




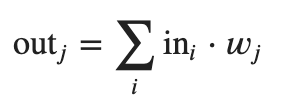
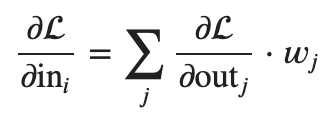
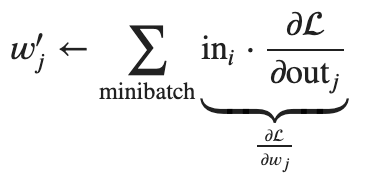






cirquit
PhD student with a focus on machine learning, distributed systems and functional programming.
Alexander Isenko
September '23
1
5th year PhD student (expected graduation in May '24)
Interests: Distributed DL, Performance Optimization
Alexander Isenko, Ruben Mayer, Jeffrey Jedele, Hans-Arno Jacobsen
ACM SIGMOD International Conference of Data 2022
Alexander Isenko, Ruben Mayer, Hans-Arno Jacobsen
VLDB 2024
2
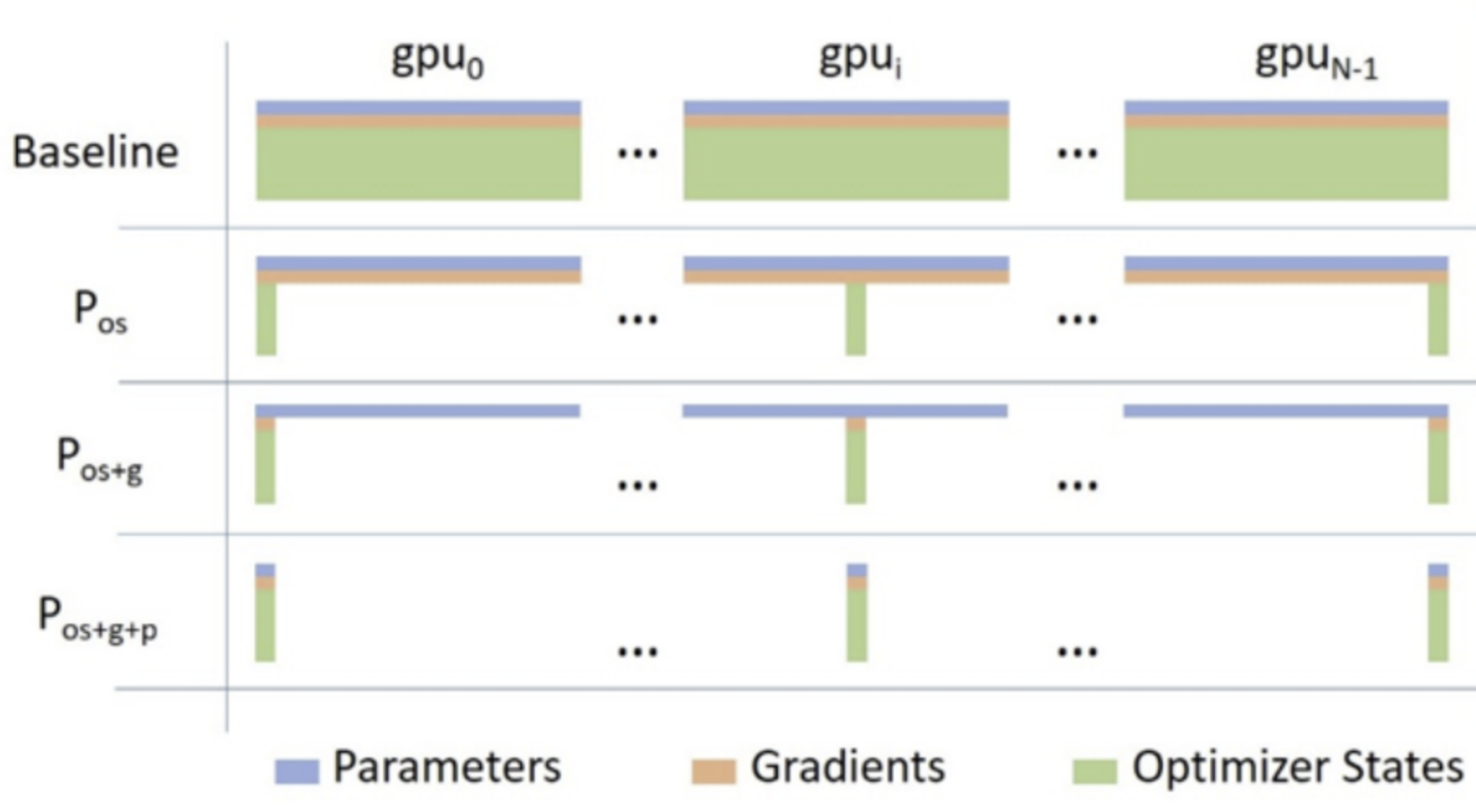
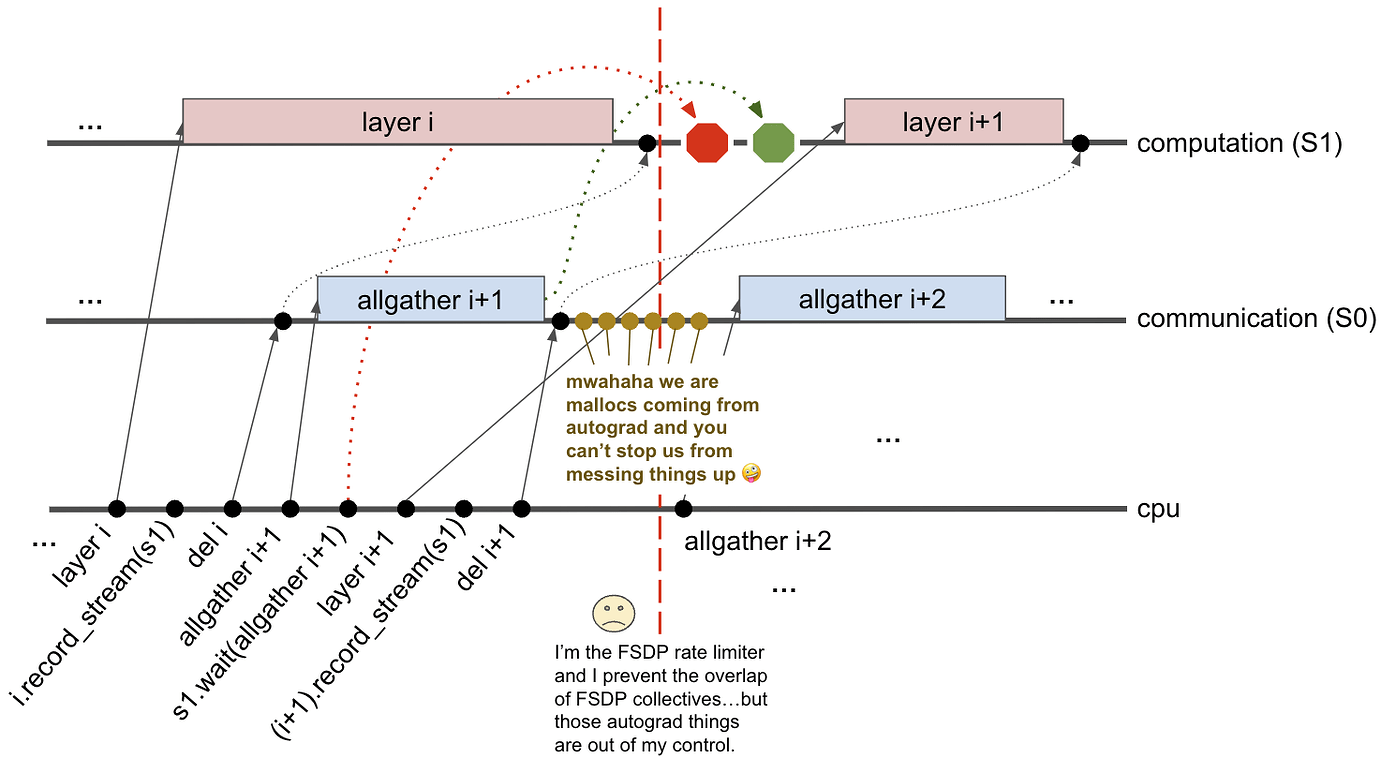
Distributed Data Parallel (DDP)
Fully Sharded Data Parallel (FSDP) [1]
Full Model
Forward
Backward
All-Reduce
opt.step()
Backward
GPU #1
Shard
All-Gather
Forward
All-Gather
For all layers
For all layers
ReduceSctr.
