Deep Software Engineering for Artificial Code Generation

Talking points (09.16.19)
-
Why does understanding the abstract representations of source code matter? What's the motivation behind? How shall we introduce the idea?
-
Uniqueness of source code:
-
Granularity concept
-
Automatic programming applicability
-
-
Any studies in the Computer Science community:
-
Automatic Programming (Program Synthesis)
-
Structured Generative Models of Natural Source Code (Maddison & Tarlow, 2014)
-
Deep Software Engineering operates with tensors for modeling high-level representations of software data, such operations are employed to automate SE tasks
Neural Network
SE
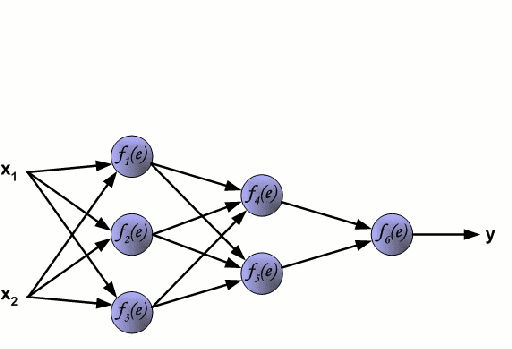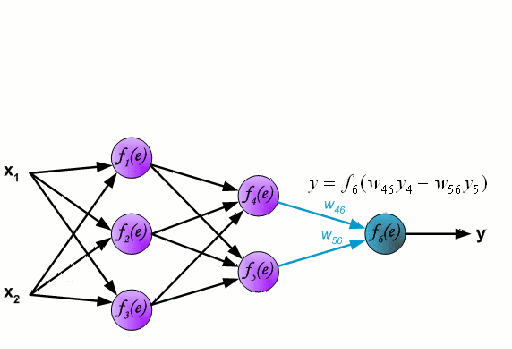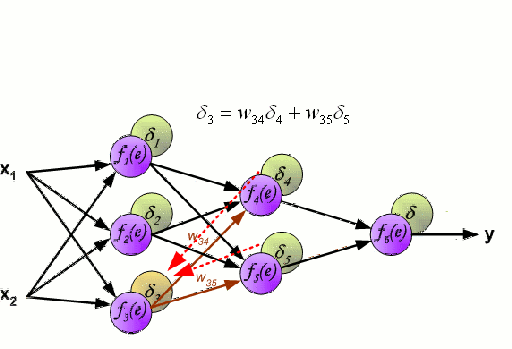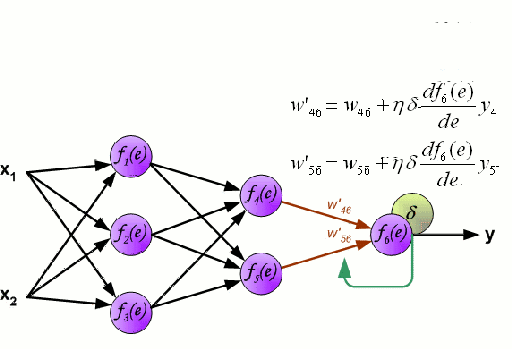
\to

Artificial Code Generation is the automatic construction of source code by means of Generative Models; algorithms which are able to generate source code might be substantially better at understanding intrinsically SE tasks
Neural Network
Program
\to

Holistic View
Source Code Generative Agent

Real Source Code
Synthetic Source Code
A (deep) NN model is able to learn the abstract features of source code to generate the same structure
Source Code Generative Agent
SE Discriminative Agent

A generative agent can be converted into a discriminative one to solve a supervised task
Transfer Learning

Source Code

SE Task
Supervised SE Task
A fine-tuned discriminative agent is able to solve and automate SE tasks in an enhance fashion
SE Discriminative Agent
OpenAI proves that Generative Agents can be trained for specific discriminative tasks
Source Code Generative Agent
SE Discriminative Agent
Purpose: to synthesize and understand the intrinsic properties of the source code
Purpose: to perform classification (e.g., bug fixing, security-related identification, traceability) or regression (prediction of metrics: bugs, source code size, error proneness)
Multi-taskers
Are machines able to learn how to generate "unique" source code?
Main Research Question
Real Source Code
We know from the Hoeffding's inequality that "learning" is feasible. However, obtaining such generalization would require more than training one agent. Goodfellow demonstrates that generator and discriminator competition improves agents' knowledge

Gaussian Noise
Synthetic Source Code
SC Generator
SC Discriminator
"unique" source code occurs as a collective behavior from the interaction of several (generative/discriminative) agents in a controlled environment
Hypothesis
Agents might be able to produce "unique" source code as an emergent behavior from the non-linear interactions with each other. Such emergent behavior is supported by observations from complexity science
Enhanced Software 2.0 Programs? or Probably Brand-New Programs?
Enhanced synthesized source code?

