AWS Glue
Hands-On
Demo

In this demo, we will:
- Set up Amazon S3 buckets and upload sample data
- Create an AWS Glue Data Catalog
- Create an AWS Glue Crawler
- Create an AWS Glue ETL job
- Run and monitor the ETL job
- Set up and use Amazon Athena to query the data
- Test the setup
- Clean up resources
Agenda
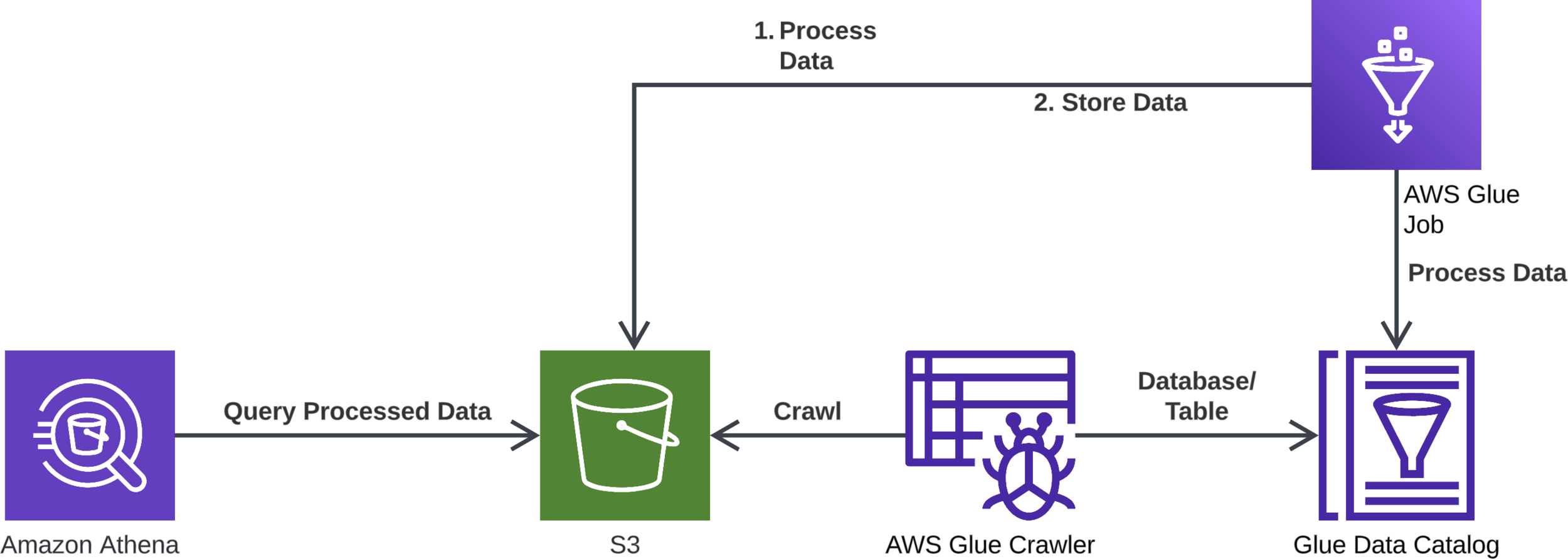
Demo Overview
Create 2
S3 Buckets
my-glue-source-bucket-619811Create 1st S3 bucket




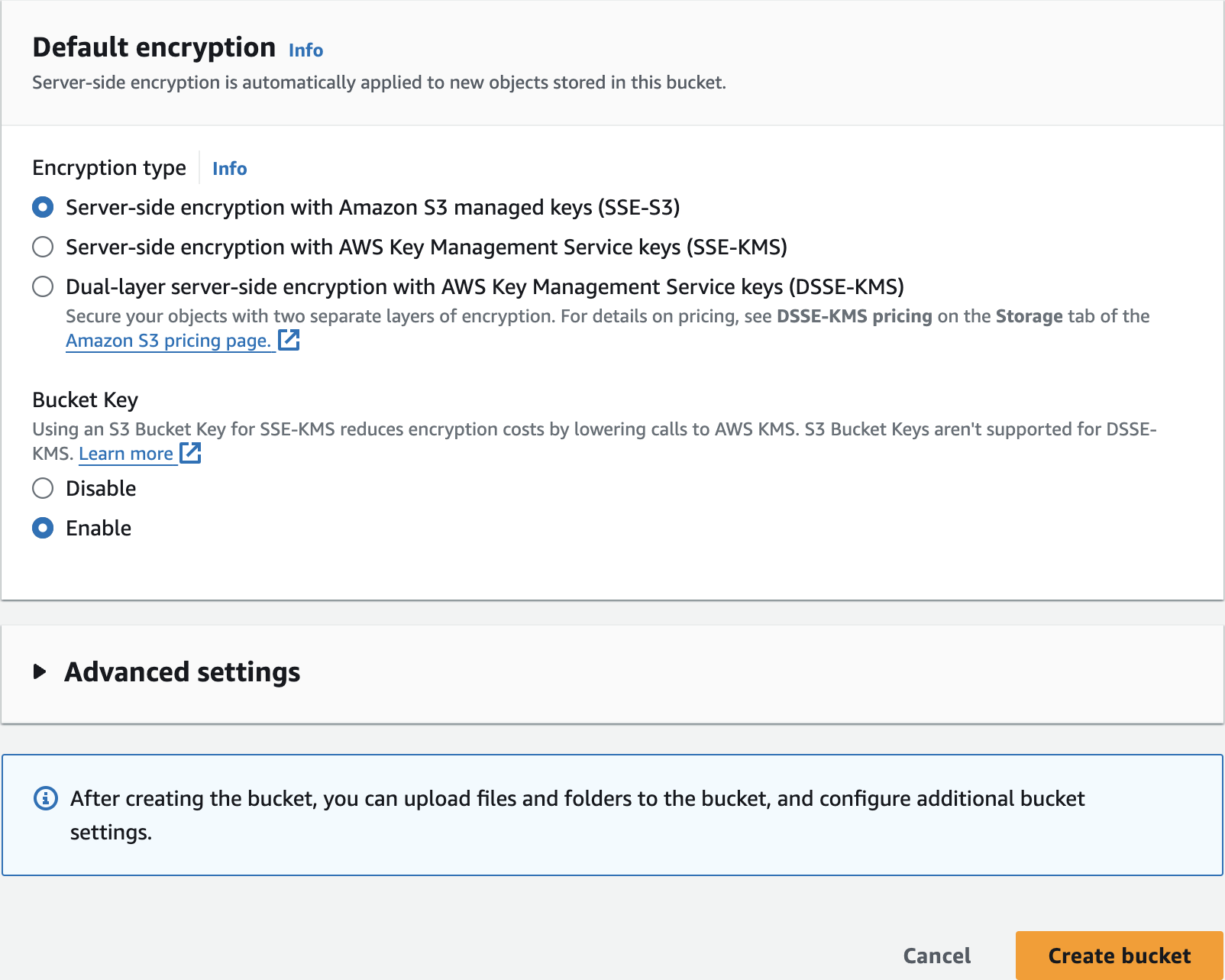

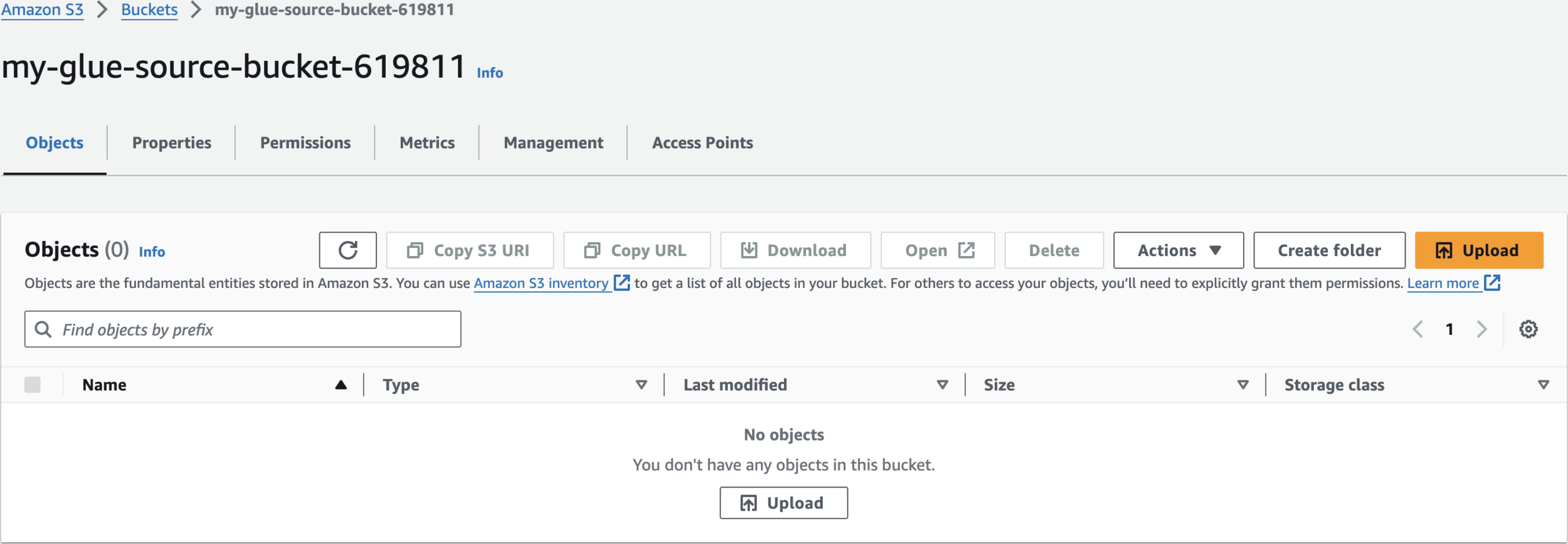
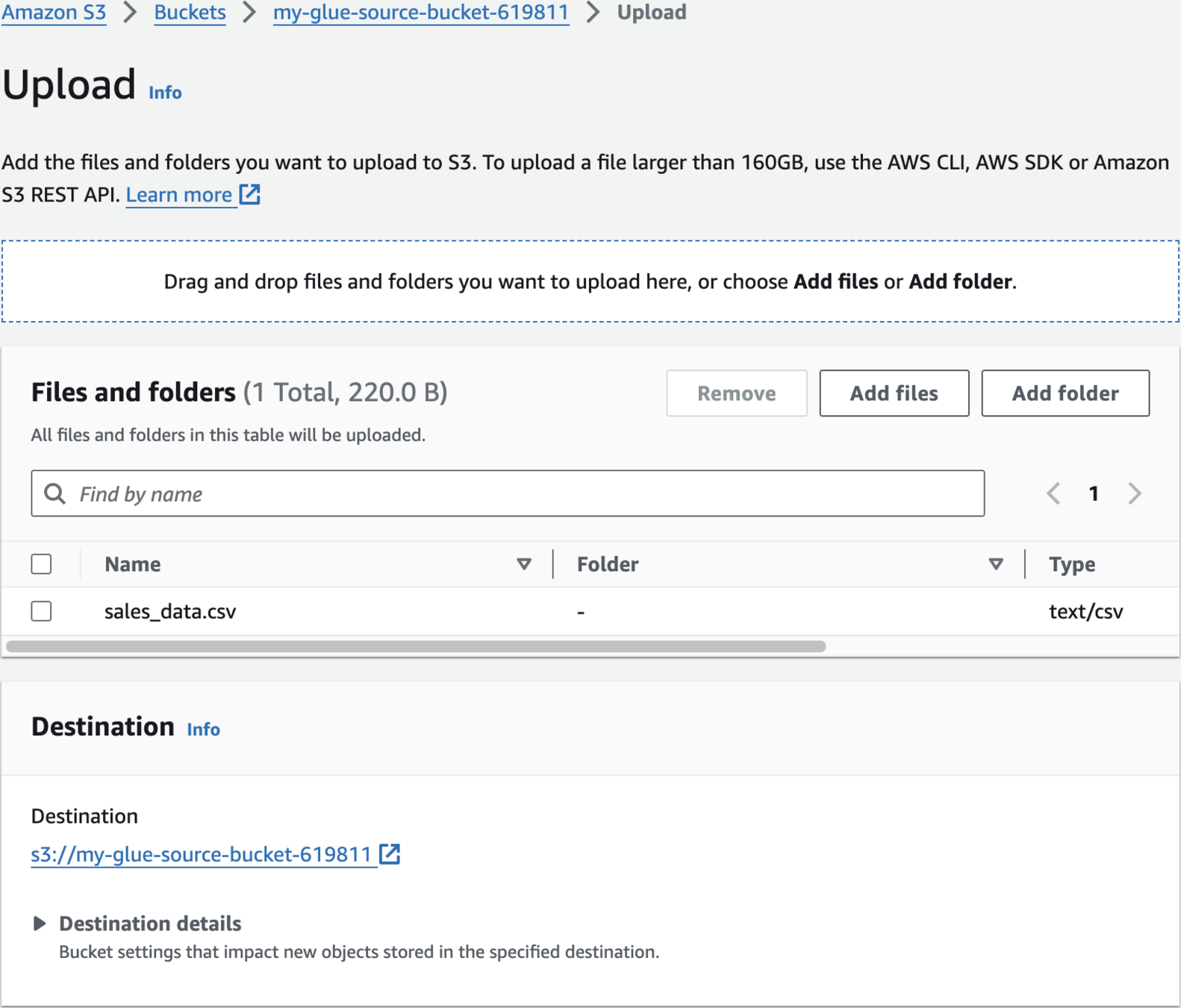
Upload Sample Data
order_id,date,customer_id,product_id,quantity,price,category
1001,2023-01-01,C001,P101,2,19.99,Electronics
1002,2023-01-02,C002,P102,1,29.99,Books
1003,2023-01-03,C001,P103,3,9.99,Clothing
1004,2023-01-04,C003,P101,1,19.99,Electronics
1005,2023-01-05,C002,P102,2,29.99,Books
