PAN 2018

Style Change Detection
Атанас, 25858 Димитрина, 25620
Даниел, 25830 Кристиян, 25625

The Task
Today's topics:
- Data Exploration
- Data Preprocessing
- Features
- Things that didn't work out
- Word-based CNN + SE
- Style Breach Detection
- Results
Data Exploration
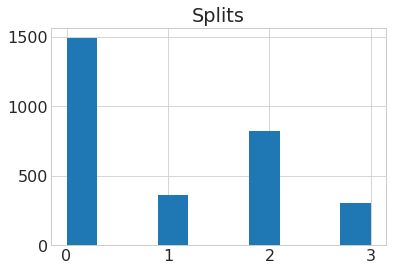
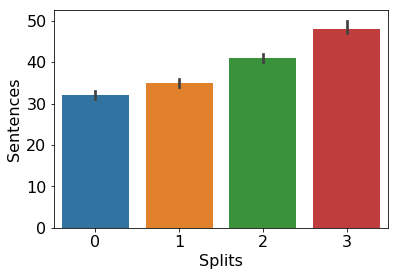
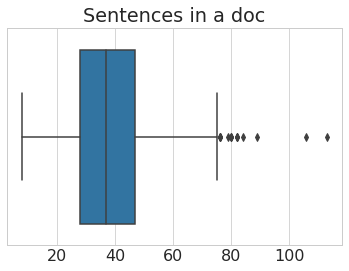
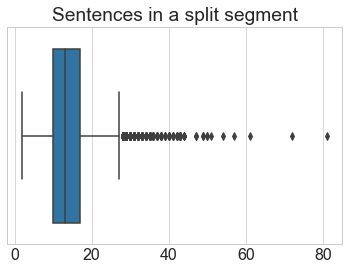
Data Preprocessing
- On raw text
- http://www.java2s.com -> _URL_
- 66657345299563332126532111111 -> _LONG_NUM_
- After segmentation
- /Users/Shared/Client/Blizzard -> _FILE_PATH_
- ================== -> _CHAR_SEQ_
- Taumatawhakatangihangakoauauo-> _LONG_WORD_
- Split hyphenated words
- Pretends-To-Be-Scrum-But-Actually-Is-Not-Even-Agile
Lexical Features
- spaces
- digits
- commas
- (semi)colons
- apostrophes
- quotes
- parenthesis
- POS-tags
- short (< 4 chars)
- long (> 6 chars)
- average length
- all-caps
- capitalized
- question
- period
- exclamation
- short (<100chars)
- long (>200 chars)
- number of paragraphs
Characters:
Words:
Sentences:
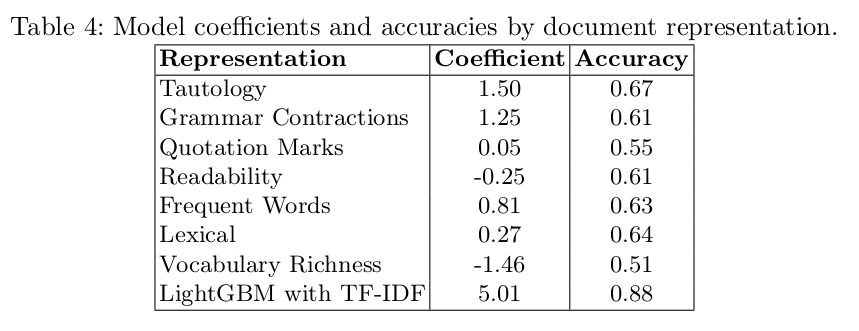
More Features
- Tautology
- Grammar Contractions
