Computer Vision
Alikhan Khabiyev
Resources used
- "What is a Convolution?Links to an external site."
- "CNN PlaygroundLinks to an external site."
- Convolutions SpreadsheetLinks to an external site.
- Nodes that Notice ThingsLinks to an external site.
- VISION 101 SpreadsheetLinks to an external site.
- Beyond Recognition: Representations and Adversarial Vision — "Feature VisualizationLinks to an external site.
Opening
Hey everyone. Today I want to show you something surprisingly simple: how a tiny 3×3 grid of numbers can transform a jumble of pixels into something a machine can recognize. We’ll break down what convolutions actually do, why they matter, and how they became the foundation of computer vision.
Ever seen one of these?

Select all the squares with traffic lights - to prove you're human. But the crazy part? A robot is grading your work. Yep, sometimes just a simple convolution network with nothing but a little bit of math and few filters could reliably figure out if you are a human and not a robot.
Why can't computers just see?
- Images essentially are just a HUGE pile of numbers (for computers)
- Light, angle, sizes constantly change. We can't just compare image of known object to our unknown image
- We are looking for a way to detect PATTERNS across images
This would give machine just as much information as you could gain from it
The Solution
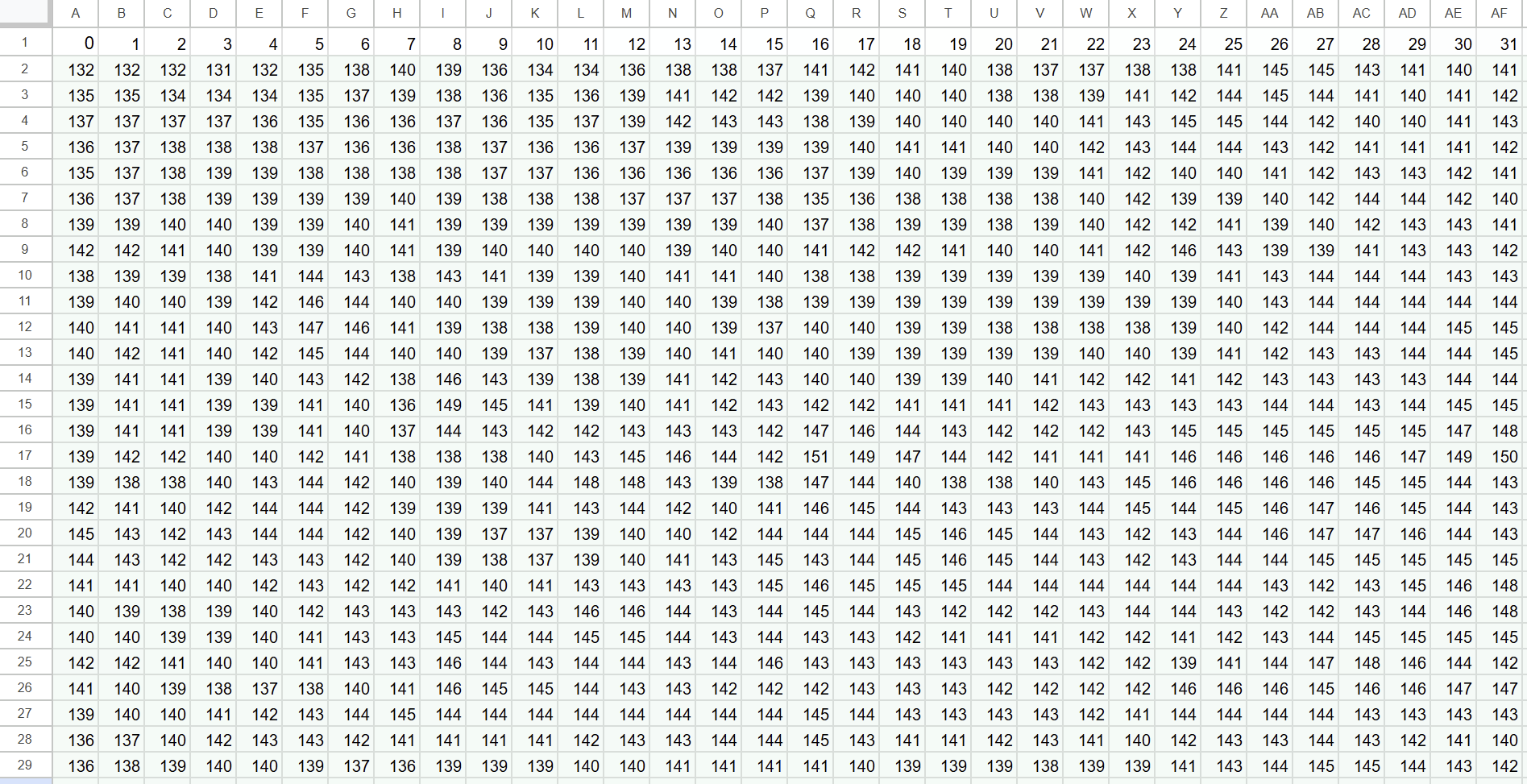
| -1 | 0 | 1 |
| -2 | 0 | 2 |
| -1 | 0 | 1 |

Convolution and Kernels
The Solution
| -1 | 0 | 1 |
| -2 | 0 | 2 |
| -1 | 0 | 1 |
Convolution and Kernels
- A kernel is a small grid of numbers that sweeps across the image.
- At each position, it compares the local pixels to a pattern and lights up wherever the match is strong.
- This example turns raw pixels into edges and meaningful features.
So, what are kernels?
We, humans, can just "see" the image - but computer can't. For a machine, it is all just complete nonsense batch of numbers, and the convolutions is its math to understanding some features

- If you were a computer and got an image, this is how you would use some of your "grids" - kernels - to make some conclusions on the image
Kernels would say:
Wait, how do kernels know if they are "seeing" what they are trained to "see"?
- Good question! Let's look at few specific examples now.
Take a guess what happens now and watch
Wait, how do kernels know if they are "seeing" what they are trained to "see"?
