























Elisa Beshero-Bondar PRO
Professor of Digital Humanities and Chair of the Digital Media, Arts, and Technology Program at Penn State Erie, The Behrend College.
Elisa Beshero-Bondar, PhD
Chair, TEI Technical Council | Professor of Digital Humanities, Penn State Behrend
Keynote for Digital Humanities and the Power of Collaboration: Expanding Connections from Local to Global Symposium at Fukuoka University, Japan, 2025-03-10
Thank you for inviting me to speak!
今日はご招待いただきありがとうございます。
Kyō wa go shōtai itadaki arigatōgozaimasu.
Interoperation: Can texts that are prepared for machine processing in one computer system be understood by other systems?
Interchange: Can the machine-readable parts of the texts be understood by humans, who can work with them as needed, without additional information?
ISO attempts to set precise standards based on measurable physical properties of our universe. According to ISO, a "second" in time is defined thus:
| The second is the duration of 9,192,631,770 periods of the radiation corresponding to the transition between the two hyperfine levels of the ground state of the caesium-133 atom. |
Contemporary nuclear science prevails in this measurement. Is it applicable to explanations of time duration from past centuries?
A nuclear physics lab can consistently measure the passage of one second from observing subatomic particles. This is more precise than watching a spring-and-weight driven watch or pendulum clock.
Text
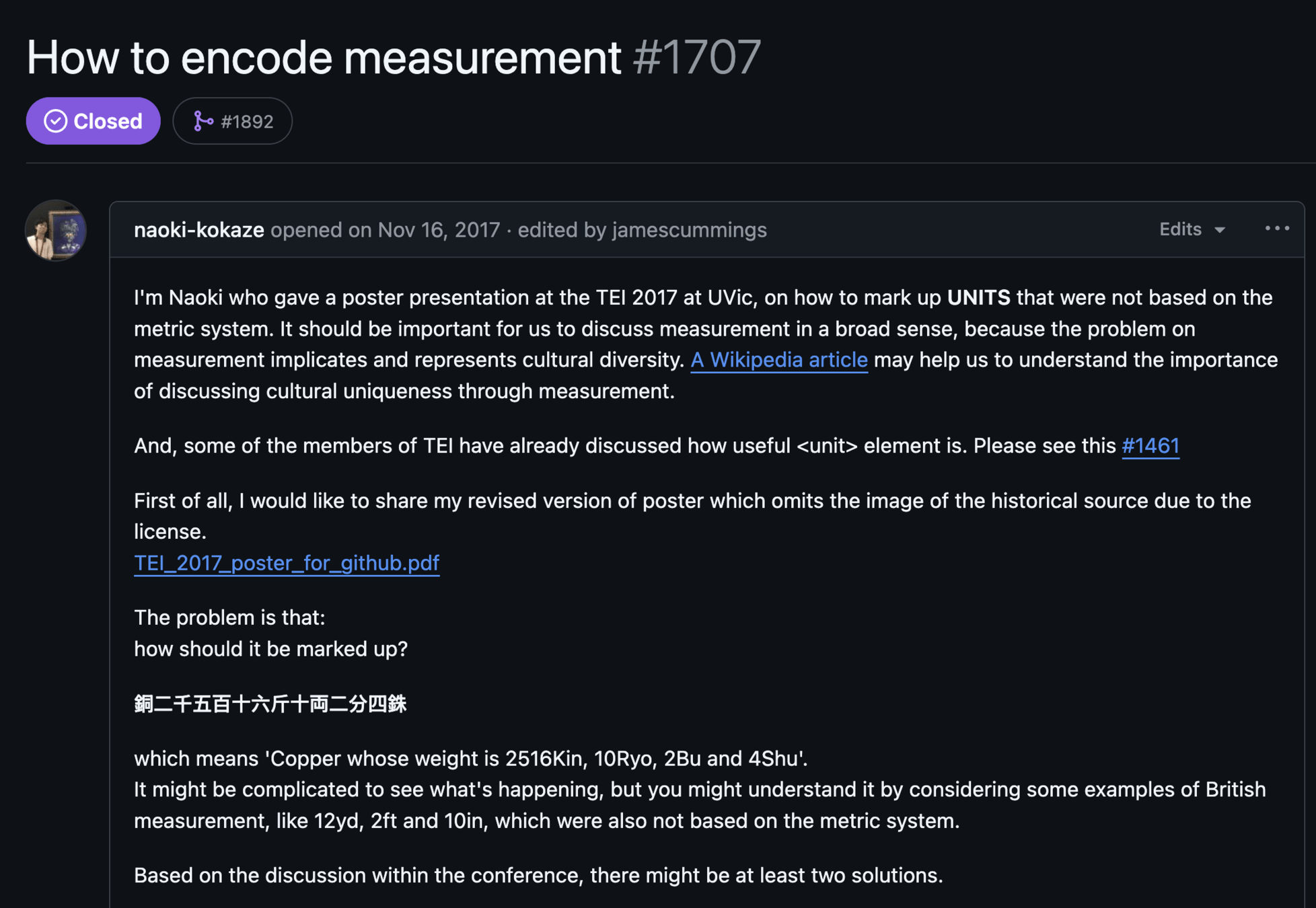
Naoki Kokaze's ticket: #1707 (2017), resolved in 2019
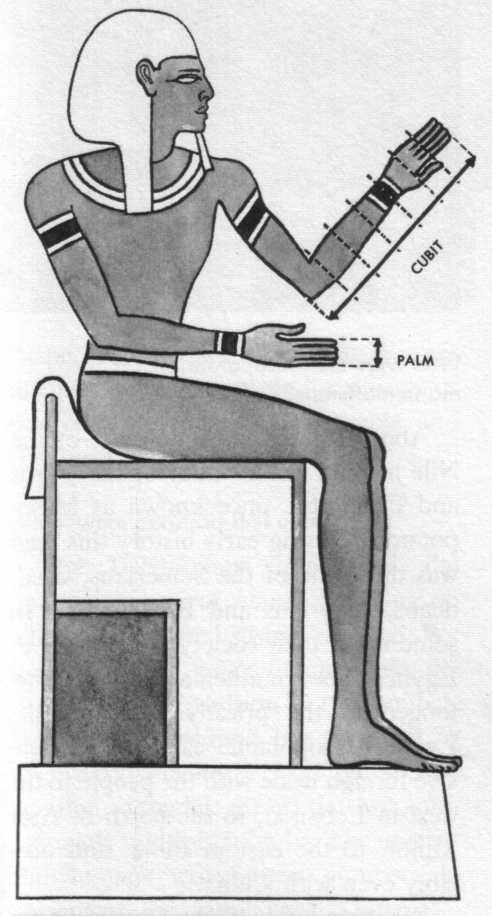
Standard weights and measures from ancient Egypt
4 digits = a palm
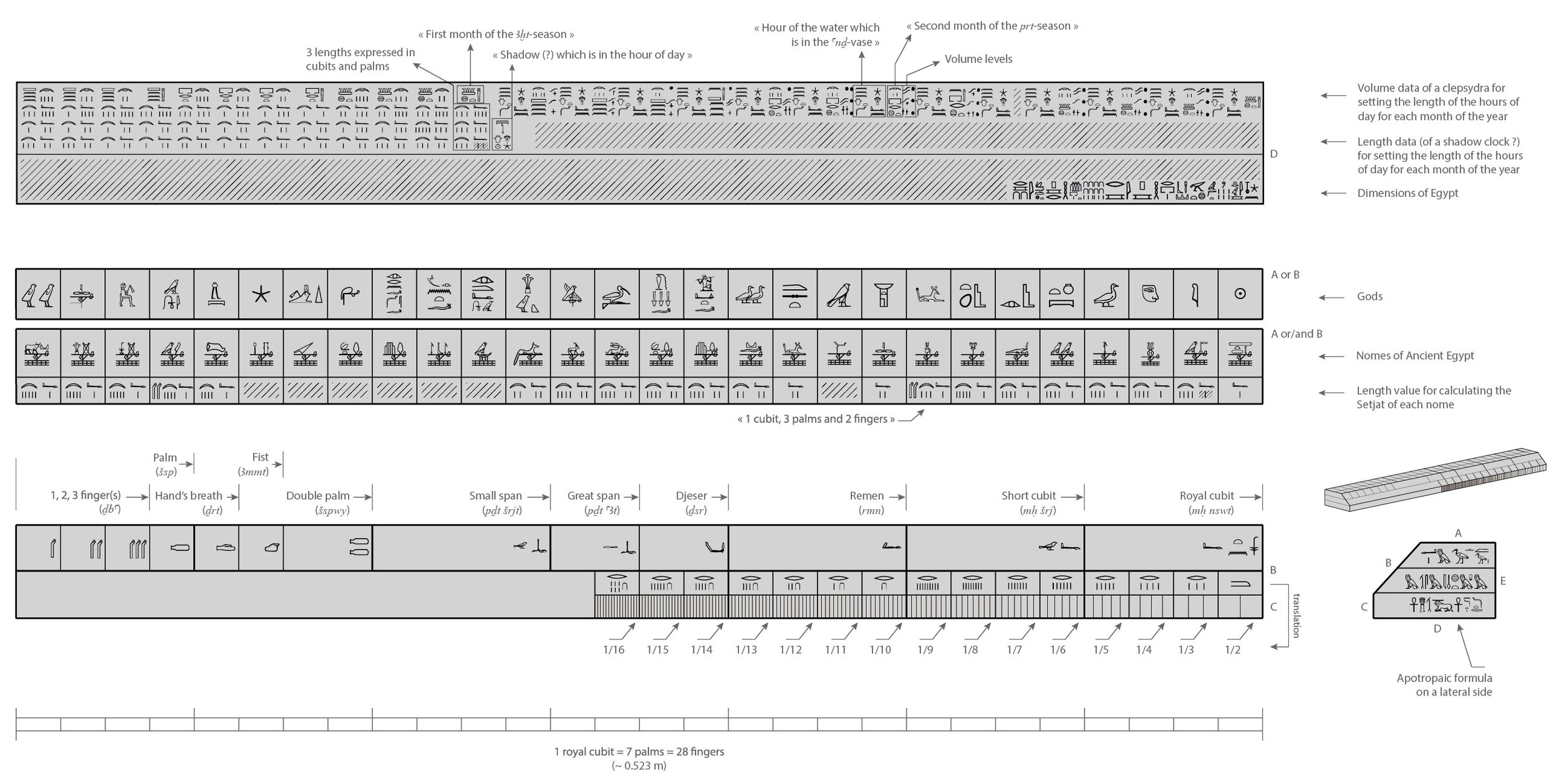
Digit-al Humanities
Visualizing New Kingdom units of measure (1500 - 1000 BCE) as they relate to one another
New elements have been introduced for the encoding of ruby annotations, a particular method of glossing runs of text which is common in East Asian scripts (#2054, with thanks to Kiyonori Nagasaki, Satoru Nakamura, Kazuhiro Okada, Duncan Paterson, and Martin Holmes):
The ruby element contains a passage of base text along with its associated ruby gloss(es).
The rb element contains the base text annotated by a ruby gloss.
The rt element contains a ruby text, an annotation closely associated with a passage of the main text.
