Decision Trees con Apache Spark

Favio Vázquez
Cosmólogo y Data Scientist


@faviovaz





17 de mayo de 2017
Seguir presentación en vivo

¿Quién soy?
- Venezolano
- Licenciado en Física e Ingeniero en Computación
- Estudiante de Maestría en el PCF-UNAM
- Data Scientist
- Colaborador del Proyecto de Apache Spark en GitHub


Releases 1.3.0, 1.4.0, 1.4.1 y 1.5.0



Resumen

¿Qué es el Big Data?
Actual paradigma en Big Data
¿Quién es un Data Scientist?
Apache Spark
Decision Tress
Demo (DT + Spark)
Big Data

¿Qué es?
Son los diversos tipos de procesos y estrategias de recolección, guardado y análisis que incluyen e integran distintos tipos de datos que no podrían ser estudiados con técnicas tradicionales de minería de datos.

Big Data
Nuevo Paradigma
Data Scientist
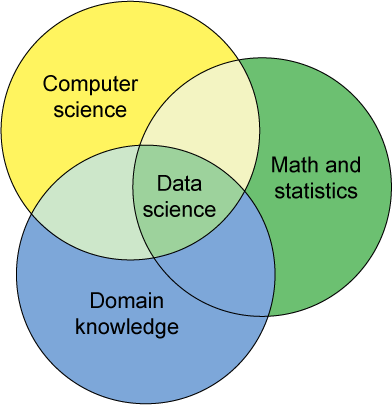
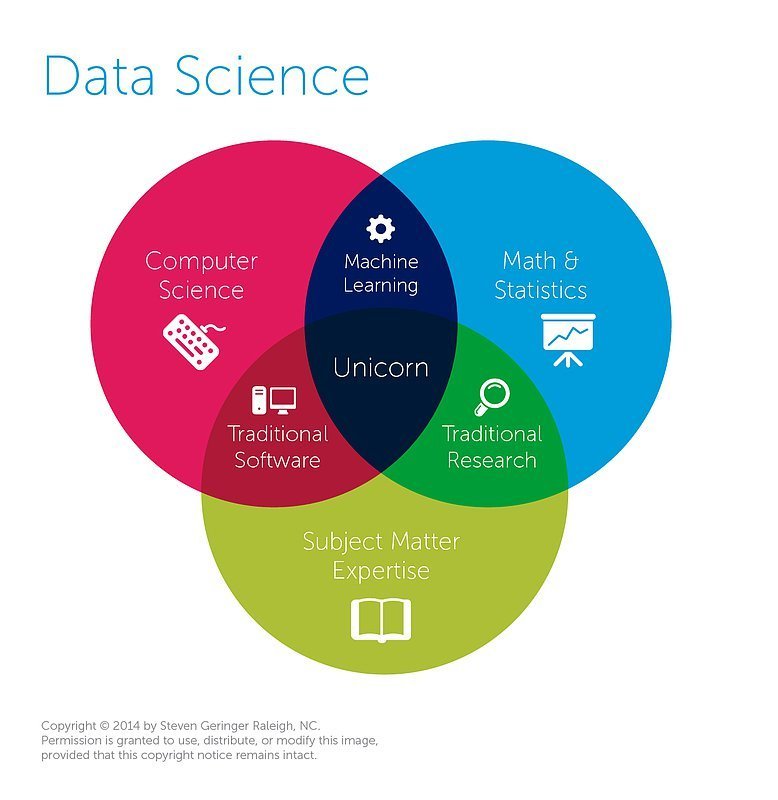
¿Quién es?

El encargado de saber todo lo necesario para poder utilizar las herramientas, lenguajes, plataformas y sistemas usados para analizar datos (tanto a pequeña como a gran escala)

Data Scientist
¿Qué debe saber?



¿Qué es complicado en Big Data?
La combinación compleja de hilos de ejecución, sistemas de almacenamiento y modos de trabajo.
- ETL, agregaciones, machine learning, streaming, etc.
Muy complicado obtener productividad y performance
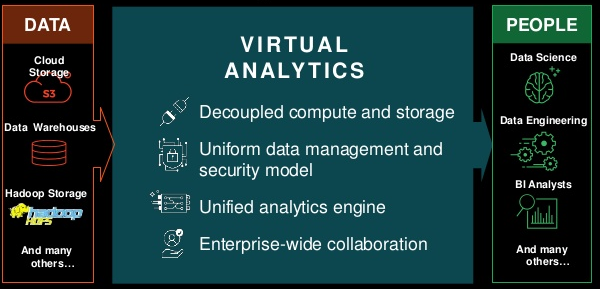
¿Qué es?
Es un motor general y muy rápido para el procesamiento en paralelo de datos en gran escala.




