Demystification du Machine Learning
nicolas bulteau - fabrice depaulis
-
data scientists -
mathématiciens -
statisticiens
-
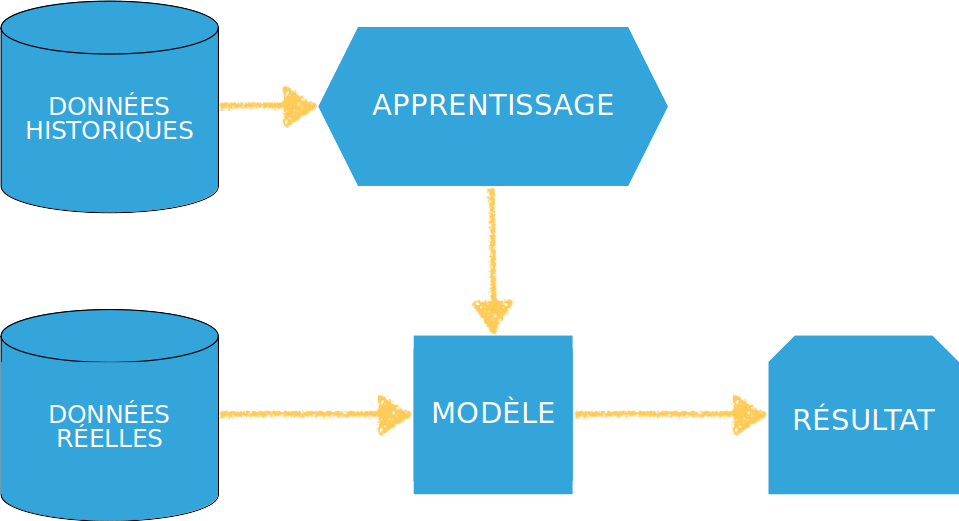
présenter le ML
-
rendre le ML tangible (code)
-
reconnaître un Use-Case

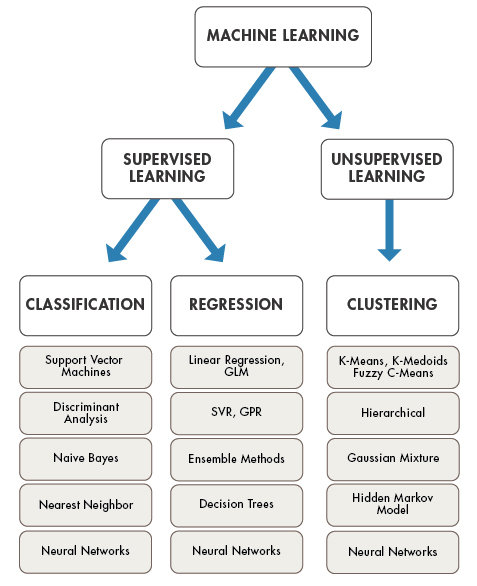
machine learning
traditional way



écrire un programme « à la main »
▸ Découvrir des corrélations dans un ensemble d'éléments collectés
▸ Fabriquer un modèle prédictif à partir d'exemples qualifiés
▸ Les données déterminent quel modèle doit être construit
learning way

pourquoi maintenant ?


