FlowPM
IDRIS Hackathon
Team CosmoStat
What are we trying to do?
- The Universe is difficult to describe analytically, for many applications in Cosmology, we need to simulate it!
- In our case we rely on a class of simple N-body simulations, based on a Particle-Mesh scheme. We alternate between:
- Interpolating particles on a 3D grid
- Computing forces on the grid by 3D Fast Fourier-Transform
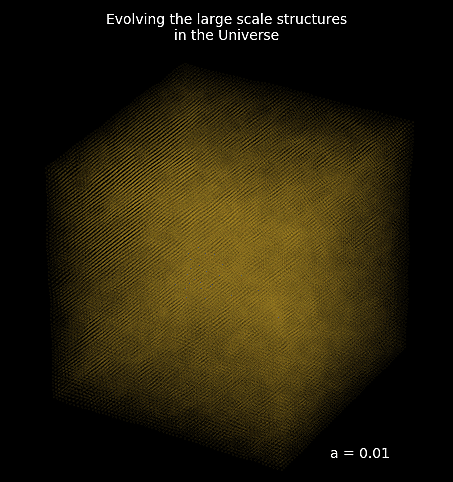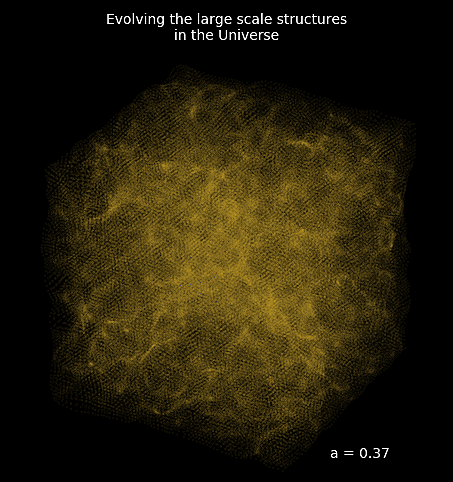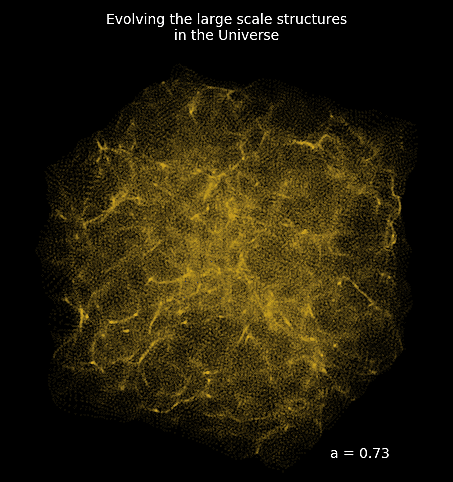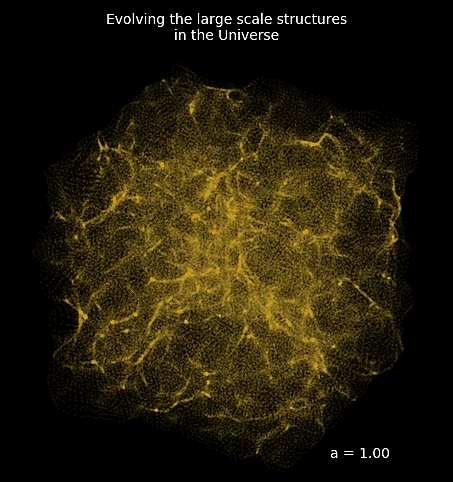

Example of reconstructing the initial conditions of the Universe by gradient descent
FlowPM: Distributed PM Solver in TensorFlow
import tensorflow as tf
import numpy as np
import flowpm
cosmo = flowpm.cosmology.Planck15()
stages = np.linspace(0.1, 1.0, 10, endpoint=True)
initial_conditions = flowpm.linear_field(32, # size of the cube
100, # Physical size of the cube
ipklin, # Initial power spectrum
batch_size=16)
# Sample particles
state = flowpm.lpt_init(cosmo, initial_conditions, a0=0.1)
# Evolve particles down to z=0
final_state = flowpm.nbody(cosmo, state, stages, 32)
# Retrieve final density field
final_field = flowpm.cic_paint(tf.zeros_like(initial_conditions), final_state[0])FlowPM on single-GPU
Scaling up: Mesh TensorFlow
- With a single GPU, 16GB of RAM can run an approximate 128^3 simulation => Far from enough for practical applications
- We adopted the Mesh TensorFlow framework for model parallelism.
