Machine Learning with Apache Spark

Favio Vázquez
Cosmologist & Data Scientist


@faviovaz





2 de junio de 2017
(And something more...)
Follow live presentation

About me
- Venezuelan
- Physicist and Computer Engineer
- Master student at PCF-UNAM
- Data Scientist
- Collaborator of Apache Spark project on GitHub


Releases 1.3.0, 1.4.0, 1.4.1 y 1.5.0



Outline

Machine Learning
Apache Spark
TensorFlow
Dask
MLeap
Demo (ML + Spark)
DVC

Machine Learning
Laying the foundations for Skynet




Machine Learning
Machine Learning is about software that learns from previous experiences. Such a computer program improves performance as more and more examples are available. The hope is that if you throw enough data at this machinery, it will learn patterns and produce intelligent results for newly fed input.
Machine Learning

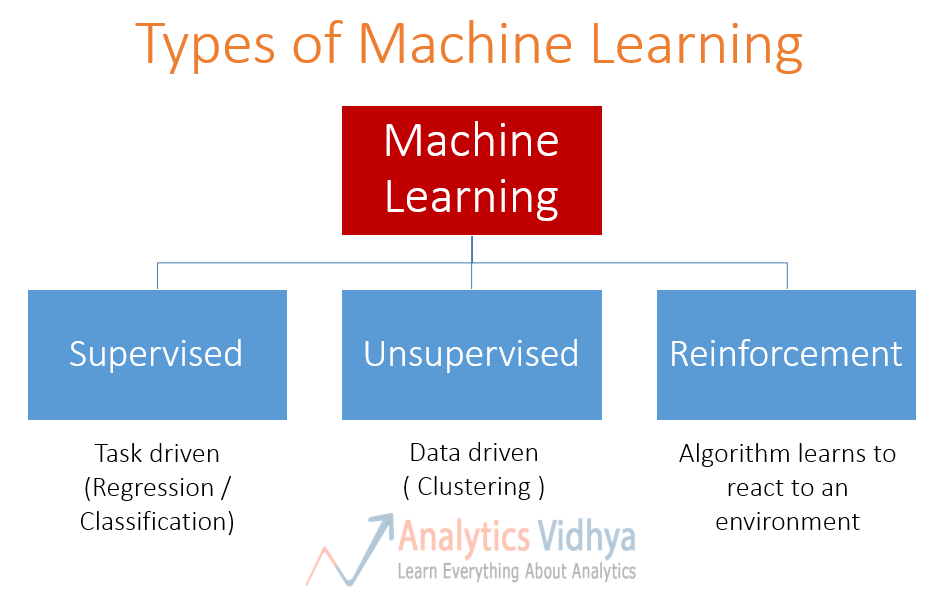
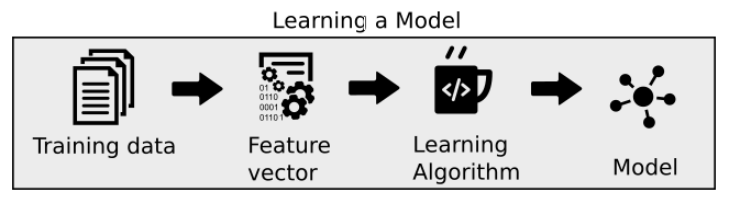
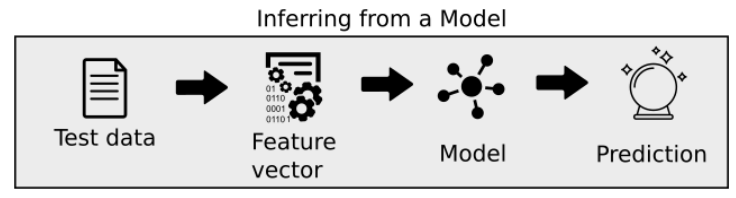
Machine Learning
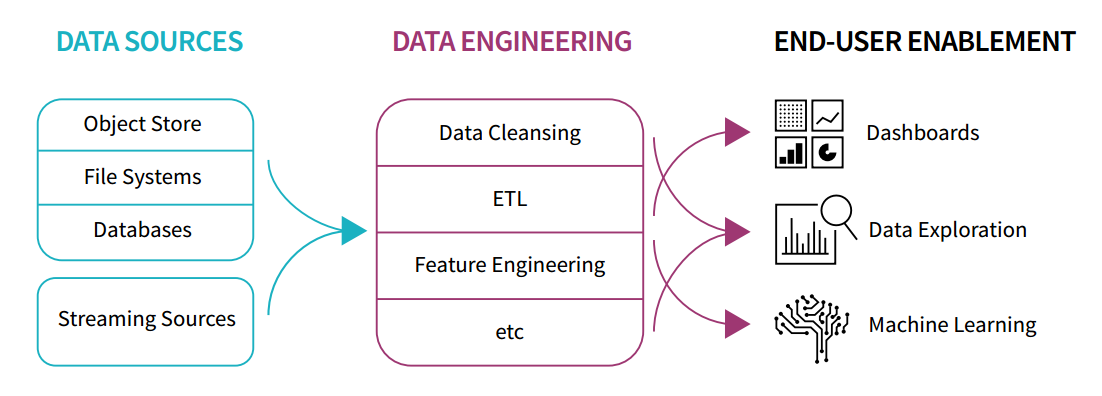


