







Elisa Beshero-Bondar PRO
Professor of Digital Humanities and Chair of the Digital Media, Arts, and Technology Program at Penn State Erie, The Behrend College.
David J. Birnbaum, Elisa Beshero-Bondar, and C. M. Sperberg-McQueen
Balisage 2018
Full paper connected with this slideshow presentation: https://www.balisage.net/Proceedings/vol21/html/Birnbaum01/BalisageVol21-Birnbaum01.html
<?xml version="1.0" encoding="UTF-8"?>
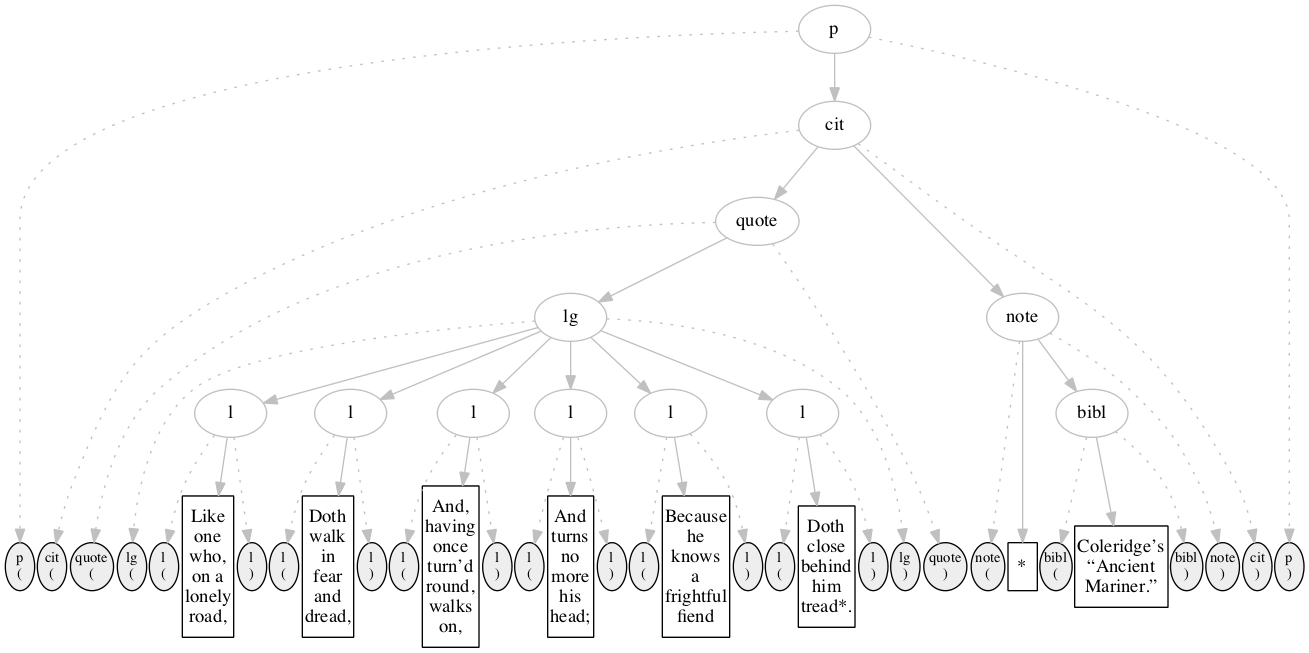
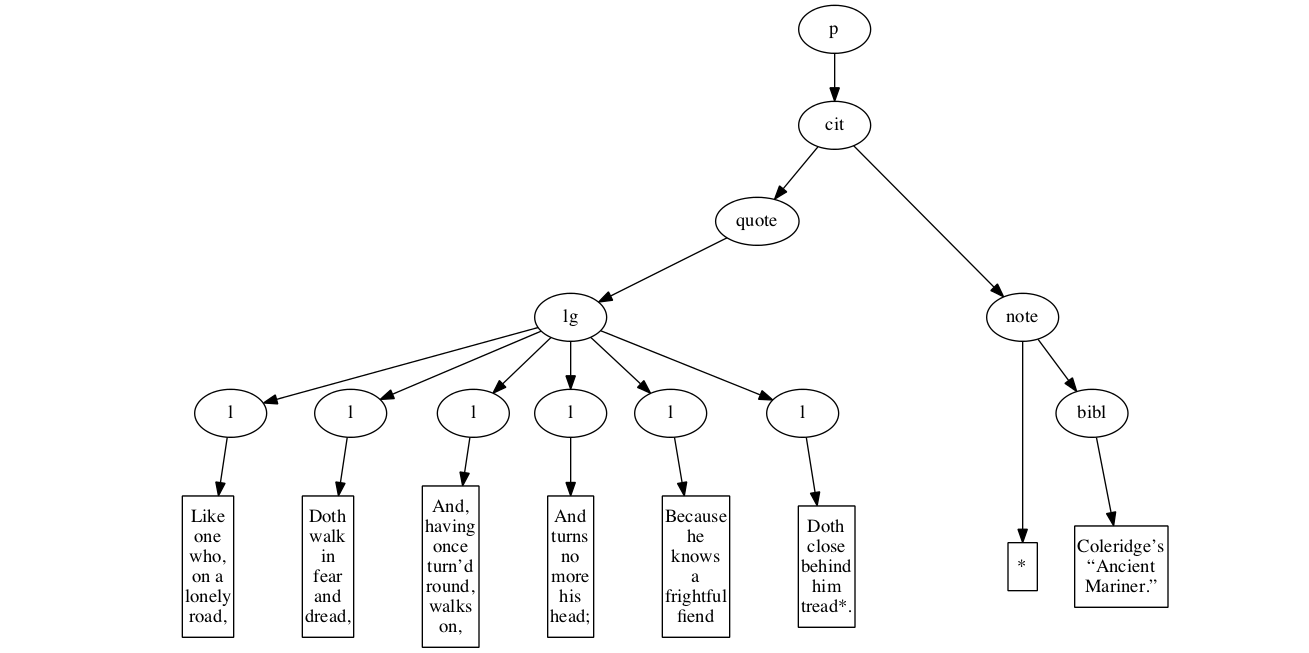
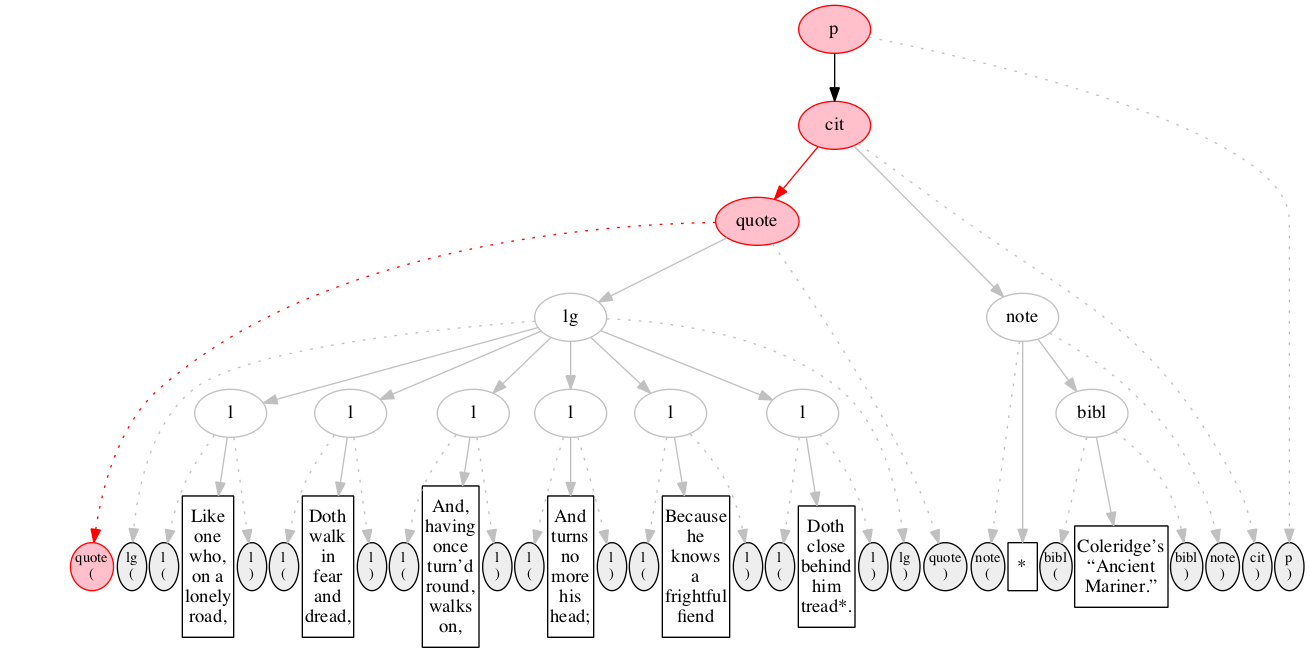
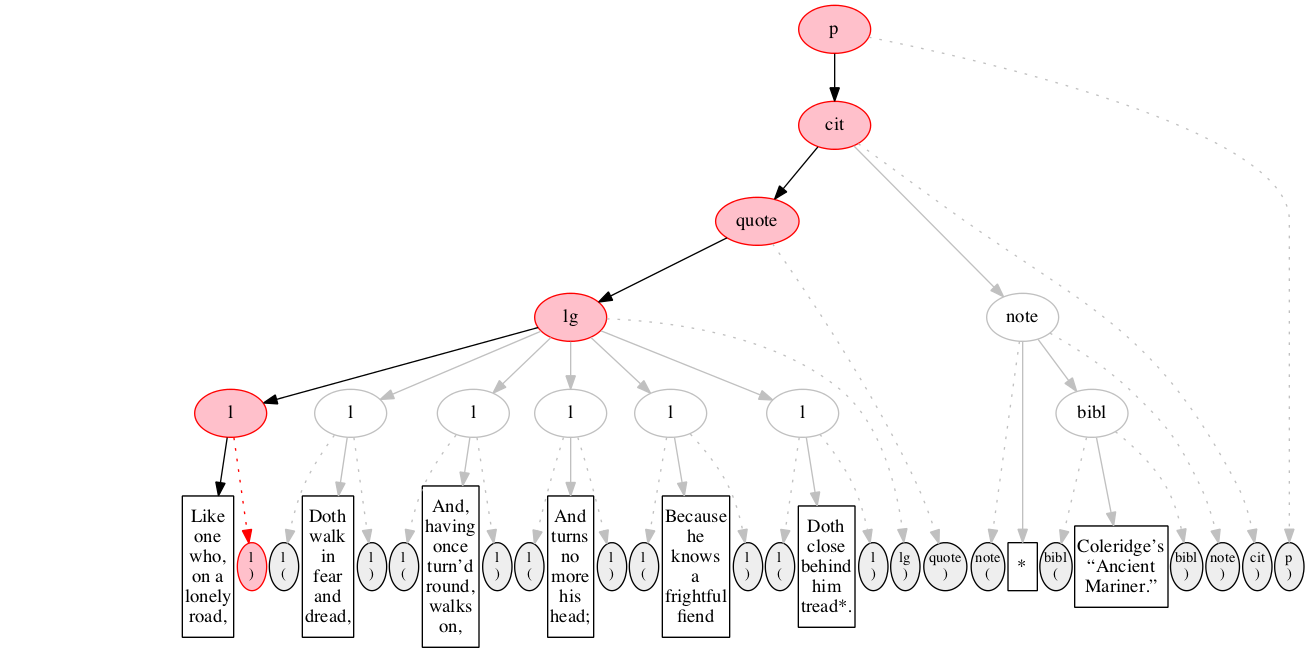
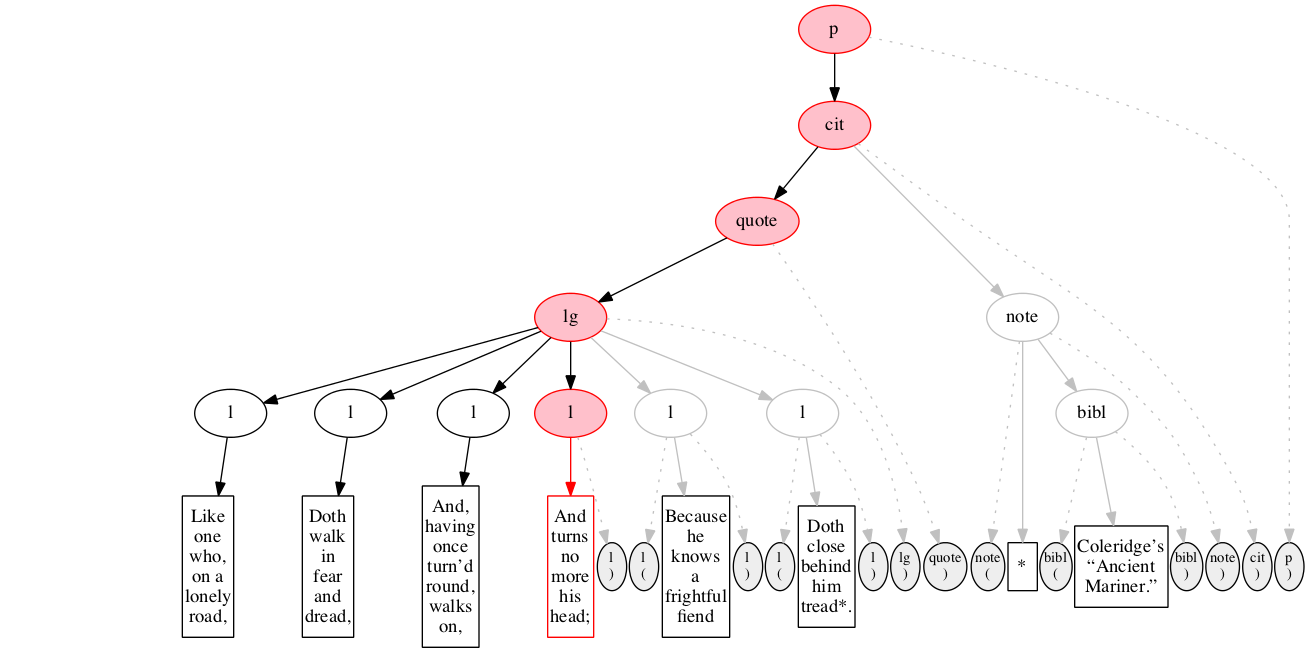
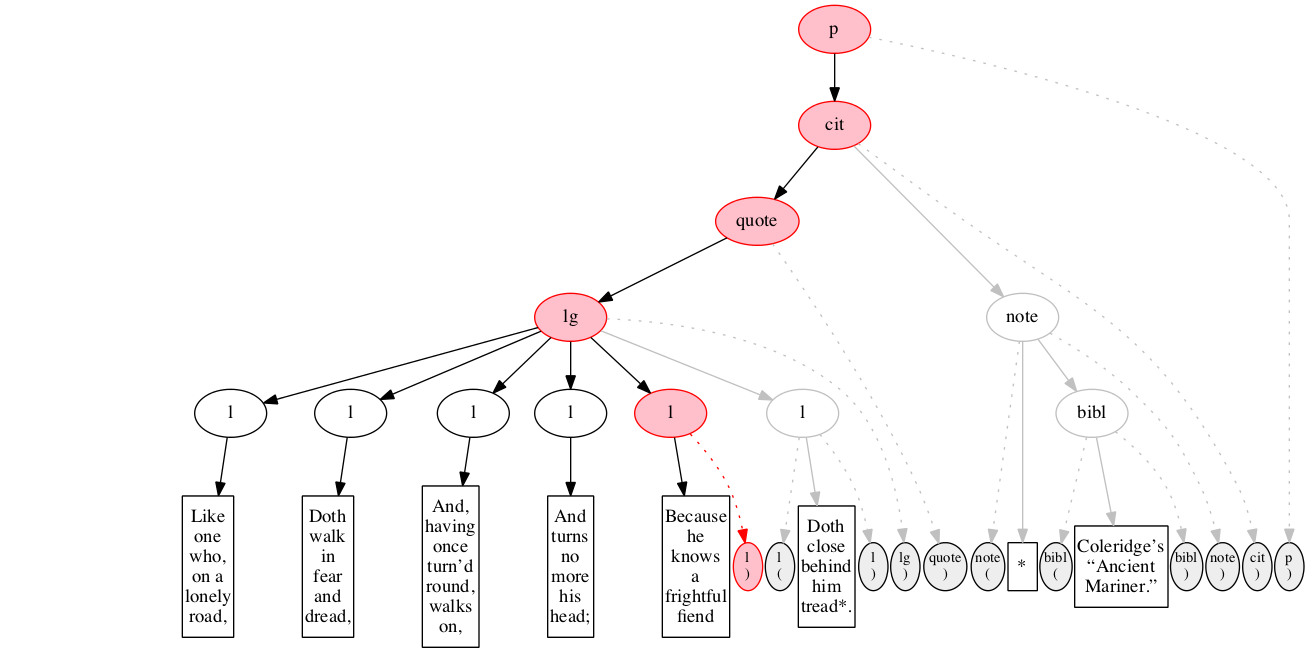
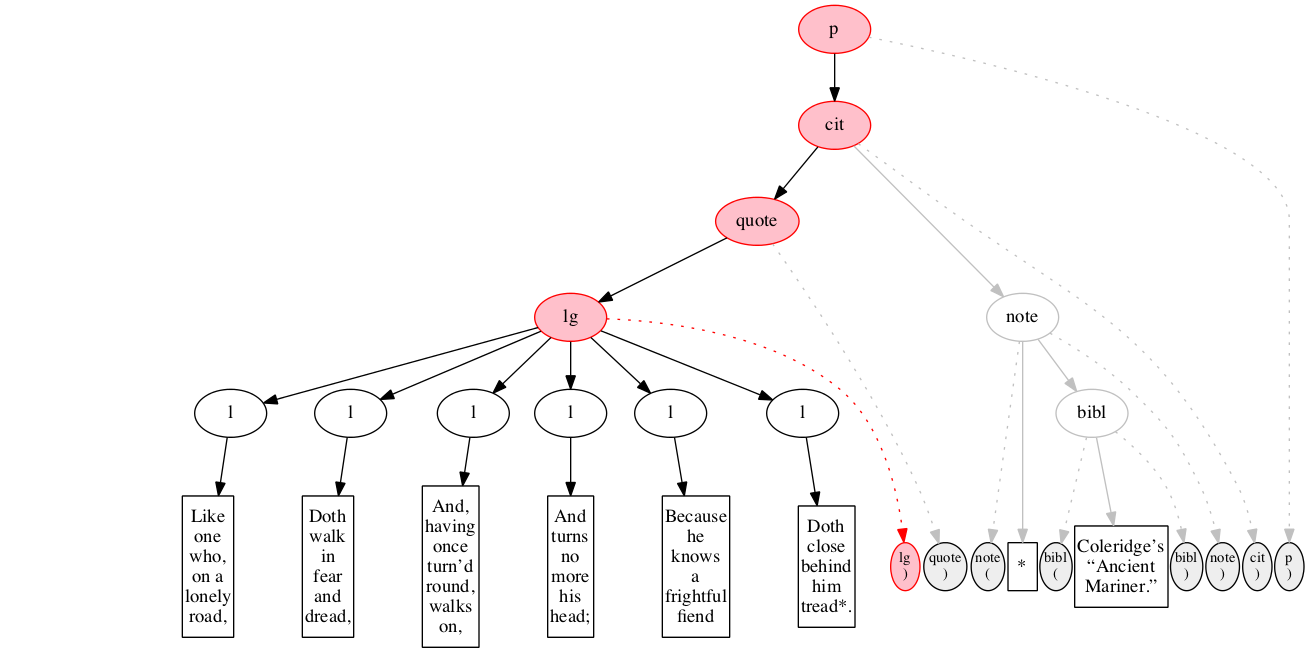
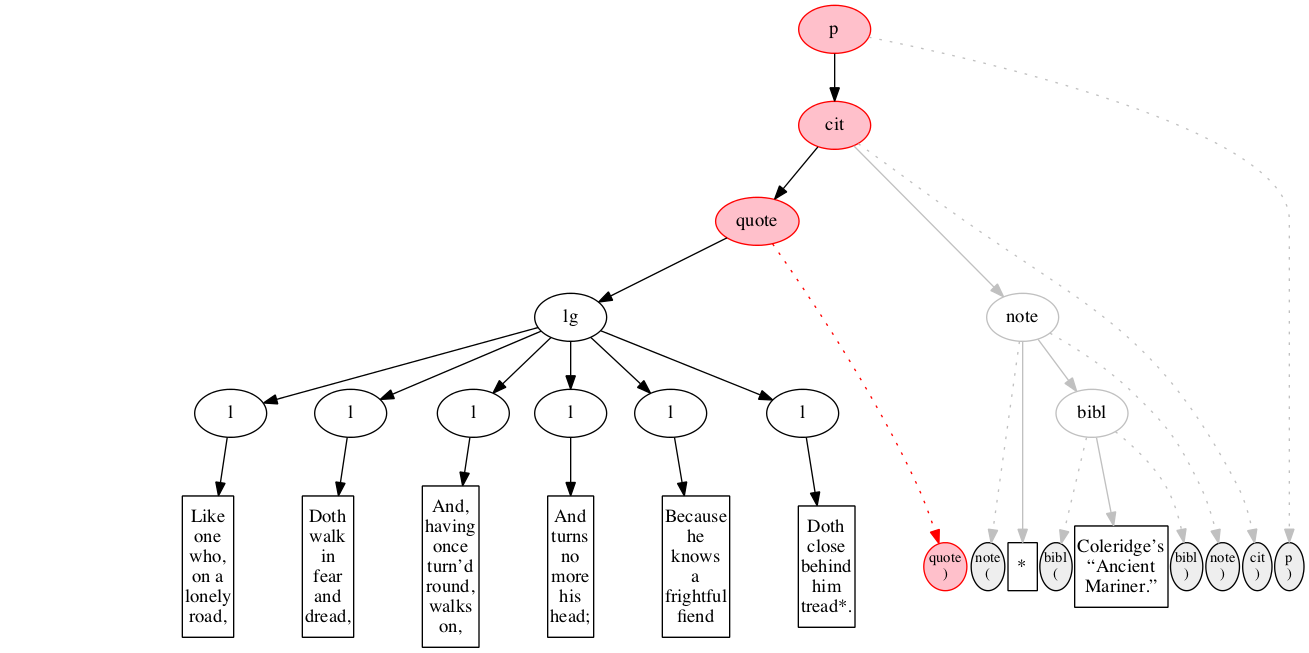
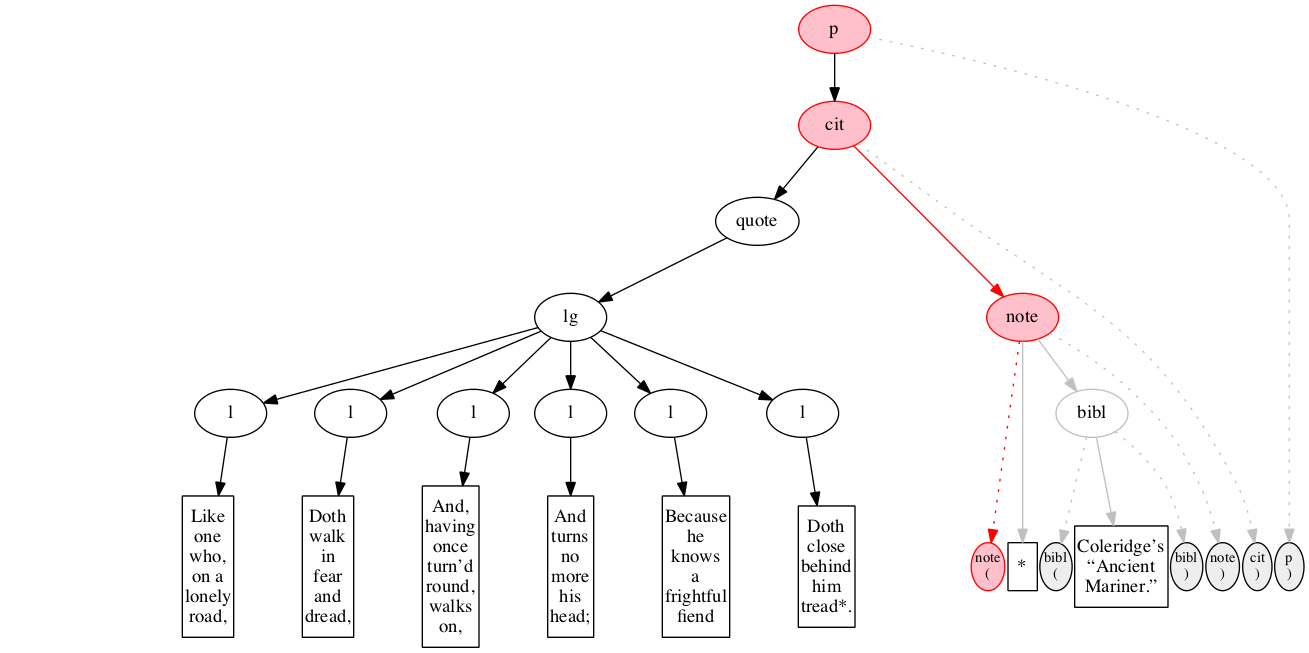
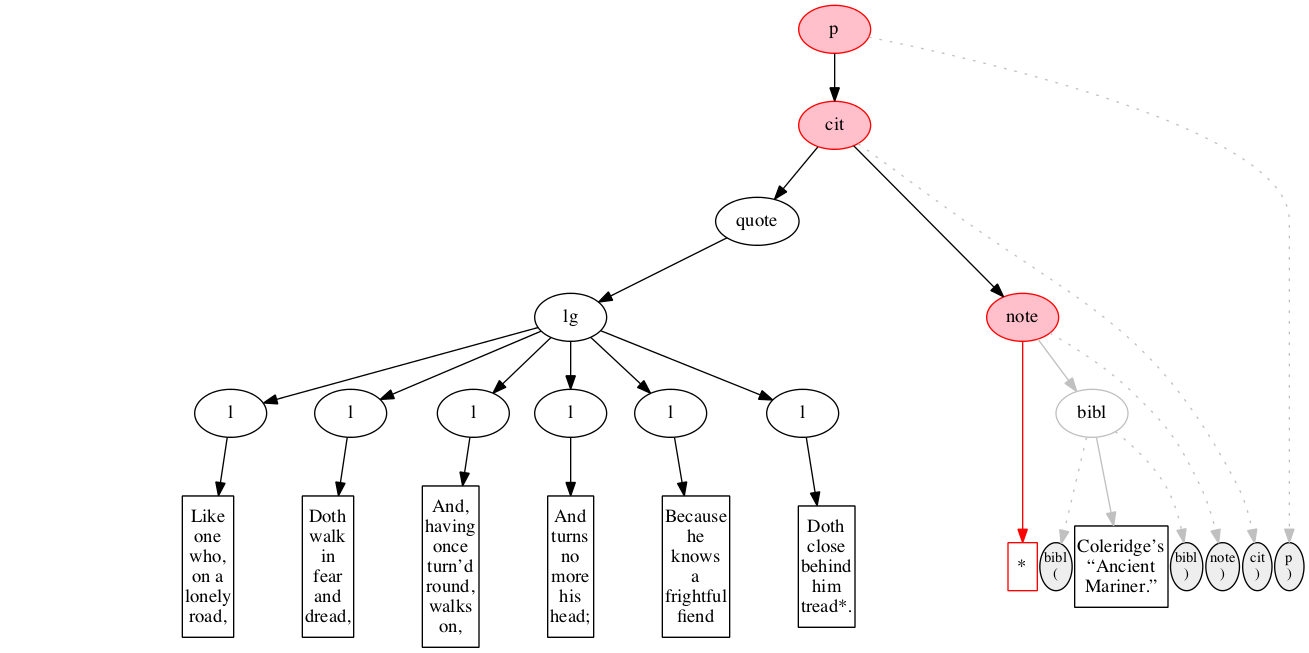
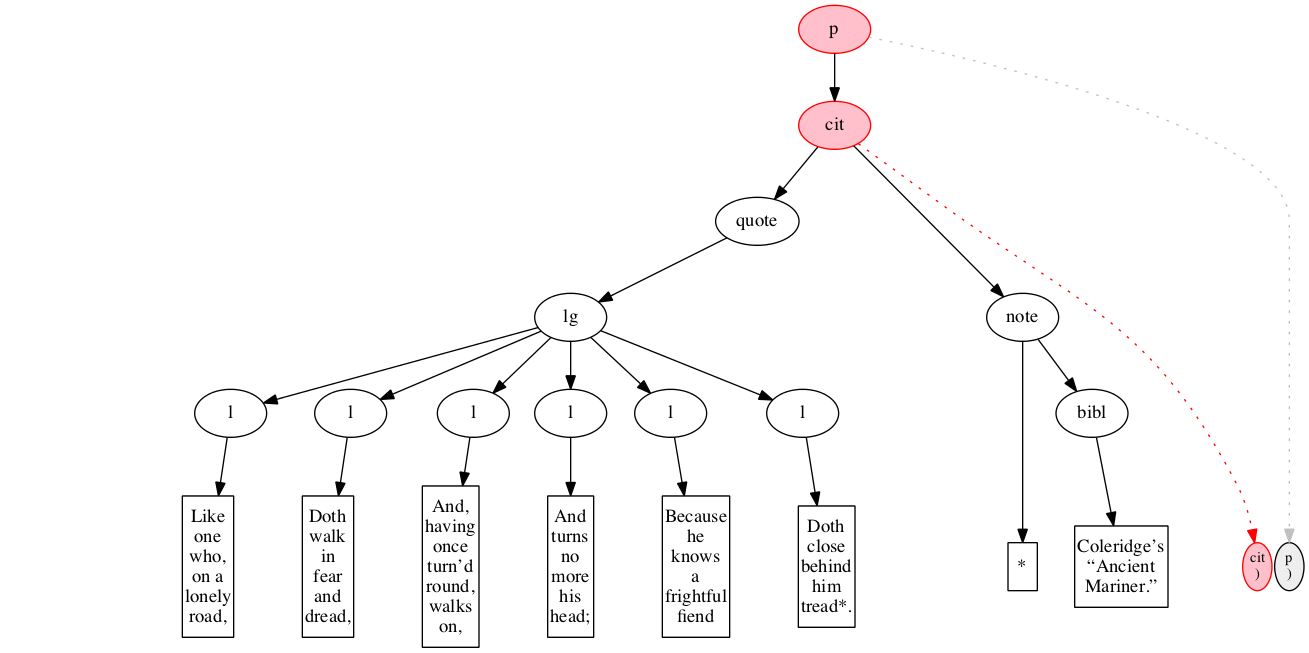
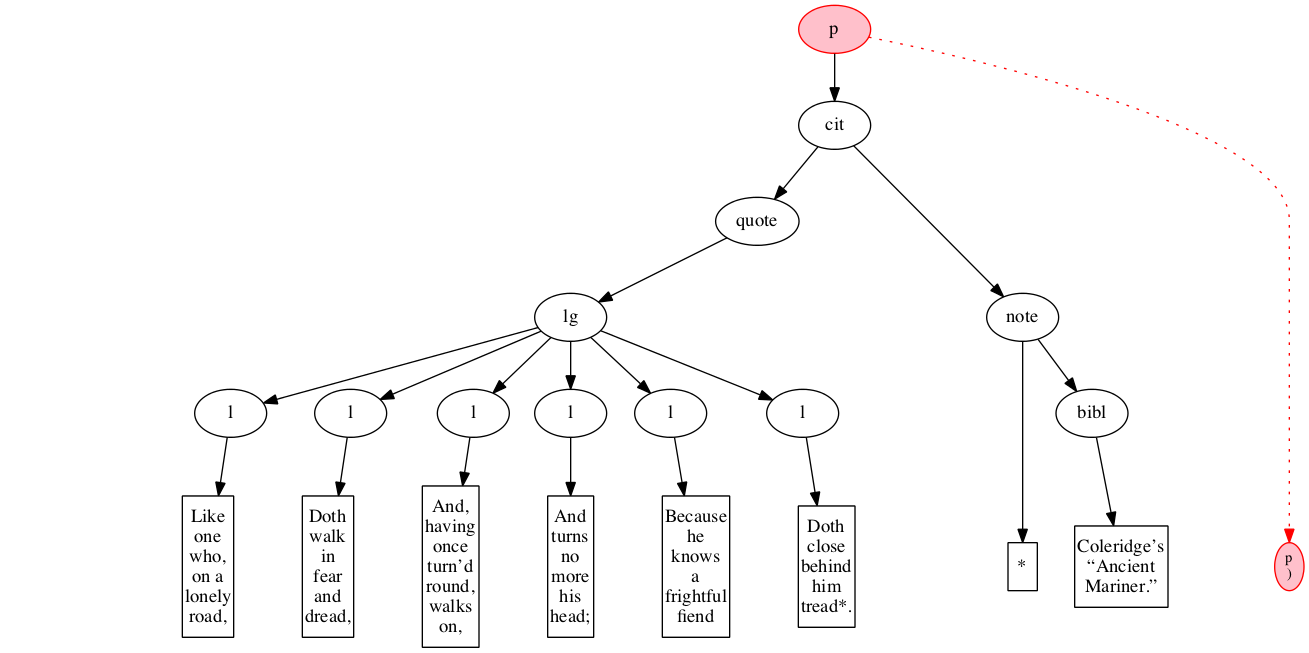
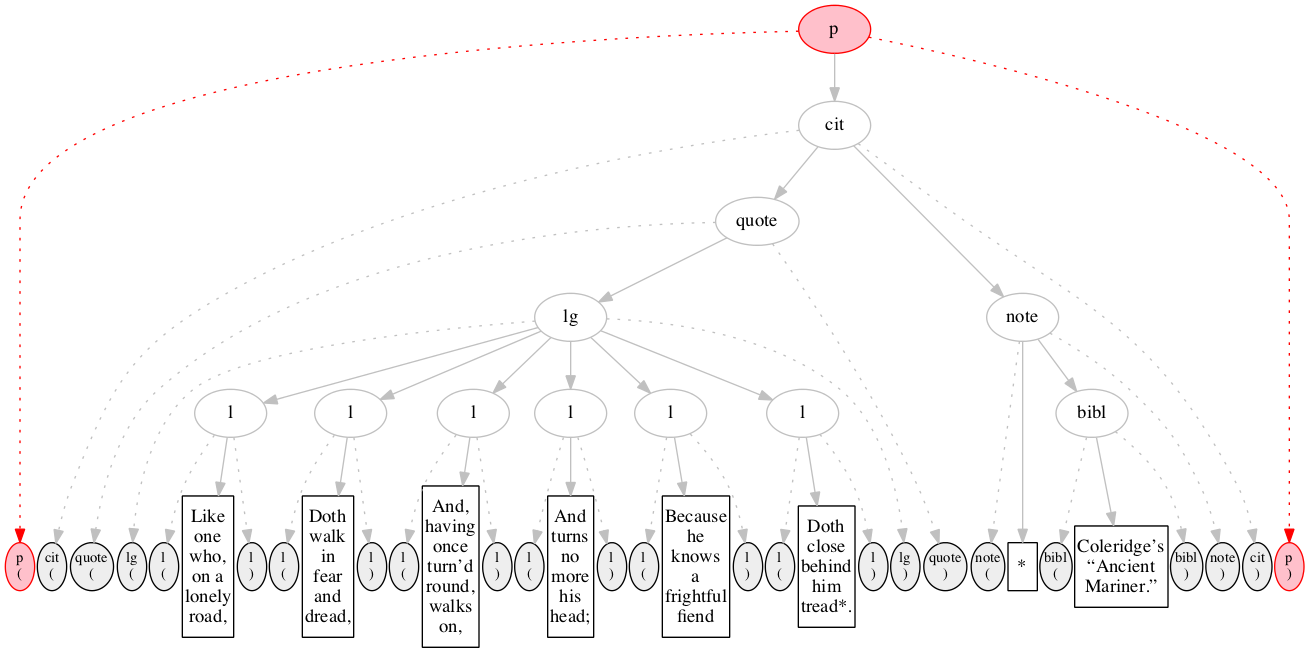
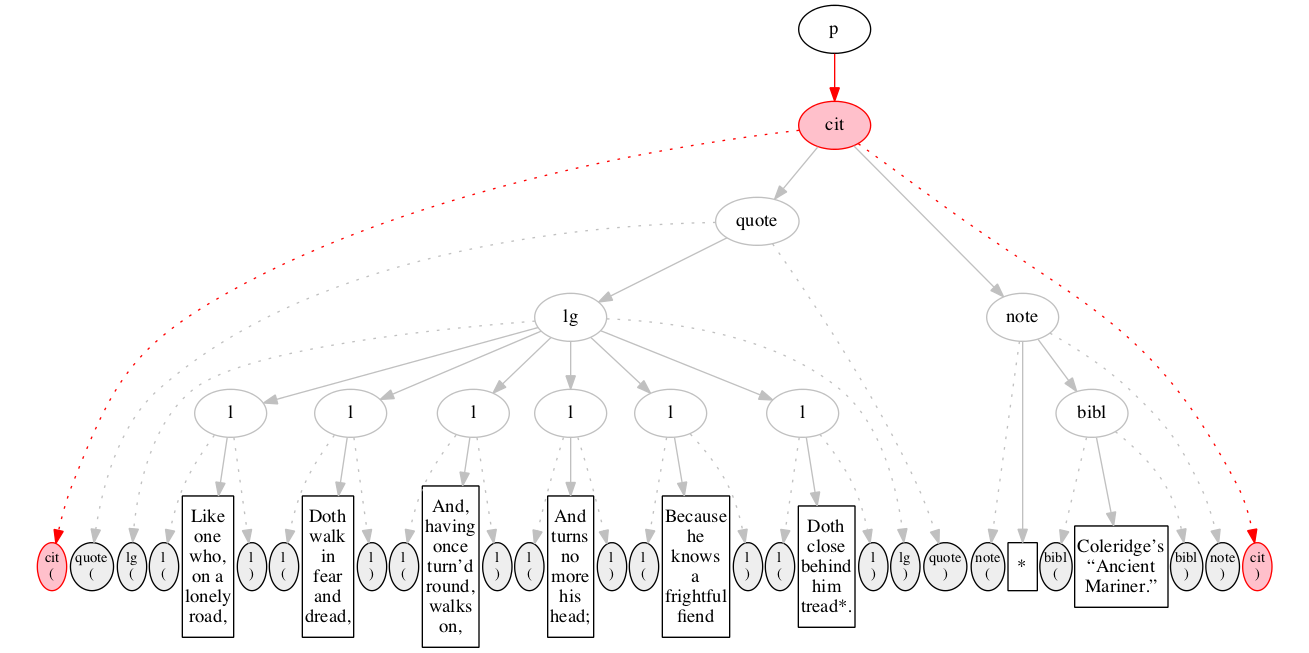
