Ciencia de Datos con Apache Spark y Optimus

Favio Vázquez
Data Scientist


@faviovaz


March 15th, 2018

Esquema

1. Introducción a Apache Spark y Optimus
-
Fundamentos de Spark
-
Fundamentos de Optimus
2. Data Science con Spark y Optimus
-
Limpieza, Exploración y Preparación de Datos con Spark y Optimus
-
Introducción a Machine Learning con Spark y Optimus.

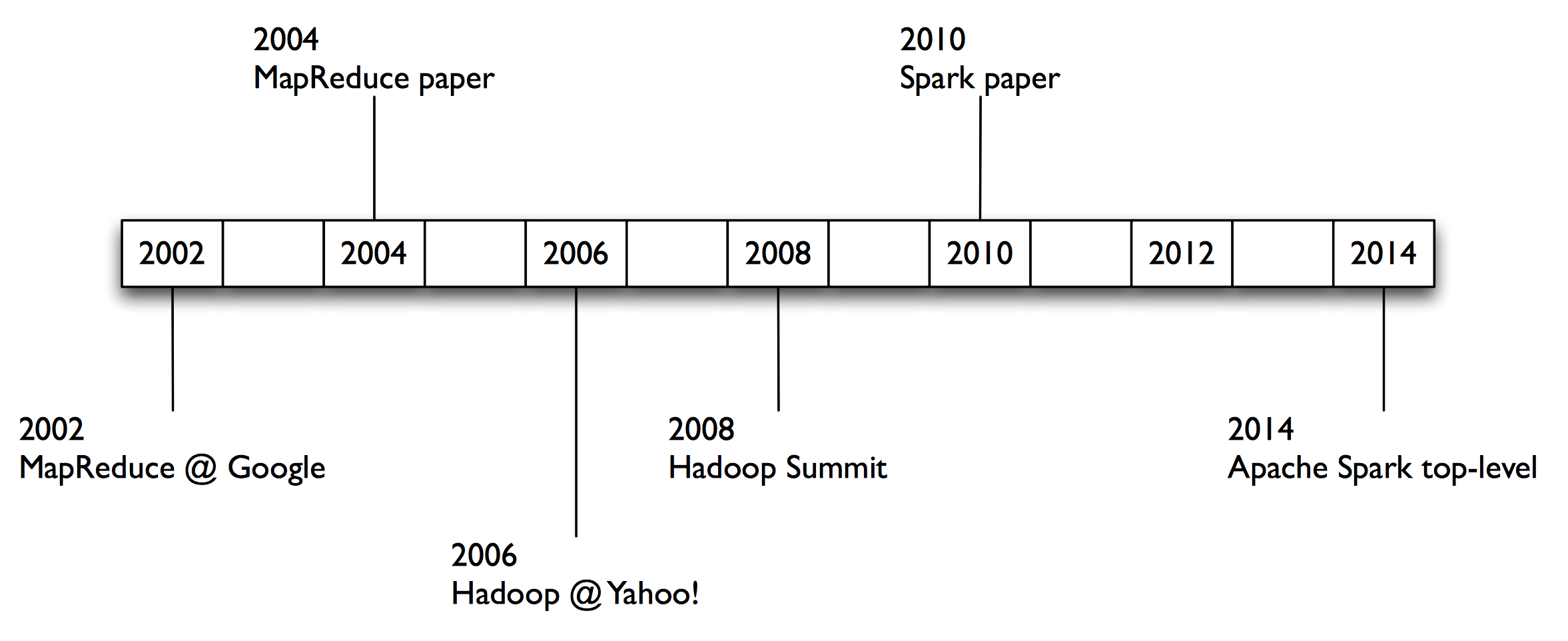
Historia

2004 – Google
MapReduce: Simplified Data Processing on Large Clusters
Jeffrey Dean and Sanjay Ghemawat research.google.com/archive/mapreduce.html
2006 – Apache
Hadoop, originating from the Nutch Project
Doug Cutting research.yahoo.com/files/cutting.pdf
2008 – Yahoo
web scale search indexing