A subsection on Ruby Annotations has been added, which is also referenced from several suitable places in the Guidelines.
With this first take we hope to initiate further discussion and the implementation of additional use cases.
Calls in the community for something more than an encoding of linguistic morphological gender
connected with personography and prosopography structures in the Guidelines.
<persona> available since 2016 as distinct from person.
TEI projects are better able to describe invented, performed identities.
Review state vs. trait encoding and discussion in Names, Dates, People, and Places chapter
New encoding features (October 2022)
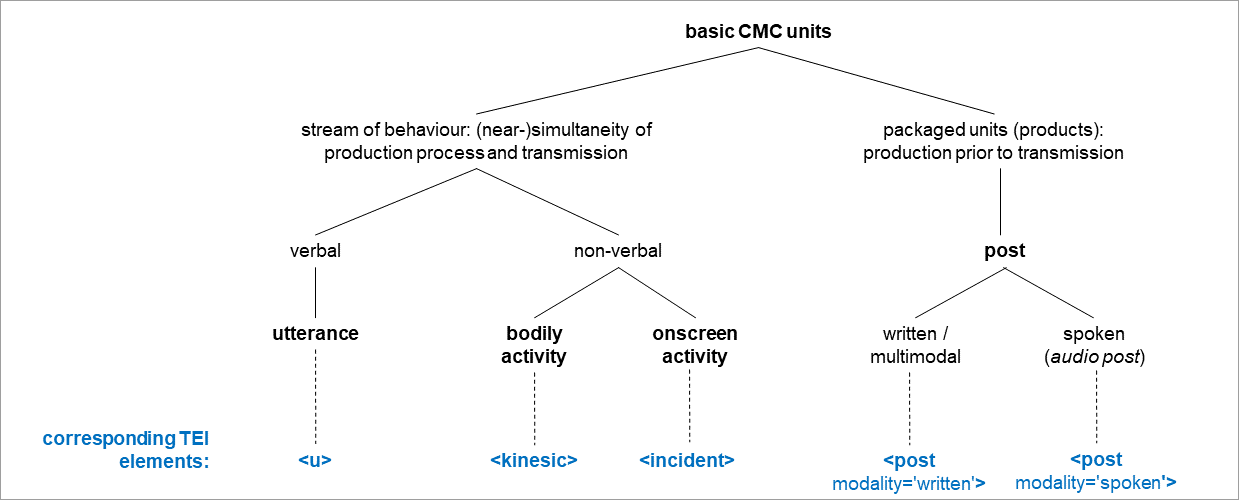
CMC data: Interactions of humans OR machines, mediated by machines
This special interest group seeks to create TEI encoding practices for various forms of digitally created content. It should also cover processable text on physical media. Some examples:
The Computable Text and Media SIG will likely intersect with other SIGs at some points (e.g. CMC and Correspondence). One of the challenges will be to elaborate neat and simple extensions and/or practices to generalize or broaden the scope of TEI to include specific aspects of computable text and media.