1006,2023-01-06,C004,P104,1,49.99,Electronics
1007,2023-01-07,C003,P105,2,15.99,Clothing
1008,2023-01-08,C005,P106,1,39.99,Books
1009,2023-01-09,C001,P107,3,12.99,Clothing
1010,2023-01-10,C002,P101,1,19.99,Electronicssales_data.csv
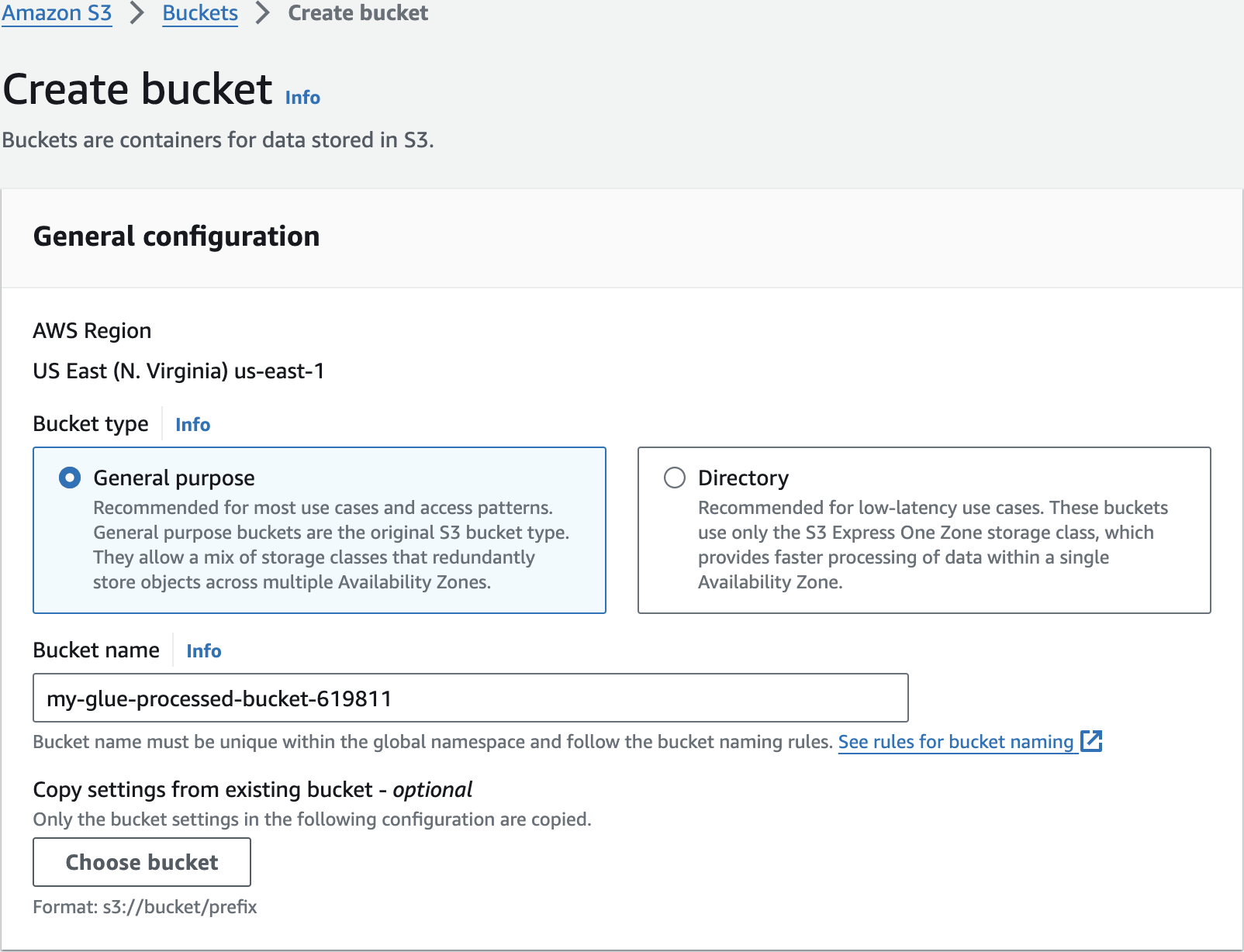
my-glue-processed-bucket-619811Create 2nd S3 Bucket
AWS Glue
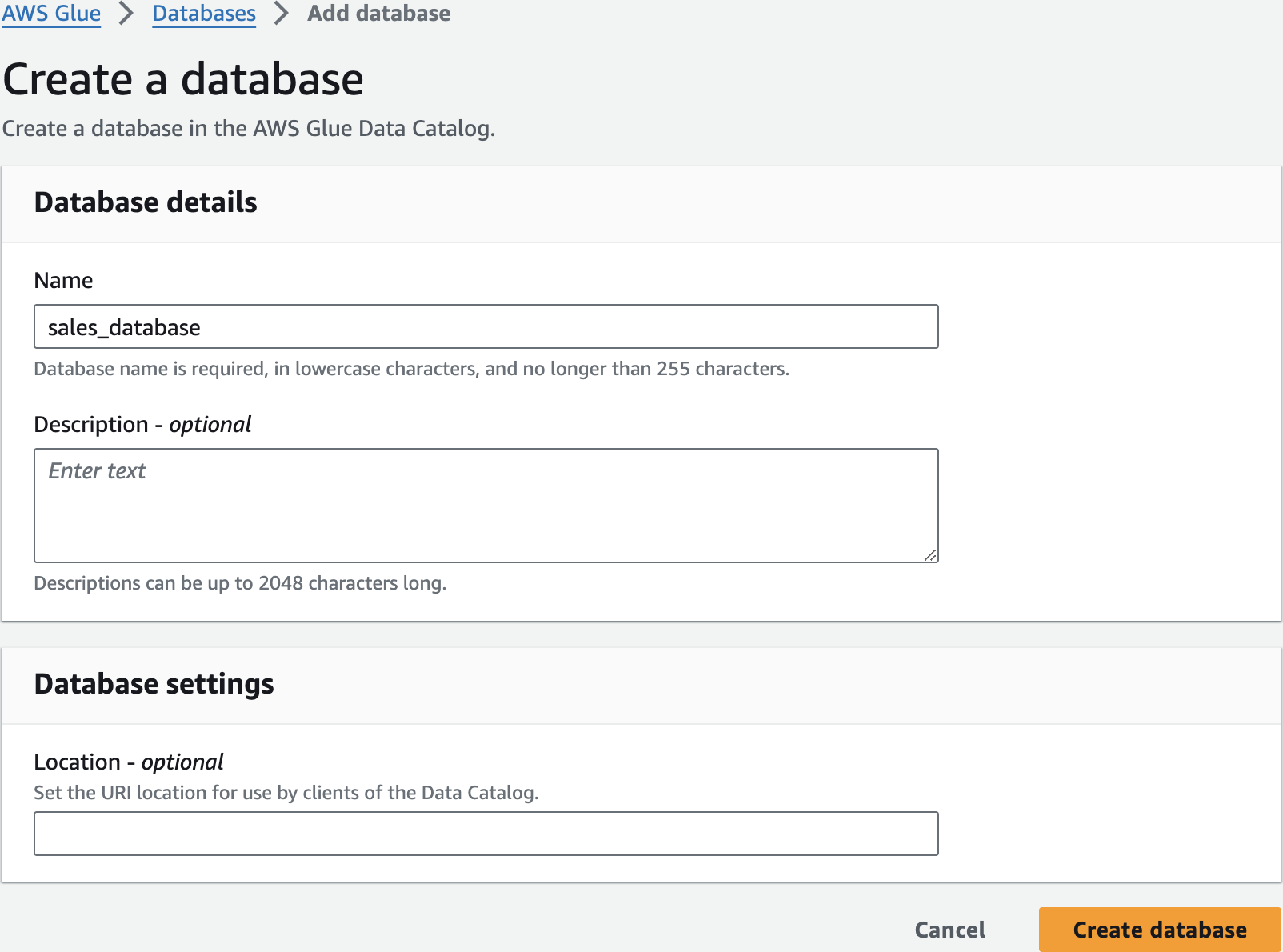
sales_databaseCreate a database
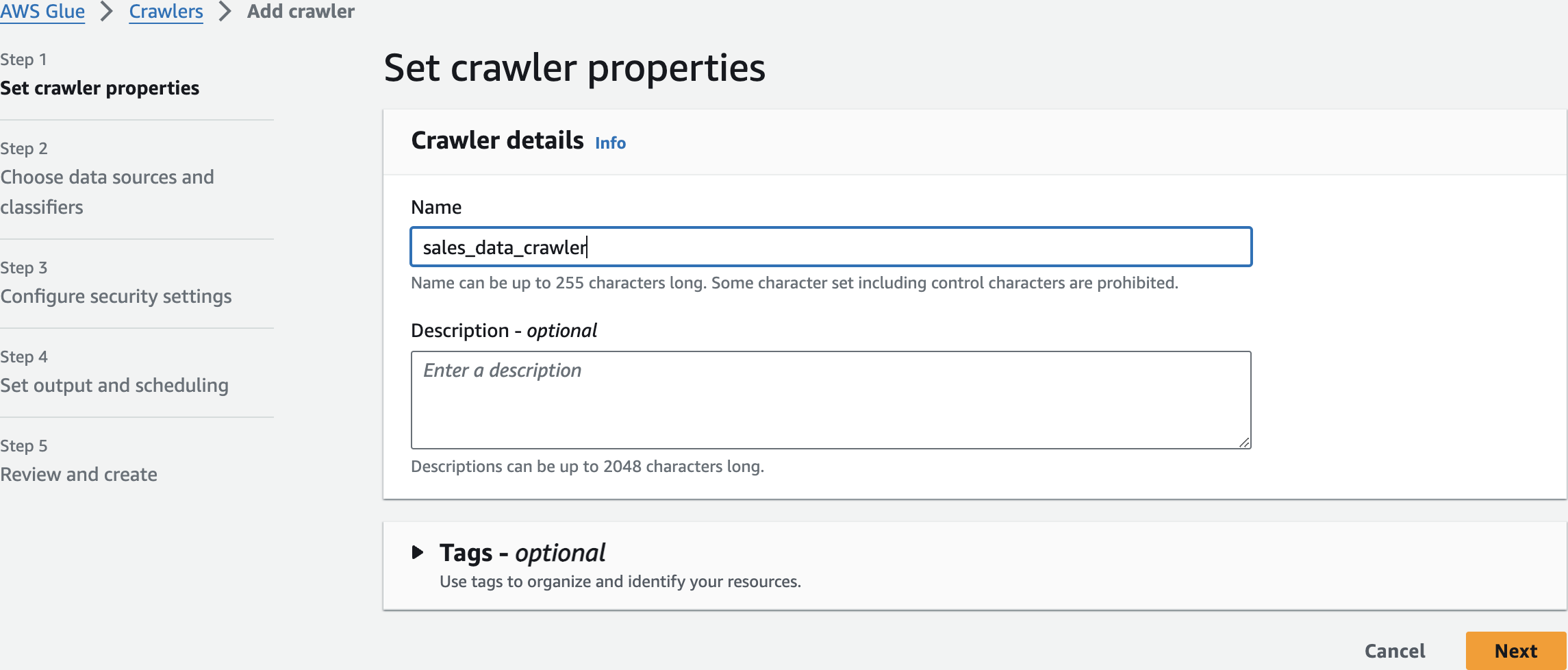
sales_data_crawlerAdd crawler
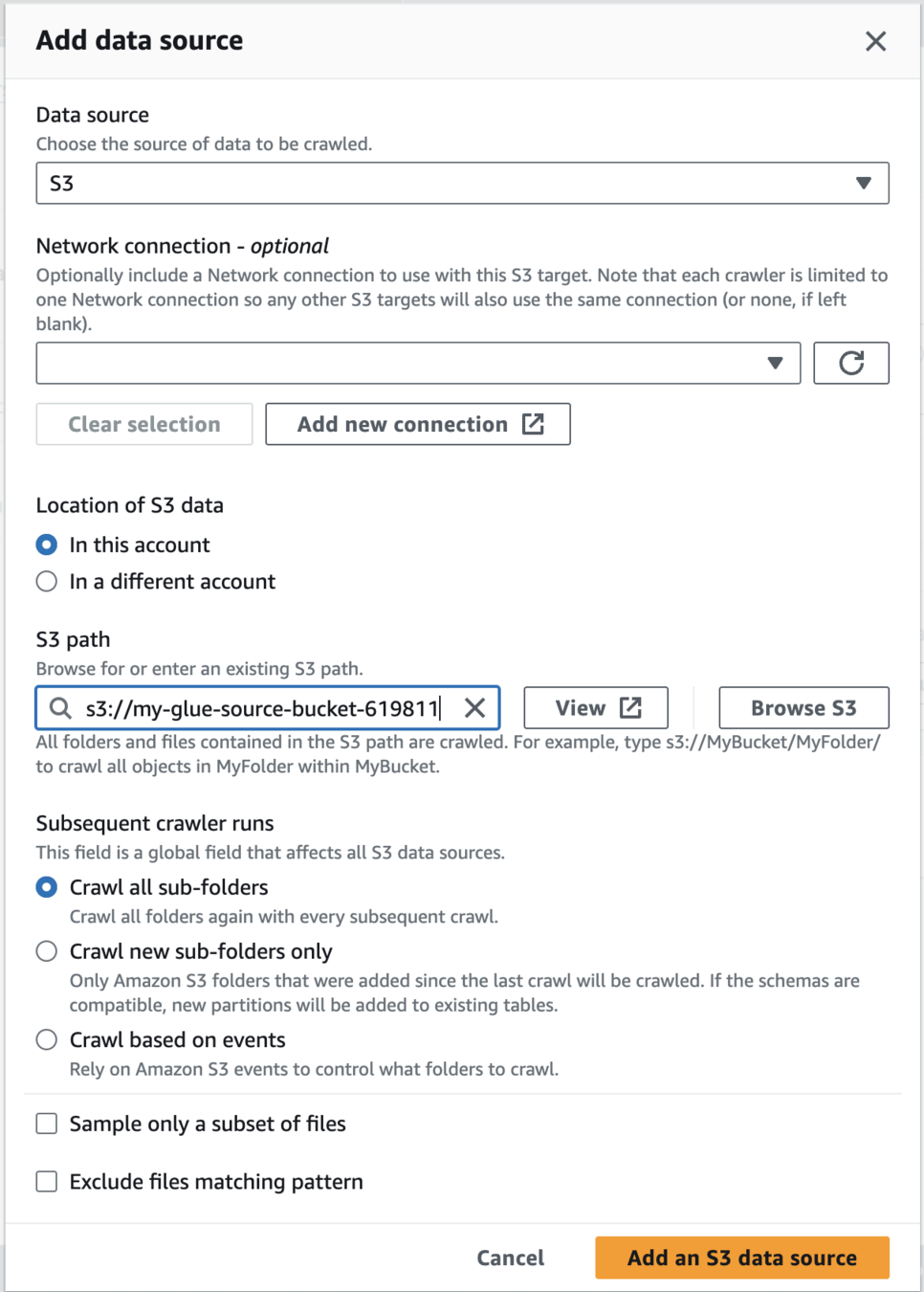
Add data source



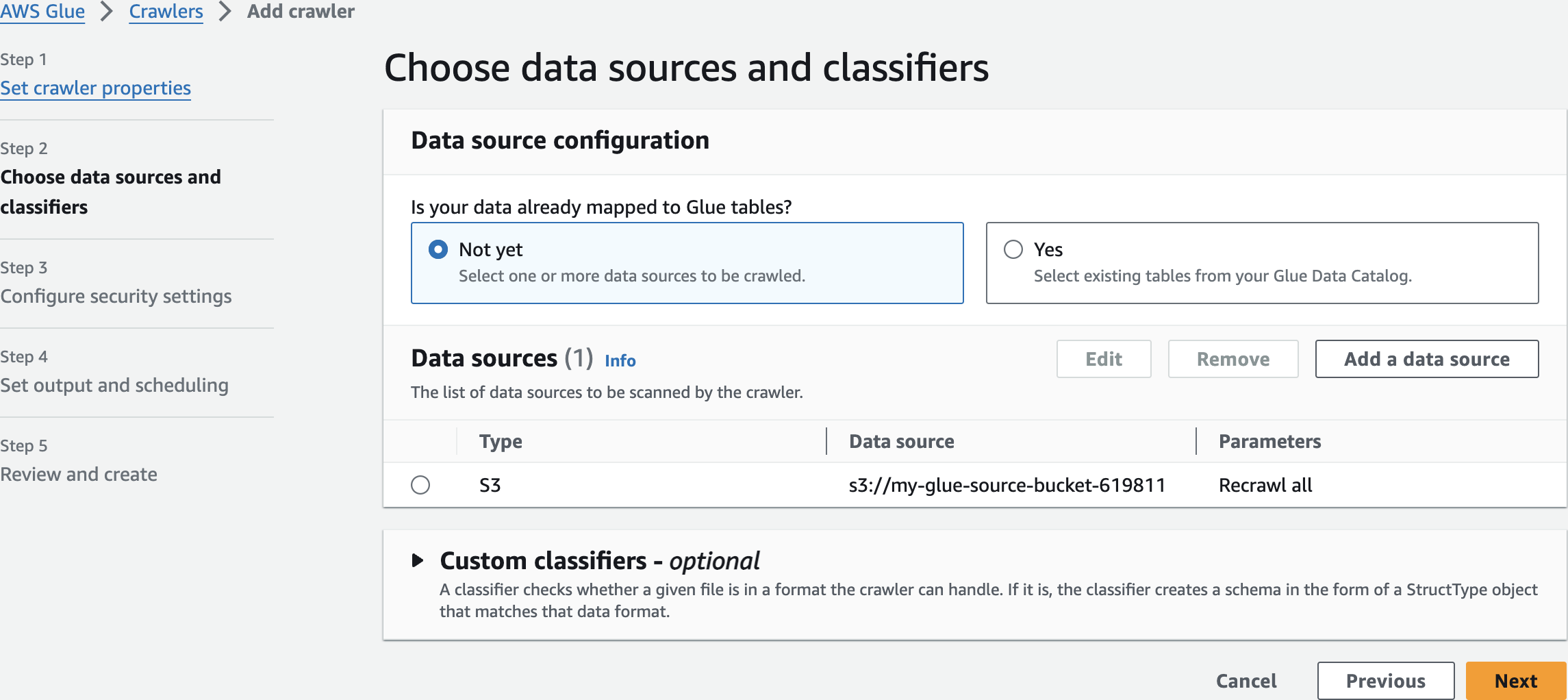
Choose data sources and classifiers
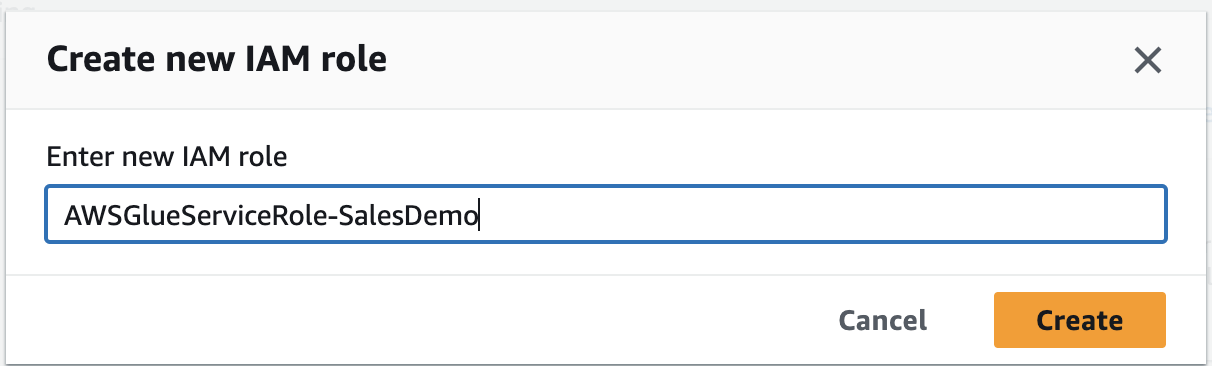
Create new IAM role
AWSGlueServiceRole-SalesDemo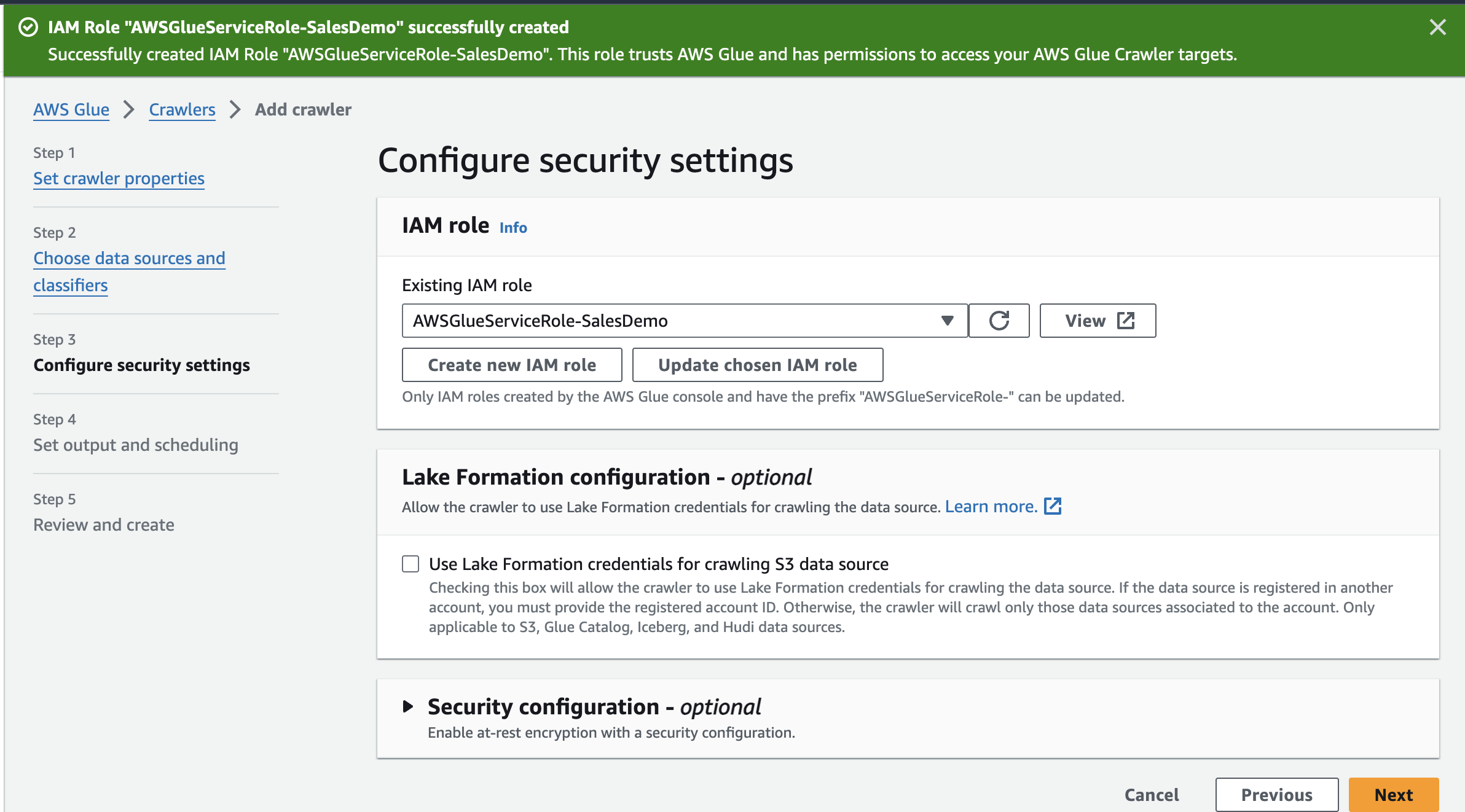
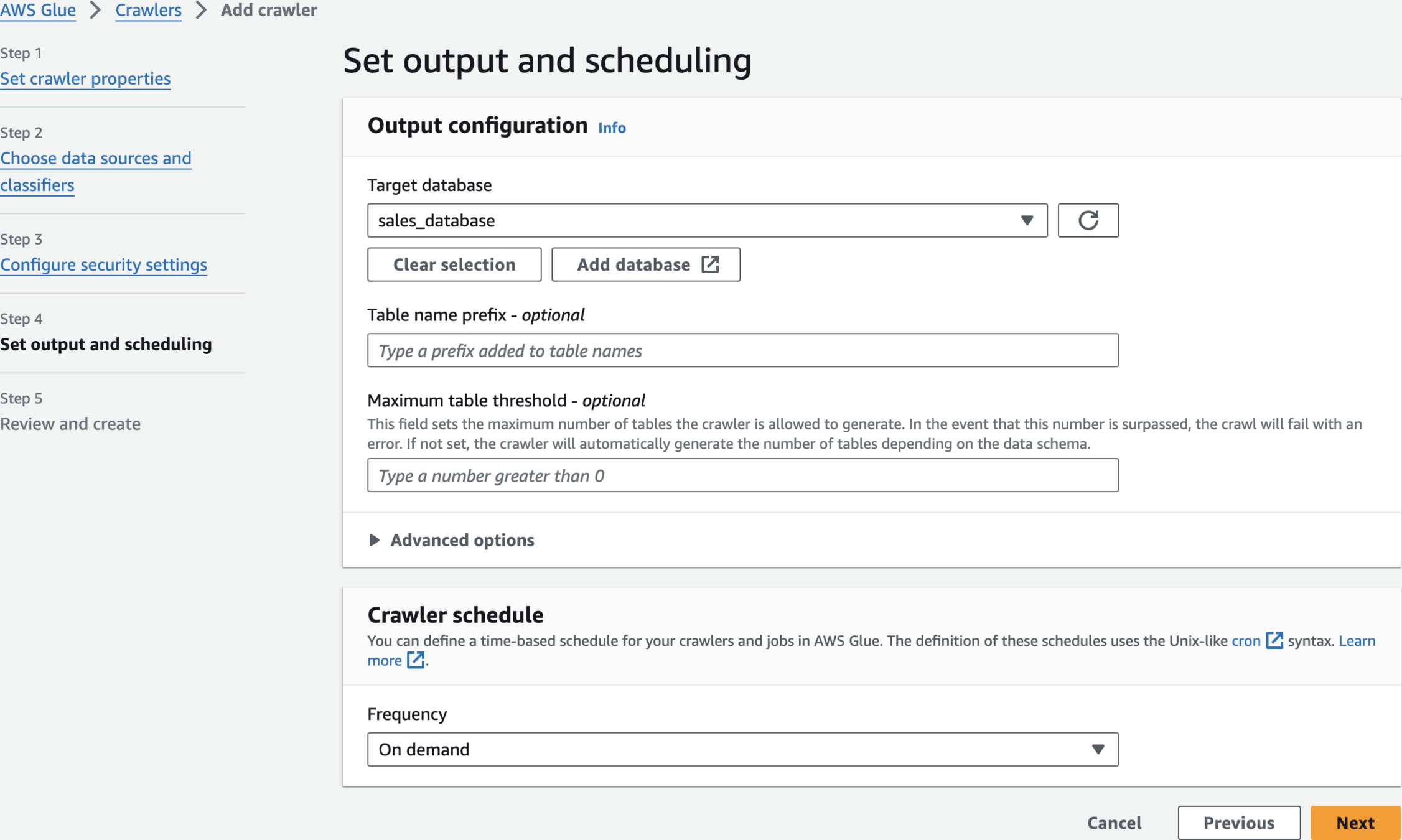
Set output and scheduling
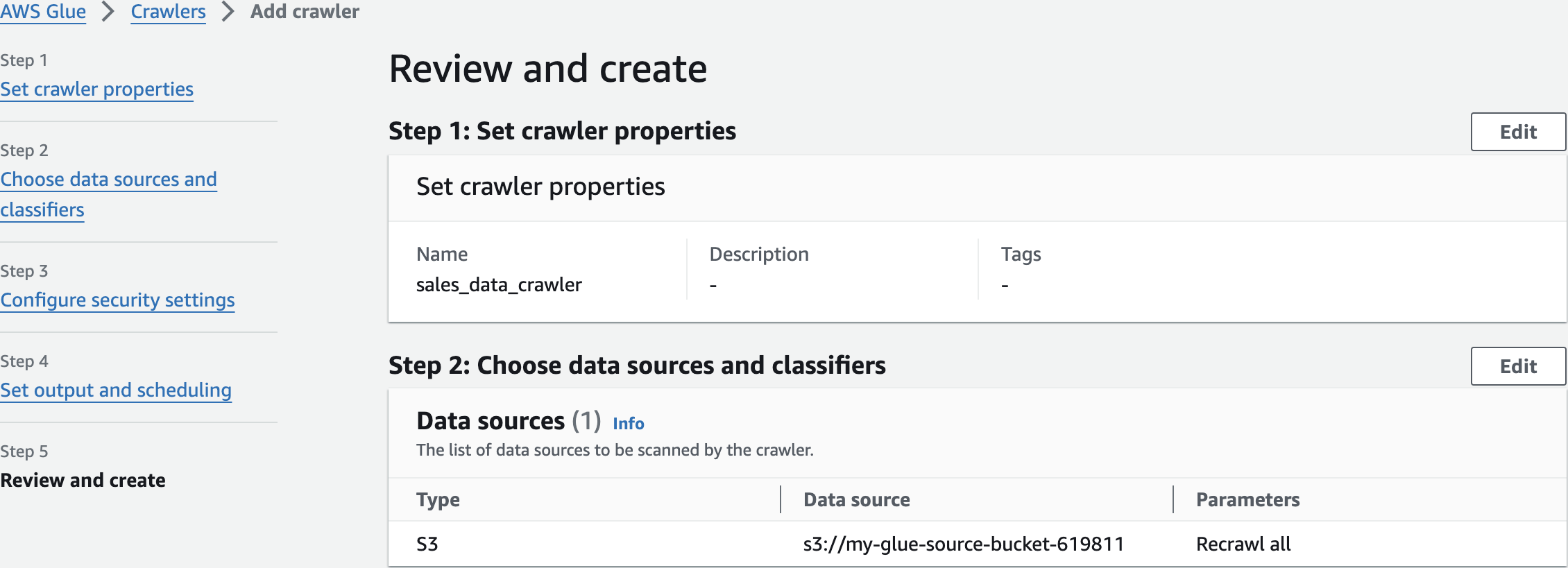
Review and create