#A simple 2 layer fully connected network
#y=Relu(xw+bias)v
#Define dimensions
batch = mtf.Dimension("batch", b)
io = mtf.Dimension("io", d_io)
hidden = mtf.Dimension("hidden", d_h)
# x.shape == [batch, io]
#Get tensors
w = mtf.get_variable("w", shape=[io, hidden])
bias = mtf.get_variable("bias", shape=[hidden])
v = mtf.get_variable("v", shape=[hidden, io])
#Define operations
h = mtf.relu(mtf.einsum(x, w, output_shape=[batch, hidden]) + bias)
y = mtf.einsum(h, v, output_shape=[batch, io])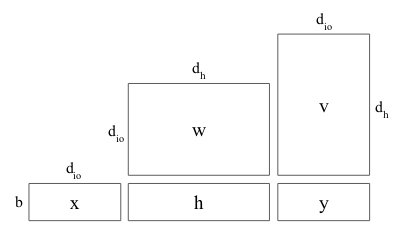
batch = mtf.Dimension("batch", b)
io = mtf.Dimension("io", d_io)
hidden = mtf.Dimension("hidden", d_h)
#Define mesh dimensions and layout
mesh_shape = [("processor_rows", 2), ("processor_cols", 2)]
layout_rules = [("batch", "processor_rows"),
("hidden", "processor_cols")]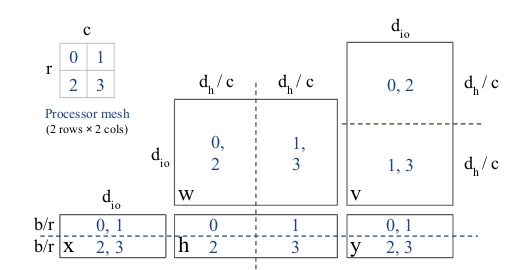
And it works!
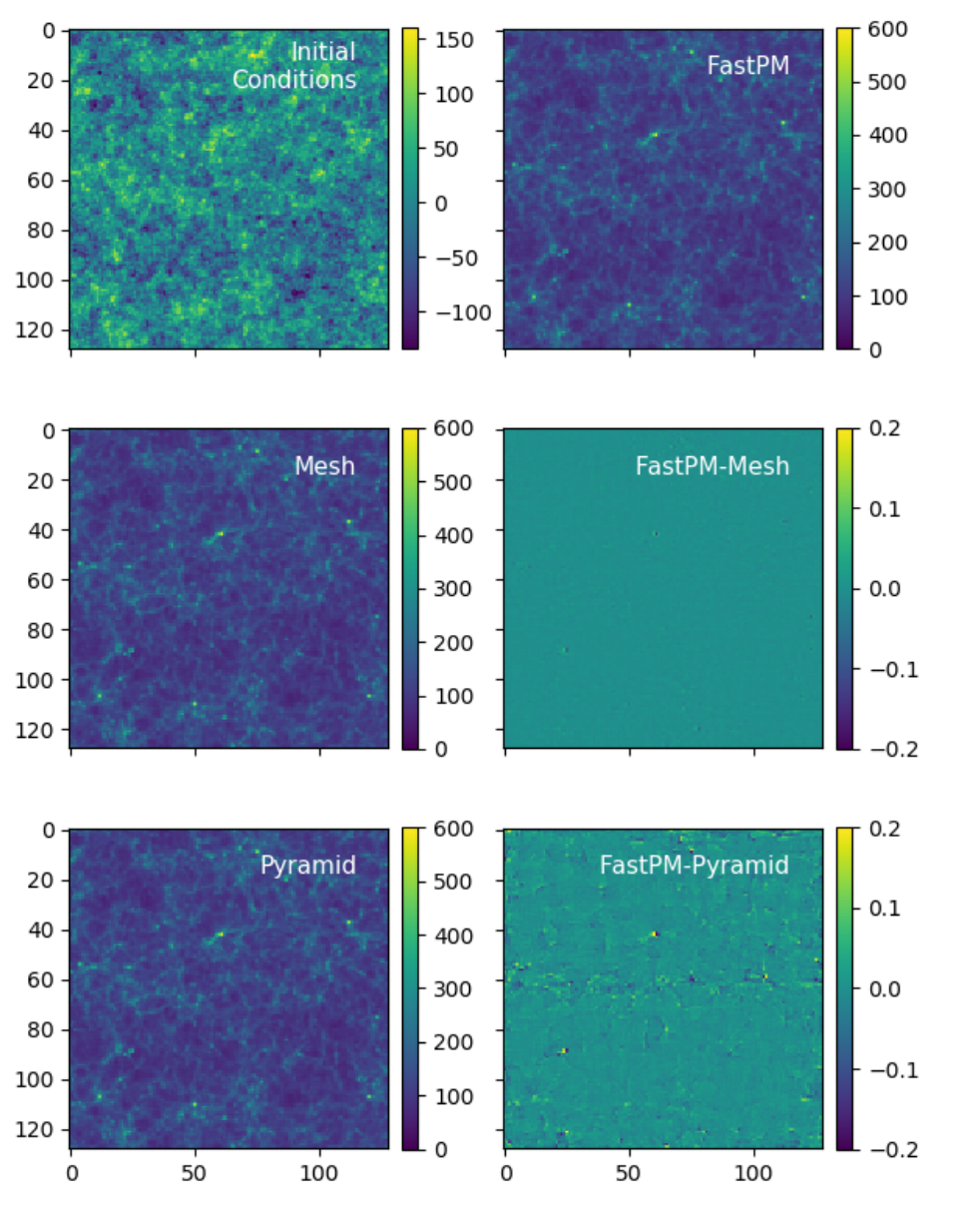
Comparison of distributed simulation on 4 GPUs
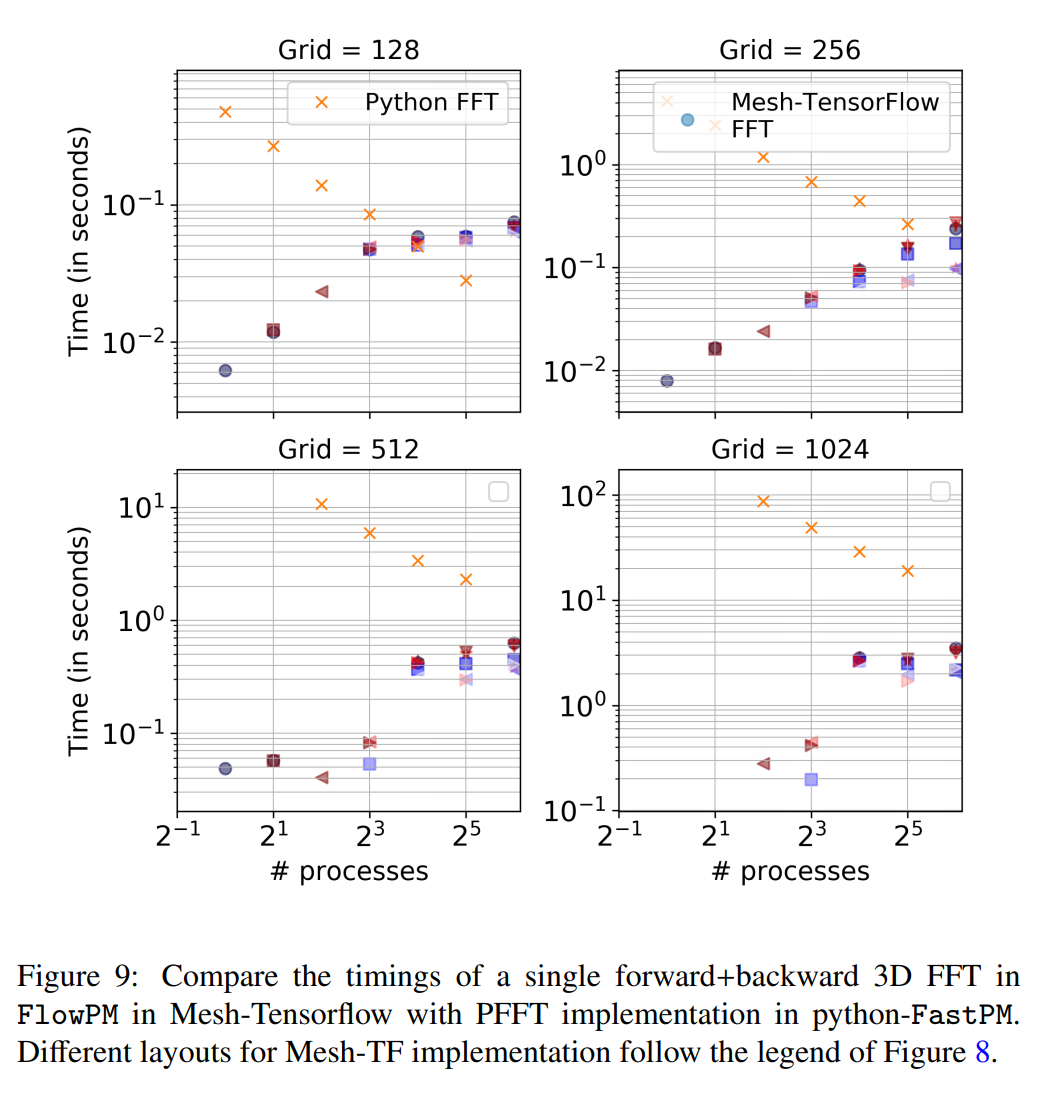
But... we are hitting performance and scalability issues
The problem with Mesh TensorFlow on GPU clusters
- Mesh TensorFlow is designed for Google's TPU pods.