data
Imagenet : 15 000 000 images
10 000 catégories
calcul matriciel
cartes gpu
algorithmes
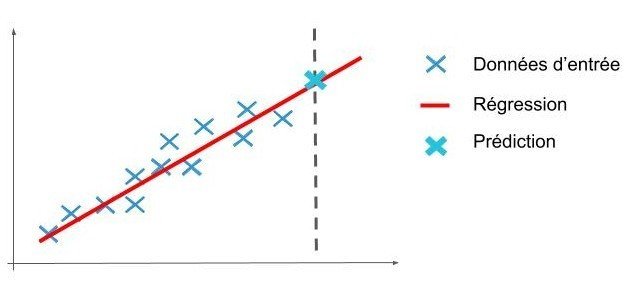
regression
classification
clustering
apprentissage
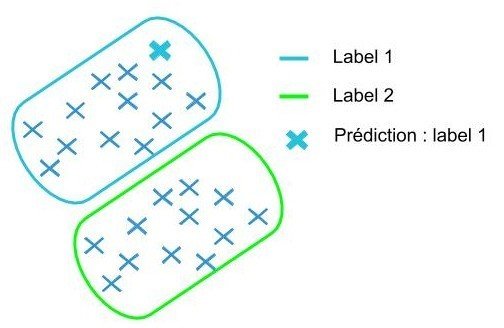
jeu de données labellisé
l'algorithme découvre seul les caractéristiques
apprentissage supervisé

plane cat dog bird beer horse frog
apprentissage
?
prediction

vendre mon appartement
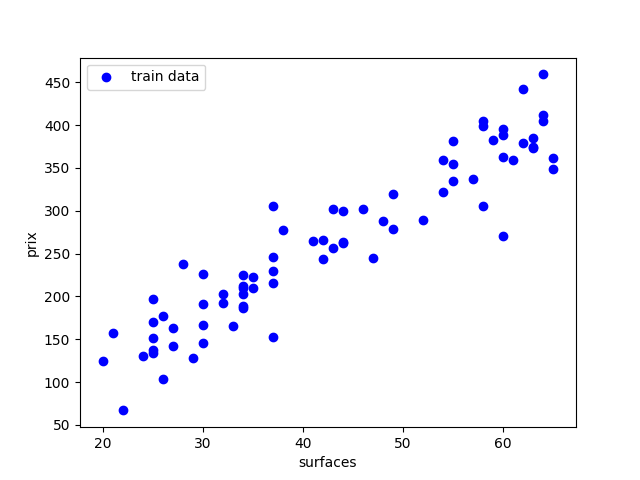
comment déterminer le prix ?
données d'apprentissage
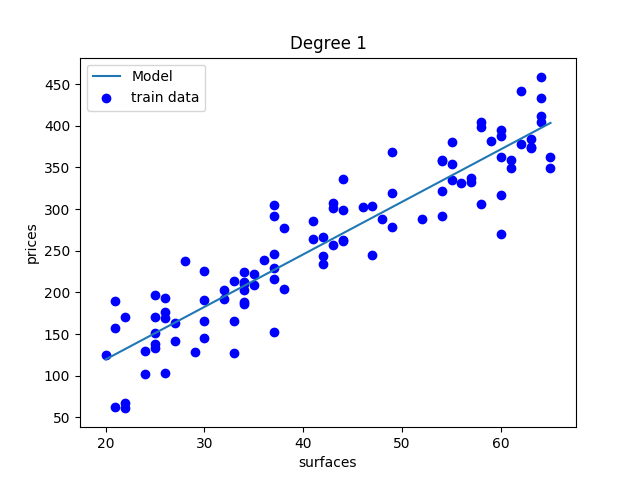
trouver prix en fonction de surface
trouver la fonction f(x) = y
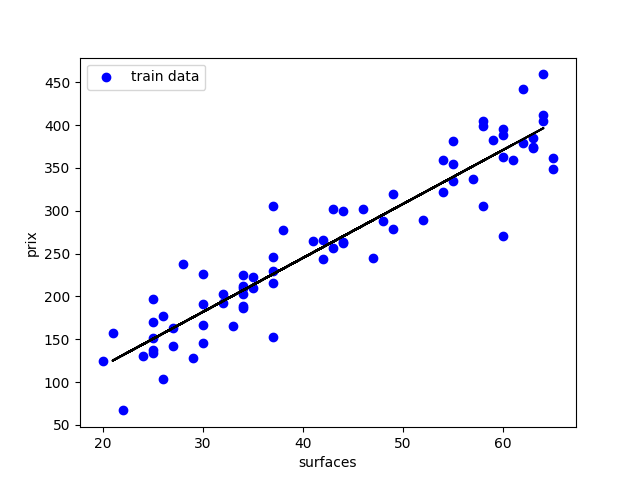
régression
surface
prix
mon appartement
| surface | prix |
|---|---|
| 61 | 171 000 |
| 23 | 112 000 |
| ... | ... |
pente
ordonnée à l'origine
apprentissage
prédiction
une droite peut être trop simple