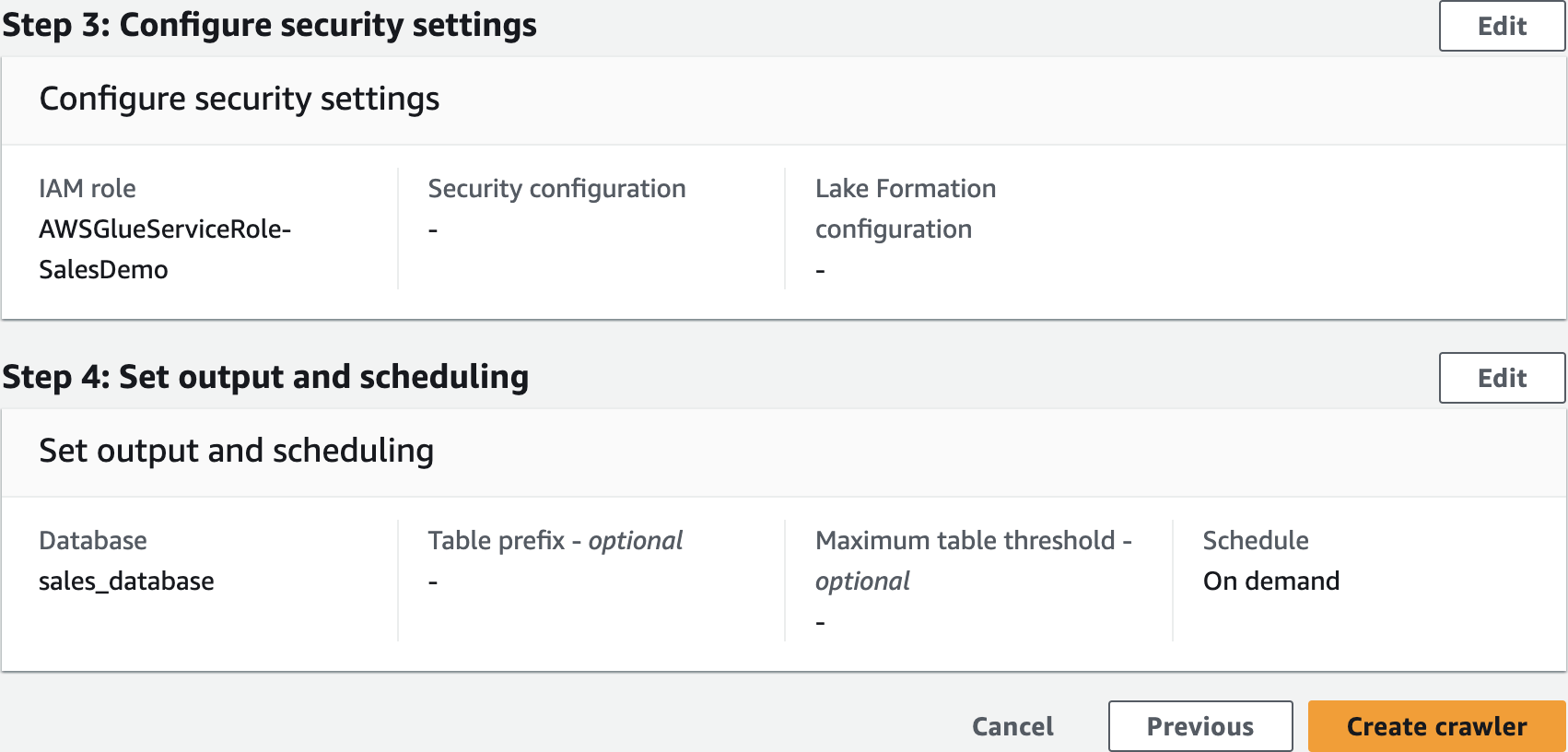
Create crawler
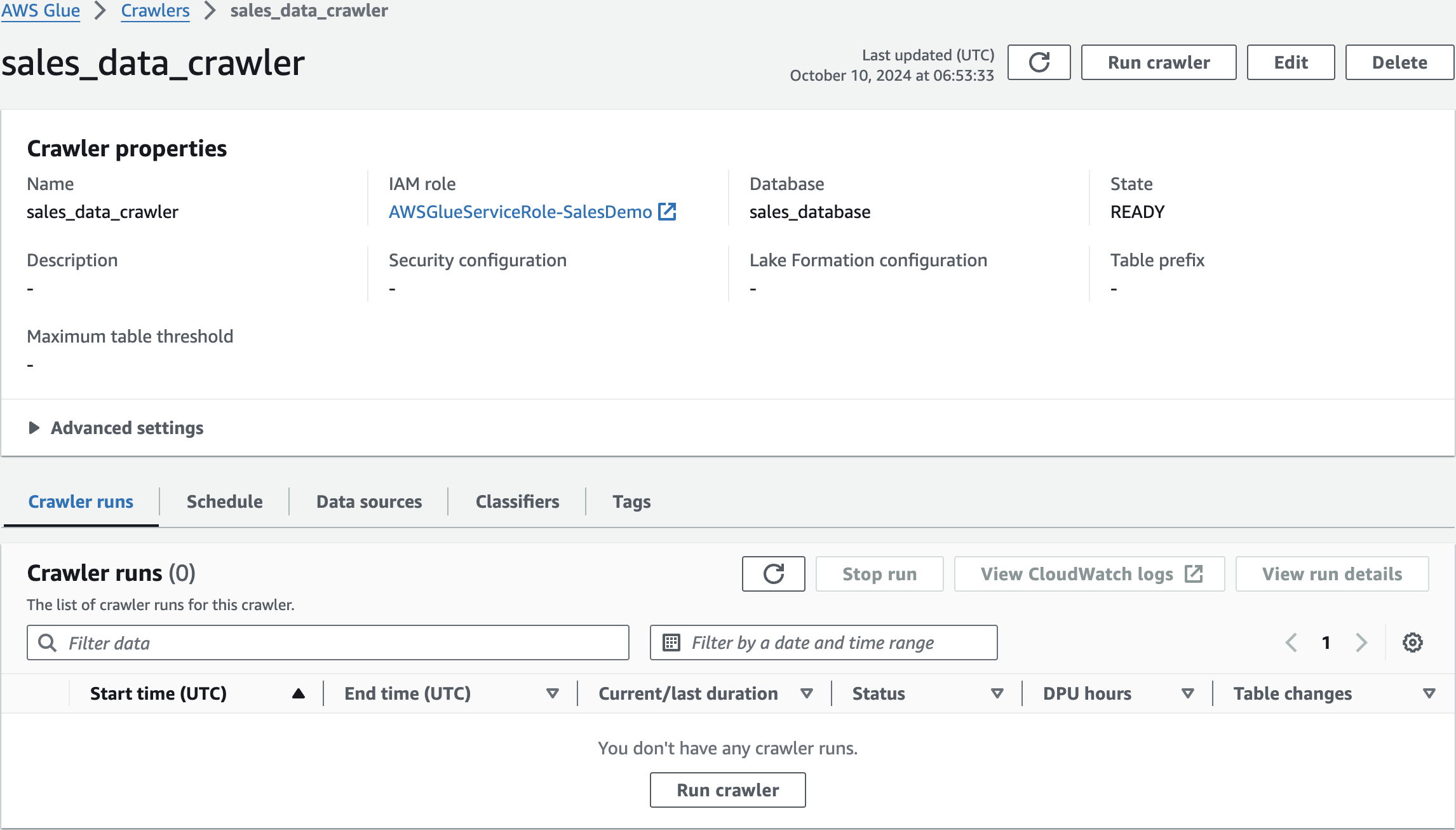
Run crawler

Crawler runs

Run Completed
Edit Role
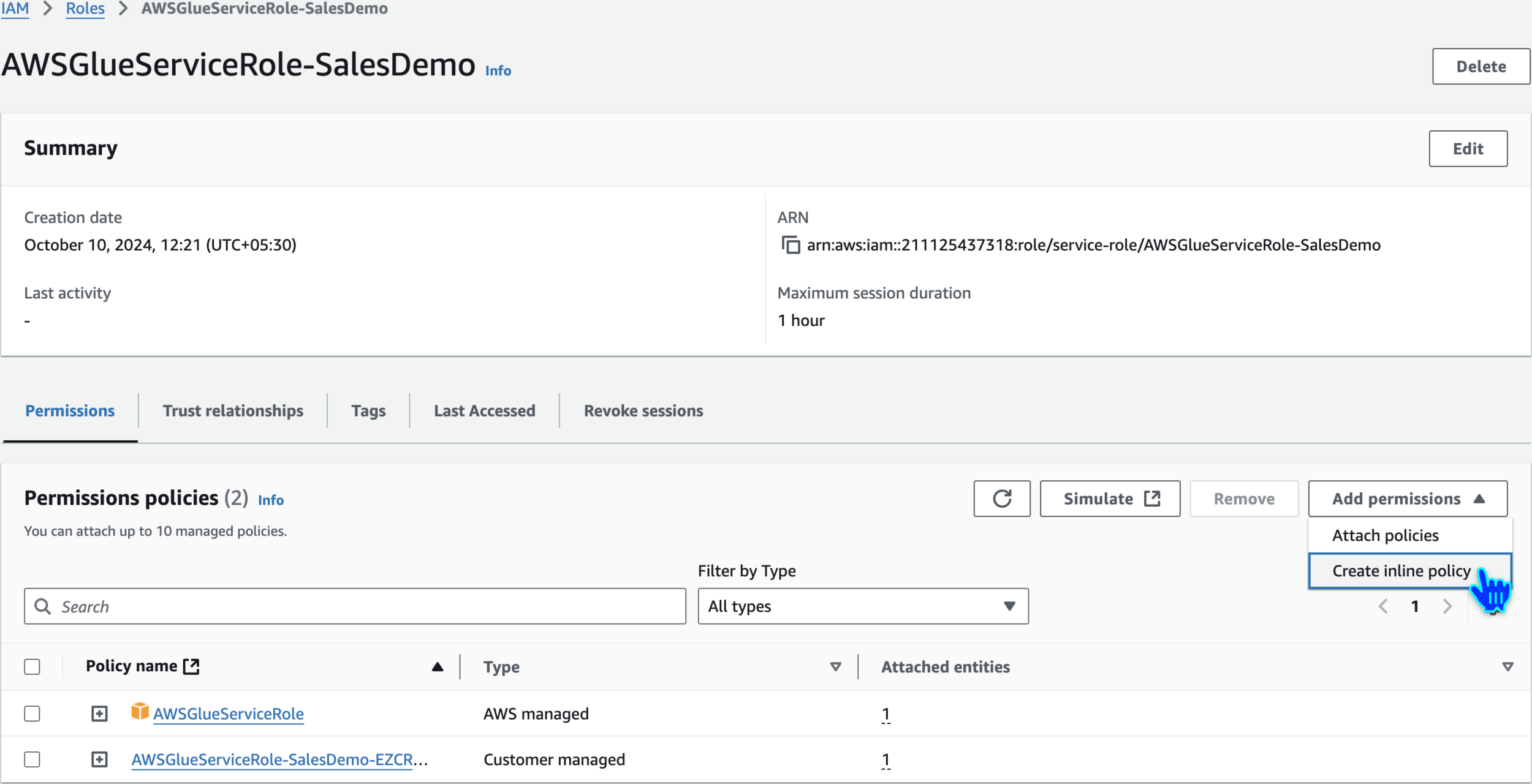
Create Inline Policy
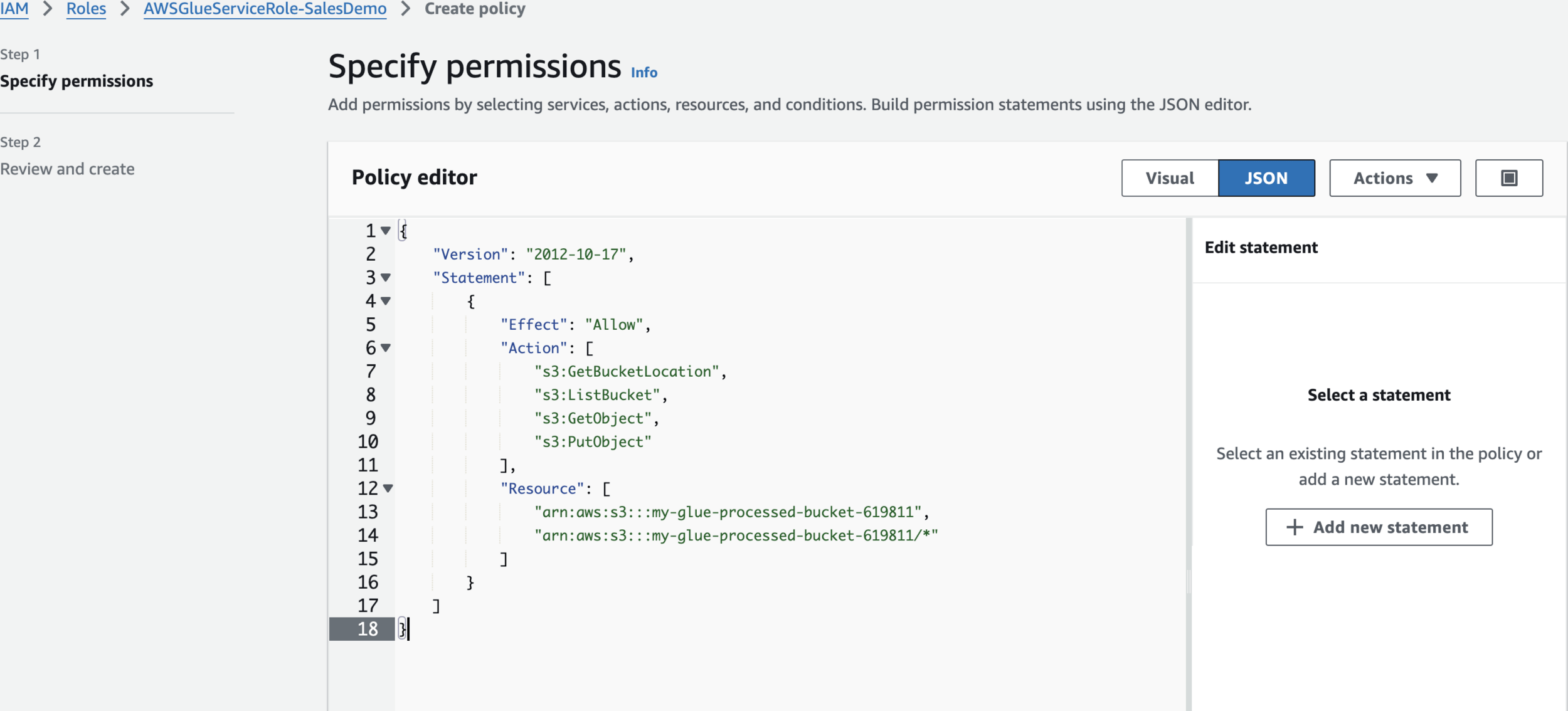
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::my-glue-processed-bucket-619811",
"arn:aws:s3:::my-glue-processed-bucket-619811/*"
]
}
]
}Create policy
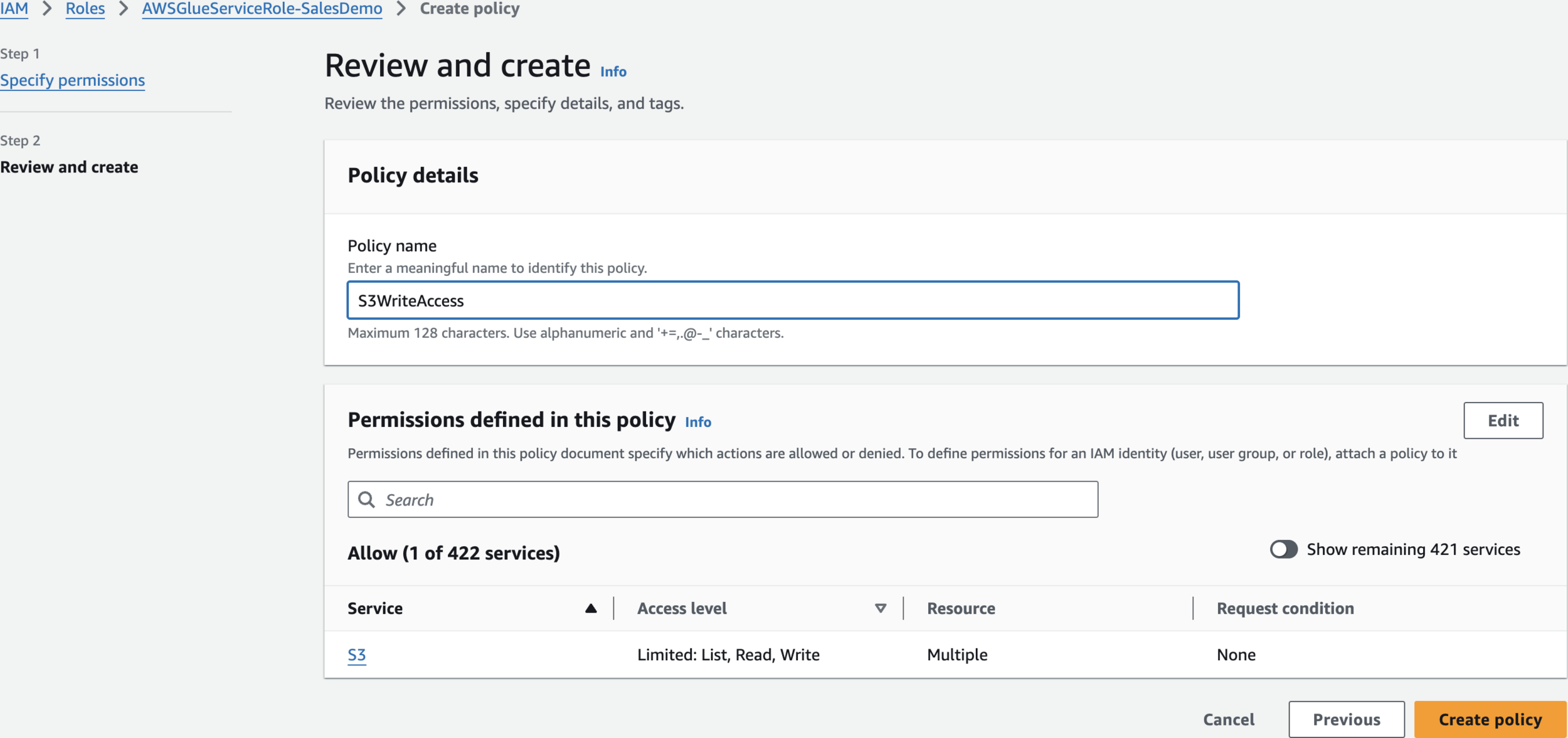
S3WriteAccessCreate Glue Job
Create job
Script
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, when, sum, avg, count, date_format, round
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'output_bucket'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Read data from the Data Catalog
datasource = glueContext.create_dynamic_frame.from_catalog(
database = "sales_database",
table_name = "my_glue_source_bucket_619811"
