






























Danielle Navarro
I am a computational cognitive scientist at the University of New South Wales. My research focuses on human concept learning, reasoning and decision making.
compcogscisydney.org
d.navarro@unsw.edu.au
twitter.com/djnavarro
github.com/djnavarro
Danielle Navarro
https://slides.com/djnavarro/scienceandstatistics
Danielle Navarro
Disclaimer: This is not my usual kind of talk.
I'm not a philosopher. I'm not a statistician. I'm not even sure what "meta-science" means. I spend most of my time doing computational cognitive science research, and I'm not entirely sure why I'm here. But let's see how this goes...
Statisticians have an understandable penchant for viewing the whole of the history of science as revolving around measurement and statistical reasoning
- Stephen Stigler (1986).
Statistics is a tool that can assist scientists develop, evaluate and modify theoretical claims
An "instrumental" perspective on the role of statistics
Statistical theory provides the logic of and the rules for scientific reasoning
A "normative" perspective on the role of statistics
Statistics is a tool that can assist scientists develop, evaluate and modify theoretical claims
Statistical theory provides the logic of and the rules for scientific reasoning
I have opinions
Thomas Kuhn
"Science does not deal in all possible laboratory manipulations. Instead, it selects those relevant to the juxtaposition of a paradigm with the immediate experience that that paradigm has partially determined. As a result, scientists with different paradigms engage in different concrete laboratory manipulations"
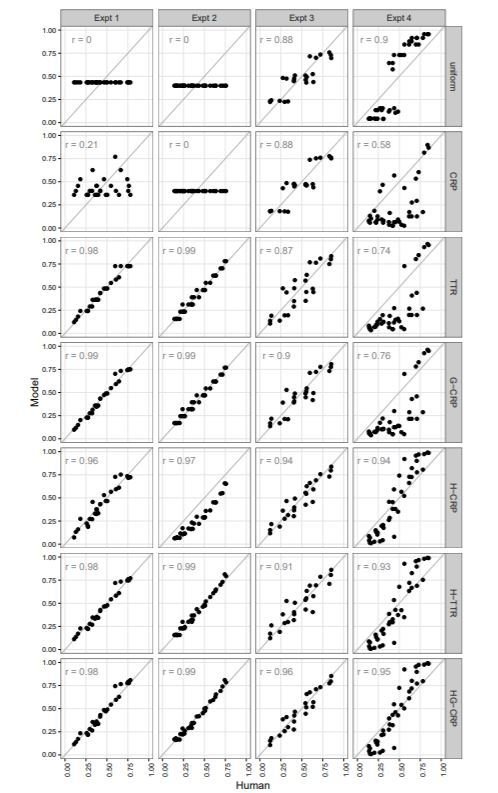
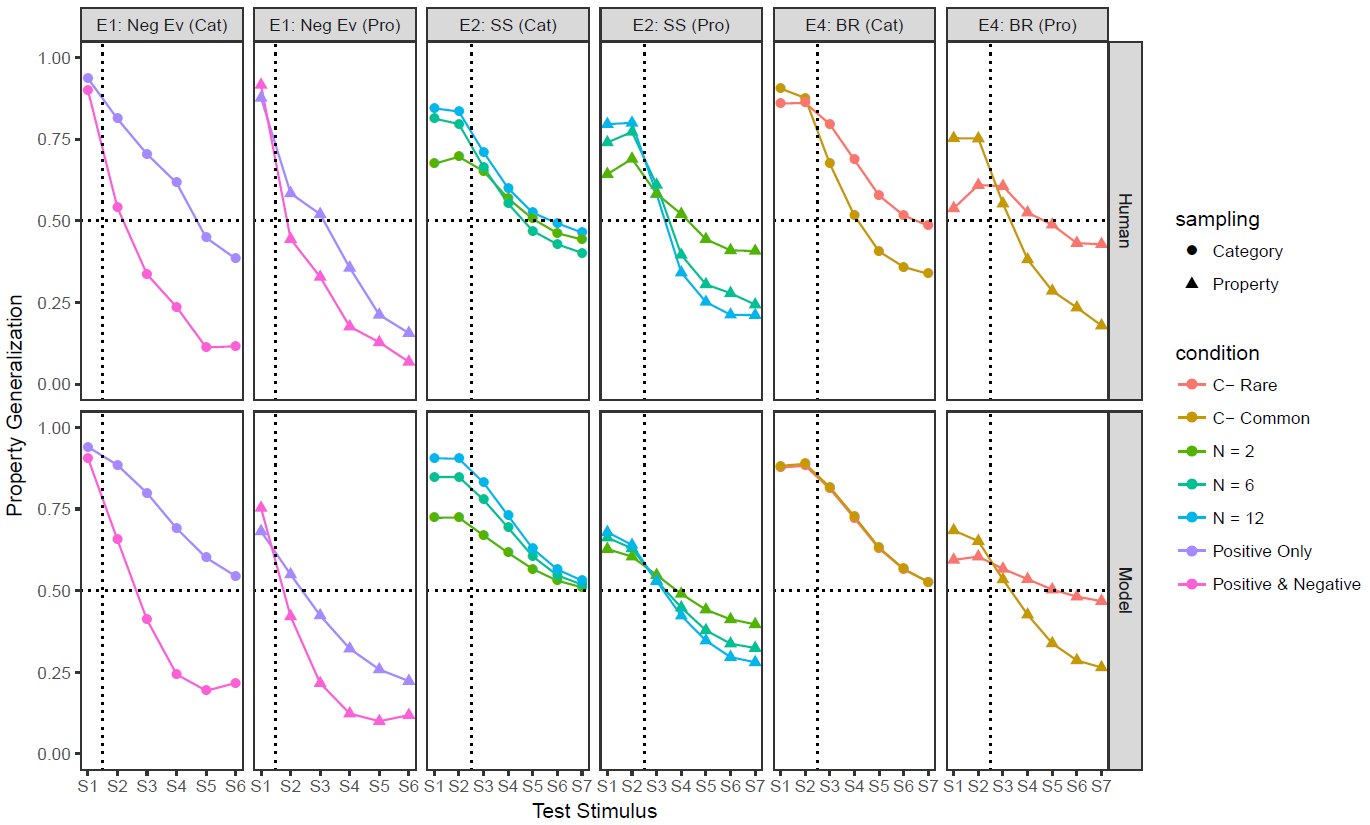
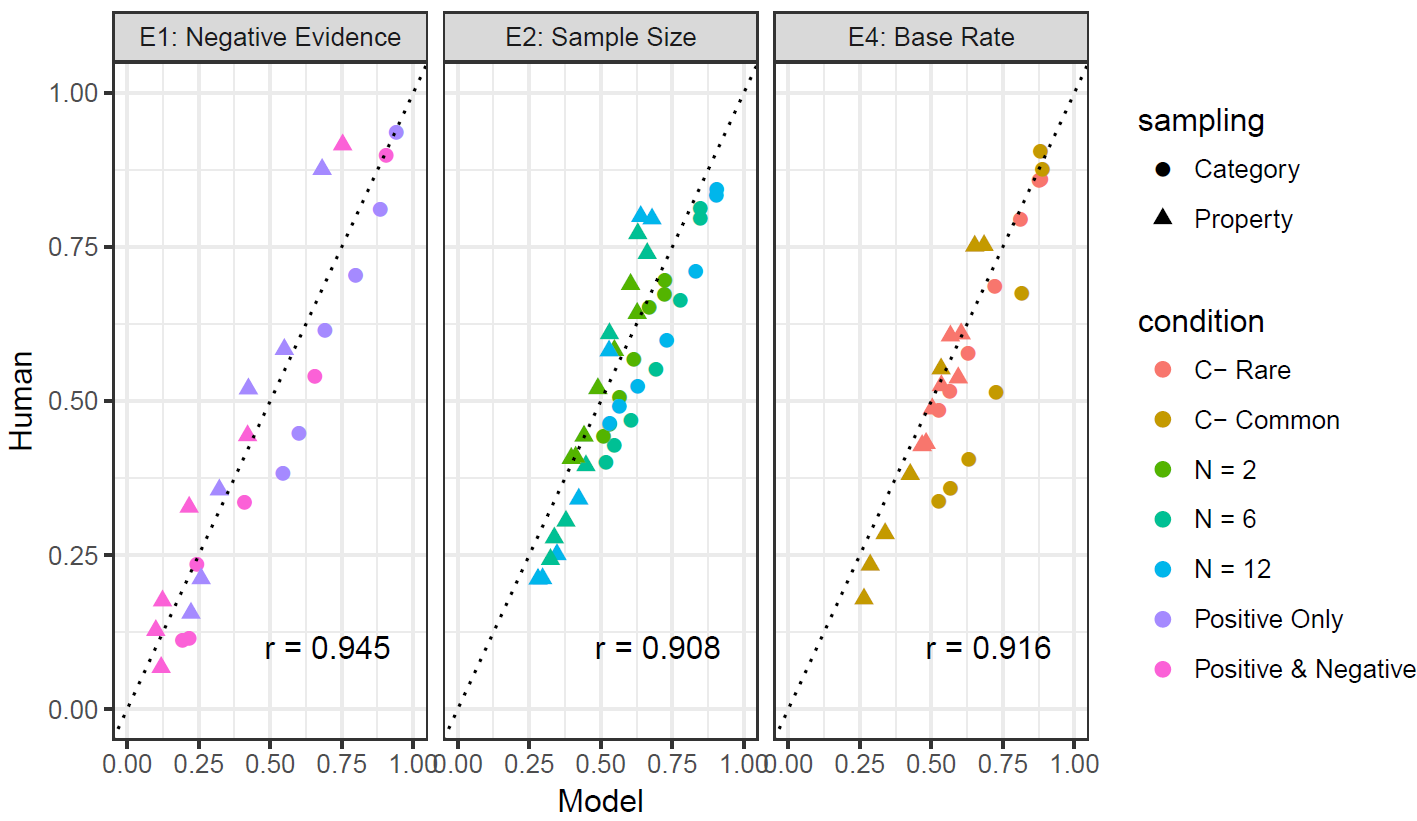
I have very clean data that discriminate between several competing computational models
What does my Bayes factor tell me about the relationship between my models and human reasoning outside of the experiment?