- SIMD mesh implementation relying on TPU-specific collectives
- SIMD mesh implementation relying on TPU-specific collectives
- For GPUs, Mesh TensorFlow ships with what's called "DevicePlacementMeshImpl"
gpus = tf.config.experimental.list_logical_devices('GPU')
if gpus:
# Replicate your computation on multiple GPUs
c = []
for gpu in gpus:
with tf.device(gpu.name):
a = tf.constant([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]])
b = tf.constant([[1.0, 2.0],
[3.0, 4.0],
[5.0, 6.0]])
c.append(tf.matmul(a, b))
with tf.device('/CPU:0'):
matmul_sum = tf.add_n(c)
print(matmul_sum)Limitations of Device Placement
-
How it works:
- One master TensorFlow process defines and runs the compute graph
-
One client TensorFlow process per node just exposes its GPUs over network
-
Limitations:
-
A very large and complex graph is executed by a single process
- Inter-process comms happen through the gRPC layer
-
A very large and complex graph is executed by a single process
# Resolve the cluster from SLURM environment
cluster = tf.distribute.cluster_resolver.SlurmClusterResolver(
{"mesh": mesh_shape.size // FLAGS.gpus_per_task},
port_base=8822,
gpus_per_node=FLAGS.gpus_per_node,
gpus_per_task=FLAGS.gpus_per_task,
tasks_per_node=FLAGS.tasks_per_node)
cluster_spec = cluster.cluster_spec()
# Create a server for all mesh members
server = tf.distribute.Server(cluster_spec, "mesh",
cluster.task_id)
# Only he master job takes care of the graph building,
# everyone else can just chill for now
if cluster.task_id > 0:
server.join()
# Otherwise we are the main task, let's define the devices
mesh_devices = [
"/job:mesh/task:%d/device:GPU:%d" % (i, j)
for i in range(cluster_spec.num_tasks("mesh"))
for j in range(FLAGS.gpus_per_task)
]
print("List of devices", mesh_devices)
mesh_impl = mtf.placement_mesh_impl.PlacementMeshImpl(
mesh_shape, layout_rules, mesh_devices)Illustration of timings for 3D FFTs

The goal: SPMD Mesh TensorFlow using NCCL
- Level I: Use Horovod as the interface layer between NCCL and TensorFlow
- Level II: Implement a Mesh TensorFlow backend on modified Horovod
- Level III:Implement and Benchmark distributed FlowPM on new Mesh TF
Level I: Horovod
- Since late last year Horovod includes all2all collectives based on NCCL. BUT, only supports one global communicator.
- With Myriam and Jin, we worked on a PR to include support for multiple communicators.
from mpi4py import MPI
import horovod.tensorflow as hvd
# This will be our baseline world communicator
comm = MPI.COMM_WORLD
# Split COMM_WORLD into subcommunicators
subcomm = MPI.COMM_WORLD.Split(color=MPI.COMM_WORLD.rank % 2,
key=MPI.COMM_WORLD.rank)
# Initialize horovod with an array of communicators
hvd.init(comm=[comm, subcomm])
[....]
# AlltoAll over the WORLD communicator
hvd.alltoall(a, communicator_id=0)
# AlltoAll over second (splitted) communicator
hvd.alltoall(a, communicator_id=1)Level I goals
- Further test implementation (check for deadlocks in particular), and try to get PR approved for merging in Horovod.