opt.step()
GPU #2
Full Model
Forward
Backward
All-Reduce
opt.step()
Backward
Shard
All-Gather
Forward
All-Gather
ReduceSctr.
opt.step()
GPU #1
GPU #2
Grads
Weights
Weights
Grads
3
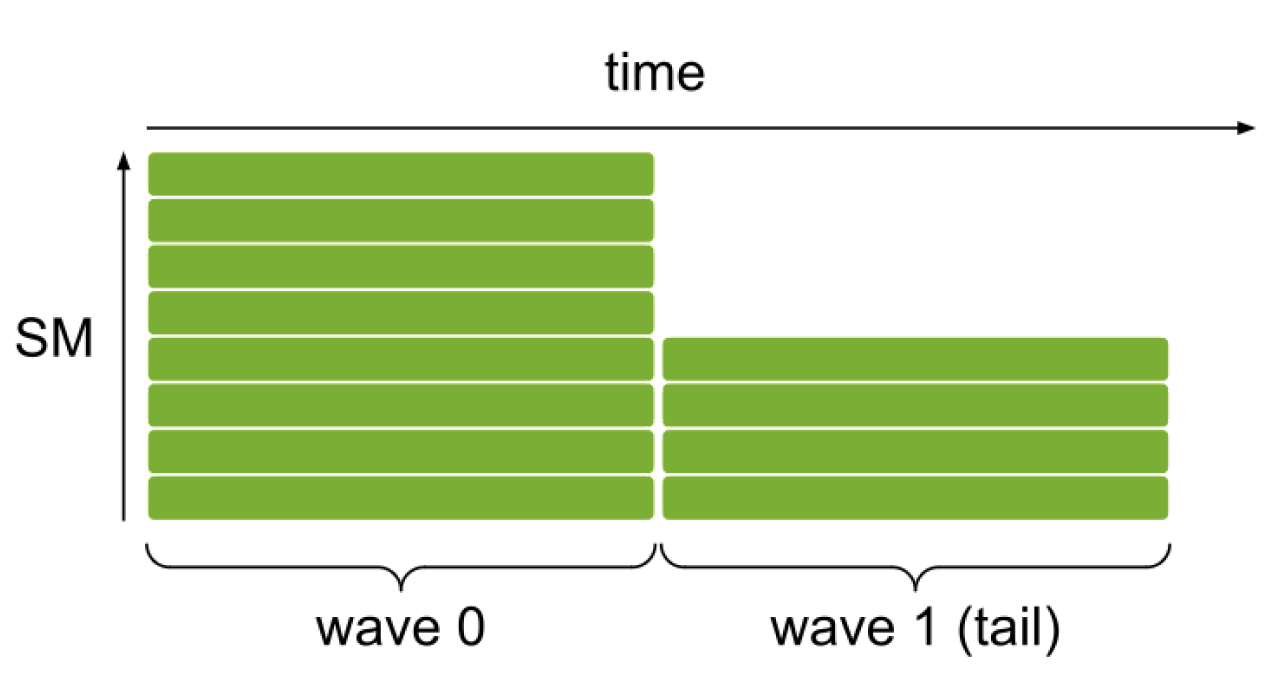
Increased memory size enables higher minibatch sizes
Leads to better parallelism due to bigger tasks and better Tensor Core utilization
Enables to "fit" the minibatch better in waves [2]
