






Elisa Beshero-Bondar PRO
Professor of Digital Humanities and Chair of the Digital Media, Arts, and Technology Program at Penn State Erie, The Behrend College.
Elisa Beshero-Bondar
GitHub: @ebeshero | Mastodon: epyllia@indieweb.social
Balisage 2023
Link to these slides: https://bit.ly/declare-string
(a paper responding to a prediction that large language models will render descriptive markup unnecessary.)
John Tenniel's illustration of Humpty Dumpty talking to Alice about words
John Tenniel's illustration of Humpty Dumpty talking to Alice about word semantics
John Tenniel's illustration of Humpty Dumpty talking to Alice about word semantics
Manuscript (from Shelley-Godwin Archive):
<lb n="c56-0045__main__2"/>It was on a dreary night of November
<lb n="c56-0045__main__3"/>that I beheld <del rend="strikethrough"
xml:id="c56-0045__main__d5e9572">
<add hand="#pbs" place="superlinear" xml:id="c56-0045__main__d5e9574">the frame on
whic</add></del> my man comple<del>at</del>
<add place="intralinear" xml:id="c56-0045__main__d5e9582">te</add>
<add xml:id="c56-0045__main__d5e9585">ed</add>1818 (from PA Electronic edition)
<p xml:id="novel1_letter4_chapter4_div4_div4_p1">I<hi>T</hi> was on a dreary
night of November, that I beheld the accomplishment of my toils.</p><del> and <p> markup<lb/> elements, attribute nodes<hi> elements as meaningful markup because sometimes they are meaningful for emphasis.MS (from Shelley-Godwin Archive):
It was on a dreary night of November that I beheld
<del>the frame on whic</del> my man
comple<del>at</del>teed1818 (from PA Electronic edition)
<p>IT was on a dreary
night of November, that I beheld
the accomplishment of my toils.</p>MS (from Shelley-Godwin Archive):
["It", "was", "on", "a", "dreary",
"night", "of". "November", "that",
"I", "beheld"
"<del>the frame on whic</del>",
"my", "man",
"comple", "<del>at</del>", "teed"]1818 (from PA Electronic edition)
["<p>", "IT", "was", "on", "a", "dreary",
"night", "of", "November,", "that", "I", "beheld",
"the", "accomplishment", "of", "my", "toils.", "</p>"]Project decision: Treat a deletion as a complete and indivisible event:
a ”long token”. This helps to align other witnesses around it.
(Embedded markup is a little more complicated than our previous example)
<app>
<rdgGrp n="['that', 'i', 'beheld']">
<rdg wit="f1818">that I beheld</rdg>
<rdg wit="f1823">that I beheld</rdg>
<rdg wit="fThomas">that I beheld</rdg>
<rdg wit="f1831">that I beheld</rdg>
<rdg wit="fMS"><lb n="c56-0045__main__3"/>that I beheld</rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['<del> the frame on whic</del>',
'my', 'man', 'comple',
'', '<mdel>at</mdel>', 'te', 'ed',
',', '.', '<del>and</del>']">
<rdg wit="fMS"><del rend="strikethrough"
xml:id="c56-0045__main__d5e9572">
<sga-add hand="#pbs" place="superlinear"
sID="c56-0045__main__d5e9574"/>the
frame on whic <sga-add eID="c56-0045__main__d5e9574"/> </del> my man
comple <mod sID="c56-0045__main__d5e9578"/>
<mdel>at</mdel>
<sga-add place="intralinear" sID="c56-0045__main__d5e9582"/>te
<sga-add eID="c56-0045__main__d5e9582"/>
<sga-add sID="c56-0045__main__d5e9585"/>ed
<sga-add eID="c56-0045__main__d5e9585"/>
<mod eID="c56-0045__main__d5e9578"/>
<sga-add hand="#pbs" place="intralinear"sID="c56-0045__main__d5e9588"/>,
<sga-add eID="c56-0045__main__d5e9588"/>.