Convener: Torsten Roeder (Center for Philology and Digitality, University of Würzburg).
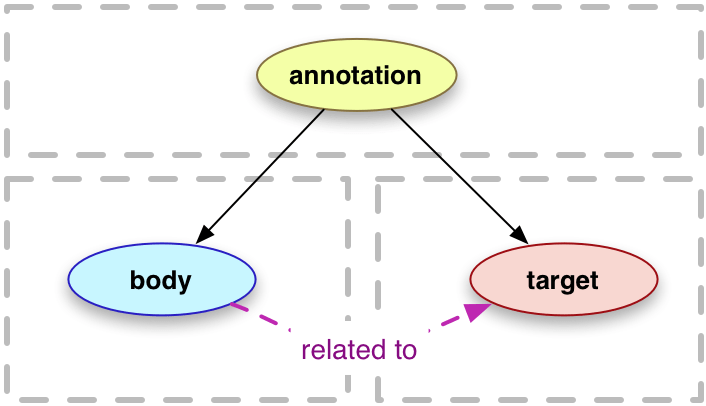
Related to w3C Web Annotation Model
See TEI ticket #1745: Led to the development of the <standoff> TEI element for expressing linked data
A cosmopolitan TEI makes itself aware of multiple formats, multiple languages, multiple approaches
Amadis in Translation project (https://newtfire.org/amadis/)
Amadis in Translation project (https://newtfire.org/amadis/)
Amadis in Translation project (https://newtfire.org/amadis/)
<cl xml:id="M0_p1_c63">
<milestone unit="said" resp="#Garinter" ana="start"/>No sin causa tiene/>.</cl>
<cl xml:id="M0_p1_c64">Esto hecho recogida toda la compaña hizo en dos
palafrenes cargar el león y el ciervo:</cl>
<cl xml:id="M0_p1_c65">y llevarlos a la villa con gran plazer.</cl>
<cl xml:id="M0_p1_c66">Donde siendo de tal huésped la reina avisada:</cl>
<cl xml:id="M0_p1_c67">los palacios de grandes y ricos atavíos/</cl>
<cl xml:id="M0_p1_c68"><seg xml:id="M0_p1_c68_1">y las mesas puestas</seg>
<seg xml:id="M0_p1_c68_2">hallaron:</seg></cl>
<cl xml:id="M0_p1_c69">en la una más alta se sentaron los reyes:</cl>
<cl xml:id="M0_p1_c70">y en otra junto con ella Elisena su hija:</cl>
<cl xml:id="M0_p1_c71">y allí fueron servidos como en casa de tan buen hombre
ser devía.</cl>Amadis in Translation project (https://newtfire.org/amadis/)
<cl xml:id="M0_p1_c63">
<milestone unit="said" resp="#Garinter" ana="start"/>No sin causa tiene/>.</cl>
<cl xml:id="M0_p1_c64">Esto hecho recogida toda la compaña hizo en dos
palafrenes cargar el león y el ciervo:</cl>
<cl xml:id="M0_p1_c65">y llevarlos a la villa con gran plazer.</cl>
<cl xml:id="M0_p1_c66">Donde siendo de tal huésped la reina avisada:</cl>
<cl xml:id="M0_p1_c67">los palacios de grandes y ricos atavíos/</cl>
<cl xml:id="M0_p1_c68"><seg xml:id="M0_p1_c68_1">y las mesas puestas</seg>
<seg xml:id="M0_p1_c68_2">hallaron:</seg></cl>
<cl xml:id="M0_p1_c69">en la una más alta se sentaron los reyes:</cl>
<cl xml:id="M0_p1_c70">y en otra junto con ella Elisena su hija:</cl>
<cl xml:id="M0_p1_c71">y allí fueron servidos como en casa de tan buen hombre
ser devía.</cl>Amadis in Translation project (https://newtfire.org/amadis/)
<p> <!-- <s> elements preceding -->
<s>
<anchor ana="start" type="add"/>When Garinter saw him fall,<anchor ana="end"/>
<anchor ana="start" corresp="#M0_p1_c62"/>he said within himself<anchor ana="end"/>
<anchor ana="start" corresp="#M0_p1_c63"/>not without cause is that Knight famed
to be the best in the world.<anchor ana="end"/>
</s>
<s>
<anchor ana="start" corresp="#M0_p1_c64"/>Meanwhile their train came up, and then
was their prey and venison laid on two horses<anchor ana="end"/>
<anchor ana="start" corresp="#M0_p1_c65"/>and carried to the City.<anchor ana="end"/>
</s>
</p>
Amadis in Translation project (https://newtfire.org/amadis/)
Alignment table showing passages added and omitted in Southey's translation