Take a guess what happens now and watch

1*(-1)
1*1
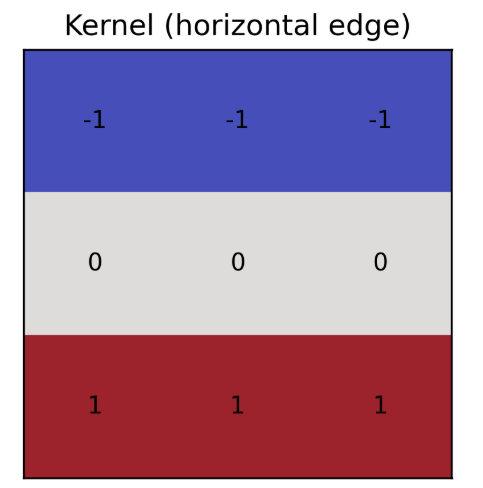
Convolution
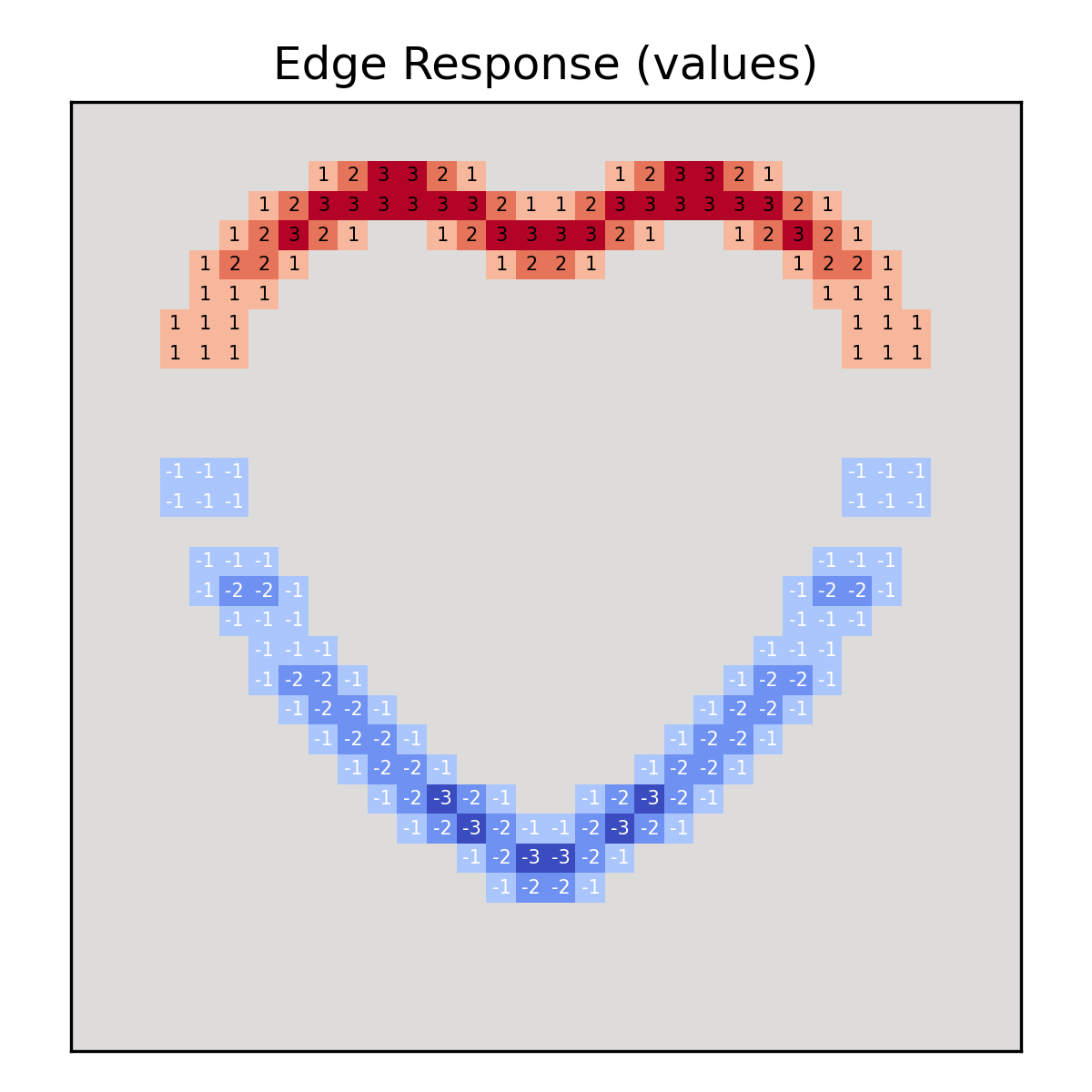
- To perform this operation, take corresponding positions and multiply by the kernel
- After all operations, sum all of the acquired product
- Put the received result into the corresponding pixel
- Here comes the result!
Wait, how do kernels know if they are "seeing" what they are trained to "see"?
Convolution
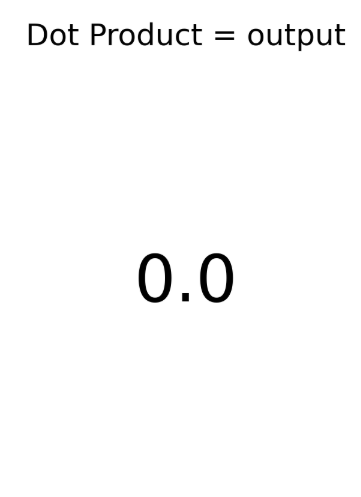
Wait, how do kernels know if they are "seeing" what they are trained to "see"?
Convolution
Wait, how do kernels know if they are "seeing" what they are trained to "see"?
Convolution
Specific values
Don't worry, you will see specific calculations in a bit
Wait, how do kernels know if they are "seeing" what they are trained to "see"?
Convolution
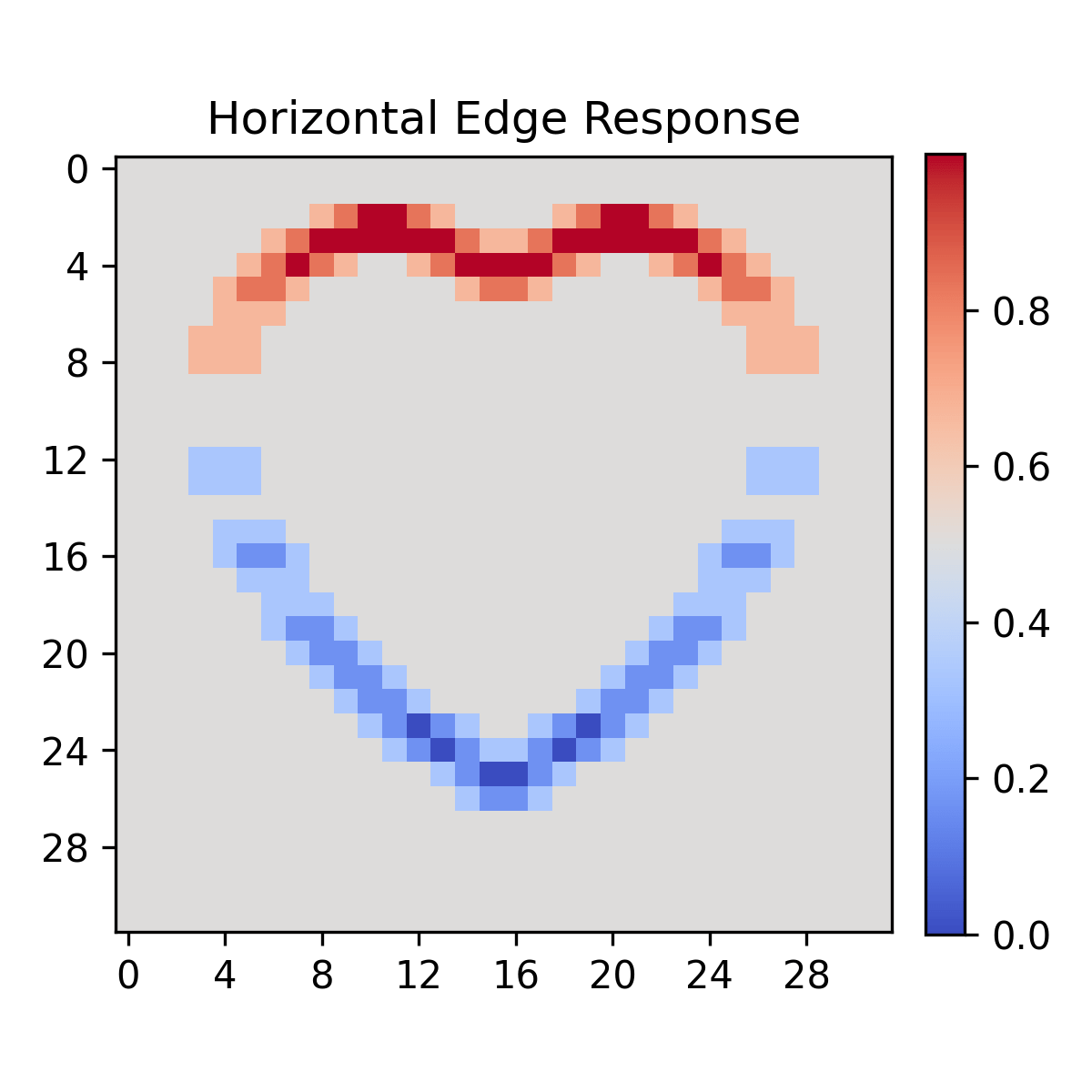
Now we can clearly see that our Netherland's flag kernel actually finds vertical EDGES
And that was just 1 kernel. Imagine if we put a whole string of those and tune them just right...
