




Content ITV PRO
This is Itvedant Content department
Build Ensemble Model Using Random Forest (Bagging)
Business Scenario
Welcome back!
Today is your sixth day as a Junior Data Scientist on the Telecom Customer Intelligence Project at AutoVision Analytics.
So far, several classification models have been developed to predict customer churn. While these models provide valuable insights, management wants a more reliable approach that can improve prediction accuracy and reduce errors. To achieve this, they have decided to explore Ensemble Learning using Bagging and Random Forest.
As part of the analytics team, your task is to build a Random Forest Classification Model and understand how combining multiple Decision Trees can enhance churn prediction and support better customer retention strategies.
Pre-Lab Preparation
Topic : Ensemble Learning
1) Bagging(Random Forest)
git pull origin branchNameGit Pull
Task 1: Understand Ensemble Learning, Bagging, and Random Forest
Before implementing an Ensemble Learning model, management wants the analytics team to understand how combining multiple models can improve prediction reliability.
Ensemble Learning
Ensemble Learning is a Machine Learning approach where multiple models are combined to make predictions. Instead of relying on a single model, several models work together to improve accuracy and stability.
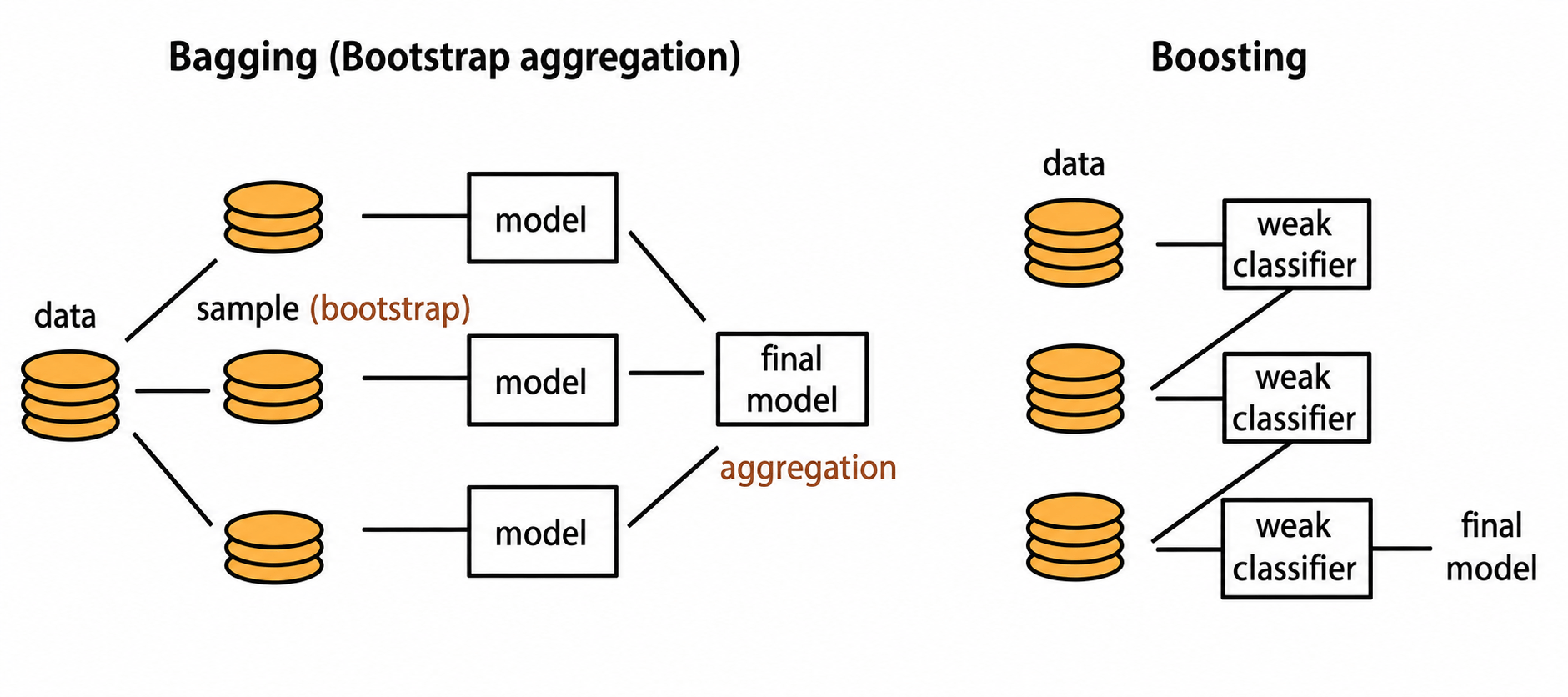
Bagging (Bootstrap Aggregating)
Bagging is an Ensemble Learning technique that creates multiple random samples from the original dataset. A separate model is trained on each sample, and the final prediction is generated through majority voting.
Why is Bagging Useful?
