























Danielle Navarro
I am a computational cognitive scientist at the University of New South Wales. My research focuses on human concept learning, reasoning and decision making.
Danielle Navarro (@djnavarro)
https://slides.com/djnavarro/scienceandstatistics2
I briefly considered giving a talk about preregistration...
... but decided against it
(https://psyarxiv.com/x36pz/)
A request: if you tweet about my talk, please think about the framing & consider adding a link to my slides
https://slides.com/djnavarro/scienceandstatistics2
Statistics is a tool that can assist scientists develop, evaluate and modify theoretical claims
Statistical theory provides the logic of and the rules for scientific reasoning
"Whatever. Those rules aren't real"
"Without rules there is chaos"
"Without rules there is chaos"
I am deeply opposed to all forms of statistical prescriptivism... and my goal in this talk is to discuss why I feel this way
original artwork made with github.com/djnavarro/jasmines
Thomas Kuhn
"Science does not deal in all possible laboratory manipulations. Instead, it selects those relevant to the juxtaposition of a paradigm with the immediate experience that that paradigm has partially determined. As a result, scientists with different paradigms engage in different concrete laboratory manipulations"
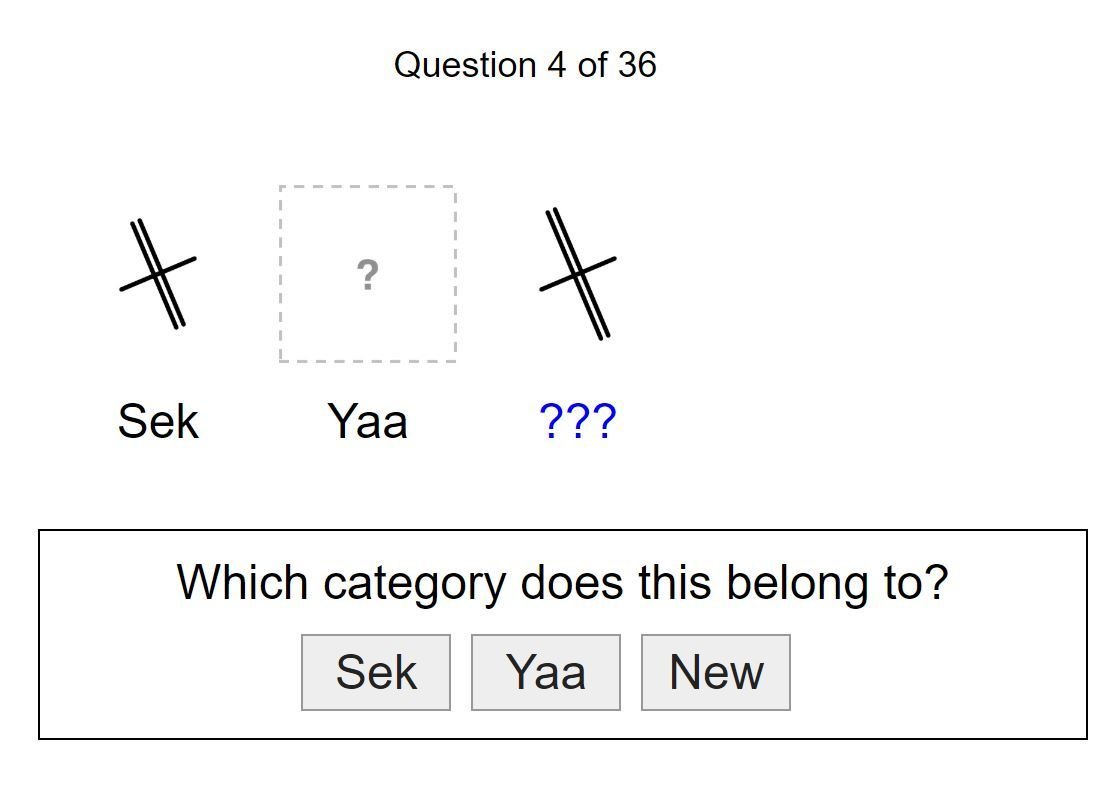
Okay, so I want to study human concept learning and inductive reasoning?
Let's consider two strategies I typically follow...