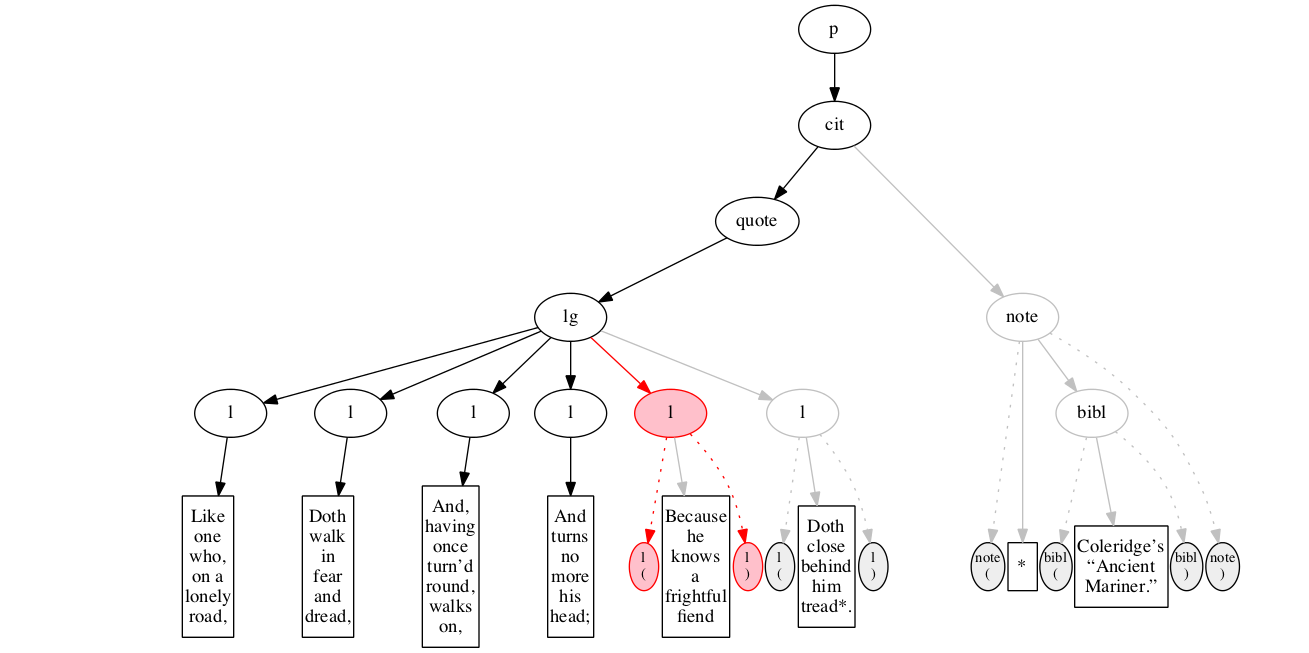
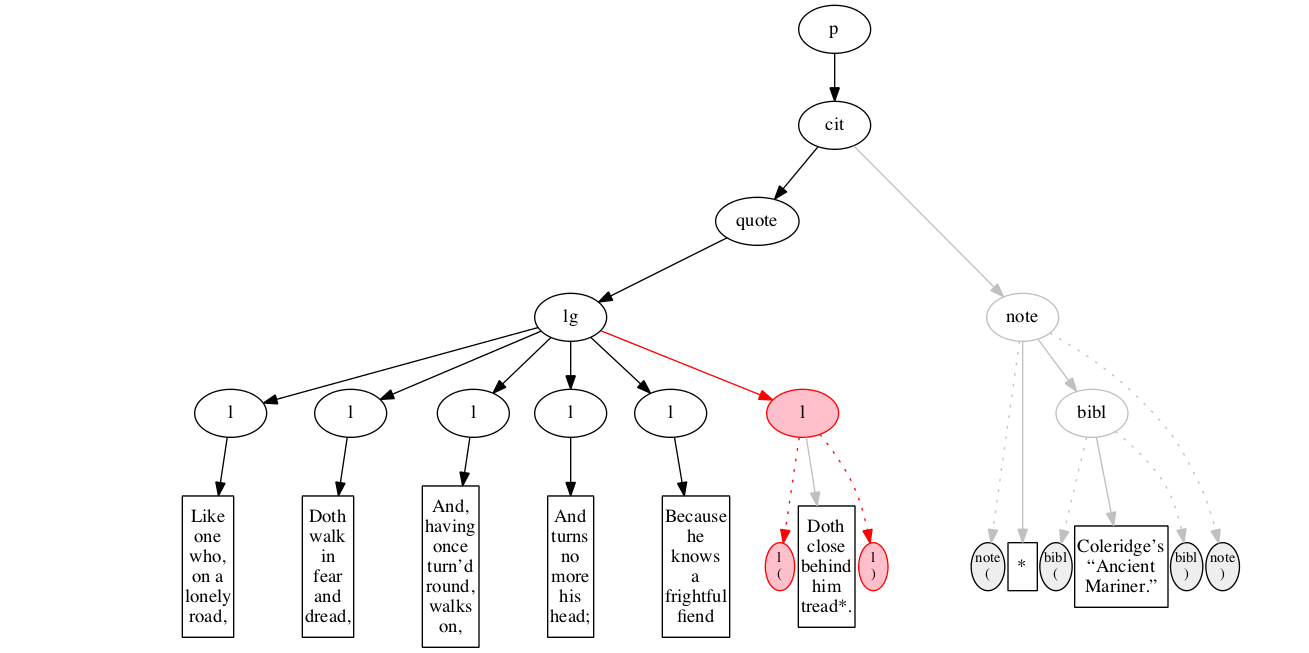
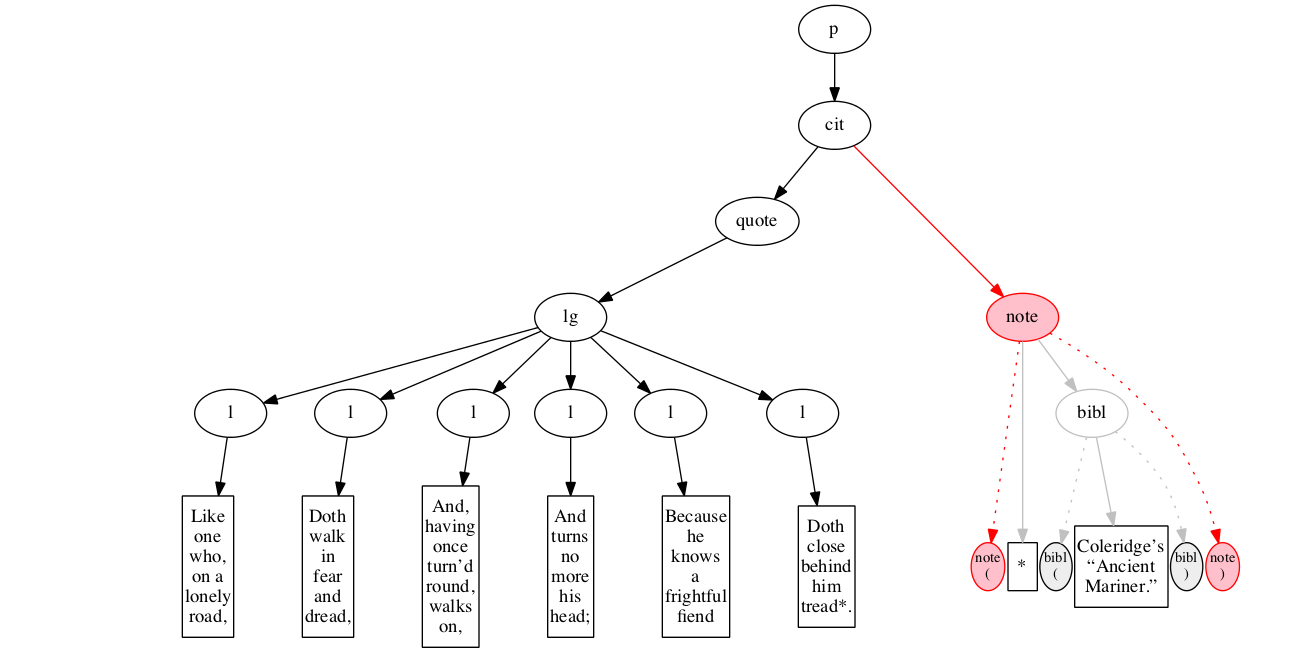
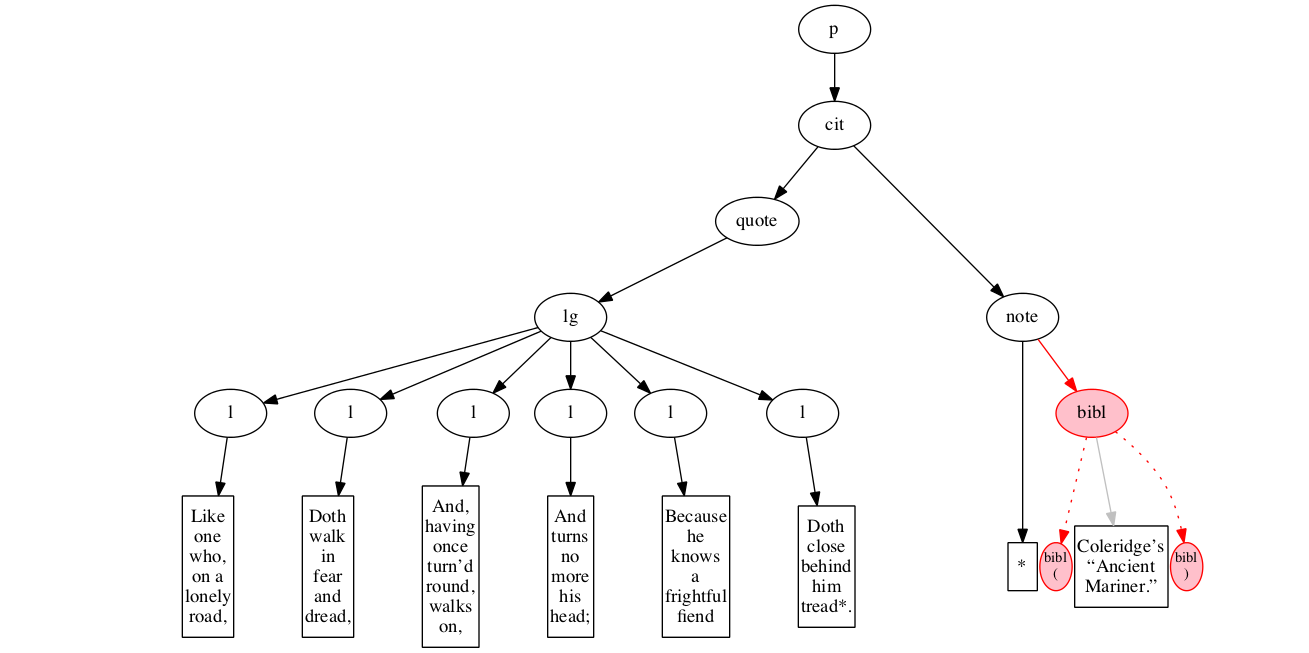
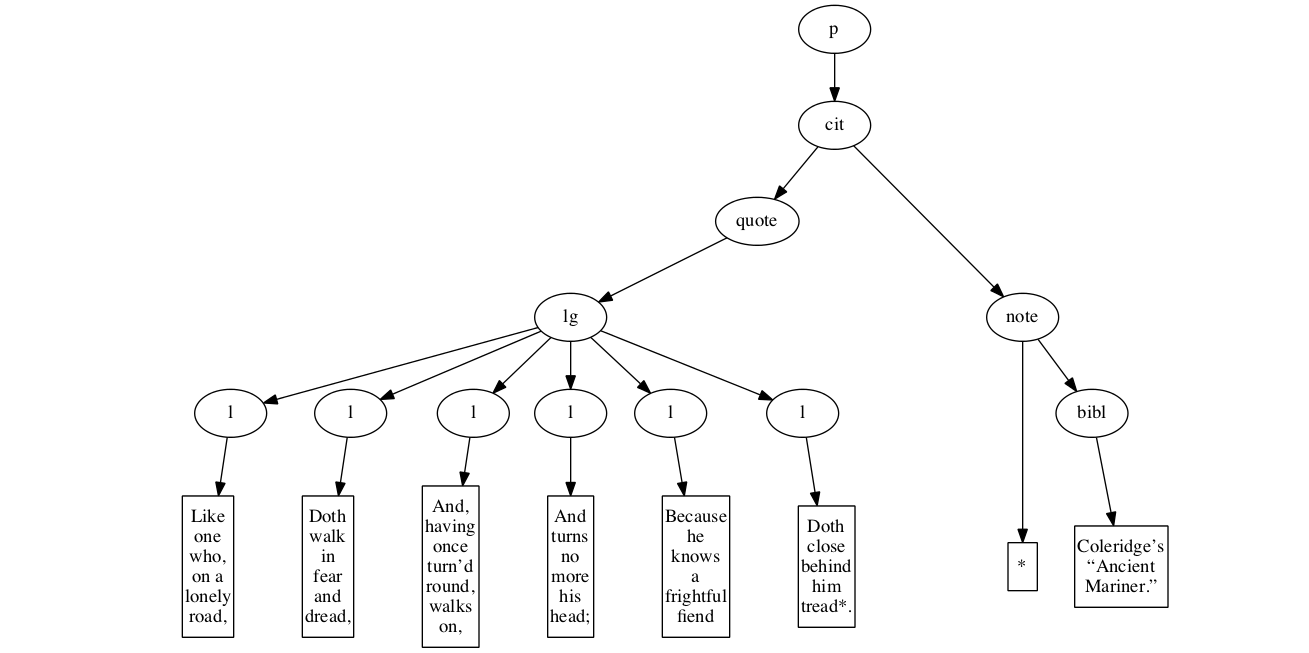
<p>
<cit>
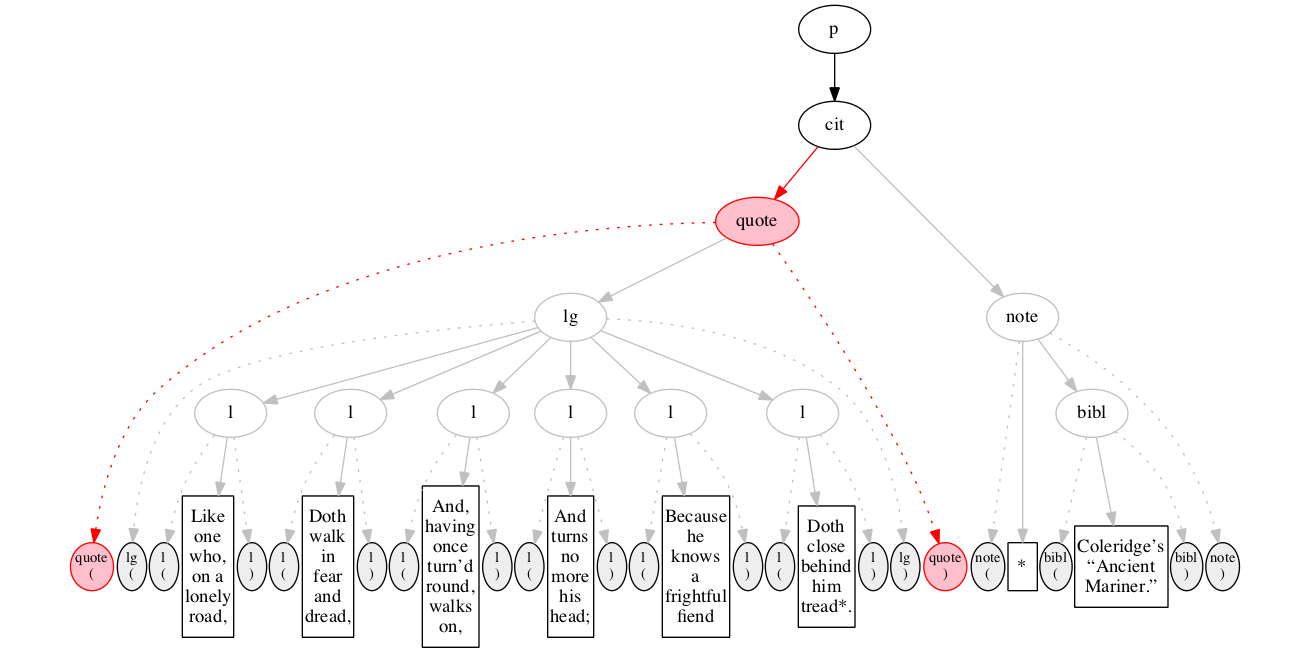
<quote>
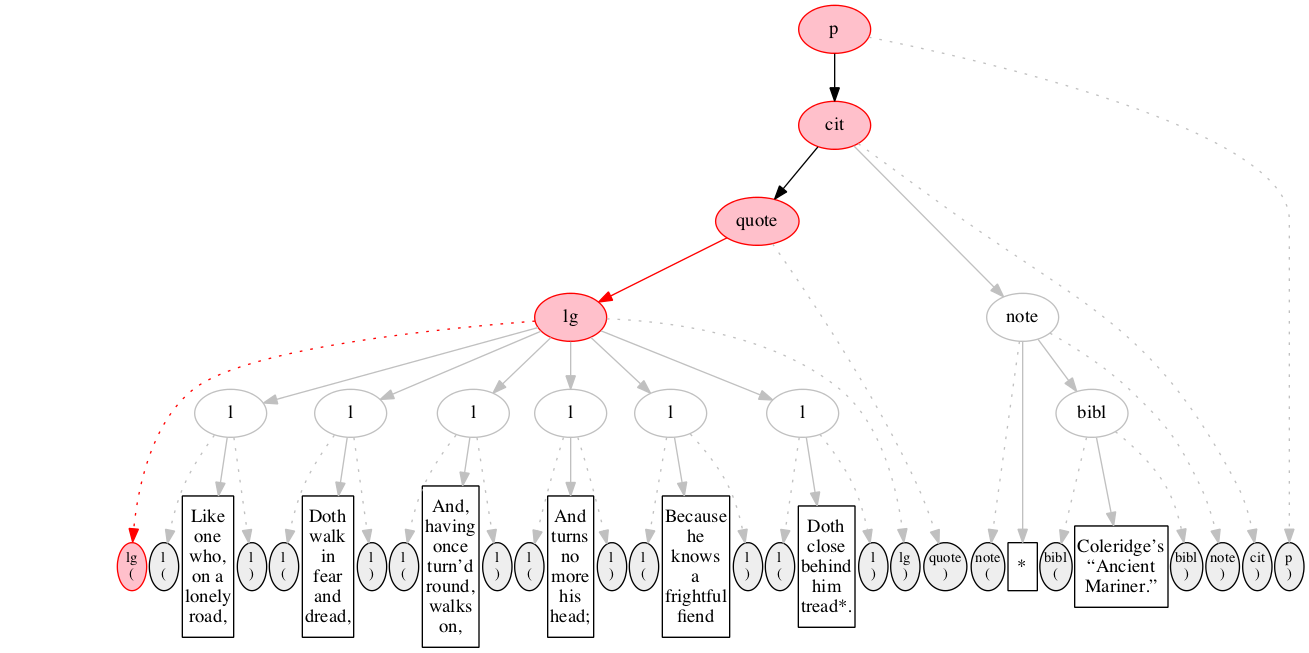
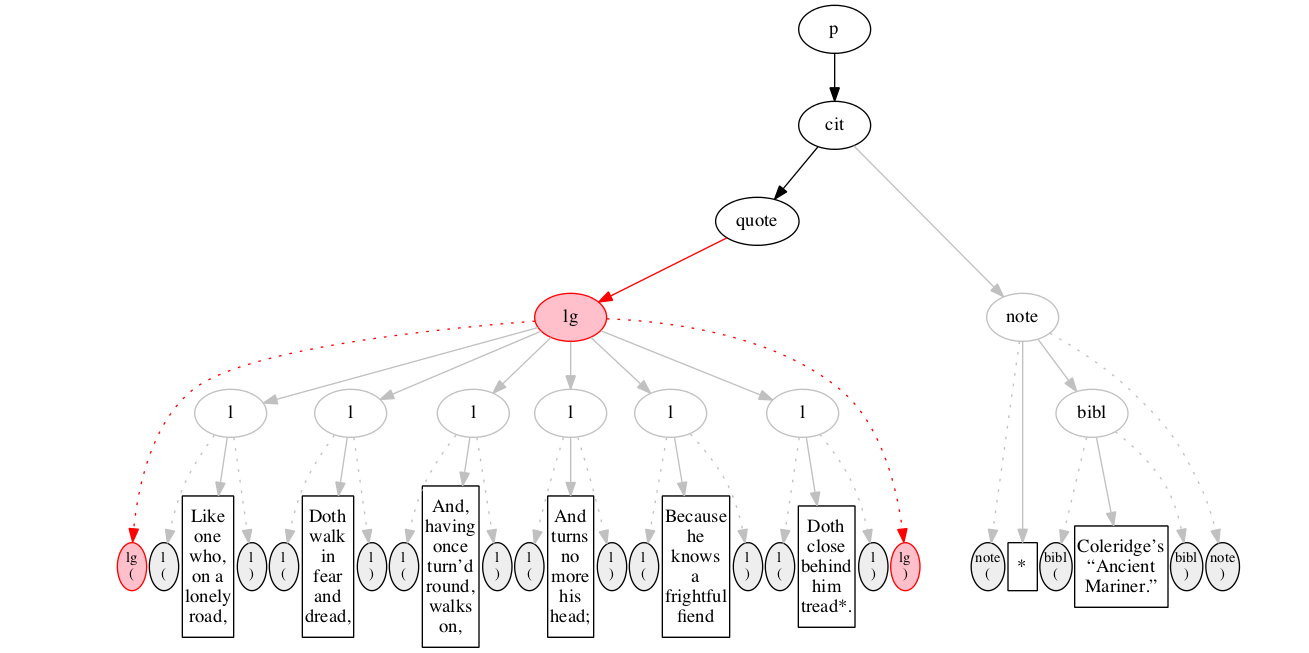
<lg>
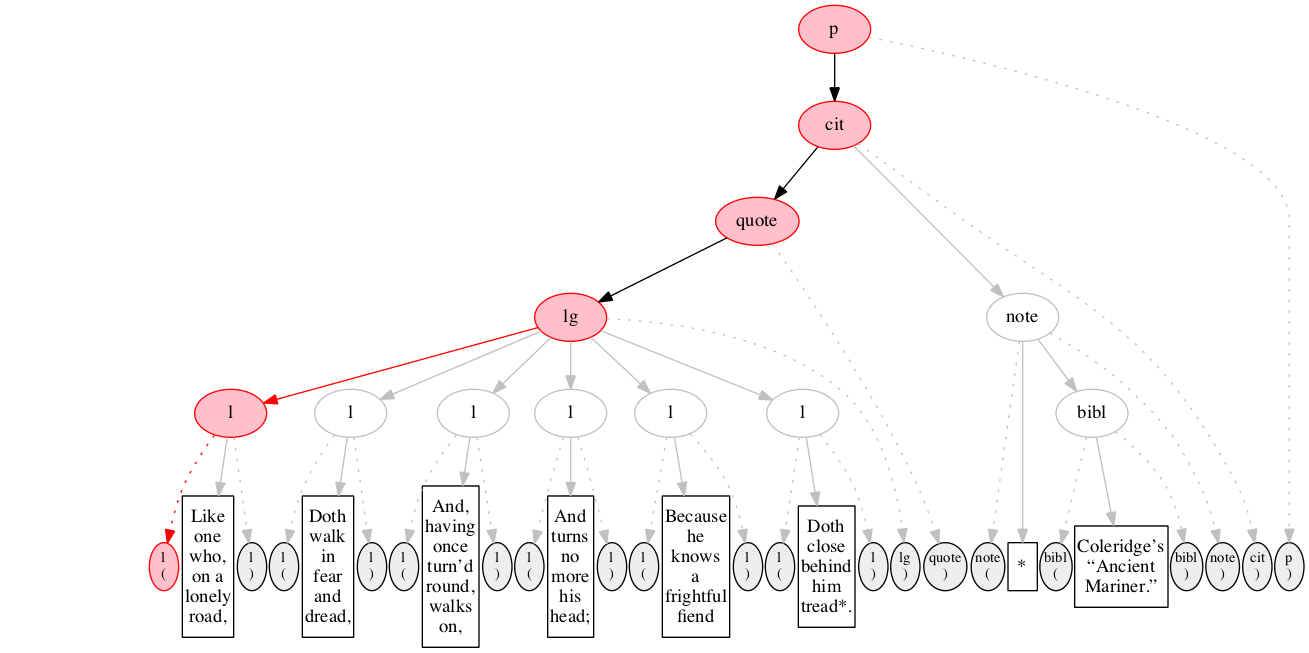
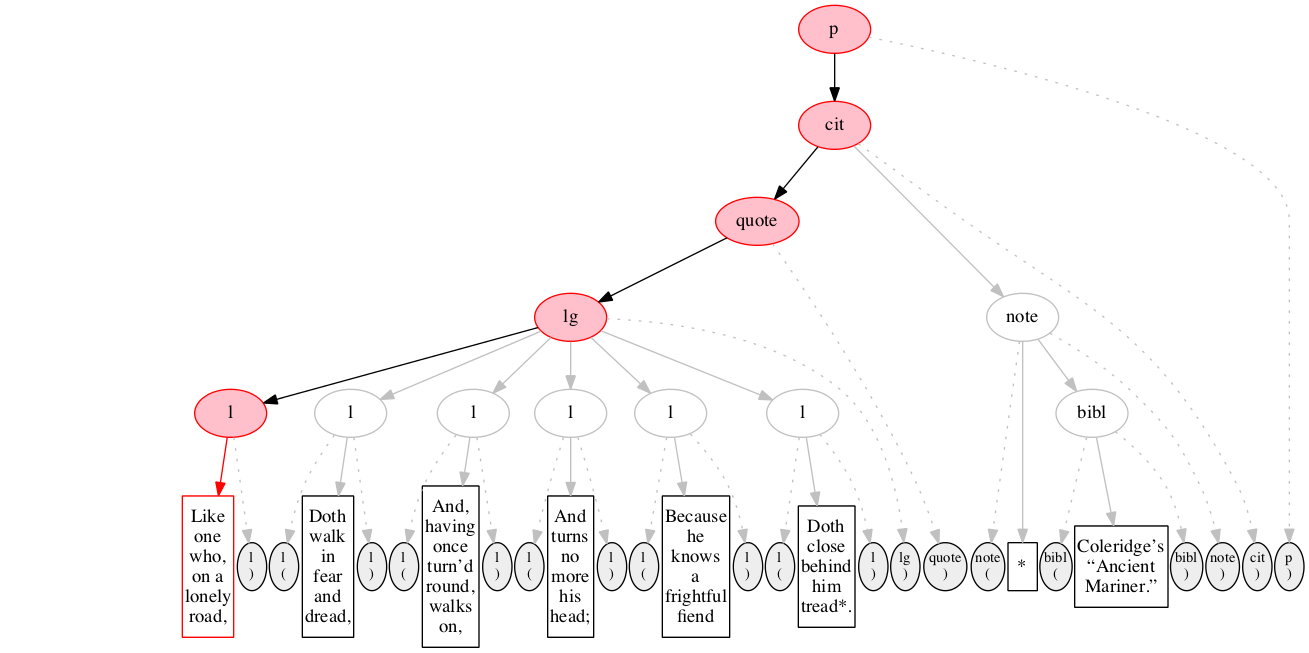
<l>Like one who, on a lonely road,</l>
<l>Doth walk in fear and dread,</l>
<l>And, having once turn’d round, walks on,</l>
<l>And turns no more his head;</l>
<l>Because he knows a frightful fiend</l>
<l>Doth close behind him tread*.</l>
</lg>
</quote>
<note> *
<bibl>Coleridge’s “Ancient Mariner.”</bibl>
</note>
</cit>
</p>Original content elements
Q. How do you get a text-collation tool to tell you about differences in (say) paragraphing or lineation?
Q. How do you ensure that XML collation output with variants that span line boundaries is well-formed?