<del rend="strikethrough"
xml:id="c56-0045__main__d5e9591">And</del></rdg>
</rdgGrp>
<rdgGrp n="['the', 'accomplishment', 'of', 'my', 'toils.']">
<rdg wit="f1818">the accomplishment of my toils.</rdg>
<rdg wit="f1823">the accomplishment of my toils.</rdg>
<rdg wit="fThomas">the accomplishment of my toils.</rdg>
<rdg wit="f1831">the accomplishment of my toils.</rdg>
</rdgGrp>
</app>That ugly but orderly and information-rich combination of "flattened" tags and markup is the basis for all the visualized interfaces we build in our digital edition, the Frankenstein Variorum.
An SVG visualization showing comparative lengths of each collation unit, constructed from collation XML output
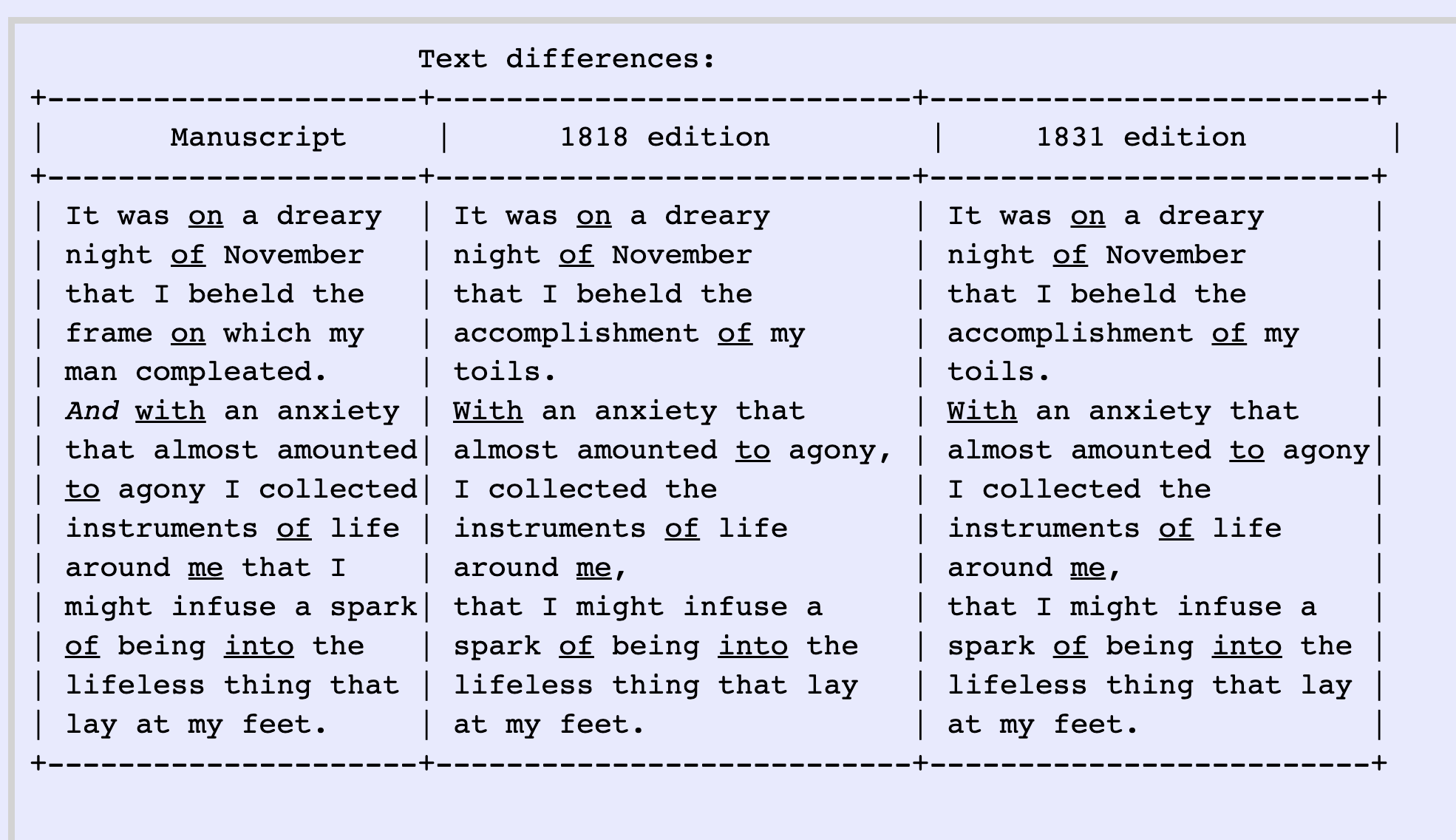
Can you prepare a data structure to show where these texts are the same and where they differ?
