Phase Field Benchmarks
Daniel Wheeler

Bag Lunch, 05/24/2023
Acknowledgements
- Larry Aagensen, INL
- Stephen DeWitt, ORNL
- Jon Guyer, NIST
- Olle Heinonen, ANL
- Andrea Jokisaari, INL
- Trevor Keller, NIST
- David Montiel, U. of Michigan
- Daniel Schwen, INL
- Mike Tonks, U. of Florida
- Peter Voorhees, Northwestern
- Jim Warren, NIST
- Daniel Wheeler, NIST
- Wenkun Wu, ANL




Phase Field Benchmark Team


OVERVIEW
- What is the phase field method?
- Why benchmarks?
- Benchmark problems
- Data collection
- Submission workflow
- Tools for FAIR practices
- Summary
Interface Tracking
Variety of methods to track material interfaces numerically:
- Sharp interface
- Volume of fluid
- Lagrangian mesh deformation
- Local front reconstruction
- Diffuse interface
- Level set method
- Phase field method
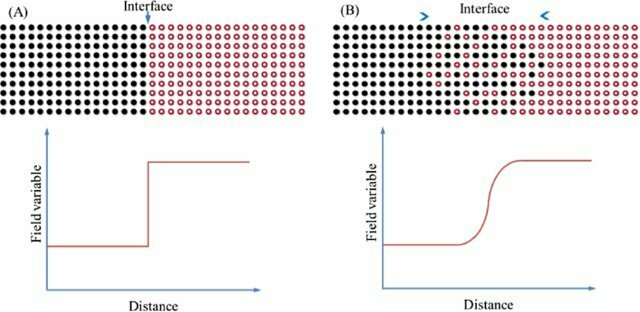
From Liu et al, DOI: 10.1051/mfreview/2018008
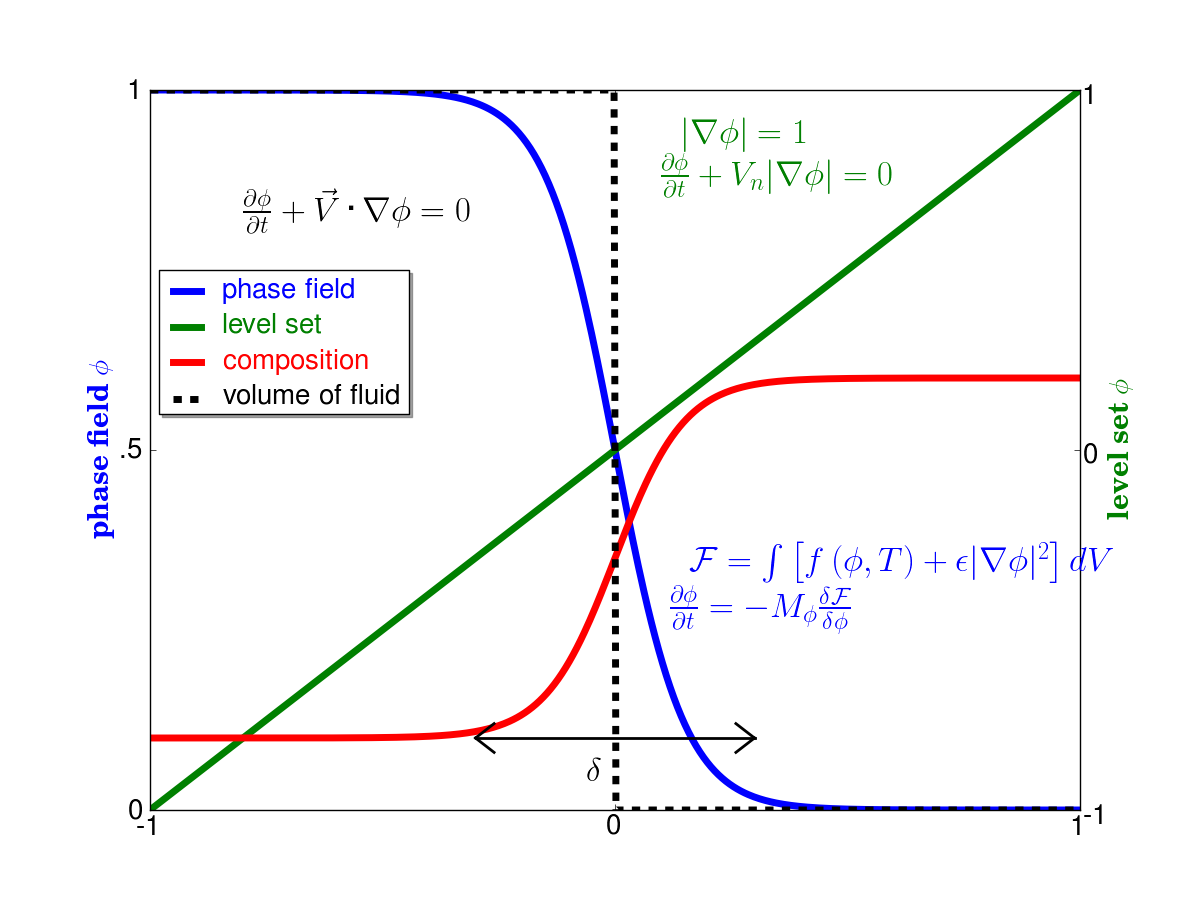
PHASE field MethoD

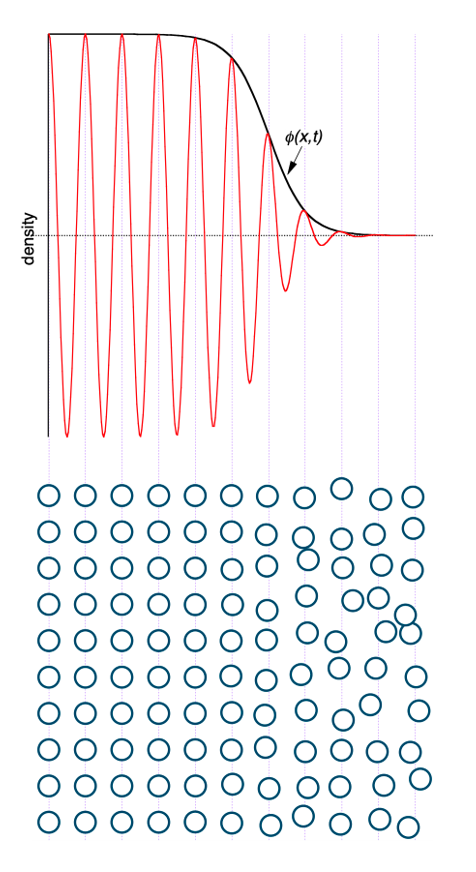
Interpretations:
- envelope of local density fluctuations
- measure of interfacial roughness
- mathematical tool to regularize the sharp interface
\text{order parameter, }\phi\left(x, t\right)
\mathcal{F}\left(\phi, T\right) = \int_V \left[ f\left(\phi, T\right) + \frac{\kappa}{2} |\nabla \phi|^2 \right]dV