(https://psyarxiv.com/szr4u)
Operationalising the phenomenon of interest
(Yay math psych! I don't have to hide the equations)
Experiments based on my operationalisation yield very clean data that discriminate between competing computational models, yay!!!
What does my Bayes factor tell me about the relationship between my models and human reasoning outside of the experiment?
But I have an external validity problem... does this map onto anything in the world?
There are more things in human reasoning than dreamt of within my operationalisation!
(https://psyarxiv.com/mb93p/)
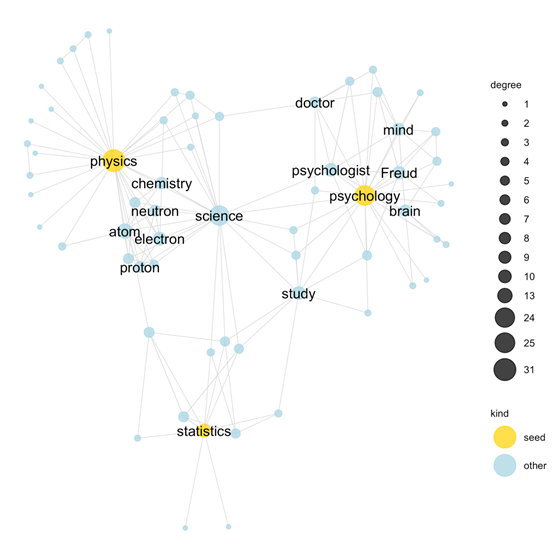
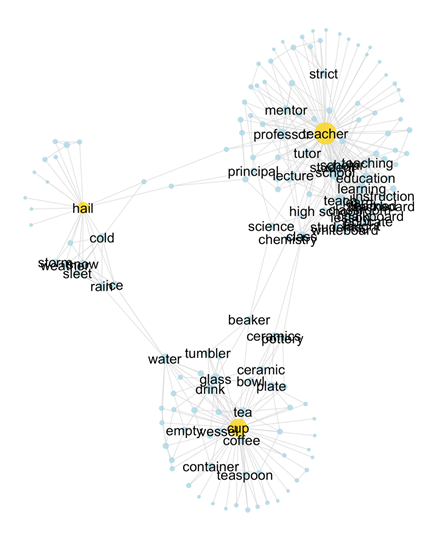
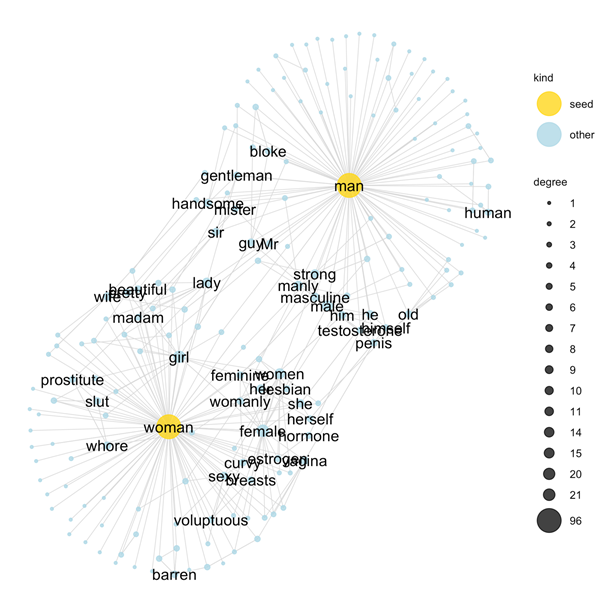
The SWOW norms encode common sense knowledge
... about science
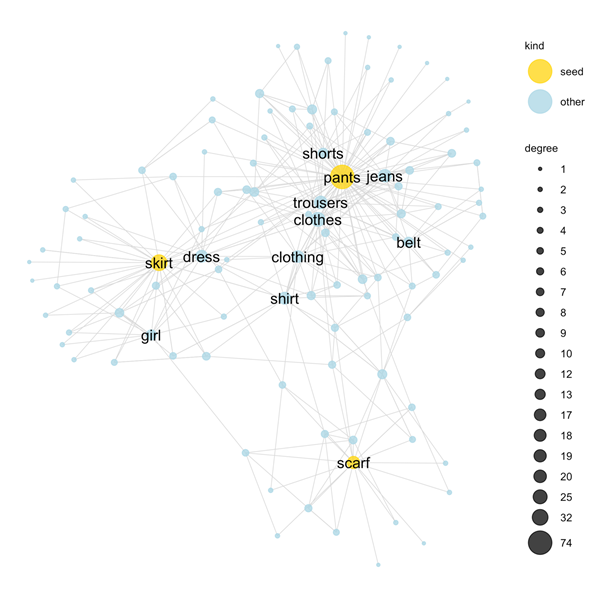
The SWOW norms encode common sense knowledge
... about clothes
We can use SWOW to study reasoning about lexicalised concepts...