Amadis in Translation project (https://newtfire.org/amadis/)
Visualization (XSLT to SVG) as a diagram of aligned content, and proportions unique to Montalvo and Southey
新宿御苑橋
Shinjukugyoen-bashi
Frankenstein Variorum: https://frankensteinvariorum.org/
sample surface encoding from S-GA
<surface xmlns:mith="http://mith.umd.edu/sc/ns1#" lrx="3847" lry="5342"
partOf="#ox-frankenstein_volume_i" ulx="0" uly="0"
mith:folio="21r" mith:shelfmark="MS. Abinger c. 56"
xml:base="https://raw.githubusercontent.com/
umd-mith/sga/master/data/tei/ox/ox-ms_abinger_c56/ox-ms_abinger_c56-0045.xml"
xml:id="ox-ms_abinger_c56-0045">
<graphic url="http://shelleygodwinarchive.org/images/ox/ms_abinger_c56/ms_abinger_c56-0045.jp2"/>
<zone rend="bordered" type="pagination"><line>75</line></zone>
<zone type="library"><line>21</line></zone>
<!-- lines of text elided here -->
<line>to form. His limbs were in proportion</line>
<line>and I had selected his features <del rend="strikethrough">h</del> as</line>
<line><mod>
<del rend="strikethrough">handsome</del>
<del rend="unmarked">.</del>
<anchor xml:id="c56-0045.01"/>
</mod>
<mod>
<del rend="strikethrough">Handsome</del>
<add hand="#pbs" place="superlinear">Beautiful</add>
</mod>; Great God! His</line>
<!-- at the end of the surface encoding, encoding material in a left-margin zone: --->
<zone corresp="#c56-0045.01" type="left_margin">
<line><add><mod>
<del rend="strikethrough">handsome</del>
<add hand="#pbs" place="superlinear">beautiful.</add>
</mod></add></line>
</zone>
<!-- other marginal insertions encoded -->
</surface>Align and “chunk”
Prescribe rules to direct the machine-assisted collation
<p> "&" is not different from "and" Manuscript (from Shelley-Godwin Archive):
<lb n="c56-0045__main__2"/>It was on a dreary night of November
<lb n="c56-0045__main__3"/>that I beheld <del rend="strikethrough"
xml:id="c56-0045__main__d5e9572">
<add hand="#pbs" place="superlinear" xml:id="c56-0045__main__d5e9574">the frame on
whic</add></del> my man comple<del>at</del>
<add place="intralinear" xml:id="c56-0045__main__d5e9582">te</add>
<add xml:id="c56-0045__main__d5e9585">ed</add>1818 (from PA Electronic edition)
<p xml:id="novel1_letter4_chapter4_div4_div4_p1">I<hi>T</hi> was on a dreary
night of November, that I beheld the accomplishment of my toils.</p><del> and <p> markup<lb/> elements, attribute nodes<hi> elements as meaningful markup because sometimes they are meaningful for emphasis.MS (from Shelley-Godwin Archive):
["It", "was", "on", "a", "dreary",
"night", "of". "November", "that",
"I", "beheld"
"<del>the frame on whic</del>",
"my", "man",
"comple", "<del>at</del>", "teed"]1818 (from PA Electronic edition)
["<p>", "IT", "was", "on", "a", "dreary",
"night", "of", "November,", "that", "I", "beheld",
"the", "accomplishment", "of", "my", "toils.", "</p>"]Project decision: Treat a deletion as a complete and indivisible event:
a ”long token”. This helps to align other witnesses around it.