4
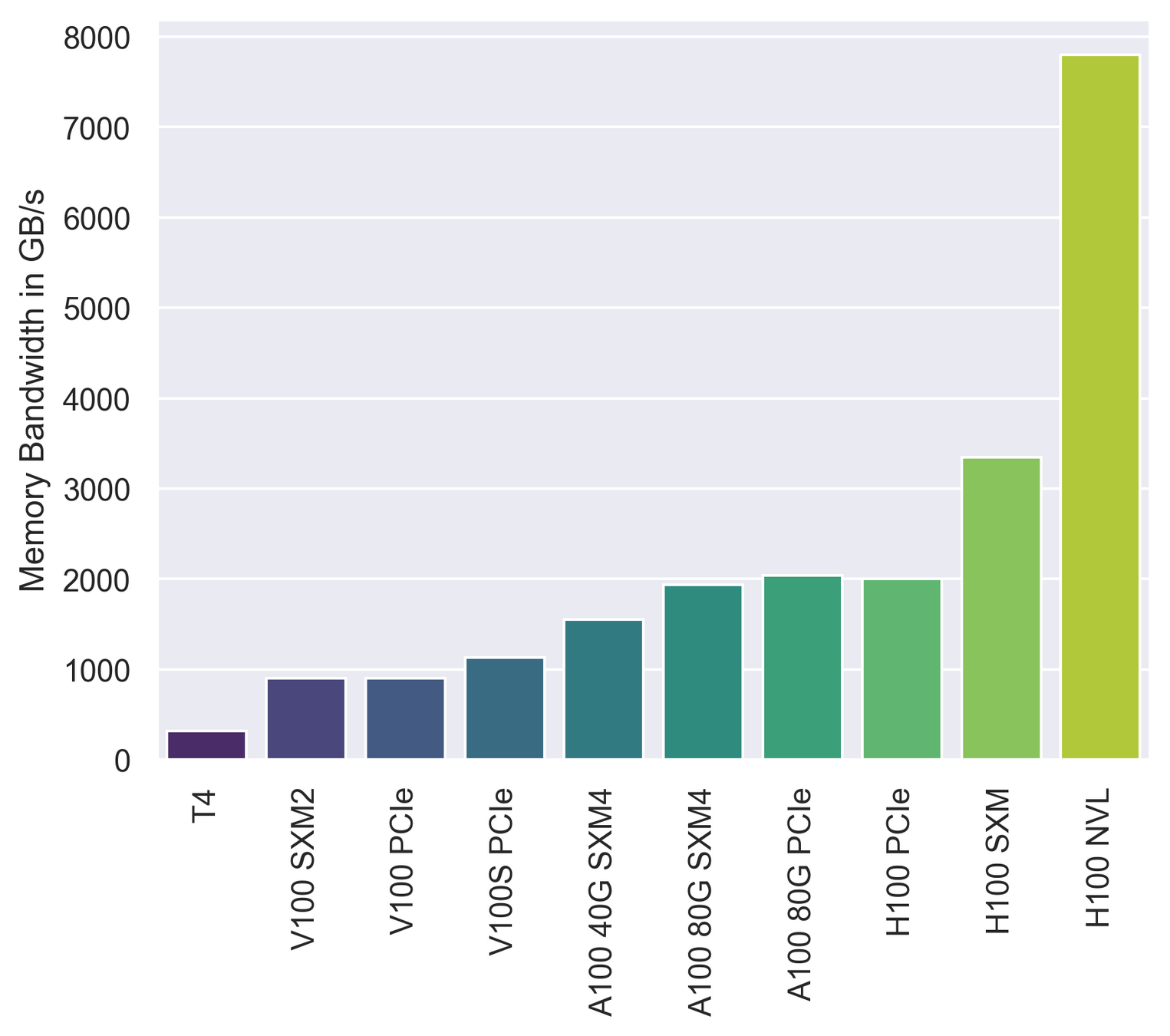
Memory Bandwidth is essential for DL
Many DL operations are memory bound due to their algorithmic intensity [3,4]
5
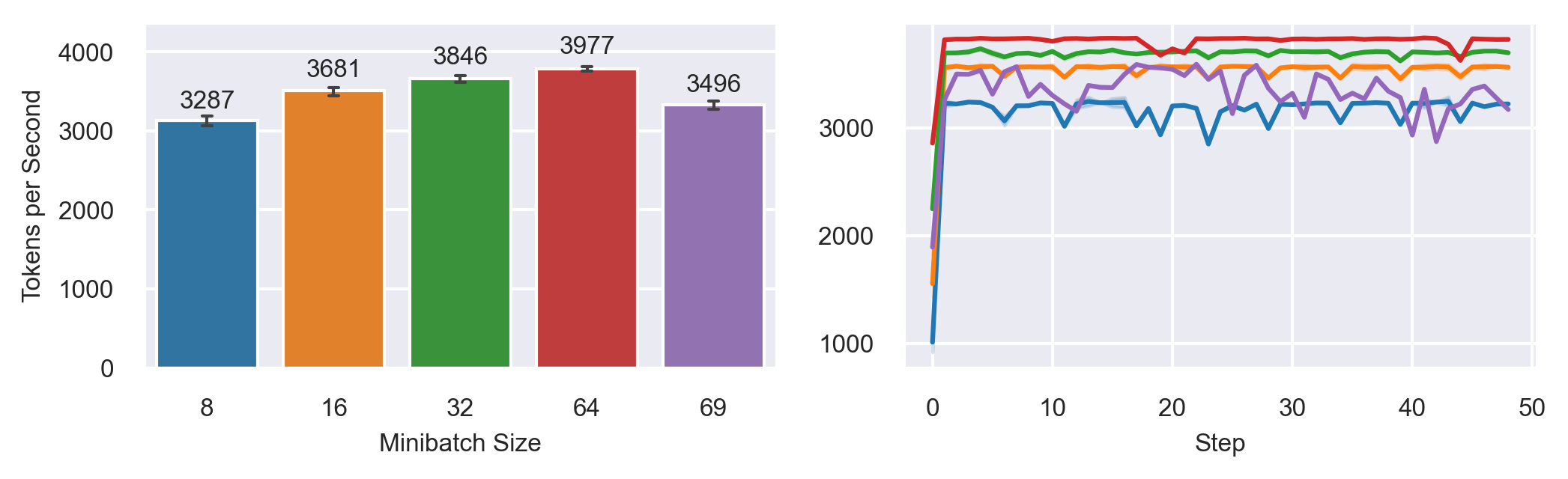
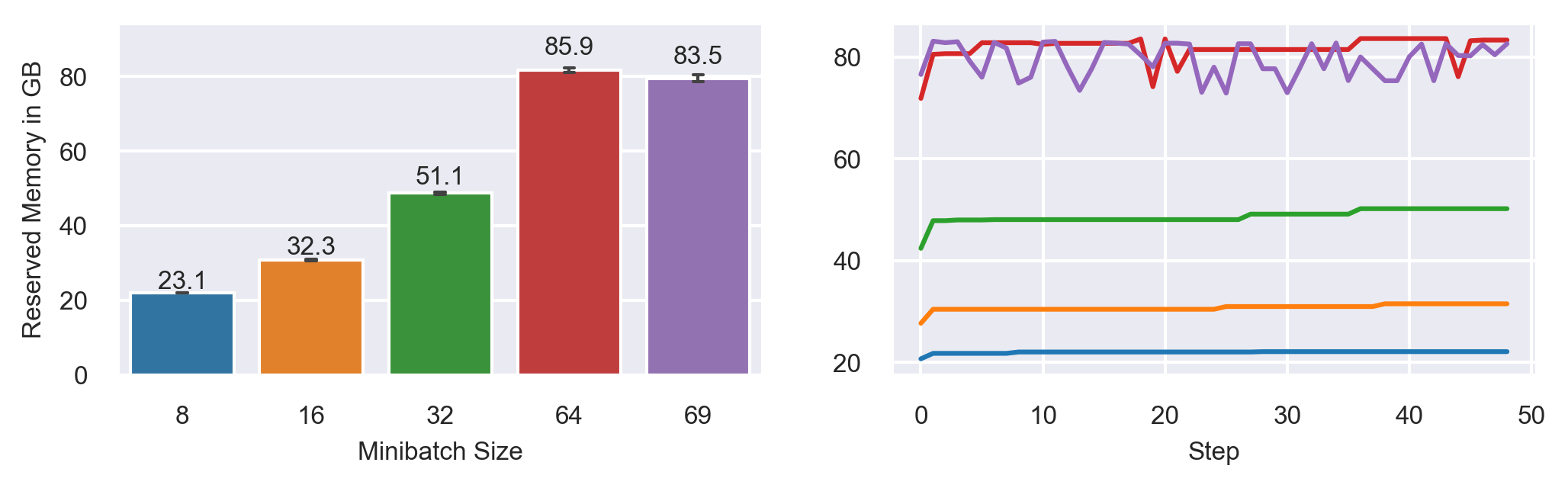
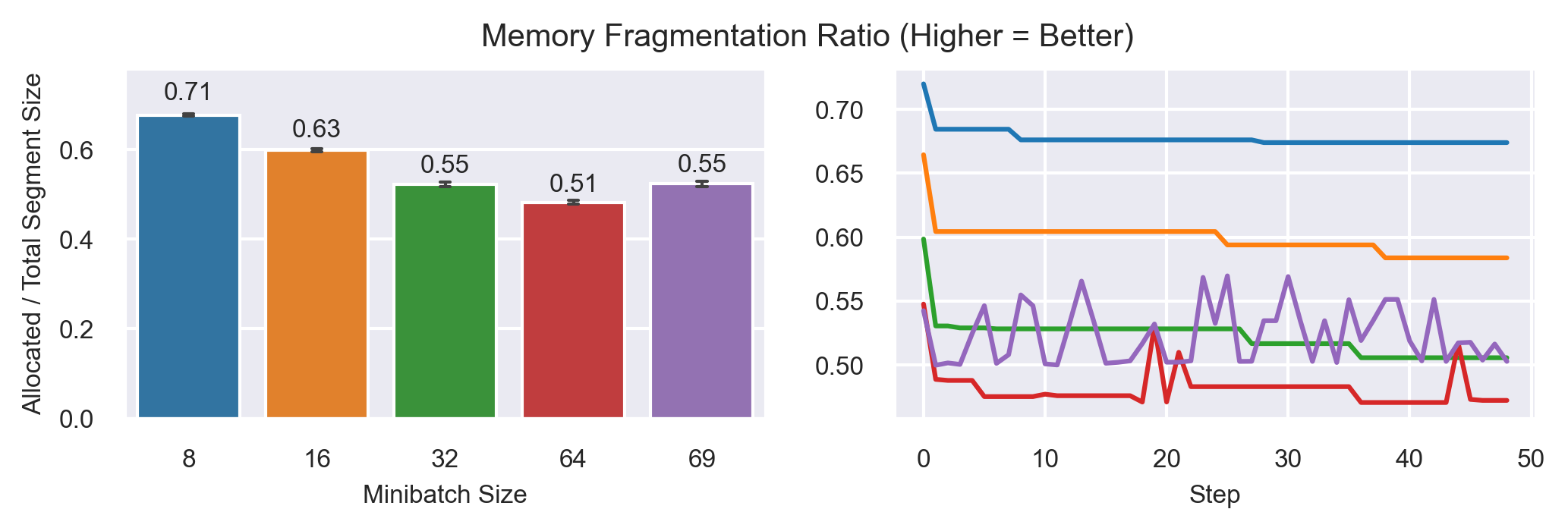
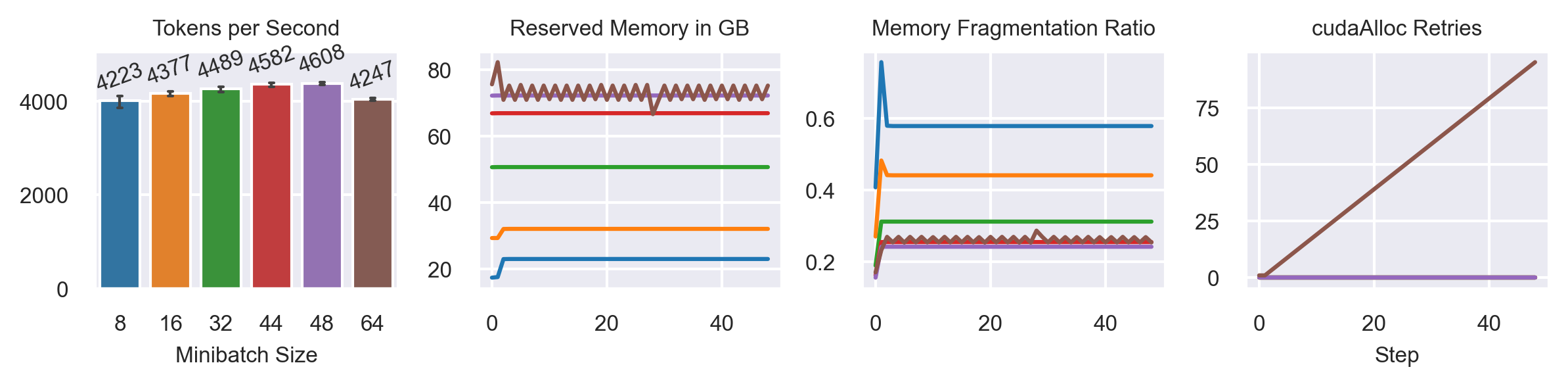
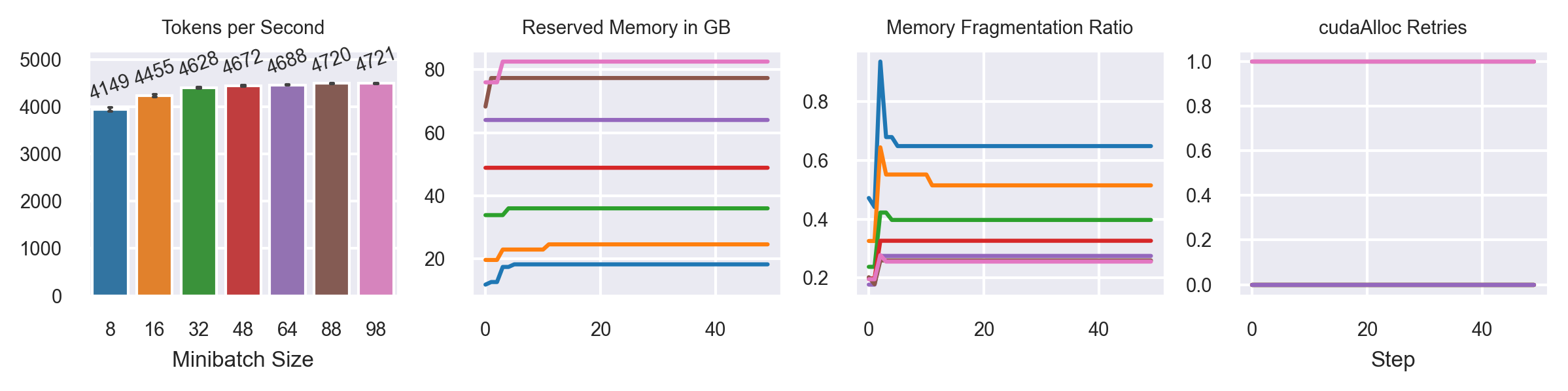