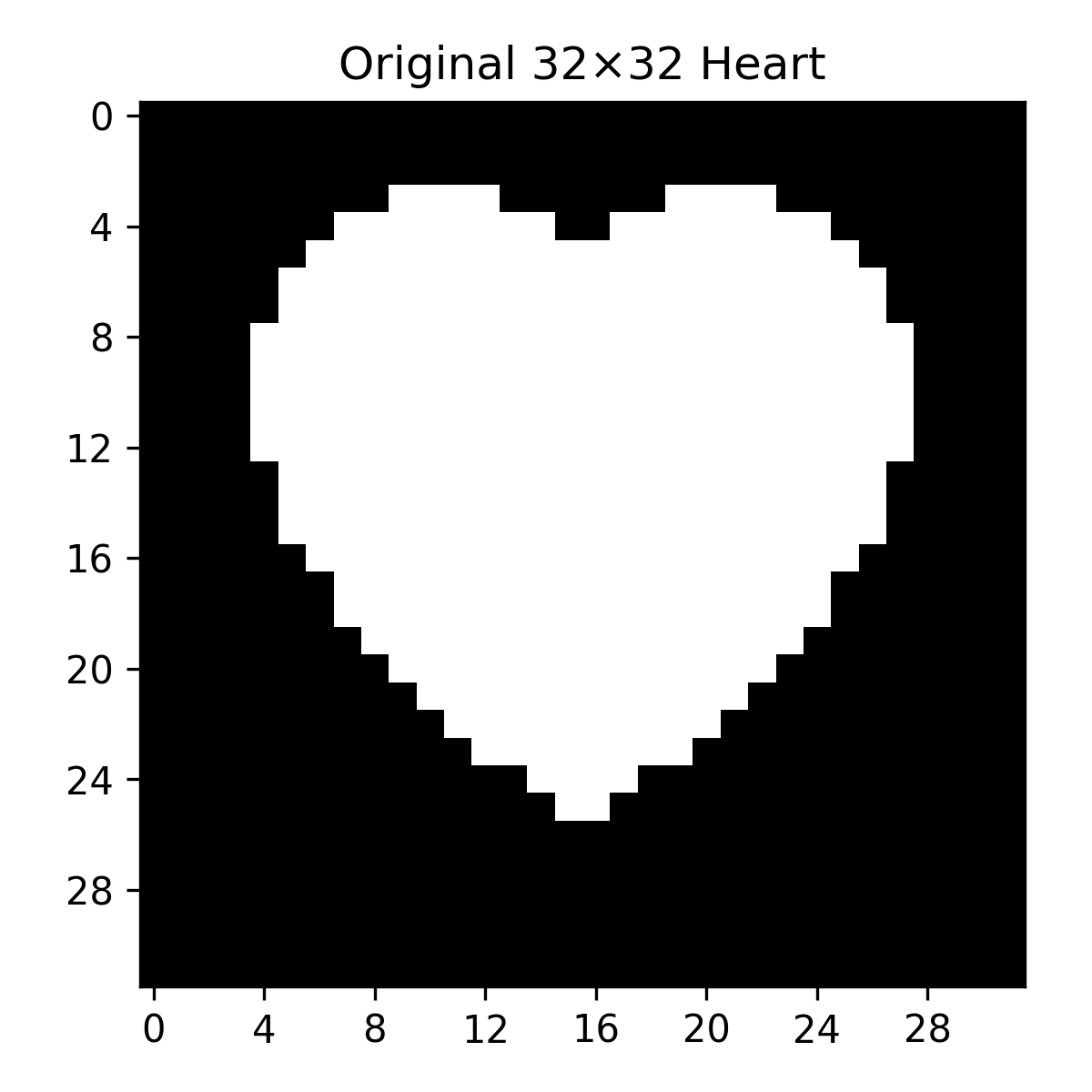
Here's example of most well-known single-kernel feature detections!
(yes, no texture heart is too simple, but otherwise it wouldn't fit into single small gif)
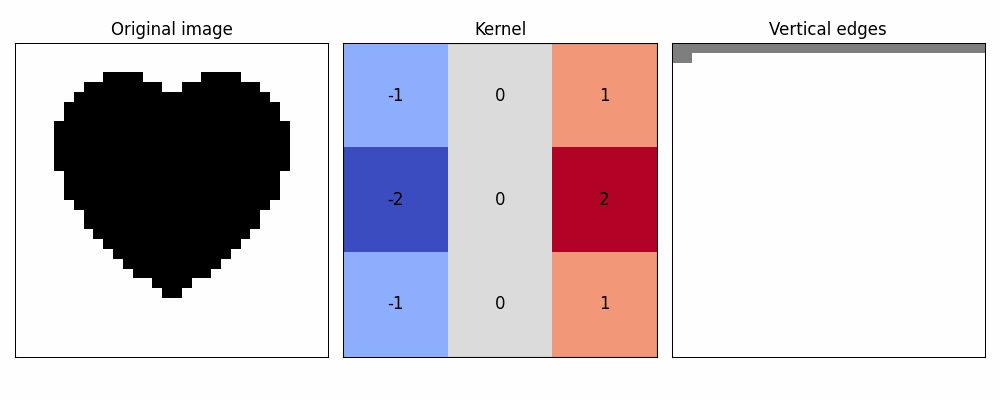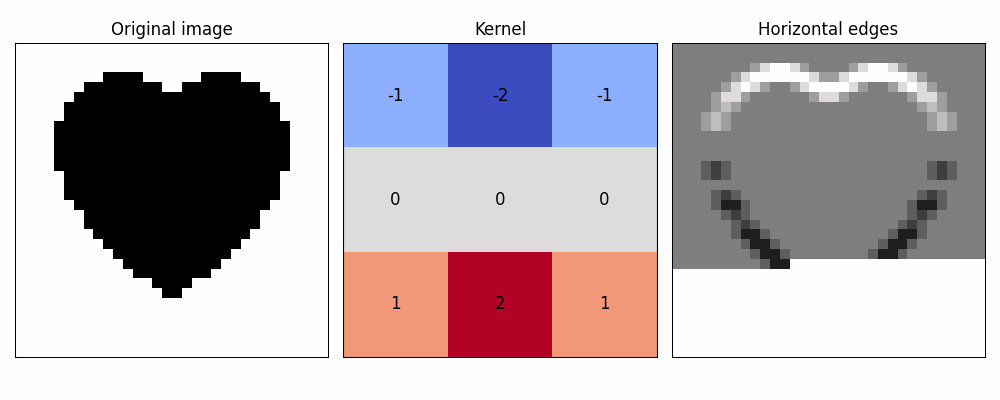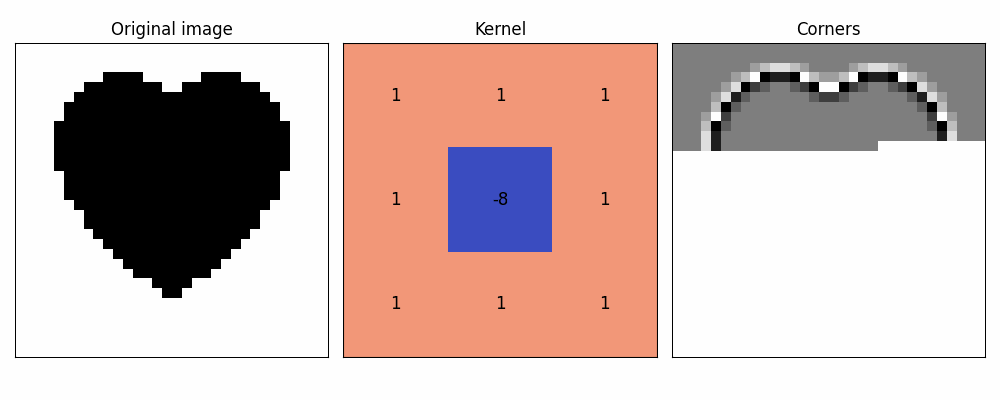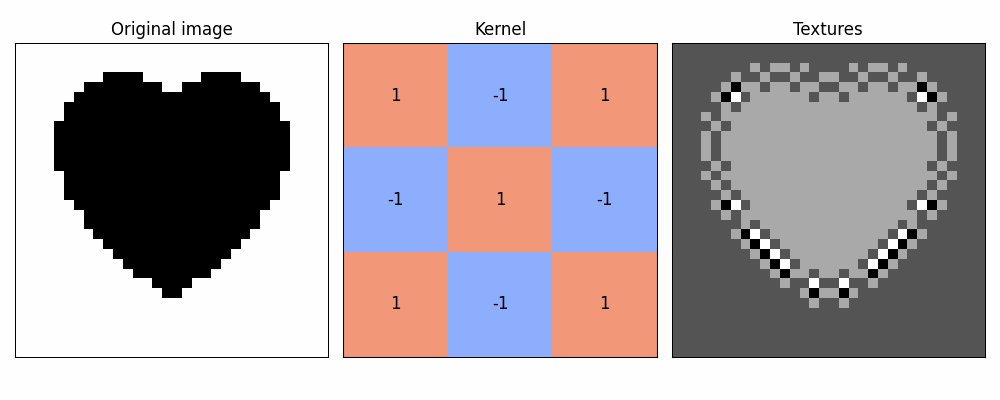
