Native AWS Services
Network Code Tech Talks
Diego Cardozo @ Aug 2021
Who am I?

Goal for this talk
- Too many services to cover (175+)
- Go over the core building blocks
- Focus on understanding how to
choose the right service- Tradeoffs
- Limitations
Sample project
Use cases
- Register devices
- Collect metrics
First decision: use NAWS?
Simplified network monitoring service
Sample project
What do we need?
- Storage
- Device registry (database)
- Alert configuration (files)
- Computing
- Register device
- Collect metrics
- Messaging
- Infrastructure management
Simplified network monitoring service
Storage
Things to consider
- Data structure
- How is data related to each other?
- Will the structure change over time?
- Scalability
- Volume, reads and writes
- Access patterns
- Read heavy? Write heavy?
- Consistency, Availability, Partition Tolerance



Storage: S3
- Data structure
- Stores objects (files)
- Can also store pictures and static websites
- Scalability
- Serverless
- High latency - double digit milliseconds
- Can store large objects (up to 5TB)
- ~5500 writes p/s, ~3500 reads p/s on a bucket
- Access patterns
- Global service, global bucket names
- Not a file system! Even if it looks like one
- Read after write consistency

Storage: DynamoDB
- Data structure
- Stores data (document store, JSON)
- Semi-structured, schema-less
- No explicit relationships
- Primary key: partition key (ID), sort key (timestamp)
- Scalability
- Serverless
- Low latency - single digit millisecond
- Small objects (up to 400KB)
- Can scale on demand
- Easily > 40k reads and writes per second

- Access patterns
- Search: query, scan
- You need to know how you are going to search
- DDB not great to search by random attributes
- Secondary indexes
- LSI - same PK, different SK
- GSI - different view of the data
- Pick a new primary key (PK and SK)
- Can have up to 20
- Consistency, Availability, Partition Tolerance
- Global tables, streams
Storage: DynamoDB
Storage: RDS
- Data structure
- Stores structured data
- Strong relationships
- DB as a service: MySQL, PostgreSQL, Aurora, etc
- Scalability
- Not serverless, unless you use Aurora serverless
- Example: bring DB down for updates
- Scales a lot less than DynamoDB
- Access patterns
- Opinion: only strong benefit is ability to write random queries
Highly discouraged to use RDS

Storage: Comparison
|
Criteria |
S3 |
DynamoDB |
RDS |
|---|---|---|---|
| Access speed | ✅ | ✅ ✅ | ✅ |
| Large objects | ✅ | ❌ | ❌ |
| Number of objects | ✅ | ✅ | ❌ |
| Schema changes | ✅ | ✅ | ✅ ❌ |
| Searchability | ❌ | ✅ | ✅ ✅ |
| Relational | ❌ | ❌ | ✅ |
Compute
Things to consider
- Invocation patterns
- Reacts to events or runs permanently?
- How long do actions take?
- Scalability
- Scale horizontally (multiple instances)
- Scale vertically (bigger instances)
- Overhead
- How much work do I need to keep it running?



Compute: EC2
- Invocation patterns
- In a nutshell, it is a VM. Runs permanently.
- Connect it to a VPC
- Scalability
- Scale horizontally (multiple instances)
- You choose specific instance sizes
- Overhead
- Conceptually very simple
- It is your responsibility to keep it up to date

