Enabling Software Traceability Analyses
For Continuous Integration
David N. Palacio, Kevin Moran, Carlos Bernal-Cárdenas,
Denys Poshyvanyk, Chris Shenefiel
Agenda
- Why Traceability Matters?
- Brief Introduction to Software Traceability
- Project Overview
- SecureReqNet & Comet
- Neural Unsupervised Software Traceability
- Information Science to Understand Trace Models
- Tools [Jenkins Integration]
enthusiastic developer


assigned


new Webex requirement
checks
repos
Where does our enthusiastic dev start at?
enthusiastic developer
assigned
new Webex requirement
checks
implements
repos
A Comprehension Problem

assigned
new Webex requirement
checks
implements
repos
Which artifacts are being affected by the req?


architecture team
assigned
new Webex requirement
checks
implements
repos
An Impact Change Problem

affects a set of artifacts
architecture team

inspects
new Webex requirement
checks
repos
What if instead of the developer, an analyst is assessing the security impact of the requirement?

affects a set of artifacts
inspects
new Webex requirement
checks
is the new req security related?
repos
A Security Problem
affects a set of artifacts
Stakeholders
- Managers
- Data Scientists
- Testers
Imagine other roles in the company related to the new req
Source Code
Test Cases
Bug Reports
Requirements
Software Artifacts and their nature
Source Code
Test Cases
Bug Reports
Requirements
Software Artifacts and their nature
Software Team Assessment
How can we automatically identify if the source code is related to a specific requirement?

Software Data Mining or Traceability is the mechanism to uncover implicit relationships among software artifacts

Why should we run Traceability Analyses for CI?
Continuous Integration enables maintainability
Traceability eases change impact and program comprehension during maintainability
Some consequences:
- Errors
- Software Decay
- Vulnerability Proneness
- Wasted Effort
Researchers have shown that engineers who have little knowledge of the code tent to apply changes to inadequate code locations (P. Mader, et al; 2011).
Software Traceability Background
Source File
Requirement (Issue) File
Software Traceability is the mechanism to uncover implicit relationships among software artifacts
How deep are the artifacts correlated?
Source File
Requirement (Issue) File
Test File
How deep are the artifacts correlated?
Source File
Requirement (Issue) File
Test File
Is it feasible to manually recover trace links? How do you assess the quality of those manual links?
Assuming that the artifacts of a software system are text-based (e.g., requirements, source code, or test cases), what type of automation techniques can be employed to uncover hidden links?
\theta
Trace Link (Similarity) Value [0,1]
S_n
Source Artifacts (i.e., requirement files)
T_n
Target Artifacts (i.e., source code files)
\theta = f_{IR/ML}(S_n, T_n) = dist(S_n,T_n)
Information Retrieval (IR) or Machine Learning (ML) techniques help to vectorize text-based artifacts and perform a distance metric
S_n
T_n
\theta = dist(S_n,T_n)
Project Overview
IR on Security Req
0
COMET
CI T-Miner
1
1
IR on Security Req
0
SecureReqNet
COMET
CI T-Miner
1
2
1
IR on Security Req
0
SecureReqNet
COMET
CI T-Miner
1
2
1
IR on Security Req
0
Deep Unsupervised Traceability
3
SecureReqNet
COMET
T-Miner
CI T-Miner
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
SecureReqNet
COMET
T-Miner
CI T-Miner
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
Security
Soft. Trace.
Tools
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
SecureReqNet
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev

Issue Tracker
Security Related
non-Security Related
We need to design automated approaches to identify whether <issues> describe Security-Related content




SecureReqNet is an approach that identifies whether <issues>describe security-related content
Issue Tracker