- [Very Optional] Implement missing collectives like shifts along one mesh axis
Level II: Mesh TensorFlow
- We already have a prototype here of a Horovod-based Mesh TensorFlow backend, already runs but with limited functionality)
mesh_impl = HvdSimdMeshImpl(mtf.convert_to_shape(mesh_shape),
mtf.convert_to_layout_rules(layout_rules))
# And internally, HvdSimdMeshImpl essentially does:
# Use MPI to define needed communicators
cart_comm = MPI.COMM_WORLD.Create_cart(dims=dims,
periods=[False]*len(dims))
[...]
# Initializing horovod with our set of communicators
hvd.init(comm=[c for _, c in comms.items()])
# When collectives are called:
t = hvd.alltoall(t, communicator_id=self._comms_id[name_dim])Level II goals
- Finish and test Mesh TF Horovod implementation
- Benchmark and optimize main ops needed for simulation: FFT3D and halo exchange
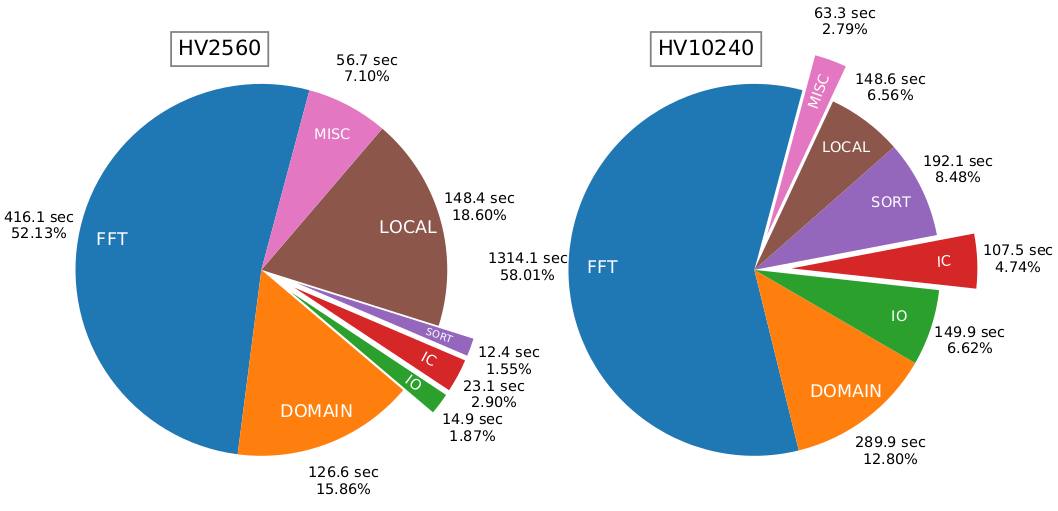
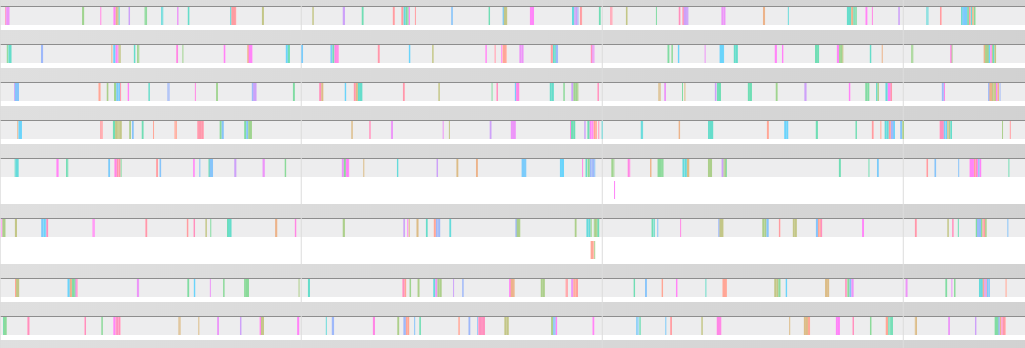
GPU utilisation for 3D FFT in device placement Mesh TF
Level III: FlowPM and Mesh TF applications
- We have never have been able to run FlowPM simulations on grids larger than 1024^3, so we want to test the scaling of our end-application under the new backend
- Some recent functionalities of FlowPM are not yet distributed, in particular Gravitational Lensing. They should be reimplemented in Mesh TF, and tested and optimized for the new backend
- Our lab is also working on 3D brain imaging with NeuroSpin, we have a prototype Mesh TF reconstruction code that can be transfered to new backend
Level III goals
- Benchmark final application
- Implement missing Mesh TF FlowPM components
- [Bonus goal] Proof of Concept of 3D brain imaging with Mesh TF model parallelism on new backend
IDRIS Hackathon Intro
By eiffl




