Dynamic Content Summarization
[ Product Review Highlights ]
About Me
Garrett Eastham

edgecase
Founder & Chief Data Scientist
- AI & Ecommerce Focus
- CS @ Stanford
- Background in Web Analytics
- Career in Product Management
- Prior: Bazaarvoice, RetailMeNot
Today's Talk
Content Summarization in Context
Overview of Prior Art
Example: Graph-based Methods
Q&A
Content Creation Explodes
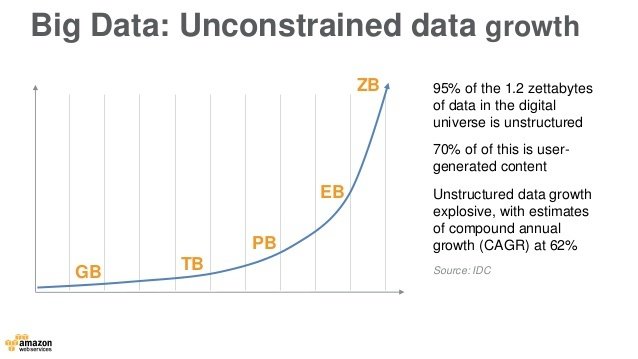
Content Creation Explodes
A
Content Creation Explodes
A
B
Content Creation Explodes
A
B
Data Exhaust
Product Reviews
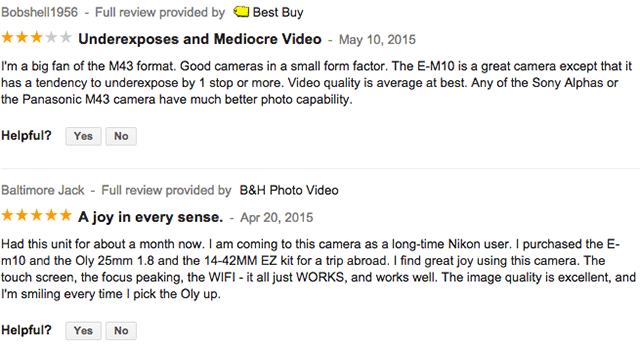
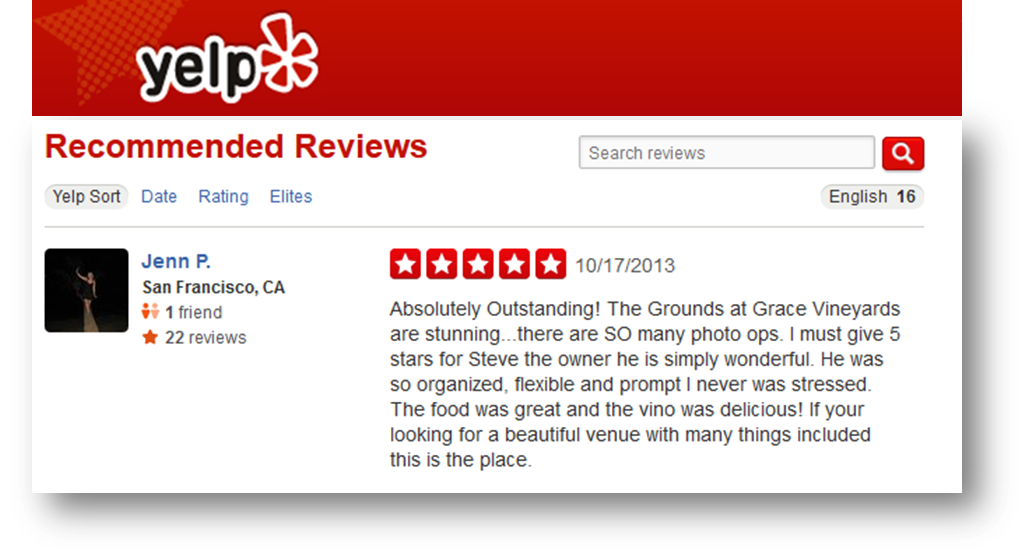
Review Highlights
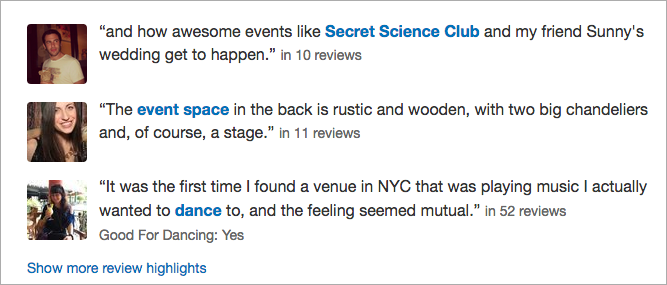

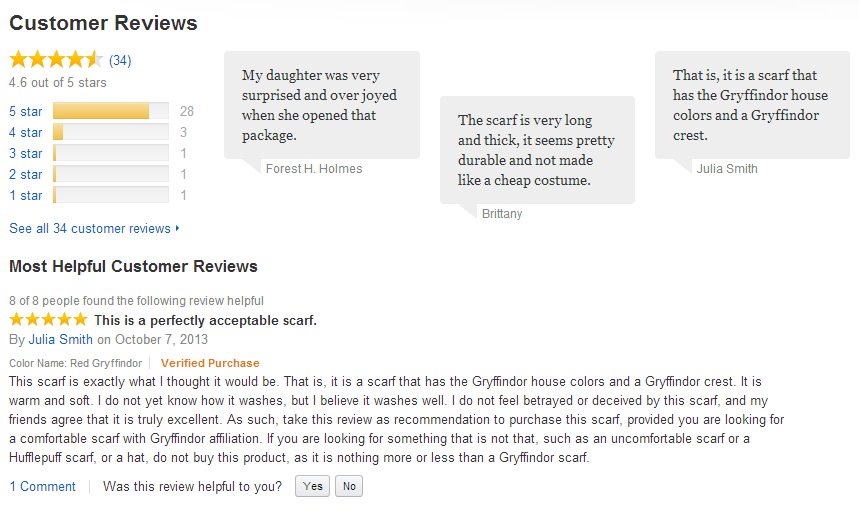
Content "Highlights"
Framing the Problem
Given: Sentences from Reviews of a Product (S | R, P)
Choose: S' that maximizes content integrity given summary constraint K
What is Content Integrity?
General Principles
Query Relevance
vs
Document Coverage
Overlapping & Redundant Content

laptops
The laptop was noisy.
Very loud when turned on.
I couldn't hear anything.
Had to turn up the volume.
Conceptual Model
=>
|M|
|N|
Sentences
Context Vector
Classic IR Approach
Generic Text Summarization Using Relevance Measure and Latent Semantic Analysis (Y. Gong & X. Liu, 2001)
Sentence
Document