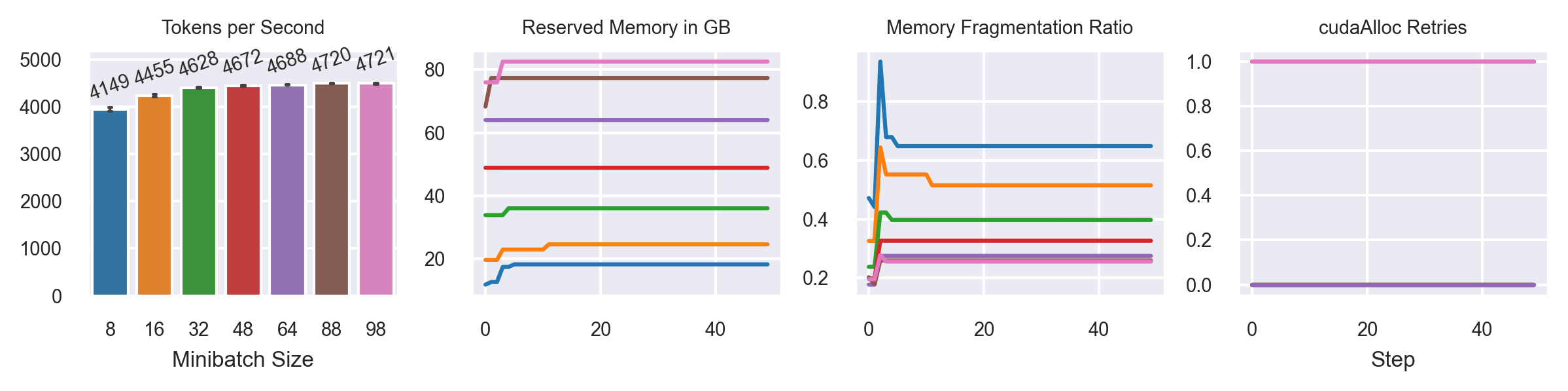
Varying Minibatch Sizes
Model: T5-3B
Fully Sharded FSDP configuration (ZeRO-3)
Seq2Seq Grammar Correction Task
Sequence Length: 512
ZeRO-1
ZeRO-2
ZeRO-3
2xA100 SXM4 80G
PyTorch Nightly (15.09.2023)
CUDA 12.1
Activation Recomputation (30% memory savings)
50 steps
[5]
6
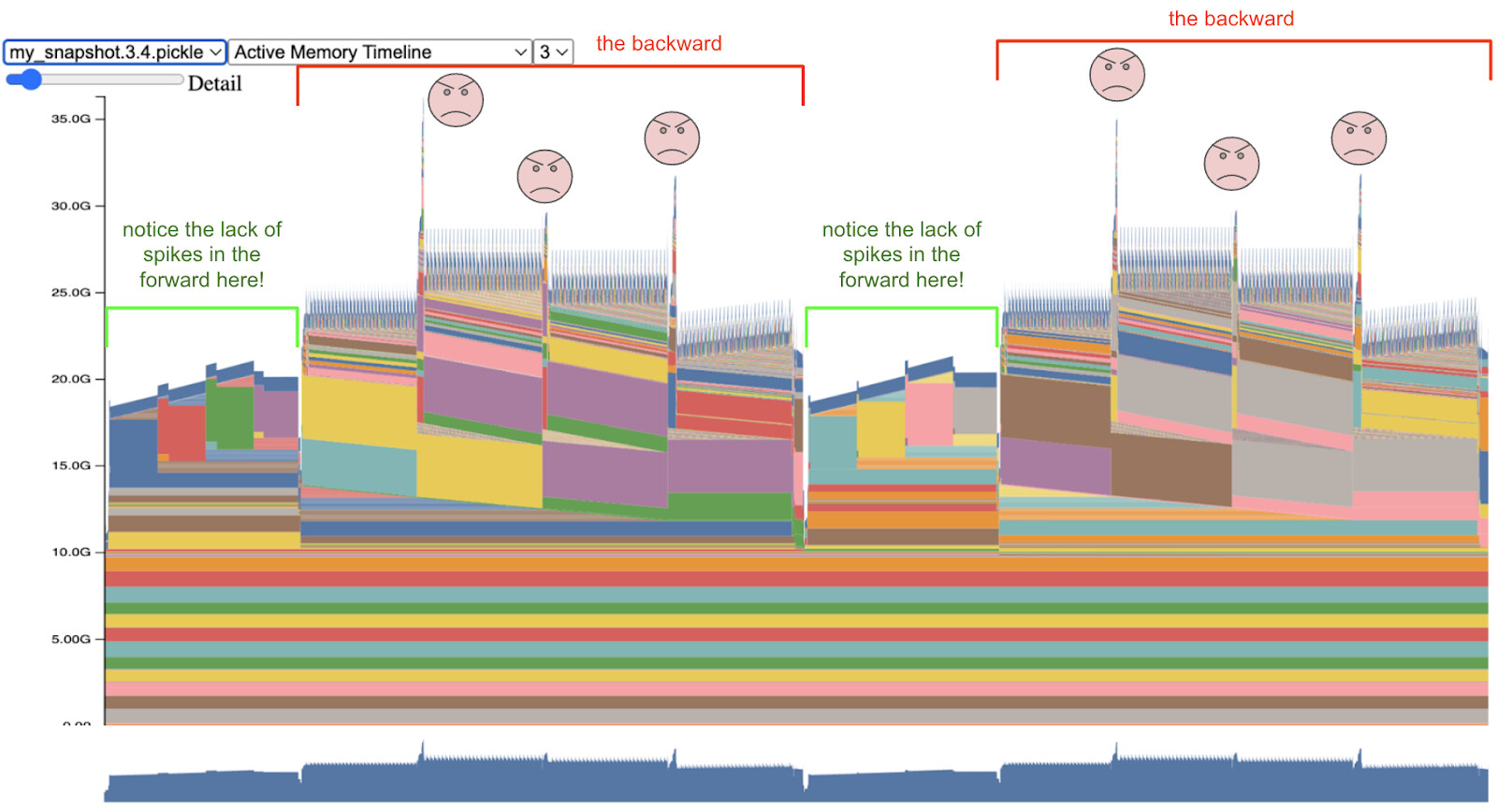
MB: 69 slow
MB: 8,16,32 increase memory consumption over time!