But I have an external validity problem... does this map onto anything in the world?
https://smallworldofwords.org/en/project/home
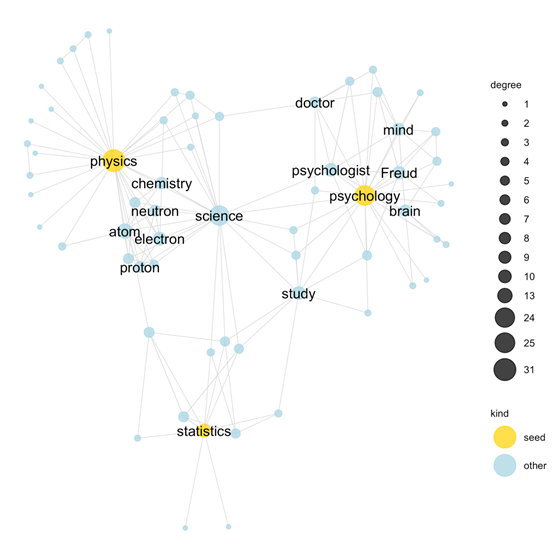
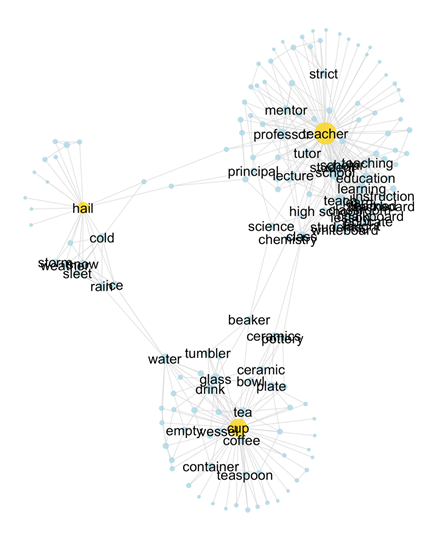
The SWOW norms contain a lot of common sense knowledge about science
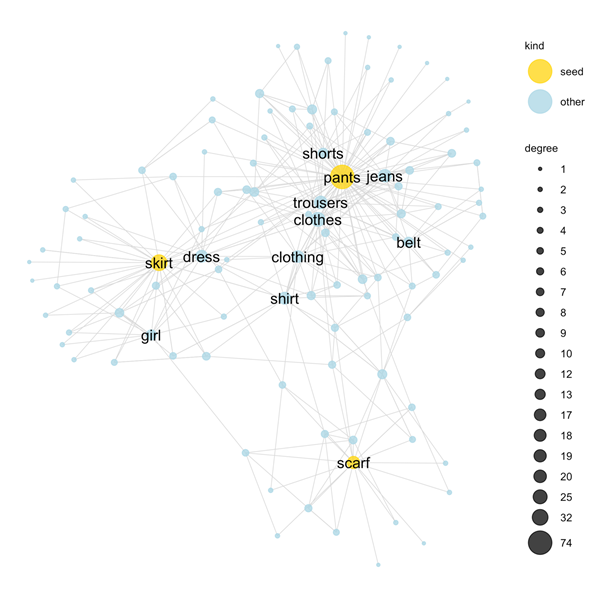
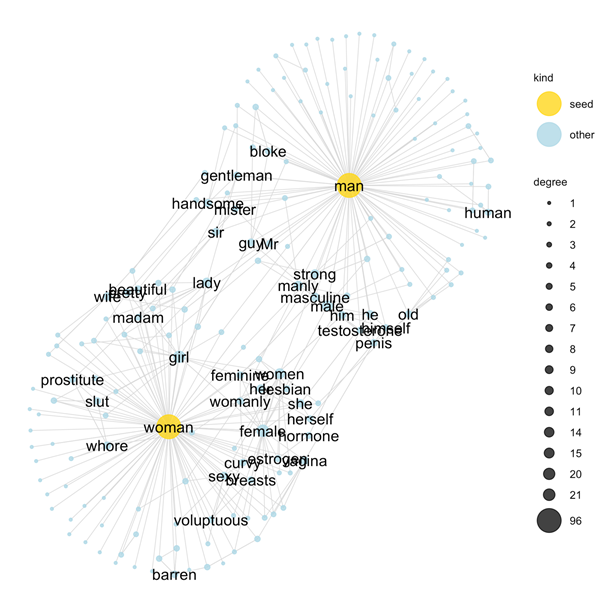
The SWOW data can provide me with many opinions about clothing
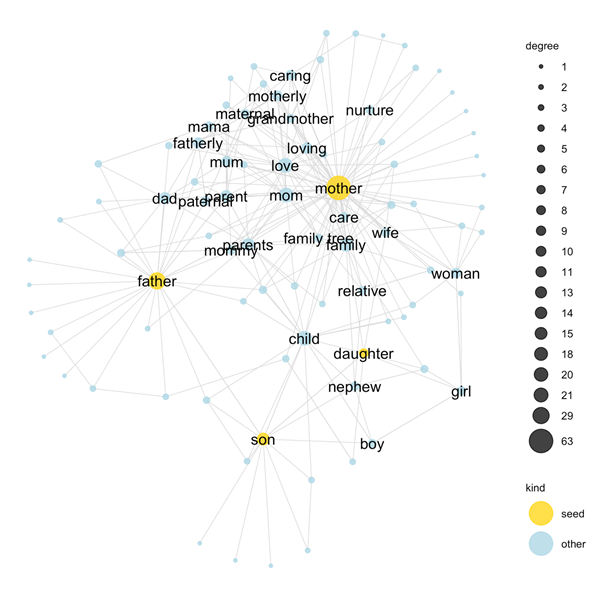
The SWOW data encodes knowledge about families are often organised
So I can use this SWOW data as a tool for explaining how people reason about natural concepts!