(https://psyarxiv.com/s3k79/)
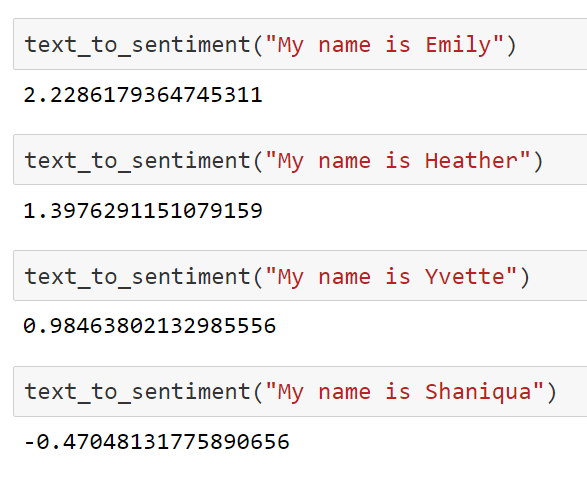
If I don't want sexist assumptions embedded in experiments that rely on SWOW norms, it is unwise to take those norms at face value
Buuuuut....
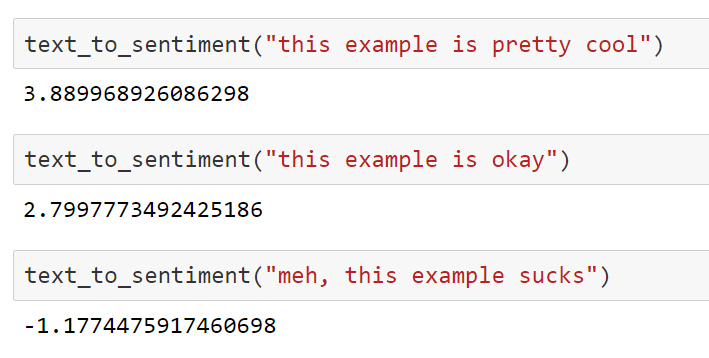
http://blog.conceptnet.io/posts/2017/how-to-make-a-racist-ai-without-really-trying/
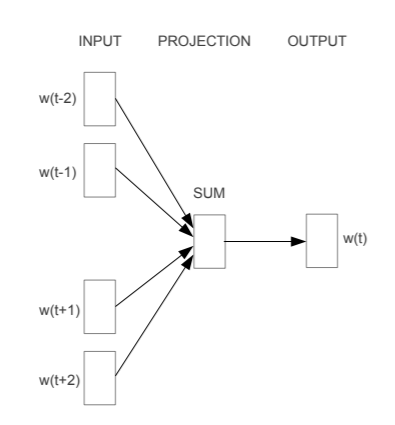
(Mikolov et al 2013)
But... does this really matter?
A cautionary example of how to misuse real world data in an applied context
Yeah, yeah, the model achieves 95% cross-validation accuracy, whatever...
Looking good!
For lab studies, the data analysis is only useful if you know how your operationalisation affects the way you to generalise outside the lab
... either way, the limitations to your design and your data ensure that the scientific problem you care about is more difficult than the one your statistical tools are built to solve
For naturalistic studies, the data analysis is only useful if you know which aspects of your uncontrolled data are relevant to the thing you are trying to study
original artwork made with github.com/djnavarro/jasmines
Statistical inference as I learned it in my Ph.D.
Life is too short to take p-values seriously
Bayes factors: A tool for confidently selecting the "best" "model"...
... where "best" is weird and the "models" are fantasies
Here be dragons.