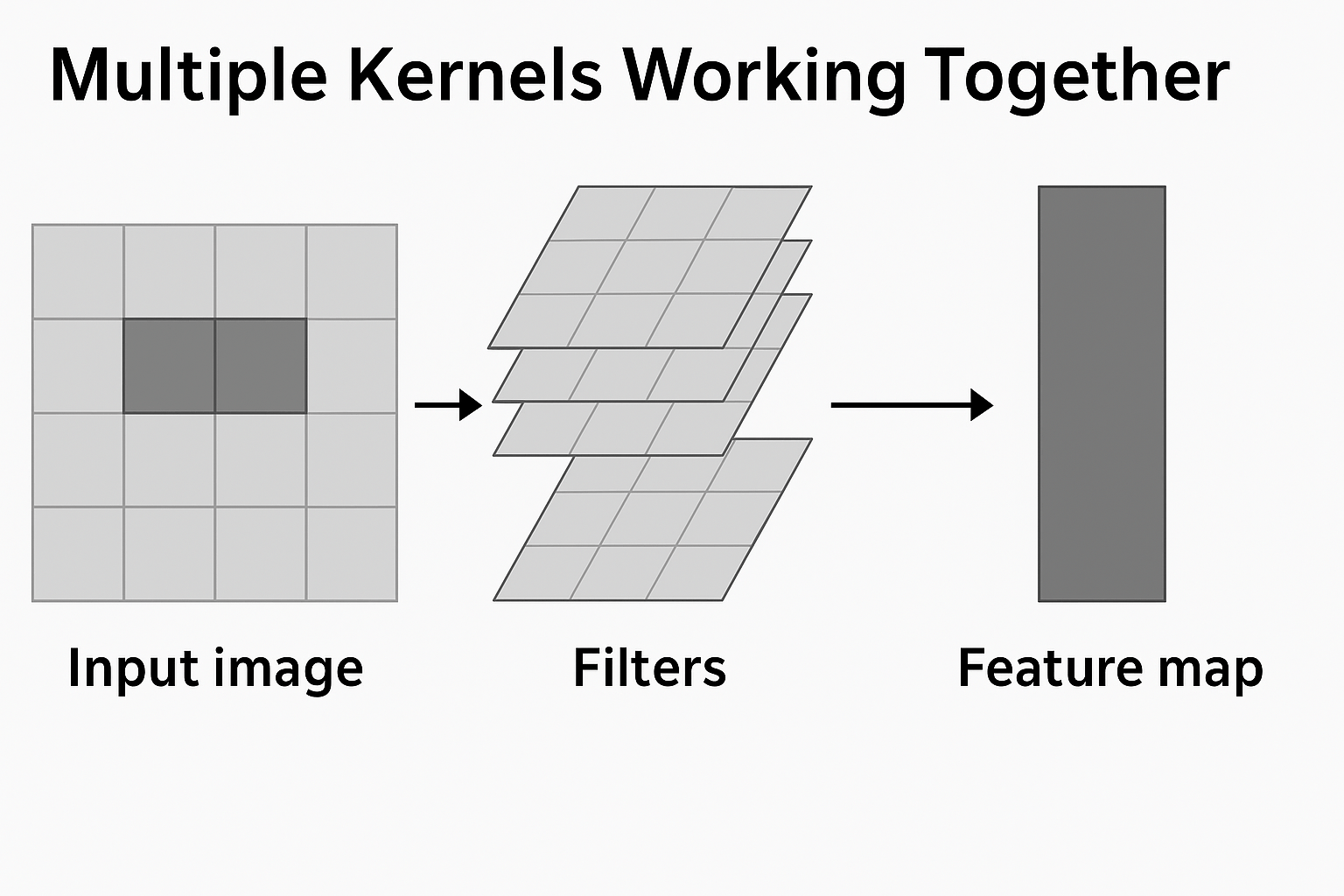
Stacking these filters on an image with a single goal in mind could help us determine concrete features
So, having a lot of these picking out the features will result in...
Stacking these filters on an image with a single goal in mind could help us determine concrete features
So, having a lot of these picking out the features will result in...