Bagging helps:
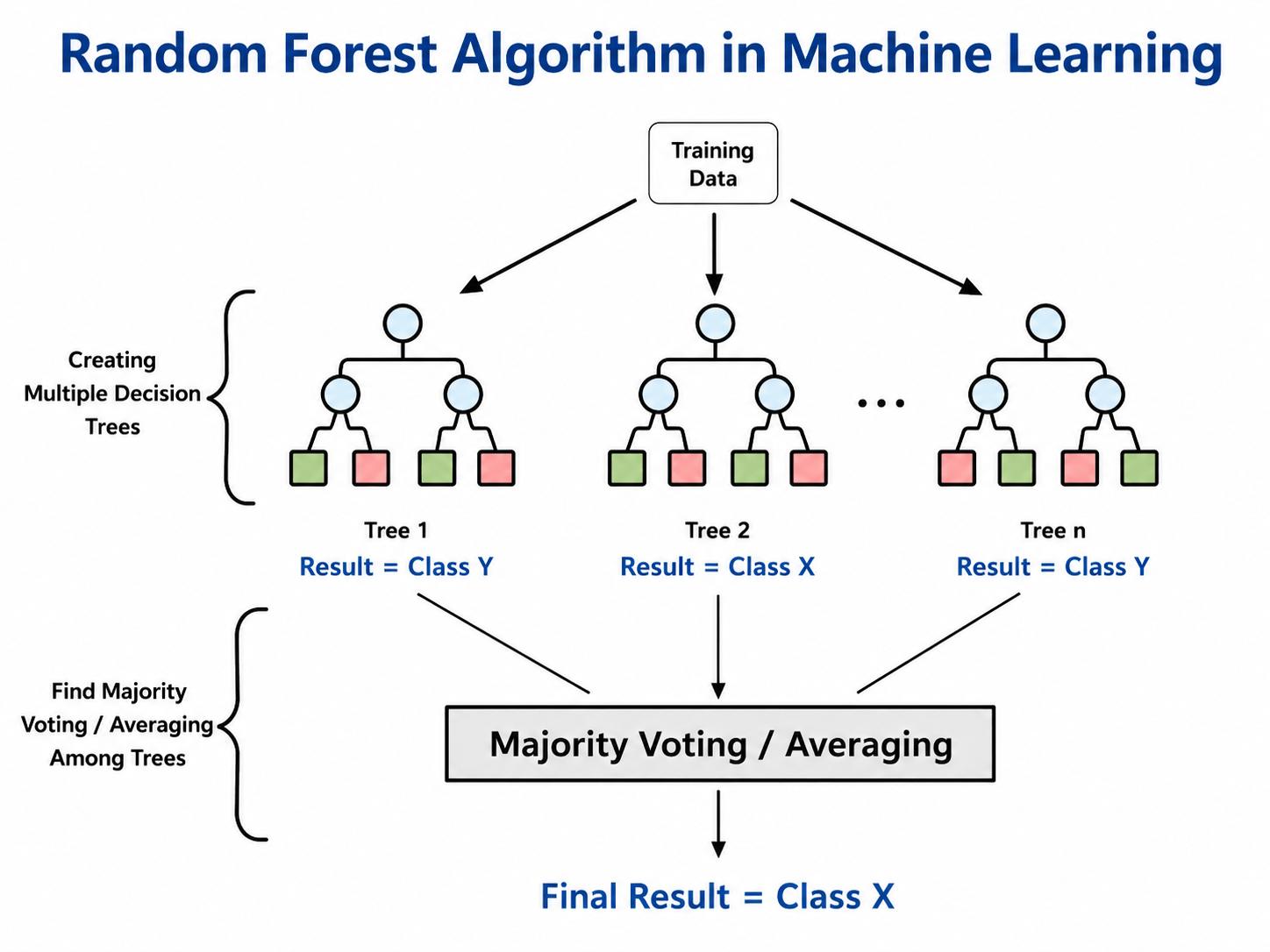
Random Forest
Random Forest is an Ensemble Learning algorithm that combines multiple Decision Trees. Each tree learns from a different random sample of data, and the final prediction is determined through majority voting.
Because many trees participate in the decision-making process, Random Forest is usually more accurate and stable than a single Decision Tree.
Task 2: Build a Random Forest Classification Model
Management wants to determine whether an Ensemble Learning model can improve customer churn prediction compared to the previously developed classification models.
from sklearn.ensemble import RandomForestClassifierrf = RandomForestClassifier(
n_estimators=100,
random_state=42
)rf.fit(X_train, y_train)Train the model
3
Create the Model
2
Import Random Forest
1
Click to download previous file : ML Lab 10.ipynb
Make predictions
4
y_pred_rf = rf.predict(X_test)Evaluate the Model
5
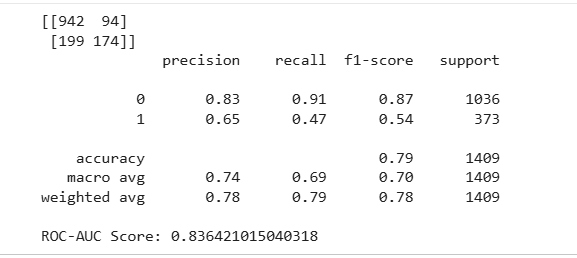
print(confusion_matrix(y_test, y_pred_rf))
print(classification_report(y_test, y_pred_rf))
y_prob_rf = rf.predict_proba(X_test)[:,1]
print(
"ROC-AUC Score:",
roc_auc_score(y_test, y_prob_rf)
)
Great job!
You have successfully completed Lab 12: Build Ensemble Model Using Random Forest (Bagging).
In this lab, you have: Understood Ensemble Learning and Bagging, learned how Random Forest works, built a Random Forest model, generated churn predictions, evaluated model performance using key classification metrics, and interpreted the results from a business perspective.
You are now ready to explore advanced Ensemble Learning techniques that focus on sequential learning and error correction.
Checkpoint
Next-Lab Preparation
Git Push
git push origin branchNameTopic : Ensemble Learning
1) Boosting (AdaBoost, Gradient Boosting,XGBoost)
2) Sampling techniques
By Content ITV




