






















Elisa Beshero-Bondar PRO
Professor of Digital Humanities and Chair of the Digital Media, Arts, and Technology Program at Penn State Erie, The Behrend College.
DH 2024 Reinvention & Responsibility, Washington, DC
Panel: Unpacking the Past, Building the Future: Navigating the Complexities of Textual Analysis and Editions
8 August 2024, 8:30 - 10am, George Mason U.: Van Metre Hall 121
Link to these slides: https://bit.ly/fv-dh24
| Elisa Beshero-Bondar | Raffaele Viglianti | Yuying Jin |
| @ebeshero | @raffazizzi | @yuying-jin |
Most immediate context: Darwin Online (ed. Barbara Bordalejo), except...
James Rieger, ed., first new edition of 1818 in 141
years : inline collation of "Thomas" w/ 1818,
1831 variants in endnotes
Legend:
Stuart Curran and Jack Lynch: PA Electronic Edition (PAEE) , collation of 1818 and 1831: HTML
Nora Crook crit. ed of 1818, variants of "Thomas", 1823, and 1831 in endnotes (P&C MWS collected works)
Romantic Circles TEI conversion of PAEE ; separates the texts of 1818 and 1831; collation via Juxta
1974
~mid-1990s
1996
Charles Robinson, The Frankenstein Notebooks (Garland): print facsimile of 1816 ms drafts
2007
Shelley-Godwin Archive publishes diplomatic edition of 1816 ms drafts
print edition
digital edition
Legend:
2013
2017
Frankenstein Variorum Project begins
assembly/proof-correcting of PAEE files; OCR/proof-correcting 1823; "bridge" TEI edition of S-GA notebook files; automated collation; incorporating "Thomas" copy text. Collation project completed in 2023, Variorum viewer officially launches in 2024.
<add>, <del>, <note> elements showing Thomas marginaliaAlign and “chunk”
Prescribe rules to direct the machine-assisted collation
<milestone type='paragraph'> is same as <p> "&" is not different from "and"Background image created by the author from a loom on Reddit and the frontispiece illustration of Frankenstein (1831)
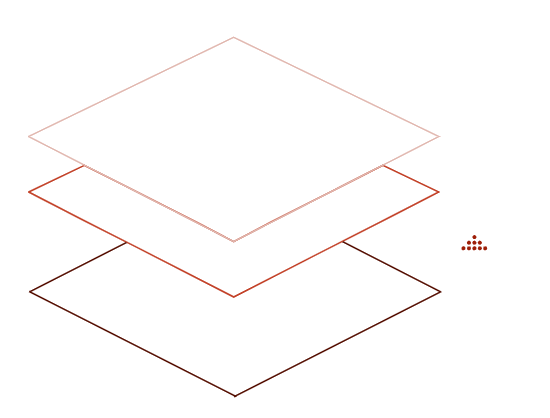
Legend
MS
1818
Thm
1823
1831
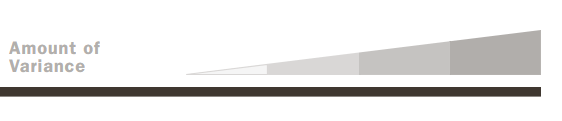
gaps, alignments, relative string-length for each ”chunk”
Heatmap navigator for the Frankenstein Variorum
How did we make this?
Out of the "Spine" data!
XSLT => SVG
See our Method page for details.
And if you want to learn more about collation and text processing, check out this nifty
"Flattening and Raising" slideshow.