)
# Convert to DataFrame for complex transformations
df = datasource.toDF()
# Data Cleaning and Type Casting
df = df.withColumn("order_id", col("order_id").cast("int"))
df = df.withColumn("date", col("date").cast("date"))
df = df.withColumn("quantity", col("quantity").cast("int"))
df = df.withColumn("price", col("price").cast("double"))
# Calculate total sale amount
df = df.withColumn("total_amount", round(col("quantity") * col("price"), 2))
# Categorize orders by total amount
df = df.withColumn("order_size",
when(col("total_amount") < 20, "Small")
.when((col("total_amount") >= 20) & (col("total_amount") < 50), "Medium")
.otherwise("Large"))
# Extract month from date
df = df.withColumn("month", date_format(col("date"), "MM-yyyy"))
# Aggregate data for analysis with rounding
monthly_sales = df.groupBy("month", "category").agg(
round(sum("total_amount"), 2).alias("total_sales"),
round(avg("total_amount"), 2).alias("avg_order_value"),
count("order_id").alias("num_orders")
)Available in Resources Section
customer_summary = df.groupBy("customer_id").agg(
round(sum("total_amount"), 2).alias("total_spent"),
count("order_id").alias("num_orders"),
round(avg("total_amount"), 2).alias("avg_order_value")
)
# Coalesce to single partition
monthly_sales = monthly_sales.coalesce(1)
customer_summary = customer_summary.coalesce(1)
# Convert back to DynamicFrames
processed_orders = DynamicFrame.fromDF(df, glueContext, "processed_orders")
monthly_sales_df = DynamicFrame.fromDF(monthly_sales, glueContext, "monthly_sales")
customer_summary_df = DynamicFrame.fromDF(customer_summary, glueContext, "customer_summary")
# Write to S3
output_bucket = args['output_bucket']
glueContext.write_dynamic_frame.from_options(