Gronau and Wagenmakers (2018)
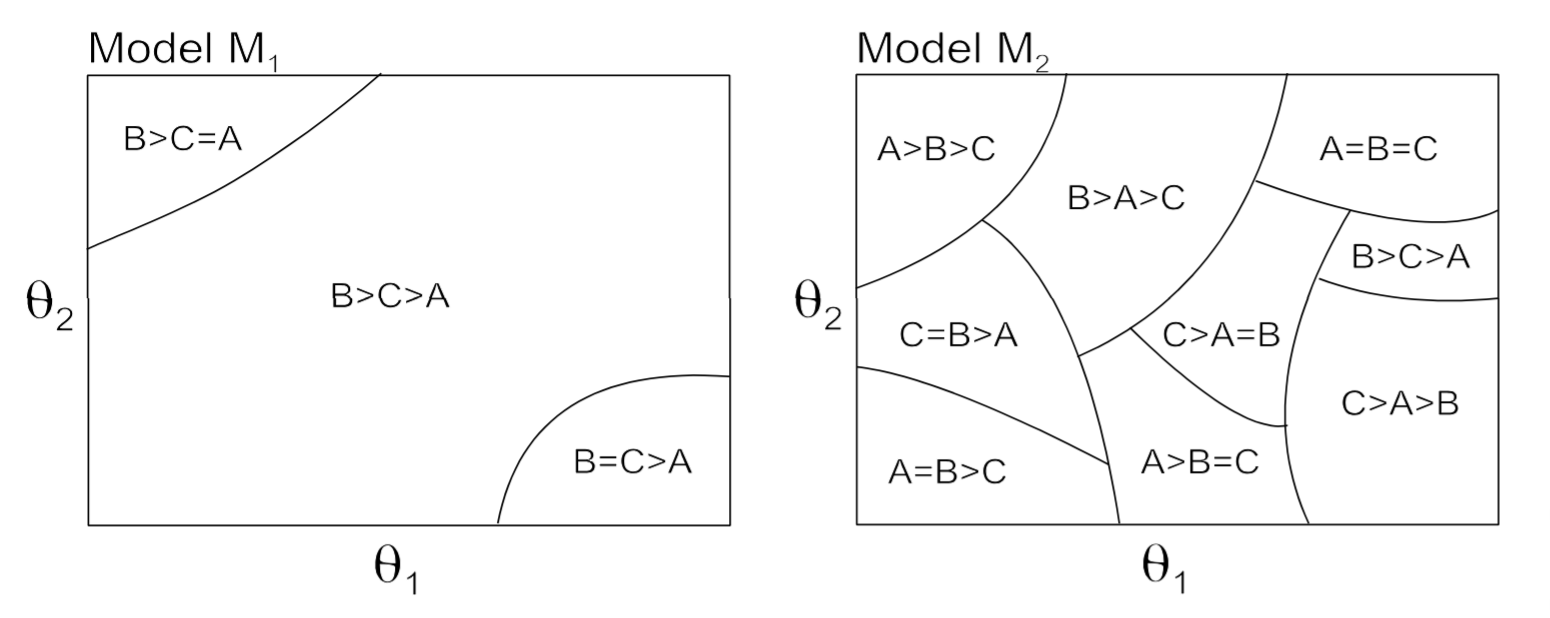
A toy problem that implicitly asserts a prescriptivist view of statistics
...which is unfortunate, because it's not in your model space
Selecting a horribly broken model with absolute confidence just because it's the "least wrong" (in KL-divergence terms) is a transparently insane inferential strategy
In real life everything falls apart when all your models are wrong in terrible ways
(https://psyarxiv.com/39q8y/)
The researcher's belief (or "knowledge") about the plausible values of the model parameters.
The prior predictive P(X|M) is quite sensitive to this prior, including the parts we don't think much about, like the heaviness of the tails
The more carefully you look, the stranger things become...
image via Michael Betancourt
The more parameters in your model, the more "tail" there is. So the closer we come to having genuinely plausible models of human reasoning, the less likely it is we can write down a plausible prior for those models
Oh and also the researcher is a human being who doesn't have perfect access to their own "beliefs" or "knowledge" (remember, we're psychologists????)
Anyone care to specify a prior for this model?