Answers:
<?xml version="1.0" encoding="UTF-8"?><p
xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse">
<cit xml:id="fThomas_C10-cit_1" th:sID="d1e3"/>
<quote xml:id="fThomas_C10-quote_1" th:sID="d1e5"/>
<lg xml:id="fThomas_C10-lg_1" th:sID="d1e7"/>
<l xml:id="fThomas_C10-l_1" th:sID="d1e9"/>
Like one who, on a lonely road, <l th:eID="d1e9"/>
<l xml:id="fThomas_C10-l_2" th:sID="d1e12"/>
Doth walk in fear and dread, <l th:eID="d1e12"/>
<l xml:id="fThomas_C10-l_3" th:sID="d1e15"/>
And, having once turn’d round, walks on, <l th:eID="d1e15"/>
<l xml:id="fThomas_C10-l_4" th:sID="d1e18"/>
And turns no more his head; <l th:eID="d1e18"/>
<l xml:id="fThomas_C10-l_5" th:sID="d1e21"/>
Because he knows a frightful fiend <l th:eID="d1e21"/>
<l xml:id="fThomas_C10-l_6" th:sID="d1e25"/>
Doth close behind him tread*. <l th:eID="d1e25"/>
<lg th:eID="d1e7"/>
<quote th:eID="d1e5"/>
<note xml:id="fThomas_C10-note_1" th:sID="d1e30"/> *
<bibl xml:id="fThomas_C10-bibl_1">
Coleridge’s “Ancient Mariner.”