frame = processed_orders,
connection_type = "s3",
connection_options = {"path": f"s3://{output_bucket}/processed_orders/"},
format = "parquet"
)
glueContext.write_dynamic_frame.from_options(
frame = monthly_sales_df,
connection_type = "s3",
connection_options = {
"path": f"s3://{output_bucket}/monthly_sales/",
"partitionKeys": []
},
format = "parquet"
)
glueContext.write_dynamic_frame.from_options(
frame = customer_summary_df,
connection_type = "s3",
connection_options = {
"path": f"s3://{output_bucket}/customer_summary/",
"partitionKeys": []
},
format = "parquet"
)
job.commit()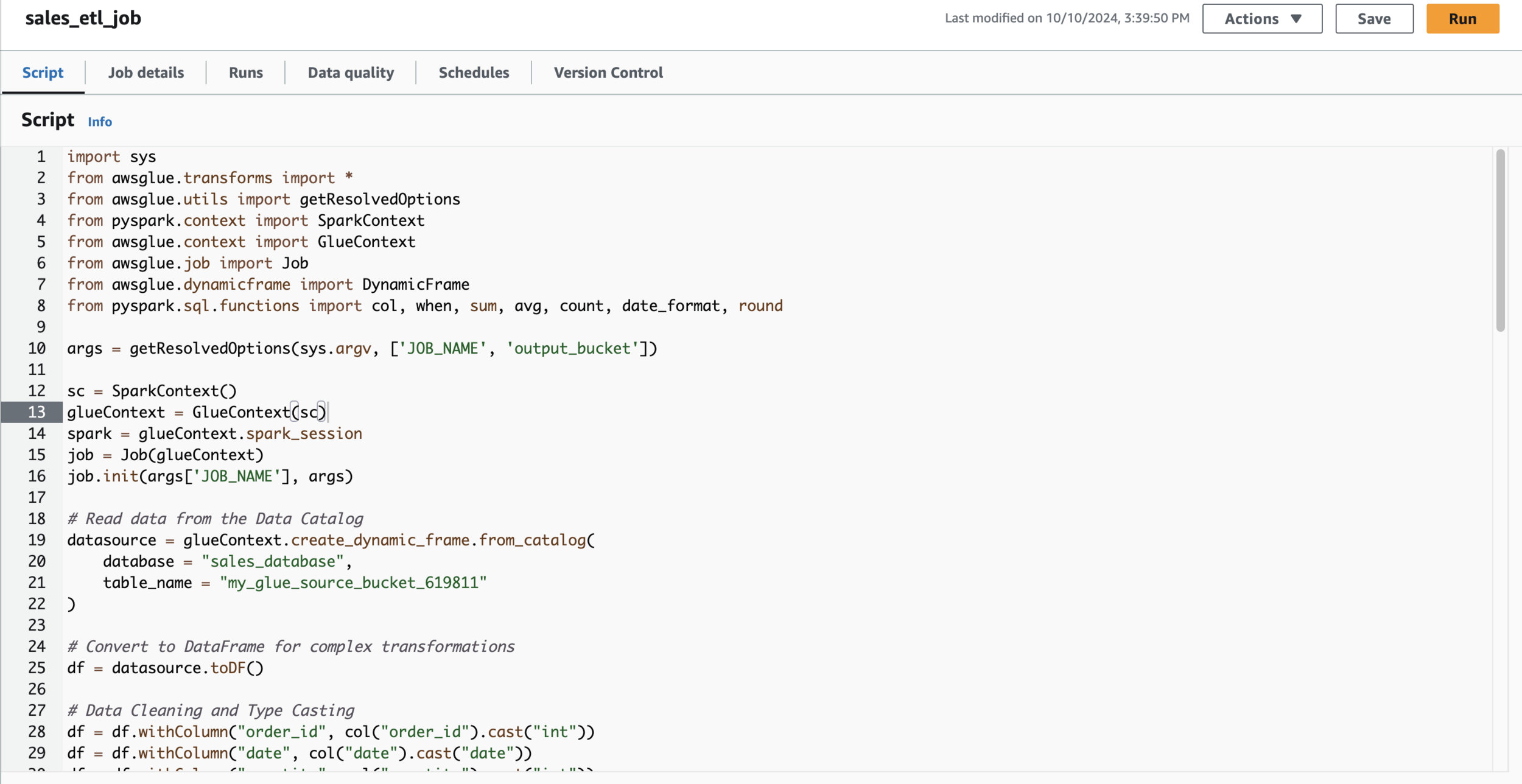
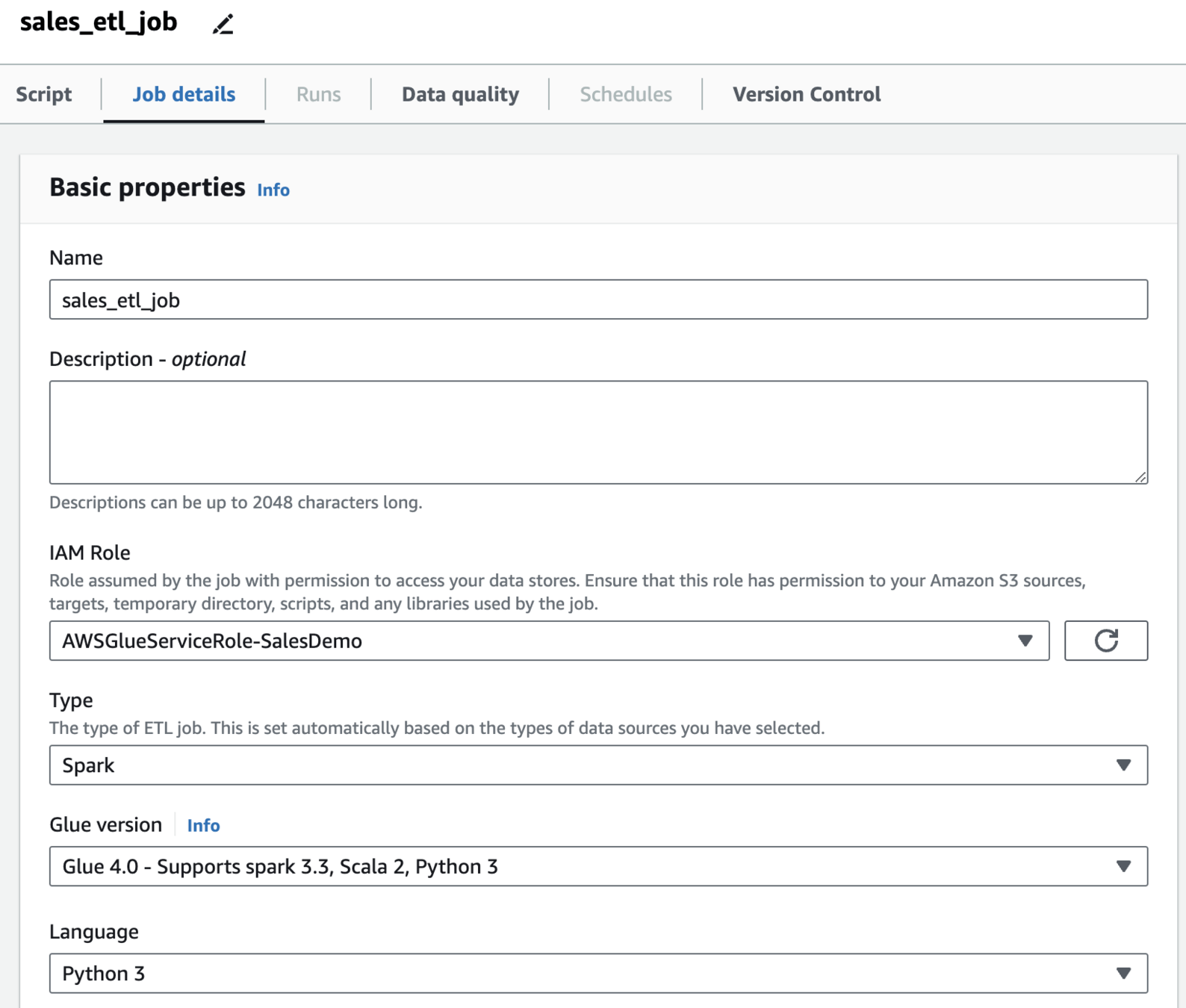
Job details
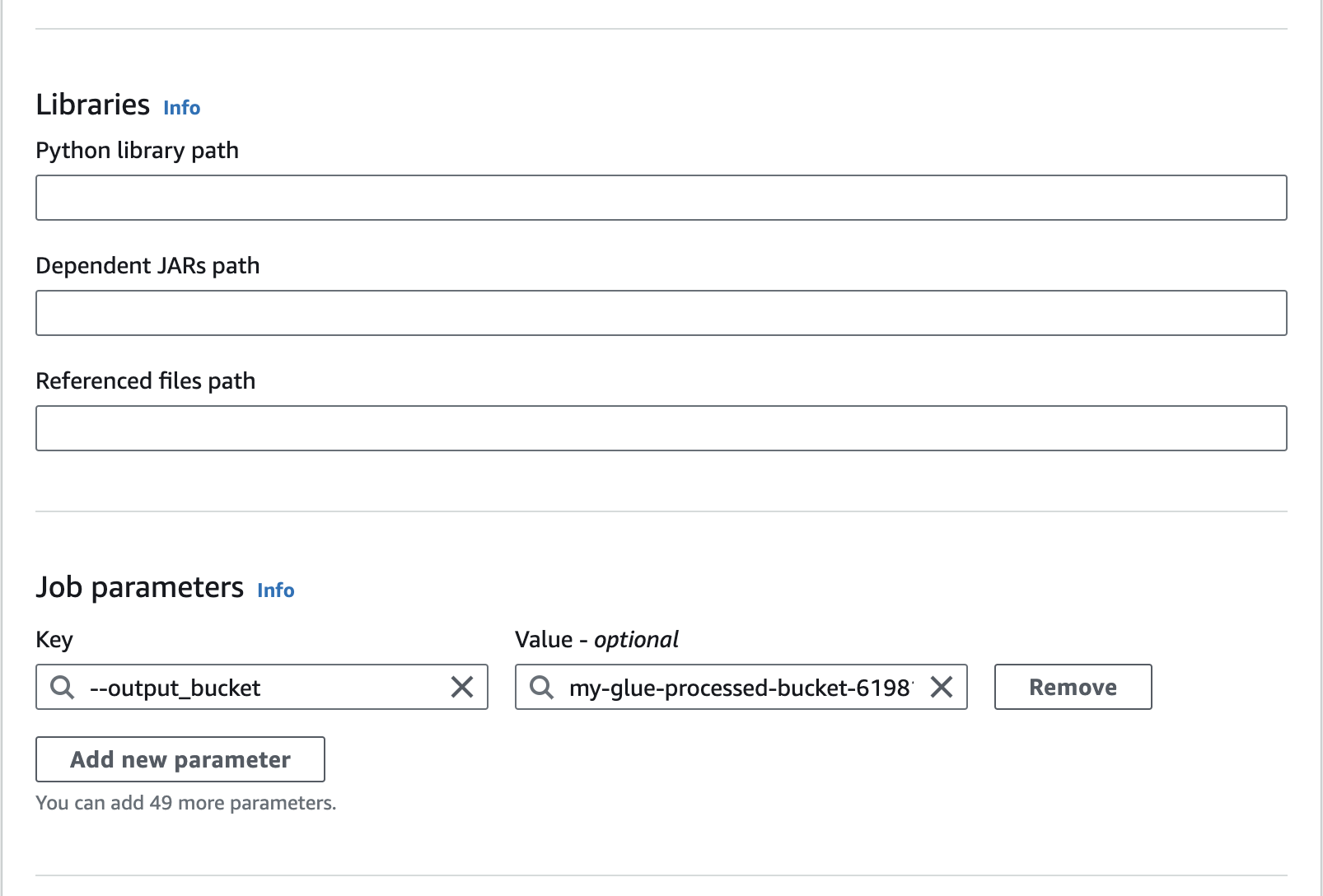
Add Job parameter
--output_bucketmy-glue-processed-bucket-619811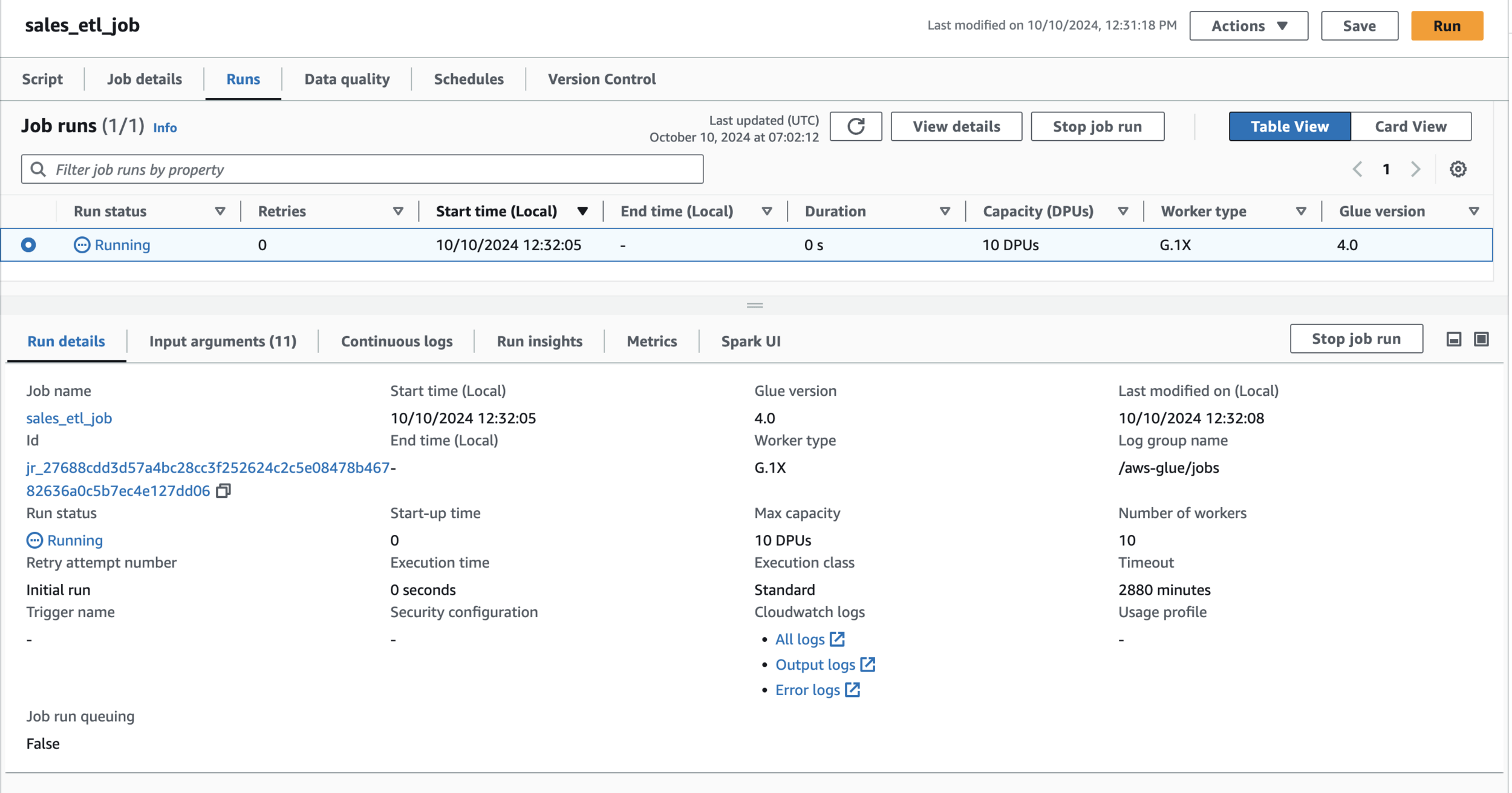
Run Job
Output
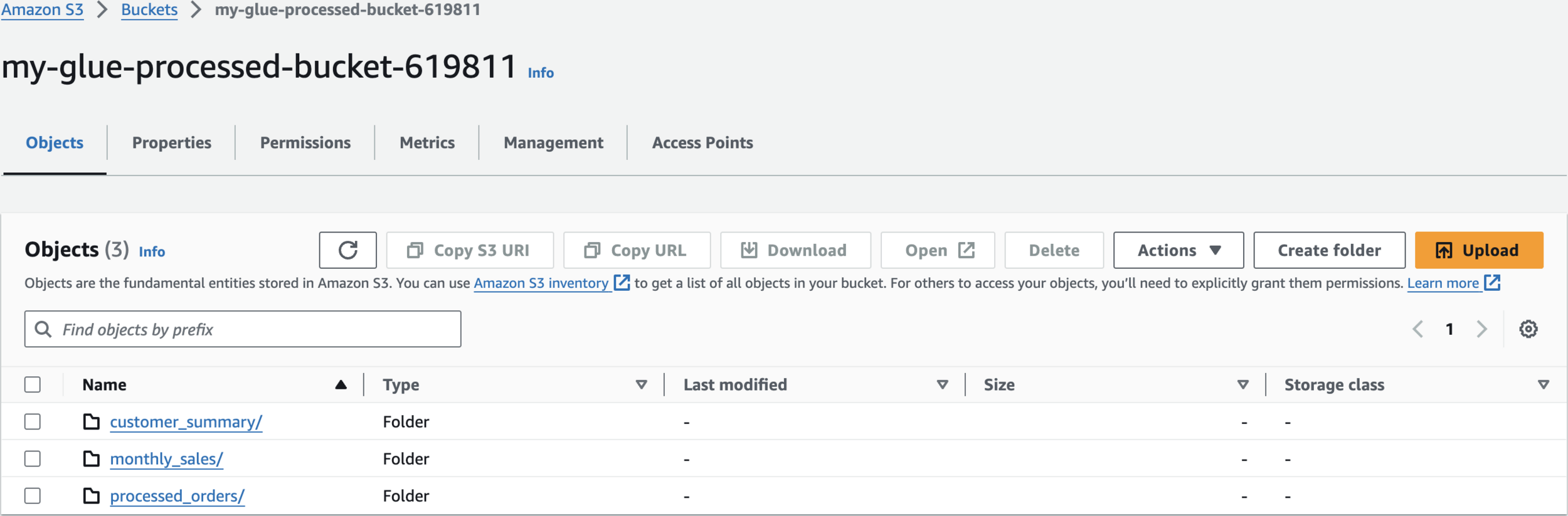