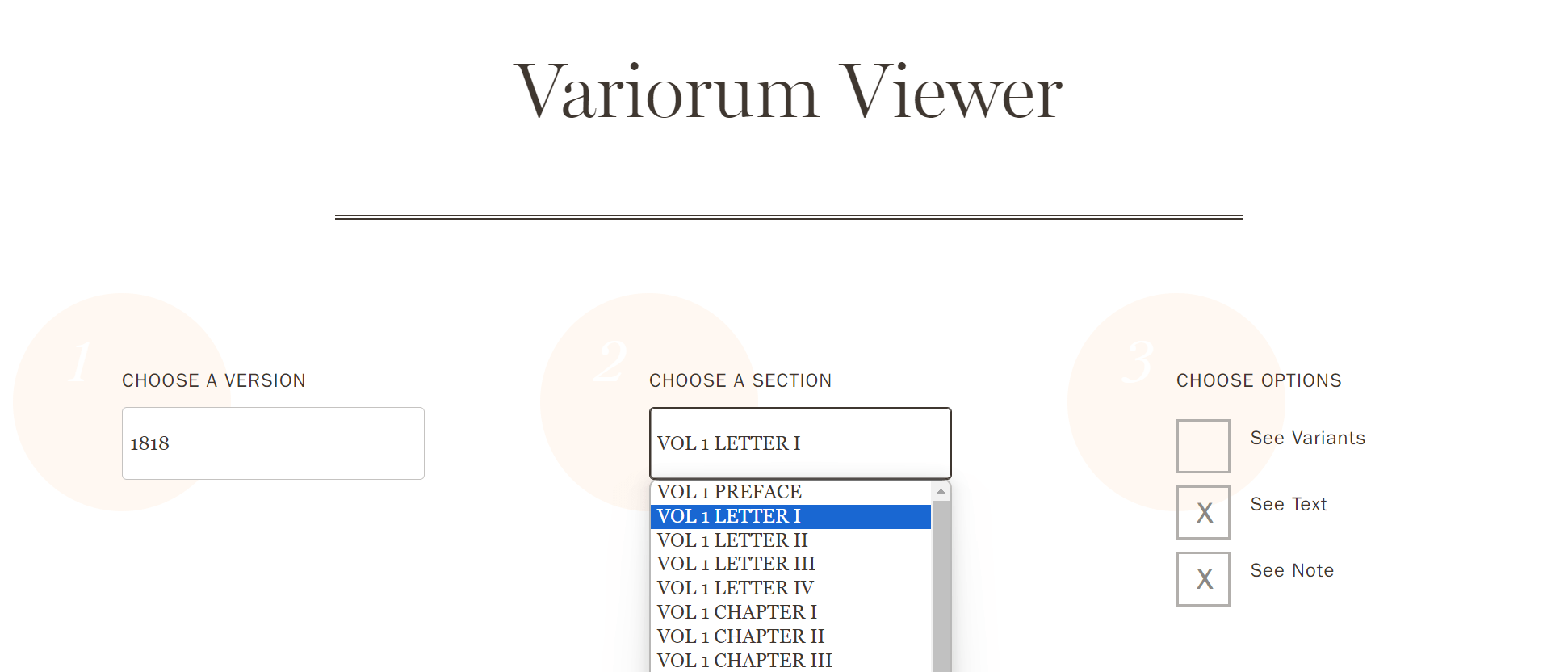
Selectors
Hot Spots
Variations
1823
Thomas
Publishing a typical TEI digital scholarly edition, today
Browser, UI & UX
Webapp logic
Database
Server
“not all projects should be maintained in perpetuity. Some are ... not worth the intellectual, technical, and financial overhead of ongoing maintenance.”
(Smithies et al. 2019)
Smithies, James, Carina Westling, Anna-Maria Sichani, Pam Mellen, and Arianna Ciula. 2019. “Managing 100 Digital Humanities Projects: Digital Scholarship & Archiving in King’s Digital Lab.” Digital Humanities Quarterly 013 (1).
Those in charge of infrastructure are also determining, particularly in the long term, the scholarly worth of a project, whether it should remain online, and in what form.
Less infrastructure: a static site approach from the start
Browser, UI & UX
Static site
generator
Server
Low infrastructure approach: inspiration
Endings Project
Minimal Computing
The Variorum's Front End Stack
Summary of technologies at each stage of the FV project
Details on our Method page: https://frankensteinvariorum.org/method/
Link to these slides: https://bit.ly/fv-dh24
Dive in and explore (mobile friendly): https://frankensteinvariorum.org/
By Elisa Beshero-Bondar
Presentation for the DH2024 conference on the now complete Frankenstein Variorum project, with emphasis on theory of edition as expressed in the structure and interface.