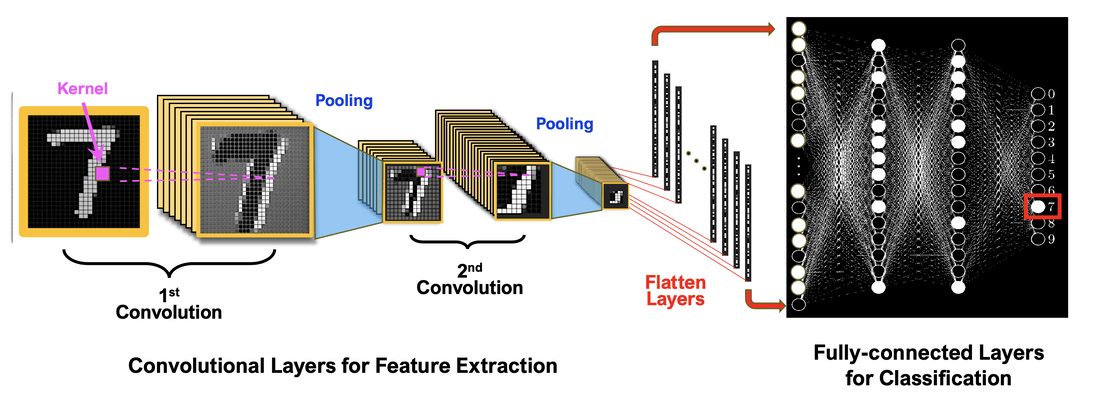
CNN
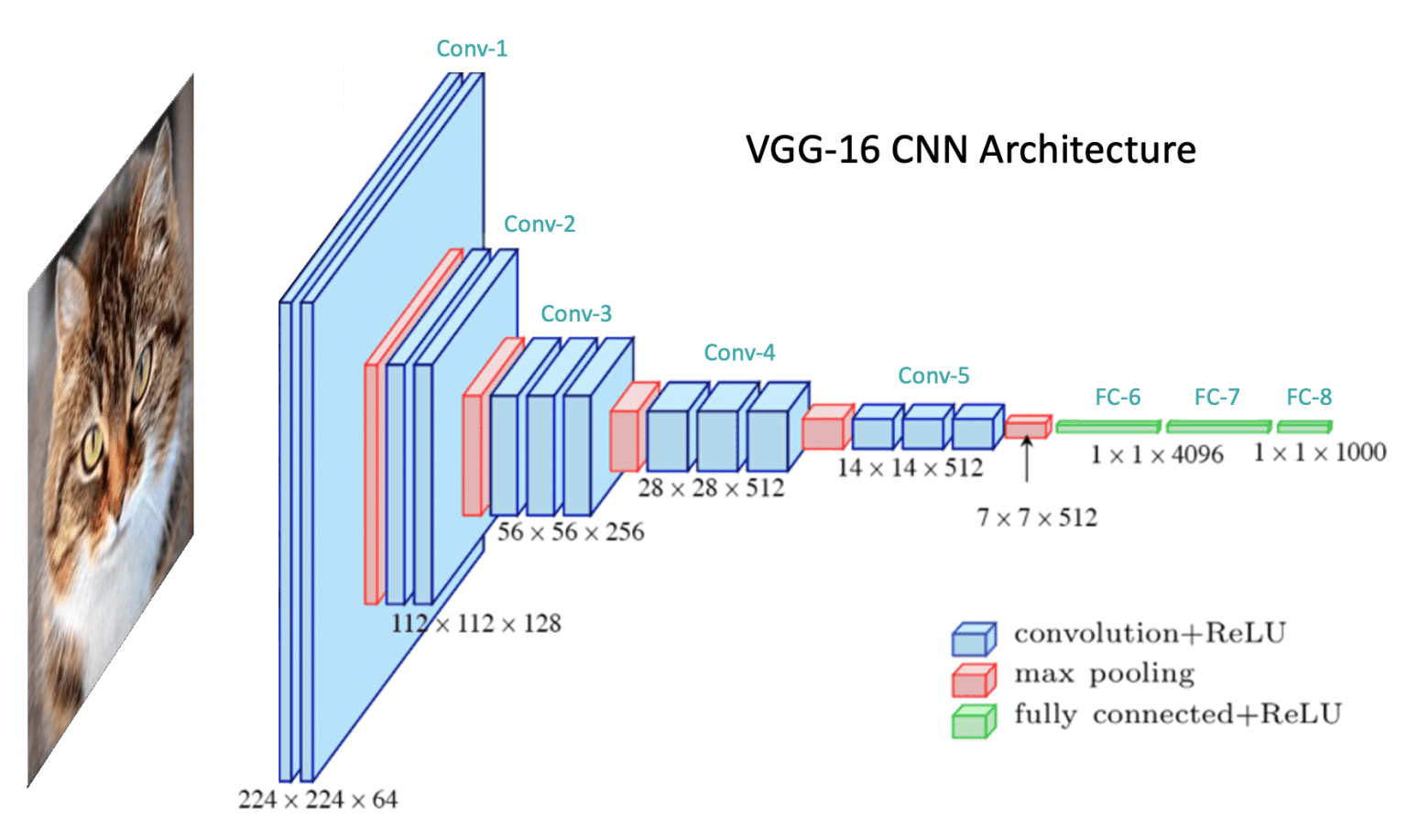
But... how do we get few thousands tuned convolutions?
- We don't! If you know the concept of machine learning of "learning" then you practically know how CNN's train. They are neural networks too!