(Shallow) SecureReqNet
α-SecureReqNet

ICSME-2019 Cleveland, OH - SecureReqNet Paper
The Link Recovery Problem and Its Probabilistic Nature
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
The link recovery problem is the fundamental problem in Software Traceability; it consists of automatically establishing the relationships of artifacts allowing for the evolution of the system (maintainability)
Source File
Requirement File
\theta
The link recovery problem: How would you compute θ ?
\theta
Trace Link (Similarity) Value [0,1]
\theta_n
Trace Link from Requirement to Test Case
Exec_n
Execution Trace from Source Code to Test Case
S_n
Source Artifacts (i.e., requirement files)
T_n
Target Artifacts (i.e., source code files)
Source File
Requirement File
Test File
\theta = ?
Exec_1
How do we enhance link recovery with recent IR/ML approaches?
Source File
Requirement File
Test File
\theta = ?
Exec_1
\theta_1
What if we compute a second θ for Req→Tc? Is the initial θ affected?
Source File
Requirement File
Test File
Test File
\theta = ?
Exec_2
Exec_1
\theta_1
\theta_2
And what if we add more information?
Prediction
Inference
Use the model to predict the outcomes for new data points
Use the model to learn about the data generation process
Prediction
Statistical Inference Methods:
- Probabilistic Inference or Bayesian Inference
- Causal Inference
Inference
Learning Process:
- Machine Learning
- Deep Learning
Source File
Requirement File
Test File
Test File
\theta = ?
Exec_2
Exec_1
\theta_1
\theta_2
Do we use Inference or Prediction to compute θ?
\theta \approx P(H|O) = \frac{P(O|H)\cdot P(H)}{P(O)}
The link recovery problem is a Bayesian Inference Problem since we want to uncover a probabilistic distribution throughout a reasoning process
A HierarchiCal PrObabilistic Model for SoftwarE Traceability
[COMET]
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
The General Model
Bayesian Inference Traceability
Examples from cisco/LibEST
(``RQ_4", ``est\_ossl\_util.c")
REQUIREMENT 4: OBTAINING CA CERTIFICATES:
| The EST client can request a copy of the current EST CA certificate(s) from the EST server. The EST client is assumed to perform this operation before performing other operations. |
/*****************************************************************************************
* Authorization routines
*****************************************************************************************/
int ossl_verify_cb (int ok, X509_STORE_CTX *ctx)
{
int cert_error = X509_STORE_CTX_get_error(ctx);
X509 *current_cert = X509_STORE_CTX_get_current_cert(ctx);
EST_LOG_INFO("enter function: ok=%d cert_error=%d", ok, cert_error);
if (!ok) {
if (current_cert) {
X509_NAME_print_ex_fp(stdout,
X509_get_subject_name(current_cert),
0, XN_FLAG_ONELINE);
printf("\n");
}
EST_LOG_INFO("%serror %d at %d depth lookup:%s\n",
X509_STORE_CTX_get0_parent_ctx(ctx) ? "[CRL path]" : "",
cert_error,
X509_STORE_CTX_get_error_depth(ctx),
X509_verify_cert_error_string(cert_error));
switch (cert_error) {
case X509_V_ERR_UNABLE_TO_GET_CRL:
/*
* We've enabled CRL checking in the TLS stack. If
* the application hasn't loaded a CRL, then this
* verify error can occur. The peer's cert is valid,
* but we can't confirm if it was revoked. We'll
* warn the application.
*/
EST_LOG_WARN("No CRL loaded, TLS peer will be allowed.");
ok = 1;
break;
case X509_V_ERR_NO_EXPLICIT_POLICY:
case X509_V_ERR_CERT_HAS_EXPIRED:
/* since we are just checking the certificates, it is
* ok if they are self signed. But we should still warn
* the user.
*/
case X509_V_ERR_DEPTH_ZERO_SELF_SIGNED_CERT:
/* Continue after extension errors too */
case X509_V_ERR_INVALID_CA:
case X509_V_ERR_INVALID_NON_CA:
case X509_V_ERR_PATH_LENGTH_EXCEEDED:
case X509_V_ERR_INVALID_PURPOSE:
case X509_V_ERR_CRL_HAS_EXPIRED:
case X509_V_ERR_CRL_NOT_YET_VALID:
case X509_V_ERR_UNHANDLED_CRITICAL_EXTENSION:
case X509_V_ERR_CERT_REVOKED:
default:
EST_LOG_WARN("Certificate verify failed (reason=%d)",
cert_error);
break;
}
return ok;
}
return (ok);
}
/*
* This function is used to load an X509_STORE using raw
* data from a buffer. The data is expected to be PEM
* encoded.
*
* Returns the number of certs added to the store
*/
static int ossl_init_cert_store_from_raw (X509_STORE *store,
unsigned char *raw, int size)
{
STACK_OF(X509_INFO) * sk = NULL;
X509_INFO *xi;
BIO *in;
int cert_cnt = 0;
in = BIO_new_mem_buf(raw, size);
if (in == NULL) {
EST_LOG_ERR("Unable to open the raw CA cert buffer\n");
return 0;
}
/* This loads from a file, a stack of x509/crl/pkey sets */
sk = PEM_X509_INFO_read_bio(in, NULL, NULL, NULL);
if (sk == NULL) {
EST_LOG_ERR("Unable to read PEM encoded certs from BIO");
BIO_free(in);
return 0;
}
BIO_free(in);
/* scan over it and pull out the CRL's */
while (sk_X509_INFO_num(sk)) {
xi = sk_X509_INFO_shift(sk);
if (xi->x509 != NULL) {
EST_LOG_INFO("Adding cert to store (%s)", xi->x509->name);
X509_STORE_add_cert(store, xi->x509);
cert_cnt++;
}
if (xi->crl != NULL) {
EST_LOG_INFO("Adding CRL to store");
X509_STORE_add_crl(store, xi->crl);
}
X509_INFO_free(xi);
}
if (sk != NULL) {
sk_X509_INFO_pop_free(sk, X509_INFO_free);
}
return (cert_cnt);
}
/*
* This function is used to populate an X509_STORE structure,
* which can be used by the OpenSSL TLS stack to verifying
* a TLS peer. The X509_STORE should already have been allocated.
*
* Parameters:
* store - Pointer to X509_STORE structure to hold the certs
* raw1 - char array containing PEM encoded certs to put
* into the store.
* size1 - Length of the raw1 char array
*/
EST_ERROR ossl_init_cert_store (X509_STORE *store,
unsigned char *raw1, int size1)
{
X509_STORE_set_flags(store, 0);
int cnt;
if (raw1) {
cnt = ossl_init_cert_store_from_raw(store, raw1, size1);
if (!cnt) {
EST_LOG_ERR("Cert count is zero for store");
return (EST_ERR_NO_CERTS_FOUND);
}
}
return (EST_ERR_NONE);
}
/*
* This function can be used to output the OpenSSL
* error buffer. This is useful when an OpenSSL
* API call fails and you'd like to provide some
* detail to the user regarding the cause of the
* failure.
*/
void ossl_dump_ssl_errors ()
{
BIO *e = NULL;
BUF_MEM *bptr = NULL;
e = BIO_new(BIO_s_mem());
if (!e) {
EST_LOG_ERR("BIO_new failed");
return;
}
ERR_print_errors(e);
(void)BIO_flush(e);
BIO_get_mem_ptr(e, &bptr);
EST_LOG_WARN("OSSL error: %s", bptr->data);
BIO_free_all(e);
}
/*! @brief est_convert_p7b64_to_pem() converts the base64 encoded
PKCS7 response from the EST server into PEM format.
@param certs_p7 Points to a buffer containing the base64 encoded pkcs7 data.
@param certs_len Indicates the size of the *certs_p7 buffer.
@param pem Double pointer that will receive the PEM encoded data.
Several of the EST message return data that contains base64 encoded PKCS7
certificates. This function is used to convert the data to PEM format.
This function will allocate memory pointed to by the **pem argument.
The caller is responsible for releasing this memory. The return value
is the length of the PEM buffer, or -1 on error.
@return int.
*/
int est_convert_p7b64_to_pem (unsigned char *certs_p7, int certs_len, unsigned char **pem)
{
X509 *x;
STACK_OF(X509) *certs = NULL;
BIO *b64, *in, *out;
unsigned char *cacerts_decoded = NULL;
int cacerts_decoded_len = 0;
BIO *p7bio_in = NULL;
PKCS7 *p7=NULL;
int i, nid;
unsigned char *pem_data;
int pem_len;
/*
* Base64 decode the incoming ca certs buffer. Decoding will
* always take up no more than the original buffer.
*/
b64 = BIO_new(BIO_f_base64());
if (!b64) {
EST_LOG_ERR("BIO_new failed");
return (-1);
}
in = BIO_new_mem_buf(certs_p7, certs_len);
if (!in) {
EST_LOG_ERR("BIO_new failed");
return (-1);
}
in = BIO_push(b64, in);
cacerts_decoded = malloc(certs_len);
if (!cacerts_decoded) {
EST_LOG_ERR("malloc failed");
return (-1);
}
cacerts_decoded_len = BIO_read(in, cacerts_decoded, certs_len);
BIO_free_all(in);
/*
* Now get the PKCS7 formatted buffer of certificates read into a stack of
* X509 certs
*/
p7bio_in = BIO_new_mem_buf(cacerts_decoded, cacerts_decoded_len);
if (!p7bio_in) {
EST_LOG_ERR("BIO_new failed while attempting to create mem BIO");
ossl_dump_ssl_errors();
free(cacerts_decoded);
return (-1);
}
p7 = d2i_PKCS7_bio(p7bio_in, NULL);
if (!p7) {
EST_LOG_ERR("PEM_read_bio_PKCS7 failed");
ossl_dump_ssl_errors();
free(cacerts_decoded);
return (-1);
}
BIO_free_all(p7bio_in);
free(cacerts_decoded);
/*
* Now that we've decoded the certs, get a reference
* the the stack of certs
*/
nid=OBJ_obj2nid(p7->type);
switch (nid)
{
case NID_pkcs7_signed:
certs = p7->d.sign->cert;
break;
case NID_pkcs7_signedAndEnveloped:
certs = p7->d.signed_and_enveloped->cert;
break;
default:
EST_LOG_ERR("Invalid NID value on PKCS7 structure");
PKCS7_free(p7);
return (-1);
break;
}
if (!certs) {
EST_LOG_ERR("Failed to attain X509 cert stack from PKCS7 data");
PKCS7_free(p7);
return (-1);
}
/*
* Output the certs to a new BIO using the PEM format
*/
out = BIO_new(BIO_s_mem());
if (!out) {
EST_LOG_ERR("BIO_new failed");
PKCS7_free(p7);
return (-1);
}
for (i=0; i<sk_X509_num(certs); i++) {
x=sk_X509_value(certs, i);
PEM_write_bio_X509(out, x);
BIO_puts(out, "\n");
}
(void)BIO_flush(out);
/*
* Now convert the BIO to char*
*/
pem_len = (int) BIO_get_mem_data(out, (char**)&pem_data);
if (pem_len <= 0) {
EST_LOG_ERR("BIO_get_mem_data failed");
PKCS7_free(p7);
return (-1);
}
*pem = malloc(pem_len + 1);
if (!*pem) {
EST_LOG_ERR("malloc failed");
PKCS7_free(p7);
return (-1);
}
memcpy_s(*pem, pem_len, pem_data, pem_len);
(*pem)[pem_len] = 0; //Make sure it's null termianted
BIO_free_all(out);
PKCS7_free(p7);
return (pem_len);
}Observe the content of the link:
\theta \approx P(H|O) = \frac{P(O|H)\cdot P(H)}{P(O)}
Traceability as a Bayesian Inference Problem
\theta \approx P(H|O) = \frac{P(O|H)\cdot P(H)}{P(O)}
The likelihood is a fitted distribution for the IR outcomes or observations O, given the probability of H. H is the hypothesis that the link exists.
Traceability as a Bayesian Inference Problem
\theta \approx P(H|O) = \frac{P(O|H)\cdot P(H)}{P(O)}
The prior probability of H. It can be drawn from the factors that influence the traceability: transitive links, other observations of IR values, or developers' feedback.
Traceability as a Bayesian Inference Problem
\theta \approx P(H|O) = \frac{P(O|H)\cdot P(H)}{P(O)}
The marginal likelihood or "model evidence". This factor does not affect the hypothesis H.
Traceability as a Bayesian Inference Problem
\theta \approx P(H|O) = \frac{P(O|H)\cdot P(H)}{P(O)}
The posterior probability that a trace link exits; it can be interpreted as the impact of an observation O on the probability of H
Traceability as a Bayesian Inference Problem
vs.