(De Deyne et al 2016)
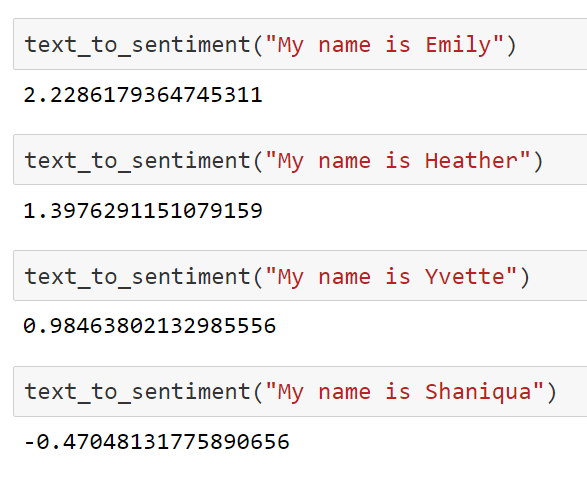
Unfortunately, the SWOW data is misogynistic ... it's "good" data, but that means is it encodes bigotry better
If I don't want sexist assumptions embedded in my data analysis I cannot take the SWOW data at face value
Well, maybe...
http://blog.conceptnet.io/posts/2017/how-to-make-a-racist-ai-without-really-trying/
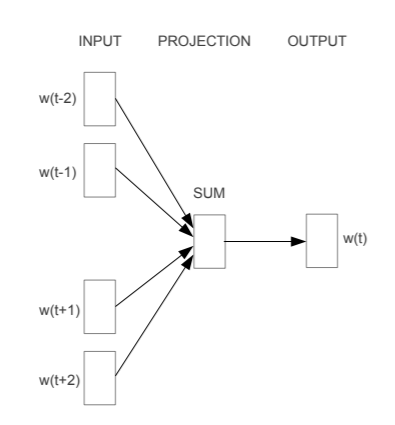
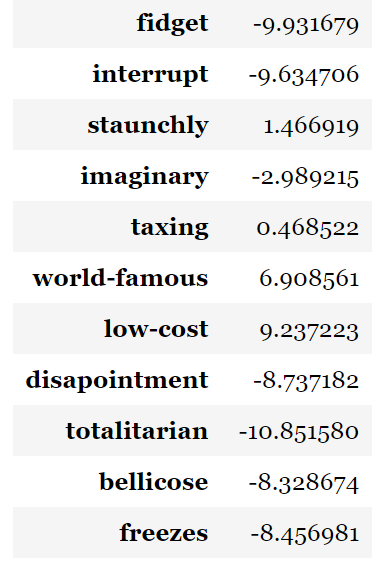
(Mikolov et al 2013)
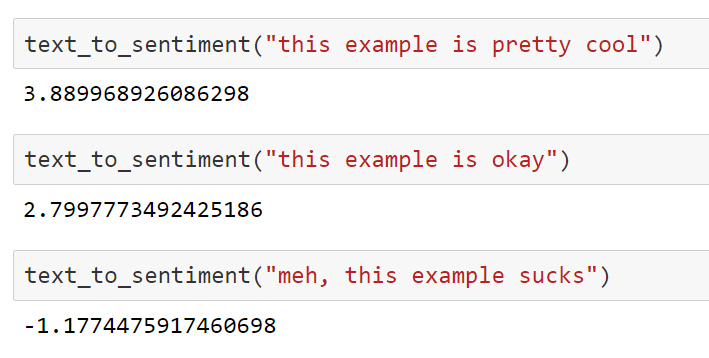
Does this matter? Using natural language to "operationally" define a measure of "sentiment"
Yeah, yeah, the model achieves 95% cross-validation accuracy, whatever...
Looking good!
For lab studies, the data analysis is only useful if you know how your operationalisation affects the way you to generalise outside the lab
... either way, the limitations to your design and your data ensure that the scientific problem you care about is more difficult than the one your statistical tools are built to solve
For naturalistic studies, the data analysis is only useful if you know which aspects of your uncontrolled data are relevant to the thing you are trying to study
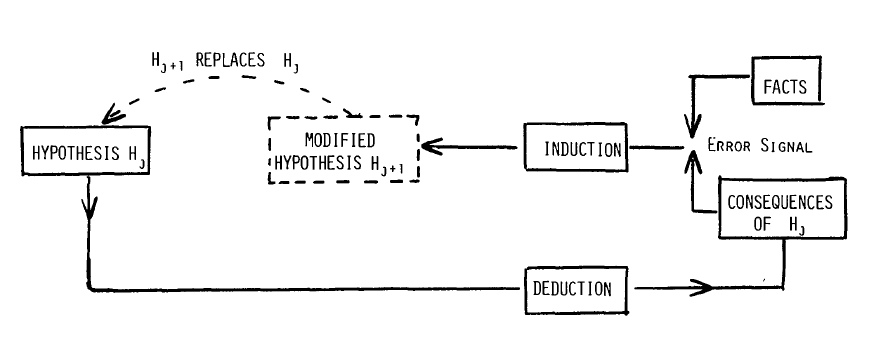
Statistical inference as I learned it in my Ph.D.