This research has, in total, four views
First view: The generative Agent
Second view: The discriminative Agent
Third view: Generative Agents by Competition
Fourth view: Emergent "uniqueness" by complex interactions
First view: The generative Agent
Second view: The discriminative Agent
Third view: Generative Agents by Competition
Fourth view: Emergent "uniqueness" by complex interactions
First view: The generative Agent
Second view: The discriminative Agent
Third view: Generative Agents by Competition
Fourth view: Emergent "uniqueness" by complex interactions
First view: The generative Agent
Second view: The discriminative Agent
Third view: Generative Agents by Competition
Fourth view: Emergent "uniqueness" by complex interactions
SE-Based Benchmarks for Understanding and Comparing Deep Generative Source Code Models
Why benchmarking for deep generative source code models?
- Fair comparison against other models
- Understanding of learning deep models
- Standardization of datasets and statistical analysis
- Enhancing reproducibility and replicability
- Identifying DL-oriented errors like:
- Long-range dependencies
- Rare tokens
- Semantic (i.e. returning the correct type)
A Benchmark is composed of:
- Test Case (goal): Identifying Long-Range Interaction
- Testbed: 100 java methods with different token sizes
-
Procedure:
- Train a generative model G(x)
- Compute the cross-entropy loss least 40 times for the testbed
-
Performance metric:
- Mean cross-entropy across methods
- Standard-deviation cross-entropy
Structure of the paper
Introduction
- Motivating how important is to build proper benchmarks for generative models and the advantages of having tailored statistical procedures to evaluate DL-models
- Introducing generative models in a gentle way (guided) and transfer learning
Train Code Data \sim p_{data}(x)
Generated Code Samples \sim p_{model}(x)
The goal of generative research is to answer the question: How can we learn p_model similar to p_data?
p_{model}(x) \approx p_{data}(x)
Train Code Data \sim p_{data}(x)
Generated Code Samples \sim p_{model}(x)
The goal of generative research is to answer the question: How can we learn p_model similar to p_data?
p_{model}(x) \approx p_{data}(x)
Observational Joint
Interventional Joint
Deep Generative Obvs. Code Models
- Generative model relationships: (x: source code) (z or y labels) (Theta: parameters)
Unconditioned Generator
p(x,\theta)
p(x|z,\theta)
p(y|x,\theta)
Conditioned Generator
Discriminator
Observational Code Model
Deep Generative Inter. Code Models
- Generative model relationships: (x: source code) (z or y labels) (Theta: parameters)
Unconditioned Generator
p_{do(\Theta = \theta)}(x,\theta)
p(x|z,do(\theta))
p(y|x,do(\theta))
Conditioned Generator
Discriminator
Interventional Code Model
p_{data}(x,y,z,\theta)
Deep Generative Obvs. Code Models
Unconditioned Generator
p(x,\theta)
p(x|z,\theta)
p(y|x,\theta)
Conditioned Generator
Discriminator
Deep Generative Inter. Code Models
- Generative model relationships: (x: source code) (z or y labels) (Theta: parameters)
Unconditioned Generator
p_{do(\Theta = \theta)}(x,\theta)
p(x|z,do(\theta))
p(y|x,do(\theta))
Conditioned Generator
Discriminator
p_{model}(x,y,z,\theta)
p_{data}(x,y,z,\theta)
Deep Generative Obvs. Code Models
- Generative model relationships: (x: source code) (z or y labels) (Theta: parameters)
Unconditioned Generator
p(x,\theta)
p(x|z,\theta)
p(y|x,\theta)
Conditioned Generator
Discriminator
Self-Supervised
Unsupervised
Supervised
p_{data}(x,y,z,\theta) \to G_{\theta}^O(x)
p_{data}(x,y,z,\theta) \to D_{\theta}^O(y|x)
G^O(x,\theta)
Triangle of Observational/Interventional Sampling
Unconditional
p(x|w=w_0,\theta)
p(x|w,\theta)
p(y|x,\theta)
Conditional
Classification
p_{data}(x,w,y,\theta) \to G^O(x,\theta)
p_{data}(x,y,z,\theta) \to D_{\theta}^O(y|x)
p(x|w=w_0,do(\theta))
p(x|w,do(\theta))
p(y|x,do(\theta))
p_{model}(x,w,y,\theta) \to G_{do(\Theta=\theta)}^I(x,\theta)
G_{do(\Theta=\theta)}^I(x,\theta)
Deep Code Generator
Autoregressive Transfer Learning
Unconditioned Generator
Conditioned Generator
Discriminator
Unsupervised
Supervised:
- Transf AWD
- Trans Tranformer
Self-Supervised:
- AWD-LSTM
- Tranformer
Fine-Tuning
?
p(x,\theta)
p(x|z,\theta)
p(y|x,\theta)
Sampling
- Sampling Methods: temperature (others top-k or nucleus)
Unconditioned Generator
Conditioned Generator
Unconditioned Sampling
Unconditioned Training
Conditioned Sampling
p_{do(\Theta = \theta)}(x,\theta)
p(x|z,do(\theta))
Empirical Evaluation
- Unconditioned Model
- Conditioned Model
Unconditioned Evaluation (interventional and observational)
Unconditioned Models: Manifold Analysis
- Manifold Visualization and Vectorization: code2vec
Unconditioned Interventional Sampling
Unconditioned Observational Sampling
p_{do(\Theta = \theta)}(x,\theta)
p(x,\theta)
Unconditioned Models: Semantic Manifold
Unconditioned Interventional Sampling
Unconditioned Observational Sampling
p_{do(\Theta = \theta)}(x,\theta)
p(x,\theta)
KL(p_{do(\Theta = \theta)}(x,\theta) || p(x,\theta) )
KL( p(x,\theta) || p_{do(\Theta = \theta)}(x,\theta) )
Unconditioned Models: Syntactic Manifold
Unconditioned Interventional Sampling
Unconditioned Observational Sampling
p_{do(\Theta = \theta)}(x,\theta)
p(x,\theta)
\sigma_{syx}( p_{do(\Theta = \theta)}(x,\theta) )
\sigma_{syx}( p(x,\theta) )
Unconditioned Models: SE Structure Manifold
Unconditioned Interventional Sampling
Unconditioned Observational Sampling
p_{do(\Theta = \theta)}(x,\theta)
p(x,\theta)
\sigma_{str}( p_{do(\Theta = \theta)}(x,\theta) )
\sigma_{str}( p(x,\theta) )
In conclusion, Manifold Analysis is three fold
- Semantic
- Syntactic
- SE Structure
Conditioned Evaluation (potential outcomes and counterfactuals)
Conditioned Models: Randomized Experiment
A \in (1:lstm, 0:txl)
Y is a code assessment property and A is the "treatment" or model employed.
Y \to (syx, str, loss)
E \in (1:noisy, 0:feasible)
Conditioned Models: Randomized Experiment
A \in (1:lstm, 0:human)
Syntax Correctness in all the individuals (or samples) under lstm treatment
Y \to syx
Y^{a=1}
Y^{a=0}
Syntax Correctness in all the individuals (or samples) under human treatment
Causal Inference Evaluation
A \in (1:lstm, 0:human)
We say that the generative agent (or autoregressive model) has a causal effect on the Syntax Correcteness if ...
Y \to syx
Y^{a=1}
Y^{a=0}
Y^{a=1} \neq Y^{a=0}
Causal Inference Evaluation: Null Causality
A \in (1:lstm, 0:human)
We are interested in null causality. We don't want to observe a causal effect on outcomes.
Y \to syx
Y^{a=1}
Y^{a=0}
E[P^{a=1}] - E[P^{a=0}] = 0
E[\sigma_{syx}(\hat(x))] - E[\sigma_{syx}(x))] = 0
\mathbb{E}_\theta
Interactions
A \in (1:lstm, 0:human)
We are interested in null causality. We don't want to observe a causal effect on outcomes.
Y \to syx
Y^{a=1}
Y^{a=0}
E[P^{a=1}] - E[P^{a=0}] = 0
E[\sigma_{syx}(\hat(x))] - E[\sigma_{syx}(x))] = 0
Deep Generative Source Code Models
- It introduces what is p(x), p(x|y) and p(y|x)
- Autoregressive as Generative Models
- Transfer Learnt Autoregressive
- Sampling Methods: top-k or nucleus
- Manifold Visualization and Vectorization: code2vec
Data Collection and Analysis
-
Datasets: raw data and structured data
- CodeSearchChallenge (~6M-method g)
- TitanGenCode (~1M-language-file g)
- TufanoBuggy/NonBuggy (~1M)
Distribution of the dataset
Training
Validation
Test
BPE
Data Collection and Analysis
Training (0.8)
Validation (0.1)
Test (0.09)
BPE (0.01)
[feasible-java-methods]
Testbed Generation
[feasible-py-methods]
[transXL-java-samples]
Transformation
[noisy-py-methods]
Deep Generators
[TransformerXL]
[AWD-LSTM]
Sampling
[noisy-java-methods]
[lstm-java-samples]
[transXL-py-samples]
[lstm-py-samples]
\mathbb{E}_\theta[P^{a=1}] - \mathbb{E}_\theta[P^{a=0}]
p(x|w=w_0,do(\theta))
G^O(x,\theta)
G_{do(\Theta=\theta)}^I(x,\theta)
Unconditional Interpretability
Artificial Code Data
Human Code Data