One that is precise enough for a Bayes factor calculation to actually mean something?
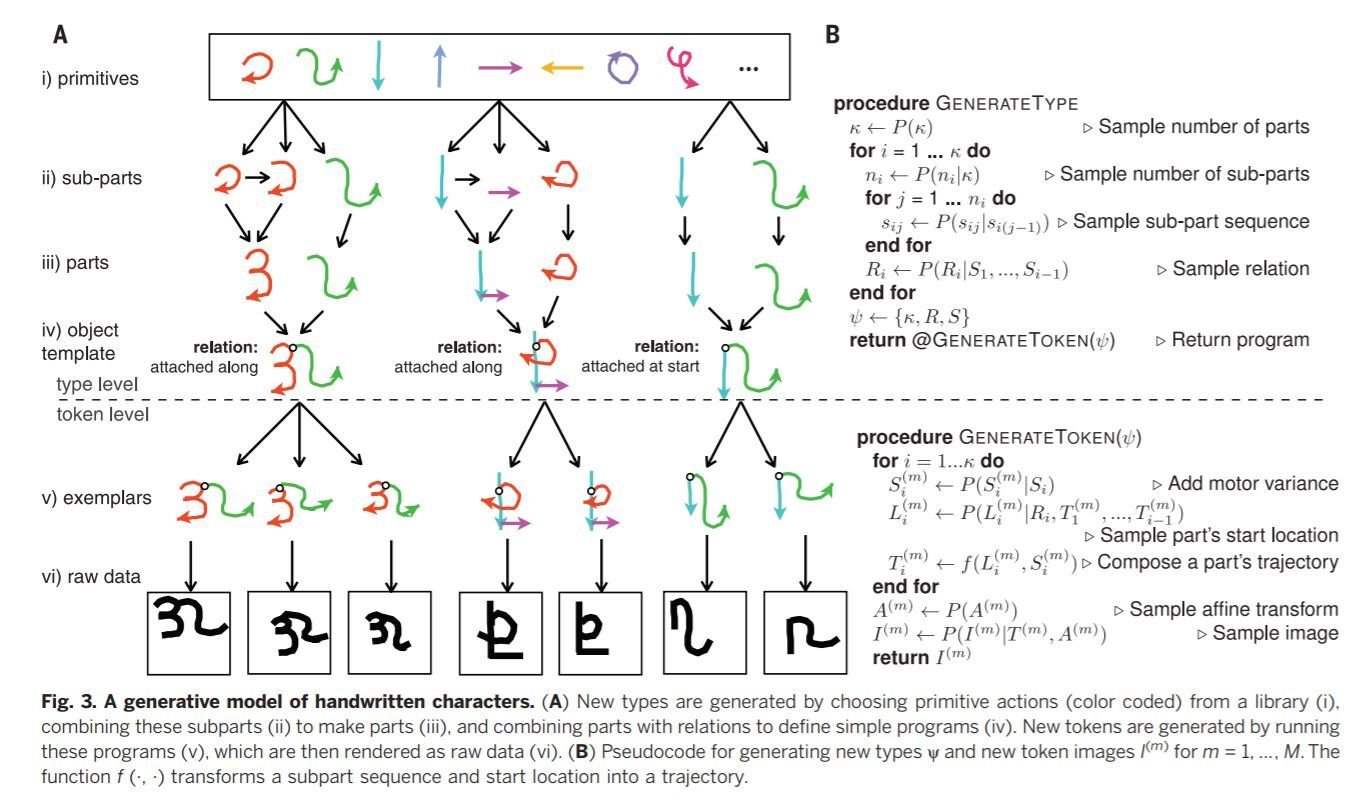
Lake et al (2015)
original artwork made with github.com/djnavarro/jasmines
Since all models are wrong the scientist must be alert to what is importantly wrong. It is inappropriate to be concerned about mice when there are tigers abroad.