Watch this video below:

(Author disallowed embedding :( this video is linked on the left too)
https://youtu.be/JboZfxUjLSk?si=8UH3-8nDDL1emuoq&t=30
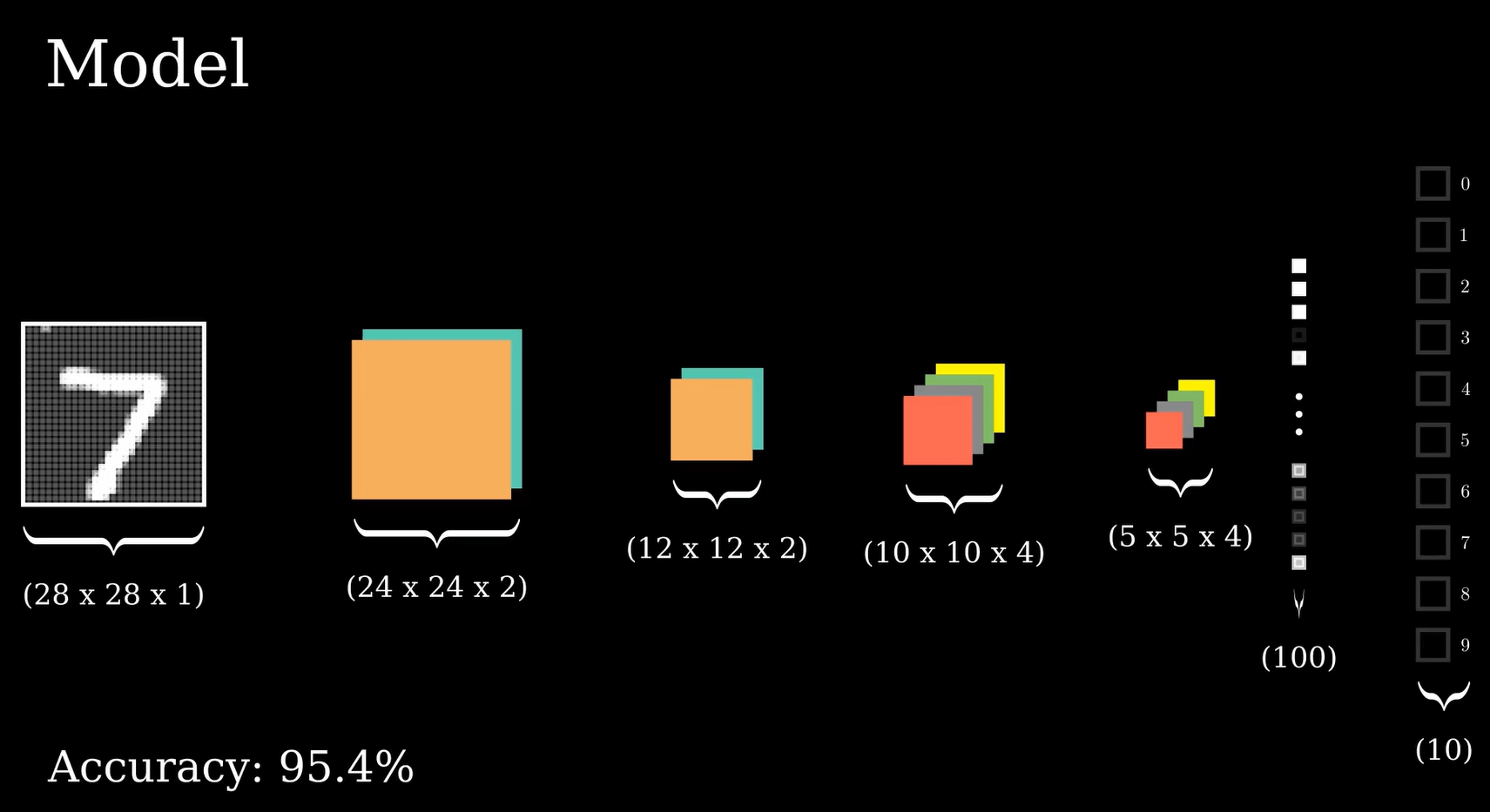
Important detail here is notice that at the end we arrive at around 100 features
Important detail here is notice that at the end we arrive at around 100 learned features
This amount of "features" are not what we could understand as humans. But to machines, these small details play a huge role in determining the correct class
Important detail here is notice that at the end we arrive at around 100 learned features
This amount of "features" are not what we could understand as humans. But to machines, these small details play a huge role in determining the correct class
This is very important:
Features that are determined here are not DESIGNED, they are LEARNED
Machine thoroughly goes through hundreds of images in the class to notice small things that are consistent for same class
After learning those possible "features", the convolutions calculate the magnitude of each feature present in image, and final decision is dependent on final feature map
See for yourself
https://poloclub.github.io/cnn-explainer/
Pull up the website above (or just look up "CNN explainer" and click first link, it should be a poloclub one)
This is an immersive visualization of how CNN work in practice and thorough detail. Spend as much time with it as you wish.

That's it!
Simple math layered over and over again can create one of the most used computer vision tools
But we have so many other neural networks... why convolution if it's so stupidly simple?
But we have so many other neural networks... why convolution if it's so stupidly simple?
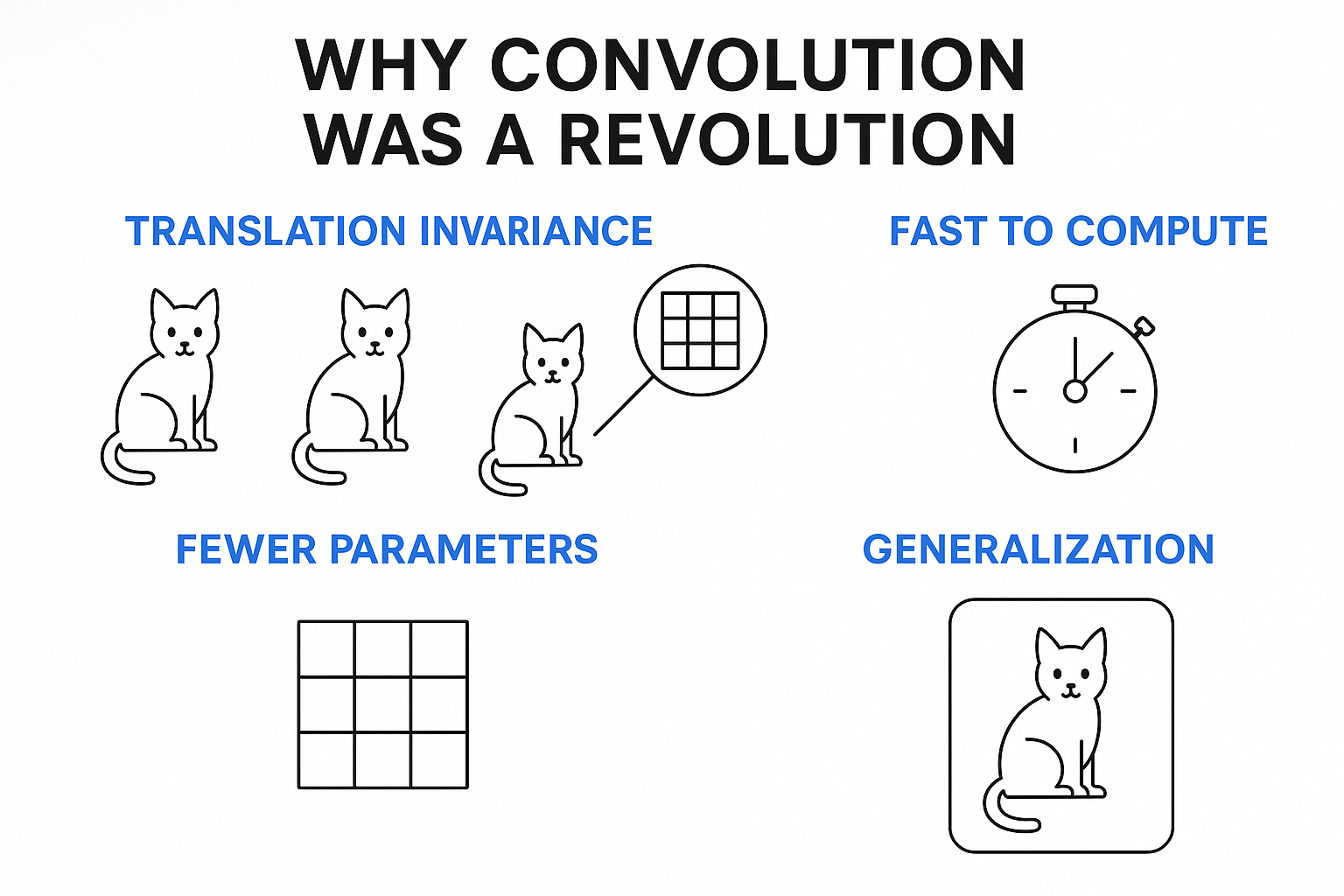
Or put simply:
- Doesn't matter where features appear
- Very light and incredibly fast to train and compute
- Far fewer parameters and less dense layers (also meaning faster training and less things to go wrong)
- Scales easily with image sizes
- Excellent generalization as in EASILY spots unseen features standing out
Woah, I wonder if those are useful...