- Invocation patterns
- Container: you describe the environment
- Has a concept of tasks (container, roles and VPC)
- Has 2 modes: EC2 and Fargate
Compute: ECS
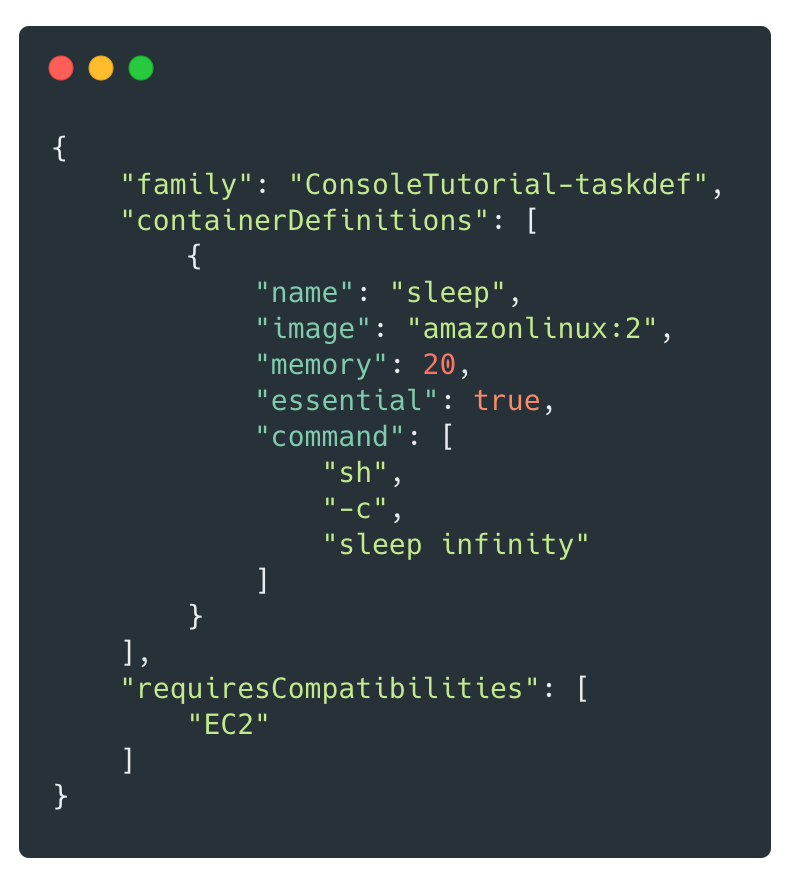
- Scalability
- Scale horizontally by starting more instances (Fargate does it for you)
- Scale vertically by changing container descriptor
- Overhead
- Conceptually more complex because you need to understand containers
- Less effort to maintain than EC2
- You can run the same Docker container locally
Also similar offering: EKS (Elastic Kubernetes Service)
Compute: ECS
Compute: Lambda

- Invocation patterns
- Fully serverless
- You bring code and AWS runs if for you
- Define triggers
- Scalability
- Scales horizontally automatically up to 1000
- Scales vertically by choosing available RAM
- Need to be careful with limitations
- Overhead
- Conceptually very simple
- Need to update runtime once in a while
- Uploading dependencies can be painful
Limitations
- Max 15 min execution
- Max 10 GB of RAM
- You do not specify CPU, depends on memory
- If you want an API, you will need API Gateway
- ZIP file cannot be larger than 50MB or 250MB unpacked
- Example: RIP v1 uses a huge JSON file. Too big to upload. Need to use RIP v2
- Cold start latency
Compute: Lambda
Compute: Comparison
|
Criteria |
EC2 |
ECS |
Lambda |
|---|---|---|---|
| Scalabity | ✅ | ✅ | ✅ |
| Invocation | ✅ | ✅ ✅ | ✅ ✅ |
| Simplicity | ✅ | ❌ | ✅ |
| Overhead | ❌ | ✅ | ✅ |
| Limitations | ✅ | ✅ | ❌ |
My opinion: use Lambda unless you can't
Messaging: SQS


- Producer adds messages to a queue
- Consumer reads messages from the queue
- Good pattern for distributing work asynchronously
- Messages up to 256KB
- Can store unlimited messages. Max retention 14 days
| Standard | FIFO |
|---|---|
| No guaranteed order | Ordered |
| Possible duplicates | No duplicates |
| 3000 messages per second | 300 messages per second |
| 120k inflight messages | 20k inflight messages |
Messaging: SNS
- Producer adds messages to a topic
- Consumer reads messages from the topic (subscribes)
- Consumer completely unaware of the producer
- Potentially multiple consumers
- Messages have attributes and you can filter
- Great for decoupling services
- Limit on max messages per second depends on the region


Messaging: Kinesis
- There are multiple flavours of Kinesis (data stream, video stream, firehose and analytics)
- Common use case: telemetry
- Low latency, guarantees in-order delivery
- Supports replaying and multiple consumers
- A stream is made of shards
- Each shard supports 1MB/s ingest, 2MB/s egress
- Determined by partition key
- Retention up to 7 days


