Machine Learning Canvas
[ Recommender Systems ]
About Me
Garrett Eastham

edgecase
Founder & Chief Data Scientist
- AI & Ecommerce Focus
- CS @ Stanford
- Background in Web Analytics
- Career in Product Management
- Prior: Bazaarvoice, RetailMeNot
Today's Talk
Framing Data Science Problems
Recommendation Science
Example: Real-Time Movie Recommendations
Q&A
Blending Art & Science

Data Exhaust
Data Scientists
Product Managers
Customer Portal
Ecommerce Site
Mobile App
Chat Logs
?
People Also Bought...
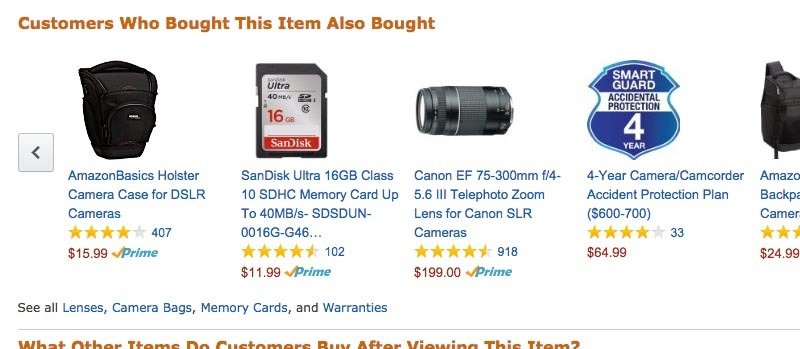
35%
(Total Product Sales)
Product Recommendation
Given: User (U')
?
Given: Products (|P|)
Choose: P' that maximizes user preference over |P|
The Machine Learning Canvas
Decisions
Making Predictions
Offline Evaluation
Features
ML Task
Data Sources
Collecting Data
Building Models
Value Propositions
Live Evaluation and Monitoring
B
D
A
F
H
C
I
E
G
J
The Machine Learning Canvas
Decisions
Making Predictions
Offline Evaluation
Features
ML Task
Data Sources
Collecting Data
Building Models
Value Propositions
Live Evaluation and Monitoring
B
D
A
F
H
C
I
E
G
J
The Machine Learning Canvas
Decisions
Making Predictions
Offline Evaluation
Features
ML Task
Data Sources
Collecting Data
Building Models
Value Propositions
Live Evaluation and Monitoring
B
D
A
F
H
C
I
E
G
J
The Machine Learning Canvas
Decisions
Making Predictions
Offline Evaluation
Features
ML Task
Data Sources
Collecting Data
Building Models
Value Propositions
Live Evaluation and Monitoring
B
D
A
F
H
C
I
E
G
J
ML Canvas: Recommenders
Decisions
Making Predictions
Offline Evaluation
Features
ML Task
Data Sources
Collecting Data
Building Models
Value Propositions
Live Evaluation and Monitoring
"Show me products that I might want."
Product carousel on PDP's.
Rendered on page-load.
Ranking
(i.e. - candidate scoring)
Clickstream.
Reviews.
Customer feedback.
First party through beacon or feed.
User-Product affinities.
Predict historical user-product affinity
Nightly batch + online updates
A/B testing for improved page performance goals (i.e. - conversion, revenue / user, etc.)
Merchants vs. Machine
Financial Outcome
Merchant
Effort
Coordinate Experience
Coordinate Concepts
Coordinate Inventory
Selecting a title for an email campaign
Updating an Open-to-Buy order
Choosing a set of similar products to show a user
Data Quality is Pivotal
16gb Ram
15'' Screen
4gb Ram
13'' Screen
32gb Ram
13'' Screen
16gb Ram
17'' Screen
Customer searches for "large screen laptop for gaming"
Has a known affinity for "Design-Centric" consumer goods


Candidate Selection
97%
14%

Candidate Ranking
Multiple Screens
Great for Gaming
Design-Centric
Predicting Product Affinity
Given: User (U')