Life is too short to take p-values seriously
Bayes factors: A tool for confidently selecting the "best" "model"...
... where "best" is weird and the "models" are fantasies
Gronau and Wagenmakers (2018)
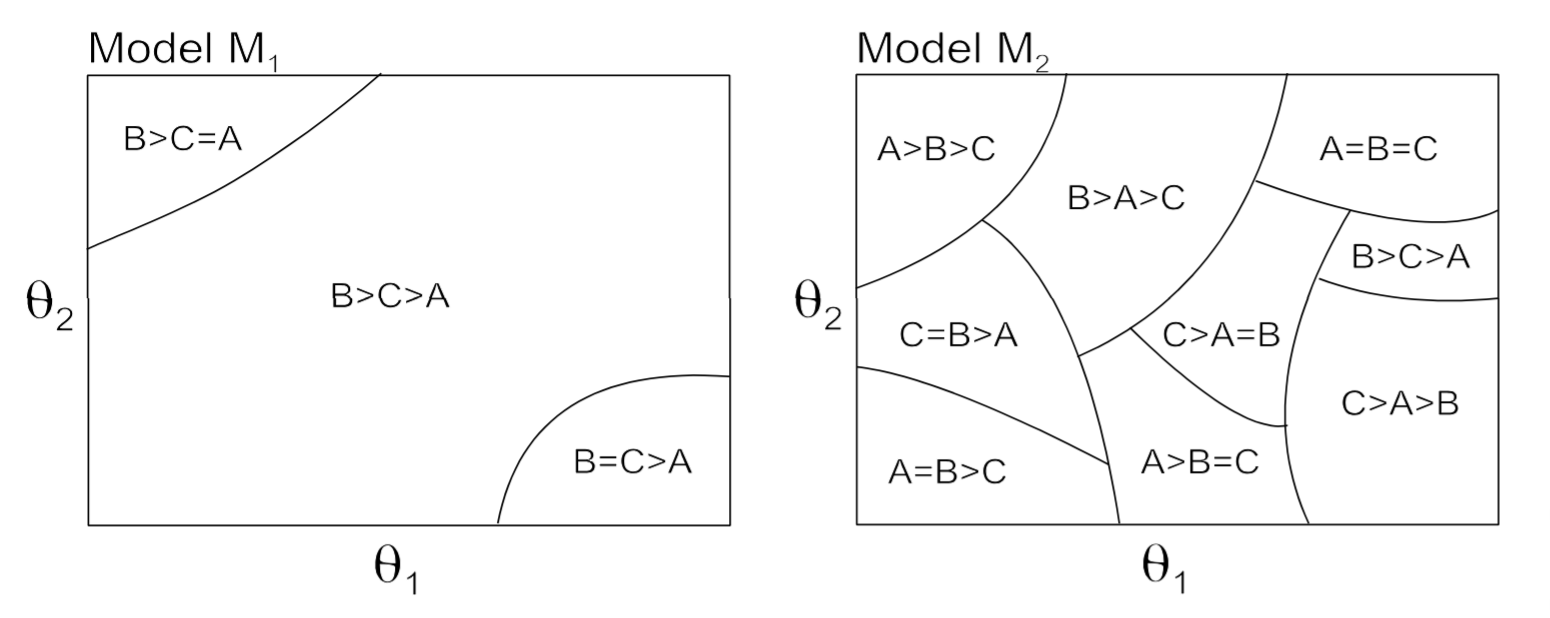
A toy problem that implicitly asserts a normative view of statistics
...which is unfortunate, because it's not in your model space
Selecting a horribly broken model with absolute confidence just because it's the "least wrong" (in KL-divergence terms) is a transparently insane inferential strategy
Everything falls apart when all your models are wrong in terrible ways
The researcher's belief (or "knowledge") about the plausible values of the model parameters.