</bibl>
<note th:eID="d1e30"/>
<cit th:eID="d1e3"/>
</p>... converted to virtual elements (*)
Context: preparing for collation:
(we expect witnesses to alter line boundaries and structure)
Context: "hotspot" variant location markers inserted in edition files following the collation process
<lg xml:id="novel1_letter4_chapter4_div4_div4_p8_cit1_quote1_lg1">
<l xml:id="novel1_letter4_chapter4_div4_div4_p8_cit1_quote1_lg1_l1"> Like
<seg xml:id="C10_app435-f1818_end"/>one
<seg xml:id="C10_app437-f1818_start"/>who,
<seg xml:id="C10_app437- f1818_end"/>on a
<seg xml:id="C10_app439-f1818_start"/>lonely road,</l>
<l xml:id="novel1_letter4_chapter4_div4_div4_p8_cit1_quote1_lg1_l2">
Doth <seg xml:id="C10_app439-f1818_end"/>walk in fear and
<seg xml:id="C10_app441-f1818_start"/>dread,</l>
<l xml:id="novel1_letter4_chapter4_div4_div4_p8_cit1_quote1_lg1_l3">
And, <seg xml:id="C10_app441-f1818_end"/>having once
<seg xml:id="C10_app443-f1818_start"/>turn’d
<seg xml:id="C10_app443-f1818_end"/>
<seg xml:id="C10_app444-f1818_start"/>round, walks on,</l>
<l xml:id="novel1_letter4_chapter4_div4_div4_p8_cit1_quote1_lg1_l4">
And <seg xml:id="C10_app444-f1818_end"/>turns no more his
<seg xml:id="C10_app446-f1818_start"/>head;</l>
<l xml:id="novel1_letter4_chapter4_div4_div4_p8_cit1_quote1_lg1_l5">
Because <seg xml:id="C10_app446-f1818_end"/>he knows a frightful
<seg xml:id="C10_app448-f1818_start"/>fiend</l>
<l xml:id="novel1_letter4_chapter4_div4_div4_p8_cit1_quote1_lg1_l6">
Doth <seg xml:id="C10_app448-f1818_end"/>close behind him
<seg xml:id="C10_app450-f1818_start"/>tread*.</l>
</lg>