Hadoop Summit, HUG, etc. developer.yahoo.com/hadoop/
2009 – Amazon AWS
Elastic MapReduce
Hadoop modified for EC2/S3, plus support for Hive, Pig, Cascading, etc. aws.amazon.com/elasticmapreduce/
¿Qué es complicado en Big Data?
La combinación compleja de hilos de ejecución, sistemas de almacenamiento y modos de trabajo.
- ETL, agregaciones, machine learning, streaming, etc.
Muy complicado obtener productividad y performance
¿Qué es?
Es un motor general y muy rápido para el procesamiento en paralelo de datos en gran escala.





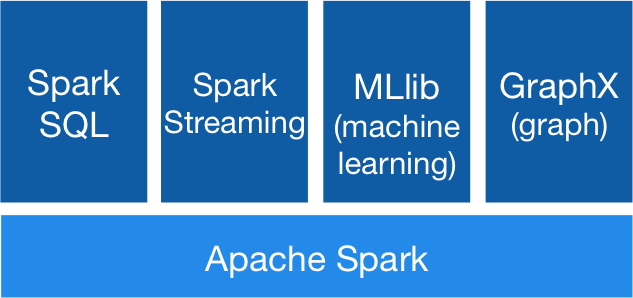
Motor Unificado
APIs de alto nivel con espacio para optimizar
- Expresa todo el workflow con una API
- Conecta librerías existentes y sistemas de almacenamiento