Output Bucket
Athena
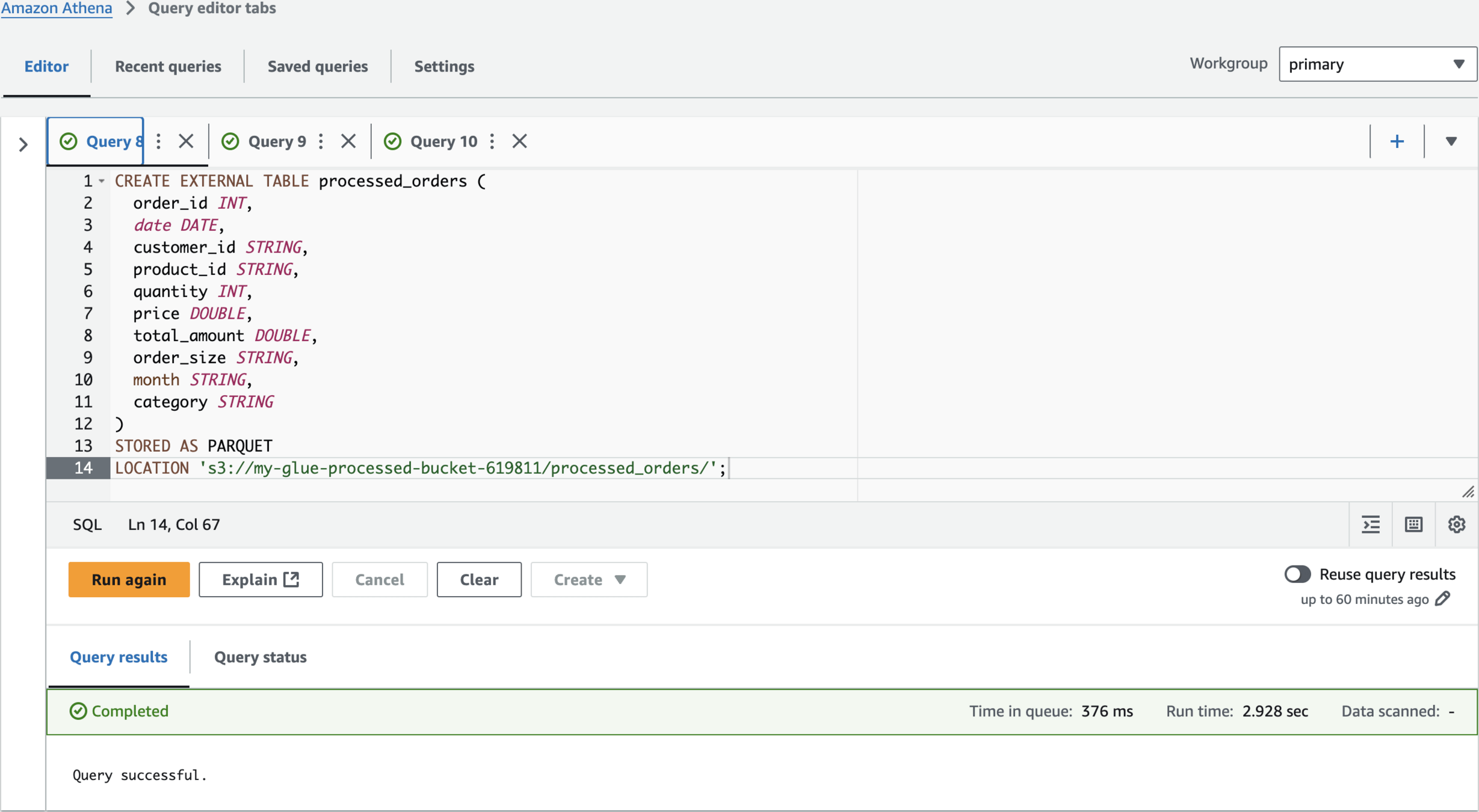
CREATE EXTERNAL TABLE processed_orders (
order_id INT,
date DATE,
customer_id STRING,
product_id STRING,
quantity INT,
price DOUBLE,
total_amount DOUBLE,
order_size STRING,
month STRING,
category STRING
)
STORED AS PARQUET
LOCATION 's3://my-glue-processed-bucket-619811/processed_orders/';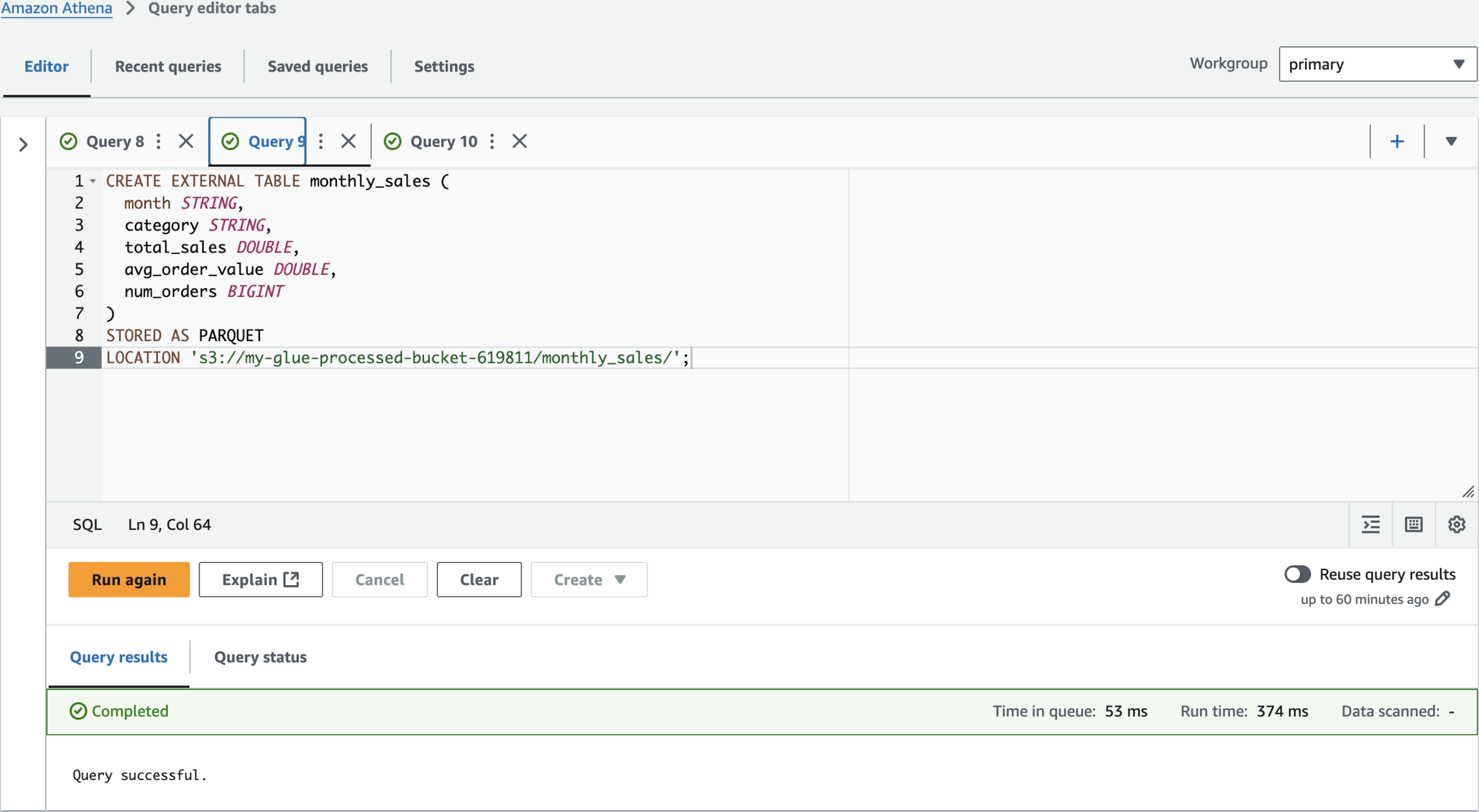
CREATE EXTERNAL TABLE monthly_sales (
month STRING,
category STRING,
total_sales DOUBLE,
avg_order_value DOUBLE,
num_orders BIGINT
)
STORED AS PARQUET
LOCATION 's3://my-glue-processed-bucket-619811/monthly_sales/';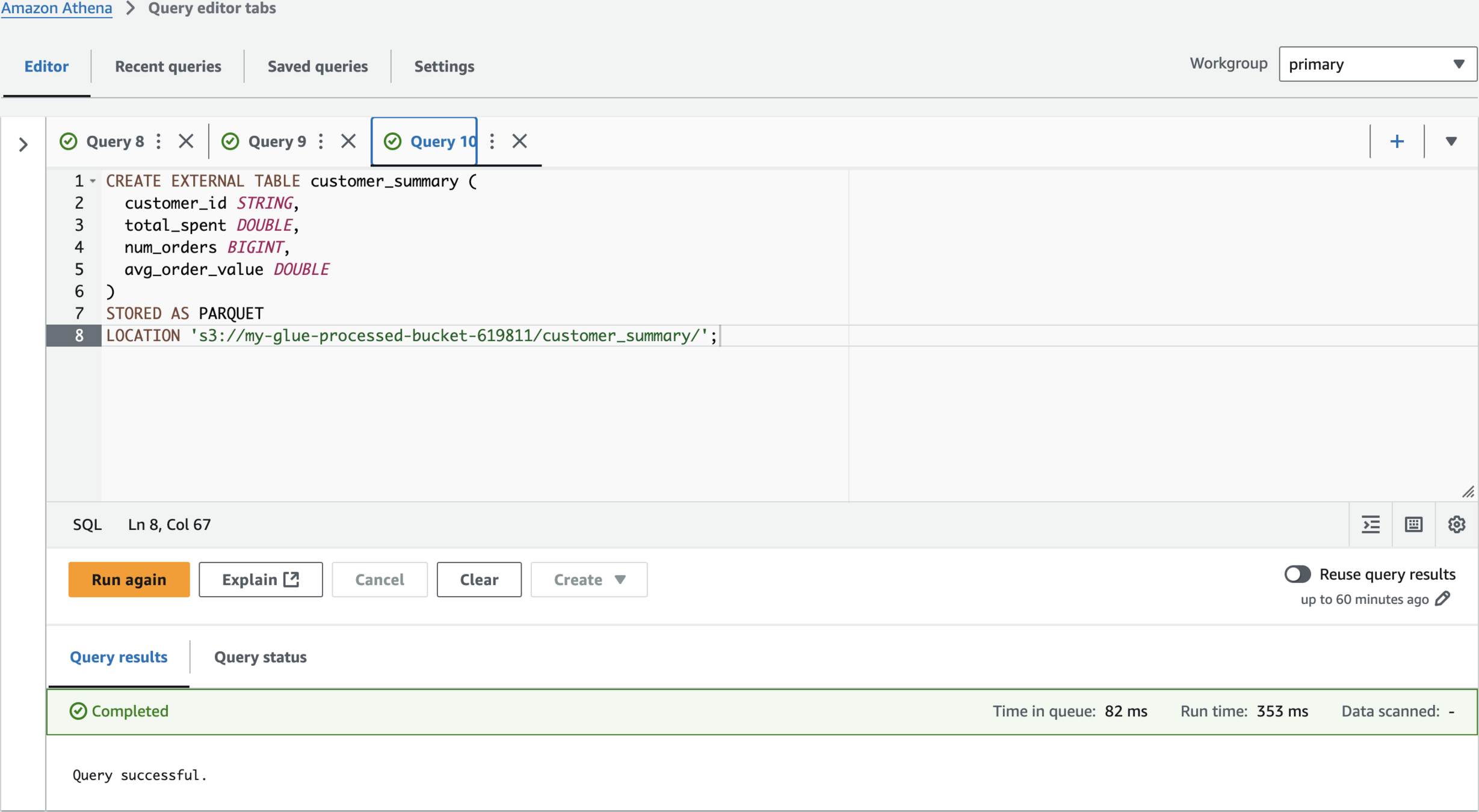
CREATE EXTERNAL TABLE customer_summary (
customer_id STRING,
total_spent DOUBLE,
num_orders BIGINT,
avg_order_value DOUBLE
)
STORED AS PARQUET
LOCATION 's3://my-glue-processed-bucket-619811/customer_summary/';