What is Spark?
Is a fast and general engine for large-scale data processing.





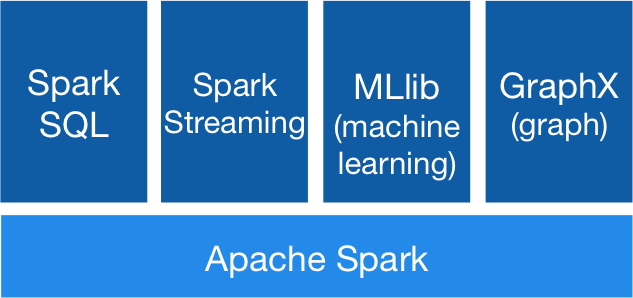
Unified Engine
High level APIs with space for optimization
- Expresses all the workflow with a single API
- Connects existing libraries and storage systems
RDD
Transformations
Actions
Caché
Dataset
Tiped
Scala & Java
RDD Benefits
Dataframe
Dataset[Row]
Optimized
Versatile

TensorFlow™ is an open source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API.


Deep Learning


Dask is a flexible parallel computing library for analytic computing.
- Dynamic task scheduling optimized for computation. This is similar to Airflow, Luigi, Celery, or Make, but optimized for interactive computational workloads.
- “Big Data” collections like parallel arrays, dataframes, and lists that extend common interfaces like NumPy, Pandas, or Python iterators to larger-than-memory or distributed environments. These parallel collections run on top of the dynamic task schedulers.
Components

import numpy as np
%%time
x = np.random.normal(10, 0.1, size=(20000, 20000))
y = x.mean(axis=0)[::100]
y
CPU times: user 19.6 s, sys: 160 ms, total: 19.8 s
Wall time: 19.7 simport dask.array as da
%%time
x = da.random.normal(10, 0.1, size=(20000, 20000), chunks=(1000, 1000))
y = x.mean(axis=0)[::100]
y.compute()
CPU times: user 29.4 s, sys: 1.07 s, total: 30.5 s
Wall time: 4.01 s> 4 GBs
MBs
MLeap is a common serialization format and execution engine for machine learning pipelines. It supports Spark, Scikit-learn and Tensorflow for training pipelines and exporting them to an MLeap Bundle. Serialized pipelines (bundles) can be deserialized back into Spark, Scikit-learn, TensorFlow graphs, or an MLeap pipeline for use in a scoring engine (API Servers).


Data Version Control
DVC makes your data science projects reproducible by automatically building data dependency graph (DAG).
DVC derives the DAG (dependency graph) transparently to the user.

Data Version Control
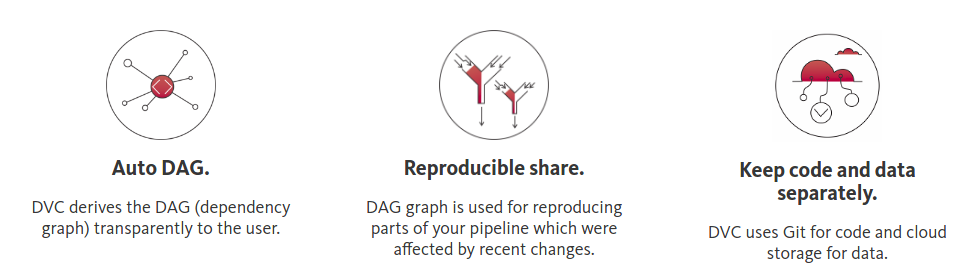
Share your code and data separately from a single DVC environment.

DEMO

Questions?
Favio Vázquez
Cosmologist & Data Scientist
@faviovaz

Apache Spark
TensorFlow
Dask
MLeap
DVC
Machine Learning with Apache Spark (and more)
By Favio Vazquez
Machine Learning with Apache Spark (and more)
Charla a dar el 2 de junio en el IA de la UNAM