Manuscript: It was on a dreary night of November that I beheld the frame on which my man compleated. And with an anxiety that almost amounted to agony I collected instruments of life around me that I might infuse a spark of being into the lifeless thing that lay at my feet.
1818 edition and 1831 edition: It was on a dreary night of November, that I beheld the accomplishment of my toils. With an anxiety that almost amounted to agony, I collected the instruments of life around me, that I might infuse a spark of being into the lifeless thing that lay at my feet.
1818 edition and 1831 edition: It was on a dreary night of November, that I beheld the accomplishment of my toils. With an anxiety that almost amounted to agony, I collected the instruments of life around me, that I might infuse a spark of being into the lifeless thing that lay at my feet.
Manuscript: It was on a dreary night of November that I beheld the frame on which my man compleated. And with an anxiety that almost amounted to agony I collected instruments of life around me that I might infuse a spark of being into the lifeless thing that lay at my feet.
+---------------------+---------------------------+-------------------------+
| Manuscript | 1818 edition | 1831 edition |
+---------------------+---------------------------+-------------------------+
| It was on a dreary | It was on a dreary | It was on a dreary |
| night of November | night of November | night of November |
| that I beheld the | that I beheld the | that I beheld the |
| frame on which my | accomplishment of my | accomplishment of my |
| man compleated. | toils. | toils. |
| And with an anxiety | With an anxiety that | With an anxiety that |
| that almost amounted| almost amounted to agony, | almost amounted to agony|
| to agony I collected| I collected the | I collected the |
| instruments of life | instruments of life | instruments of life |
| around me that I | around me, | around me, |
| might infuse a spark| that I might infuse a | that I might infuse a |
| of being into the | spark of being into the | spark of being into the |
| lifeless thing that | lifeless thing that lay | lifeless thing that lay |
| lay at my feet. | at my feet. | at my feet. |
+---------------------+---------------------------+-------------------------+
Nothing is wrong with this, but it leaves the comparison to the reader. It doesn't mark the moments of variance.
Elisa: Let's try to refine this. Where the texts are identical, just show one block of text on the screen. Then when the texts are different, use the table to put the differences side by side.
ChatGPT: Sure! Let's refine the representation to show the identical text blocks once and use a table to display the differing portions side by side. Here's an updated representation:
In this refined representation, the identical text block "It was on a dreary night of November" is displayed once at the top, indicating that this portion is the same in all versions. The table below then shows the differing text portions side by side, highlighting the variations between the Manuscript, 1818 edition, and 1831 edition.
Elisa: Your approach is what I had in mind, good. But you've forgotten where the source texts are different. Can you redo this, taking another look at the source texts?
Manuscript: It was on a dreary night of November that I beheld the frame on which my man compleated. And with an anxiety that almost amounted to agony I collected instruments of life around me that I might infuse a spark of being into the lifeless thing that lay at my feet.
1818 edition and 1831 edition: It was on a dreary night of November, that I beheld the accomplishment of my toils. With an anxiety that almost amounted to agony, I collected the instruments of life around me, that I might infuse a spark of being into the lifeless thing that lay at my feet.
ChatGPT: Apologies for the oversight. Let's revise the representation to include the differing portions as well. Here's the updated version:
In this refined representation, we have the text differences table with the Manuscript, 1818 edition, and 1831 edition side by side. The portions that are the same in all versions are omitted for brevity, and only the differing sections are displayed.
(Wha-at? you didn't omit anything!)
Elisa: You are preparing a critical edition in TEI using critical apparatus markup. Can you prepare a sample of code for comparing two editions based on the following three versions of the same passage?
Manuscript: It was on a dreary night of November that I beheld the frame on which my man compleated. And with an anxiety that almost amounted to agony I collected instruments of life around me that I might infuse a spark of being into the lifeless thing that lay at my feet.
1818 edition and 1831 edition: It was on a dreary night of November, that I beheld the accomplishment of my toils. With an anxiety that almost amounted to agony, I collected the instruments of life around me, that I might infuse a spark of being into the lifeless thing that lay at my feet.