MB: 64, 69 fluctuates around max. memory consumption
7
Segment
Marked Free Block
Block
Rounding Buffer
Free Block
Free Segment
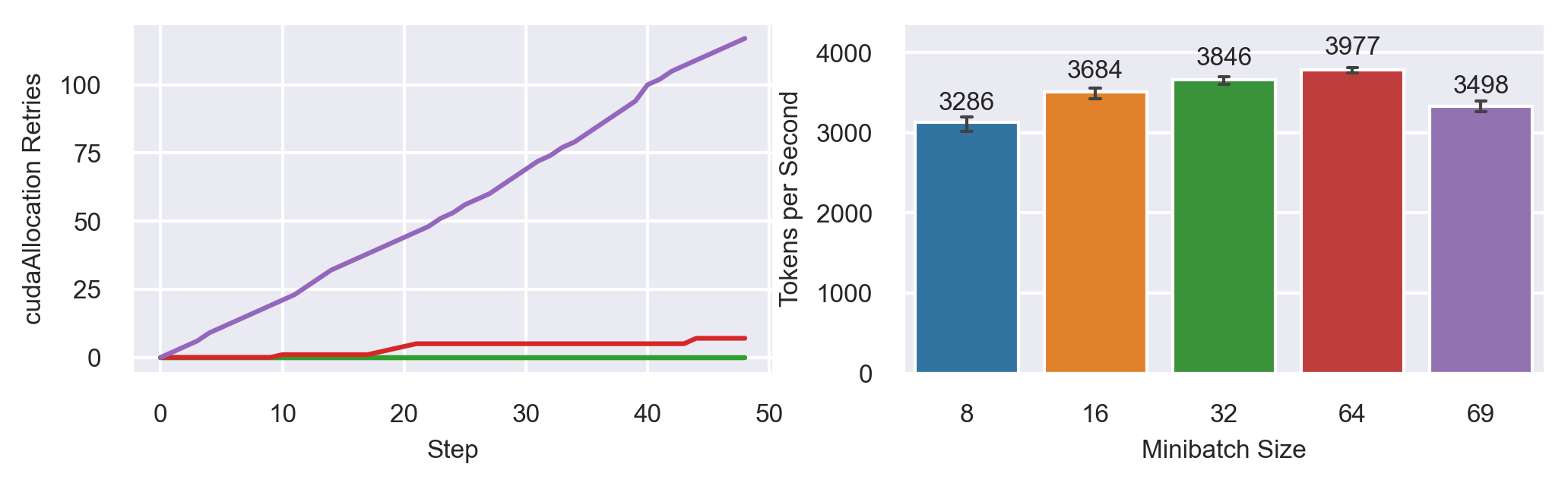
Memory Fragmentation = Allocated Segment Size / Total Segment Size [8]
8
Fragmentation is responsible for higher memory utilization
cudaAlloc retries
limit throughput
9
Post by Jane Xu (Meta Software Engineer) on Sep. 5th [9]
10
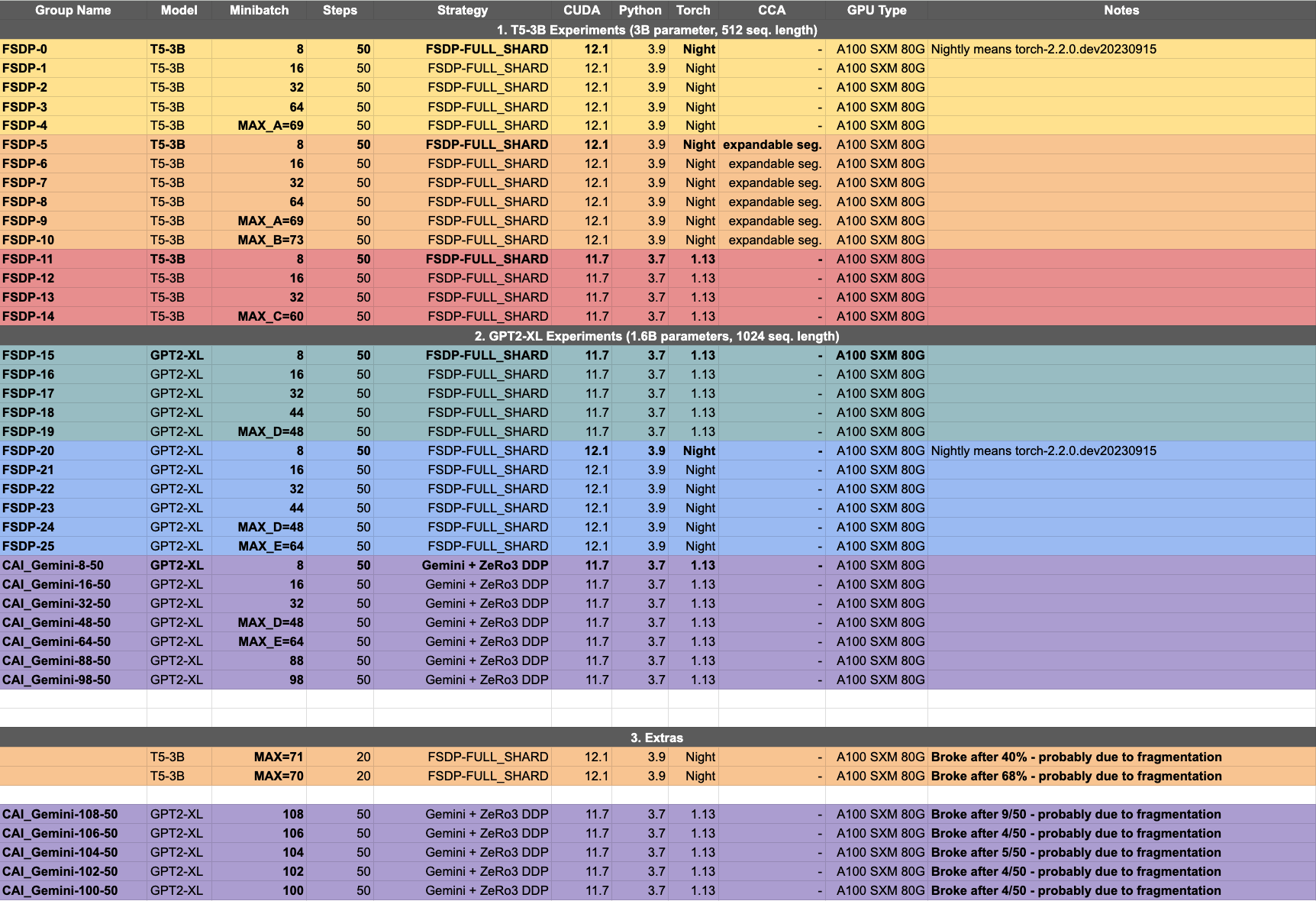
Reimplementation of how FSDP manages synchronization and memory management
Memory Management Plugin by ColossialAI (Gemini System)
CCA Tuning Parameters [10]
Chunk-based Memory Manager
Dynamic Memory Manager
backend
(currently) only supports PyTorch 1.13
(currently) only works with CUDA 11.7
max_split_size_mb
roundup_power2_divisions
roundup_bypass_threshold_mb
expandable_segments (nightly since April '23)
Goal: Stable training with deterministic memory consumption
garbage_collection_threshold
11
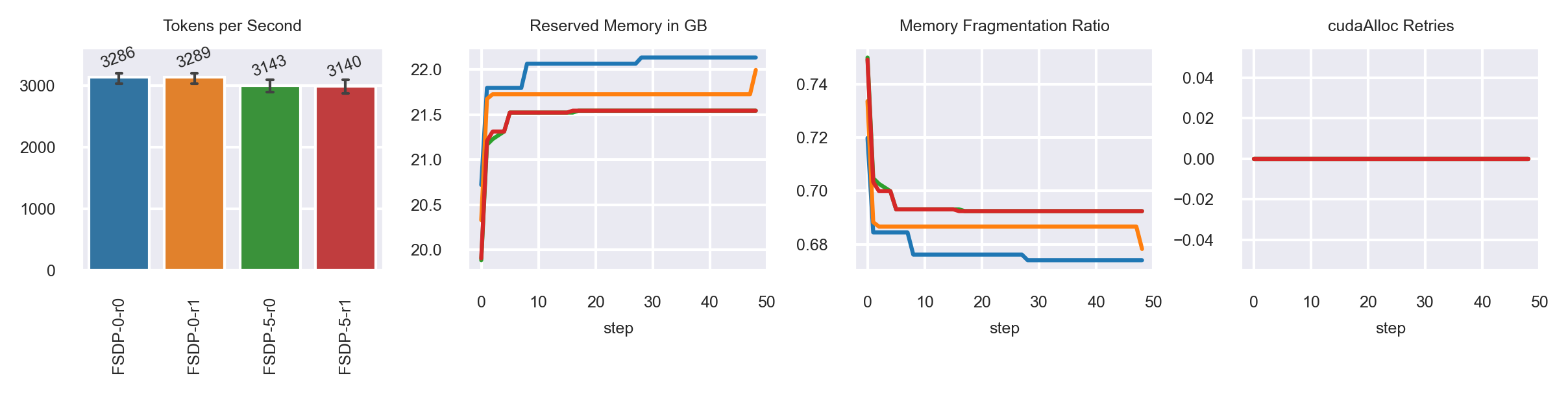
Minibatch Size: 8
default
default
exp-seg.