The Probabilistic Approach
The Deterministic Approach
COMET's Empirical Evaluation
LSTM-based
IRs
COMET
COMET performance vs Information Retrieval

ICSE-2020 Seoul, Korea - COMET Paper
From previous results and after running some initial test with unsupervised neural learners, we hypothesized that the information of the artifacts bounds the link recovery
Therefore, we proposed:
Bounding the effectiveness of Unsupervised Software Traceability with Information Decomposition
Therefore, we proposed:
Bounding the effectiveness of Unsupervised Software Traceability with Information Decomposition
But,
We need more datasets to perform an empirical evaluation that supports our claims
Goals of My Internship
- To assess Neural Unsupervised Models for on a new dataset [semantic]
- To use Information Theory to Understand Traceability Models [interpretability]
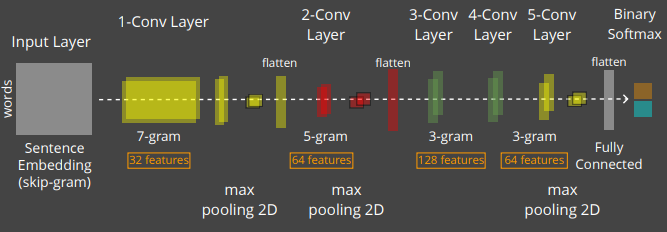
Using Neural Unsupervised Learners for Traceability
Paragragh Vector and Embeddings
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
S_n
T_n
\theta = dist(S_n,T_n)
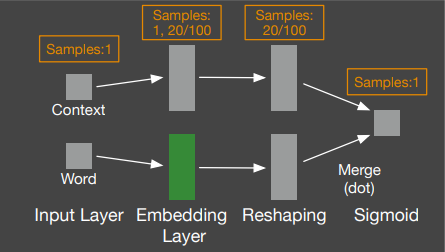
Word Neural Models (skip-gram)
Paragraph Neural Models (doc2vec)
Input Layer
word
samples:
1, 20/100
Merge (dot)
Embedding Layer
context
samples: 1
Reshaping
samples:
20/100
samples: 1
Sigmoid
Unsupervised Embedding

