgermqu1711_1828 (XML)

Texterfassung und -Annotation:
Nutzungsmöglichkeiten
Beispiel: Bleistift-Gebrauch in parthey_msgermqu1711_1828 (XML)
> Mehrzahl im Abschnitt Geographie des Organischen
- 54. St.: Kennzeichen des Organischen
- 55.–57. St.: Geographie der Pflanzen
- 58. St.: Geographie der Thiere
Texterfassung und -Annotation
- Auszeichnung von <persName> mit @ref GND/VIAF/Wikidata/...
<item>3, die <hi rendition="#u">englischen</hi> Messungen unter dem
General <persName resp="#CT" ref="http://d-nb.info/gnd/130800600">
R.<metamark><space dim="horizontal"/></metamark></persName>
<metamark>(?)</metamark> und
<persName resp="#CT" ref="http://d-nb.info/gnd/1055317457">M<metamark>....</metamark></persName>
<add place="right"><metamark>?</metamark></add><lb/>
<!-- [...] --> <item>4, Drei grosse Messungen in <hi rendition="#u">Ostindien</hi> von dem
General <persName resp="#CT" ref="http://d-nb.info/gnd/117574406">
L<metamark><space dim="horizontal"/></metamark></persName>
<metamark>?</metamark><lb/>
und <persName>T<metamark><space dim="horizontal"/></metamark></persName> <metamark>?</metamark></item><lb/>
Texterfassung und -Annotation
- Auszeichnung von <persName> mit @ref GND/VIAF/Wikidata/...

<choice><abbr>Rſe</abbr><expan resp="#SB">Reiſe</expan></choice> <choice><abbr>ds</abbr><expan resp="#SB">des</expan></choice>
<hi rendition="#aq">
<persName resp="#SB" ref="http://d-nb.info/gnd/100648282">
Kuki</persName></hi><lb/>
Texterfassung und -Annotation


Texterfassung und -Annotation
- Ansetzung vs. Vorlage:
- Welche Namen waren dem Publikum bekannt, welche nicht?
- Anzahl der Vorkommen pro Nachschrift und insgesamt:
- z.B. Uni vs. Sing-Akad.: Welches Personal für welchen Kurs?
- Ältere vs. aktuelle Forschung: Nachwuchsförderer A.v.H?
- Kosmos-Vorträge auf der Höhe der wiss. Forschung der Zeit?
- Welcher Nachschreiber 'überhört' welche Personen?
- Vernetzung: API/BEACON:
- z.B. Porträtindex/Wikimedia Comm.s, edition-humboldt.de ...
Personenregister: Nutzungsmöglichkeiten und Anschlussfragen


Siehe auch: Instrumente

Siehe auch: Bibliographie

Zugriff auf die Texte via DTA









Text-Bild-Ansicht:
- Text-Darstellung via XSLT-Transformation aus DTABf-M (=XML)
- z.B. HTML: inkl. graphischer Umsetzung einiger Elemente der Annotation