Manifold
Causal Inference
Conditional Interpretability
1
2
1
4
3
5
\vec\gamma
\vec\alpha
\vec\beta
T_i(x) = \hat{x}
d_{k}(\vec\alpha,\vec\beta)
Manifolds
LOC
CYCLO
FORs
\vec\alpha
\vec\beta
d_{cpl}(\vec\alpha,\vec\beta)=\|\vec\alpha - \vec\beta\|
d_{str}(\vec\alpha,\vec\beta)=\|\vec\alpha - \vec\beta\|
...
LOC
CYCLO
FORs
...
SE Structure Distance
1
;
-
-
...
;
-
-
...
;
-
-
...
\vec\gamma
Compilation Error Distance
d_{cpl}(\vec\gamma,\vec\beta)=\|\vec\gamma - \vec\beta\|
2
3
4
\vec\gamma
\sim p_{machine}(x,\theta)
\sim p_{human}(x,\theta)
Inf. Contentent & Semantic Distance
d_{sem}(human,artificial) =
KL( G^O(x,\theta) || p(x|w=w_0,do(\theta)) )
d_{sem}^{KL}(p_{human},p_{machine})
d_{sem}^{s}(p_{human},p_{machine})
1
2
3
Data Collection and Analysis
- Pre-processing with Byte-Pair Encoding
Training
Validation
Test
BPE
- Control of vocabulary
- Compressing information with minimum loss of information
Data Collection and Analysis
-
SE-oriented Exploratory Analysis (not just descriptive statistics)
- Finding unbalanced data and biased (KL divergence and Cross-Entropy)
- Entropy levels and gain information per method
- Structure of the data
- Quality of the data (SE metrics) and syntax correctness
- Distribution of the data
- Data snooping (clone detection)
Data Collection and Analysis
- Datasets
- Testbeds
- Pre-processing with Byte-Pair Encoding
- SE-oriented Exploratory Analysis
Benchmarking and Performance Metric Desing
- For Generative Unconditioned Models P(x)
- For Generative Conditioned Models P(x|y)
- For Discriminative Model P(y|x):
- Just one "special" SE-task
- Transfer Learnt Discriminative Model
Benchmarking and Performance Metric Desing
- For Generative Conditioned Models P(x|y)
- Test Case: Long-range interactions. Statistical analysis (probability on closing tokens). For example, the distance between '{' and '}'
-
Testbeds: [brace-end-x] :
- 0-20 granularity
- 20-40 granularity
- 40-60 granularity
-
Procedure:
- Retrieve the predicted probability for the ending token
- Make several inferences (around 35) to create confidence intervals
- Performance Metric: Mean P("}")