{'attack': ['network', 'exploit', 'unauthor'],
'code': ['execut', 'inform', 'special'],
'exploit': ['success', 'network', 'attack']}
Unsupervised Training or Skip-Gram Model
Word2Vec or wv
- Similarity Metrics:
- Word Movers Distance (WMD)
- Soft Cosine Similarity (SCM)
- Preprocessing Strategies:
- Conventional Pipeline (e.g., camel case splitting, stop words removal, stemming)
- Byte Pair Encodings or Subwordings:
- BPE-8k, 32k, and 128k
Doc2Vec or pv
- Similarity Metrics:
- Euclidean and Manhattan
- Cosine Similarity (COS)
- Preprocessing Strategies:
- Conventional Pipeline (e.g., camel case splitting, stop words removal, stemming)
- Byte Pair Encodings or Subwordings:
- BPE-8k, 32k, and 128k
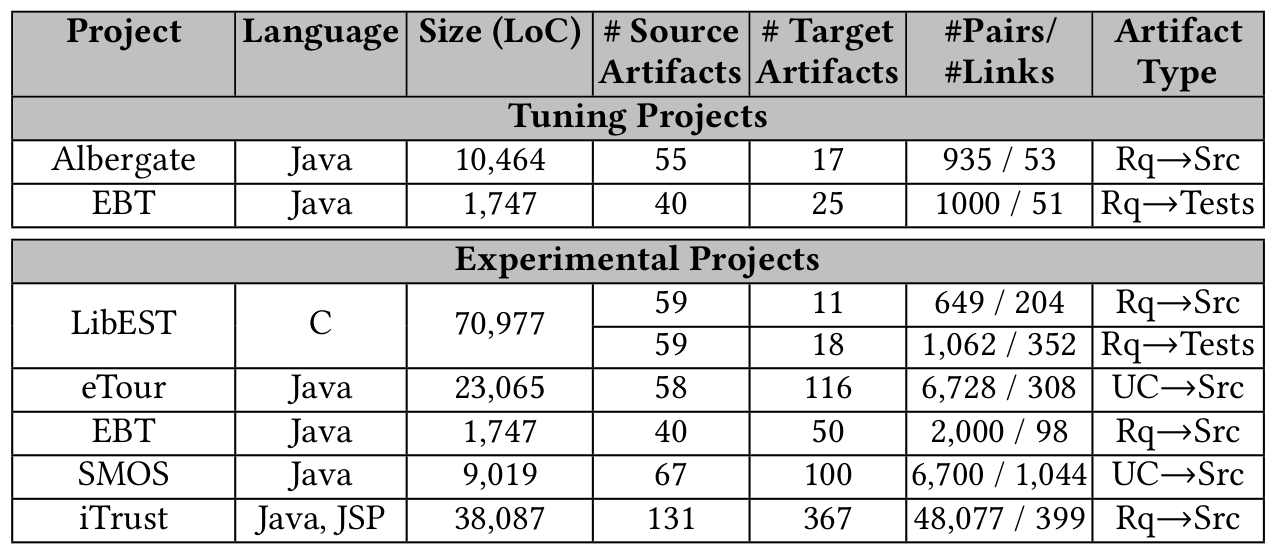
Datasets
- Traceability Benchmarks
- cisco/repo:
- cisco/LibEst
- cisco/SACP
- Semantic Vectors were trained on:
- ~1M Java Files
- ~1M Python Files
- ~6M English Files (all Wikipedia)
cisco/LibEst
- Type of links Requirements (req) to Test Cases (tc)
- Approx 200 potential links
- Natural Language/C++
cisco/SACP
- Type of links Pull Requests (pr) to Python Files (py)
- Approx 20143 potential links
- Natural Language/Python
Some Results for cisco/SACP
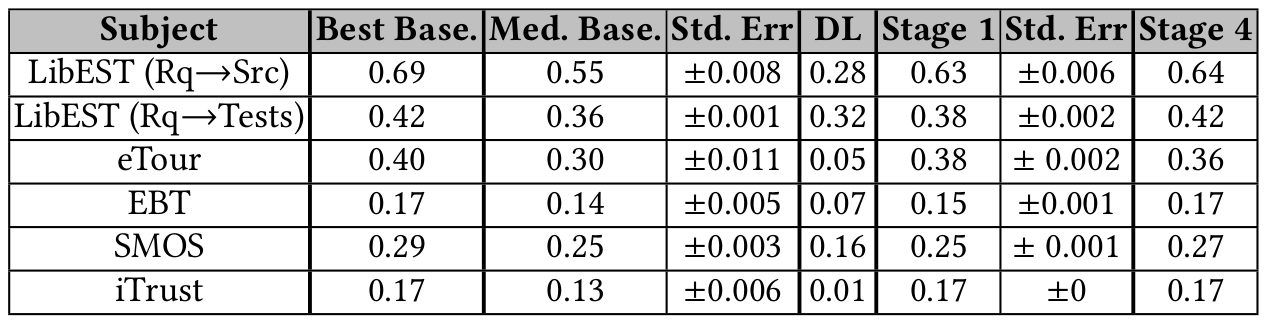
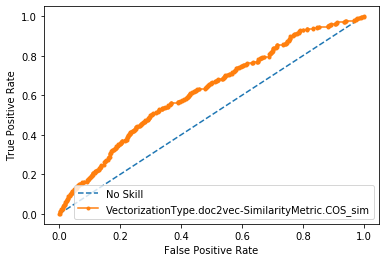
Word Vectors (or skip-gram)
AUC = 0.66
Paragraph Vectors
AUC = 0.62
ROC CURVES with conventional prep. for cisco/SACP
Word Vectors (or skip-gram)
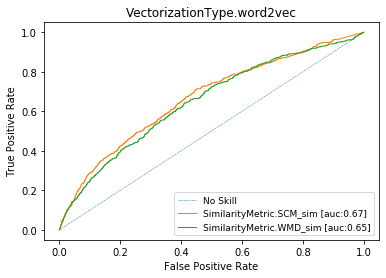
auprg= 0.38
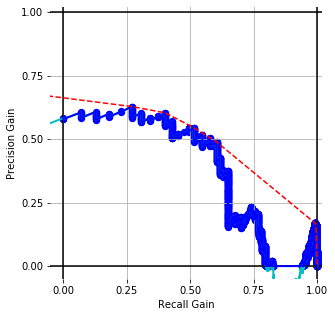
ROC CURVES with BPE-8k prep. (WMD) for cisco/SACP
A General Data Science Assessment with Ground Truth
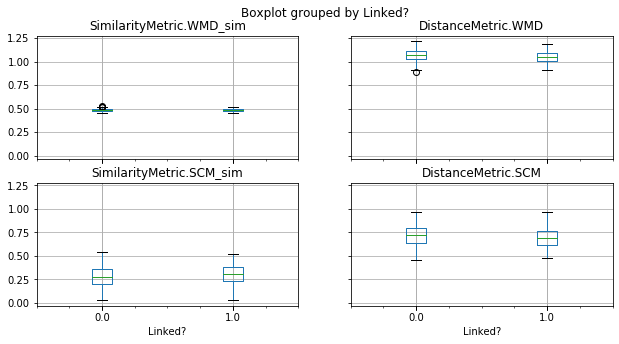
Traceability techniques are recovering links but not learning [cisco/LibEst]
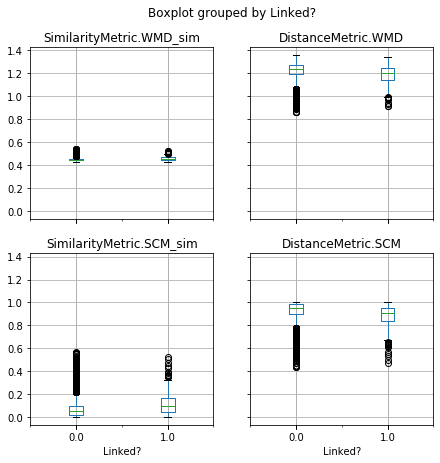
Traceability techniques are recovering links but not learning for cisco/SACP