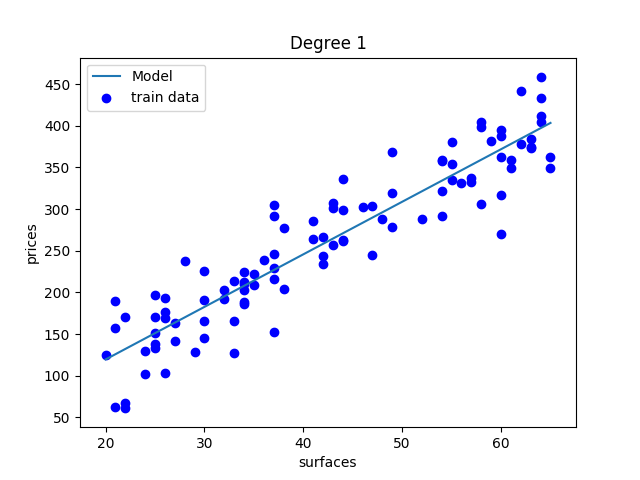
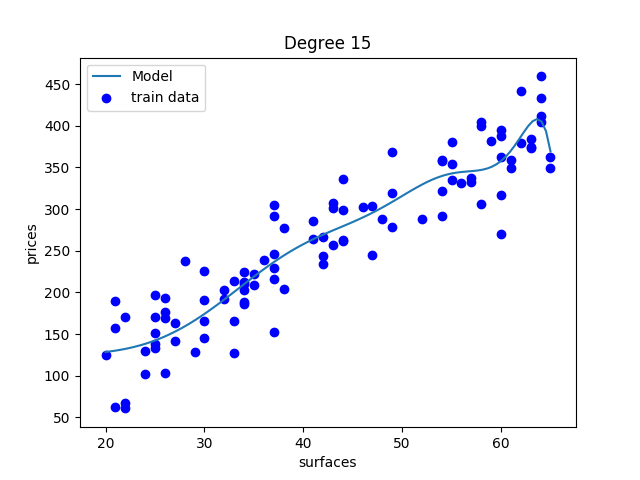
y = ax + b
y = ax + b + cx²
y = ax + b + cx² + dx³ + ...
overfitting !
en pratique !
collecter les données
entrainer le classifieur
prédire une valeur
from sklearn.linear_model import LinearRegression
surfaces, prix = surface_prix_data()
linear_regression.predict(63)
print(prediction)
> 390linear_regression = LinearRegression()
linear_regression.fit(surfaces, prix)| surface | prix |
|---|---|
| 22 | 66 |
| 63 | 373 |
| ... | ... |
plus de paramètres ?
-
Valeurs discrètes —> ensemble continue (la courbe noire)
-
Régression Linéaire à 1 paramètre
-
-
Dans la réalité beaucoup de « features » (dimensions) : surface, nb chambres, nb salles de bain, nb cheminées, garage, nb étages …
nombre de salles de bain
surface
nombre de chambres
...
