



Elad Silberring
Python Web developer,. As a hobby I develop html 5 2D games
Elad Silberring
(USN future CTO)
No one worth mentioning
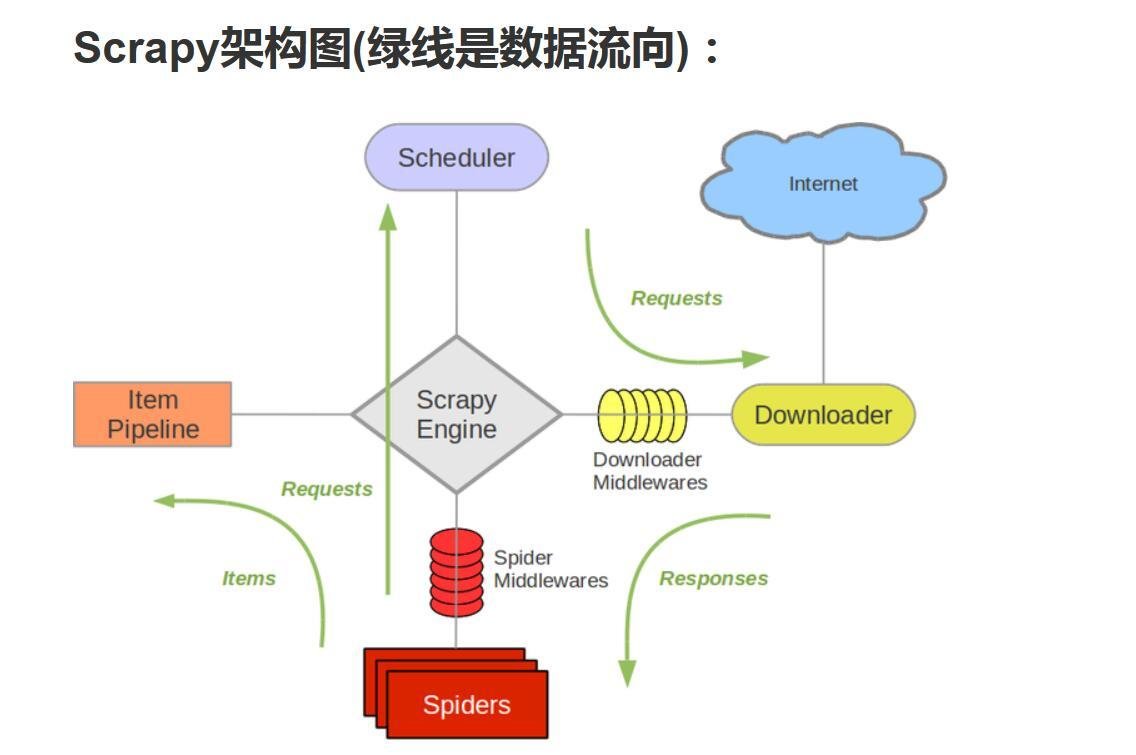
An open source and collaborative framework for extracting the data you need from websites.
In a fast, simple, yet extensible way.
Maintained by Scrapinghub and many other contributors
• Deals website
• LinkedIn candidate search
• Data(base) enrichment
• Better SEO
• Know your competition
• Fetch data
• Fetch data
• Fetch data
• Fetch data
• Fetch data
The job of the spider is to fetch specific content from urls and send them to get processed
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://blog.scrapinghub.com']
def parse(self, response):
for title in response.css('.post-header>h2'):
yield {'title': title.css('a ::text').get()}
for next_page in response.css('a.next-posts-link'):
yield response.follow(next_page, self.parse)
>>> scrapy runspider myspider.py
Text
Stand-alone spider
scrapy shell - a special workplace to run scrapy requests and see their output real time
scrapy shell 'https://scrapy.org'
>>> response.xpath('//title/text()').get()
'Scrapy | A Fast and Powerful Scraping and Web Crawling Framework'export - using the -O arg we can output the data into a json file as so:
$ scrapy crawl quotes -O quotes.jsonsettings - a wide set of options which include:
• AWS integration
• CONCURRENT_REQUESTS
• Logging
• robots.txt options such as user agent, parser and obey rules
$ scrapy startproject tutorialBy Elad Silberring