Predict: Affinity (U' | P')
Model Selection
|U|
|P|
User-Product Affinity Matrix (Q)
Q is seeded with known affinities.
Issue: Very few "explicit" affinities are known (sparsity).
Model: Can we predict the full matrix Q using <0.01% of known affinities?
Approximate Matrix Q
User-Product Affinity Matrix (Q)
~
~
User Factor Matrix (X)
Y^T
X
Item Factor Matrix (X)
\cdot
Method: Matrix Factorization via Alternating Least Squares
Data: Product Affinities
Movie Ratings (MovieLens)
Data Source: https://grouplens.org/datasets/movielens/
userId,movieId,rating,timestamp
1,169,2.5,1204927694
1,2471,3.0,1204927438
1,48516,5.0,1204927435
2,2571,3.5,1436165433
2,109487,4.0,1436165496
2,112552,5.0,1436165496
2,112556,4.0,1436165499
3,356,4.0,920587155
3,2394,4.0,920586920
3,2431,5.0,920586945
3,2445,4.0,920586945
Example Records (Movies)
ml-latest/ratings.csv
Determine Hyperparameters
// Load ratings data -- using Spark CSV (https://github.com/databricks/spark-csv)
val ratings = sqlContext.read.format("com.databricks.spark.csv")
.option("header", "true").option("inferSchema", "true")
.load("file:///.../movies/ml-latest/ratings.csv")
.map(r => {
Rating(r(0).toString.toInt, r(1).toString.toInt, r(2).toString.toDouble)
}).registerTempTable("ratings")
// Create training, validation, and test datasets
val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))
// Iterate over models and train
def trainAndTest(rank: Int, lambda: Double, numIter: Int) = {
// Build the recommendation model using ALS on the training data
val model = ALS.train(training, rank, numIter, lambda)
// Evaluate the model on test data
val usersProducts = test.map { case Rating(user, product, rate) =>
(user, product)
}
val predictions = model.predict(usersProducts).map { case Rating(user, product, rate) =>
((user, product), rate)
}
val ratesAndPreds = test.map { case Rating(user, product, rate) =>
((user, product), rate)
}.join(predictions)
val MSE = ratesAndPreds.map { case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean()
println("RMSE (validation) = " + MSE + " for the model trained with rank = "
+ rank + ", lambda = " + lambda
+ ", and numIter = " + numIter + ".")
}Apache Spark (Scala API)
Train on Full Dataset
/* ==== Test Results ====
[Baseline]
RMSE (validation) = 0.6832349868066907 for the model
trained with rank = 5, lambda = 0.1, and numIter = 5.
[Pivot on Rank]
RMSE (validation) = 0.6800594873467324 for the model
trained with rank = 10, lambda = 0.1, and numIter = 5.
RMSE (validation) = 0.690144394236897 for the model
trained with rank = 20, lambda = 0.1, and numIter = 5.
RMSE (validation) = 0.698129529945344 for the model
trained with rank = 50, lambda = 0.1, and numIter = 5.
[Pivot on Lambda]
RMSE (validation) = 0.6925651848679597 for the model
trained with rank = 5, lambda = 0.01, and numIter = 5.
RMSE (validation) = 1.0692672408983346 for the model
trained with rank = 5, lambda = 0.5, and numIter = 5.
RMSE (validation) = 1.7497220606946313 for the model
trained with rank = 5, lambda = 1.0, and numIter = 5.
[Use Best Performing Parameters]
RMSE (validation) = 0.6649058015762571 for the model
trained with rank = 10, lambda = 0.1, and numIter = 20.
*/
// Train full model
val model = ALS.train(ratings, 10, 10, 0.1)
// Save model
model.save(sc, "file:///.../movies/models/ml/v1")
Con Air Recommender
// Open raw movie data
val movies = sqlContext.read.format("com.databricks.spark.csv")
.option("header", "true").option("inferSchema", "true")
.load("file:///.../movies/ml-latest/movies.csv")
.registerTempTable("movies")
// Load item factors
case class ItemFactor(id: Int, features: Array[Double])
case class IndexedItemFactor(id: Int, features: Array[Double], index: Int)
val item_factors = sqlContext.load("file:///.../movies/models/ml/v1/data/product","parquet")
.as[ItemFactor].rdd.zipWithIndex.map(x => {
IndexedItemFactor(x._1.id, x._1.features, x._2.toInt)
})
item_factors.toDF().registerTempTable("item_factors")
// Get the feature vector for Con Air
val target_item_factors = item_factors.filter(i => i.id == 1552).take(1)(0).features
// Iterate over all other item factors and map a cosine distance
case class SimilarItem(movie_id: Int, similarity: Double)
val similar_items = sc.parallelize(item_factors.collect()).map(i => {
// Calculate similarity
val similarity = CosineSimilarity.cosineSimilarity(target_item_factors, i.features)
(similarity, i)
}).takeOrdered(20)(Ordering[Double].reverse.on(x=>x._1)).map(x => SimilarItem(x._2.id, x._1))
// Prep for Spark SQL
sc.parallelize(similar_items).toDF().registerTempTable("similar_items")
// Merge with book lookup and show top 10 similar books
sqlContext.sql("SELECT m.title, s.similarity, s.rank
FROM movies m JOIN similar_items s ON m.movieId = s.movie_id
ORDER BY s.similarity DESC LIMIT 20").foreach(println)