exp-seg.
12
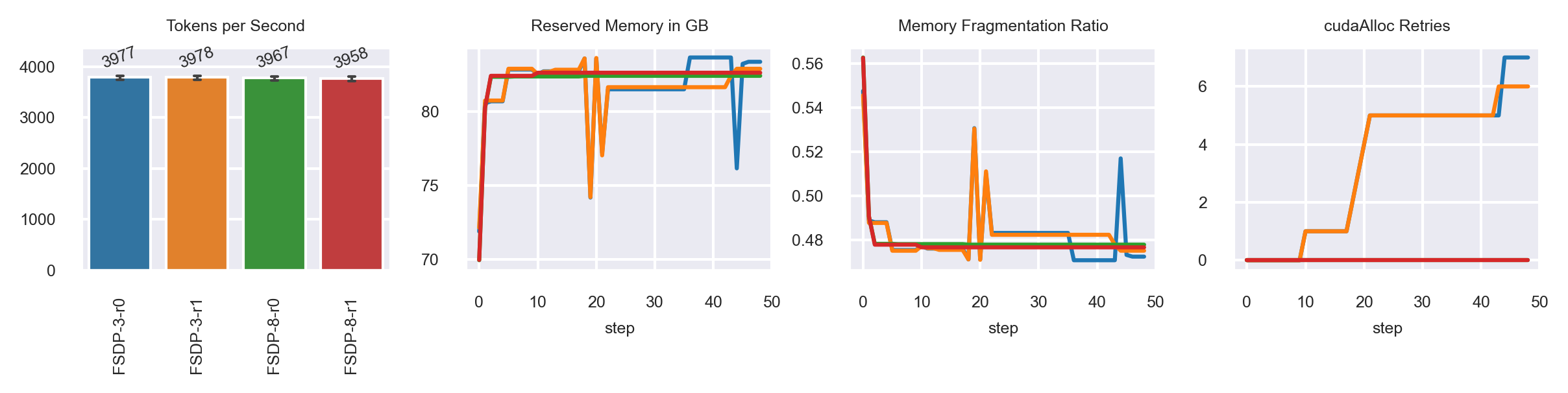
MB: 64
MB: 69
default
default
exp-seg.
exp-seg.
default
default
exp-seg.
exp-seg.
MB: 73 possible (backup slides)
13
1. Seems help with fragmentation when below maximum memory utilization.
3. Not officially documented, unknown plans for this feature.
2. Enables higher minibatch training, but takes an even higher penalty in throughput.
14
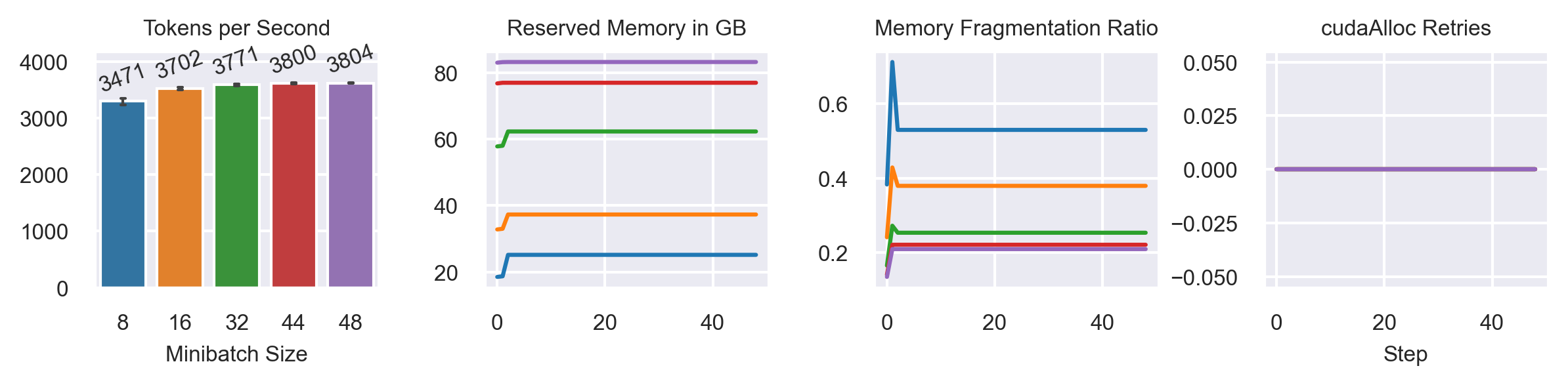
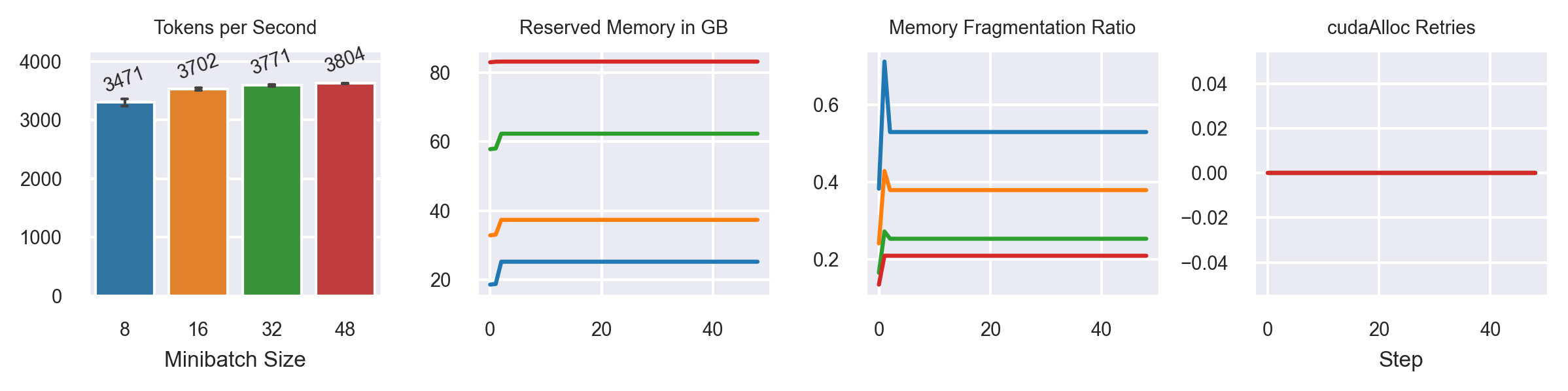
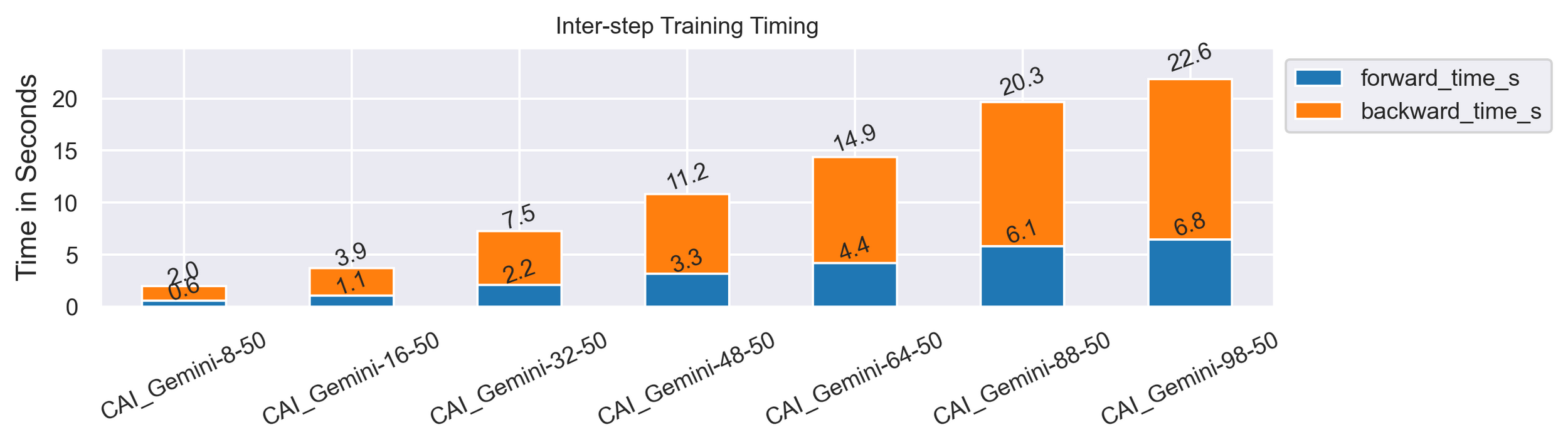
Varying Minibatch Sizes
Model: GPT2-XL (1.6B)
Casual Language Modeling (random data)
Sequence Length: 1024
2xA100 SXM4 80G
Activation Recomputation
50 steps
Fully Sharded FSDP configuration (ZeRO-3) vs. CAI_Gemini (ZeRO-3 DDP + Gemini)
use_orig_params=False [11]