From Guyer's summer school slides
From FiPy dendrite example
PHASE field Method
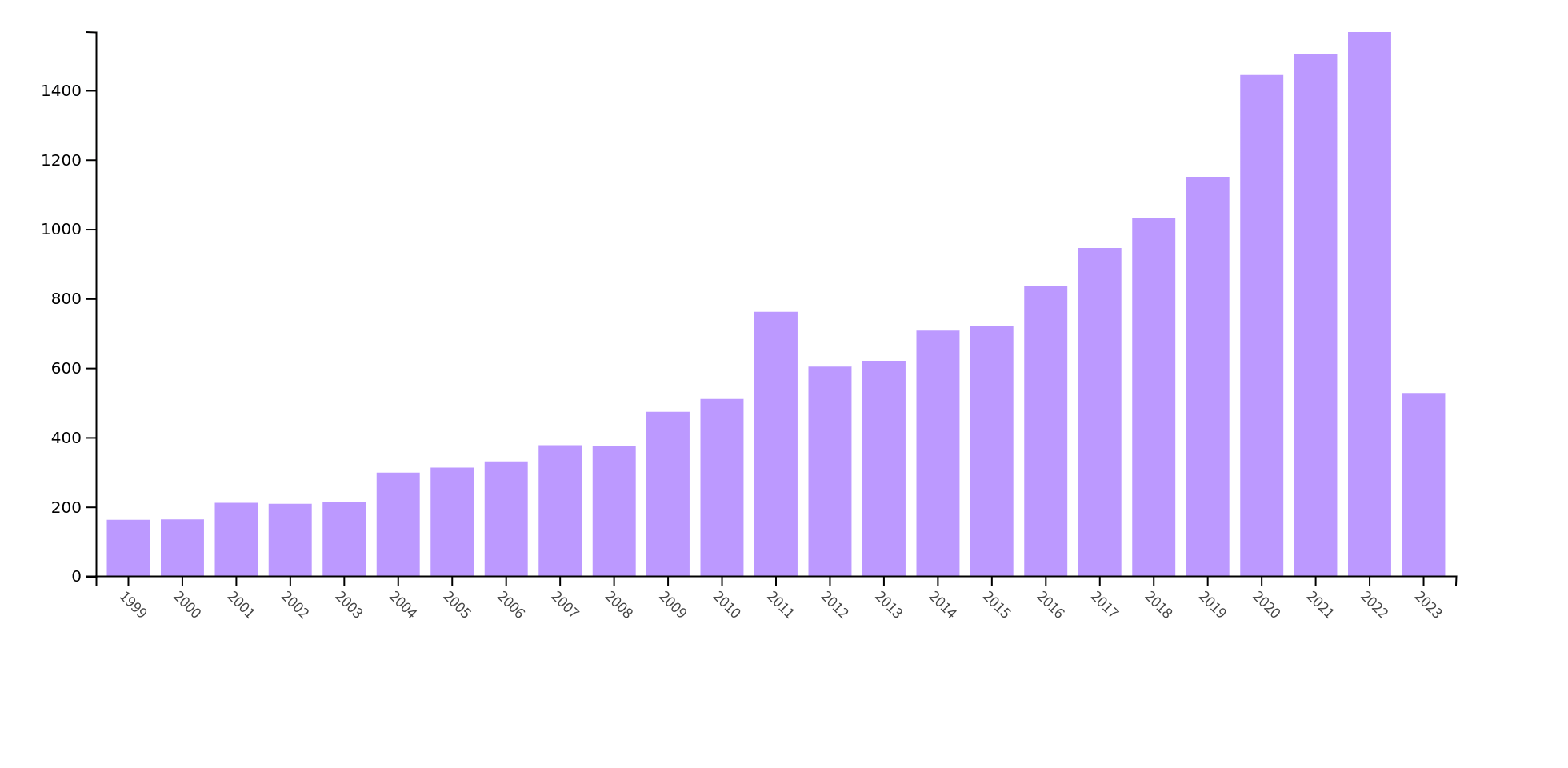
Year on year phase field publications
TS=("phase field" OR "phase-field")
Why phase field?
- Diffusive interface good, sharp bad
- No explicit interface tracking
- Dissipative dynamics
- No "special" equations, algorithms
- Visualize the microstructure
- Many phase field codes available
Issues preventing wider adoption
- Difficult to formulate
- Not enough quantitative comparisons
- Computationally expensive (resolve interface)
- Interface width is not always physical when also tractable
- Some unproven assumptions (irreversible thermo, Taylor expansions)
- Many numerical choices (FE, FV, FD, Spectral)
BENCHMARKS at NIST
- MNIST database
- Jarvis-leaderboard
- AM-Bench challenge problems
- versus experimental data
- µMAG

- Number of micromagentic codes in 1990s
- Developed standard problems
- Not computationally demanding
- Useful in development of OOMFF, Mumax and Magpar
- Inspiration for our benchmarks
Bob McMichael, Donald Porter and Mike Donahue
PHASE Field Methods Workshop, January 2015
- 2015 meeting with phase field code developers
- Consolidate coding efforts?
- Olle Heinonen talked about µMAG standard problems
- Dimitry Karpeev talked about maintaining a community repository