- George Box (1976)
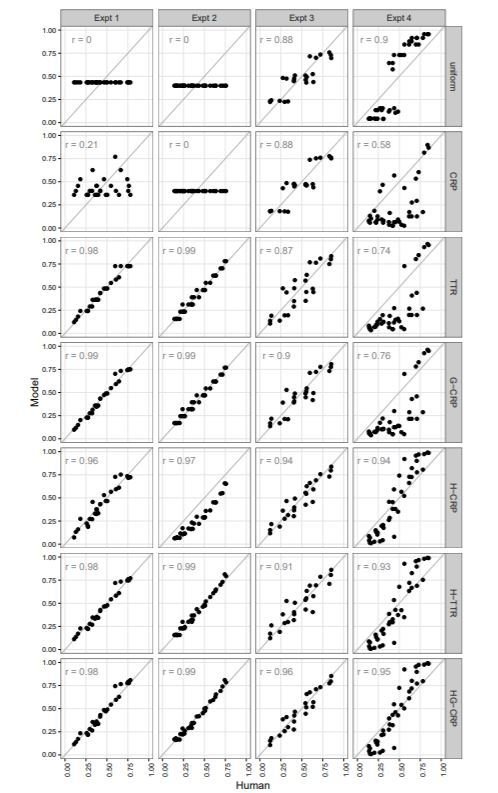
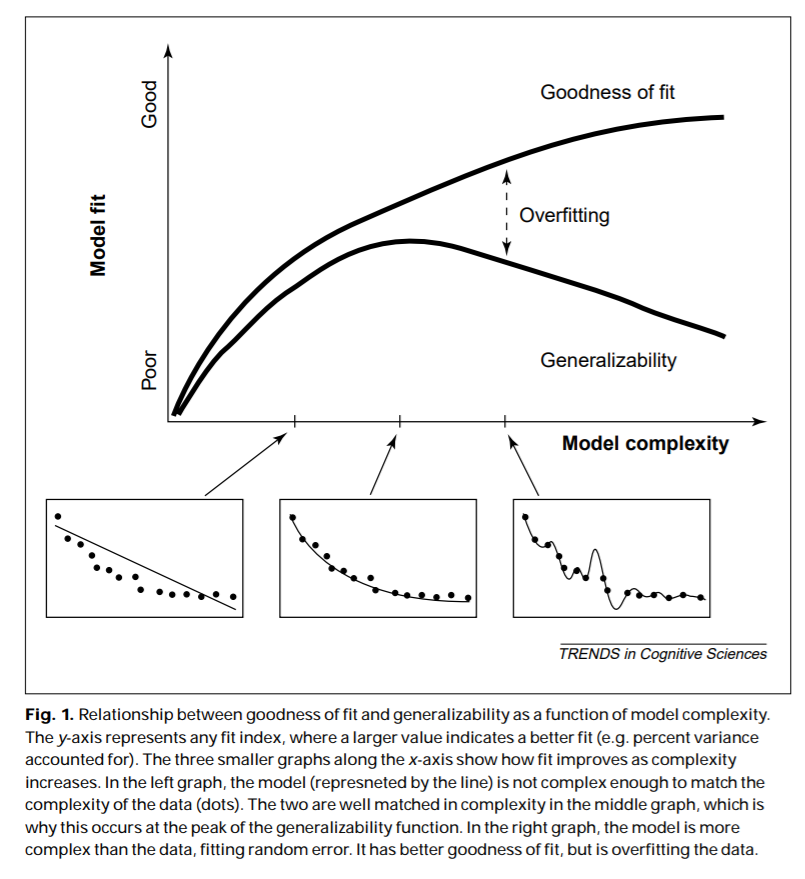
Model fitting the way I was taught it as a naive young thing ... quantify the degree of agreement between model and data
(https://psyarxiv.com/2m83v/)
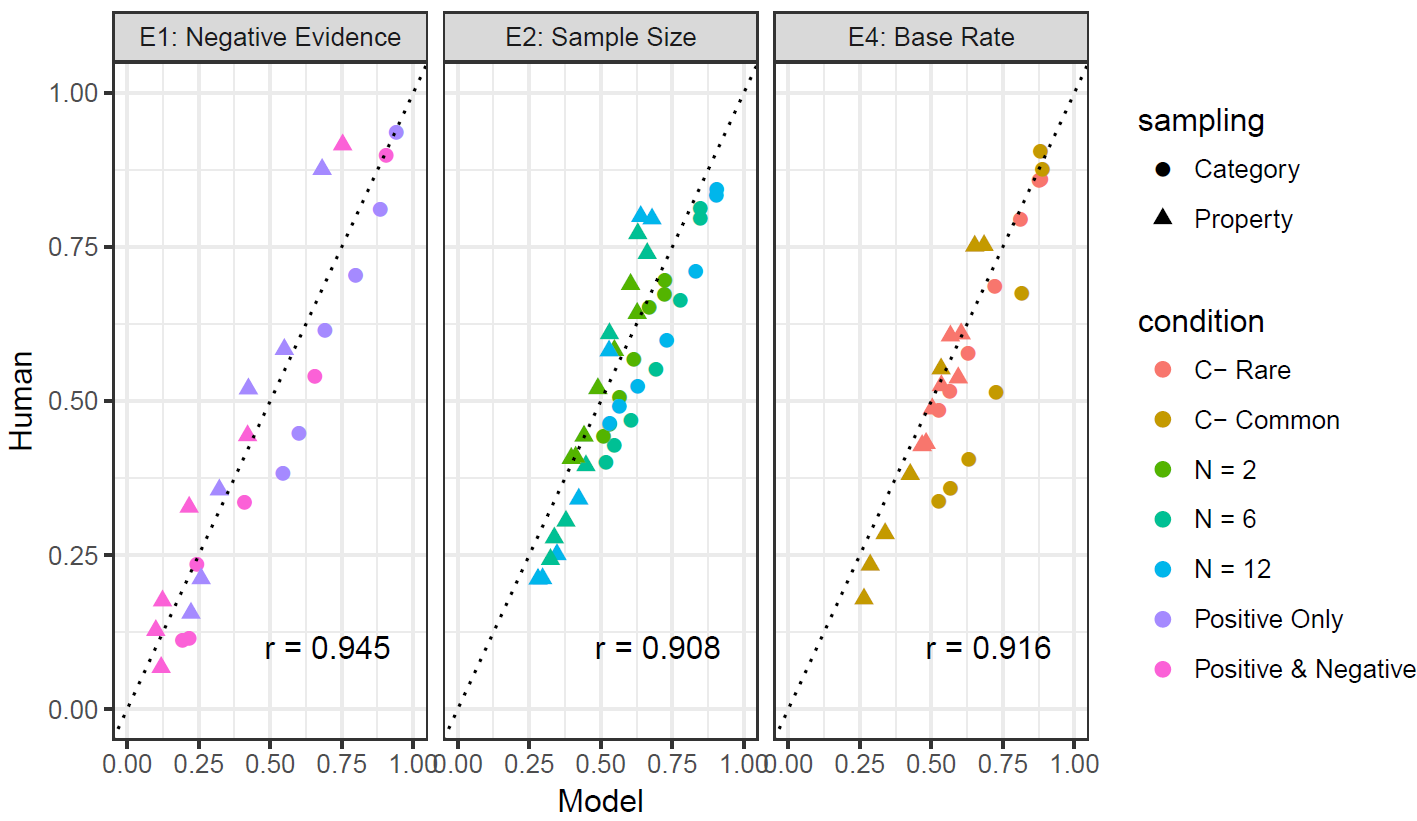
Correlations range from .91 to .95. About what I'd expect for a decent model, but is it ... (gasp) ... overfitting?
The middle-aged cynic, having found a way to "break" every model selection criterion she has tried...
(e.g., https://djnavarro.net/post/a-personal-essay-on-bayes-factors/)
What I do now...
What counts as a meaningful pattern in the data? To what extent is are such patterns a priori predictions of the model?