Similar Films to Con Air
scala> sqlContext.sql("SELECT m.title, s.similarity
FROM movies m
JOIN similar_items s
ON m.movieId = s.movie_id
ORDER BY s.similarity
DESC LIMIT 20").foreach(println)
[Con Air (1997),1.0]
[Bad Boys (1995),0.9885250995229632]
[Striking Distance (1993),0.9868059080297423]
[City Hunter (Sing si lip yan) (1993),0.9857155838604543]
[Rock, The (1996),0.9855154341766271]
[Another 48 Hrs. (1990),0.9842966650016308]
[Program, The (1993),0.9830120663020663]
[Young Guns II (1990),0.982577633206861]
[Face/Off (1997),0.9825008152957304]
[Navy Seals (1990),0.9823346682235141]
[Assassins (1995),0.9820721829300805]
[Lethal Weapon 3 (1992),0.9820630838696822]
[Sharpe's Challenge (2006),0.9820047546907581]
[My Avatar and Me (Min Avatar og mig) (2010),0.9817191629728049]
[Blue Streak (1999),0.9817106802763232]
[Days of Thunder (1990),0.9816860526998341]
[Outbreak (1995),0.9804433142553622]
[Whispers in the Dark (1992),0.9803792985641578]
[Rapid Fire (1992),0.9803632101298569]
[Cowboy Way, The (1994),0.9799338957065918]



Predicting New Affinities
Given: Known Product Affinities
Predict: Unknown Product Affinities
P_u
P_u'
?
User-Product Affinity Matrix (Q)
P_u
Offline Computation
Online Computation
- Add P(U) to training set and re-run matrix factorization
P_u = X_u \cdot Y^T
- Must find an approximation of user factor X(U)
P_u \approx X_u \cdot Y^T
Y^T
X
\cdot
X_u
Capturing (Implicit) Affinities
Nicolas Cage


Browsing Time (Session)

Derived Movie Affinities

People also liked...
76s
18s
29s
P_u
P_u'
Approximating X(U)
Q = X \cdot Y^T
Q_u = X_u \cdot Y^T
P_u \approx X_u \cdot Y^T
Find:
X_u = X(U|P_u)
(Y^T Y)(Y^TY)^{-1} = 1
Y[Y(Y^TY)^{-1}] = 1
Y(Y^TY)^{-1} = (Y^T)^{-1}
Identity Property
P_u (Y^T)^{-1} \approx X_u \cdot Y^T (Y^T)^{-1}
X_u \approx P_u (Y^T)^{-1} = P_u \cdot Y(Y^T Y)^{-1}
Computing P(U)
// Instantiate the user product matrix (in-memory)
val number_of_factors = item_factors.first.features.length
val number_of_items = item_factors.count().toInt
val Y = matrix(item_factors.collect().map(i => i.features), number_of_items, number_of_factors)
// Set up preferred films
val preferred_movies = Array(
// Provide captured implicit movie preference weights
)
// Create G = Y * (Y.t * Y) ^ -1
val G = Y * inv(Y.t * Y)
// Find predicted user factor vector X_u => P_u * Y * (Y.t * Y) ^ -1'
val X_u = preferred_movies.map(x => x._3 * G(x._2,::))
.fold(DenseMatrix.zeros[Double](1, number_of_factors))((acc, v) => {
acc + v
})
// Use X_u to get personalized movie scores Q_u = X_u * Y.t
val Q_u = X_u * Y.t
// ..... TEST .......
// Sort and pair with movie id
case class ItemRating(id: Int, score: Double)
val rated_items = (0 to (number_of_items - 1)).map(i => ItemRating(i, Q_u(0, i)))
.sortBy(ir => -1.0 * ir.score).toArray
sc.parallelize(rated_items).toDF().registerTempTable("rated_items")
// Find the top recommended movies
sqlContext.sql("SELECT m.title, s.similarity, r.score
FROM rated_items r
JOIN movies m ON r.id = m.movieId
JOIN similar_items s ON s.movie_id = r.id
ORDER BY r.score DESC LIMIT 30").foreach(println)Real-Time Personalization
// Taste Profile: "Lord of War was my JAM!"
val preferred_movies = Array(
(3717, 403, 10.0), // Gone in Sixty Seconds
(1835, 30170, 50.0), // City of Angels
(36529, 27388, 100.0), // Lord of War
(733, 15060, 25.0) // The Rock
)// Taste Profile: "National Treasure was just the best..."
val preferred_movies = Array(
(3717, 403, 10.0), // Gone in Sixty Seconds
(1835, 30170, 50.0), // City of Angels
(8972, 30893, 100.0), // National Treasure
(47810, 8756, 50.0) // The Wicker Man
)A
B



Improving the Results
|U|
|P|
User-Product Affinity Matrix (Q)
A
t
B
How to Contact Me
garrett@dataexhaust.io
- Follow up questions
- Model development / implementation
- Product team training
- Moral support
Thank You!
Questions?
Machine Learning Canvas: Recommender Systems
By Garrett Eastham