The prior predictive P(X|M) is quite sensitive to this prior, including the parts we don't think much about, like the heaviness of the tails
The more carefully you look, the stranger things become...
image via Michael Betancourt
The more parameters in your model, the more "tail" there is. So the closer we come to having genuinely plausible models of human reasoning, the less likely it is we can write down a plausible prior for those models
Oh and also the researcher is a human being who doesn't have perfect access to their own "beliefs" or "knowledge" (remember, we're psychologists????)
Anyone care to specify a prior for this model?
One that is precise enough for a Bayes factor calculation to actually mean something?
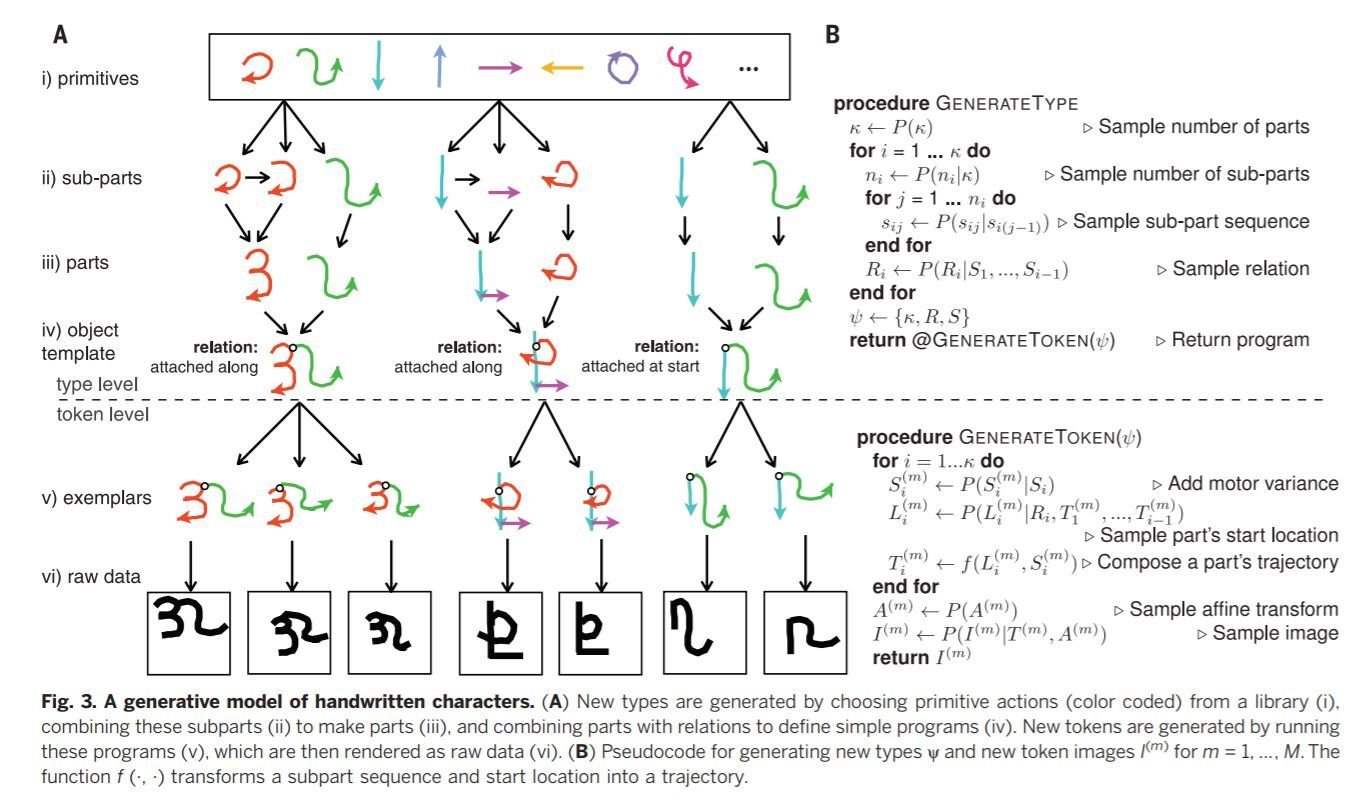
Lake et al (2015)
(in search of "pretty good" inference)
Since all models are wrong the scientist must be alert to what is importantly wrong. It is inappropriate to be concerned about mice when there are tigers abroad.