Benchmarking and Performance Metric Desing
- For Generative Unconditioned Models P(x)
- Test Case: Alien Meaningfulness Test Case. To identify unique/new methods or files that are not contained in the original training set. This analysis will provide insights into how different the generated code is from the code used for training
- Testbeds: [gen-code-x]:
- Procedure: Code Vectorization, K-medoids, overlapping, compute distances.
- Performance Metric: Uniqueness or distance between medoids
Alien Prototype
(confidence or entropy)
Original Training Set
Alien Criticism
Alien Prototype
Case Study 1
- Benchmarking for Unconditioned/Conditioned Autoregressive Models
- Models: AWD-LSTM, Transformer, and n-gram
- Dataset: [SearchCodeChallenge] and [TitanGenCode]
- Run Previous Benchmarks
Case Study 2
- Benchmarking for Transfer Autoregressive Model
- Models: AWD-LSTM (transferred)
- Dataset: [Buggy-NonBuggy-Tufano]
- Run Previous Discriminative Benchmark
The generative agent
First View
p(x,y)
Source Code Generative Agent
The generative model is autoregressive. That is, it is trained on sequential data by predicting the next token
p(x,y)
Conditioned Sampling
Unconditioned Sampling
P(w_0, \dots,w_m) = \prod_{i=0}^{m}P(w_i|w_1,\dots,w_{i-1})
P(w_0|token)
P(w_i|w_1,\dots,w_{i-1})
Conditioned Sampling Analysis
- Cross-Entropy measurement
- Noisy datasets
- Optimal testbeds
- Long-term dependencies with especial characters
- Typification of errors
P(w_i|w_1,\dots,w_{i-1})
Are machines able to produce correct source code? Which type of errors are generated?
Research Question
Unconditioned Sampling Analysis
- Mani-fold analysis
- KL-Divergence comparison
- Alien clustering
P(w_i|w_1,\dots,w_{i-1})
Are machines able to produce unseen source code? Which type of code is generated?
Research Question
Study Design
Autoregressive Models Under Study
- n-grams (for Source-Code)
- LSTM (many-to-one, many-to-many)
- GRU (many-to-one, many-to-many)
- Bi-(LSTM/GRU)
- Transformer (for Source-Code)
Output Space Analysis
Feature Space Analysis
Conditioned Sampling
Unconditioned Sampling
P(w_0|token)
P(w_i|w_1,\dots,w_{i-1})
Feature Clustering Representation
Cell Activation
Output Space Analysis
Feature Space Analysis
Conditioned Sampling
Unconditioned Sampling
P(w_0|token)
P(w_i|w_1,\dots,w_{i-1})
Clustering Represenation
Cell Activation
Pipeline (on a given 'g' granularity)
Unconditioned Sampling
P(w_0|token)
Pipeline (on a given 'g' granularity)
- Open-Ended Sampling (Beam, Top k & Nucleus)
- Data Vectorization (skip-grams or autoencoders)
- Identifying clusters on synthesized and human source code:
- Convex - Concave
- Computing centroids
- Uniqueness (criticisms and prototypes: separation of centroids)
Unconditioned Sampling
P(w_0|token)
A math representation of Source Code "Uniqueness"
Unconditioned Sampling
P(w_0|token)
\mathbb{R}^n \to \mathbb{R}^3
Uniqueness: distance from centroids
u = |d(c_i, c_j)|
Pipeline (on a given 'g' granularity)
- Open-Ended Sampling (Beam, Top k & Nucleus)
- Data Vectorization (skip-grams or autoencoders)
- Identifying clusters on synthesized and human source code:
- Convex - Concave
- Computing centroids
- Uniqueness (criticisms and prototypes: separation of centroids)
- Run Syntax Checker on Medioids (a measure of meaningfulness)
Unconditioned Sampling
P(w_0|token)
A math representation of Source Code "Meaningfulness"
Unconditioned Sampling
P(w_0|token)
Static: Syntax Checkers
Syntax Error Rate
Static and Dynamic Meaningfulness
Pipeline (on a given 'g' granularity)
- Open-Ended Sampling (Beam, Top k & Nucleus)
- Data Vectorization (skip-grams or autoencoders)
- Identifying clusters on synthesized and human source code:
- Convex - Concave
- Computing centroids
- Uniqueness (criticisms and prototypes: separation of centroids)
- Run Syntax Checker on Medioids (a measure of meaningfulness)
- Identify and describe "aliens" by overlapping human and synthetic datasets
Unconditioned Sampling
P(w_0|token)
Aliens by Overlapping
Unconditioned Sampling
P(w_0|token)
Alien Cluster
(confidence or entropy)
Alien Sample
Pipeline (on a given 'g' granularity)
- Open-Ended Sampling (Beam, Top k & Nucleus)
- Data Vectorization (skip-grams or autoencoders)
- Identifying clusters on synthesized and human source code:
- Convex - Concave
- Computing centroids
- Uniqueness (criticisms and prototypes: separation of centroids)
- Run Syntax Checker on Medioids (a measure of meaningfulness)
- Identify and describe "aliens" by overlapping human and synthetic datasets
- Compute KL-Divergence (distance from synthetic and human sets)
Unconditioned Sampling
P(w_0|token)
Pipeline (granularity: method level)
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
Pipeline (granularity: method level)
-
Long-range interactions: statistical analysis (probability on closing tokens). For example, the distance between '{' and '}'
-
Generate testbeds (if-else, {-}, (-), return, ';'):
- 0-20 granularity
- 20-40 granularity
- 40-60 granularity
- Retrieve the predicted probability for the ending token
- Make several inferences (around 35) to create confidence intervals
-
Generate testbeds (if-else, {-}, (-), return, ';'):
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
Pipeline (granularity: method level)
-
Long-range interactions: statistical analysis (probability on closing tokens). For example, the distance between '{' and '}'
-
Generate testbeds (if-else, {-}, (-), return, ';'):
- 0-20 granularity
- 20-40 granularity
- 40-60 granularity
- Retrieve the predicted probability for the ending token
- Make several inferences (around 35) to create confidence intervals
-
Generate testbeds (if-else, {-}, (-), return, ';'):
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
Pipeline (granularity: method level)
- ..
-
Error Analysis: to gain deeper insight into the errors that are unique to the generative models
- "... we define a character to be an error if the probability assigned to it by a model on the previous time step is below 0.5 ..."
- Build test-set
- Compute [avg+-std] probability assigned to the correct (target) token
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
for (int i = 0;=forint....
0.3
0.4
0.01
0.01
Pipeline (granularity: method level)
- ..
-
Error Analysis: to gain deeper insight into the errors that are unique to the generative models
- "... we define a character to be an error if the probability assigned to it by a model on the previous time step is below 0.5 ..."
- Build test-set
- Compute [avg+-std] probability assigned to the correct (target) token
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
for (int i = 0;=forint....
0.3
0.4
0.01
0.01