(https://psyarxiv.com/43auj/)
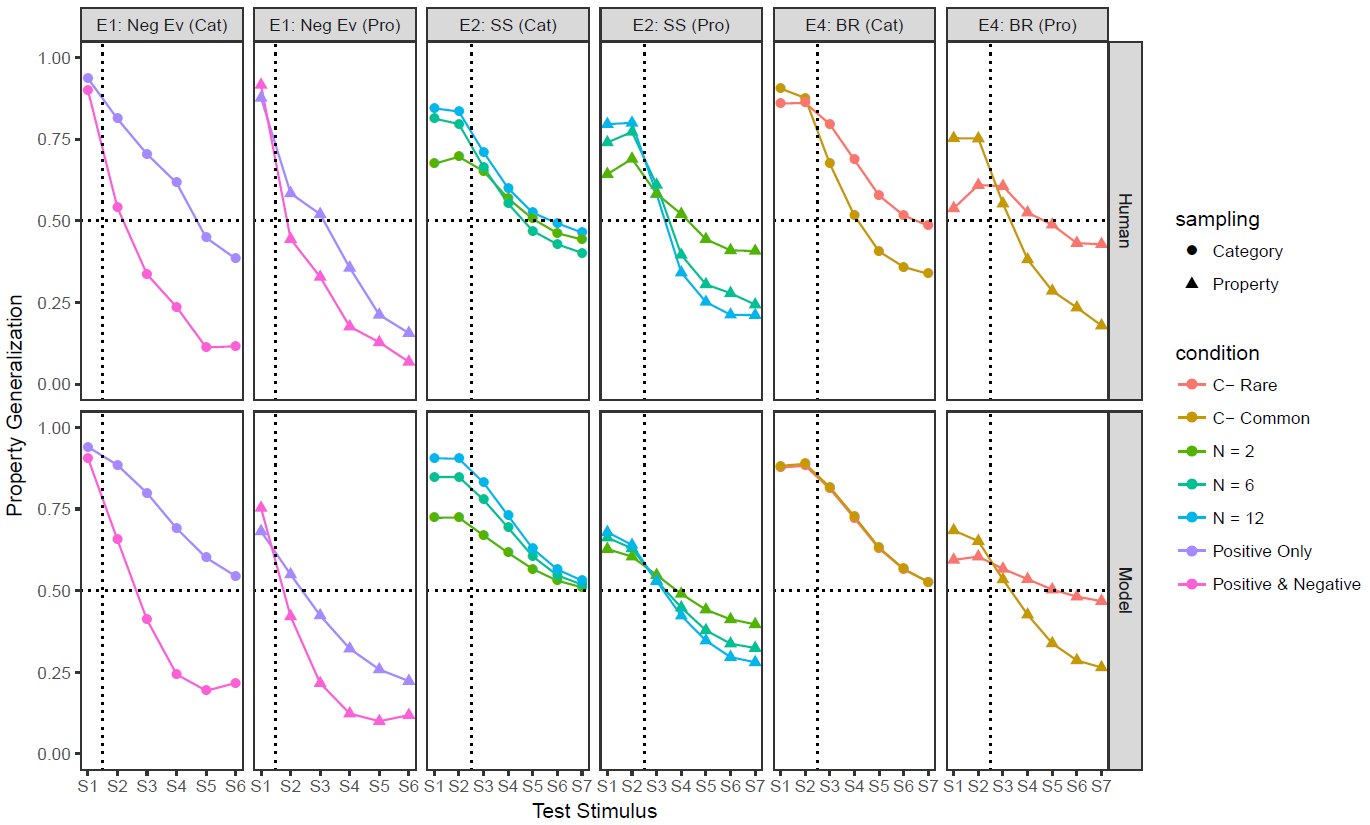
The same data set and model fits replotted.
Huh. Maybe I'm underfitting???
(https://psyarxiv.com/2m83v/)
This theoretically meaningful model failure is barely noticeable on the scatterplot, and a correlation of 0.92 rarely leads us to worry about underfitting, does it?
Fit looks good, but is the model overfitting???
Theoretical agreement looks good, but is the model underfitting???
Alas, this iterative process means Sir Ronald Fisher & I are "double dipping". This is purported to be a questionable research practice.
Oh well
(1) When statistical inferences don't work as advertised, they lose their usual meaning for confirmatory tests. So why be so petrified of making tentative inferences in exploratory analysis?
(2) Science is hard. Transparency, openness, audit trails, and scrupulous honesty are absolutely critical. This does not mean we must endorse the "remove researcher degrees of freedom to avoid p-hacking" opinion currently popular among methodological reformists
Thank you
https://slides.com/djnavarro/scienceandstatistics2
original artwork made with github.com/djnavarro/jasmines
By Danielle Navarro
Slides for my invited talk for the mathematical psychology satellite day at the 2019 psychonomics conference. This is a variation on an earlier talk I gave at the Aarhus open science workshop. http://mathpsych.org/conferences/psychonomics2019/