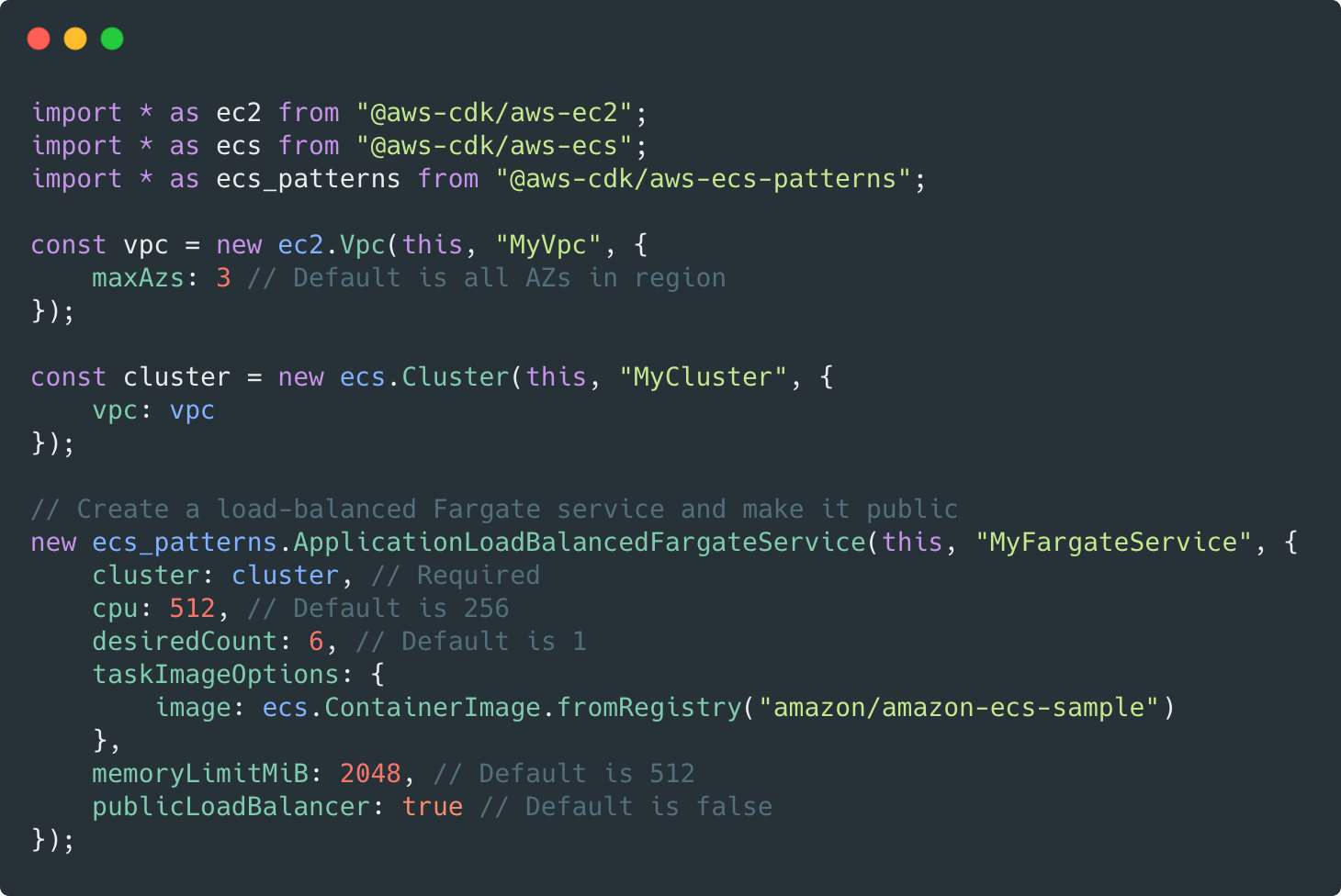
Infrastructure as code
CDK
Other services worth mentioning
-
IAM
- Users, roles, permissions
-
CloudWatch
- Logs, metrics, alarms
-
EventBridge
- Rules-based messaging service
Feedback
In chat
Thank you!
Native AWS Services - Network Code Tech talks
By diegocard