Pipeline (granularity: method level)
- ...
- ...
-
Failure cases: limitations of the generative models, the relative severity of each error, and to suggest areas for further study [probability]
- Categorize errors made in previous steps and create the procedures to remove them:
- "Return" oracle (e.g., scaling up neurons)
- "Repetitive tokens" oracle (e.g., augmenting n-gram window)
- "Bad Smells / Antipatterns" oracle
- "Bugs" oracle
- "Syntax error" oracle
- Categorize errors made in previous steps and create the procedures to remove them:
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
Pipeline (granularity: method level)
- ...
- ...
-
Failure cases: limitations of the generative models, the relative severity of each error, and to suggest areas for further study [probability]
- Categorize errors made in previous steps and create the procedures to remove them:
- "Return" oracle (e.g., scaling up neurons)
- "Repetitive tokens" oracle (e.g., augmenting n-gram window)
- "Bad Smells / Antipatterns" oracle
- "Bugs" oracle
- "Syntax error" oracle
- Categorize errors made in previous steps and create the procedures to remove them:
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
Transformer (20 layers)
Transformer (50 layers)
- syntax error removal
- token repetition removal
Pipeline (granularity: method level)
- ...
- ...
- ...
-
Entropy Analysis: (counterfactual analysis)
- Well-written code testbed
- Noisy code testbed
- Use mutations on well-written code
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
Well-written testbed
Which generative model is a good predictor?
Correlation
Pipeline (granularity: method level)
- ...
- ...
- ...
-
Entropy Analysis: (counterfactual analysis)
- Well-written code testbed
- Noisy code testbed
- Use mutations on well-written code
Conditioned Sampling
P(w_i|w_1,\dots,w_{i-1})
Well-written testbed
Noisy testbed 1
mutations
Noisy testbed 2
Which generative model is a good predictor?
Correlation
Causation
Projects
- Subproject 1: "Visualizing and Understanding Deep Autoregressive Generators for Source Code"
The discriminative agent
Second View
p(y|x)
Source Code Discriminative Agent
The generative model can be adapted by transfer learning strategies to become a discriminative one
p(y|x)
Classification
Regression