R(S)= [t_1 t_2 ... t_m]^T
vs
R(D)= [t_1 t_2 ... t_m]^T
t_i = tf(i) \cdot idf(i)
idf(i) = log(N/n(i))
s.t.
TF-IDF Metric Space
R(S_1)
R(D)
R(S_2)
Cosine Similarity
\frac{R(S_2) \cdot R(D)}{||R(S_2)|| ||R(D)||}
Generic Text Summarization Using Relevance Measure and Latent Semantic Analysis (Y. Gong & X. Liu, 2001)
Overcoming Information Overlap
- Choose sentence that has smallest cosine distance to total document
- Remove all words from sentence from document
- Recalculate relevance scores
- Repeat until K selections
Latent Semantic Analysis
Context Matrix
=>
U
\Sigma
V^T
Singular Value Decomposition
Generic Text Summarization Using Relevance Measure and Latent Semantic Analysis (Y. Gong & X. Liu, 2001)
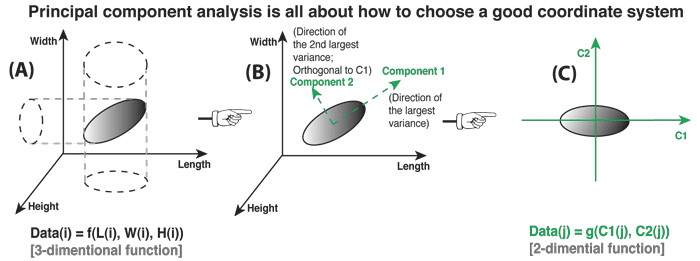
Graph-based Approaches
A Language Independent Algorithm for Single and Document Summarization (R. Mihalcea & P. Tarau, 2005)
S_1
S_2
S_3
S_4
S_5
?
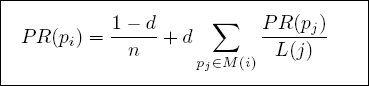
Lexical Chaining
Using Lexical Chains for Text Summarization (R. Barzilay & Michael Elhadad, 1995)
w_1
w_2
w_3
w_4
L1
L2
L3
L4
Conceptual Hierarchy
Sentence
Pilsner
Ale
Example: Album Reviews

Data Analysis
S_1
S_1
S_1
S_1
S_1
Data Source: http://jmcauley.ucsd.edu/data/amazon/
{
"reviewerID": "A23HCR977WY1YN",
"asin": "B000000IRB",
"reviewerName": "Adam",
"helpful": [0, 0],
"reviewText": "..."