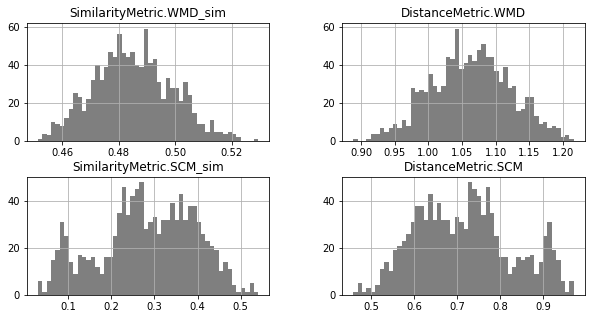
Unimodal Distributions for cisco/LibEst :(
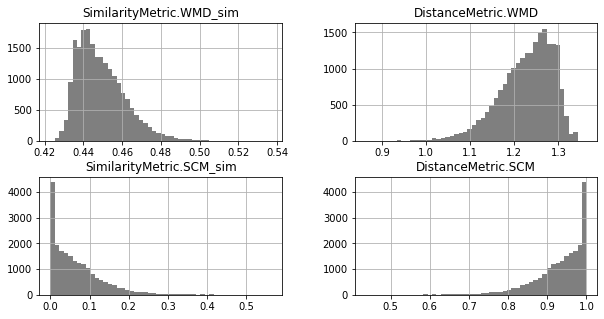
Unimodal Distributions for cisco/SACP :(
On the Use of Information Theory to Interpret Software Traceability
Information Analysis, Transmitted Information, and Clustering
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
By measuring Shannon Entropy, Extropy, and (Minimum) Shared Information, we are able to understand the limits of traceability techniques
H(req)
H(src)
H(req,src)
Shannon Entropy or Self-Information
H(A) = - \sum_{i=1}^{n}[P(a_i)\log_b P(a_i)]
J(req)
J(src)
J(req,src)
Shannon Extropy or External-Information
J(A) = - \sum_{i=1}^{n}[(1 - P(a_i))\log_b (1- P(a_i))]
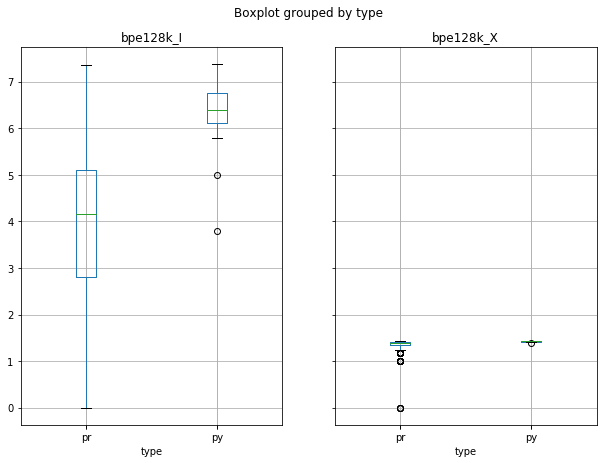
Entropy and Extropy for cisco/SACP
H(req)
H(src)
H(req,src) = H(min(req,src))
Minimum Shared Information (Entropy/Extropy)
Minimum Shared Information vs WMD for cisco/SACP
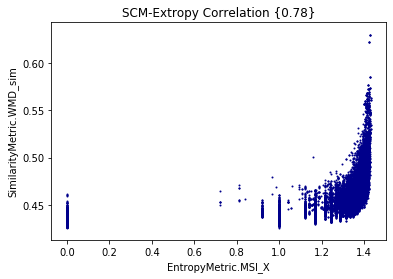
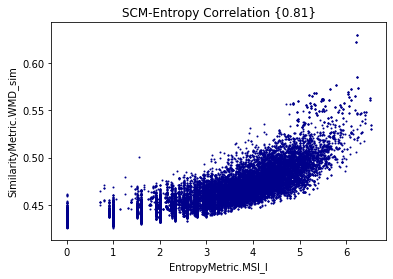
Entropy
Extropy
Semantic-Information Analysis (SCM) for cisco/SACP
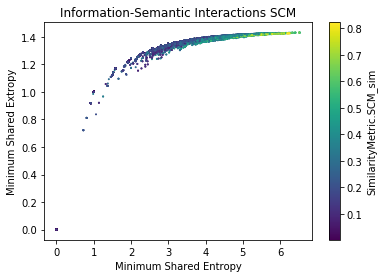
Semantic-Information Analysis by Ground Truth (SCM) for cisco/SACP
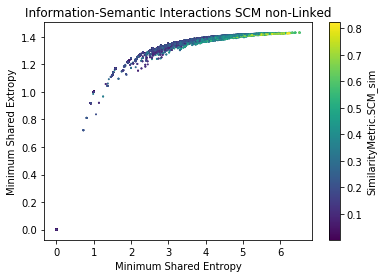
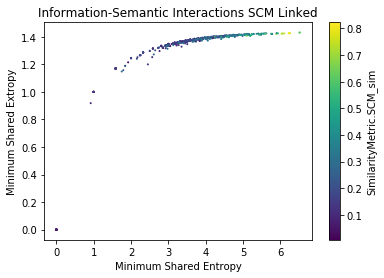
Findings
- SACP Pull Requests are more informative than SACP Python Files
- However, PR Entropy has a big variability (bigger than py)
- The larger the shared information value, the more similar the potential links are (?)
A Traceability Analysis Tool
COMET + SecureReqNet + Interpretability
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
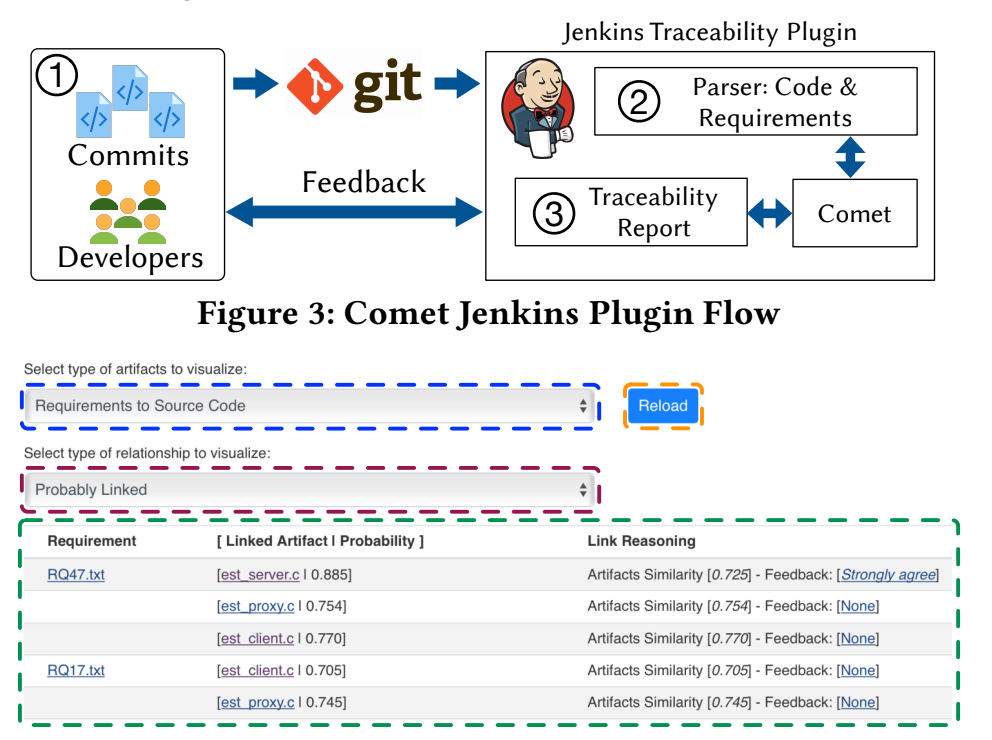
Current Deployment of [CI]T-Miner Tool
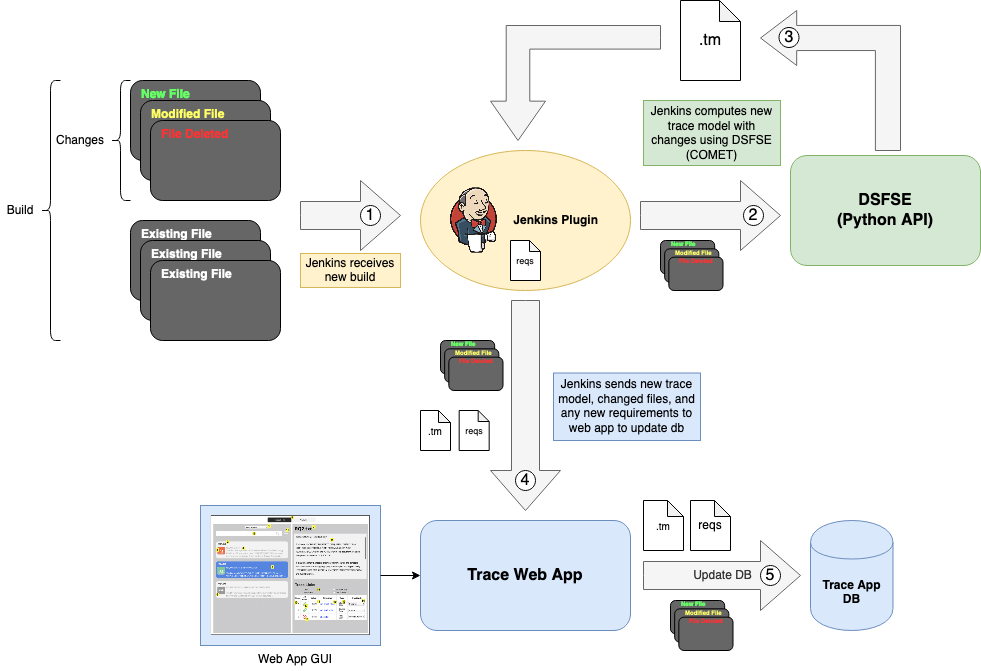
T-Miner Tool with the Information-Semantic Module included
Summary
\approx dist(S_n,T_n)