1818 edition and 1831 edition: It was on a dreary night of November, that I beheld the accomplishment of my toils. With an anxiety that almost amounted to agony, I collected the instruments of life around me, that I might infuse a spark of being into the lifeless thing that lay at my feet.
Manuscript: It was on a dreary night of November that I beheld the frame on which my man compleated. And with an anxiety that almost amounted to agony I collected instruments of life around me that I might infuse a spark of being into the lifeless thing that lay at my feet.
Claude.ai: Here is a sample TEI encoding of the critical apparatus comparing those three versions of the passage:
<p>It was on a dreary night of November, that I beheld the
<app>
<rdg wit="#MS">frame on which my man compleated</rdg>
<rdg wit="#1818 #1831">accomplishment of my toils</rdg>.
</app>
With an anxiety that almost amounted to agony, I collected the instruments of
life around me, that I might infuse a spark of being into the lifeless thing that
lay at my feet.</p>The <app> elements contain the variants, with each <rdg> containing the text as it appears in each witness. The witnesses are identified in the wit attributes using shorthand labels (#MS for the manuscript, #1818 and #1831 for the two editions). This allows you to encode the differences between the versions in a structured way. Additional notes or details about the variants could also be added in the encoding.
Elisa: There's at least one error in your critical apparatus, if we're being strict about punctuation differences. Can you catch and correct it?
Claude.ai: You're right, my initial sample critical apparatus overlooked a punctuation difference between the manuscript and editions. Let me take another look and update the encoding:
<p>It was on a dreary night of November, that I beheld the
<app>
<rdg wit="#MS">frame on which my man compleated</rdg>
<rdg wit="#1818 #1831">accomplishment of my toils</rdg>.
</app>
With an anxiety that almost amounted to agony, I collected the instruments of life
around me, that I might infuse a spark of being into the lifeless thing that lay
<app>
<rdg wit="#MS">at my feet</rdg>
<rdg wit="#1818 #1831">at my feet.</rdg>
</app>
</p>Claude.ai:
The editions end the sentence with a period, while the manuscript does not. To accurately encode the differences, I've wrapped the final punctuation in an <app> element as well. Thanks for catching my oversight! Proper encoding requires accounting for all variations, including minor punctuation.
( ...no, that wasn't a real difference...)
Elisa: That wasn't the difference. Both sets of witnesses do end with a period. It's a different moment in the text...
Claude.ai: You're absolutely right, my apologies. Let me take another careful look at the punctuation in the passages:
The key difference is that the manuscript has a comma after "November", while the 1818 and 1831 editions do not. Here is the corrected encoding.
<p>It was on a dreary night of November<app>
<rdg wit="#MS">,</rdg>
<rdg wit="#1818 #1831" />
</app> that I beheld the
<app>
<rdg wit="#MS">frame on which my man compleated</rdg>
<rdg wit="#1818 #1831">accomplishment of my toils</rdg>.
</app>
With an anxiety that almost amounted to agony,
I collected the instruments of life around me,
that I might infuse a spark of being into the
lifeless thing that lay at my feet.</p>Claude.ai's TEI apparatus (take 2)
(...Claude has this backwards: 1818 and 1831 have the comma, and the MS lacks it.
Why does it make that mistake?)
Talking to an LLM chat bot seems declarative...
...but the declarative semantics of a prompt are slippery, inconsistently processed.
Declarative semantics make it possible to reason about representations; imperative semantics impede.
The technology of descriptive markup
is not value-free or value-neutral
A stochastic parrot?
Source: Midjourney prompted by THE DECODER, from
https://the-decoder.com/language-models-defy-stochastic-parrot-narrative-display-semantic-learning/
A stochastic parrot?
Source: Midjourney prompted by THE DECODER, from
https://the-decoder.com/language-models-defy-stochastic-parrot-narrative-display-semantic-learning/
inlineVariationEvent = ['head', 'del', 'mdel', 'add', 'note', 'longToken']Python variable storing a list of "longToken" element names for special treatment in tokenizing
Our Python processing supplies each of these flattened nodes as a single complete indivisible "token" for collation
inlineVariationEvent = ['head', 'del', 'mdel', 'add', 'note', 'longToken']
ignore = ['sourceDoc', 'xml', 'comment', 'include',
'addSpan', 'handShift', 'damage',
'unclear', 'restore', 'surface', 'zone', 'retrace']Python variable storing a list of element names to ignore
Our Python processing skips over these flattened nodes, not feeding them to the collation software.