"overall": 4.0,
"summary": "...",
"unixReviewTime": 1203984000,
"reviewTime": "02 26, 2008"
}Example Review (Album)
Dark Side of the Moon
- 855 reviews
- 8,077 sentences
- 164,072 words
Data Preparation
// NLP imports
import edu.stanford.nlp.process.Morphology
import edu.stanford.nlp.simple.DocumentStanford NLP
// Load music reviews - find albums with most reviews
val music_reviews = sqlContext.load("file:///.../music/reviews_CDs_and_Vinyl_5.json", "json")
music_reviews.registerTempTable("reviews")
// Create merged review document for target albums
val document = sqlContext.sql("SELECT reviewText FROM reviews WHERE asin = 'B000000IRB'")
.map(r => r(0).toString).collect().mkString("\n\n")
// Parse out sentences -- leverage NLP sentence parser
val sentences = new Document(document).sentences() // 8077 sentences
// Filter out only words that exist in the keywords of sentences that we want to find distance
val parsed_sentences = sentences.map(s => {
// Extract words and their part of speech
val words = s.words().toList
val tags = s.posTags().toList
// Filter and return nouns
(words zip tags).filter( x => List("NN","NNP").contains(x._2))
}).toListChoosing a Similarity Metric
S_2
S_1
?
How can we tell if one sentence has "similar" concepts to another sentence?
Computational Semantics
Efficient Estimation of Word Representations in Vector Space (T. Mikolov et. al, 2013)
The dog played with the child.
The little girl held the cat.
“You shall know a word by the company it keeps”
- J. R. Firth (1957)
W_1
W_2
W_1
W_2
Similarity
Semantic Similarity
The dog played with the child.
W_1
W_2
=>
R(S)
R(S) = \frac{1}{n} \sum\limits_{i=1}^n W_i
Prepare Word Vectors
// Save raw text file of all reviews -- one per line -- for FastText training purposes
music_reviews.select("reviewText").rdd.map(r => r(0).toString)
.coalesce(1).saveAsTextFile("file:///.../music/text")
/*
Train Word Vectors from Text -- Using Fast Text
=========
fasttext skipgram -input part-00000 -output word_vectors -dim 300
*/
// Load word-vectors into memory map
val raw_word_vectors = sc.textFile("file:///.../music/text/word_vectors.vec")
.mapPartitionsWithIndex { (idx, iter) =>
if (idx == 0) iter.drop(1) else iter }
// Get all keywords from parsed sentences
val keywords = parsed_sentences.flatMap(x => x).map(x => x._1).toList
// Filter word vectors
val filtered_word_vectors = raw_word_vectors.filter(line => keywords.contains(line.split(" ")(0)))
filtered_word_vectors.cachePrepare Word Vectors
// Zip sentences together to get index
val indexed_sentences = parsed_sentences.zipWithIndex
// Parallize sentences
val sentences_rdd = sc.parallelize(indexed_sentences)
// Break into individual keywords
case class SentenceKeyword(id: Int, keyword: String, pos: String)
val keywords_by_sentence = sentences_rdd.flatMap(s => s._1.map(x => (s._2, x._1, x._2)))
.map(s => SentenceKeyword(s._1, s._2, s._3))
// Save to disk
keywords_by_sentence.toDF().write.parquet("file:///.../music/parsed_sentences/")
// Load from disk
val keywords_by_sentence = sqlContext.load("file:///.../music/parsed_sentences/*", "parquet")
.as[SentenceKeyword]
// Merge with keywords
val transformed_word_vectors = filtered_word_vectors.map(line => {
// Split line
val values = line.split(" ")
// Add to in-memory word vector map
(values(0), values.slice(1, values.length).map(_.toFloat))
})
val grouped_keywords_vectors = keywords_by_sentence.map(sk => (sk.keyword, sk))
.rdd.cogroup(transformed_word_vectors)
Prepare Word Vectors
// Map keywords to vectors
case class MappedSentenceKeyword(id: Int, keyword: String, vector: Array[Float])
val mapped_sentence_keywords = grouped_keywords_vectors.flatMap(grouped_keyword => {
// Check if word exists
if(grouped_keyword._2._2.toList.length > 0) { // word exists in vocabulary
// Get word vector
val word_vector = grouped_keyword._2._2.toList(0)
// Map each sentence keyword to vector
grouped_keyword._2._1.toList.map(sk => {
MappedSentenceKeyword(sk.id, sk.keyword, word_vector)
})
} else {
// Map each sentence keyword to vector
grouped_keyword._2._1.toList.map(sk => {
MappedSentenceKeyword(sk.id, sk.keyword, new Array[Float](300))
})
}
})
// Save to disk
mapped_sentence_keywords.toDF().write.parquet("file:///.../music/mapped_sentence_keywords/")
// Load from disk
val mapped_sentence_keywords = sqlContext.load("file:///.../music/mapped_sentence_keywords/*",
"parquet").as[MappedSentenceKeyword]
Create Sentence Graph
// Load sentences
case class IndexedSentence(id: Int, keywords: List[MappedSentenceKeyword])
val indexed_sentences = mapped_sentence_keywords.rdd.map(sk => (sk.id, sk)).