prix
live coding
classifier
-
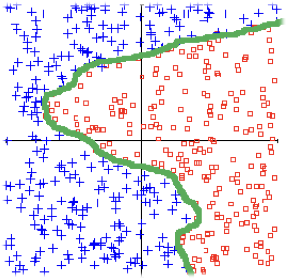
Classifier en utilisant l’apprentissage supervisé à partir de données étiquetées
-
Déterminer une fonction séparant les points bleus et rouges
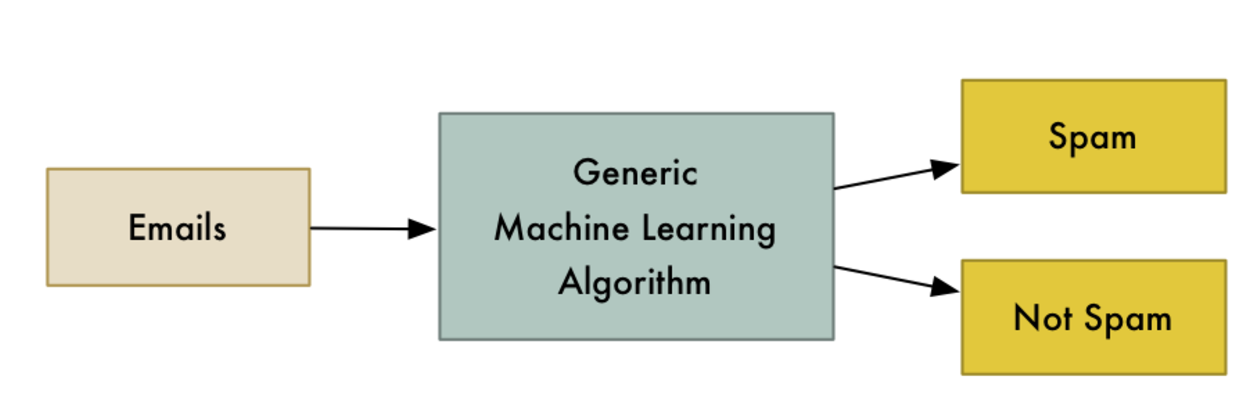
spam !
pas spam
classifier : SVM
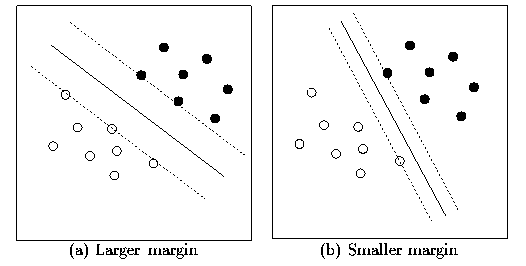
classifier : SVM
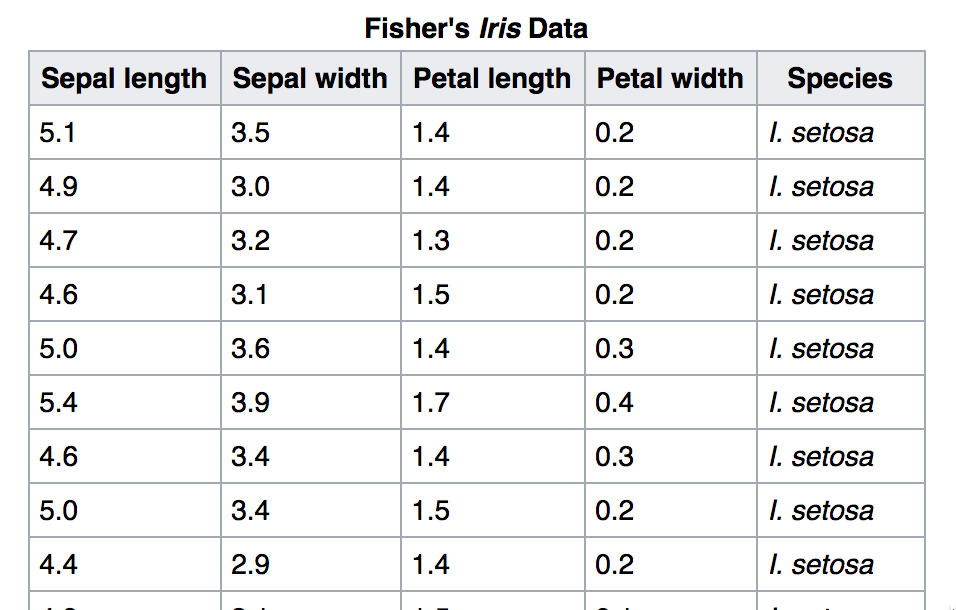



setosa
versicolor
virginica
live coding
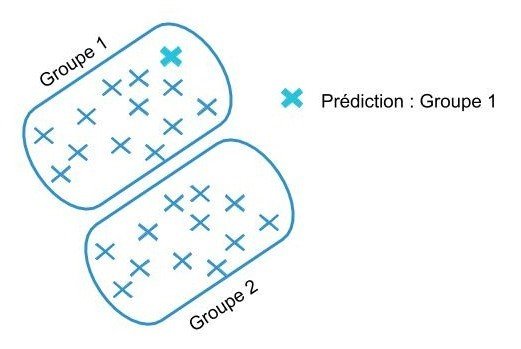
apprentissage non supervisé