- Of course they are! They are used SO much, I can bet you've ran into few today, yesterday, the day before and so on...
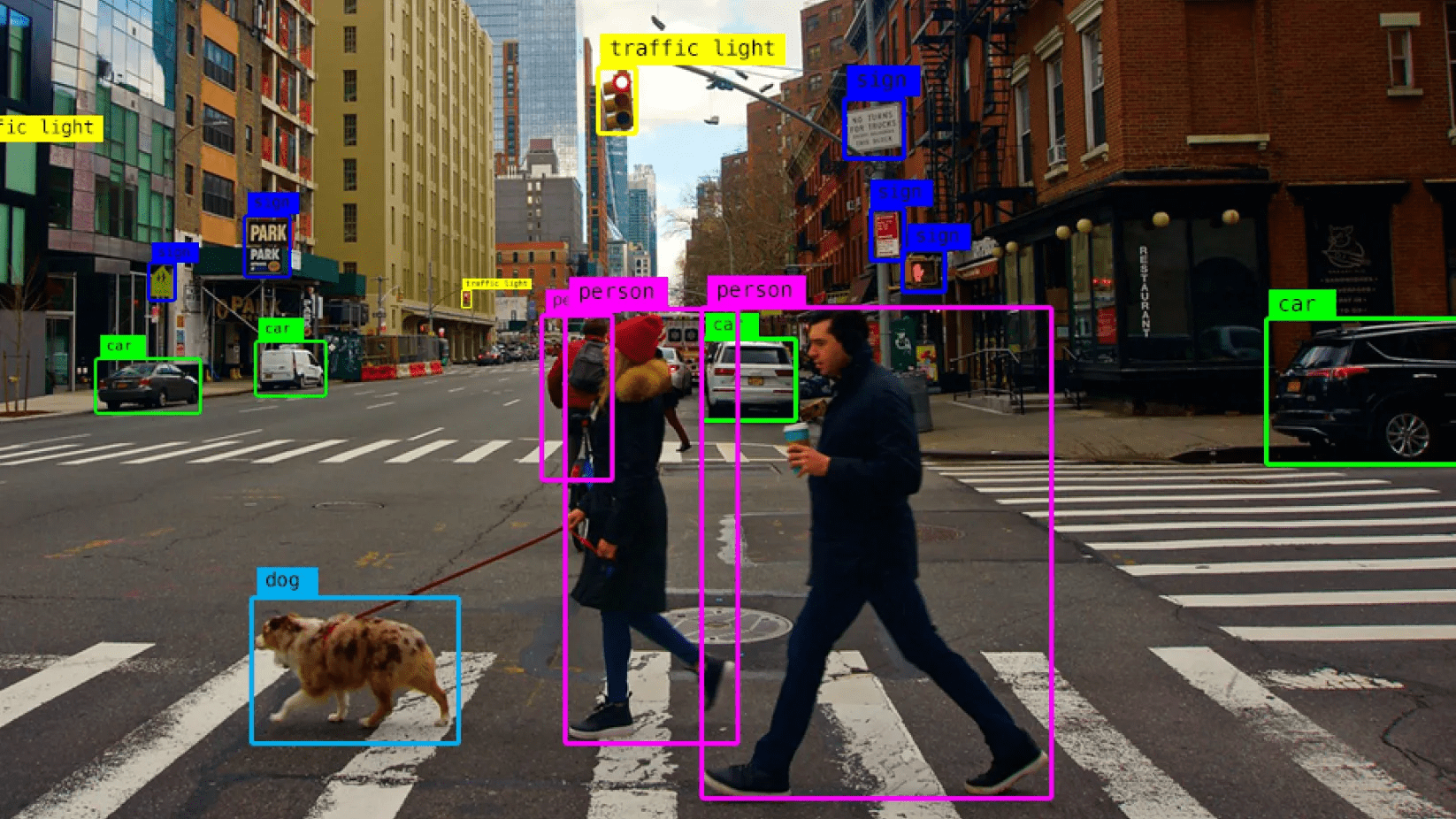
Object detection

Segmentation

Style transfer
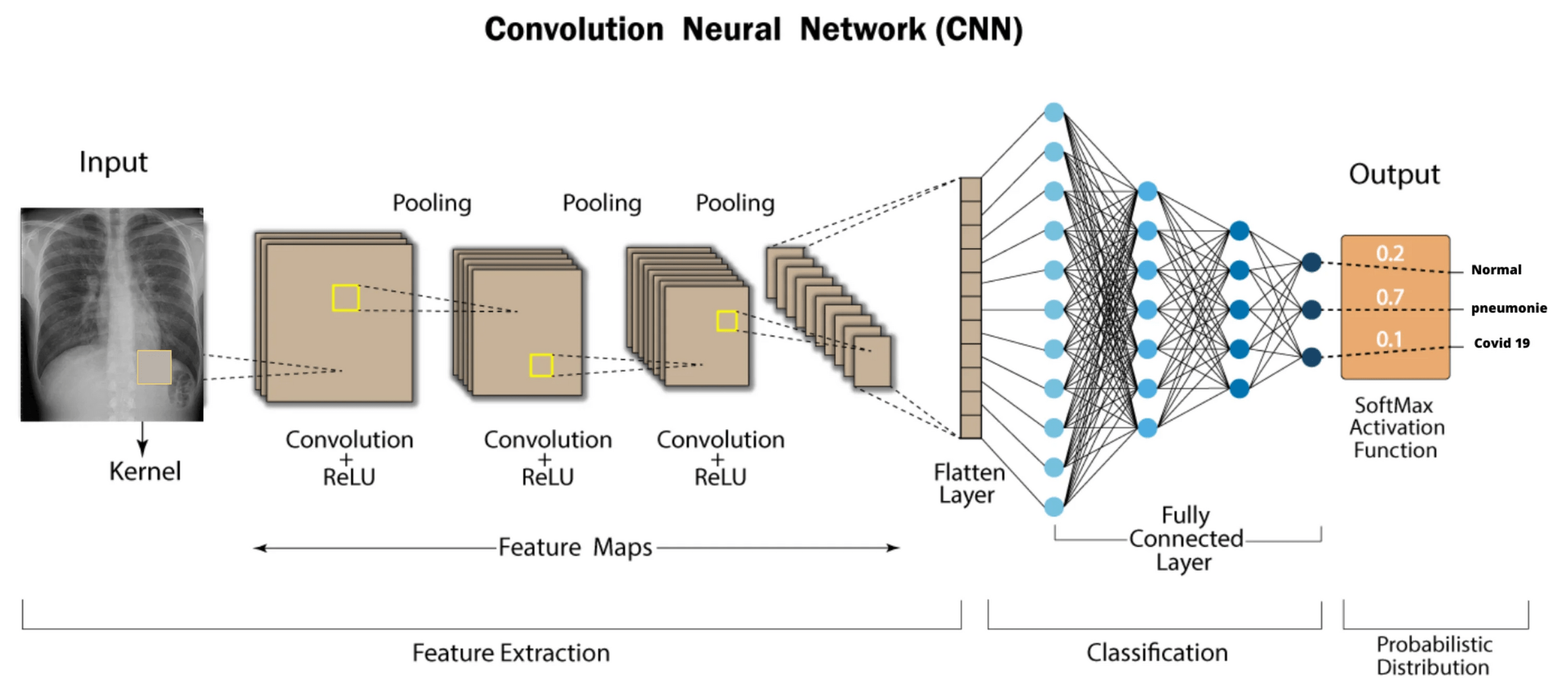
Medical imaging
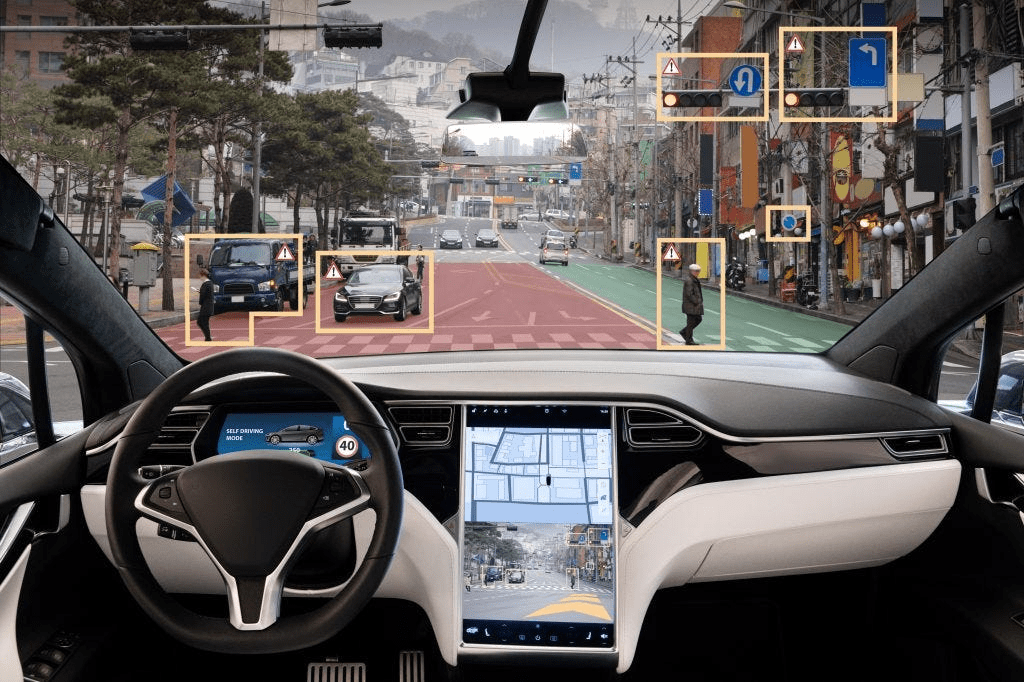
Self driving systems and cars
Woah, I wonder if those are useful...
- Of course they are! They are used SO much, I can bet you've ran into few today, yesterday, the day before and so on...
Object detection
Segmentation
Style transfer
Medical imaging
Self driving systems and cars
- You using ChatGPT to solve a problem
- "Smart" cameras and doorbells detecting people
Text
- "Blur background" in online meetings
- MOST of the social media filters
- Also tons of new "comic" or similar social media effects
- I hope this one speaks for itself
- Diagnosis and other medical applications