dies fand
<subst>
<del rendition="#s" hand="#pencil">
<subst>
<del rendition="#ow">
<supplied reason="covered" cert="high" resp="#CT">ich</supplied>
</del>
<add place="across" hand="#ink2">
<persName ref="http://d-nb.info/gnd/118554700">Humbold</persName></hi>
</add>
</subst>
</del>
<add place="superlinear" hand="#pencil">ich</add>
</subst> auf dem Chimboraßo,
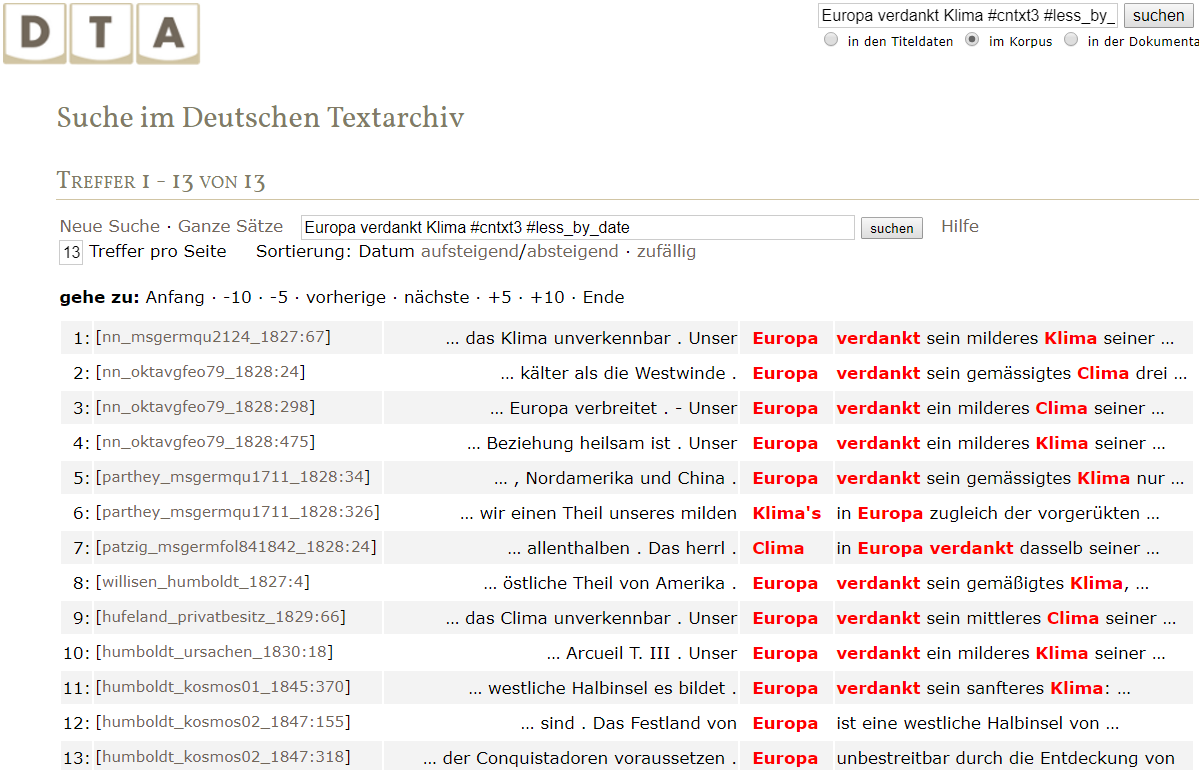
<!-- Beispiel vereinfacht: <hi> entfernt, cf. http://www.deutschestextarchiv.de/nn_msgermqu2345_1827/17 -->Zugriff auf die Texte via DTA/DDC
http://www.deutschestextarchiv.de/search/ddc/search?ctx=8&q=Europa%20verdankt%20Clima%20%23cntxt3%20%23less_by_date%20;start=1;limit=13;fmt=kwic
DTA/DDC, GermaNet integriert
DDC-Suche mit GermaNet-Erweiterung, Synset "Grundstoff; Urstoff"



@ref-erenzieren mit Normdaten

<!-- [...] --> <persName ref="http://d-nb.info/gnd/118534912">Franklin</persName><lb/>
hat die wichtige Entdeckung gemacht, wie man nach dem<lb/>Projekt "Hidden Kosmos"
Ziel: Publikation sämtlicher bis dato bekannter Nachschriften verschiedener Hörer der 'Kosmos-Vorträge' (1827/28):
- Ermittlung bekannter und weiterer Nachschriften,
- Bilddigitalisierung, Volltexterfassung, Annotation (TEI-XML),
- digitale Publikation im Deutschen Textarchiv,
- exemplarische Verknüpfung der Dokumente,
[somit Humboldts] Vorlesungen
als Forschungsfeld erstmals erschließen.
(Erdmann/Hug/Kassung/Thomas: Antrag auf Förderung des Projekts, Exzellenz-Initiative HU)


<!-- [...] --> <persName ref="http://d-nb.info/gnd/118534912">Franklin</persName><lb/>
hat die wichtige Entdeckung gemacht, wie man nach dem<lb/>@ref-erenzieren mit Normdaten
A picture
Version A
Die Natur ist
Einheit und Vielheit,
sie ist der Inbegriff der Naturdinge und
Naturkräfte...
Version B
Die Natur ſelbſt iſt
Einheit in der Vielheit;
ſie iſt der Inbegriff der Naturdinge und der Naturkräfte...

Humboldt, Alexander von: Kosmos. Entwurf einer physischen Weltbeschreibung. Bd. 1. Stuttgart u. a., 1845, S. 5
Folien zum Symposium "Lektüre im Zeitalter digitaler Medien", HU Berlin, IdL, 29.–30. September 2017
By Christian Thomas