groupByKey().map(x => IndexedSentence(x._1, x._2.toList))
// Create sentence pairs
val sentence_pairs = indexed_sentences.flatMap(s1 => {
// Only create pairs for sentences that have an ID greater than the current sentences ID
sentences_array.slice(s1.id + 1, sentences_array.length).map(s2 => (s1, s2))
})
// Create sentence graph
case class SentenceEdge(id_1: Int, id_2: Int, score: Double)
val sentence_graph = sentence_pairs.map(S => {
// Zip keywords with vectors
val s1_vectors = (S._1.keywords.map(_.vector)).map(arr => new DenseVector(arr.map(_.toDouble)))
val s2_vectors = (S._2.keywords.map(_.vector)).map(arr => new DenseVector(arr.map(_.toDouble)))
// Fold and normalize each vector
val avg_s1_vector = s1_vectors.fold(DenseVector.zeros[Double](300))
((acc,v) => { acc + v }) / (1.0 * s1_vectors.length)
val avg_s2_vector = s2_vectors.fold(DenseVector.zeros[Double](300))
((acc,v) => { acc + v }) / (1.0 * s2_vectors.length)
// Return sentence graph edge
SentenceEdge(S._1.id, S._2.id,
CosineSimilarity.cosineSimilarity(avg_s1_vector.toArray, avg_s2_vector.toArray))
})
// Save sentence graph to disk
sentence_graph.toDF().write.parquet("file:///.../music/sentence_graph/v1/")
// Load sentence graph from disk
val sentence_graph = sqlContext.load("file:///.../music/sentence_graph/v1/*").as[SentenceEdge]
Compute PageRank
// Create vertex RDD from sentences
val sentenceVertices: RDD[(VertexId, String)] =
indexed_sentences.map(s => (s.id.toLong, s.id.toString))
val defaultSentence = ("-1")
// Create edges RDD from sentence graph -- only create links if above minimum similarity
val sentenceEdges = sentence_graph.filter(se => se.score > 0.75).flatMap(se => {
List(Edge(se.id_1.toLong, se.id_2.toLong, se.score),
Edge(se.id_2.toLong, se.id_1.toLong, se.score))
}).rdd
// Create graph
val graph = Graph(sentenceVertices, sentenceEdges, defaultSentence)
graph.persist() // persist graph (for performance purposes
// Calculate page rank
val ranks = graph.pageRank(0.0001).vertices
// Find top K sentences by rank
val top_ranks = ranks.sortBy(_._2, ascending=false).take(10)
val ranksAndSentences = ranks.join(sentenceVertices).sortBy(_._2._1, ascending=false).map(_._2._2)
// Get the top 10 results
ranksAndSentences.take(10)
/*
Results: (1401, 824, 2360, 2717, 4322, 1150, 4363, 2320, 238, 3128)
*/
Get Results
// Zip sentences together to get index
case class SentenceRaw(id: Int, text: String)
val indexed_sentences_original = sentences.toList
.zipWithIndex.map(x => (x._1.text(),
x._2))
val sentencesArray = sc.parallelize(indexed_sentences_original).collect()
sc.parallelize(sentencesArray.map(x => SentenceRaw(x._2, x._1)))
.toDF().registerTempTable("sentences")
// Show top sentences
sqlContext.sql("SELECT text
FROM sentences
WHERE id in (1401, 824, 2360, 2717, 4322,
1150, 4363, 2320, 238, 3128)")
.map(r => r(0).toString).rdd.foreach(println)
Results
"This is the best music, the best recording, the best rock album, the best concept album."
Results
"To make a long review short, you should buy "Dark Side Of The Moon" because: a) it's music, combining the band's sharp songwriting, outstanding musical chemistry, and impressive in-the-studio skills, is fantastic, b) it's timeless theme about all the things in life that can drive us mad---money, mortality, time (or lack of), war, etc., is pure genius, c) the clever lyrics by Roger Waters REALLY hit home, d) it's unsurpassed production & sound effects make it without question THE album to test your new stereo equipment with, and e) although I've never tried it myself, it's widely reputed to be a GREAT soundtrack album for....er, intimate encounters (especially while playing "The Great Gig In The Sky"---it's supposed to be really cool, man)."
Results
"The Dark Side Of The Moon is a key album into defining the peak of space rock, the revival of psychedelic rock into modern settings, the point were blues is taken into a higher prospective, the point were progressive rock can't be called pretentious but remarkable nor snooze cultural but sincere and direct, and the unique characteristic where music fits with the listener and musicians in the most pure way; not their most complex neither their most cultural one, but the most pure."
How to Contact Me
garrett@dataexhaust.io
- Follow up questions
- Model development / implementation
- Product team training
- Moral support
Dynamic Content Summarization
By Garrett Eastham