RDD
Transformaciones
Acciones
Caché
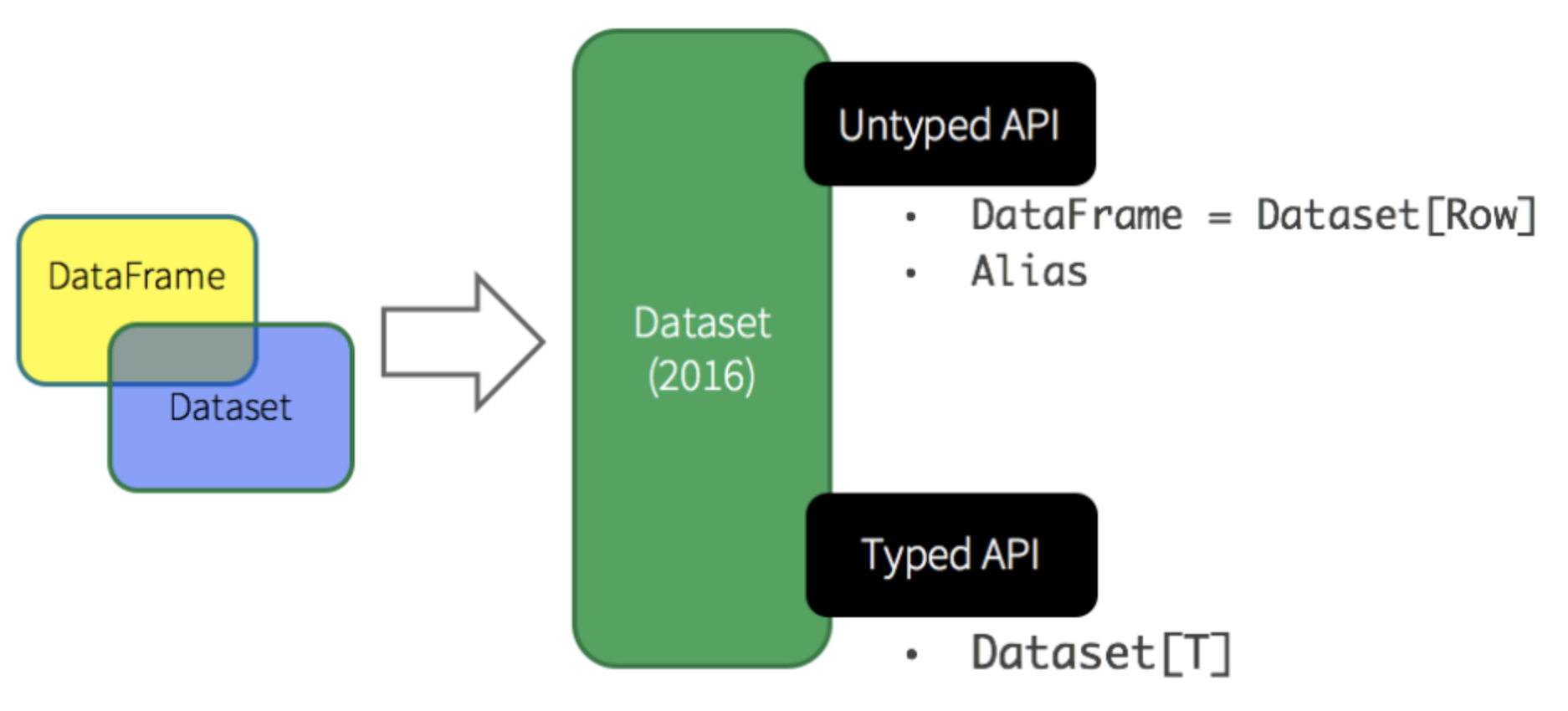
Dataset
Tipado
Scala y Java
Beneficios de RDD
Dataframe
Dataset[Row]
Optimizado
Versátil
FUNDAMENTOS
SparkContext
- Un programa Spark crea primero un objeto SparkContext que le indica a Spark cómo y dónde acceder a un clúster.
- El shell PySpark y Optimus crean automáticamente la variable sc.
- iPython y los programas deben usar un constructor para crear un nuevo SparkContext
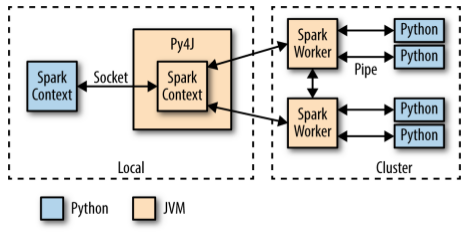
RDDs
Los Resilient Distributed Datasets (RDD) son una colección distribuida de objetos JVM inmutables que permiten realizar cálculos muy rápidamente, y son la columna vertebral de Apache Spark.

