























Elisa Beshero-Bondar PRO
Professor of Digital Humanities and Chair of the Digital Media, Arts, and Technology Program at Penn State Erie, The Behrend College.
Elisa Beshero-Bondar
Twitter: @epyllia | GitHub: @ebeshero
Balisage: The Markup Conference
Monday August 1, 2022 @ 11am
Link to these slides: https://bit.ly/untangle-fv
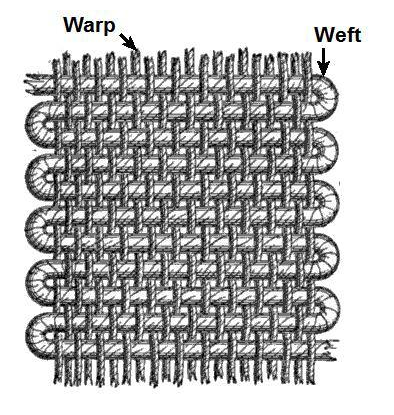
Background image created by the author from a loom on Reddit and the frontispiece illustration of Frankenstein (1831)
Our use of the term: A digital edition that investigates change to a work by comparing distinct versions of it.
1818 Edition published anonymously (3 volumes)
1823 Edition printed by MWS's father William Godwin, the first to include her name as the author. (2 volumes)
1831 Edition extensively revised by MWS, bound with Friedrich von Schiller's The Ghost Seer in Bentley's Standard Series of novels) (1/2 of a volume)
Thomas Copy made sometime between 1818 and 1822: MWS's marginal comments on a print copy of 1818
James Rieger, ed., first new edition of 1818 in 141
years : inline collation of "Thomas" w/ 1818,
1831 variants in endnotes
Legend:
Stuart Curran and Jack Lynch: PA Electronic Edition (PAEE) , collation of 1818 and 1831: HTML
Nora Crook crit. ed of 1818, variants of "Thomas", 1823, and 1831 in endnotes (P&C MWS collected works)
Romantic Circles TEI conversion of PAEE ; separates the texts of 1818 and 1831; collation via Juxta
1974
~mid-1990s
1996
Charles Robinson, The Frankenstein Notebooks (Garland): print facsimile of 1816 ms drafts
2007
Shelley-Godwin Archive publishes diplomatic/documentary edition of 1816 ms drafts
print edition
digital edition
Legend:
2013
2017
Frankenstein Variorum Project :
assembly/proof-correcting of PAEE files; OCR/proof-correcting 1823; "bridge" TEI edition of S-GA notebook files; automated collation; incorporating "Thomas" copy text
Can we make an edition that conveniently compares the manuscripts to the print publications?
Can we make a comprehensive variorum to show changes to the novel over time, from 1816 to 1831?
Which editorial interventions persist from 1816 to 1831?
MWS in the "Thomas" copy: how much of this persists into 1831?
PBS's additions: which/how many of these persist to 1831?
What parts of the novel were most mutable?
1. Share a nonlinear, divergent edition history
2. Introduce textual scholarship to students, fans of Frankenstein as well as text scholars, 19c specialists:
Prepared from OCR new XML of 1823 edition
Well, mostly...
...But let's take it one stage at a time...
...unless we
Shelley-Godwin Archive’s diplomatic edition of the 1816 Notebooks at http://shelleygodwinarchive.org
collection of TEI files, one file per notebook page
<surface lrx="3847" lry="5342"
partOf="#ox-frankenstein_volume_i"
ulx="0" uly="0" folio="21r" shelfmark="MS. Abinger c. 56" base="ox-ms_abinger_c56/ox-ms_abinger_c56-0045.xml"
id="ox-ms_abinger_c56-0045" sID="ox-ms_abinger_c56-0045"/>
<graphic url="http://shelleygodwinarchive.org/images/ox/ms_abinger_c56/ms_abinger_c56-0045.jp2"/>
<zone type="main" sID="c56-0045__main"/>
<lb n="c56-0045__main__17"/>
<del rend="strikethrough" sID="c56-0045__main__d2e9811"/>But how<del eID="c56-0045__main__d2e9811"/> How can I describe
my <lb n="c56-0045__main__18"/> emotion at this catastrophe; or how
<w ana="start"/>deli<lb n="c56-0045__main__19"/>neate<w ana="end"/>
the wretch whom with such <lb n="c56-0045__main__20"/> infinite pains and care I had endeavoured <lb n="c56-0045__main__21"/> to form. His limbs were in proportion <lb n="c56-0045__main__22"/> and I had selected his features <del rend="strikethrough" sID="c56-0045__main__d2e9830"/>h<del eID="c56-0045__main__d2e9830"/> as <lb n="c56-0045__main__23"/>
<mod sID="c56-0045__main__d2e9835"/>
<del rend="strikethrough" sID="c56-0045__main__d2e9837"/>handsome<del eID="c56-0045__main__d2e9837"/>
<mdel>.</mdel>
<anchor xml:id="c56-0045.01"/>
<zone corresp="#c56-0045.01" type="left_margin" sID="c56-0045__left_margin"/>