def extract(input_xml):
"""Process entire input XML document, firing on events"""
doc = pulldom.parse(input_xml)
output = ''
for event, node in doc:
if event == pulldom.START_ELEMENT and node.localName in ignore:
continue
# ebb: The following handles our longToken and longToken-style elements:
# complete element nodes surrounded by newline characters
# to make a long complete token:
if event == pulldom.START_ELEMENT and node.localName in inlineVariationEvent:
doc.expandNode(node)
output += '\n' + node.toxml() + '\n'
# stops the problem of forming tokens that fuse element tags to words.
elif event == pulldom.START_ELEMENT and node.localName in blockEmpty:
output += '\n' + node.toxml() + '\n'
# ebb: empty inline elements that do not take surrounding white spaces:
elif event == pulldom.START_ELEMENT and node.localName in inlineEmpty:
output += node.toxml()
# non-empty inline elements: mdel, shi, metamark
elif event == pulldom.START_ELEMENT and node.localName in inlineContent:
output += '\n' + regexEmptyTag.sub('>', node.toxml())
# output += '\n' + node.toxml()
elif event == pulldom.END_ELEMENT and node.localName in inlineContent:
output += '</' + node.localName + '>' + '\n'
# elif event == pulldom.START_ELEMENT and node.localName in blockElement:
# output += '\n<' + node.localName + '>\n'
# elif event == pulldom.END_ELEMENT and node.localName in blockElement:
# output += '\n</' + node.localName + '>'
elif event == pulldom.CHARACTERS:
# output += fixToken(normalizeSpace(node.data))
output += normalizeSpace(node.data)
else:
continue
return output<app>
<rdgGrp n="['<del>to his statement, which was delivered</del>',
'to him with interest for he spoke']">
<rdg wit="fThomas"><del rend="strikethrough">to his statement,
which was delivered</del> <add>to him with interest
for he spoke</add></rdg>
</rdgGrp>
<rdgGrp n="['to his statement, which was delivered']">
<rdg wit="f1818"><longToken>to his statement, which was
delivered</longToken></rdg>
<rdg wit="f1823"><longToken>to his statement, which was
delivered</longToken></rdg>
<rdg wit="f1831"><longToken>to his statement, which was
delivered</longToken></rdg>
</rdgGrp>
</app>Notice:
<longToken> elements in the <rdg> text nodes
<rdgGrp> elements shows the basis for comparison: the normalized version delivered to the collation software
<longToken> and <add> elements because we decided these tags were not relevant to the comparison.
Kordjamshidi P, Roth D, Kersting K., "Declarative Learning-Based Programming as an Interface to AI Systems," Frontiers in Artifical Intelligence 5:755361, 2022 Mar 14. doi:10.3389/frai.2022.755361. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8967162/
The earlier AI problem solvers were expert systems that attempted to model the way experts reason and make decisions using a set of logical rules. Programming languages like Lisp and Prolog were designed to make programming such systems easy even for non-expert users. The idea was to represent the domain knowledge using a set of logical rules, and use the rules in a logical reasoning process hidden from the programmers.
. . .
The expert programs could go beyond an independent set of rules and turn to logical programs with a Turing-complete expressivity, supporting logical inference, for example, by unification and resolution.
Kordjamshidi P, Roth D, Kersting K., "Declarative Learning-Based Programming as an Interface to AI Systems," Frontiers in Artifical Intelligence 5:755361, 2022 Mar 14. doi:10.3389/frai.2022.755361. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8967162/
...We emphasize the need to use some fundamental declarative ideas such as first-order query languages, knowledge representation and reasoning techniques, programming languages for multi agent systems, database management systems (DBMS), and deductive databases (DDB). We need to place these ideas within and around ML formalisms including classical ML tools, deep learning libraries and automatic differentiation tools, and integrate them with innovative programming languages and software development techniques, as a way to address complex real-world problems that require both learning and reasoning models.
Could a text-generative AI system operate in a fully declarative way, or even just a more declarative way?
For my little collation experiment:
Thanks for listening!
What do you think?
By Elisa Beshero-Bondar
Slides on a talk about the significance of declarative markup during a time of AI driven by large language models. For presentation at Balisage: The Markup Conference, 2023.