Adapting IR/ML Approaches
Introducing the Probabilistic Nature of the Traceability Problem
Using Information Science Theory to Understand Traceability Models
Mining Software Artifacts for Continious Integration
thank you!
Appendix →
Estimating the Likelihood
P(O|H)
Y
P(O|H) = Y = p(l_i|\theta_i)= Bern(l_i|\theta_i)
P(O|H) = Y = p(l_i|\theta_i)= Bern(l_i|\theta_i)
l(``RQ_1" \rightarrow ``us895")
| Model | Observation | Linked? |
|---|---|---|
| VSM | 0.085 | 0 |
| JS | 0.446 | 1 |
| LDA | 0.01 | 0 |
k_i > 0.4
P(O|H) = Y = p(l_i|\theta_i)= Bern(l_i|\theta_i)
l(``RQ_1" \rightarrow ``est\_ossl\_util.c")
| Model | Observation | Linked? |
|---|---|---|
| VSM | 0.119 | 0 |
| JS | 0.457 | 1 |
| LDA | 0.014 | 0 |
k_i > 0.4
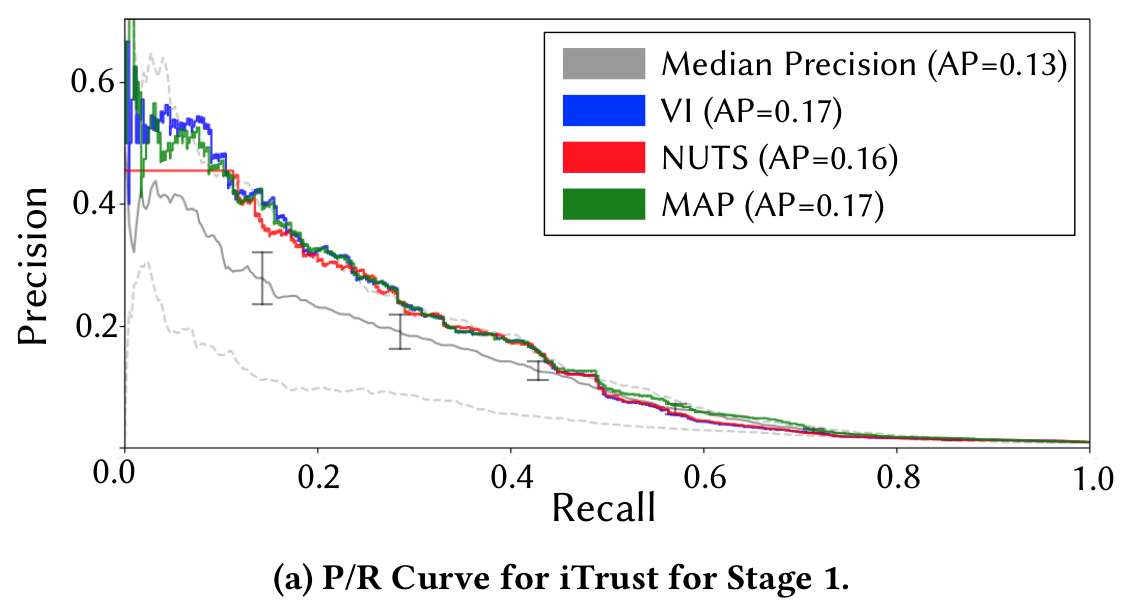
Precision-Recall Semantic Analysis
Shannon Entropy or Self-Information for cisco/SACP
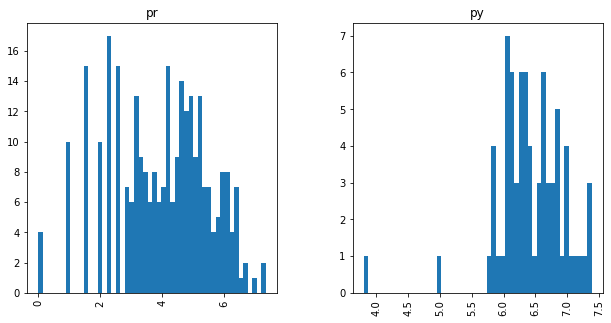
Relative Frequencies
Shannon Extropy for cisco/SACP
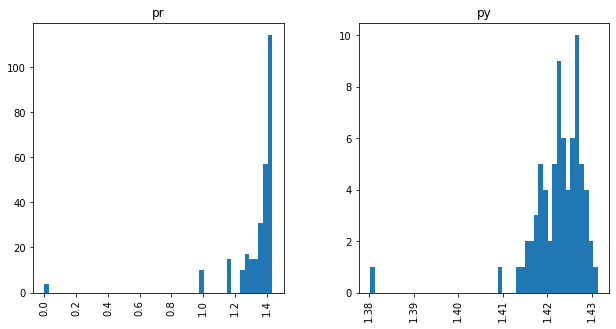
Relative Frequencies
How do we enhance link recovery with recent IR/ML approaches?