<lb n="c56-0045__left_margin__1"/>
<add sID="c56-0045__left_margin__d2e9849"/>
<mod sID="c56-0045__left_margin__d2e9851"/>
<del rend="strikethrough" sID="c56-0045__left_margin__d2e9853"/>handsome<del eID="c56-0045__left_margin__d2e9853"/>
<add hand="#pbs" place="superlinear" sID="c56-0045__left_margin__d2e9856"/>beautiful.<add eID="c56-0045__left_margin__d2e9856"/>
<mod eID="c56-0045__left_margin__d2e9851"/>
<add eID="c56-0045__left_margin__d2e9849"/>
<zone eID="c56-0045__left_margin"/>
<mod eID="c56-0045__main__d2e9835"/>
<mod sID="c56-0045__main__d2e9863"/>
<del rend="strikethrough" sID="c56-0045__main__d2e9865"/>Handsome<del eID="c56-0045__main__d2e9865"/>
<add hand="#pbs" place="superlinear" sID="c56-0045__main__d2e9868"/>Beautiful<add eID="c56-0045__main__d2e9868"/>
<mod eID="c56-0045__main__d2e9863"/>; Great God! His <lb n="c56-0045__main__24"/>
Gothenburg model : algorithm for computer-assisted collation, developed in 2009 workshop of collateX and Juxta developers.
Tokenization :
Break down the smallest unit of comparison: (words--with punctuation, or character-by-character):
FV tokenizes words and includes punctuation and tags:
'<del>the', 'frame', 'on', 'whic<del>', 'my', 'man', 'completeed,.'
Normalization
'&' = 'and'
<p xml:id="novel1_letter4_div4_p2"> = <p/>
Alignment
Identify comparable divergence: what makes text sequences comparable units?
“Chunking” text into comparable passages (chapters/paragraphs that line up with identifiable start and end points). Collation proceeds chunk by chunk.
Analysis
Study output, correct, and re-align after machine process, AND refine automated processing
Visualization:
Critical edition interface, graph displays
With witnesses prepared and inspected, we turn to the Python script that tokenizes and normalizes the source files, preparing the witnesses to be compared by collation software.
warp: sets tension or looseness of weave:
normalizing the text "thread" to tell us how to "pull" it
weft: moves through the warp threads cross-wise:
establishes moments of alignment across the text threads
You need to be able to modify this
def tokenize(inputFile):
return regexLeadingBlankLine.sub('\n', regexBlankLine.sub('\n',
extract(inputFile))).split('\n')reduces multiple `\n`with a single `\n`and separates word and element tokens with newlines. The actual tokens are built up by the extract() function. . .
def extract(input_xml):
"""Process entire input XML document, firing on events"""
# Start pulling; it continues automatically
doc = pulldom.parse(input_xml)
output = ''
for event, node in doc:
# elements to ignore: xml
if event == pulldom.START_ELEMENT and node.localName in ignore:
continue
if event == pulldom.START_ELEMENT and node.localName in inlineVariationEvent:
doc.expandNode(node)
output += '\n' + node.toxml() + '\n'
elif event == pulldom.START_ELEMENT and node.localName in blockEmpty:
output += '\n' + node.toxml() + '\n'
# ebb: empty inline elements that do not take surrounding white spaces:
elif event == pulldom.START_ELEMENT and node.localName in inlineEmpty:
output += node.toxml()
elif event == pulldom.START_ELEMENT and node.localName in inlineContent:
output += '\n' + regexEmptyTag.sub('>', node.toxml())
elif event == pulldom.END_ELEMENT and node.localName in inlineContent:
output += '</' + node.localName + '>' + '\n'
elif event == pulldom.CHARACTERS:
output += normalizeSpace(node.data)
else:
continue
return outputignore = ['mod', 'sourceDoc', 'xml', 'comment', 'anchor', 'include',
'delSpan', 'addSpan','handShift', 'damage',
'restore', 'zone', 'surface',
'graphic', 'unclear', 'retrace']
blockEmpty = ['pb', 'p', 'div', 'milestone',
'lg', 'l', 'cit', 'quote',
'bibl', 'ab', 'head']
inlineEmpty = ['sga-add', 'lb', 'gap', 'hi', 'w']
inlineContent = ['del-INNER', 'add-INNER', 'metamark',
'mdel', 'shi']
inlineVariationEvent = ['del', 'add', 'note']Prepare the warp: create lists of XML element names for special treatment
How should the collation software read the tokens and understand sameness?