15
FSDP PyTorch 1.13
FSDP PyTorch Nightly
23% speedup
constant memory consumption
16
Gemini PyTorch 1.13
FSDP PyTorch Nightly
17
1. Gemini supports higher minibatch sizes (30% bigger for GPT2-XL).
2. Training throughput with Gemini is, at best, 3% faster.
3. Fragmentation is not fully "solved" with Gemini as it still showed up MB=16.
4. GPT2-XL is not prone to fragmentation compared to the T5 model.
5. When comparing PyTorch 1.13 only, Gemini is faster by 23% and enables 50% bigger minibatches.
18
FSDP still needs to be rewritten, the hot-fix with CCA parametrization is not a long-term solution
Memory management with Gemini seems very promising, but it is tightly coupled with ColossialAI
No fragmentation with FSDP + GPT2-XL: Reason unknown
Test with LLaMa-2
Test with Foundation Model Stack
Many runs with both Gemini (GPT2) and FSDP (T5) worked for 4-25 steps before crashing!
The current trend of leaving 10-20% of HBM free is preferable to maximize throughput and training stability
19
After cleaning up the codebase [12], we plan to publish a blogpost with the results
Add the insights to the PyTorch forum discussion initiated by Jane Xu
Future collaborations are planned, please contact me if anything emerges!
5th year PhD student (expected graduation in May '24)
Interests: Distributed DL, Performance Optimization
Backup slides: Experimental Setup, FSDP 1.13 vs Gemini 1.13, Intermediate Timings, Expandable Segments MB:73, Model FLOPs Calculations
20
21
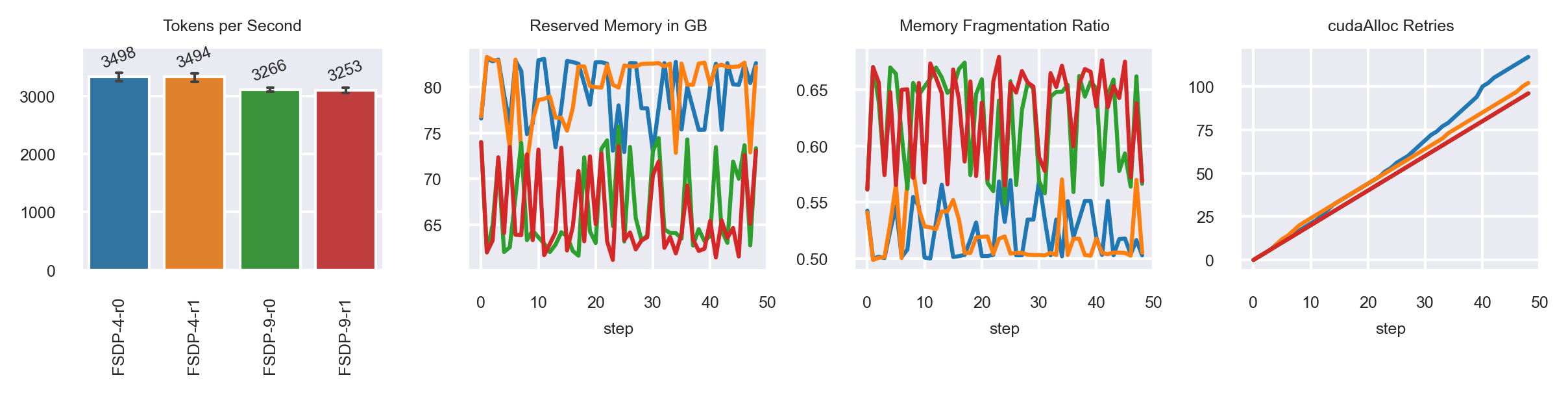
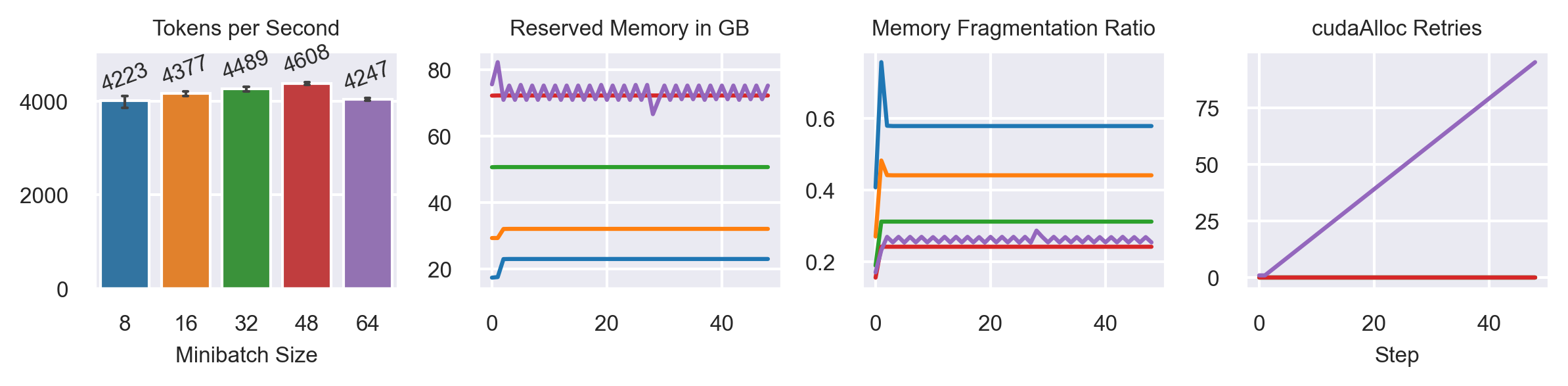
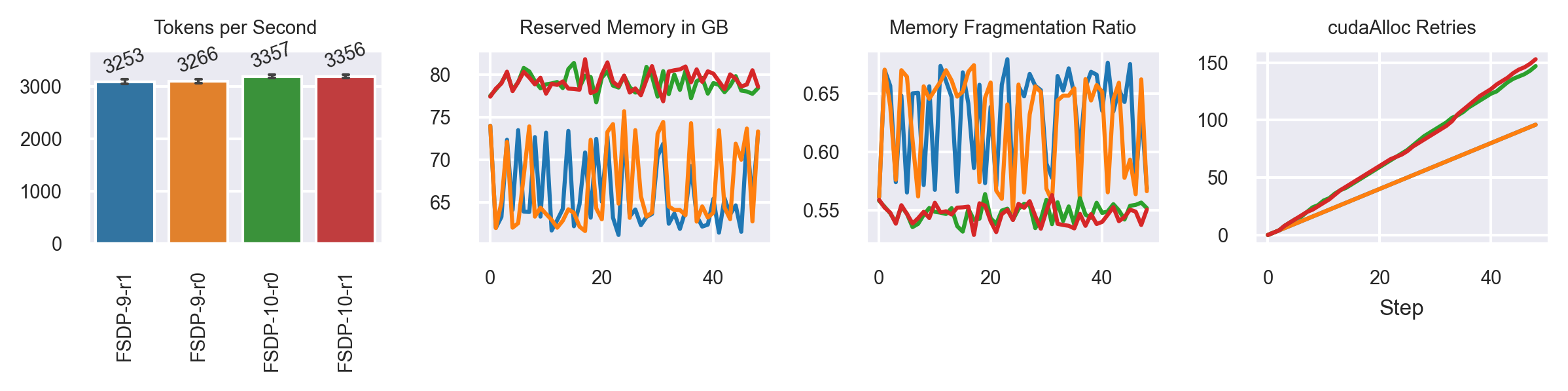