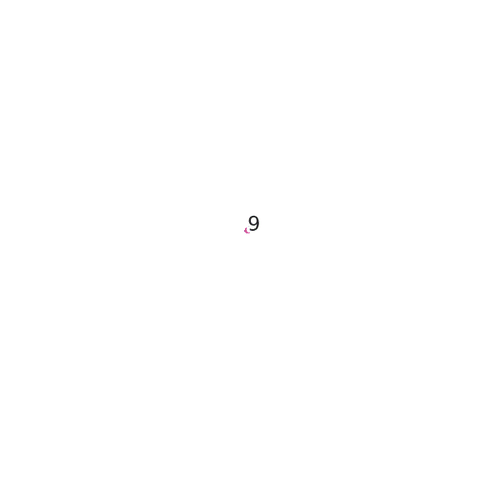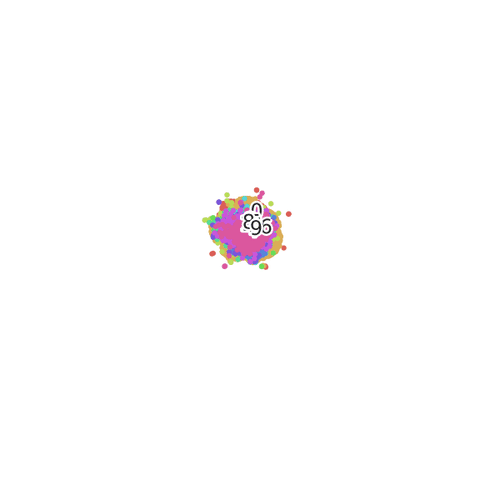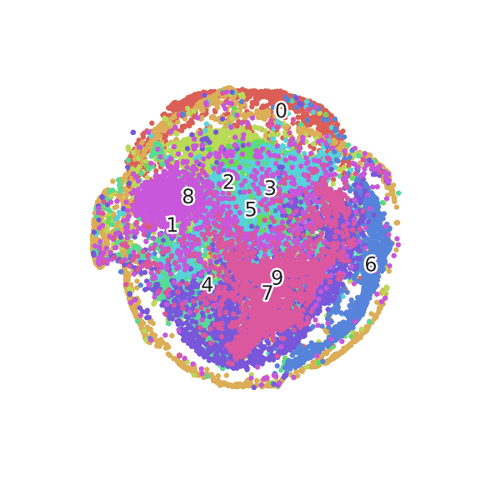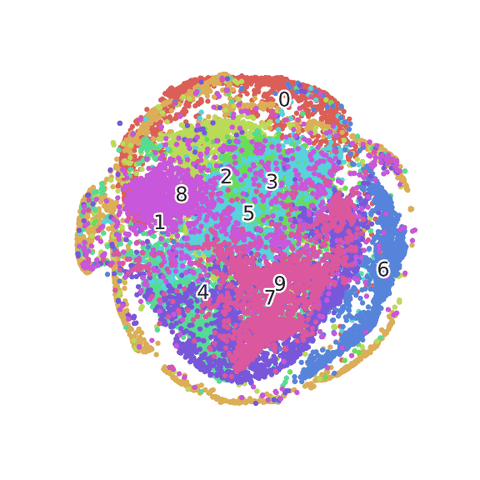
Classification Analysis
- Detecting Bugs
- Security-related identification
- Summarizing Source Code
Are pre-trained machines able to enhance the performance of supervised approaches? To what extent do Source Code Generators optimize the classification error?
Research Question
Source Code Generative Agent + Discriminative