Given Trojan Horse* elements of the form
produce
... <e th:sID="x"/> ... <e th:eID="x"/> ... ... <e> ... </e> ...* DeRose 2004 “Markup overlap: a review and a horse,” Extreme Markup Languages 2004
XML processing and raising
XML processing may involve
Each of these stages can be accessed for raising
* Actually, there are more, but seven may be enough.
** We only have time to visit five of these on our short walk today. For the others, read our paper / come talk to us afterwards!
(<[^>]+?)th:sID\s*=\s*['"]\w+?['"](.*?)/(>)Match
Replace
\1\2\3Match
(<)(\S+?)\s+[^>]*?th:eID=['"]\w+['"][^>]*?/(>)Replace
\1/\2\3Raise start markers
Raise end markers
Input: pulldom (SAX-like event processor)
>or: String output</
XML output
<
>
SAX-like event interface, with ability to pull in DOM-like subtrees
<lg th:sID="id1"/><lg th:eID="id1"/>for event, node in parseString(input.read()):
if event == START_ELEMENT:
# process pseudo-end-tags on END_ELEMENT event
if not node.hasAttribute('th:eID'):
open_elements.peek().appendChild(node)
open_elements.push(node)
elif event == END_ELEMENT:
# don't declare now-unused th: namespace
if node.hasAttribute('xmlns:th'):
node.removeAttribute('xmlns:th')
# can't remove @start until we're done with the node
if node.hasAttribute('th:sID'):
node.removeAttribute('th:sID')
# pop only on container elements and Trojan end-tags
else:
open_elements.pop()
elif event == CHARACTERS:
# create and add text() node for character data
t = d.createTextNode(node.data)
open_elements.peek().appendChild(t)
result = open_elements.pop().toxml() # root is at top of stackThe core of the Python app
