PySpark

Cam Davidson-Pilon
camdp.com
10 second bio:
I'm an ex-finance quant currently
doing data at

Bayesian Methods for Hackers
Open source textbook on an intro to Bayesian Methods
in Python!
Spark is a distributed way of dealing with big data
When should I use Spark, vs when should I use in-memory?
1. How much data do you have? You better have a lot!
2. Do you need to do complex joins? Spark can't do complex joins.
3. Do you have access to a cluster? Clusters are expensive.
4. Do you have individuals who can maintain a cluster's health?
1. Lack of data? You're not logging enough.
2. Complex joins - that will be solved eventually and be common.
3. No cluster? Amazon has a service where you can spin up your own Spark cluster.
4. Individuals to maintain the cluster? Amazon does.
Spark to will become as common to data analysts as S3 is to developers
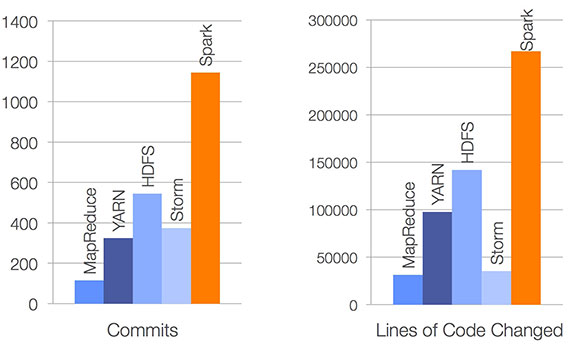
First, Some History
2004

2005

2010

2014
PySpark
Make PySpark go now
deck
By Cam DP