SE Multitask Agent
Unsupervised multi-task learners are employed in Language Models, the same way we can employ SE Multitask learners!
- Code Summarization
- Code Completion
- Code Translation (bug fixing)
Projects
- Subproject 2: "Towards Enhancing Deep Software Classifiers via Pre-train (Generative) Models"
- Subproject 3: "Unsupervised Software Maintenance Multi-tasker "
Subproject #2
Universal Language Model FineTuning (ULMFiT)
- Pretraining a LM for better performance on downstream tasks
- Avoids catastrophic forgetting through specialized learning rates and gradual unfreezing of model weights
Counter Factual (Ablation) Study
- Compare frozen LM vs ULMFiT
- Trace back performance on downstream tasks to different error oracles
- Allows for analysis of which error type most impacts performance on downstream tasks
Downstream Tasks
- Classification:
- Vulnerable / Non Vulnerable
- Design Pattern
- Code Smell
- Clone Detection
- Regression:
- Bug localization
- Sequence to Sequence:
- Bug Repair
- Comment Generation
- Code Migration
- Test Case Generation
Subproject #3
Broad Research Goals
- Analyze different schemes of training an Auto Regressive Language Model for performing supervised tasks
- Compare approach against other SOTA models on the different supervised tasks
- Compare other transfer learning approaches against our transfer learning approach
- Evaluate ability of trained Language Model as a single task learner as well as multitask learner
GPT-2
Unsupervised Multi-Task Learner
- Able to perform multiple tasks (i.e. summarization, QA, translation, etc)
- Uses zero shot learning on target task
- Produces very convincing and coherent text
- Trained only on producing the next word given some context (millions of examples)
Limitations
- Only applicable to tasks that resemble those found in the training data (e.g. blog posts that contain TLDRs for text summarization)
- Requires a significant amount of data to get sub-par results across multiple tasks
Applying Auto Regressive Language Models to Supervised Tasks
Supervised Tasks as AR LM Tasks
- Supervised learning trains models on x, y pairs
- Can convert supervised tasks into AR LM tasks
- Treat y as a part of the vocabulary the AR LM is trying to predict given the context x
- To make multi tasking easier, add a special token to each supervised task
Classification Example
- Supervised task: Given some method x, predict if the a method has some code smell y
- AR LM Task: Convert code smell y into some text term such as "Long method" and append this term to x.
- E.g. "public static void ... } <code_smell> Long method"
- This gives the AR LM a bunch of training data that teaches it to produce the term "Long method" if it is given a method that is long.
Types of Supervised Tasks (SME)
Classification
- Given some class or method x, generate corresponding code smell y
- Given some class or method x, generate corresponding design pattern y
- Given some class or method x, generate corresponding ransomware y
- Given two classes or methods,x and x', generate corresponding clone classification y
Sequence to Sequence
- Given some question about some class or method x, generate corresponding answer y
- Given some class or method x, generate corresponding comments y
- Given some class or method x, generate corresponding test cases y
- Given some class or method x in some language p, generate corresponding method y in some language q
Counter Factual (Ablation) Study
- Trace back performance on downstream tasks to different error oracles
- Allows for analysis of which error type most impacts performance on downstream tasks
Empirical Evaluation of Supervised Tasks
- Compare training LM on multiple tasks vs single tasks
- Compare LM against SOTA supervised models
- Compare LM SOTA against transfer learning approaches
- Compare pretraining LM vs unpretraining LM for multi-task and single-task performance
Generative Agents by Competition
Third View
Real Source Code
Gaussian Noise
Synthetic Source Code
SC Generator
SC Discriminator
The generator learns how to create source code in such a way that the discriminator is not able to distinguish synthetic source code
Real Source Code
Gaussian Noise
Synthetic Source Code
SC Generator
SC Discriminator
The generator is an "Intelligent Agent" that is able to enhance its source code by competition (game theory)
Agent
Enviroment
To what extent do machines generate (human-level) Source Code? Are agents competition producing "unseen" source code?
Research Question
Projects
- Subproject 5: "Can Machines Generate (human-level) Source Code?"
Generating "human-level" Source Code with NeuroEvolution
Fourth View
Large scale agent interactions might produce "emergent" (human-level) source code
Close-ended Evolution
Open-Ended Evolution
f(x) = min(E)