- Decided to focus on phase field benchmarks and repository of benchmark results


PFHUb Website
- PFHub website hosting benchmark specifications and results
- Automated submission procedure
- Phase field best practices guide
- Suggested codes and annotated examples
Current Benchmarks
Benchmarks must satisfy three requirements:
Computationally robust on modest resources
Provide assessment, validation, verification
Relevant (e.g. for pedagogical purposes)
| Benchmark | Paper | Submissions | Variations |
|---|---|---|---|
| 1. Spinodal Decomposition | Cahn (1961) | 62 | 4 |
| 2. Ostwald Ripening | Zhu (2004) | 29 | 4 |
| 3. Dendritic Growth | Karma & Rappel (1998) | 14 | 1 |
| 4. Elastic Precipitate | Jokisarri (2017) | 12 | 8 |
| 5. Stokes Flow | 0 | 2 | |
| 6. Electrostatics | Guyer (2004) | 9 | 2 |
| 7. Allen-Cahn MMS | Salari and Knupp (2000) | 10 | 3 |
| 8. Homogeneous Nucleation | 6 | 4 |
Method OF Manufactured Solutions Benchmark
MMS explained in "Code Verification by the Method of Manufactured Solutions", Salari and Knupp Sandia technical report, 2000
\frac{\partial \eta}{\partial t} = - \left[ 4 \eta \left(\eta - 1 \right) \left(\eta-\frac{1}{2} \right) - \kappa \nabla^2 \eta \right]
How do we assess results for the Allen-Cahn (for example) equation in 2D (no analytical solution in general)?