- George Box (1976)
Every statistical tool for evaluating the performance of a model has severe limitations
The data you have are likely to misrepresent the phenomenon you care about
What do we do?
Also your models are wrong and you have no idea how to write down priors for them
But I got smarter, I got harder in the nick of time
Honey, I rose up from the dead, I do it all the time
I’ve got a list of names and yours is in red, underlined
- Taylor Swift
Relying on substantive knowledge by the domain expert... What counts as a meaningful pattern in the data? To what extent is that an a priori prediction of the model?
(Pitt et al 2006)
Michael Betancourt
What problem am I trying to solve? What do I want to learn from these data by using this model?
Are there qualitative successes (and failures) that remain invariant across parameters or model instantiation?
"Statistical" perspective: we are looking to quantify a degree of agreement between model and data
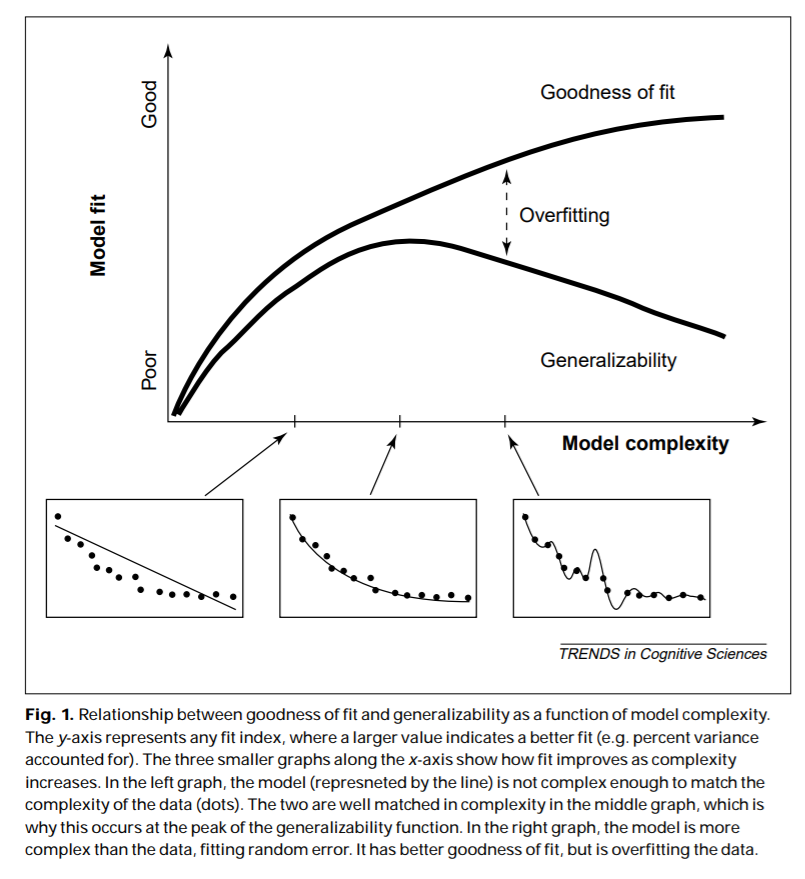
Fit looks good, but is the model overfitting???
Theoretical agreement looks good, but is the model underfitting???
Curiously, Sir Ronald Fisher's behaviour would probably be called a "questionable research practice" these days
"There are so many tools that are made for my hands
But the tide smashes all my best-laid plans to sand
And there's always someone to say it's easy for me"
- Neko Case
compcogscisydney.org
d.navarro@unsw.edu.au
twitter.com/djnavarro
github.com/djnavarro
https://slides.com/djnavarro/scienceandstatistics
By Danielle Navarro
Slides for my talk for Open Science and Reproducibility, at Aarhus University. 12 March 2019. http://interactingminds.au.dk/events/single-events/artikel/2-day-workshop-open-science-and-reproducibility/