La question n’est plus « peut-on prédire Y à partir de X ? » mais « que peut-on dire sur la manière dont les variables sont distribuées ? »
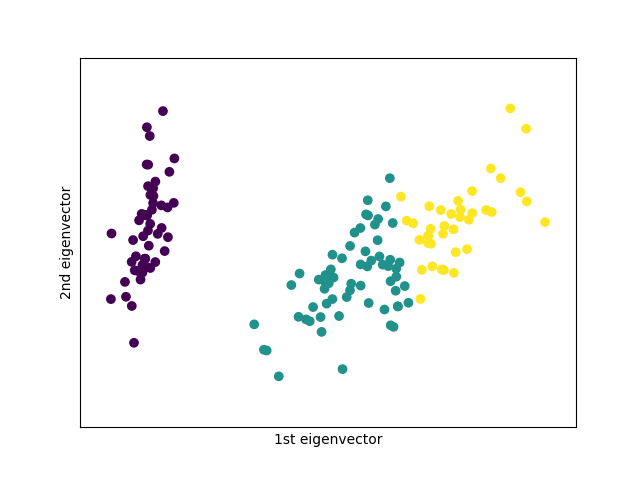
iris = datasets.load_iris()
X = iris.data
clf = KMeans(n_clusters=3)
clf.fit(X)
labels = clf.labels_supervisé / non supervisé
corrélation != causalité


La data est plus importante que l'algorithme
préparation des données
80%
algo
20%
deep learning
IA
ML
DL


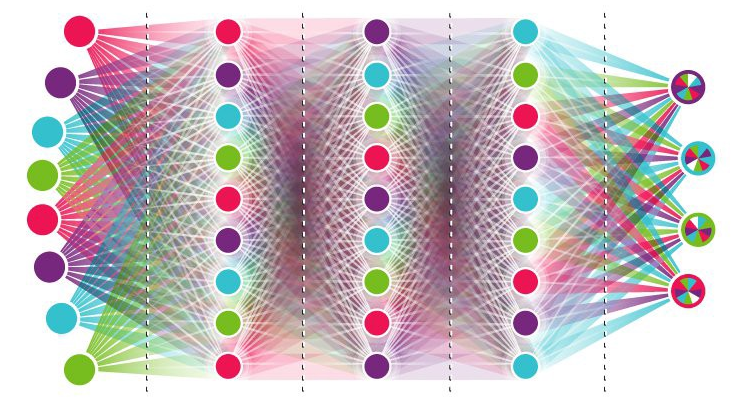


f(x_1, ..., x_n)
x_1
x_2
x_n
y
neurone
neurone formel