Cheat a little bit with a neat trick. Substitute a "manufactured solution" and derive a source.
\eta_{sol}(x,y,t)
\frac{\partial \eta}{\partial t} = - \left[ 4 \eta \left(\eta - 1 \right) \left(\eta-\frac{1}{2} \right) - \kappa \nabla^2 \eta \right] +
S(x, y, t)
We now have an analytical solution to a slightly different equation
carefully construct to be smooth with non-trivial derivatives, but bounded (perturbed tanh is ideal here)
Method OF Manufactured Solutions Benchmark
primarily work of Stephen DeWitt
\eta_{sol}(x,y,t) = \frac{1}{2}\left[ 1 - \tanh\left( \frac{y-\alpha(x,t)}{\sqrt{2 \kappa}} \right) \right]
Manufactured solution constructed based on 1D analytical solution
chosen to yield complex behavior

initial conditions
final conditions (t=8 time units)
S(x, y, t)\text{ is long complicated expression}
simulation by Trevor Keller using Hiperc
Method OF Manufactured Solutions Benchmark
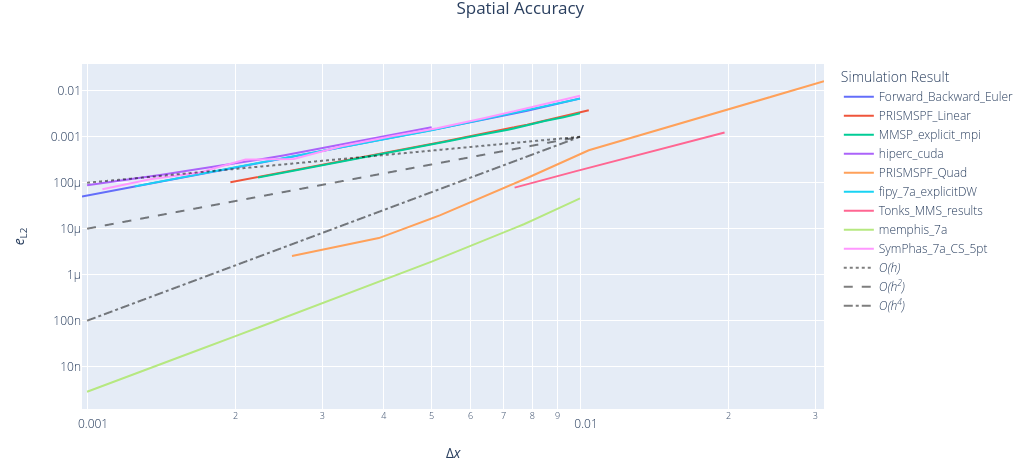
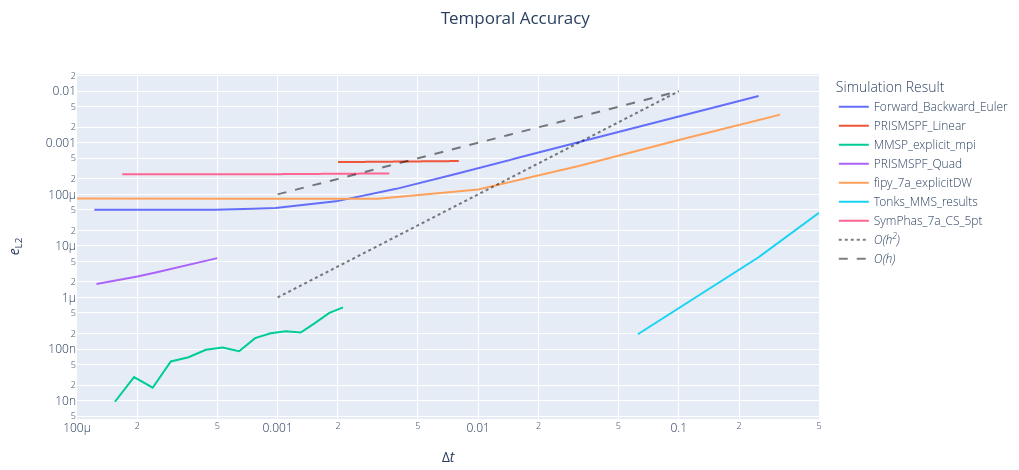
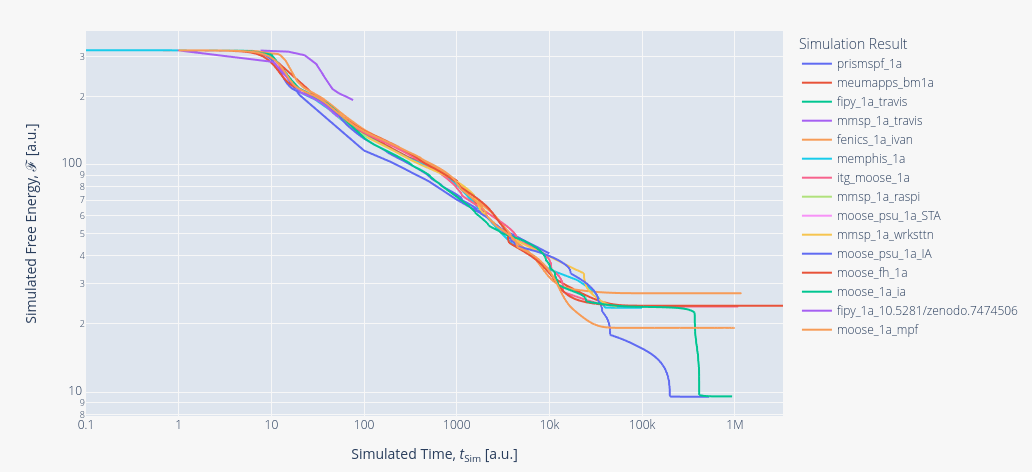
MMS makes it much easier to calculate both temporal and spatial accuracy
results from PFHub website for benchmark 7a.0
Method OF Manufactured Solutions Benchmark
MMS makes it much easier to calculate both temporal and spatial accuracy
results from PFHub website for benchmark 7a.0
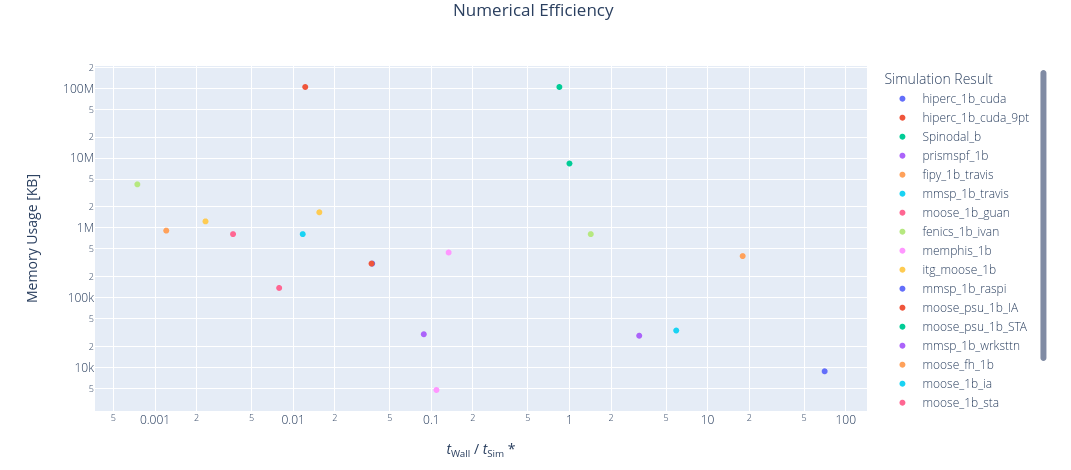
SPinodal Decomposition Benchmark
Orders of magnitude range in resource usage
results from PFHub website for benchmark 1b.1
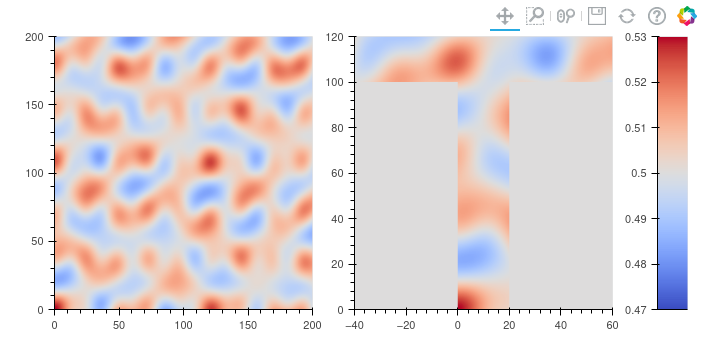
BM1a.1: periodic, square,
BM1b.1: Neumann, square
BM1c.1: Neumann, t-shape
BM1d.1: sphere
Data Collection
- What data to we currently collect?