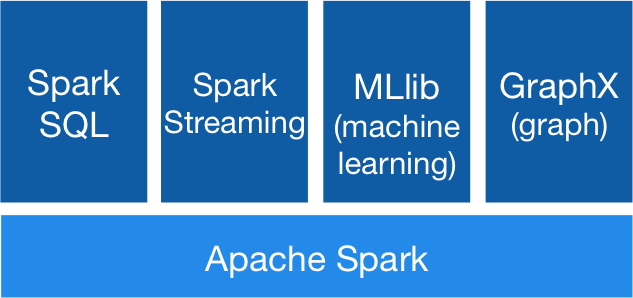

Motor Unificado
APIs de alto nivel con espacio para optimizar
- Expresa todo el workflow con una API
- Conecta librerías existentes y sistemas de almacenamiento
RDD
Transformaciones
Acciones
Caché
Dataset
Tipado
Scala y Java
Beneficios de RDD
Dataframe
Dataset[Row]
Optimizado
Versátil

Decision Trees
Decision
Trees

Son una forma de organizar gráficamente un proceso de decisión secuencial.



¿Como voy de mi casa a la UNAM?
Si
Si
No
No
Decision
Trees
DT -> Supervised Learning
Hay de dos tipos:
-
Clasificación
-
Regresión

Variables continuas
o discretas

Decision
Trees
¿Por qué usar Decision Trees?
- Expresivamente arbitrarios, pero fáciles de interpretar
- Fáciles de tunear
- Soporte natural para distintos tipos de features
- Fácilmente extendibles a ensambles (Random Forest) o técnicas de boosting (Boosted Trees)
Decision
Trees
Decision Trees en Spark
The decision tree is a greedy algorithm that performs a recursive binary partitioning of the feature space. The tree predicts the same label for each bottommost (leaf) partition. Each partition is chosen greedily by selecting the best split from a set of possible splits, in order to maximize the information gain at a tree node. In other words, the split chosen at each tree node is chosen from the set argmaxsIG(D,s) where IG(D,s) is the information gain when a split s is applied to a dataset D.
Decision
Trees
Decision Trees en Spark
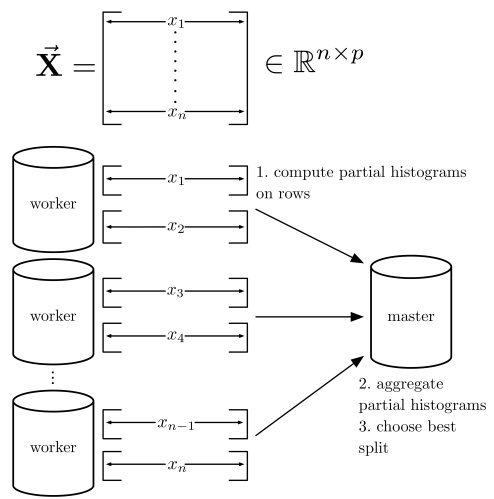
- Particionar el set de training por fila
- Se hacen histogramas para computar splits
- Los workers computan histogramas parciales en subconjuntos de filas
- El master agrega los histogramas parciales y escoge el mejor feature para hacer el split
Decision
Trees
Impureza de nodo
La impureza del nodo es una medida de la homogeneidad de las etiquetas en el nodo.

Ganancia de Información (IG)
La ganancia de información es la diferencia entre la impureza del nodo padre y la suma ponderada de las dos impurezas del nodo hijo.
IG(D,s) = Impurity(D) - \frac{N_{left}}{N} Impurity(D_{left}) - \frac{N_{right}}{N} Impurity(D_{right})
DEMO

¿Preguntas? ¿Dudas?
Favio Vázquez
Cosmólogo y Data Scientist
@faviovaz

Apache Spark
Decision Trees con Apache Spark
By Favio Vazquez
Decision Trees con Apache Spark
Proyecto final Bayesian Reasoning and Machine Learning - UNAM