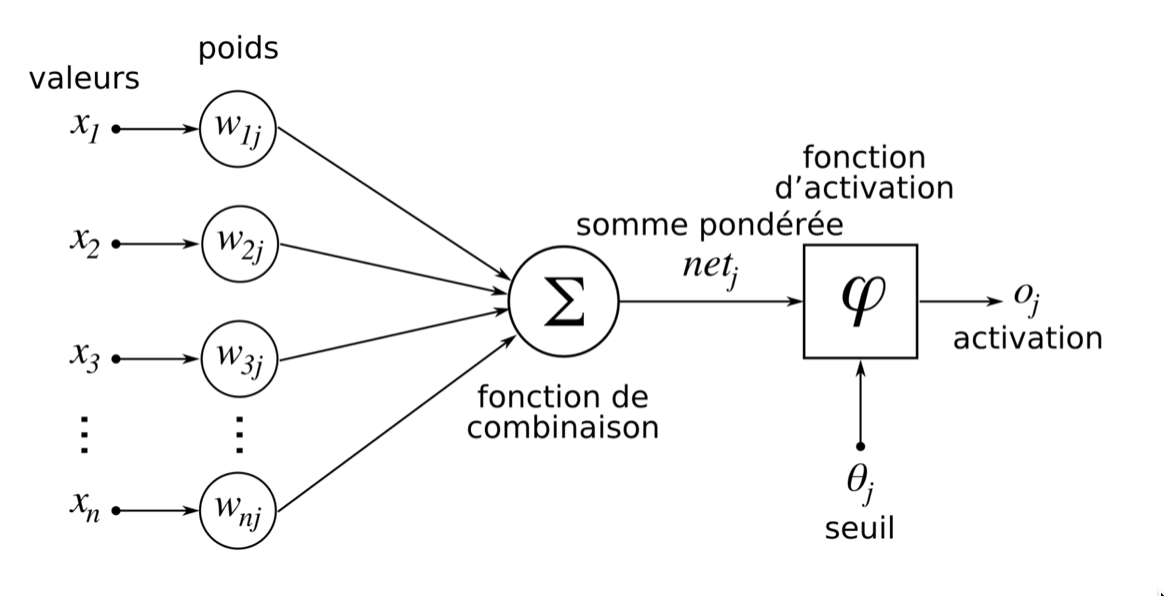
valeurs d'entrée
poids
somme des valeurs
pondérées
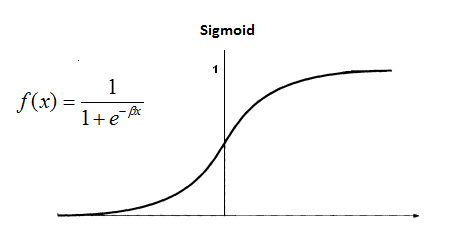
met la valeur
entre 0 et 1
valeur de sortie
neurone
formel
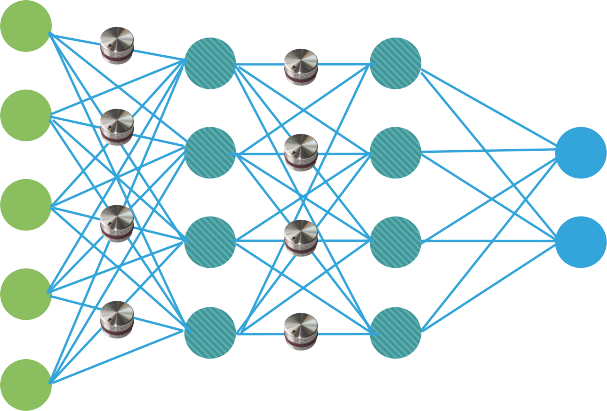
couche d'entrée
couches cachées
couche de sortie
réseau de neurones
Ok mais il est où l'apprentissage ?
ce qu'on apprend : les poids
modèle : matrice des poids
minimiser l'erreur : backpropagation
cross validation
f1 score
alpha go
renforcement
convolution
...
hyperparamètres
les poules de nico
ca marche !
