Applying a supervised approach recursively to find style breaches in text
D. Zlatkova, D. Kopev, K. Mitov,
A. Atanasov, M. Hardalov, I. Koychev
FMI, Sofia University, Bulgaria
The 18th International Conference on Artificial Intelligence: Methodology, Systems, Applications
Varna, Bulgaria
13 September 2018
P. Nakov
Qatar Computing Research Institute, HBKU, Doha, Qatar
Agenda
- Motivation
- Related Work
- Data
- Method
- Results
- Conclusions & Future Work

Style Change Detection
Given a document, determine whether it contains style changes or not, i.e., if it was written by a single or multiple authors. [Kestemont et al., 2018]
1
Style Breach Detection

Given a document, determine whether it is multi-authored, and if yes, find the borders where authors switch. (Hard)
2
Motivation
- Finding style breaches in text is a prerequisite for applying authorship attribution models when multiple authors are involved.
-
Example domains:
- plagiarism detection
- cyber-security
- forensics
- social media analysis
Related Work
1. Authorship attribution:
- Based on TF.IDF [Kuznetsov et al. 2016]
- Features from stylometry [Khan et al. 2017, Sittar el al., 2016]
2. Style Breach Detection:
- Wilcoxon Signed Rank test to check whether two segments are likely to come from the same distribution [Karas et al., 2017]
- Outlier detection using cosine-based distance between sentence vectors using pre-trained skip-thought models [Safin et al., 2017]
Style Change Detection Model
(Winning submission at PAN @ CLEF 2018)
Data (Style Change)
- PAN 2018
- StackExchange forum
- 3k train, 1.5k validation, 1.5k test
- Balanced classes (50/50)
- 300-1000 words per doc
- Different topics
- bicycles
- gaming
- parenting
- poker
- ...
Data Preprocessing
- Special tokens
- http://www.java2s.com -> _URL_
- 66657345299563332126532111111 -> _LONG_NUM_
- /Users/Shared/Client/Blizzard -> _FILE_PATH
- ================== -> _CHAR_SEQ
- Taumatawhakatangihangakoauauo-> _LONG_WORD_
- Split hyphenated words
- Pretends-To-Be-Scrum-But-Actually-Is-Not-Even-Agile
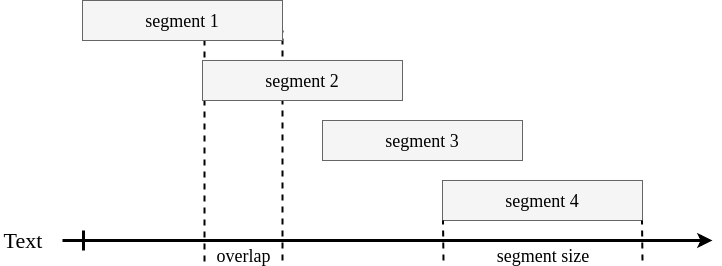
Text Segmentation
- Sliding Window
- Window Size: 1/4 of doc length
- 1/3 subsequent window overlap
- Max diff of feature vectors
Lexical Features
- spaces
- digits
- commas
- (semi)colons
- apostrophes
- quotes
- parenthesis
- number of paragraphs
- POS-tags
- short (< 4 chars)
- long (> 6 chars)
- average length
- all-caps
- capitalized
- question
- period
- exclamation
- short (<100chars)
- long (>200 chars)
Characters:
Words:
Sentences:
More Features
- Stop words: you, the, is, of, ...
- Function words: least, well, etc, whether, ...
- Readability, e.g Flesch reading ease:

- Vocabulary richness
- Average word frequency class
- frequency class of 'the' is 1
- frequency class of 'doppelganger' is 19
- Proportion of unknown words (not in the corpus)
- Average word frequency class
Even More Features
- Repetition
- average number of occurrences of unigrams, bigrams, ..., 5-grams
- Grammar Contractions
- I will vs. I'll
- are not vs. aren't
- Quotation variation: ' vs. "
Stacking Architecture