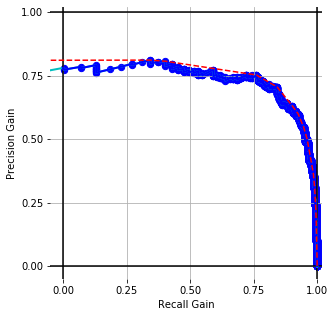
Word Vectors (or skip-gram) [WMD]
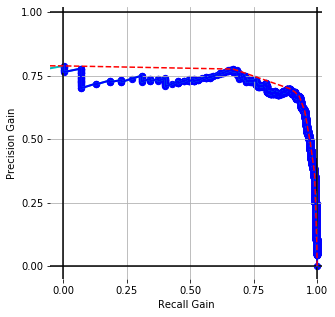
Paragraph Vectors [COS]
Embedding Performance [precision-recall gain] with conventional prep. for cisco/SACP
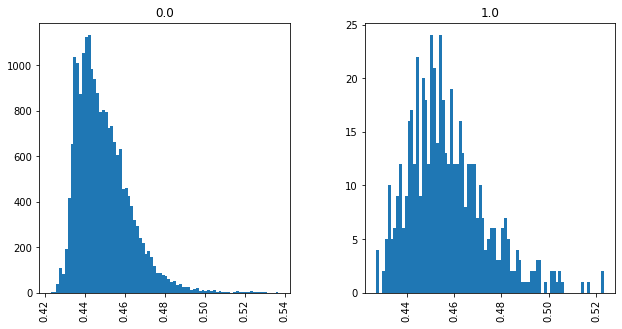
Unimodal Distributions by Ground-Truth (WMD) for cisco/SACP
S = \{S_{1},S_{2},\ldots S_{n}\}
S_{libest} = \{RQ_{1},RQ_{2},\ldots RQ_{58}\}
REQUIREMENT 4: OBTAINING CA CERTIFICATES:
| The EST client can request a copy of the current EST CA certificate(s) from the EST server. The EST client is assumed to perform this operation before performing other operations. |
Source Artifacts S are based on RFC 7030 “Enrollment over secure transport”
T = \{T_{1},T_{2},\ldots T_{n}\}
T_{libest} = \{``est.c",``est.h",\ldots ``est\_server.c"\}
TC_{libest} = \{``us1005.c,``us1060.c",\ldots ``us903.c"\}
Source Target Artifacts are both source code <T> and test cases <TC> of LibEST
L = \{(s,t) | s\in S, t\in T, s\leftrightarrow t\}
L_{libest} = \{(``RQ_4", ``est\_ossl\_util.c"), (``RQ_4", ``us1864.c")\ldots \}
Trace Links that exits between all possible pairs of artifacts from S → T
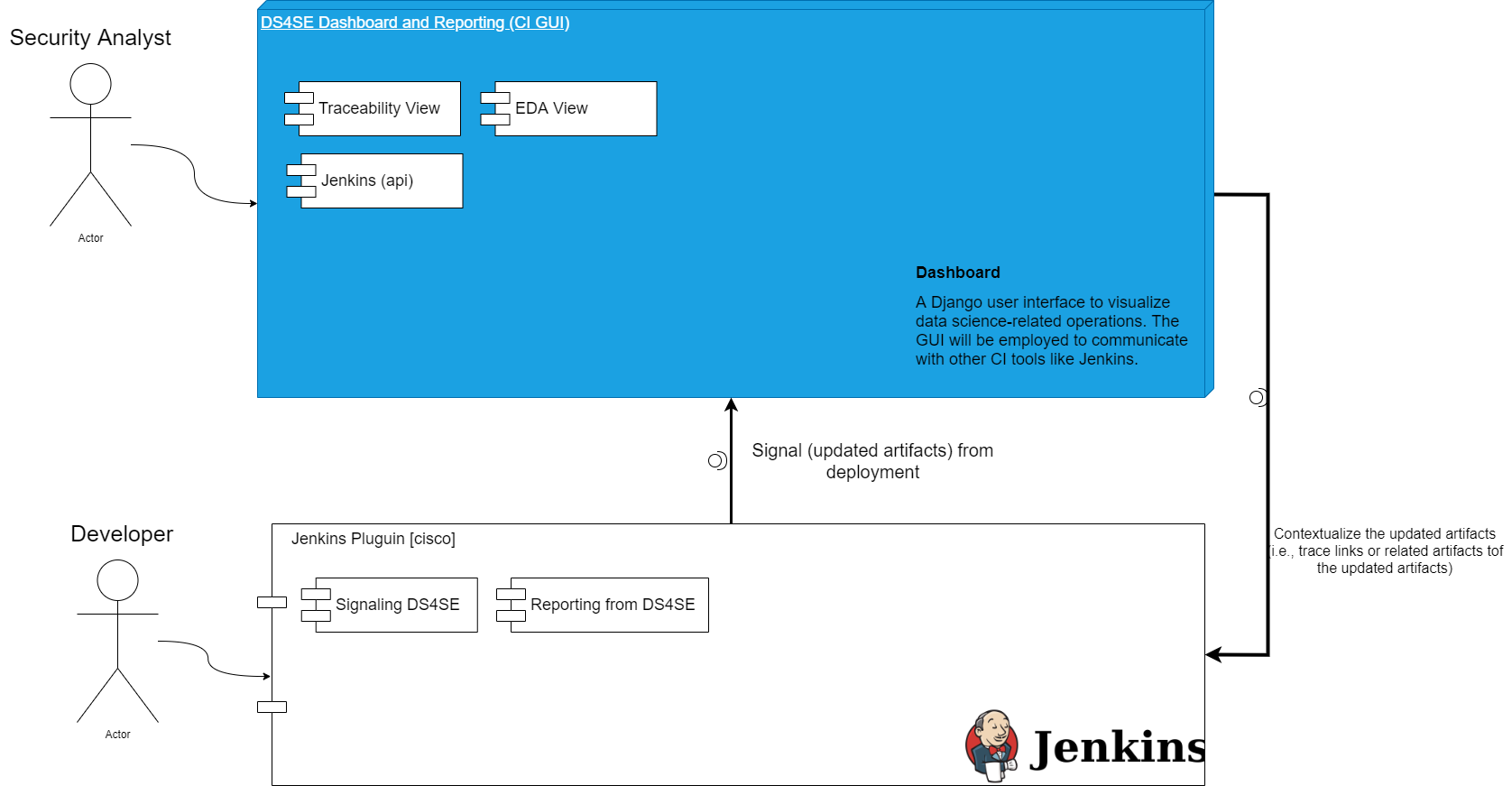
Solution Architecture
David A. Nader
I am 3th year PhD Student at William and Mary in Computer Science.
I was born in Bogota, Colombia. I did my undergrad in Computer Engineer at The National University of Colombia (UNAL). My master was in CS between The Technical University of Munich (TUM) and UNAL.
Research interest: Deep Learning for SE, Natural Computation, Causal Inference for SE, Code Generation and Representation
Hobbies: Kayaking, Hiking, Movies,
Mentor: Chris Shenefiel
Manager: Jim Warren