RDDs

DataFrames

DataFrames

DataFrames
DataFrames
data.map(lambda x: (x.rooms, [x.age,1]) \
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]]) \
.map(lambda x: x[0], x[1][0] / x[1][1]) \
.collect()- GroupBy y AVG con RDDs
- GroupBy y AVG con DataFrames
data.groupBy("rooms").avg("age")DataFrames

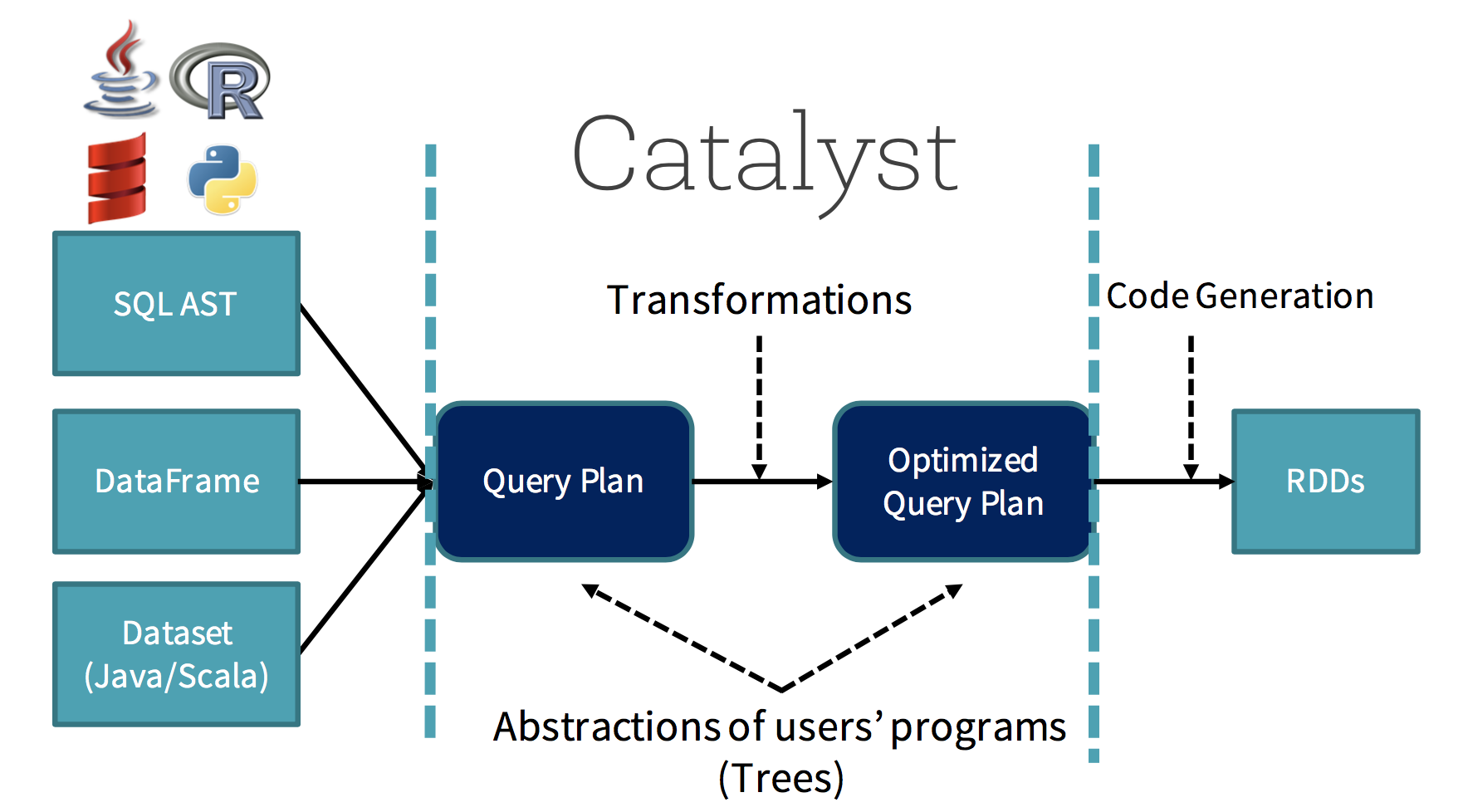
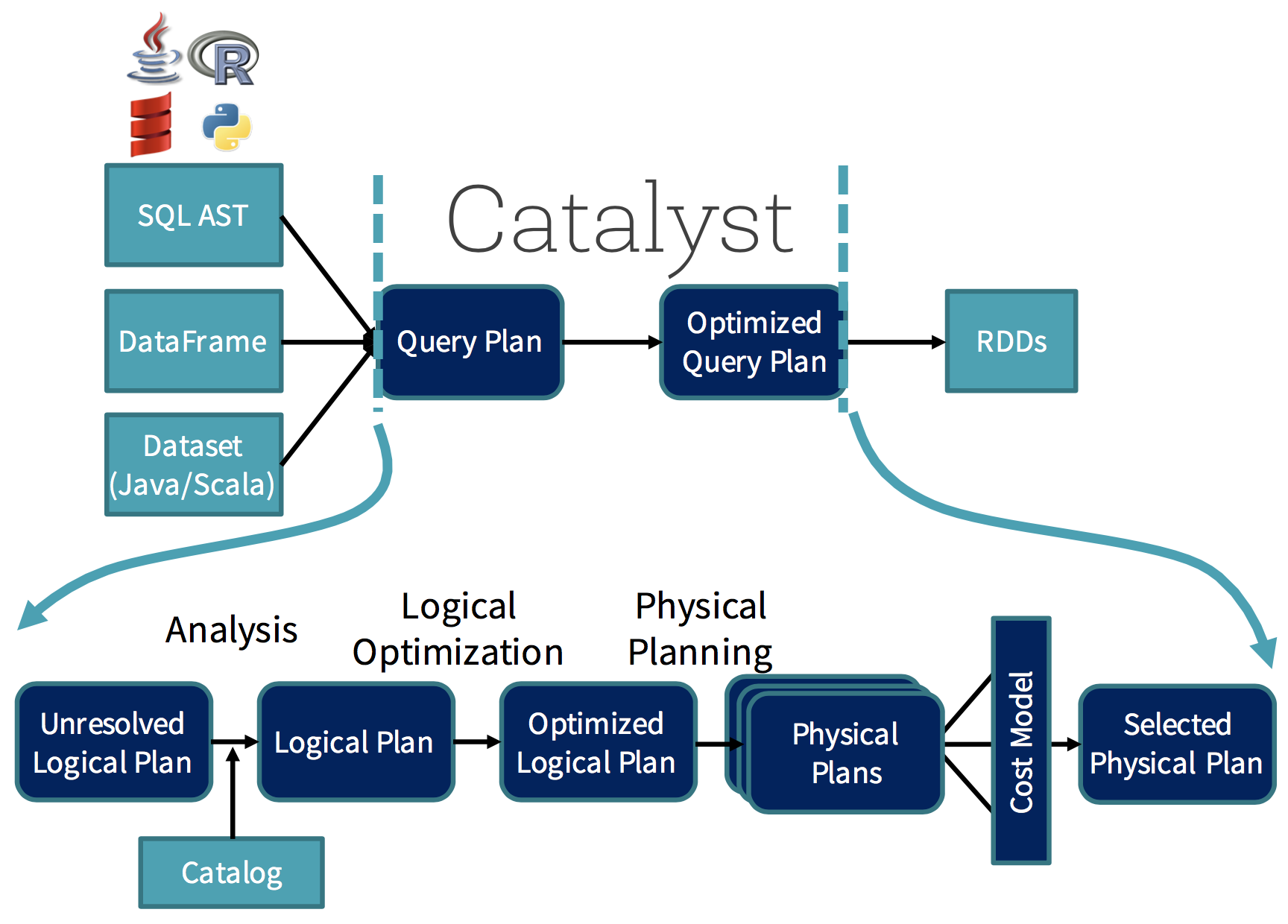
Optimización