- I will vs. I'll
- are not vs. aren't
- Quotation variation: ' vs. "
- Named entity spelling
- New York City vs. NYC
Begin and end of author segments
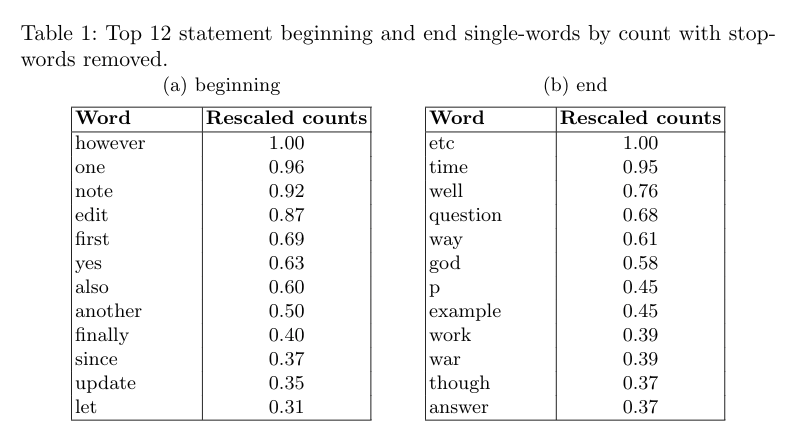
Feature Importance
Things that didn't work out
- Dual input model
- LSTM with self-trained embeddings
- LSTM with pre-trained embeddings
- LSTM on feature vectors
- SVM with tf-idf
- Ridge Regression
Word-based CNN
- Window size: 11
- Dropout rate: 0.1
- Optimizer: adam
- Filter depth: 64
- Batch size: 256
- Max words: 1024
- Vocab size: 60k
- Embedding size: 300
- Bagging
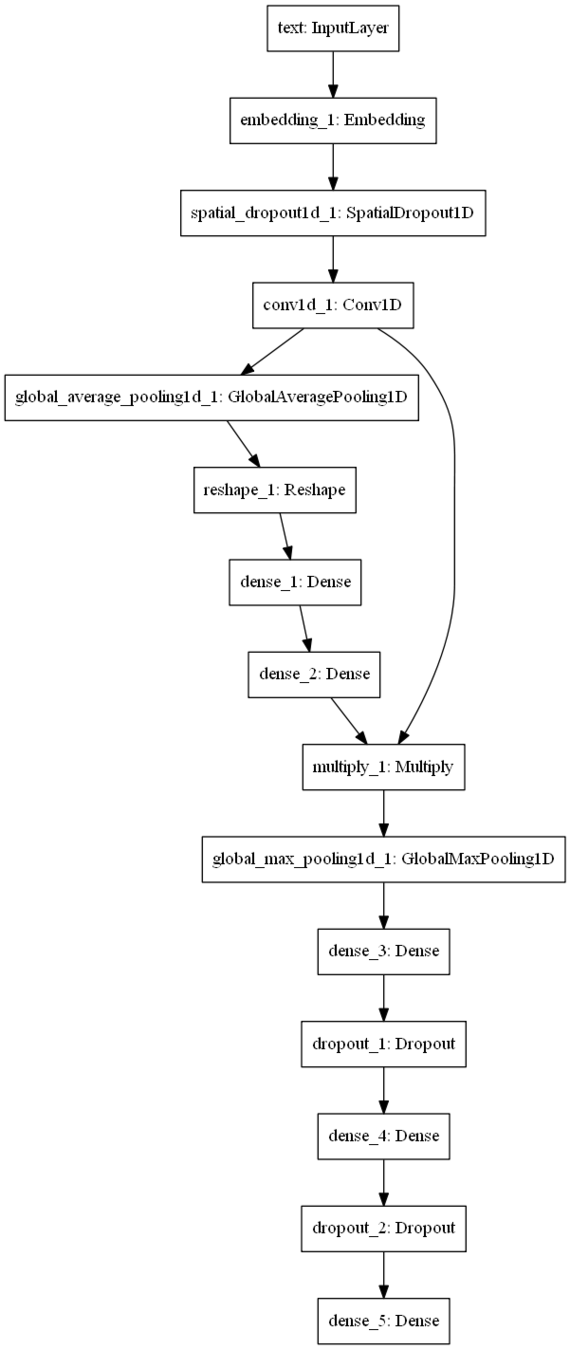
Squeeze & Excitation

Results
| Classifier | Dataset | Accuracy |
|---|---|---|
| CNN | validation | 85.92 |
| Stacking w/ CNN | validation | 78.02 |
| Stacking w/ CNN and LightGBM | validation | 86.93 |
| CNN (train + validation) | test | 88.39 |
| Stacking w/ LightGBM | test | 89.35 |
Style Breach Detection

- PAN 2017
- 134 training examples
- 0 to 8 breaches
- unbalanced classes (80:20)
- recursive search for breaches
- stop at 20 sentences
- confidence threshold: 75%
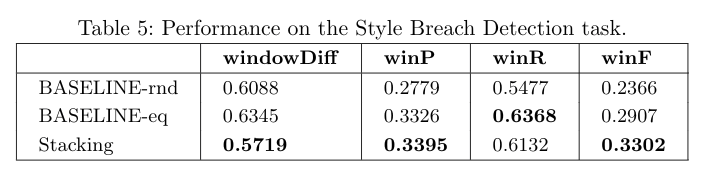
Results
PAN Text Mining
By Dimitrina Zlatkova