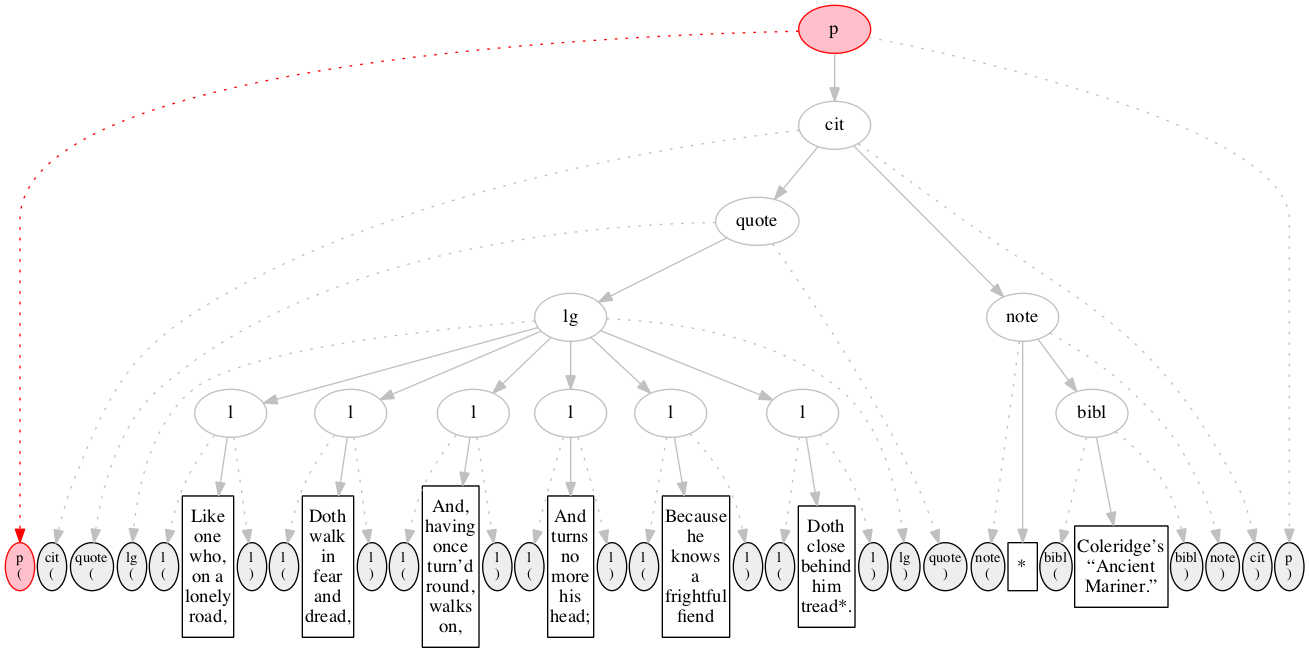
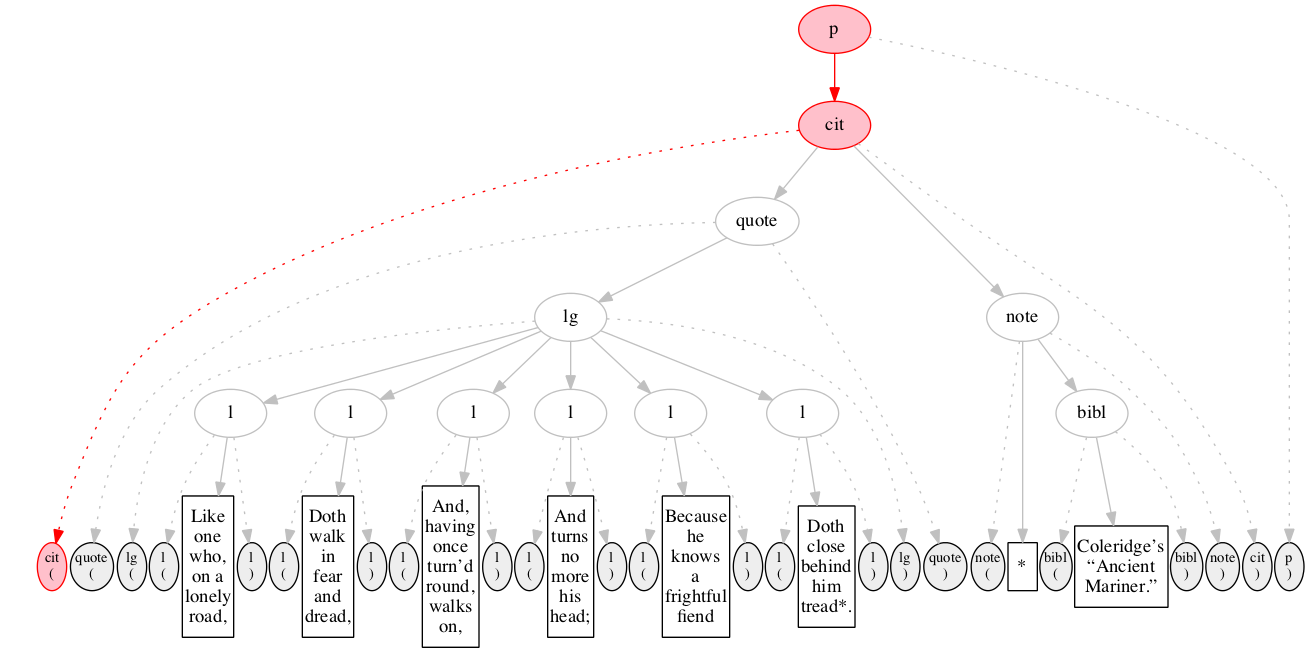
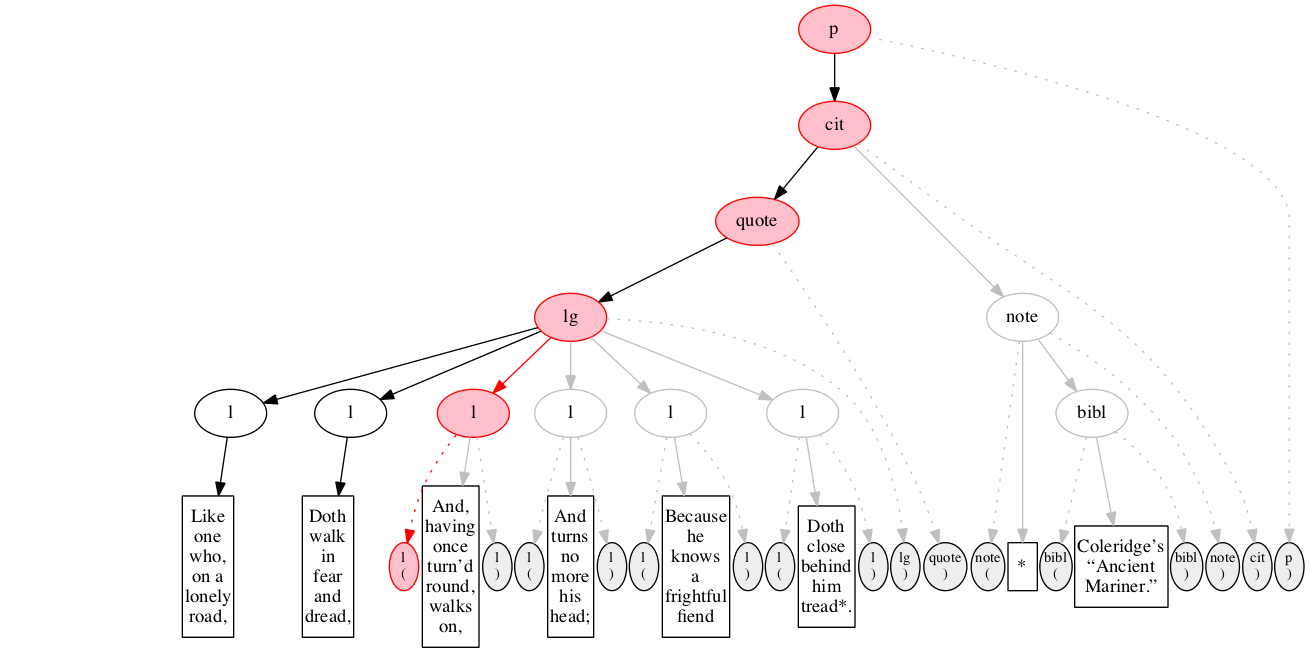
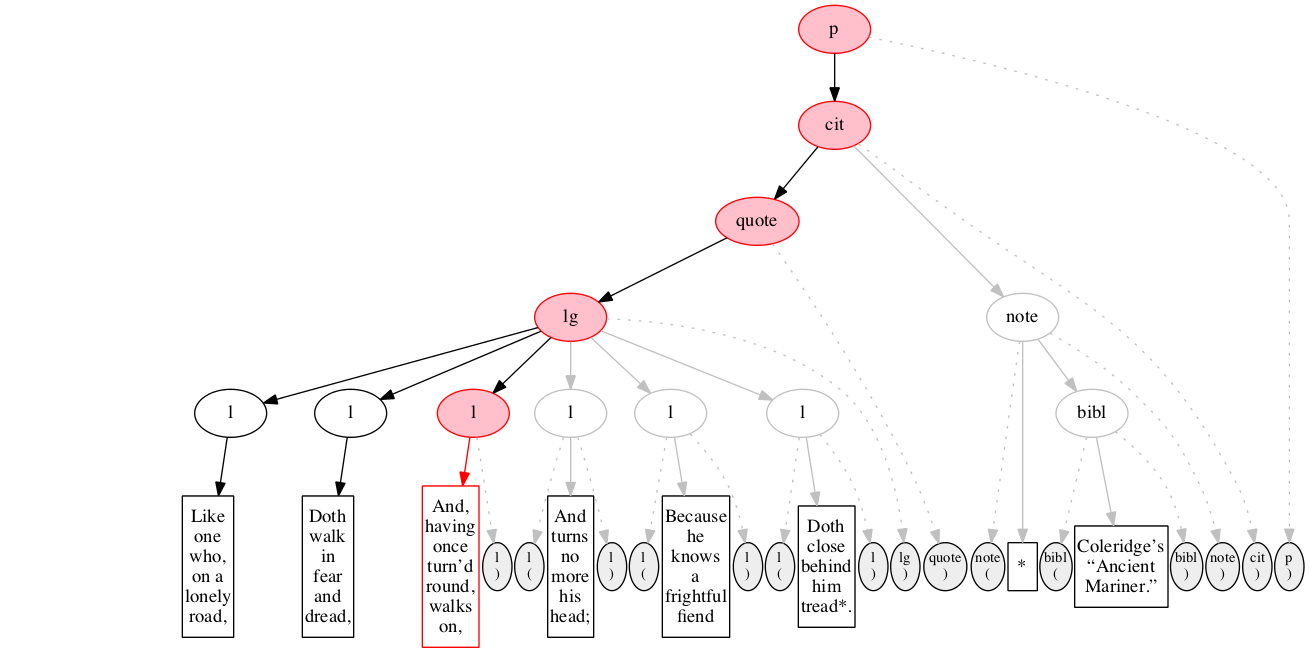
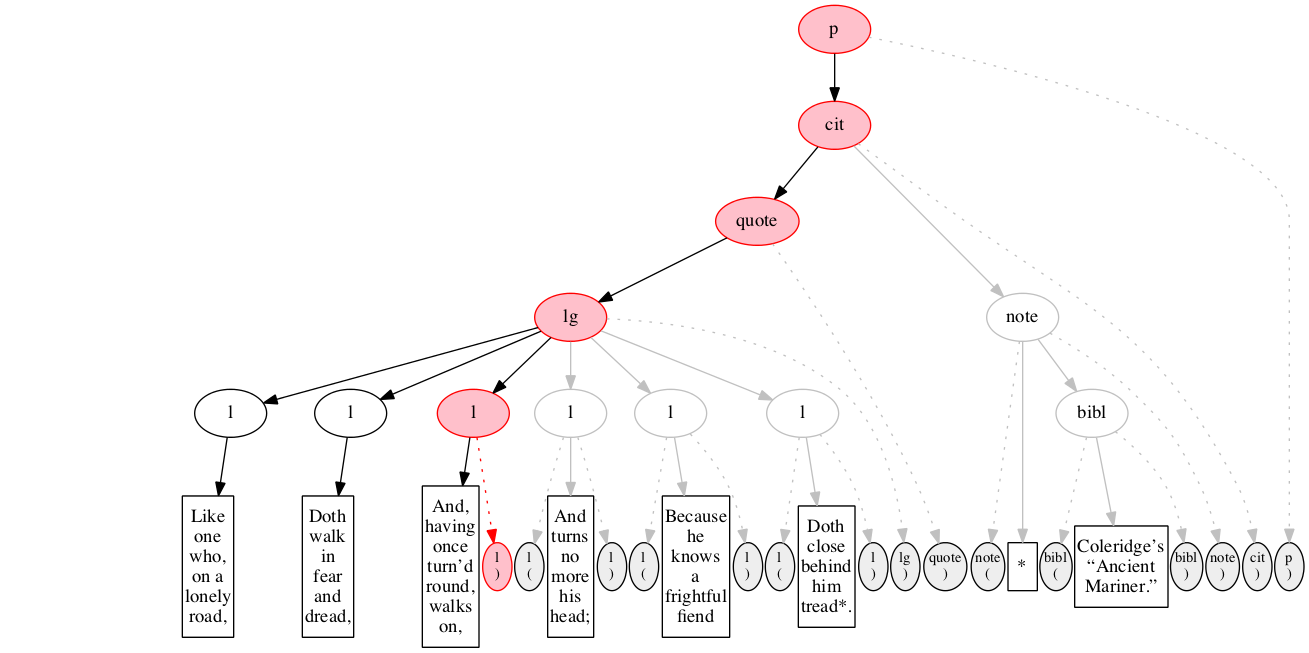
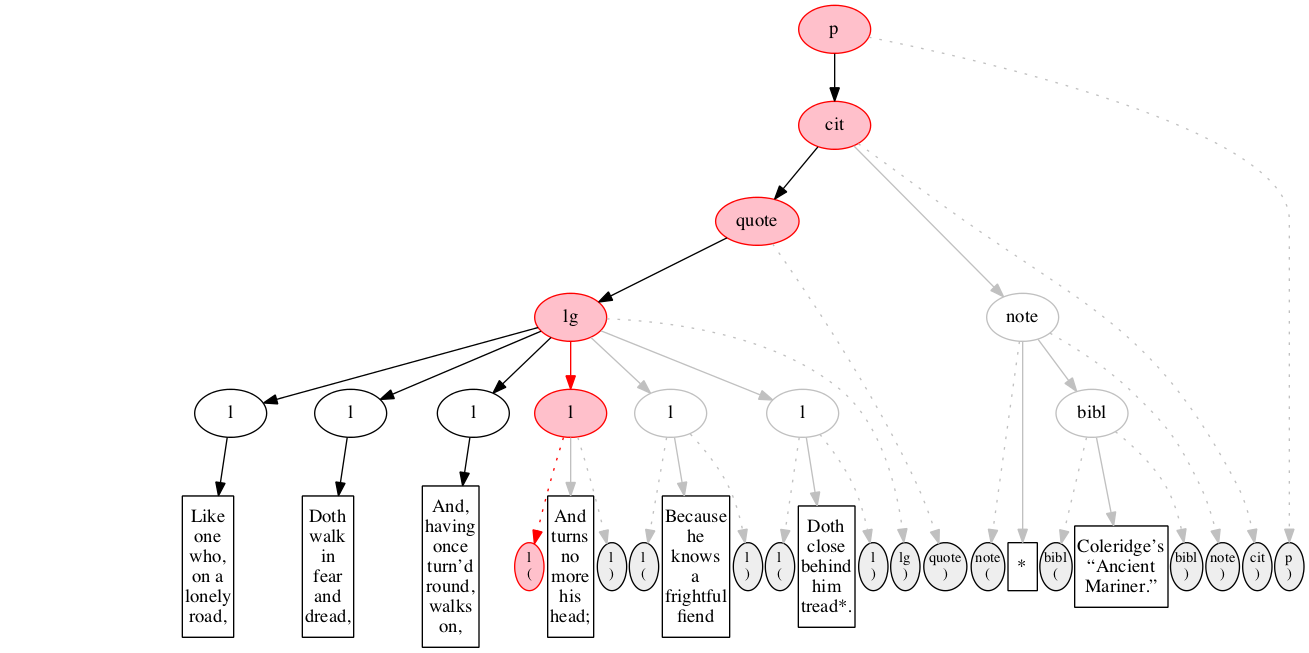
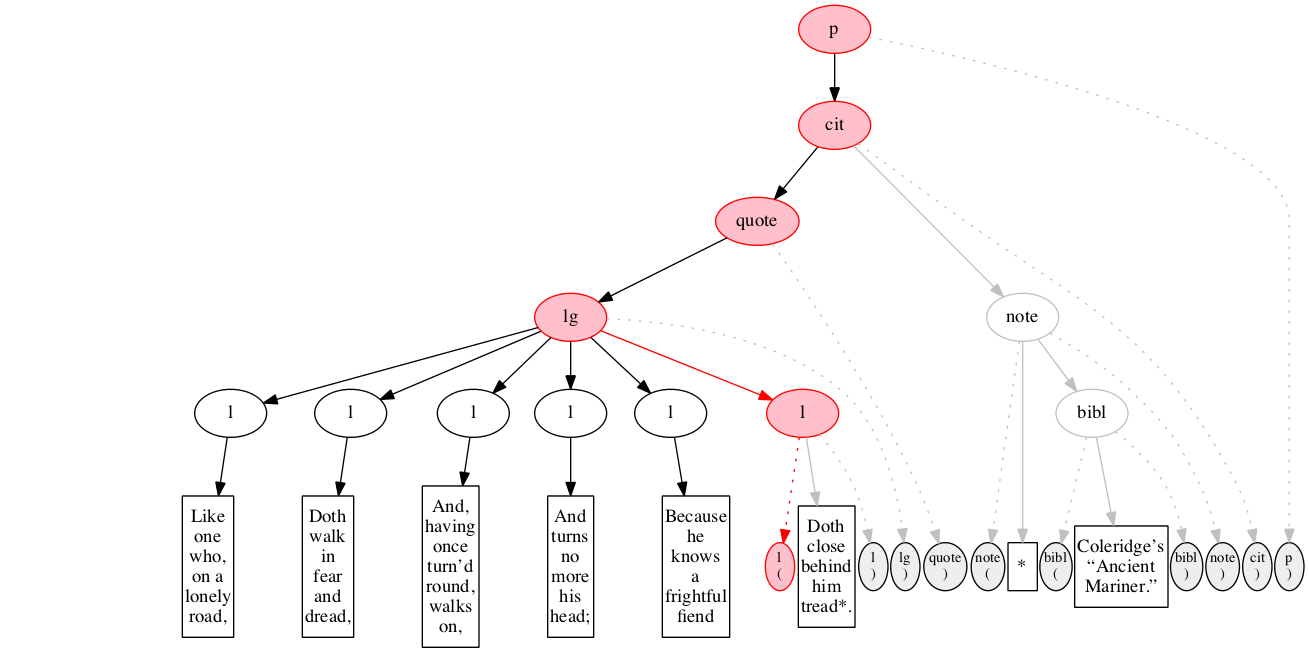
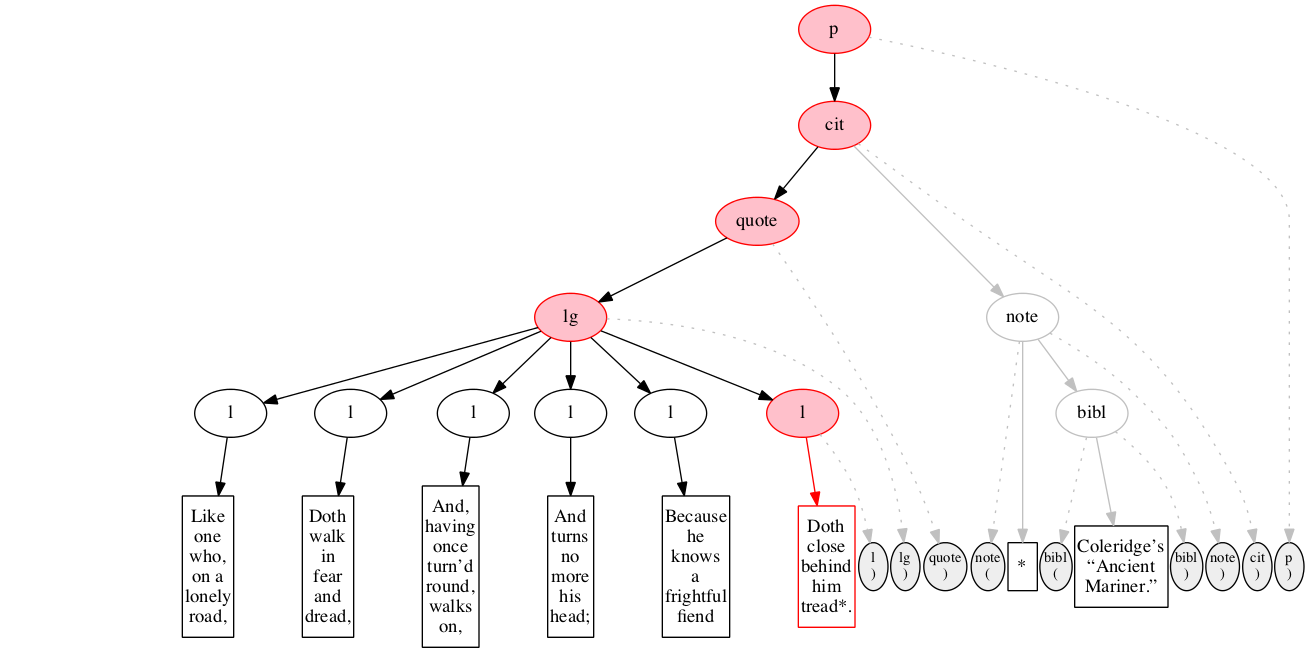
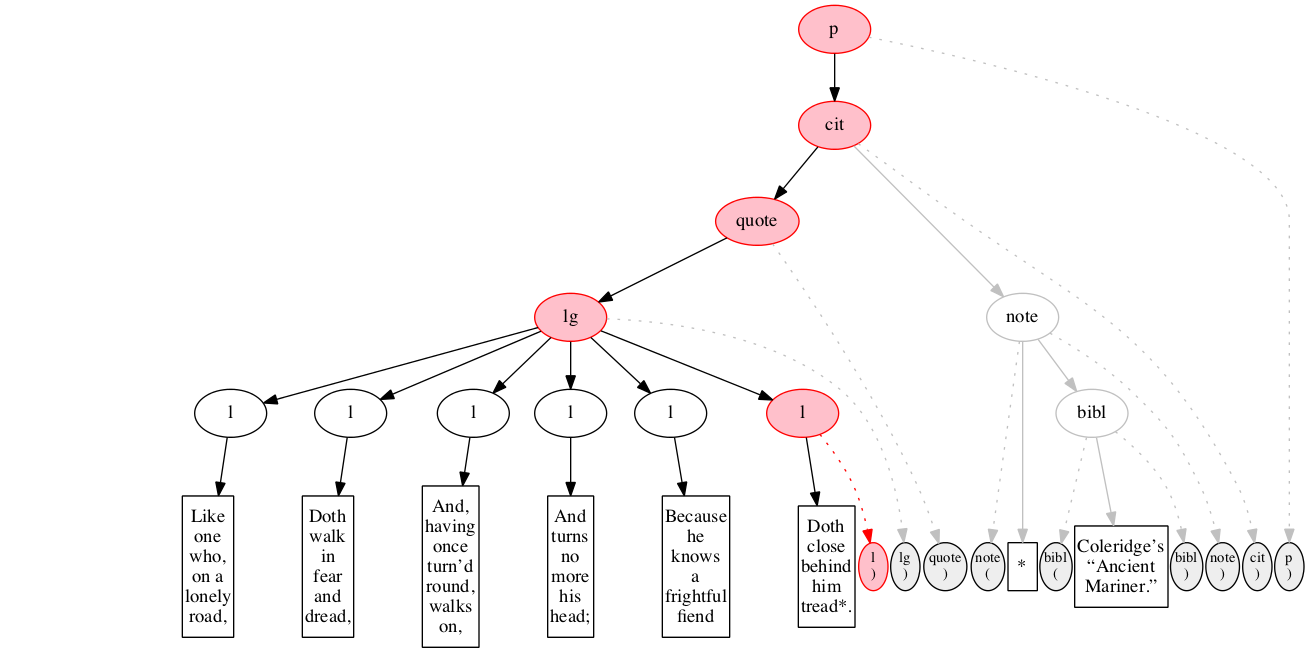
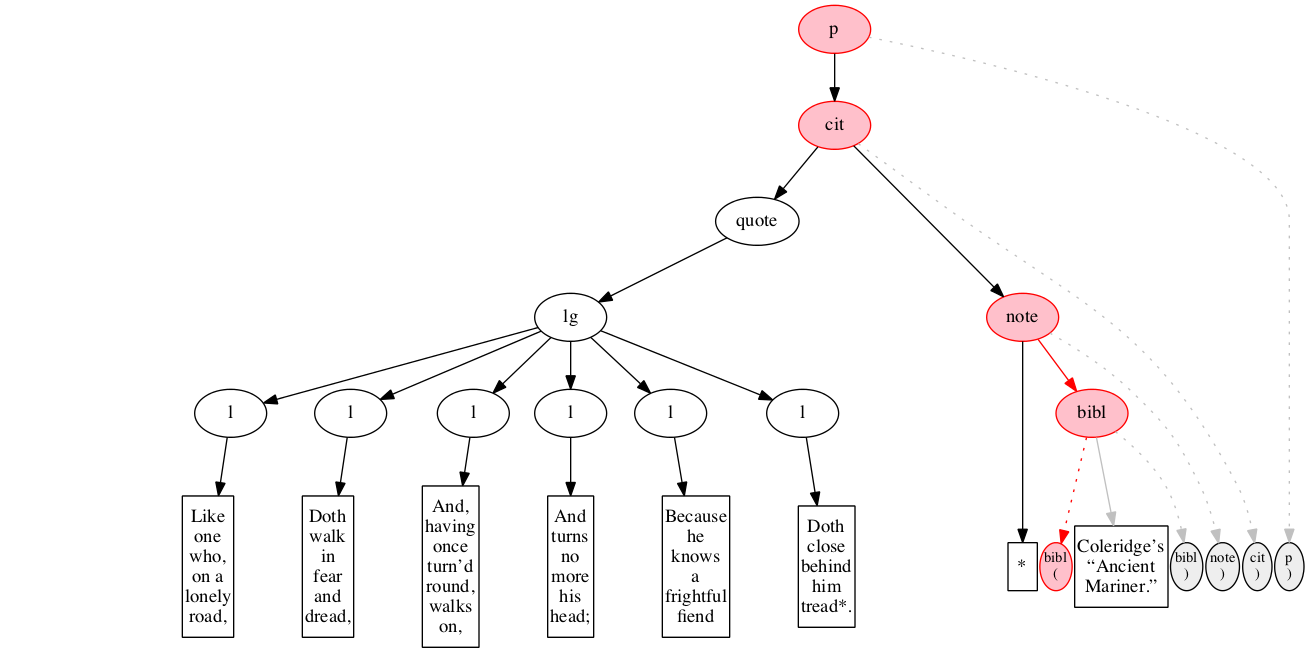
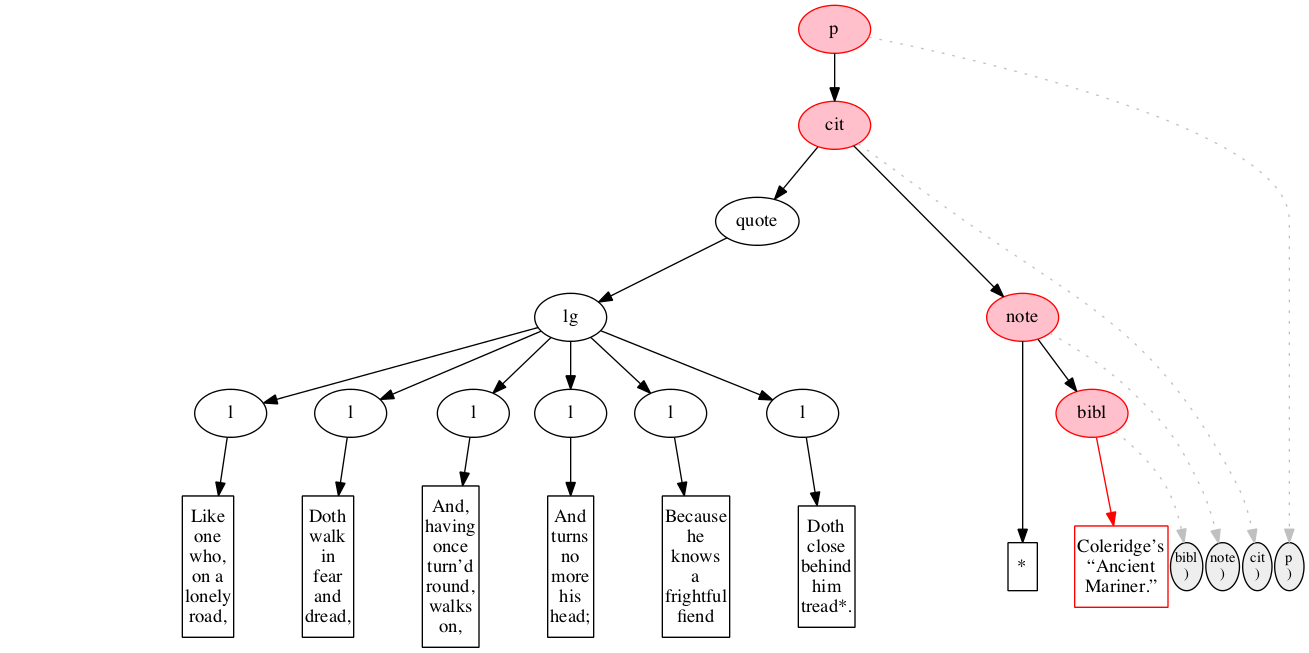
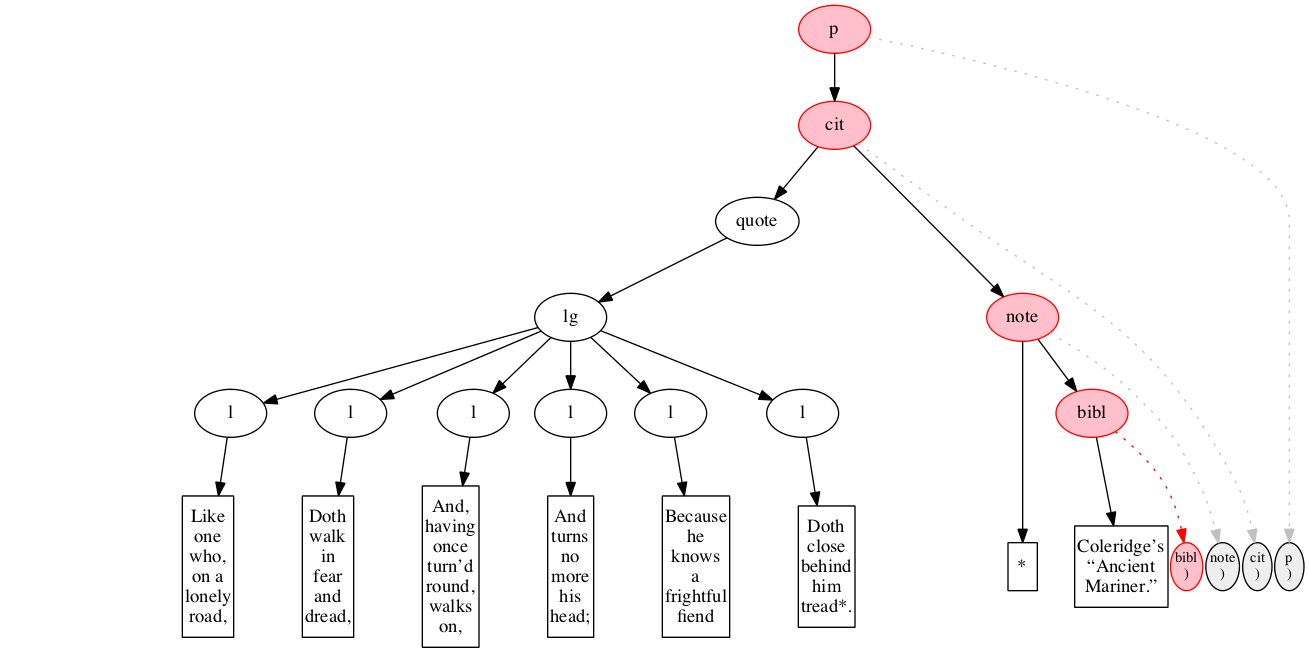
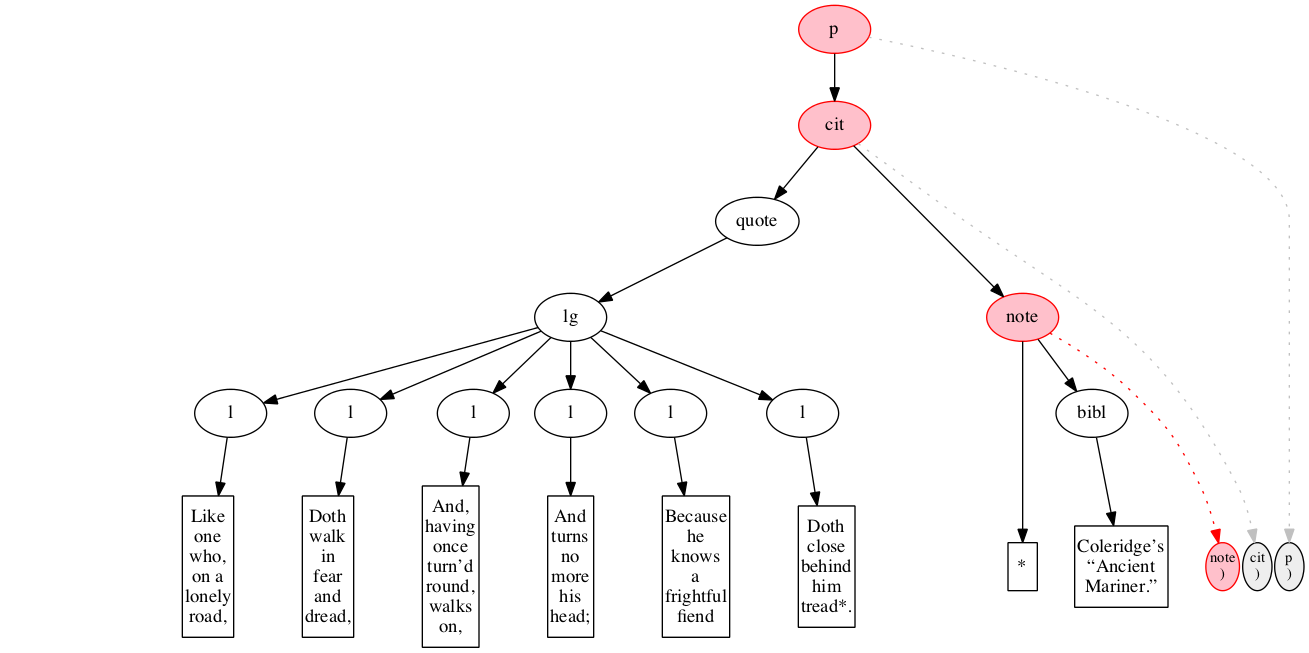
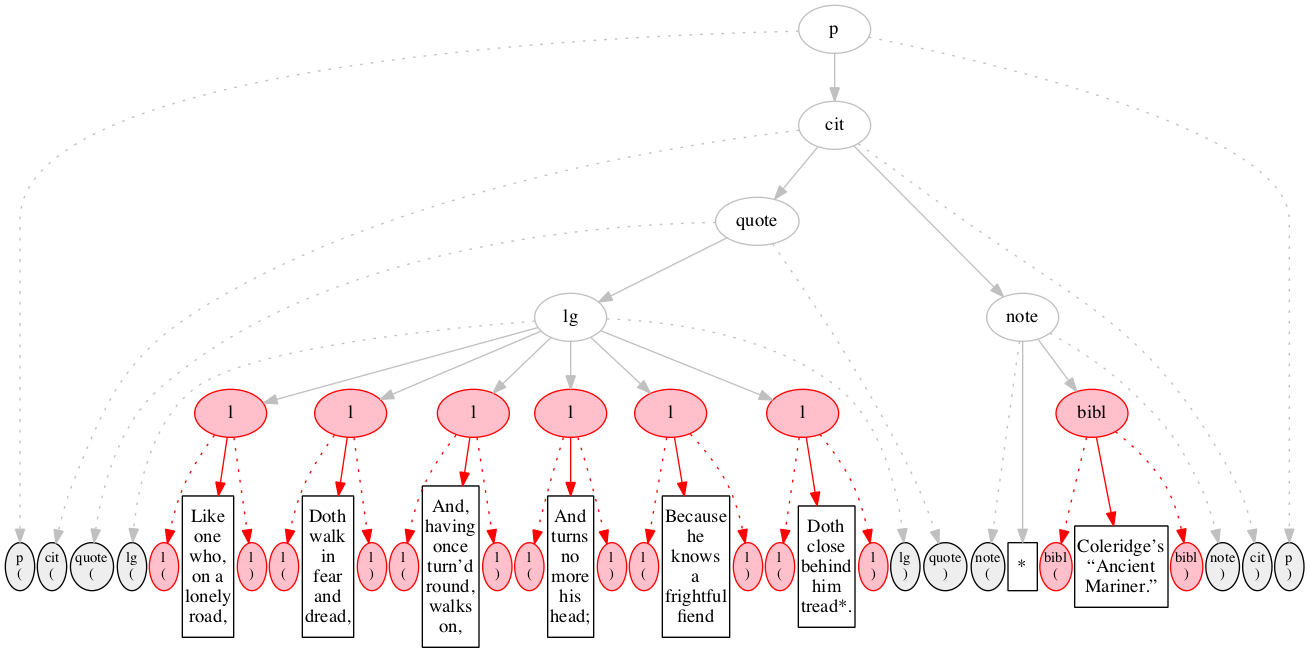
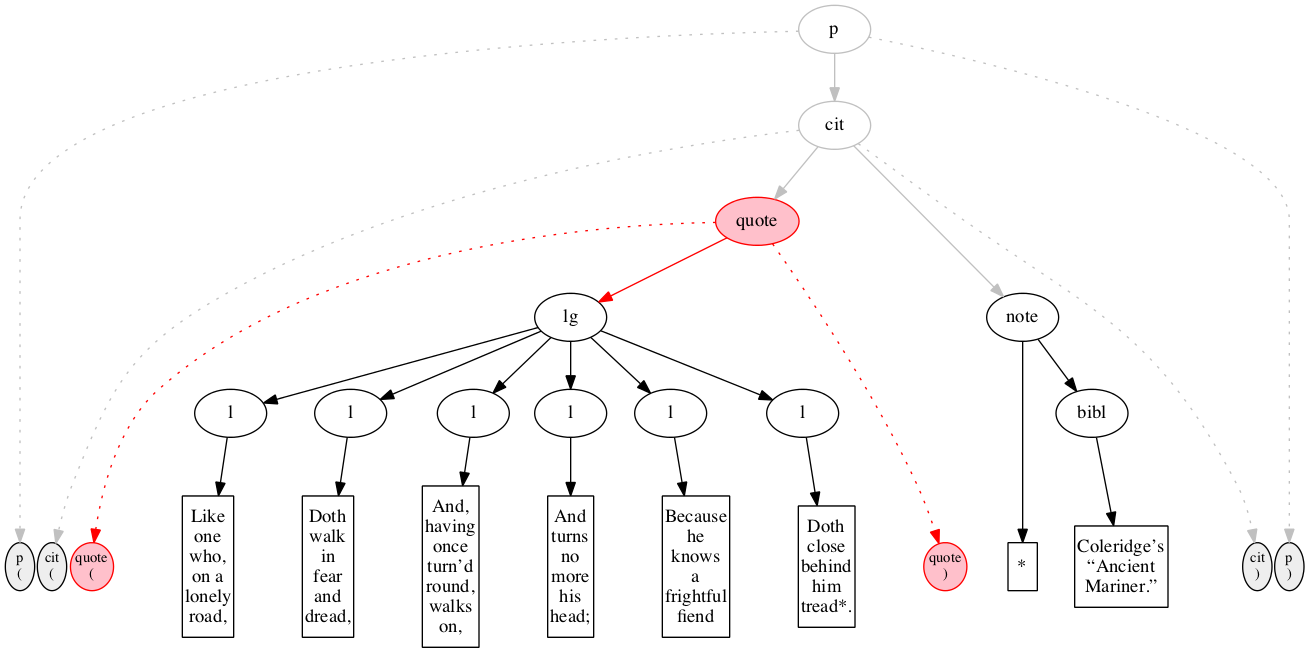
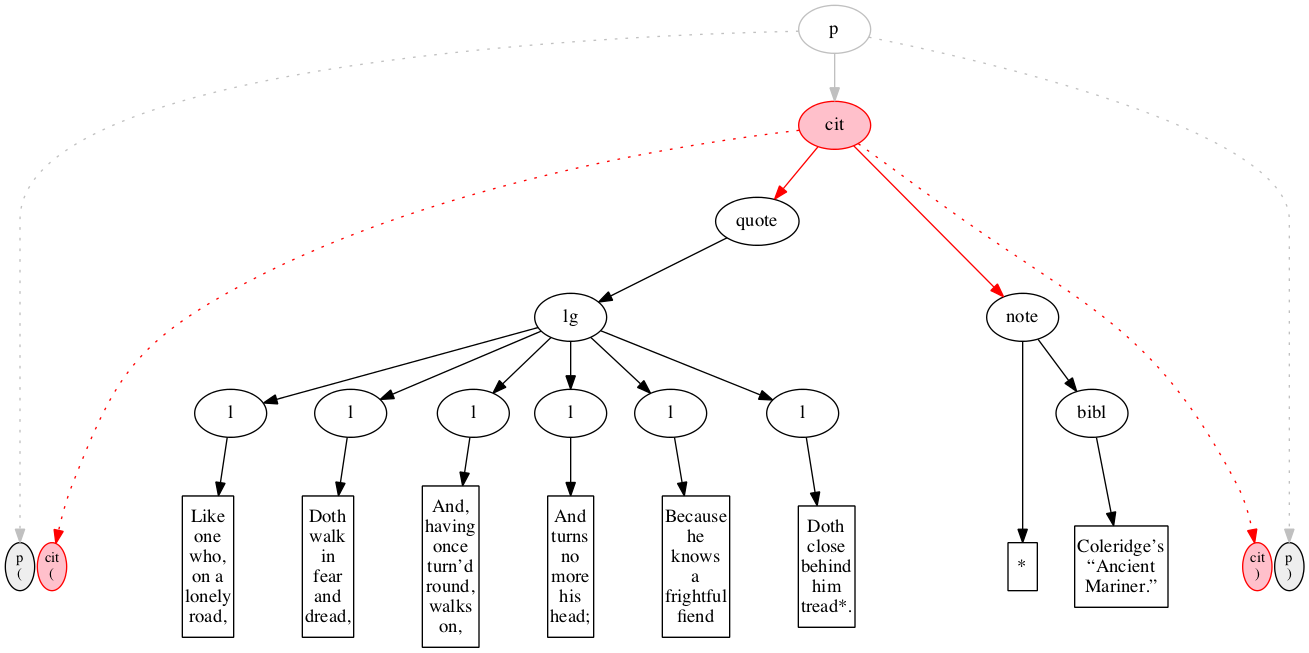
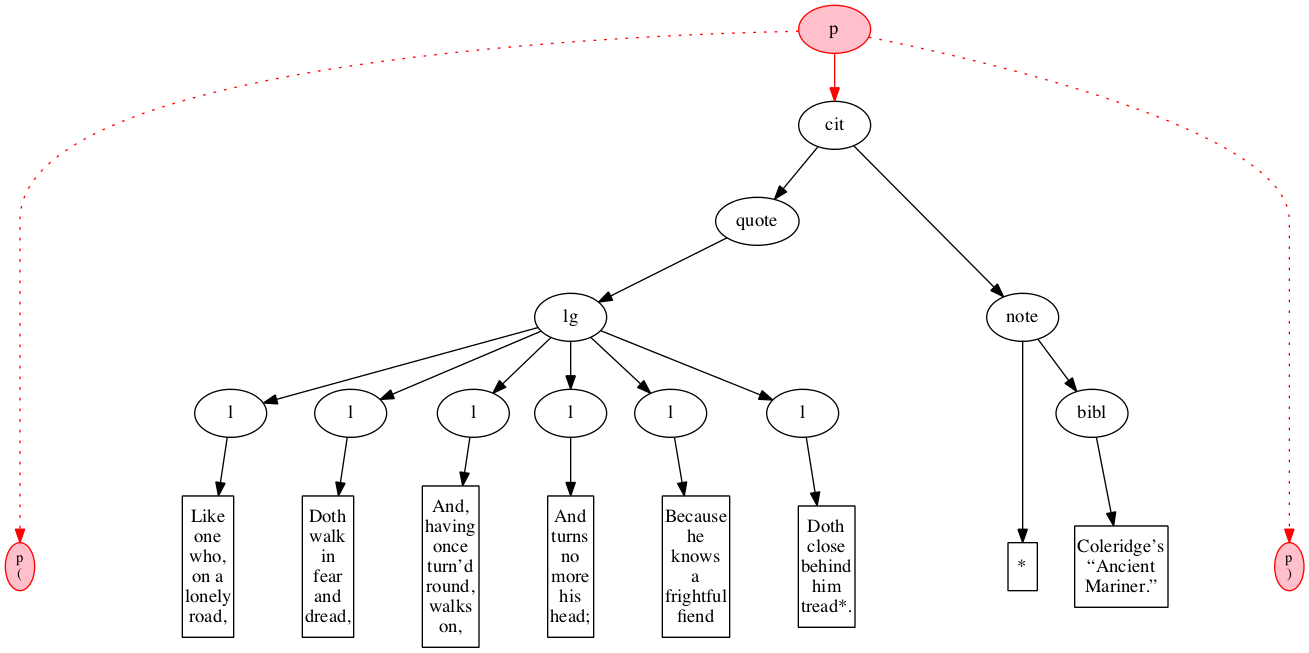
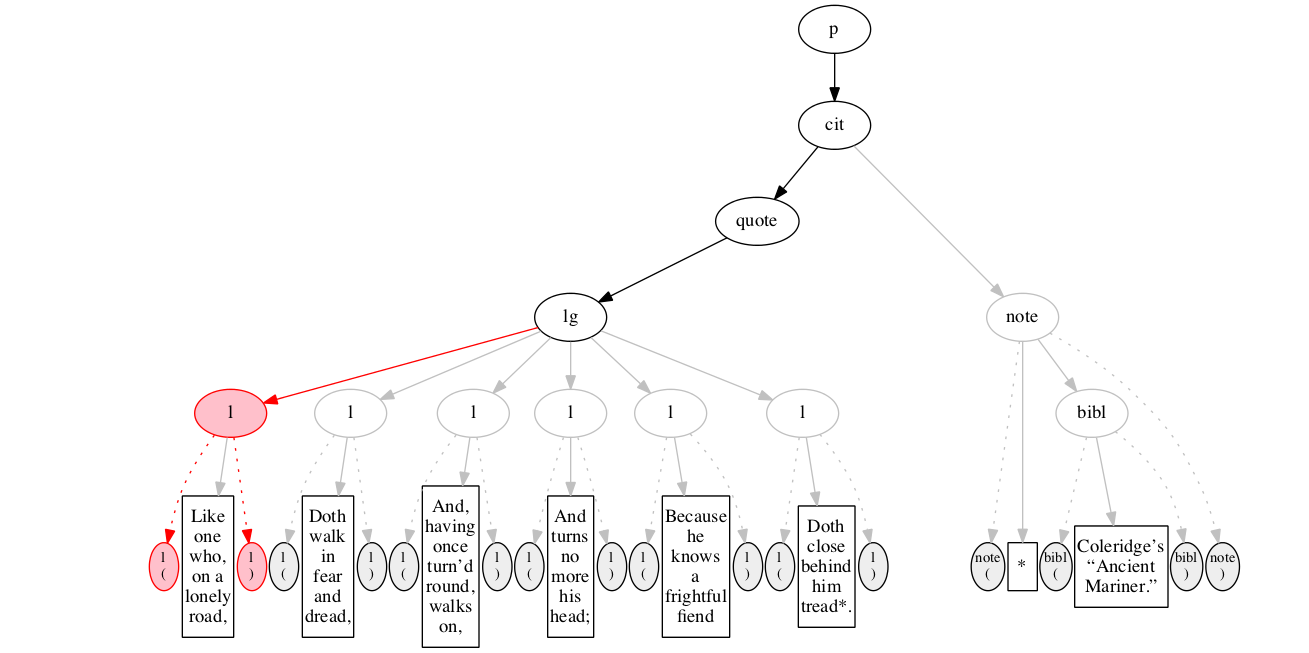
At the outset, we have a flat sequence of nodes.
We first encounter the start-marker for the paragraph.
We then encounter a start-marker for a citation. The paragraph has been started but not finished.
We then encounter a start-marker for a quotation.
We then encounter a start-marker for a line group.
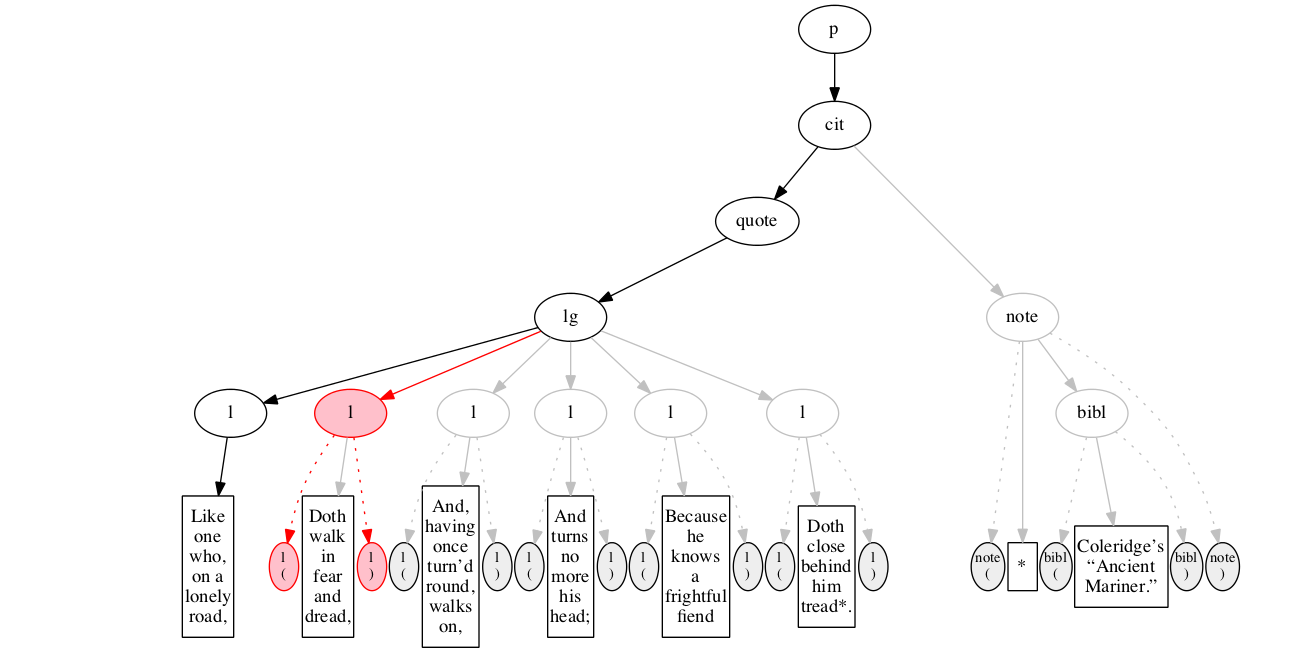
We then encounter a start-marker for the first line of verse.
And finally some text data: the text of the first line of verse.
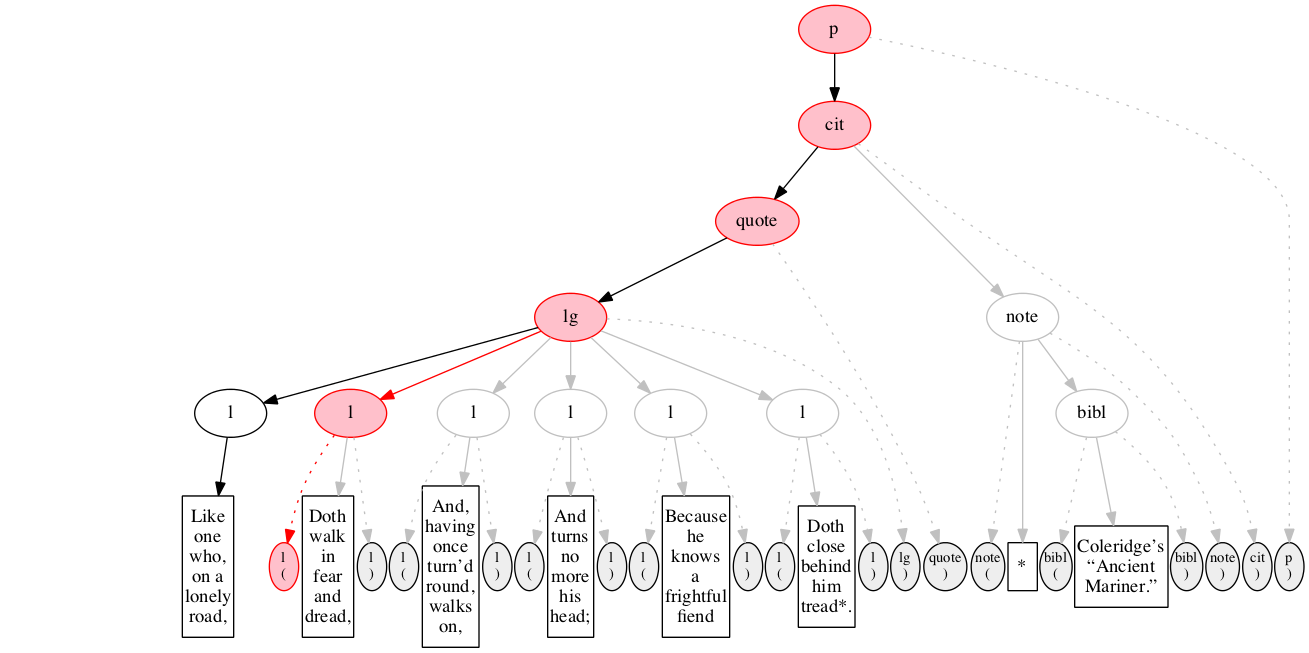
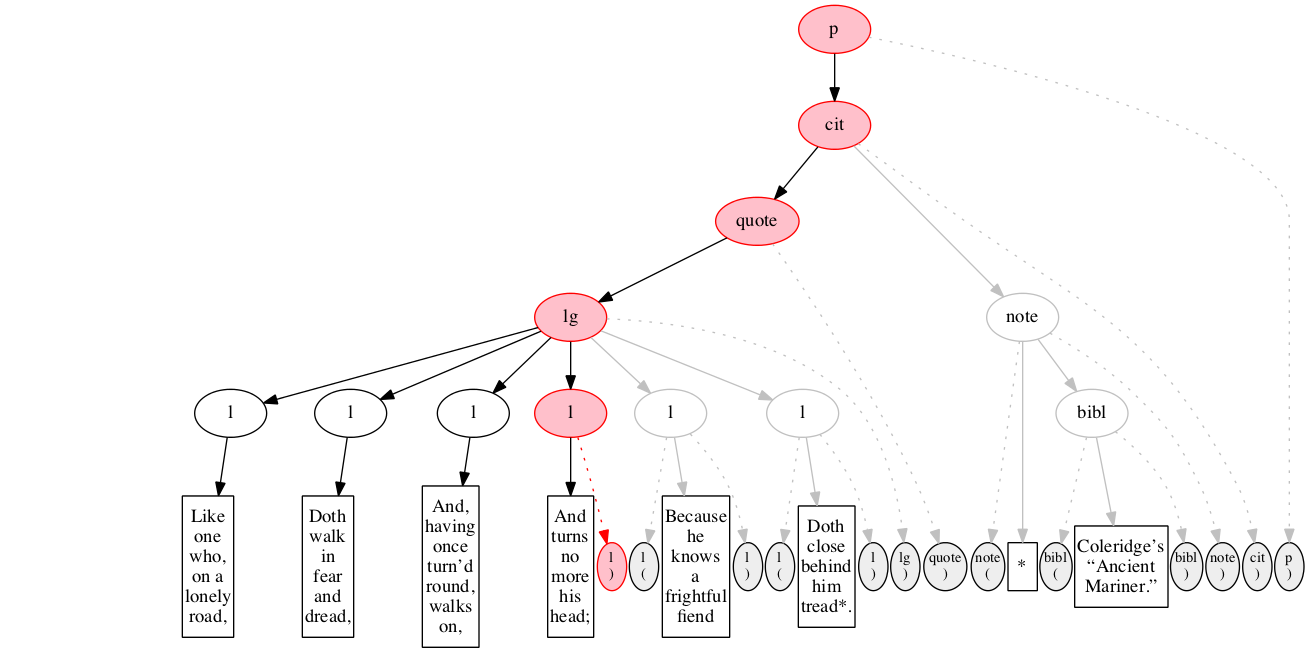
End-marker for the first line.
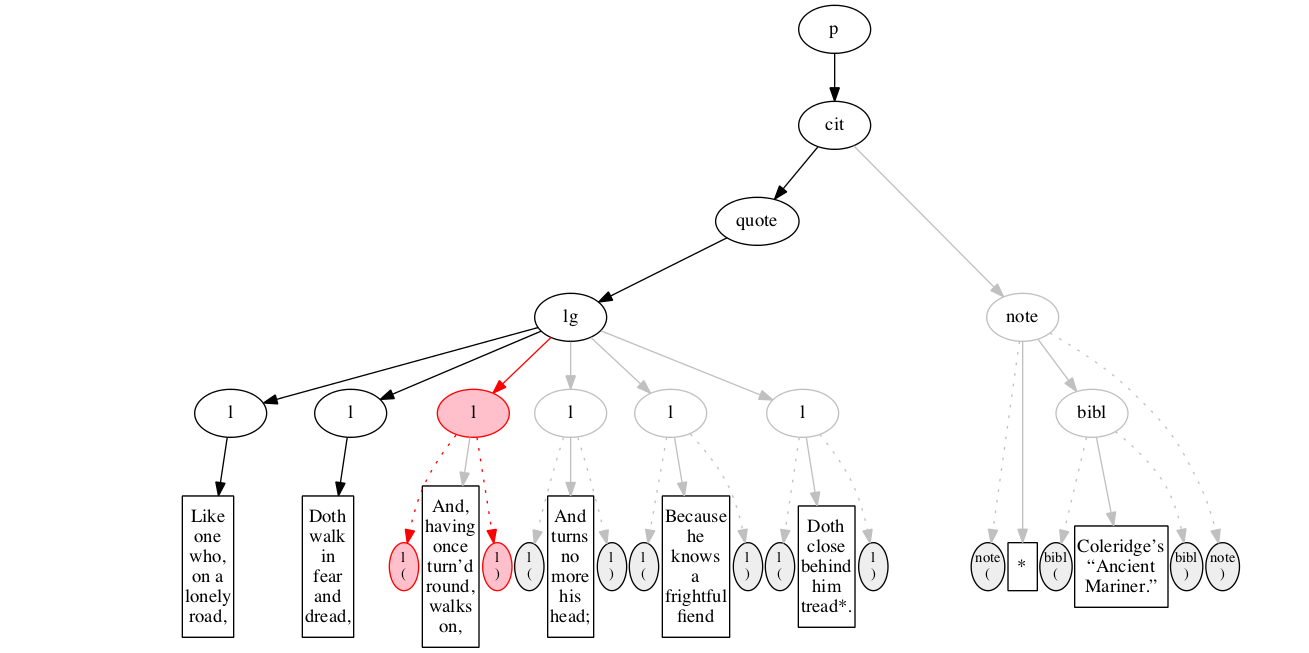
We then encounter a start-marker for the second line of verse. The first line is now finished (as signaled by the change in color).
The text of the second line of verse.
End-marker for the second line.