- Ensemble + Weighting:
- SVM
- Random Forest
- AdaBoost
- MLP
- LightGBM + TF-IDF:
- Character [2-6]-grams (up to 300k)
- Word [1-2]-grams (up to 300k)
- Logistic Regression
Migrating to Style Breach
- Use the developed supervised method
- Search for breaches recursively
- Split at the sentence level
- Stop at 20 sentences
- Confidence threshold of 75% for breach to fight unbalanced data
Data (Style Breach)
- PAN 2017
- 134 training examples
- 0 to 8 breaches
- unbalanced classes (80:20)
- 1,000–2,400 words per doc
- border positions only at the end of sentences / paragraphs
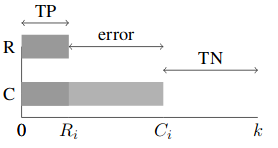
Metrics
WindowDiff (lower is better)
WinPR (higher is better)
Source: [Pevzner el al., 2002, Scaiano el al., 2012]
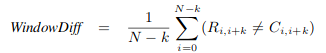
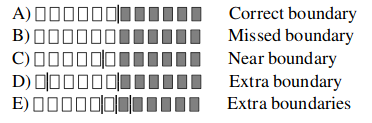
Baselines
- BASELINE-rnd randomly places between 0 and 10 borders at arbitrary positions inside a document.
- BASELINE-eq also decides on a random basis how many borders should be placed (again 0–10), but then places these borders uniformly, i.e., so that all resulting segments are of equal size with respect to the tokens contained.
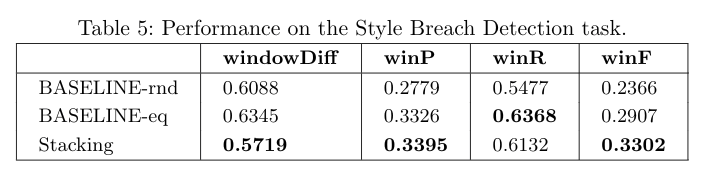
Results
5-fold Cross Validation on Train data
Conclusion & Future Work
- High accuracy for Style Change Detection is achievable.
- Style Breach Detection is a hard task, but can be tackled using a supervised approach.
- Finding other types of contrasting views of text projection by the authors could be the key to success.
- Results can be improved if training is done on text pieces of different lengths.

References I
[Kestemont et al., 2018] Kestemont, M., Tschuggnall, M., Stamatatos, E., Daelemans, W., Specht, G., Stein, B., Potthast, M.: Overview of the author identification task at PAN-2018: Cross-domain authorship attribution and style change detection. In: Working Notes of CLEF 2018 - Conference and Labs of the Evaluation Forum. CLEF ’18, Avignon, France (2018)
[Safin et al., 2017] Safin, K., Kuznetsova, R.: Style breach detection with neural sentence embeddings—notebook for PAN at CLEF 2017. In: CLEF 2017 Evaluation Labs and Workshop – Working Notes Papers. CLEF ’17, Dublin, Ireland (2017)
[Karaś et al., 2017] Karaś, D., Śpiewak, M., Sobecki, P.: OPI-JSA at CLEF 2017: Author Clustering and Style Breach Detection—Notebook for PAN at CLEF 2017. In: CLEF 2017 Evaluation Labs and Workshop – Working Notes Papers. CLEF ’17, Dublin, Ireland (2017)
[Kuznetsov et al., 2016] Kuznetsov, M., Motrenko, A., Kuznetsova, R., Strijov, V.: Methods for intrinsic plagiarism detection and author diarization—notebook for PAN at CLEF 2016. In: CLEF 2016 Evaluation Labs and Workshop – Working Notes Papers. CLEF ’16, Évora, Portugal (2016)
[Khan et al., 2017] Khan, J.: Style breach detection: An unsupervised detection model—notebook for PAN at CLEF 2017. In: CLEF 2017 Evaluation Labs and Workshop – Working Notes Papers. CLEF ’17, Dublin, Ireland (2017)
References II
[Sittar et al., 2016] Sittar, A., Iqbal, H., Nawab, R.: Author Diarization Using Cluster-Distance Approach—Notebook for PAN at CLEF 2016. In: CLEF 2016 Evaluation Labs and Workshop – Working Notes Papers. CLEF ’16, Évora, Portugal (2016)
[Pevzner et al., 2002] Pevzner, L., Hearst, M.A.: A critique and improvement of an evaluation metric for text segmentation. Computational Linguistics 28(1), 19–36 (2002)
[Scaiano et al., 2012] Scaiano, M., Inkpen, D.: Getting more from segmentation evaluation. In: Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 362–366. NAACL-HLT ’12, Montreal, Canada (2012)
AIMSA
By Dimitrina Zlatkova