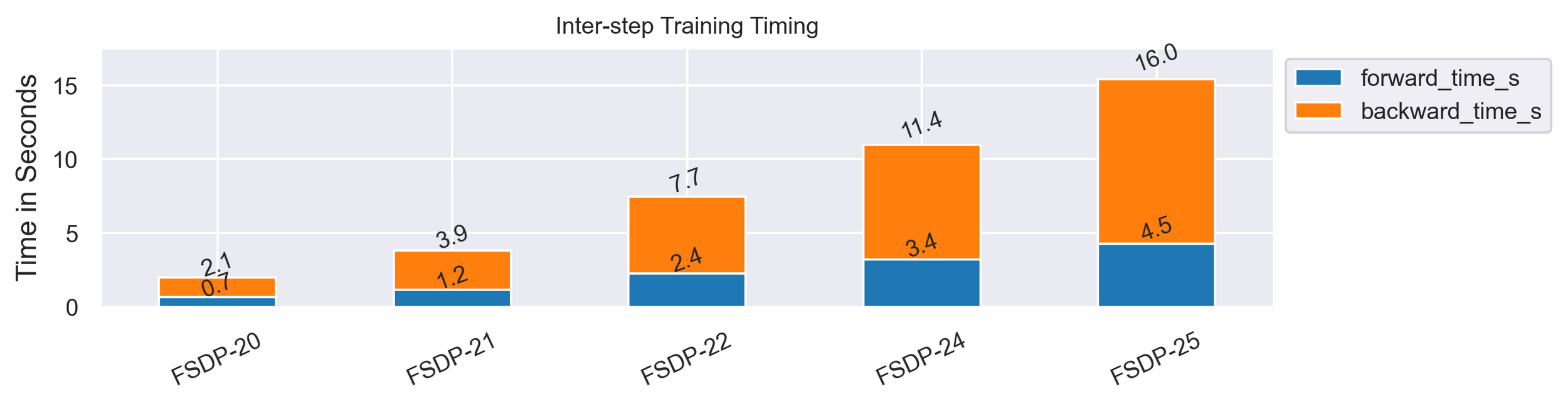
FSDP-9 = MB:69
FSDP-10 = MB:73
Less fluctuation in memory consumption, but a higher cudaAlloc Retries count
Fragmentation is worse!
MB:64 has ~ 3.9k tk/s, so performance is still worse
default
default
exp-seg.
exp-seg.
22
MB:48 Gemini is ~ 23% faster, ~ 50% less mem. consumption
FSDP PyTorch 1.13
Gemini PyTorch 1.13
23
FSDP PyTorch Nightly
Gemini PyTorch
1.13
MB:8
MB:16
MB:32
MB:48
MB:64
MB:8
MB:16
MB:32
MB:48
MB:64
MB:88
MB:98
24
nvidia-smi
Device Utilization
GPU utilization is deceptive! [1]
Samples per second
May not be comparable between models
NLP uses different sequence lengths
CV uses different sizes images
No additional insights when changing hardware except "faster" or "slower"
Only useful when model and hardware is fixed
We need a metric that incorporates the model and hardware information!
FLOPs and Memory Bandwidth are not easily measured without intrusive profiling
25
[2] PaLM: Scaling Language Modeling with Pathways https://arxiv.org/pdf/2204.02311.pdf
"How well is the hardware used?"
"How well is the model suited to leverage the available hardware?"
[4] Andrey Karpathy FLOPs Calculation: https://github.com/karpathy/nanoGPT/blob/master/transformer_sizing.ipynb
[3] The FLOPs Calculus of Language Model Training https://medium.com/@dzmitrybahdanau/the-flops-calculus-of-language-model-training-3b19c1f025e4
26
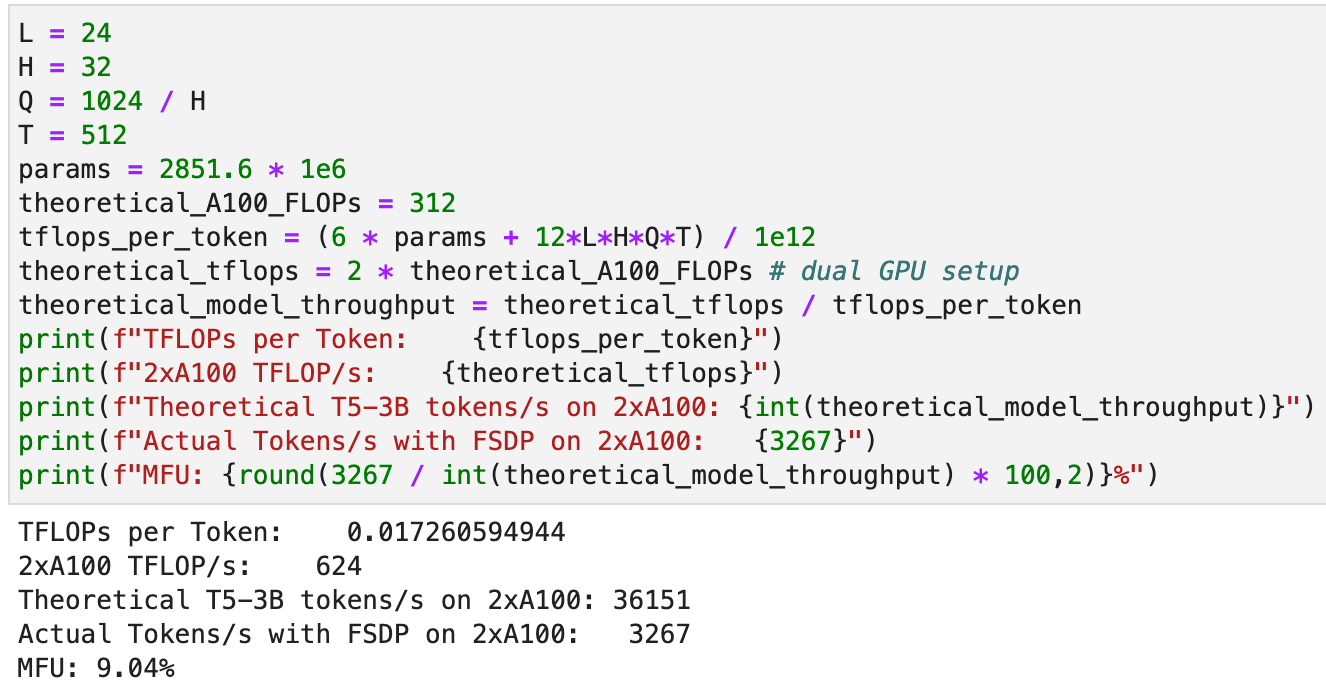
MFU: 9% - why are we so bad?
Current SotA [2]
[2] PaLM: Scaling Language Modeling with Pathways https://arxiv.org/pdf/2204.02311.pdf
By cirquit
Profling Memory Utilization in PyTorch FSDP