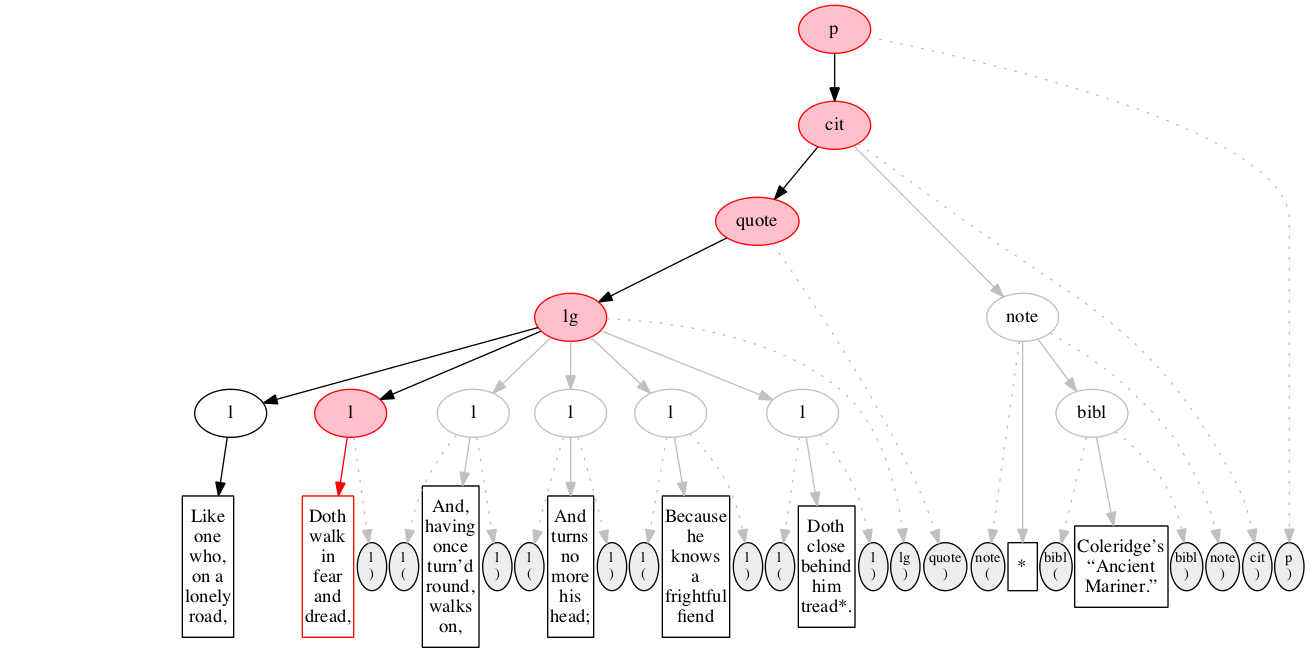
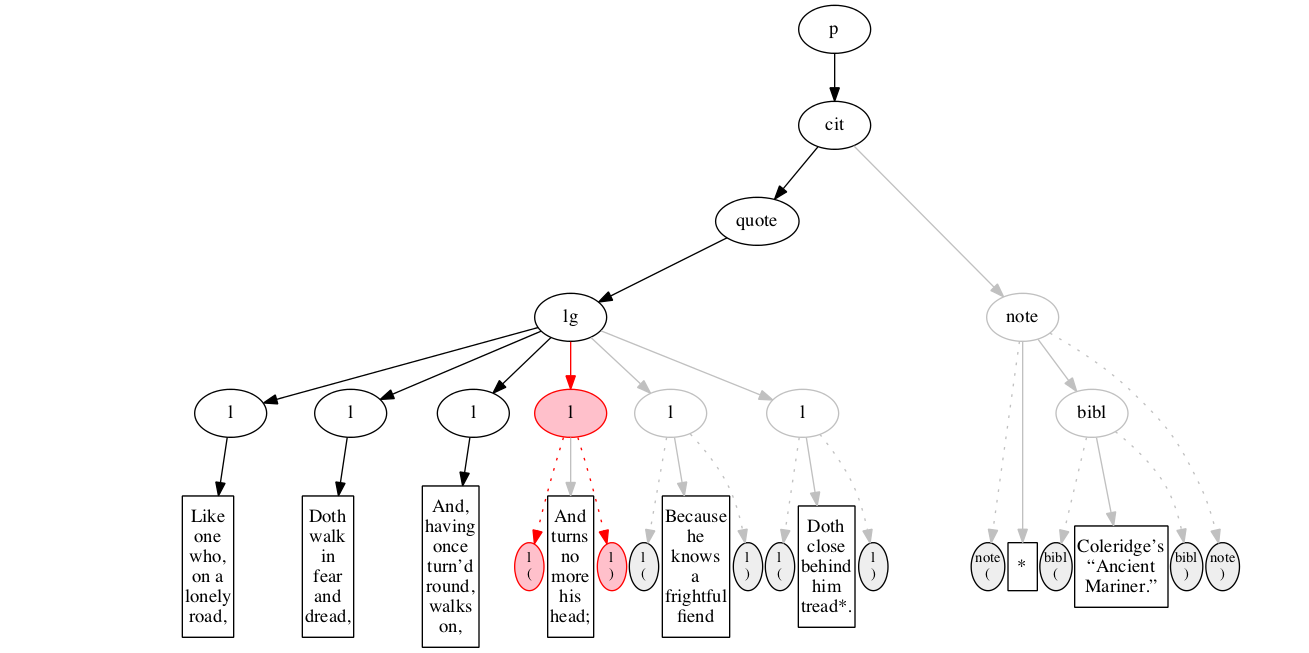
Start-marker for the third line of verse.
Text of the line.
End-marker for the line.
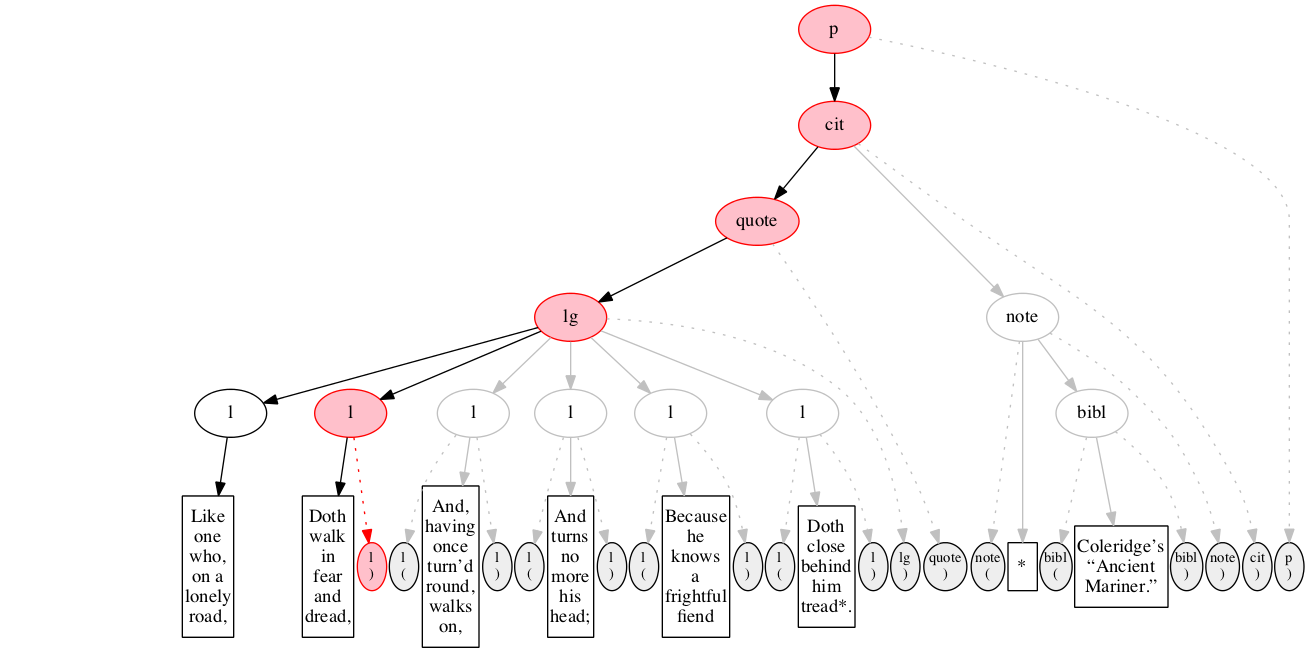
Start-marker for the fourth line of verse.
Text of the line.
End-marker for the fourth line.
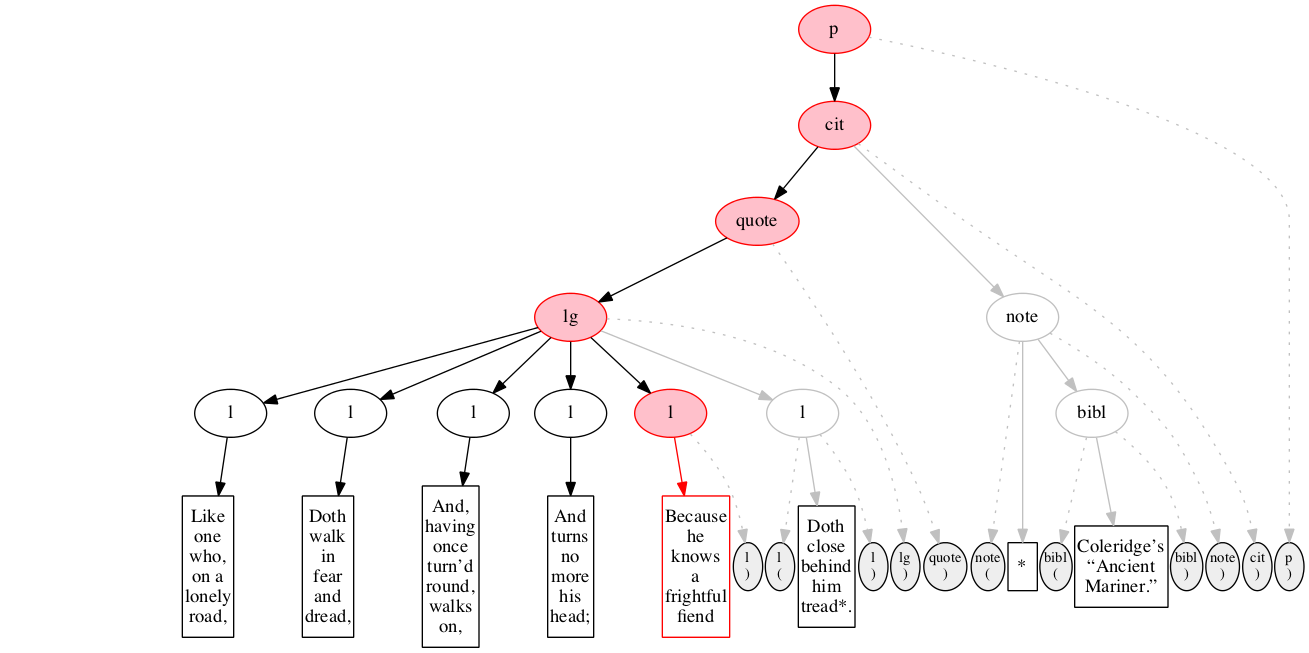
Start-marker for the fifth line of verse.
Text of the line.
End-marker for the fifth line.
Start-marker for the last line of verse.
Text of the line.
End-marker for the line.
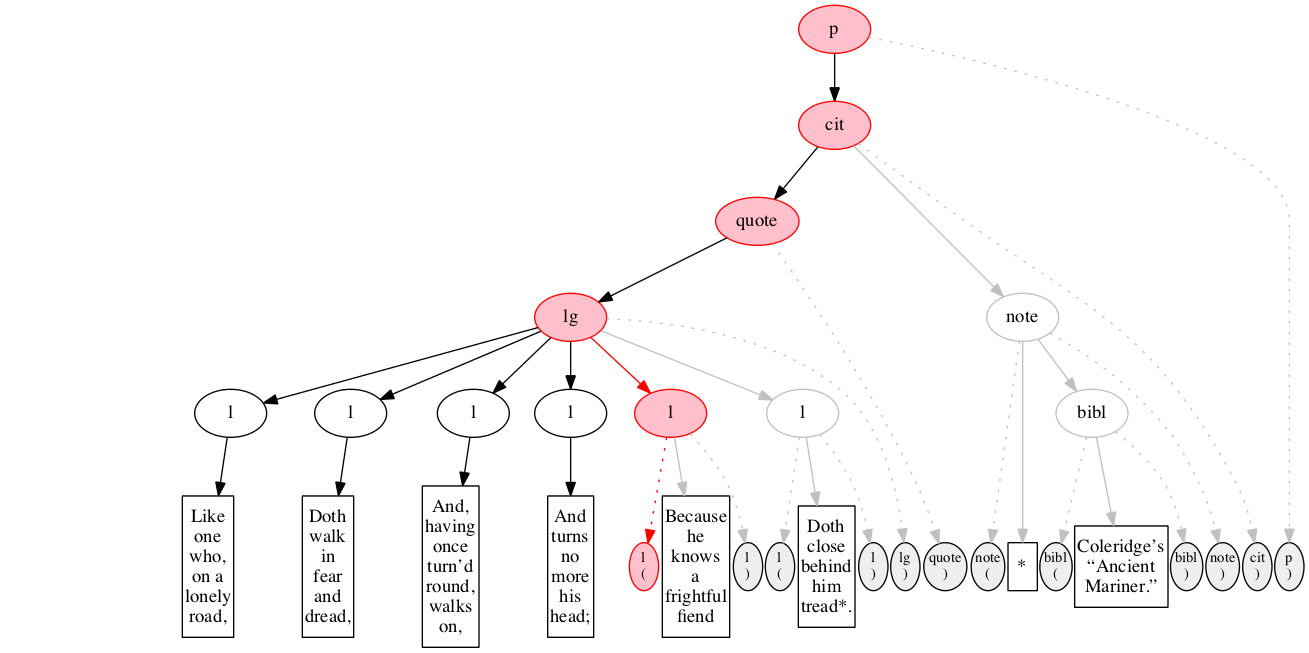
The end-marker for the line group.
End-marker for the quotation.
Start-marker for the note attributing the quotation.
Text directly within the note.
Start-marker for bibliographic reference.
Text of the bibliographic reference.
End-marker for the bibliographic reference.
End-marker for the note.
End-marker for the citation.
End-marker for the paragraph.
Final raised state.
<xsl:template match="*[th:is-start-marker(.)]" mode="raising">
<!--* 1: handle this element *-->
<xsl:copy copy-namespaces="no">
<xsl:copy-of select="@* except @th:*"/>
<xsl:apply-templates select="following-sibling::node()[1]"
mode="raising">
</xsl:apply-templates>
</xsl:copy>
<!--* 2: continue after this element *-->
<xsl:apply-templates select="th:matching-end-marker(.)
/following-sibling::node()[1]"
mode="raising">
</xsl:apply-templates>
</xsl:template>On start-marker
<xsl:template match="*[th:is-end-marker(.)]" mode="raising">
<!--* no action necessary *-->
<!--* we do NOT recur to our right. We leave it to our parent
to do that. *-->
</xsl:template>On end-marker
On other nodes
<xsl:template match="text() | comment() | processing-instruction()"
mode="raising">
<xsl:copy/>
<xsl:apply-templates select="following-sibling::node()[1]"
mode="raising"/>
</xsl:template>At the outset, we have a flat sequence of nodes.
On the first pass we raise all character-only elements.
On the second pass, we raise the line group and the note.
On the third pass, we raise the quote element.
On the fourth pass, the citation element.
On the fifth and final pass, we raise the paragraph.
Final state. Number of passes = depth of tree.
Initiation: call th:raise() on the document node:
<xsl:template match="/">
<xsl:sequence select="th:raise(.)"/>
</xsl:template>th:raise() function: either applies templates and then recurs or stops:
<xsl:function name="th:raise">
<xsl:param name="input" as="document-node()"/>
<xsl:choose>
<xsl:when test="exists($input//*[@th:sID eq
following-sibling::*[@th:eID][1]/@th:eID])">
<!-- If we have more work to do, do it -->
<xsl:variable name="result" as="document-node()">
<xsl:document>
<xsl:apply-templates select="$input" mode="loop"/>
</xsl:document>
</xsl:variable>
<xsl:sequence select="th:raise($result)"/>
</xsl:when>
<xsl:otherwise>
<!-- We have no more work to do, return the input unchanged. -->
<xsl:sequence select="$input"/>
</xsl:otherwise>
</xsl:choose>
</xsl:function>Matching the virtual innermost pairs
<xsl:template match="*[@th:sID eq
following-sibling::*[@th:eID][1]/@th:eID]" priority="1">
<xsl:copy copy-namespaces="no">
<xsl:copy-of select="@* except @th:sID"/>
<xsl:variable name="end-marker" as="element()"
select="following-sibling::*[@th:eID][1]"/>
<xsl:copy-of select="following-sibling::node()
[. << $end-marker]"/>
</xsl:copy>
</xsl:template>If the first end-marker we see after a start-marker matches, we have a virtual innermost pair. Raise it!
Suppress anything inside a virtual innermost pair:
<xsl:template match="node()
[preceding-sibling::*[@th:sID][1]/@th:sID
eq
following-sibling::*[@th:eID][1]/@th:eID]"
priority="1"/>Suppress the end-marker:
<xsl:template match="*
[@th:eID eq preceding-sibling::*[@th:sID][1]/@th:sID]"
priority="1"/>Copy anything not inside an innermost pair:
<!-- identity template (all modes) -->
<xsl:template match="@* | node()" mode="#all">
<xsl:copy>
<xsl:apply-templates select="@* | node()"/>
</xsl:copy>
</xsl:template>Q: Can we make a mirror-image of inside-out from the other way around?
A: Sort of. . .
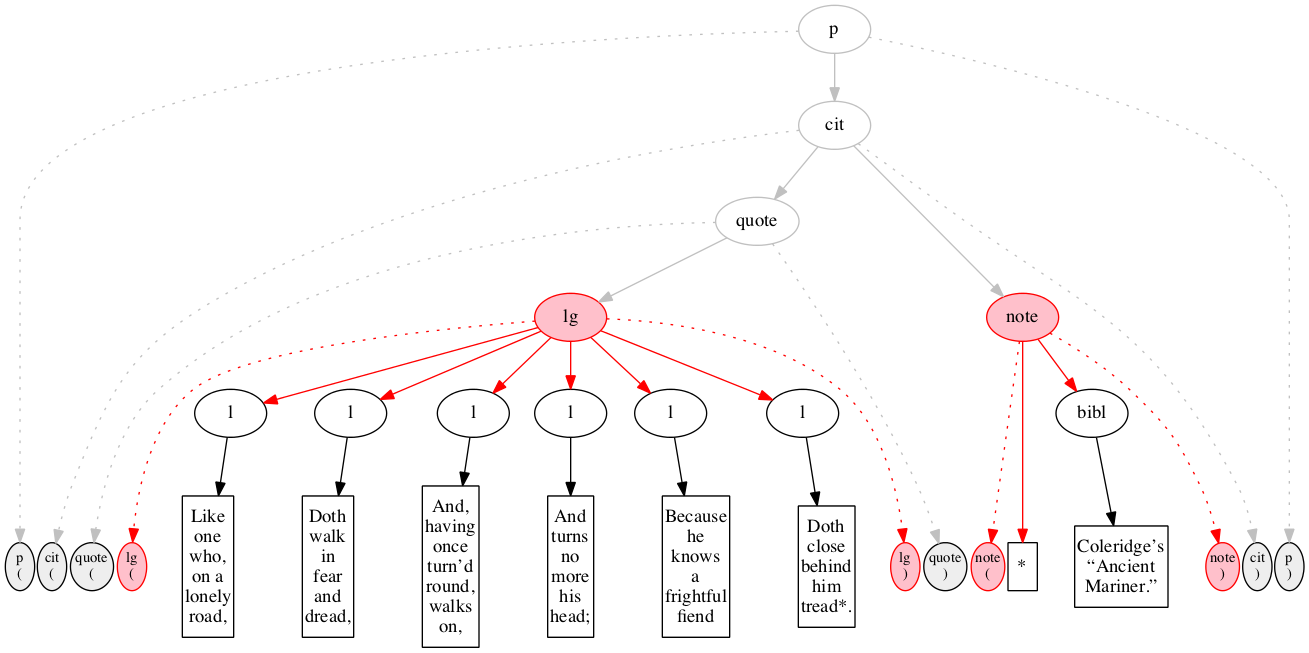
At the outset, we have a flat sequence of nodes.
On the first pass we raise the outermost element, the <p>.
On the second pass, we raise the citation element. The <p> element is finished, though its children are still in process.
On the third pass, we raise the <quote> element, but we don't know how to raise the <note> at the same time.
On the fourth pass, we recur on the content of the quotation and raise the line group.
On the fifth pass, we raise the first line.
We raise the second line (6th pass).
Third line (7th pass).
Fourth line (8th pass).
Fifth line (9th pass).
Sixth line (10th pass)
Now we finally make it to the note. (11th pass)
On the 12th and final pass, we raise the bibliographic reference within the note.
Final raised state.
<xsl:template match="*[exists(node())]">
<xsl:copy>
<xsl:sequence select="@*, th:raise-sequence(child::node())"/>
</xsl:copy>
</xsl:template>
On any content element, check for markers and raise them:
<xsl:function name="th:raise-sequence" as="node()*">
<xsl:param name="ln" as="node()*"/>
<!--* lidStarts, lidEnds: lists of IDs for start- and end-markers *-->
<xsl:variable name="lidStarts" as="xs:string*"
select="for $n in $ln[th:start-marker(.)]
return th:id($n)"/>
<xsl:variable name="lidEnds" as="xs:string*"
select="for $n in $ln[th:end-marker(.)]
return th:id($n)"/>
<xsl:choose>
<!--* base case: no start-marker / end-marker pairs present *-->
...
<!--* 'normal' case: take first start-marker with matching end-marker *-->
...
</xsl:choose>
</xsl:function>The th:raise-sequence() function checks for matching start-/end-marker pairs. If none, it terminates, returning its input. Otherwise, it has work to do.
<!--* base case: no start-marker / end-marker pairs present *-->
<xsl:when test="empty($lidStarts[. = $lidEnds])">
<!--* The sequence may contain elements with markers inside,
* so we apply templates, instead of just returning $ln *-->
<xsl:apply-templates select="$ln"/>
</xsl:when>If there are no matching markers present, we're done.
