
cjtsai
失蹤的c++殭屍
失蹤
鬼轉一波
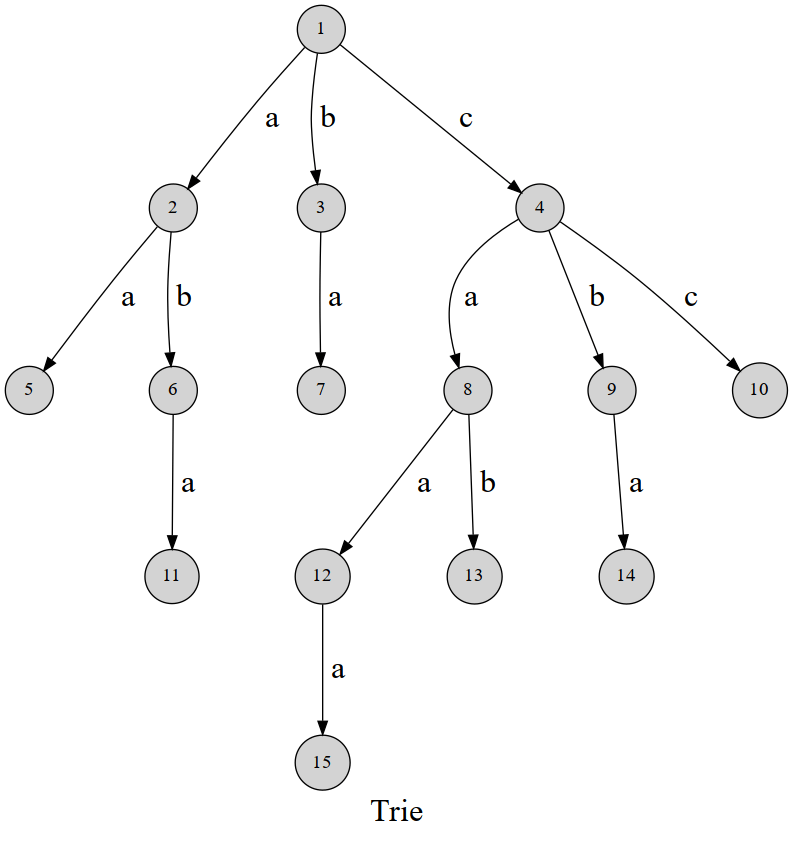
畢竟算是一棵樹對吧
| 1 | ∅ |
| 2 | a |
| 3 | b |
| 4 | c |
| 5 | aa |
| 6 | ab |
| 7 | ba |
| 8 | ca |
| 9 | cb |
| 10 | cc |
| 11 | aba |
| 12 | caa |
| 13 | cab |
| 14 | cba |
| 15 | caaa |
struct Trie{
Trie* c[26];//看你下面有幾種字元,也可以是不定長度的
int cnt=0; //為了儲存這個節點有幾個字是結尾在這裡的
Trie():cnt(0){
memset(c, 0, sizeof(c));
}
};
trie* root = new trie();
void insert(string s){
trie* tmp = root;
for(int i=s.size()-1; i>=0; i--){
if(!tmp->c[(s[i]-'a')]){
tmp->c[(s[i]-'a')] = new trie();
}
tmp=tmp->c[(s[i]-'a')];
}tmp->cnt++;
}bool query(string s){
trie* tmp =root;
for(int i=0; i<s.size(); i++){
int eee=s[i]-'a';
if(tmp->c[eee]){
tmp=tmp->c[eee];
}else{
return false;
}if(tmp->cnt&&i==s.size()-1){
return true;
}
}
return false;
}
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define modd 1000000007
vector<int> dp(100007, 0);
struct trie{
trie* c[26];
int cnt=0;
trie(){
memset(c, 0, sizeof(c));
}
};
trie* root = new trie();
void insert(string s){
trie* tmp = root;
for(int i=s.size()-1; i>=0; i--){
if(!tmp->c[(s[i]-'a')]){
tmp->c[(s[i]-'a')] = new trie();
}
tmp=tmp->c[(s[i]-'a')];
}tmp->cnt++;
}
string ans;
void query(int e){
trie* tmp =root;
int tpe=e;
while(tpe>=0){
int eee=ans[tpe]-'a';
if(tmp->c[eee]){
tmp=tmp->c[eee];
}else{
break;
}if(tmp->cnt){
dp[tpe]+=dp[e+1];
dp[tpe]%=modd;
}tpe--;
}
}
signed main(){
cin>>ans;
int n;cin>>n;
for(int i=0; i<n; i++){
string t;cin>>t;
insert(t);
}
dp[ans.size()]=1;
for(int i=ans.size()-1; i>=0; i--){
query(i);
}cout<<dp[0];
}
SHARE CODE TO OTHERS今天時間蠻多的
大家現在去想辦法AC他
Knuth–Morris–Pratt 就三個人名
vector<int> prefix_function(string s) {
int n = (int)s.length();
vector<int> pi(n);
for (int i = 1; i < n; i++) {
int j = pi[i - 1];
while (j > 0 && s[i] != s[j]) j = pi[j - 1];
if (s[i] == s[j]) j++;
pi[i] = j;
}
return pi;
}By cjtsai