¿Por qué?

Los datos sucios cuestan $3 trilliones+ por año


Las compañías pierden 12% de revenue
Malos Modelos

¿Por qué?
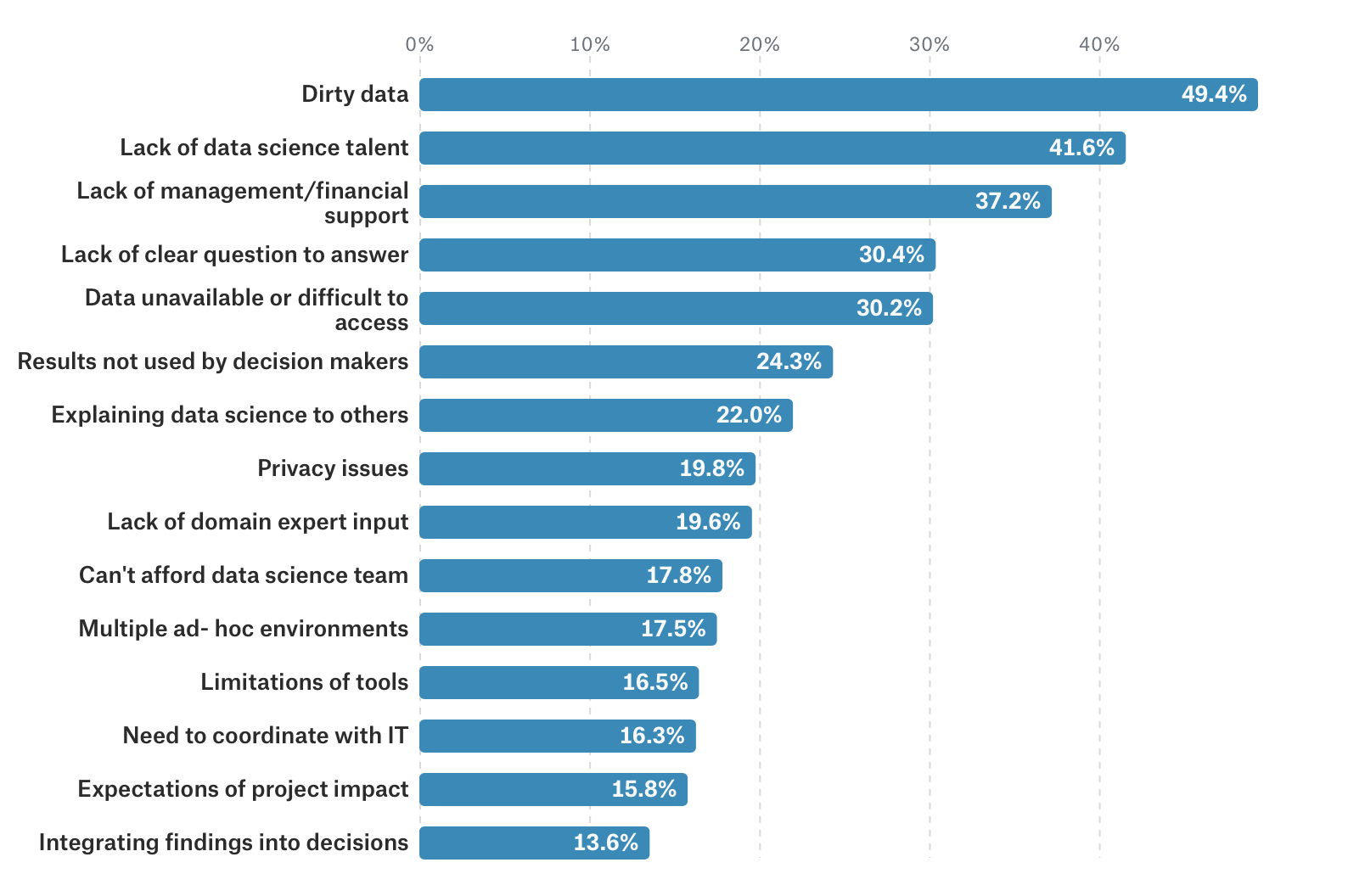
Encuesta Kaggle 16000 DS. Problemas.
Problemas

Los Datos están sucios

Fact of the day:

Problems
- Difíciles de usar y entender.
- La mayoría de ellos tienen su propio lenguaje.
- No son adecuados para Big Data.
- SampleClean no continuado y nada fácil de usar.
- Mala integración con Machine Learning.
- Atascados en la limpieza.
- Mal documentado.
- Un poco feos.
Soluciones actuales para limpiar datos


Optimus

Optimus is the missing framework for cleaning and pre-processing data in a distributed fashion. It uses all the power of Apache Spark (optimized via Catalyst) to do so. It implements several handy tools for data wrangling and munging that will make your life much easier. The first obvious advantage over any other public data cleaning library or framework is that it will work on your laptop or your big cluster, and second, it is amazingly easy to install, use and understand.
Optimus
Características:
- Fácil de instalar, usar e implementar.
- Utiliza Python y PySpark.
- Funciona en tu computadora portátil o clúster.
- DFTransformer con excelentes métodos para la limpieza de datos y disputas.
- DFAnalyzer con excelentes métodos para visualizar datos y comprender.
- Métodos para feature engineering (realmente fáciles de usar).
- Machine Learning con Spark (fácil e igualmente rápido). Trabajo en progreso.

Demo
Ciencia de Datos con Apache Spark y Optimus
By Favio Vazquez
Ciencia de Datos con Apache Spark y Optimus
Presentación sobre ciencia de datos con Spark y Optimus