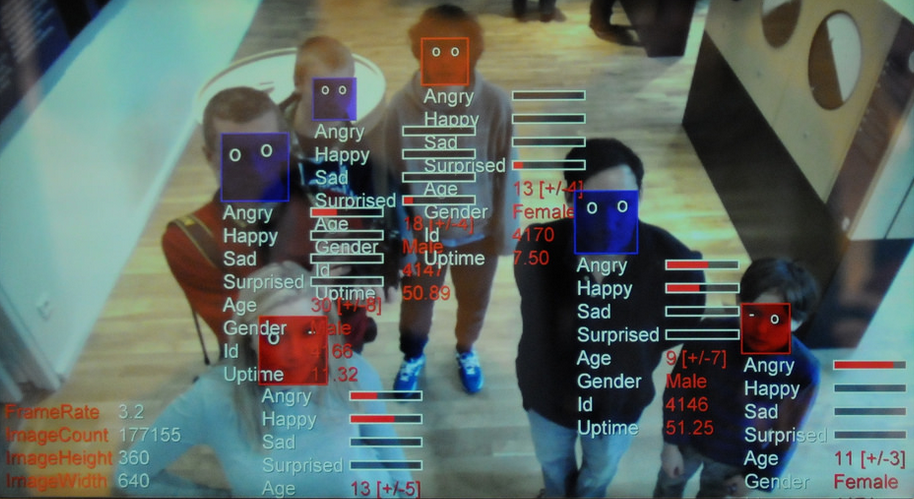







appliqué à nos problèmes
-
A quelle question veut-on répondre ?
-
Quelles sont les "features" ?
-
Traiter les données
-
Choisir l'algorithme
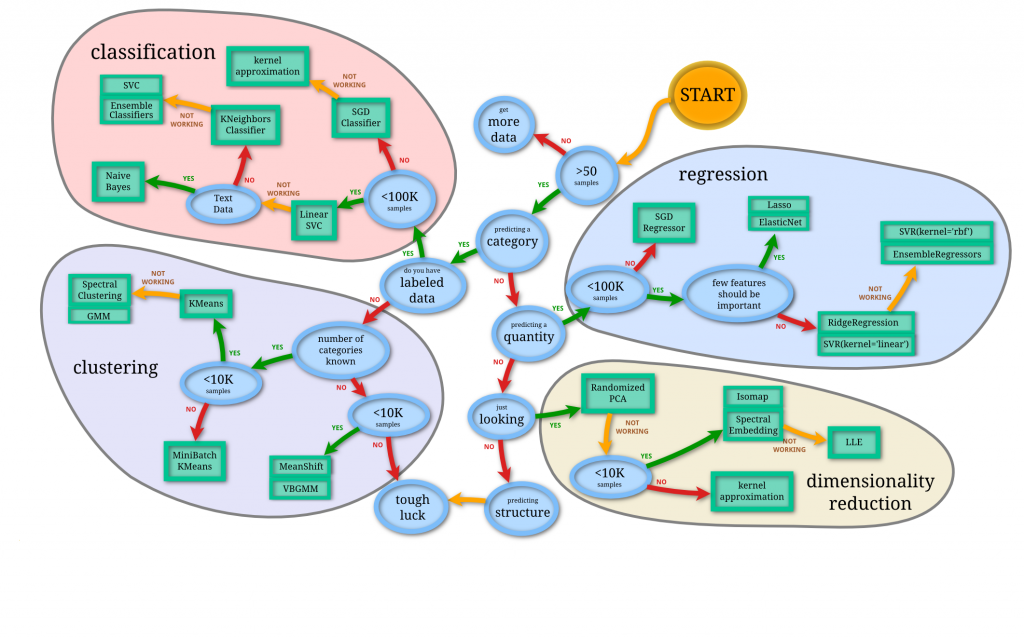
questions ?
Demystification du Machine Learning
By Fabrice Depaulis