SELECT * FROM processed_orders LIMIT 10;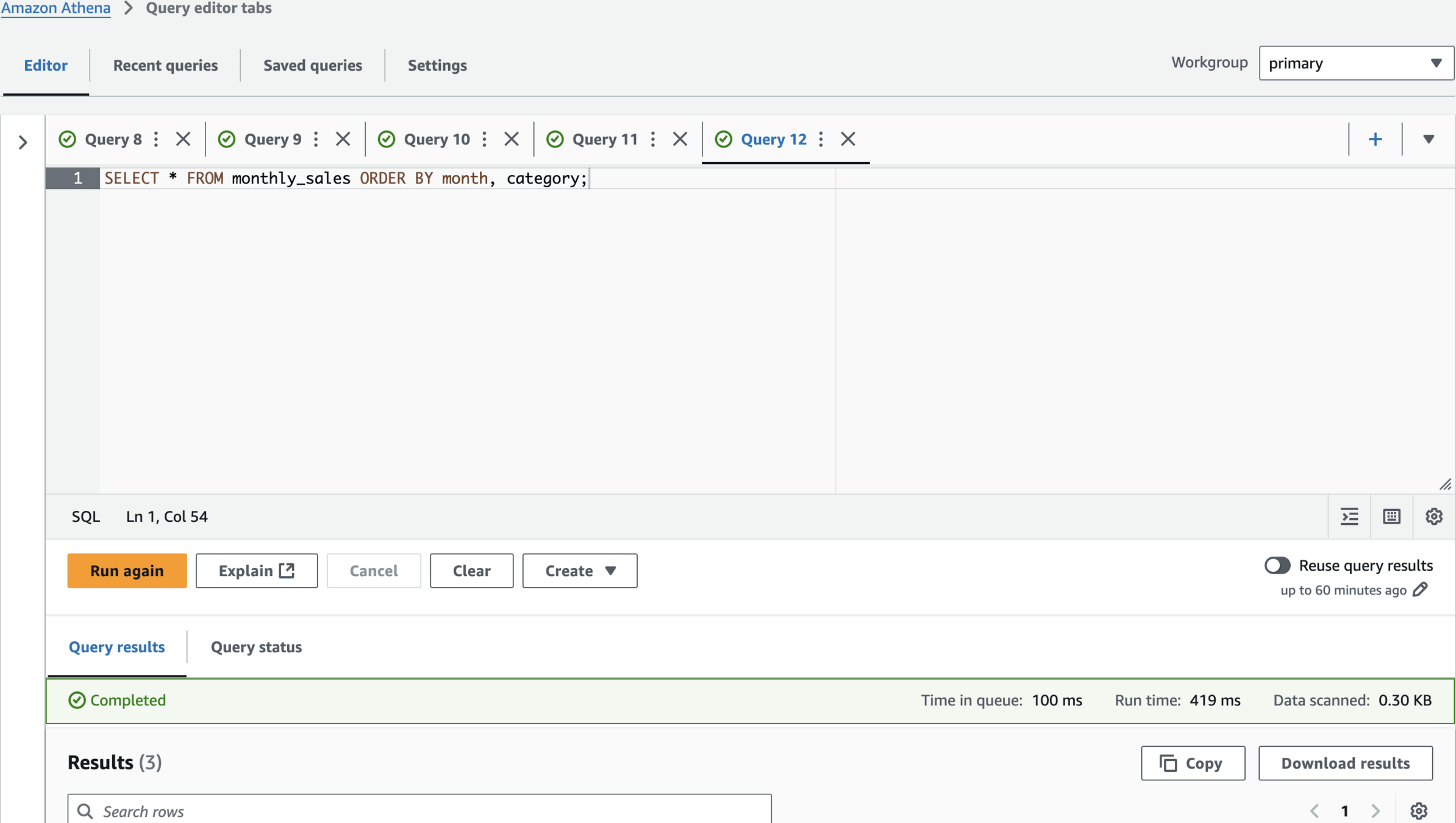
SELECT * FROM monthly_sales ORDER BY month, category;
SELECT * FROM customer_summary ORDER BY total_spent DESC LIMIT 5;Clean Up
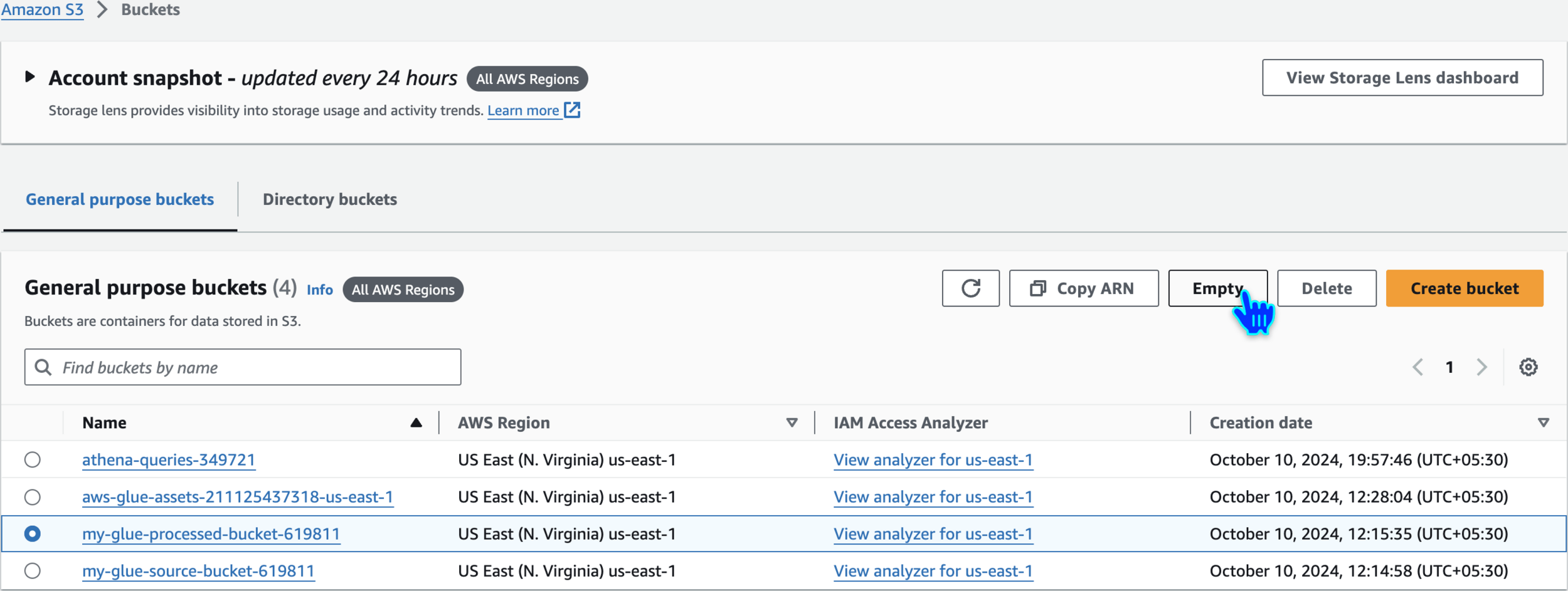
Empty and Delete S3 Buckets
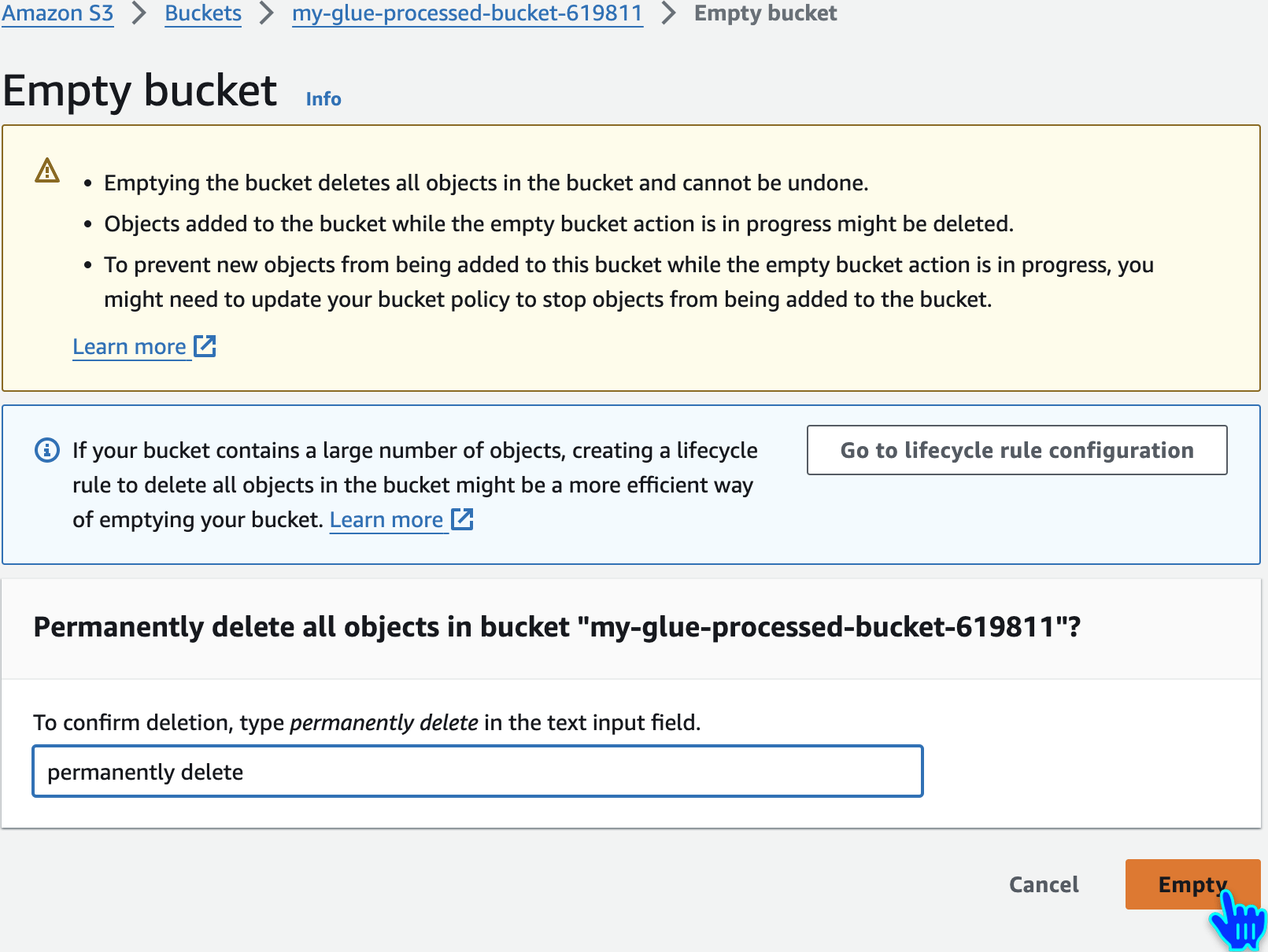
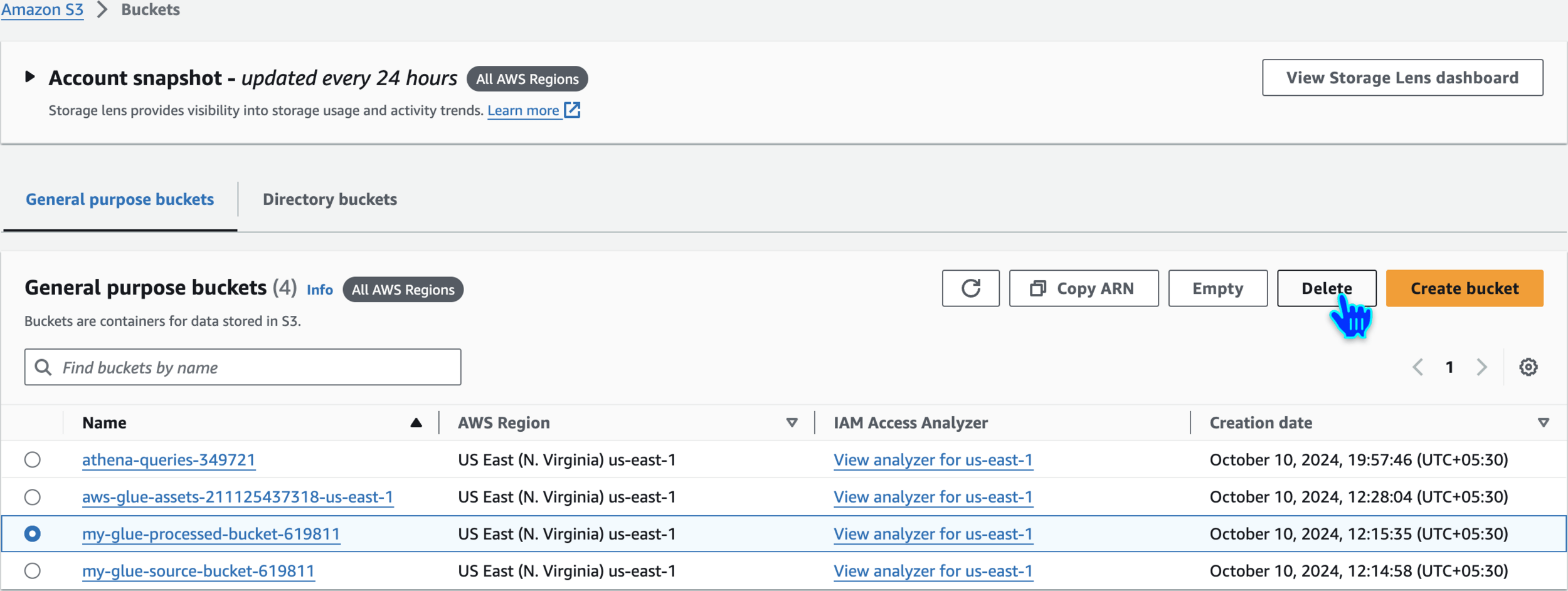
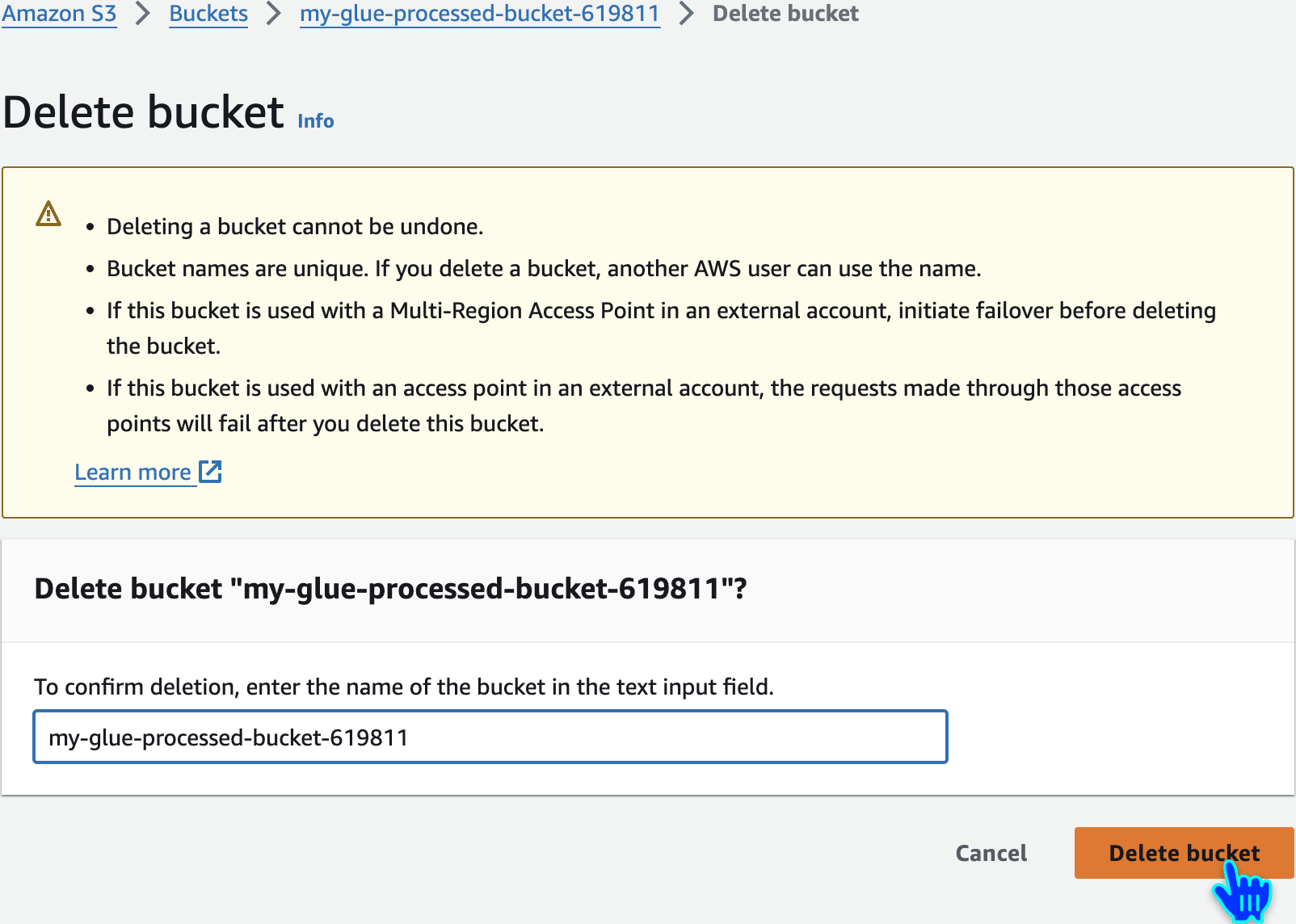
Repeat the Same for other buckets also
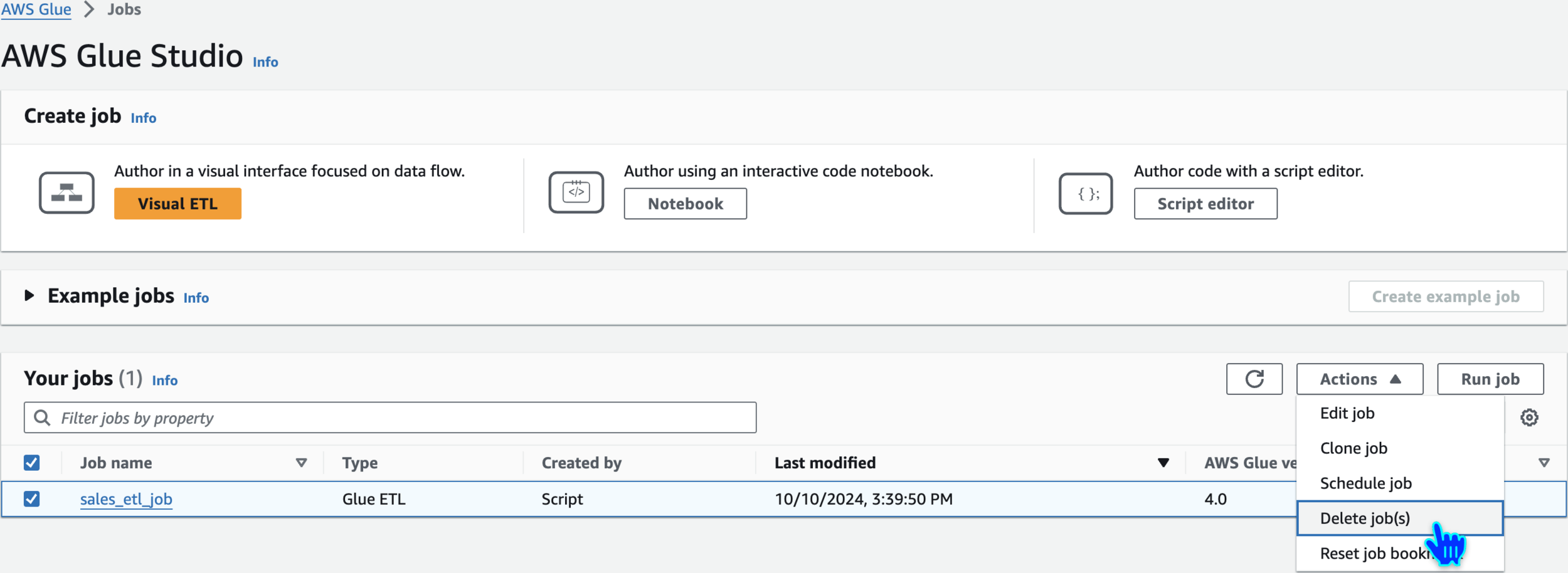
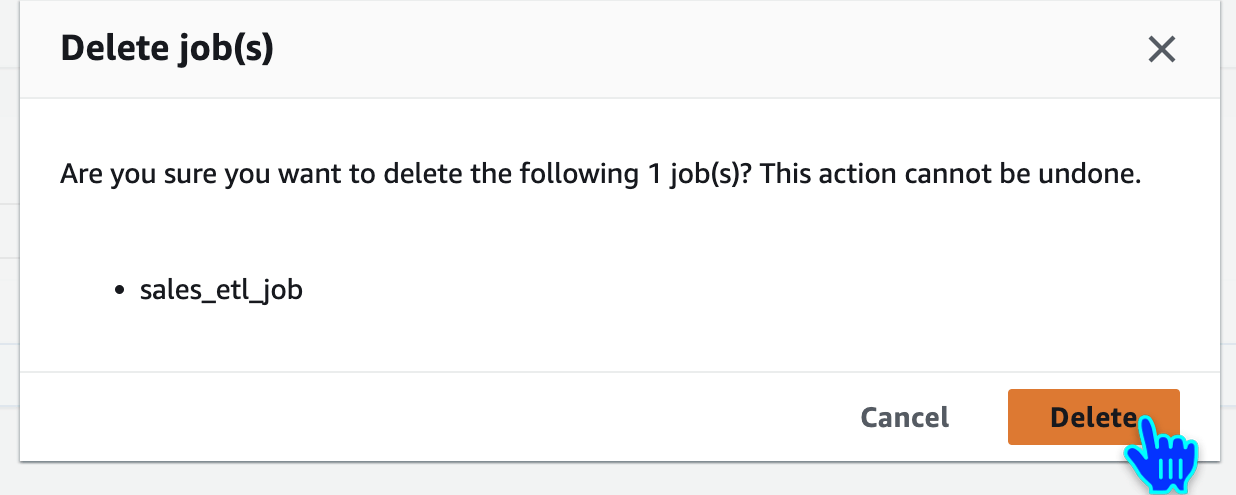
Delete job
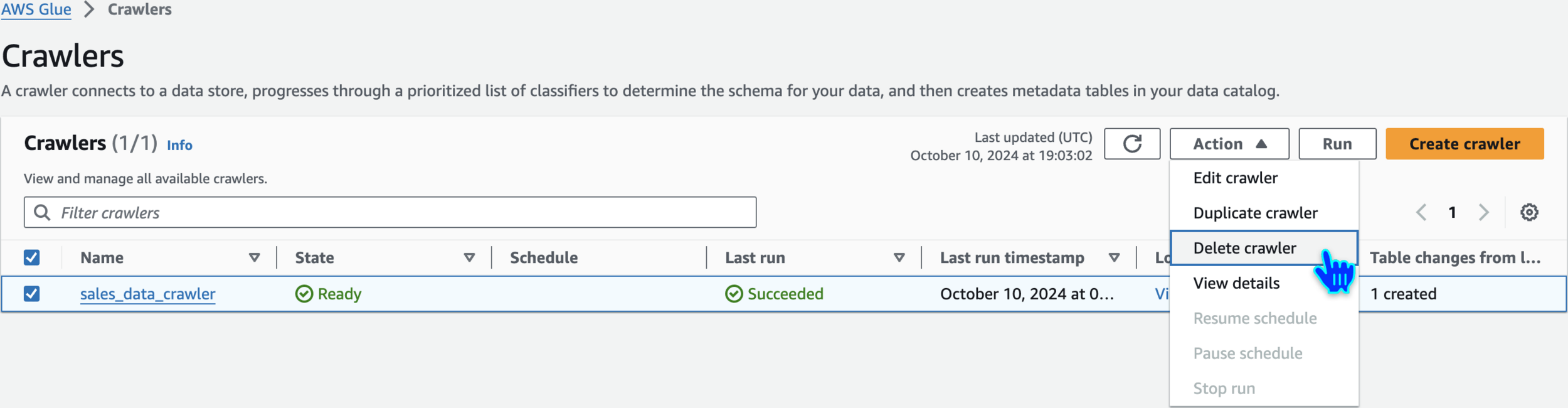
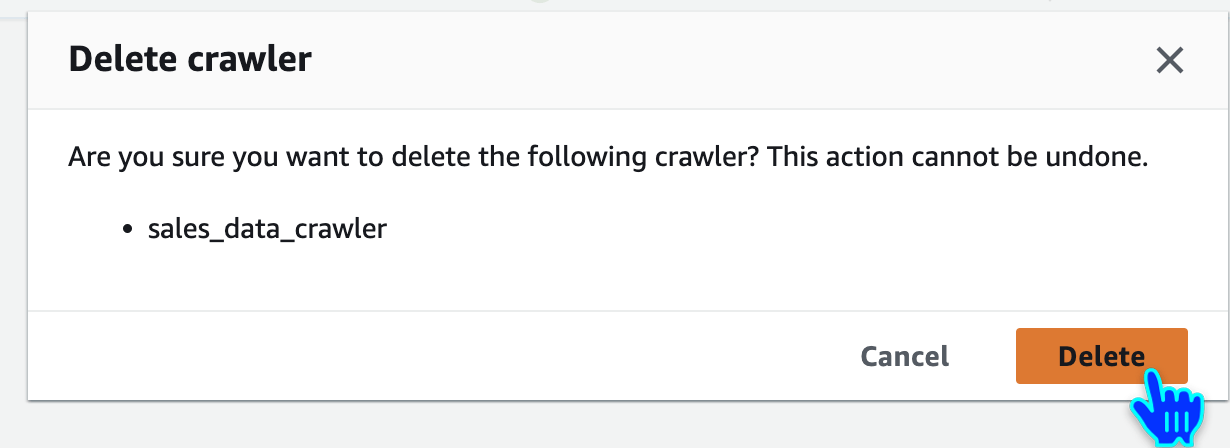
Delete crawler

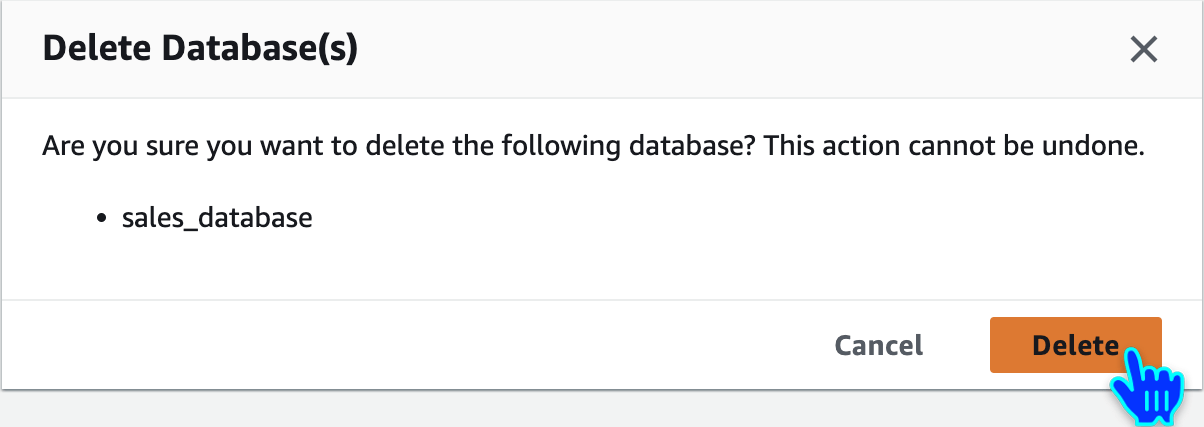
Delete Glue Database

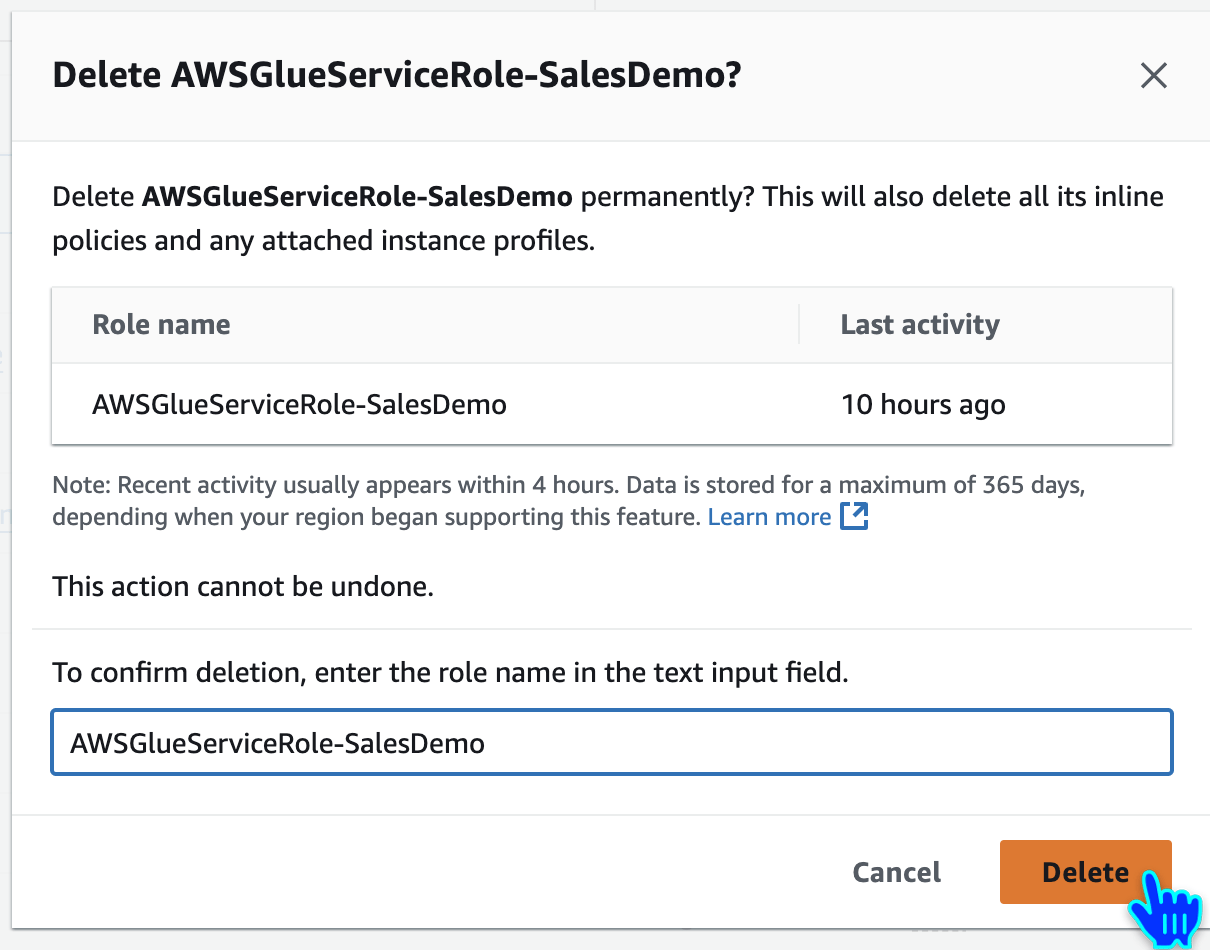
Delete IAM Role
🙏
Thanks
for
Watching
AWS Glue - Hands-On Demo
By Deepak Dubey
AWS Glue - Hands-On Demo
AWS Glue - Hands-On Demo