Evolutionary Computation to communicate SC agents
Neural Network
Are Neural Networks Turing Complete?
Algorithm
Program
\approx
\approx

ON THE TURING COMPLETENESS OF MODERN NEURAL NETWORK ARCHITECTURES (ICLR'19 Perez, et al.)
Close-ended Evolution
- Define a fitness function to reduce the entropy
f(x) = min(E)
Close-ended Evolution
- Define a fitness function to reduce the entropy
- An individual (genotype) is a Neural Network
f(x) = min(E)
Close-ended Evolution
- Define a fitness function to reduce the entropy
- An individual (genotype) is a Neural Network
- An individual (phenotype) is Source Code
f(x) = min(E)
Close-ended Evolution
- Define a fitness function to reduce the entropy
- An individual (genotype) is a Neural Network
- An individual (phenotype) is Source Code
- Genetic Operators are based on "Transfer Learning" strategies
f(x) = min(E)
Are machines able to learn how to generate "human-level" source code?
Main Research Question
Open-ended Evolution
- "a process in which there is the possibility for an indefinite increase in complexity" (Corominas, et al. 2018)
- John von Neumann: self-replication, genotype-phenotype mappings, special classes of material substrates and Physico-chemical processes
- Alan Turing: Morphogenesis
https://royalsocietypublishing.org/doi/10.1098/rsif.2018.0395
- Property 1: Simple Components or agents (simple relative to the whole system)
Auto-regressive, adversarial, or autoenconder architectures
Trained Generative Agent
Trained Fine-Tuned Agent
Deep Neural Classifier
- Property 2: Nonlinearity and Complex Interactions (synergy)
Better Performance
Generative Agents are sensitive to initial conditions (hyper-parameters) and inputs
Fine-Tune Strategy 1
Fine-Tune Strategy 2
Worst Performance
- Property 3: Descentralization or no central control
No leading agent or "deep neural net" controlling for interactions
- Property 4: Emergency
Case study 1 [self-replication]: Are self-replicated "programs" (or NN or Software 2.0) somewhat better? What type of properties have? Can the multi-tasker agents perform a brand new task?
- Property 4: Emergency
Case study 2 [self-organization]: are the generative agents reporting enhanced accuracy after transfer-learning interactions?
Assembled Agent (by transfer learning strategies)
Enhanced synthesized code?
Simple and Local Transfer Rules
Better accuracy? What type of tasks emerged?
Fine-Tuning

Complex Programs or Advanced Software Systems
Projects
- Subproject 6: "Emerging Human-Level Source Code by Complex Interactions of Deep Software Engineering Agents"
Interpretability
Fifth View
Title Text
-
[semantic|conditioned] Learned Representation Analysis for SE Metrics: to determine if the learned representation from the generators has learned about the concept of SE metrics such as cyclomatic complexity, lines of code, etc.
-
Probing classifier - MLP that is fed the representation (i.e. hidden state) of a method the model is given and is asked to predict some SE Metric, i.e. cyclomatic complexity
-
Performance Metric: We are attempting to measure how well the generator is able to capture SE related metrics and so we will be measuring mostly precision, recall, accuracy for each SE metric.
-
Title Text
- [code-smell-01] Testbed of smelly methods such as long method, feature envy, etc.
[design-pattern-01] Testbed of classes with different design patterns such as factory method, singleton, decorator, etc.
[anti-pattern-01] Testbed of classes with different anti patterns such as anemic domain model, call super, circular dependency, etc.
[ast-01] Testbed of methods with different types of AST nodes and relations.
[cfg-01] Testbed of methods with different types of CFGs.
[type-01] Testbed for classifying the type based on the variable name
Summary
First view: The generative Agent
Second view: The discriminative Agent
Third view: Generative Agents by Competition
Fourth view: Emergent "uniqueness" by complex interactions
Deep Software Engineering for Artificial Code Generation
By David Nader Palacio