- Provenance
- Benchmark ID
- Implementation repository
- Post-processed outputs
- Limited metadata
- run time
- memory usage
- simulation time
- Limited hardware data
- Limited software data
id: moose_1a_amjokisaari_ia
benchmark_problem: 1a.0
contributors:
- id: https://orcid.org/0000-0002-4945-5714
name: A.M. Jokisaari
affiliation:
- INL
email: andrea.jokisaari@northwestern.edu
date_created: '2016-06-28'
implementation:
url: https://bitbucket.org/ajokisaari/coral
commit: e8fc74f
results:
fictive_time: 935803.78997793
hardware:
architecture: cpu
cores: 6
nodes: 1
memory_in_kb: 815104
time_in_s: 3720
dataset_temporal:
- name: free_energy_1a.csv
columns:
- time
- free_energy
schema:
url: https://github.com/usnistgov/pfhub-schema/tree/e0010d9/project
summary: MOOSE, IA solver, periodic domain.
framework:
- url: https://mooseframework.inl.gov/modules/phase_field/index.html
name: MOOSE
download: https://github.com/idaholab/moose
version: 1.0.0YAML file showing PFHub result schema derived using LinkML (Trevor Keller)
Data queries
How can we currently query the data
- Plot the dendrite tip position for all results for a particular code
- Show results only from a particular author
- Show results that use >N nodes
- Show results that use a GPU
Better ways to query the data
- Show dendrite curves for all finite difference methods
- Show the transient free energy curve for all results with nominal O(h⁴) accuracy
- Show the resource usage per nominal DOF
- Characterize Ostwald ripening simulations by a length scale associated with the microstructure
- Color data points in an efficiency plot based on numerical method or meshing strategy
Currently collect only derived quantities such as free energy
Data Collection updated
What else should we collect?
- Descriptions of discretization methods (FD, FV, FE, Spectral, ...)
- Nominal order of accuracy, nominal DOF, meshing strategy
- Description of linear solvers, preconditioners, non-linear strategy
- Time stepping strategy (implicit v explicit)
- Field variables at various times for statistical post-processing