- Literally maps surroundings and processes visual input for routing and driving overall
- Interestingly, the visual input in driving cars works so flawlessly that this happened... ->

But there are Cons too
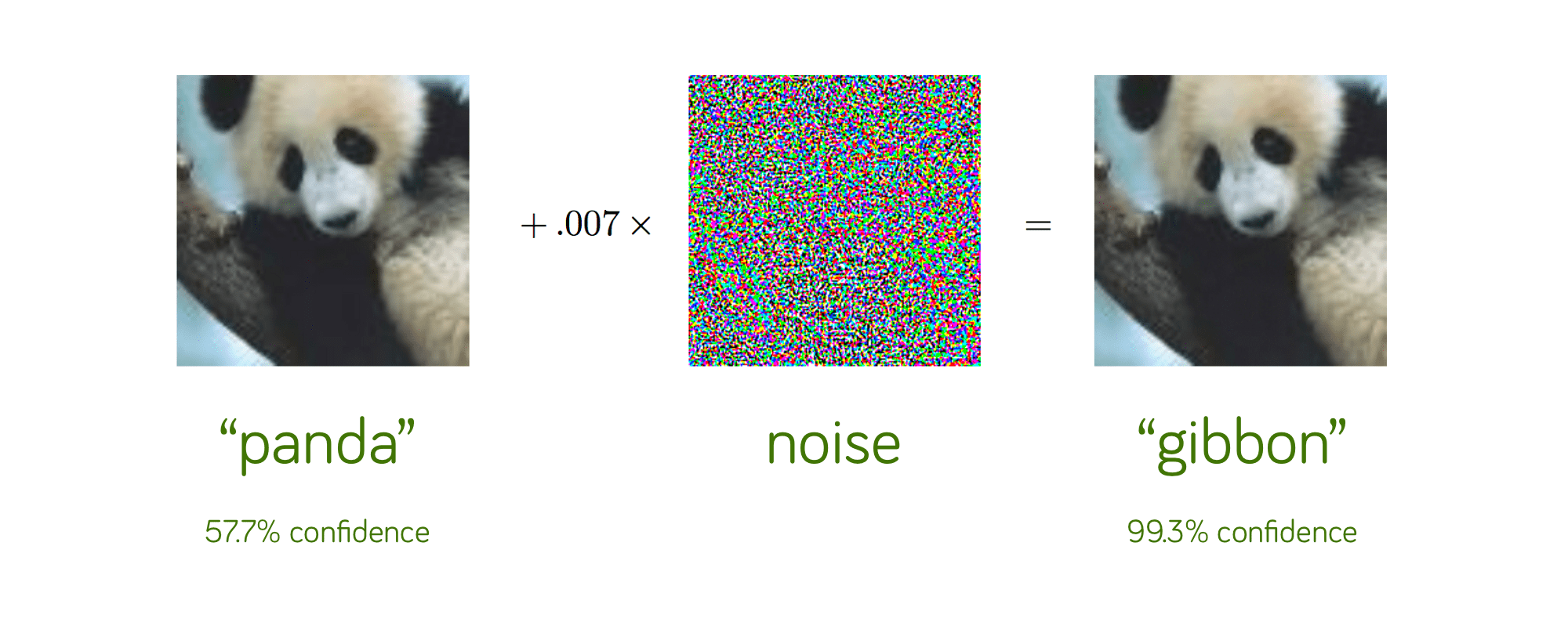
What CNNs struggle with:
-
Adversarial images
-
Small perturbations
-
Out-of-distribution objects
-
Optical illusions
-
Context understanding
Context:
The image above was released to show that due to machine perceiving pure mathematics instead of how humans do, slight variation of initial numbers by a tiny (0.007) bit ENTIRELY shifts the perspective for the CNN. This specific "panda/gibbon" incident is very famous
Conclusion
So the next time you’re clicking boxes to prove you’re human, remember:
the machine on the other end is ‘seeing’ through stacks of tiny filters - and that simple math is what makes modern vision possible.
deck
By Dan Ryan