In the normal case, we
<!--* 'normal' case: take first start-marker with matching end-marker *-->
<xsl:otherwise>
<!--* find ID of first start-marker with matching end-marker *-->
<xsl:variable name="id" as="xs:string"
select="$lidStarts[. = $lidEnds][1]"/>
<!--* find position of start- and end-markers with that ID *-->
<xsl:variable name="posStartEnd" as="xs:integer+"
select="for $i in 1 to count($ln) return
if ($ln[$i][(th:start-marker(.)
or th:end-marker(.))
and th:id(.) eq $id])
then $i else ()"/>
<xsl:variable name="posStart" as="xs:integer"
select="$posStartEnd[1]"/>
<xsl:variable name="posEnd" as="xs:integer"
select="$posStartEnd[2]"/>Find the first start-marker with a matching end-marker. Then divide the sequence into left, center, right subsequences.
<!--* Apply templates to all items to left of start. These may
* include markers, but if so they are not matched and not
* raisable. They may also include elements which contain
* markers, so we need to apply templates, not just return
* them. *-->
<xsl:apply-templates select="$ln[position() lt $posStart]"/>Apply templates to left subsequence.
<!--* Raise the element and call raise-sequence() on its
* content. *-->
<xsl:copy select="$ln[$posStart]">
<!--* copy the attributes (filtering as needed) *-->
<xsl:sequence select="$ln[$posStart]/(@* except @th:*)"/>
<!--* handle children *-->
<xsl:sequence select="th:raise-sequence(
$ln[position() gt $posStart
and position() lt $posEnd]
)"/>
</xsl:copy>Make element from start-marker; recur on center subsequence (as children of new element).
<!--* call raise-sequence() on all items to right of end *-->
<xsl:sequence select="th:raise-sequence(
$ln[position() gt $posEnd]
)"/>
</xsl:otherwise>Recur, moving to the right subsequence:
So, how do they perform?
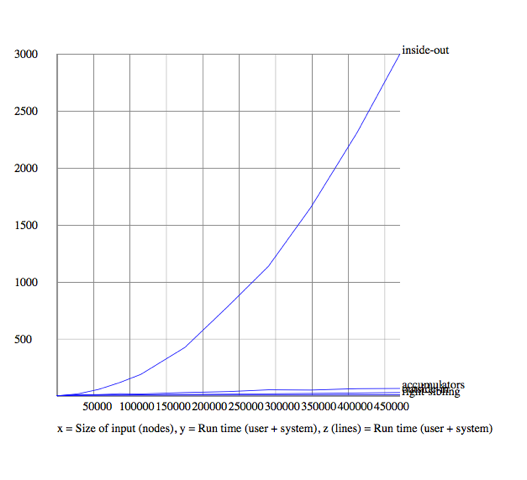
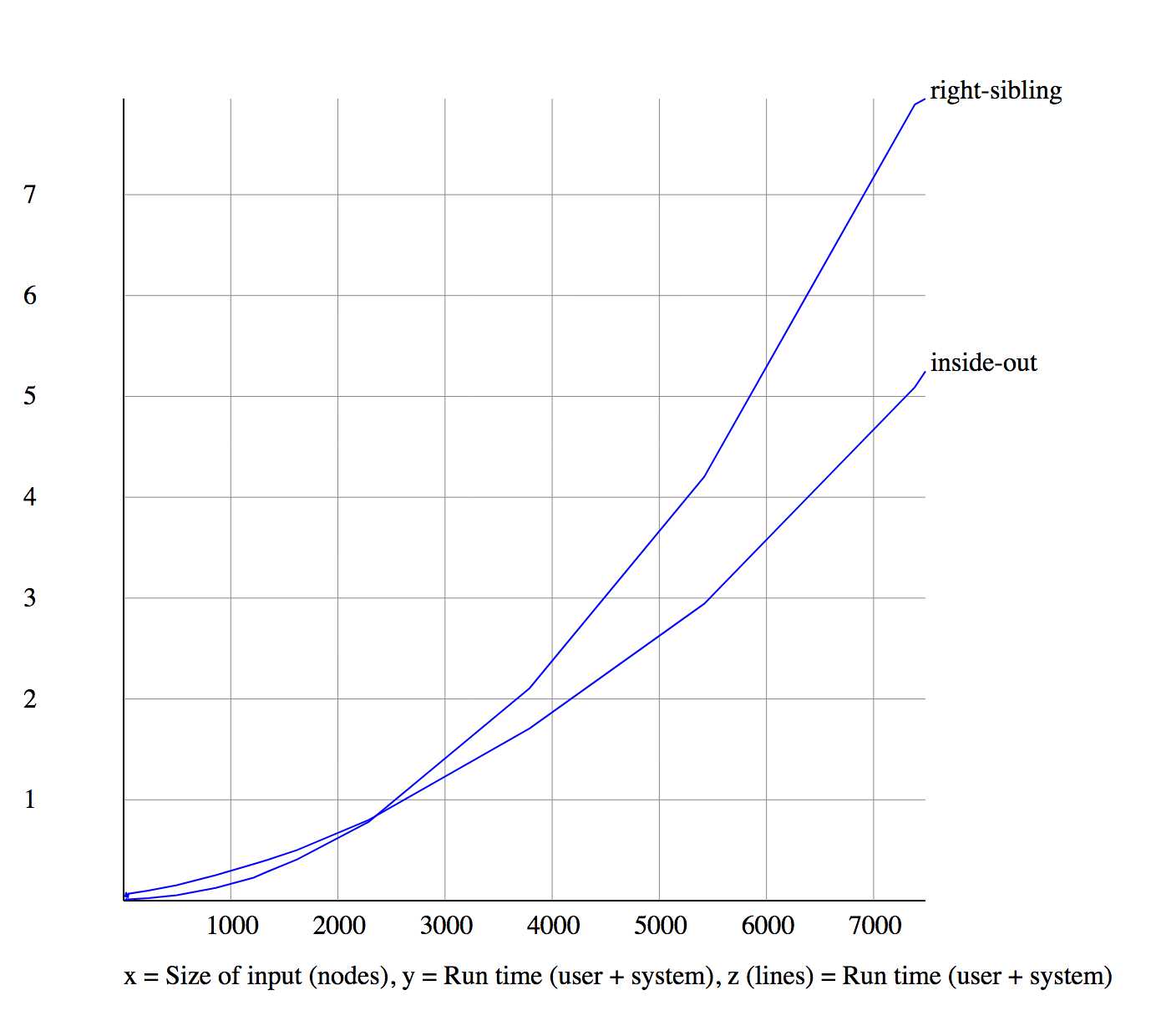
Comparison (four-way)
Right-sibling, outside-in, and accumulator are linear
Inside-out is quadratic
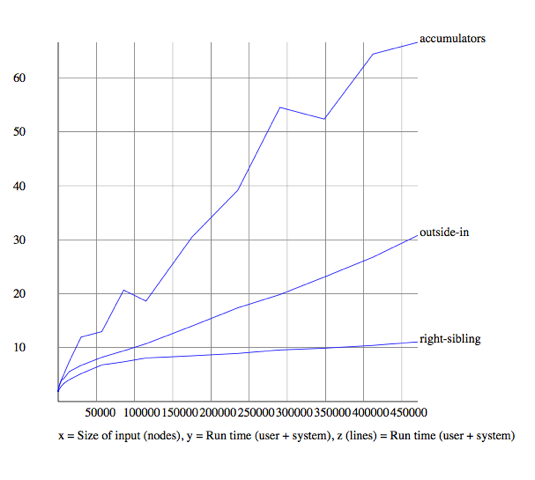
Comparison (three-way)
Right-sibling, outside-in, and accumulator
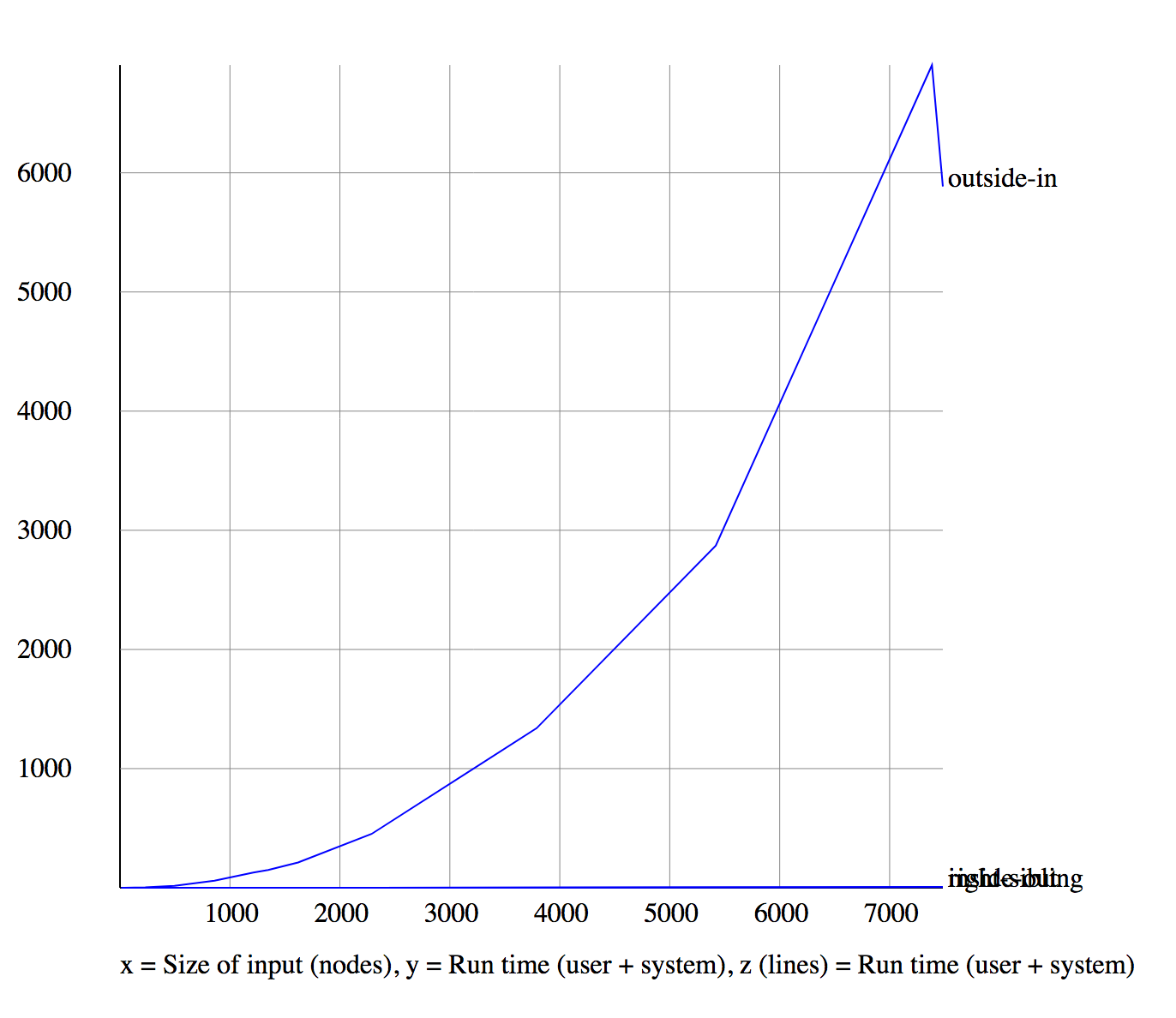
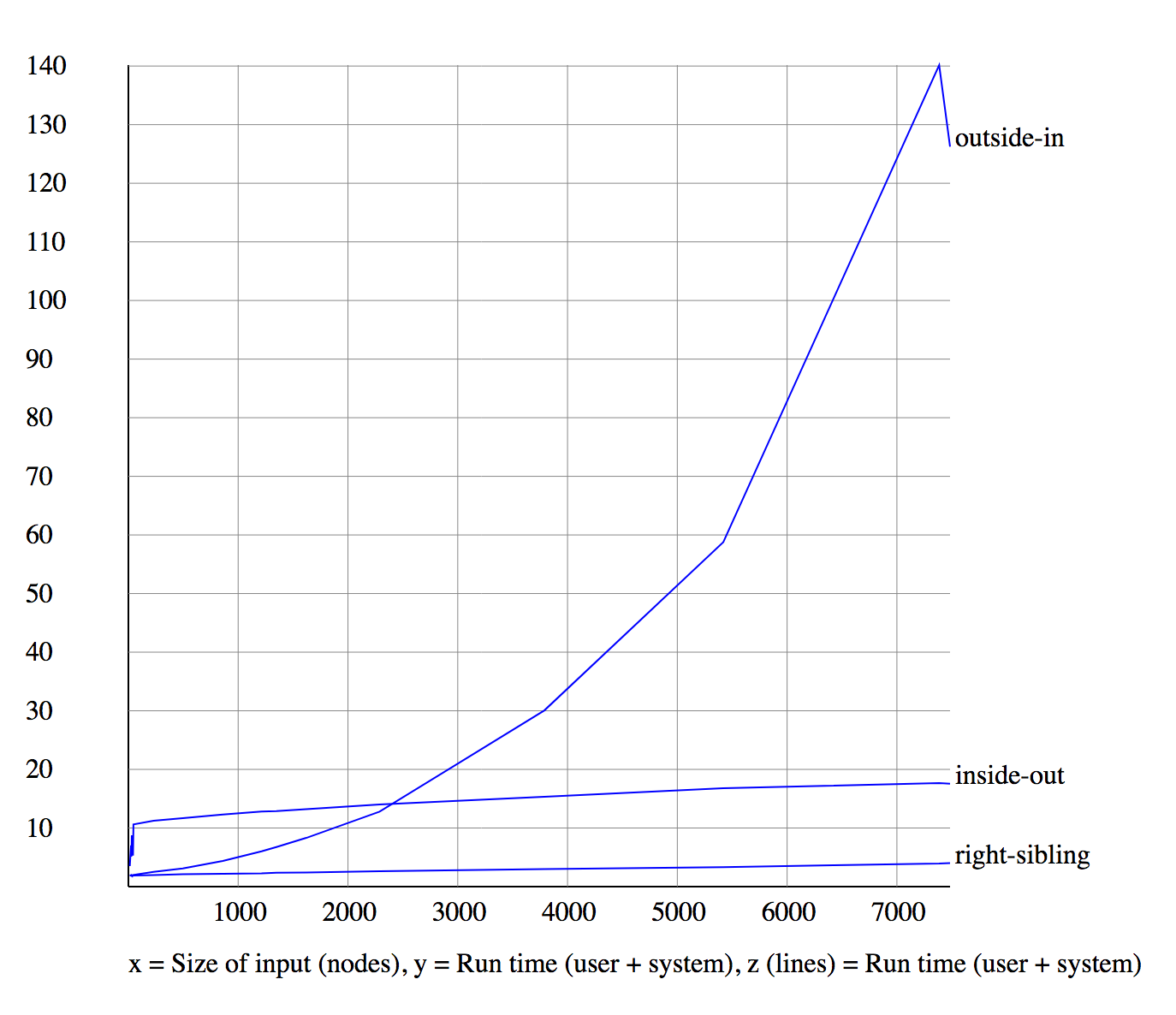
XSLT 1.0 comparison
Outside-in is now the problem child
XSLT 1.0 comparison
When we remove outside-in, inside-out is better than right-sibling
But look at the Y-axis scale
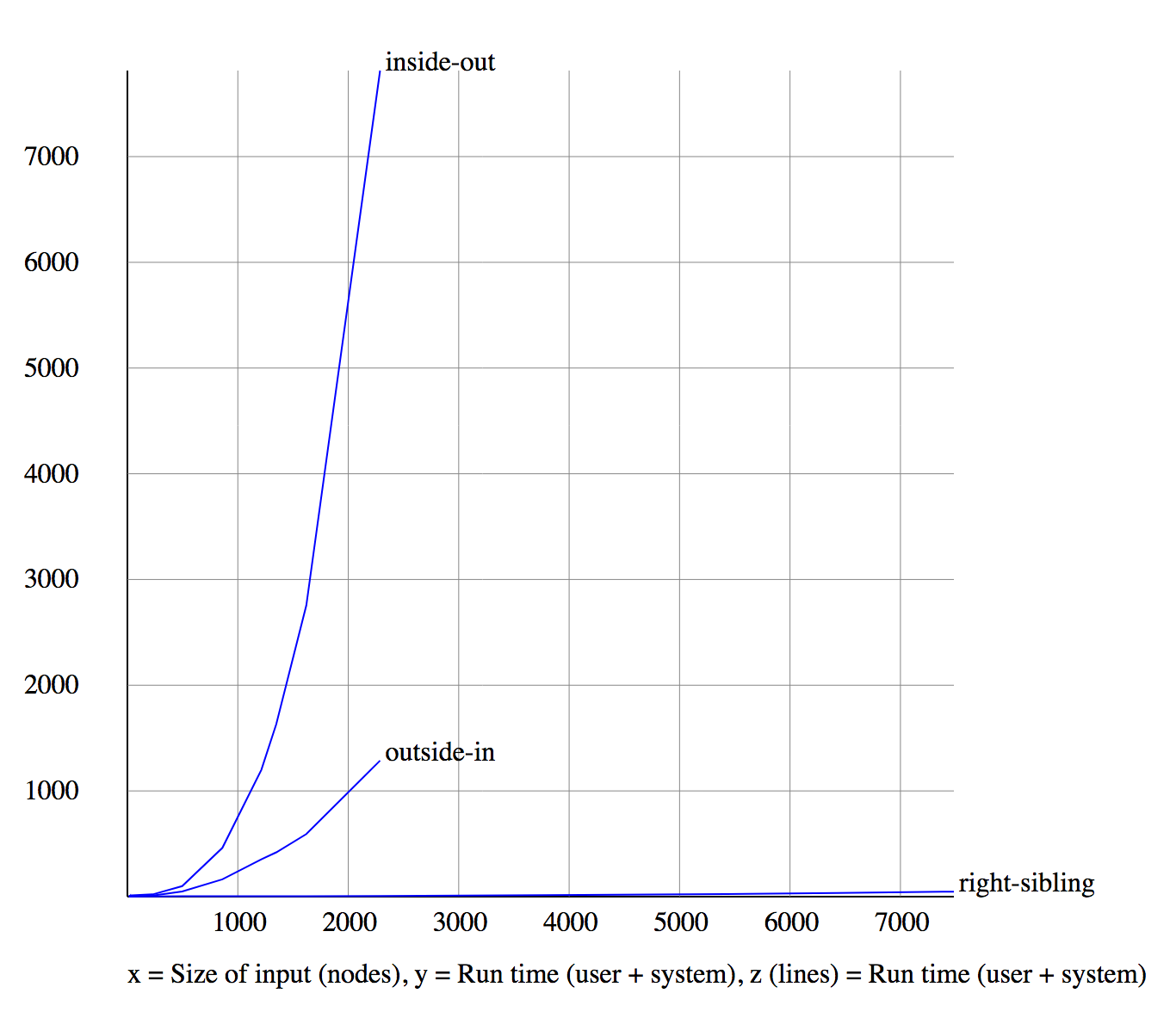
XSLT 1.0 comparison
Processor 2
XSLT 1.0 comparison
We gave up on inside-out and outside-in
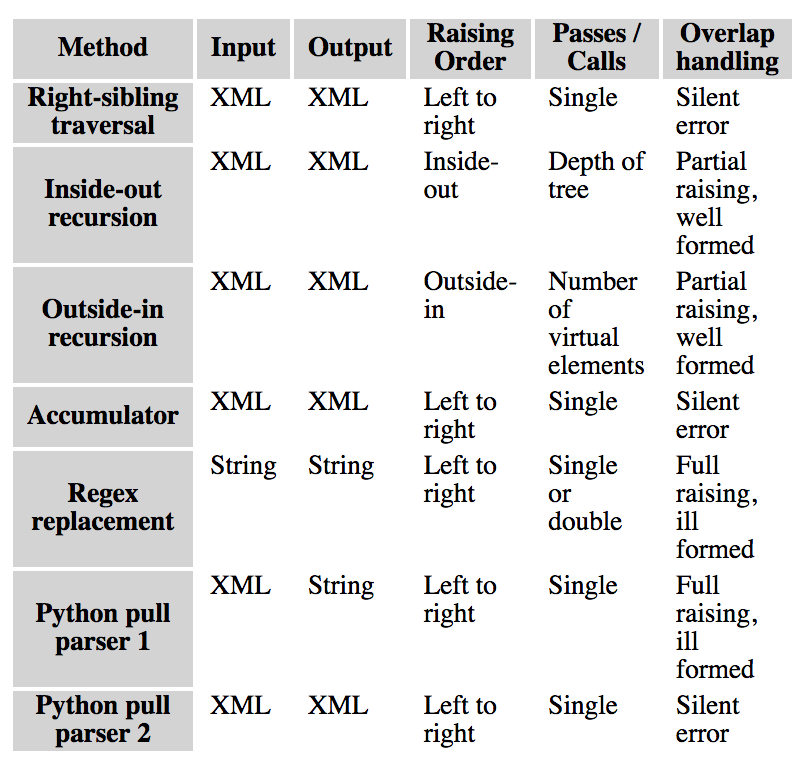
Feature comparison
String-processing tags
Pull parsing in Python
Left to right sibling traversal
Inside-out recursion
Inside-out recursion
Scans too far in case end-marker repeats (it doesn’t)
<xsl:copy-of
select="following-sibling::node()
[following-sibling::*[@th:eID eq current()/@th:sID]]"/>Finds the one match quickly
<xsl:variable
name="end-marker"
as="element()"
select="key('end-markers', @th:sID)"/>
<xsl:copy-of
select="following-sibling::node()[. << $end-marker]"/>Accumulators
Be sure your Saxon processor is fully XSLT 3.0.
Don't try this with Saxon HE 9.6.0.5
Don't forget to specify @use-accumulators= "stack" on default mode declaration.
For further investigation
Performance analysis
Memory usage? Stack space?
Are functions faster than named templates? Slower? Indifferent?
Are patterns of performance constant across processors?
Do XQuery function implementations of inside-out and outside-in show same performance patterns?
Why is outside-in tumbling window performance so bad in preliminary tests?
More solutions?
By Elisa Beshero-Bondar
presentation materials for Balisage 2018