- Links to input files (rather than just the implementation repository)
- Container (Docker build, Singularity build, Nix build)
- What about the actual problem being solved?
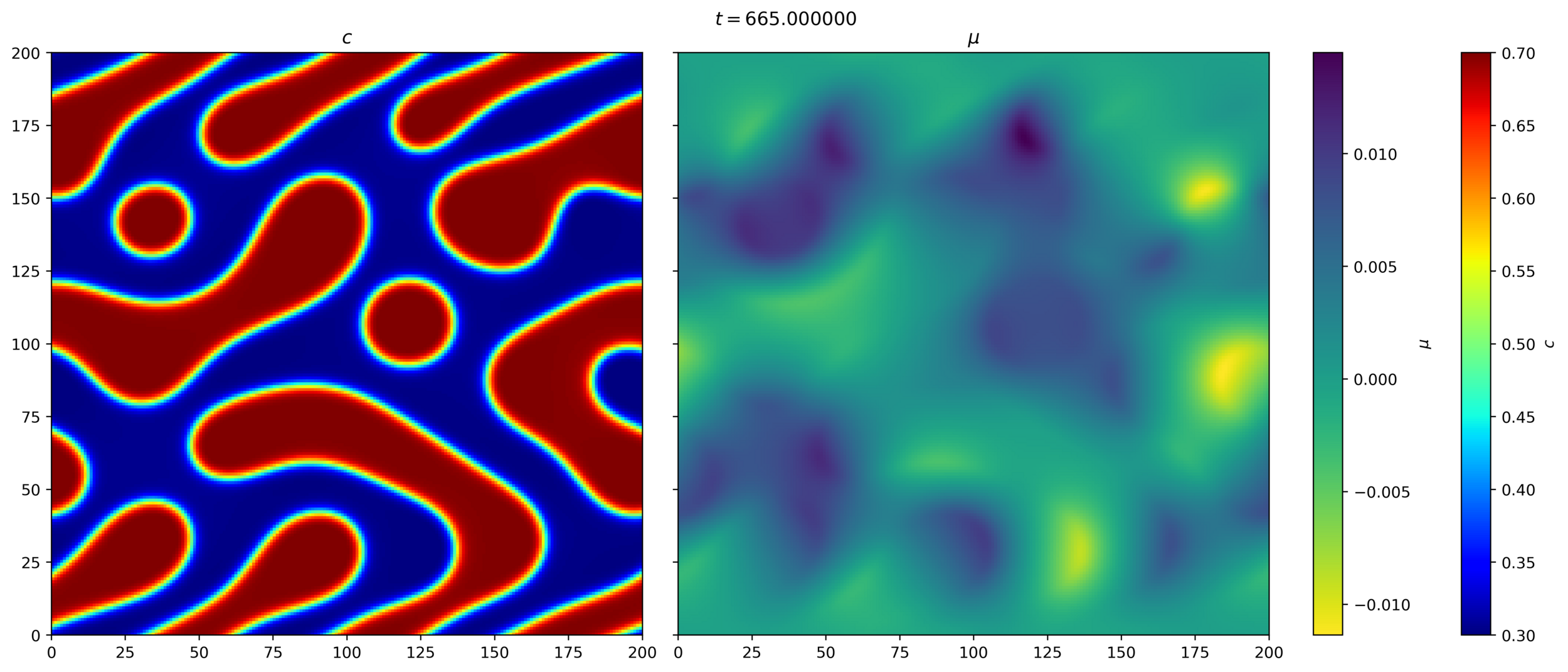
Not collecting the field variables currently (results during evolution of BM1, Trevor Keller)
| Code | Submissions | Solution Methods | Contributors (Year) | Language | Person-Years | Open Source |
|---|---|---|---|---|---|---|
| MOOSE (INL) | 69 | FE, PETSc, adaptive, parallel | 393 (109) | C++ | 116 | Yes |
| FEniCS (Numfocus) | 14 | FE, multiple solvers, parallel | 171 (5) | C++ | 89 | Yes |
| MMSP (RPI) | 11 | FD, explicit, massive parallel | 10 (0) | C++ | 5 | Yes |
| FiPy (NIST) | 13 | FV, implicit, parallel | 21 (2) | Python | 12 | Yes |
| PRISMS-PF (U Michigan) | 10 | FE, explicit, adaptive, massive parallel | 12 (1) | C++ | 10 | Yes |
| Sfepy (U West Bohemia) | 8 | FE, parallel? | 34 (7) | Python | 21 | Yes |
| Custom | 8 | |||||
| MEMPHIS (Sandia, not OS) | 4 | FD, explicit / implicit, massive parallel | ? | Fortran | ? | No |
| AMPE (LLNL) | 5 | FV, implicit, CPODES, adaptive | 3 (1) | C++ | 20 | Yes |
| HiPerC (NIST) | 3 | FD, GPU, explicit | 3 (0) | C | 2 | Yes |
| MEUMAPPS (ORNL) | 1 | Fourier Spectral, KKS, works with thermocalc | 11 (3) | Fortran | 3 | Yes |
| SymPhas (U Western Ontario) | 1 | Symbolic algebra (like MOOSE and PRISMS), forward Euler FD (explicit), implicit Fourier spectral | 3 (2) | C++ | 10 | Yes |
Submissions by Code
Other dedicated codes with 0 uploads include MICRESS and OpenPhase
Other non-dedicated codes are COMSOL, OpenFOAM
Submission Workflow
Submitter has a temporary website to view the submission


GitHub pull-requests (PR) provide a platform for data submissions
- Generate a "pfhub.yaml" using a Jupyter Notebook
- Submit pfhub.yaml and data to Zenodo (or other archival service with DOI)
-
Submit DOI to usnistgov/pfhub issue
- Automatically opens PR and launches automated checks, informs admins and fires up temporary views of the data
- Discussion between submitter and admins in the PR, change or update data if necessary on Zenodo