UNAL'17
W&M'17
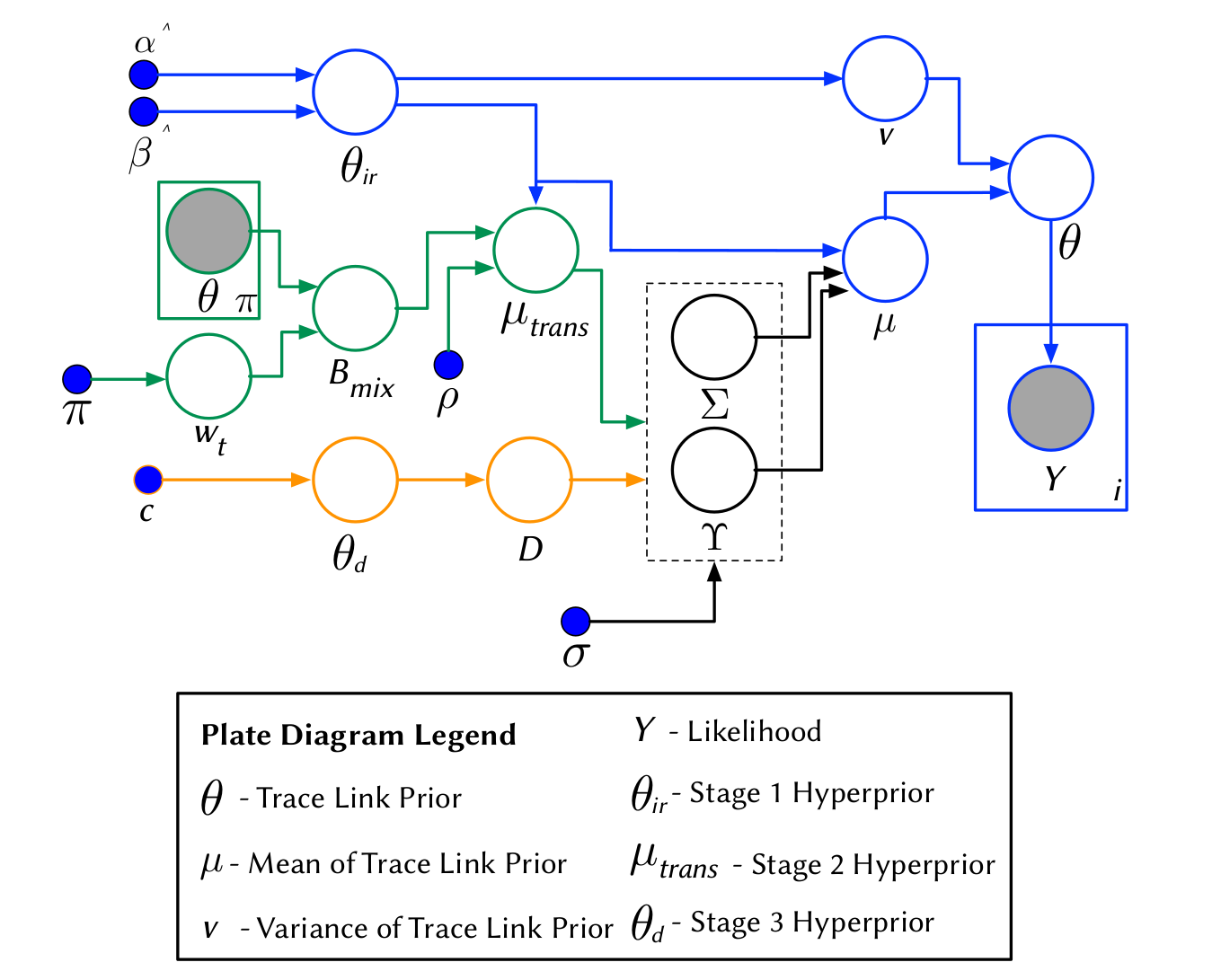
A Hierarchical Bayesian Network to model priors
P(H)
Y
P(H)
Random factors that influence the probability that a trace link exists in LibEST
- Textual Similarities among artifacts
- CISCO Developers feedback
- Transitive Relationships
P(H)
Textual Similarities
Developers' Feedback
Transtive Links
Textual Similarities
Stage 1
P(H) = \theta
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
The BETA distribution is fitted from distinct observations of IR techniques
Developers' Feedback
Stage 2
\theta_{d} \sim B(\mu_{d}=c,sd=0.01)
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
A different BETA distribution is fitted from distinct observations of Developers' feedback from the link under study
Transitive Links
Stage 3
Source File
Test File
Test File
\theta
Exec_2
Exec_1
\theta_1
\theta_2
B_{mix} \sim Mix(w_t,\theta_\pi)
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
A BETA mixture model is employed to model all transitive (probabilistic) links
The Holistic Model
Stage 4
B_{mix} \sim Mix(w_t,\theta_\pi)
\theta_{d} \sim B(\mu_{d}=c,sd=0.01)
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
Inferring the Traceability Posterior
P(H|O)
P(H|O) = \frac{P(O|H)\cdot P(H)}{P(O)} = p(\Theta|L)
B_{mix} \sim Mix(w_t,\theta_\pi)
\theta_{d} \sim B(\mu_{d}=c,sd=0.01)
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
p(\Theta|L)
p(\Theta|L) = \dfrac{p(\Theta)p(L|\Theta)}{\int p(\Theta)p(L|\Theta)d\Theta} \propto p(\Theta) \prod\limits_{i=1}^n p(L_i|\Theta_i)
How do we compute a posterior probability given the traceability hyperpriors?
Good luck!
well actually, we performed...
- Maximum a Posteriori estimation (MAP)
- Markov Chain Monte Carlo (MCMC) via the No-U-Turn Sampling (NUTs)
- Variational Inference (VI)
Estimating the Likelihood
P(O|H)
Y
P(O|H) = Y = p(l_i|\theta_i)= Bern(l_i|\theta_i)
P(O|H) = Y = p(l_i|\theta_i)= Bern(l_i|\theta_i)
l(``RQ_1" \rightarrow ``us895")
| Model | Observation | Linked? |
|---|---|---|
| VSM | 0.085 | 0 |
| JS | 0.446 | 1 |
| LDA | 0.01 | 0 |
k_i > 0.4
P(O|H) = Y = p(l_i|\theta_i)= Bern(l_i|\theta_i)
l(``RQ_1" \rightarrow ``est\_ossl\_util.c")
| Model | Observation | Linked? |
|---|---|---|
| VSM | 0.119 | 0 |
| JS | 0.457 | 1 |
| LDA | 0.014 | 0 |
k_i > 0.4
A Hierarchical Bayesian Network to model priors
P(H)
Y
P(H)
Random factors that influence the probability that a trace link exists in LibEST
- Textual Similarities among artifacts
- CISCO Developers feedback
- Transitive Relationships
P(H)
Textual Similarities
Developers' Feedback
Transtive Links
Textual Similarities
Stage 1
P(H) = \theta
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
The BETA distribution is fitted from distinct observations of IR techniques
Developers' Feedback
Stage 2
\theta_{d} \sim B(\mu_{d}=c,sd=0.01)
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
A different BETA distribution is fitted from distinct observations of Developers' feedback from the link under study
Transitive Links
Stage 3
Source File
Test File
Test File
\theta
Exec_2
Exec_1
\theta_1
\theta_2
B_{mix} \sim Mix(w_t,\theta_\pi)
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
A BETA mixture model is employed to model all transitive (probabilistic) links
The Holistic Model
Stage 4
B_{mix} \sim Mix(w_t,\theta_\pi)
\theta_{d} \sim B(\mu_{d}=c,sd=0.01)
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
Inferring the Traceability Posterior
P(H|O)
P(H|O) = \frac{P(O|H)\cdot P(H)}{P(O)} = p(\Theta|L)
B_{mix} \sim Mix(w_t,\theta_\pi)
\theta_{d} \sim B(\mu_{d}=c,sd=0.01)
\theta \sim B(\mu, \nu)
Y \sim Bern(l_i|\theta_i)
p(\Theta|L)
p(\Theta|L) = \dfrac{p(\Theta)p(L|\Theta)}{\int p(\Theta)p(L|\Theta)d\Theta} \propto p(\Theta) \prod\limits_{i=1}^n p(L_i|\Theta_i)
How do we compute a posterior probability given the traceability hyperpriors?
Good luck!
well actually, we performed...
- Maximum a Posteriori estimation (MAP)
- Markov Chain Monte Carlo (MCMC) via the No-U-Turn Sampling (NUTs)
- Variational Inference (VI)
The Probabilistic Nature of The Link Recovery Problem
The link recovery problem is the fundamental problem in Software Traceability; it consists in automatically establishing the relationships of artifacts allowing for the evolution of the system and the nature of the data
The link recovery problem: How would you compute theta?
Source File
Requirement File
\theta
How do we enhance link recovery with recent IR/ML approaches?
\theta
Trace Link (Similarity) Value [0,1]
\theta_n
Trace Link from Requirement to Test Case
Exec_n
Execution Trace from Source Code to Test Case
S_n
Source Artifacts (i.e., requirement files)
T_n
Target Artifacts (i.e., source code files)
How do we enhance link recovery with recent IR/ML approaches?
Source File
Requirement File
Test File
\theta = ?
Exec_1
What if we compute a second theta for Req to Tc? Is the initial theta affected?
Source File
Requirement File
Test File
\theta = ?
Exec_1
\theta_1
And what if we add more information?
Source File
Requirement File
Test File
Test File
\theta = ?
Exec_2
Exec_1
\theta_1
\theta_2
CISCO Traceability Research
By David Nader Palacio