<!-- Should punctuation be ignored? -->
<xsl:param name="tan:ignore-punctuation-differences" as="xs:boolean" select="false()"/>
<xsl:param name="additional-batch-replacements" as="element()*">
<!--ebb: normalizations to batch process for collation. NOTE: We want to do these to preserve some markup \\
in the output for post-processing to reconstruct the edition files.
Remember, these will be processed in order, so watch out for conflicts. -->
<replace pattern="(<.+?>\s*)>" replacement="$1"
message="normalizing away extra right angle brackets"/>
<replace pattern="&" replacement="and"
message="ampersand batch replacement"/>
<replace pattern="</?xml>" replacement=""
message="xml tag replacement"/>
<replace pattern="(<p)\s+.+?(/>)" replacement="$1$2"
message="p-tag batch replacement"/>
<replace pattern="(<)(metamark).*?(>).+?\1/\2\3" replacement=""
message="metamark batch replacement"/>
<!--ebb: metamark contains a text node, and we don't want its
contents processed in the collation, so this captures the entire element. -->
<replace pattern="(</?)m(del).*?(>)"
replacement="$1$2$3" message="mdel-SGA batch replacement"/>
<!--ebb: mdel contains a text node, so this catches both start and end tag.
We want mdel to be processed as <del>...</del>-->
<replace pattern="</?damage.*?>"
replacement="" message="damage-SGA batch replacement"/>
<!--ebb: damage contains a text node, so this catches both start and end tag. -->
<replace pattern="</?unclear.*?>" replacement=""
message="unclear-SGA batch replacement"/>
<!--ebb: unclear contains a text node, so this catches both start and end tag. -->
<replace pattern="</?retrace.*?>" replacement=""
message="retrace-SGA batch replacement"/>
<!--ebb: retrace contains a text node, so this catches both start and end tag. -->
See Joel Kalvesmaki's Balisage papers on
tan:diff (2021) and tan:collate 2022 (this week)
RE_PARA = re.compile(r'<p\s.+?/>')
RE_INCLUDE = re.compile(r'<include.*?/>')
RE_HEAD = re.compile(r'<head.*?/>')
RE_AB = re.compile(r'<ab.*?/>')
RE_ADDEND = re.compile(r'</add>')
RE_NOTE_START = re.compile(r'<note.*?>')
RE_NOTE_END = re.compile(r'</note>')
RE_DELSTART = re.compile(r'<del.*?>')
RE_DELEND = re.compile(r'</del>')
RE_SGA_ADDSTART = re.compile(r'<sga-add.+?sID.+?>')
RE_SGA_ADDEND = re.compile(r'<sga-add.+?eID.+?>')
RE_MDEL = re.compile(r'<mdel.*?>.+?</mdel>')
RE_SHI = re.compile(r'<shi.*?>.+?</shi>')
RE_METAMARK = re.compile(r'<metamark.*?>.+?</metamark>')
RE_HI = re.compile(r'<hi\s.+?/>')
RE_PB = re.compile(r'<pb.*?/>')
RE_LB = re.compile(r'<lb.*?/>')
RE_LG = re.compile(r'<lg[^<]*/>')
RE_L = re.compile(r'<l\s[^<]*/>')
RE_CIT = re.compile(r'<cit\s[^<]*/>')
RE_QUOTE = re.compile(r'<quote\s[^<]*/>')
RE_OPENQT = re.compile(r'“')
RE_CLOSEQT = re.compile(r'”')
RE_GAP = re.compile(r'<gap\s[^<]*/>')
RE_sgaP = re.compile(r'<milestone[^<]+?unit="tei:p.+?/>')
RE_MILESTONE = re.compile(r'<milestone.+?>')
RE_MULTI_LEFTANGLE = re.compile(r'<{2,}')
RE_MULTI_RIGHTANGLE = re.compile(r'>{2,}')def normalize(inputText):
return RE_MULTI_LEFTANGLE.sub('<',\
RE_MULTI_LEFTANGLE.sub('>', \
RE_INCLUDE.sub('', \
RE_AB.sub('', \
RE_HEAD.sub('', \
RE_AMP.sub('and', \
RE_MDEL.sub('', \
RE_SHI.sub('', \
RE_HI.sub('', \
RE_LB.sub('', \
RE_PB.sub('', \
RE_PARA.sub('<p/>', \
RE_sgaP.sub('<p/>', \
RE_MILESTONE.sub('', \
RE_LG.sub('<lg/>', \
RE_L.sub('<l/>', \
RE_CIT.sub('', \
RE_QUOTE.sub('', \
RE_OPENQT.sub('"', \
RE_CLOSEQT.sub('"', \
RE_GAP.sub('', \
RE_DELSTART.sub('<delstart/>', \
RE_DELEND.sub('<delend/>', \
RE_ADDSTART.sub('<addstart/>', \
RE_ADDEND.sub('<addend/>', \
RE_MOD.sub('', \
RE_METAMARK.sub('', inputText))))))))))))))))))))))))))).lower()Find and replace the regex patterns before feeding to collateX
<app>
<rdgGrp n="['spot,', 'and', 'endeavoured,']">
<rdg wit="f1818">spot, and endeavoured, </rdg>
<rdg wit="f1823">spot, and endeavoured, </rdg>
<rdg wit="fThomas">spot, and endeavoured, </rdg>
<rdg wit="f1831">spot, and endeavoured, </rdg>
</rdgGrp>
<rdgGrp n="['spotand', 'endeavoured']">
<rdg wit="fMS">spot& endeavoured </rdg>
</rdgGrp>
</app> . . . the spot<add eID="c57-0117__main__d3e21951"/> & endeavoured . . . In the fMS source:
if event == pulldom.START_ELEMENT and node.localName in inlineEmpty:
output += '\n' + node.toxml() + '\n'by adding newline characters around markup nodes
corrected this output...