- Submission is then registered on PFHub website
Ask the submitter to check the submission
Clean up any issues and then admins approve and submitter approves
Automated tests are run on submission
FAir Improvements
- New schema in human readable form using LinkML
- Seamless conversion between schema.org, json-schema, jsonld, yaml
- MaRDA working group for more general phase field schema
- Require implementation to be in publicly accessible archive
- Encourage use of FAIR4RS principles (metadata.json)
- Require curation of result data on Zenodo (or similar)
- Improve data accessibility using Jupyter Notebooks and Python utility (in place of JS stack and custom apps)
Zenodo submission includes "pfhub.json" metadata file
PHASE FIeld BEST Practices GUIDE
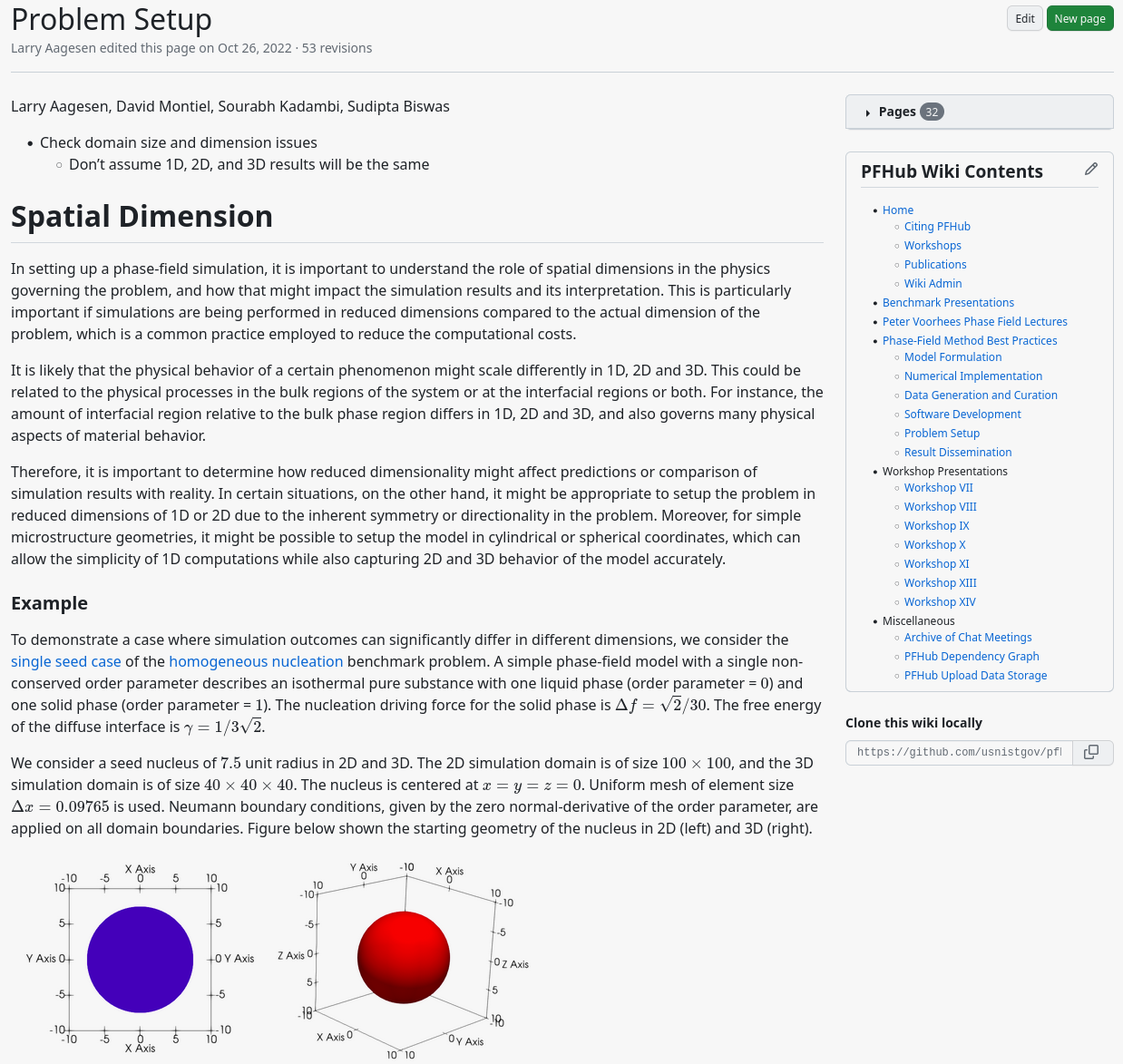
Practical guide to phase field modeling addressing issues most publications often neglect
- Model Formulation
- Numerical Implemenation
- Data Generation and Curation
- Software Development
- Problem Setup
- Result Dissemination
Workshops
14 workshops
3 hackathons
1 install-a-thon
1 upload-a-thon

tools
- Nix
- entirely reproducible environments
- more packages than any distro
- same environment on CI and development
- functional store with every single file hashed
- Papermill
- role out notebooks programmatically
- Jupytext
- store notebooks in markdown
- Snakemake
- makes workflows much tidier, better than Make, and more scalable
- Renku platform?
- versioning data with Git LFS
- read from Zenodo
- integrated with Snakemake
Summary
- GitHub-centric template for code / data pooling for small scientific communities
- Low maintenance
- Long term reliability
- Easy to deploy
- Benchmarks have helped
- phase field code quality assurance
- community cohesion
- education
- Future work
- Expand data collection efforts
- More general phase field data schema
- Expand assurance efforts (stats, uncertainty, characterization)
- New benchmark (triple junction dynamics, AI challenge, PFC)
Bag Lunch 2023-05-24
By Daniel Wheeler