<app>
<rdgGrp n="['that', 'i', 'beheld']">
<rdg wit="f1818">that I beheld</rdg>
<rdg wit="f1823">that I beheld</rdg>
<rdg wit="fThomas">that I beheld</rdg>
<rdg wit="f1831">that I beheld</rdg>
<rdg wit="fMS"><lb n="c56-0045__main__3"/>that I beheld</rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['<del> the frame on whic</del>',
'my', 'man', 'comple',
'', '<mdel>at</mdel>', 'te', 'ed',
',', '.', '<del>and</del>']">
<rdg wit="fMS"><del rend="strikethrough"
xml:id="c56-0045__main__d5e9572">
<sga-add hand="#pbs" place="superlinear"
sID="c56-0045__main__d5e9574"/>the
frame on whic <sga-add eID="c56-0045__main__d5e9574"/> </del> my man
comple <mod sID="c56-0045__main__d5e9578"/>
<mdel>at</mdel>
<sga-add place="intralinear" sID="c56-0045__main__d5e9582"/>te
<sga-add eID="c56-0045__main__d5e9582"/>
<sga-add sID="c56-0045__main__d5e9585"/>ed
<sga-add eID="c56-0045__main__d5e9585"/>
<mod eID="c56-0045__main__d5e9578"/>
<sga-add hand="#pbs" place="intralinear"sID="c56-0045__main__d5e9588"/>,
<sga-add eID="c56-0045__main__d5e9588"/>.
<del rend="strikethrough"
xml:id="c56-0045__main__d5e9591">And</del></rdg>
</rdgGrp>
<rdgGrp n="['the', 'accomplishment', 'of', 'my', 'toils.']">
<rdg wit="f1818">the accomplishment of my toils.</rdg>
<rdg wit="f1823">the accomplishment of my toils.</rdg>
<rdg wit="fThomas">the accomplishment of my toils.</rdg>
<rdg wit="f1831">the accomplishment of my toils.</rdg>
</rdgGrp>
</app>
A Thomas copy edit of Letter IV at an early moment of intense revision
where the Creature comes to life in MS and Thomas
We made it from the "Standoff Spine" collation data:
XSLT transformation of TEI to SVG
So far this presentation has praised the TEI as “cosmopolitan”
Tokyo International Forum
Photo credit: David B. Cox, photographylife.com
<p xml:id="p_23.d1e747" xml:lang="ar">وما برحت الآمال معقودة بأن تبلغ الصحافة عما قليل أشدها ورشدها
<lb change="#d2e635 #d2e861" ed="print" edRef="#edition_1" xml:id="lb_9.d2e1448"/>
لتضاهي صحافة الأمم الراقية في موضوعاتها وتأثيراتها إذ أن العقلاء يذهبون
<lb change="#d2e808 #d2e861" ed="print" edRef="#edition_1" xml:id="lb_10.d2e1647"/>
إلى أن صحافتنا مازالت حالها على ما انتهت إليه غير متناسبة مع عمرها الطويل.
<lb change="#d2e808 #d2e861" ed="print" edRef="#edition_1" xml:id="lb_11.d2e1649"/>
والمعمر في الأعم من حالاته يشتد ساعده وزنده وتقوى ملكة عقله وعلمه
<lb change="#d2e808 #d2e861" ed="print" edRef="#edition_1" xml:id="lb_12.d2e1651"/>
بكثرة تجاربه وأسباب رويته. ولا خير في أمة لا يقوم بشؤونها شيوخ
<lb change="#d2e808 #d2e861" ed="print" edRef="#edition_1" xml:id="lb_13.d2e1653"/>
تفاخر بأعمالهم مفاخرتها بعقولهم وطول أعمارهم.</p>
Thank you for listening! Any questions?
ご清聴ありがとうございました!
何か質問はありますか?
Go seichō arigatōgozaimashita! Nanika shitsumon wa arimasu'ka?By Elisa Beshero-Bondar
The internationalization of the TEI and our understanding of text