<app>
<rdgGrp n="['spot', '<addend/>']">
<rdg wit="fMS">spot
<add eID="c57-0117__main__d3e21951"/> </rdg>
</rdgGrp>
<rdgGrp n="['spot,']">
<rdg wit="f1818">spot, </rdg>
<rdg wit="f1823">spot, </rdg>
<rdg wit="fThomas">spot, </rdg>
<rdg wit="f1831">spot, </rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['and']">
<rdg wit="f1818">and </rdg>
<rdg wit="f1823">and </rdg>
<rdg wit="fThomas">and </rdg>
<rdg wit="f1831">and </rdg>
<rdg wit="fMS">& </rdg>
</rdgGrp>
</app>but created a new problem...
<app>
<rdgGrp n="['for', 'there']">
<rdg wit="f1818">for there </rdg>
<rdg wit="f1823">for there </rdg>
<rdg wit="fThomas">for there </rdg>
<rdg wit="f1831">for there </rdg>
<rdg wit="fMS">for there </rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['', '', '<addstart/>']">
<rdg wit="fMS"><lb n="c57-0118__main__4"/>
<lb n="c57-0118__left_margin__1"/> <add hand="#pbs"
sID="c57-0118__left_margin__d3e21996"/> </rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['was']">
<rdg wit="f1818">was </rdg>
<rdg wit="f1823">was </rdg>
<rdg wit="fThomas">was </rdg>
<rdg wit="f1831">was </rdg>
<rdg wit="fMS">was </rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['<addend/>']">
<rdg wit="fMS"><add eID="c57-0118__left_margin__d3e21996"/> </rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['no', 'sign', 'of', 'any']">
<rdg wit="f1818">no sign of any </rdg>
<rdg wit="f1823">no sign of any </rdg>
<rdg wit="fThomas">no sign of any </rdg>
<rdg wit="f1831">no sign of any </rdg>
<rdg wit="fMS">no sign of any </rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['violence']">
<rdg wit="fMS">violence </rdg>
</rdgGrp>
<rdgGrp n="['violence,']">
<rdg wit="f1818">violence, </rdg>
<rdg wit="f1823">violence, </rdg>
<rdg wit="fThomas">violence, </rdg>
<rdg wit="f1831">violence, </rdg>
</rdgGrp> </app>When to make the interventions?
Making a “stand-off“ Spine (info + pointers to collation data)
Generating the edition files with collation data marked “inline”
Tokenization and alignment is a research method.
There will be more than one way to express it.
Your alignment decisions express your theory of your text.
Reflections on machine-assisted collation and the TEI critical apparatus
We (scholars and programmers, and scholarly programmers) need to share our algorithms for tokenization and alignment, together with the editions and interfaces we design with it.
A heavily revised passage, showing the MS notebook view
”Heatmap” view, showing variation intensity as blocks with circles color-coded by edition. Selecting a circle on the heatmap view displays the edition and its variants.
Legend
MS
1818
Thm
1823
1831
Alignments, gaps, and comparative lengths of each collation unit
chapter heading or other structural boundary
Mouse over a black box...
Strengths
Weaknesses
Solutions
By Elisa Beshero-Bondar
The word by word, comma by comma, and sometimes tag by tag comparison of manuscripts and editions (called “collation”) is notoriously tedious and error-prone. But computer-aided collation is like a power loom that inevitably tangles up threads caught in the machinery. We need new tooling to help us unsnarl the threads. To this point, we aligned variant passages in the Frankenstein Variorum project using a Python script to feed collateX. Now we are experimenting with the Text Alignment Network’s tandiff XSLT to handle the string comparison completely with XPath and XSLT. How far can we take XSLT and Schematron in automating the preparation, collation, and correction of electronic editions?


