How Machines Learn
Reinforcement Learning (rewards, games, and agents)
Sources
Hello, my project is reinforcement learning in computers. I am going to take Computer Learning and make it accessible and understandable for everyone in this room.
I will take the mathematical frameworks like the Value and Reward functions and hopefully, even if you don't completely understand them, make them more accessible and easier to deal with.
Hopefully, this presentation will show you how similar we are to your average computer.
Reinforcement Learning in Computers
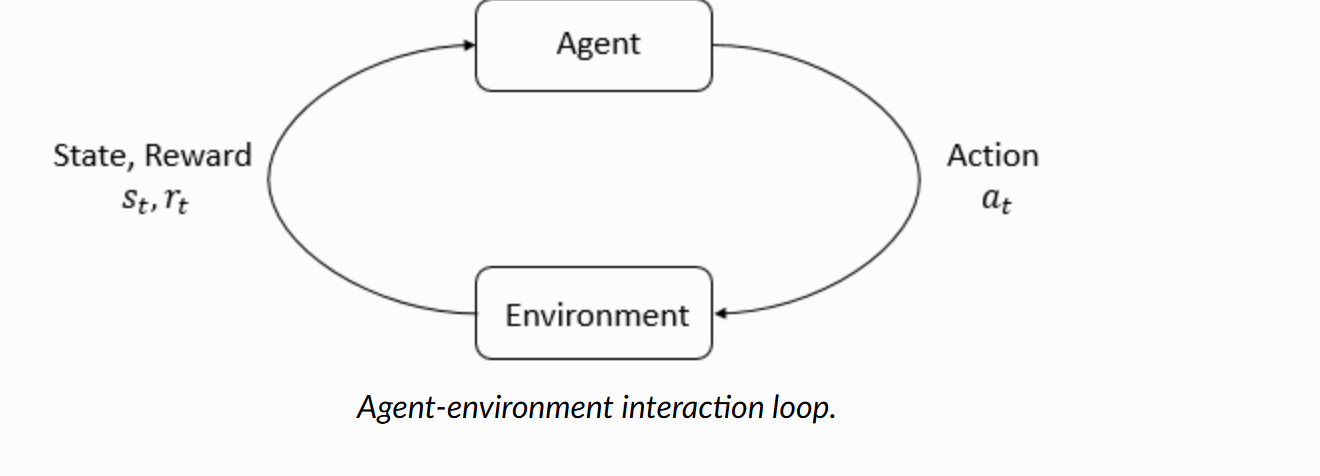
The Environment is the world around the learning entity, with both rewards and punishments
Every moment, the agent sees the environment and decides what action to take. The environment gives feedback in terms of a reward signal, and the goal of the agent is to maximize this signal.

Take this teenager, Greg.
He wants to figure out how to maximize his quality of life in high school.
To do this, he has to balance grades, his social life, and his sleep.
These narrative slides are great.
- Dan
Greg's first action is to get really good grades. As a freshman in high school, Greg has a 4.0 and A's in all his classes.

But, something doesn't feel right. Greg hasn't seen his friends much since school started. The work doesn't seem worth it if he has no time away from it.
So, Greg flips a switch. His sophomore year of high school, he stops worrying so much about his grades.

He parties every weekend, stays up all night, and has the time of his life. But his grades plummet. His parents are angry at him, and his dreams of getting into a good school get farther away every day.

Greg now wants to have both. The solution? Less sleep.
Greg reasons that if he cuts down his sleep, he can go out, then come home and study, and he would have the best of both worlds.

So, Greg starts to experiment with different systems. More sleep and less party, more study and less sleep, until he lands on the best one.
Study for 3 hours every weeknight, and go out every weekend night. And make sure to get 8 hours each night.
Gridworld in Relation to Greg
Greg's Math Project
Greg wants to model his struggles mathematically for his final project.
His whole environment he calls a State, and each time he experimented with a different sleep-fun-work cycle was an observation about this environment.

The steps Greg is able to take to change his situation (more or less sleep, etc.) are the action space of his given environment. It dictates what Greg can or cannot do in his environment.
The Reward Function
He decides to model his feeling of life satisfaction as a function of the environment and the action taken.
The function depends on the the current and future state of the environment, and the action taken between the two. For Greg to correctly model himself, he needs to try and maximize this function.
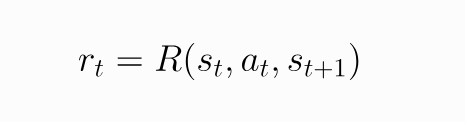
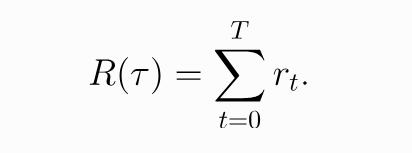
One possible return from this function is called the Finite Horizon Undiscounted Return, and this models the amount of reward (satisfaction) that Greg gets after a certain number of steps.
The steps taken by Greg can be modeled as a "Value Function". There are many different types, but all of them dictate the movement of an agent based on a policy, and how much they are allowed to stray from that policy.
The Value Function with the most freedom is the Optimal Action Value Function, and therefore the one Greg will use. (Because Greg is a human with free will).


And now Greg gets a 100 and is very happy!
Real World Applications




I hope you have gained some insight into the workings of computers. And, I hope you see that, in many ways, they are just like us.

Alec Anderson
By Dan Ryan



